
多层线性模型简介
第一节多层线性模型概述
一、多层线性模型分析数据的特点
在社会科学研究中,调查得来的数据往往具有层次结构(嵌套结构)的特点,在心理学研究中这种情况尤为常见,如关于学业成绩影响因素的研究中,我们可以考虑的预测变量有学生的入学成绩、学生性别、学生的社会经济地位、班级人数、班主任和任课教师、教室环境等,这些变量中有的是学生个体变量,有的是班级整体变量。这样的数据具有两个水平,第一水平是学生,第二水平是班级,学生嵌套于班级之中,称为分层数据。如果观测涉及不同的学校• 同时考虑不同的学校变量,则构成一个三水平模型,即学生水平嵌套于班级水平,班级水平嵌套于学校水平。在层次结构数据中,不仅有描述个体的变量,而且有由个体组成的更高一层的变量。在经济学、地理学、心理学和社会学的研究中,不乏这样的数据存在。根据层次结构数据的特点,重复测量的数据也可以看成是具有层次结构的数据,其第一水平为不同测量,第二水平为个体,重复测量数据的这一层次性的特点扩大了多层线性模型的使用范围。
传统的线性回归模型假设变量间存在线性关系,变量总体上服从正态分布,方差齐性,个体间随机误差相互独立。而对于多层数据,传统的回归分析有以下两种处理方法。
(1 ) 在个体(如学生)水平上分析。即将所有的更高一层的变量(即组变量) 都看作第一水平的变量,直接在个体水平上对数据进行分析。这种分析方法存在的问题是,组变量对同一组内的个体有相同的影响,例如,班级变量对同一个班级内的学生有相同的影响,不同班级学生对应不同的班级变量,而不区分班级对学生的影响,假设同一班级的学生间相互独立是不合理的,同样对不同班级的学生和相同班级的学生作同一假设也是不合理的。
为了便于理解和计算,我们举一个简单的例子(例子数据为模拟生成的,实际数据将会更加复杂),以下一组数据中,共有 5 个组,每组 2 名被试,如表 13 - 1 所示。
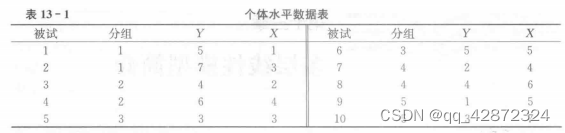
如果忽略组变量,直接在被试个体层面采用预测变量 X 对因变量 Y 进行回归分析,结果如表 13 - 2 和表 13 - 3 所示,
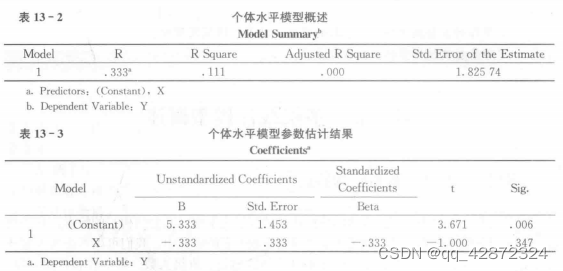
回归方程为:Y=5.333-0.333 X+£。回归方程图如图 13 - 1 所示。
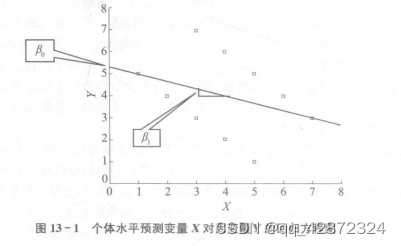
(2) 在组(如班级) 水平上分析。将第一水平的变量直接合并为第二水平的变量,然后直接对组水平(如班级) 做分析,这种分析方法存在的问题是丢失了组内个体间的差异的信息,而在实际中,这一部分的变异往往占总变异中很大的一部分。
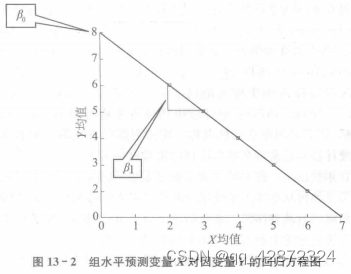
如果使用上述案例,将数据合并到组层面,则如表 13 - 4 所示。

直接在组层面采用预测变量 X 对因变量 y 进行回归分析,结果如表 13 - 5 和表 13 - 6所示。
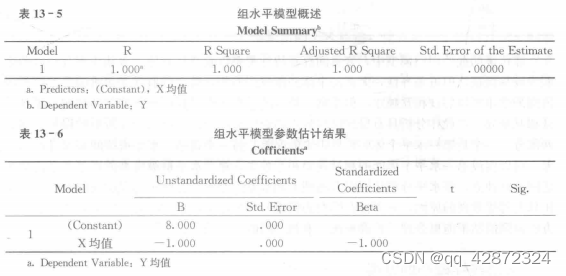
回归方程为:Y—8.000—1.000 X+e。 回归方程图如图 13 - 2 所示。
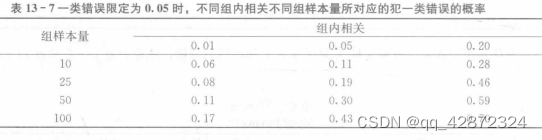
上述两种方法有可能得到不同的结果,在对结果的解释上也很不一致。基于上述的讨论,这两种分析数据的方法有一个共同点,即它们都没有考虑数据间分层的特点,有可能对数据结果做出不合理的甚至是错误的解释。这就是传统回归分析方法在分析具有结构层次特点数据时的局限性。具体来讲,传统回归分析没有考虑同一组观测值之间误差的相关,得到的标准误往往偏小,犯一类错误的概率往往偏大。如表 13 - 7 所示,已有研究发现,当组内相关为 0.20,一类错误率限定为 0.05, 且组内样本量达到 100 时,实际所犯—类错误的概率高达 0.70 (Barcikowski,1981;Kreft de Leeuw, 1998)。
在传统的线性回归模型中,变量间存在线性关系以及变量总体上服从正态分布这两个假设较易保证,但方差齐性,尤其是个体间随机误差相互独立的假设却很难满足。即不同班级的学生可以假设相互独立,但是同一班级的学生由于受相同班级变量的影响,很难保证相互独立。因此在分析具有层次结构特点的数据时,应将传统回归分析中的误差分解为两部分,一个是第一水平个体间差异带来的误差,另一个是第二水平班级间差异带来的误差。可以假设第一水平个体间的测量误差相互独立,第二水平班级带来的误差在不同班级之间相互独立。多水平分析法同时考虑到不同水平的变异,这也正是多层线性分析法的应用越来越受重视的原因,它不仅在模型的假设上与实际情况更加吻合,更重要的是由这种方法得到的结果能更合理、正确地揭示事物之间的真正关系。
二、多层线性模型的发展
多层线性模型在不同的学科领域有不同的名称,如在社会学的研究中常用多水平线性模型(multilevel linear model ) 这 一 术 语 (例 如,Goldstein, 1987;Mason,Wong,& - Entwisle,1983);在生物计量学中,常采用混合效应模型 (mixed-effects model) 或 随 机效 应 模 型 ( random-effect model) 这 一 术 语 (例 如,Elston & Grizzle,1962;Laird 8/. Ware, 1982);在计量经济学中称为随机系数回归模型(mndom-coefficiem model; 例 如,Rosenberg,1973);统计学中用协方差成分模型 ( covariance components model) 这一术语。不管采用什么样的名称,实质上都没有区别。在本书中,我们采用能够充分体现这一统计技术数据特征的多层线性模型这一术语。
自 20 世纪 70 年代以来,许多研究者开始寻求怎样将系统的方法引入社会科学的研究中,主要是一种关于如何从整体上系统地分析研究得来的数据特征和合理建立模型的统计方法。协方差结构模型为从整体的、系统的角度分析事物间的因果关系提供了可能,使得传统回归分析的方法从理论上和实际应用上都得到了相当范围的推广。自 20 世纪 80 年代以来,Aitkin 和 Longford (1986) 等将系统的方法应用于具有层次特征结构数据的统计建模和分析中,这一方法的主要原理就是多层线性模型的理论。20 世纪 90 年代初期,随着计算机技术的发展,出现了专门用于分析具有多层特征结构数据的软件。从多层分析法的发展阶段来看,主要经历了以下三个阶段。
(一)模型理论构想阶段
多层线性模型这一术语最早由 Lindley 和 Smith 于 1972 年提出,这一模型的提出对后来贝叶斯线性模型的发展起到很大的作用,他们构建了具有复杂误差结构的嵌套数据的一般模型结构。但是由于该模型参数估计的方法与传统的回归方法不同,他们提岀的模型需要估计非平衡数据的方差成分和不同水平的误差协方差矩阵,在计算上遇到了很大的障碍,正是由于计算技术的限制,它在很长一段时间内没得到推广。这一阶段发展的主要特点是仅限于理论上对该模型进行探讨。
(二)问题解决阶段
Dempster,Laird 和 Rubin (1977) 等提出的 EM 算法,使得解决参数估计这一问题有了实质性的突破。Dempster,Rubin 和 Tsutakawa (1981) 等将 EM 算法应用于解决多层线性模型的参数估计,使这一方法的应用成为可能。Strenio,Weisberg 和 Bryk (1983) 等相继将这一方法应用于社会学的研究,使这一方法得以具体应用。随后,Goldstein (1986) 应用迭代加权广义最小二乘法 (iteratively reweightecl generalized least squares)估计参数,Longford (1987) 应用 Fisher 得分算法 (Fisher scoring algorithm) 对模型参数进行了估计。在这一阶段,发展出了一系列估计参数的理论和计算方法。
(三)快速发展阶段
随着参数估计问题的解决和计算机技术的发展,很多算法被程序化,相继出现了一些相应的软件,目前较常用的有 HLM、 Mplus, SPSS、MlwiN 和 VARCL 等。这一系列统计软件的开发和应用使这一方法很快被应用于社会科学各个领域的研究。
三、多层线性模型在心理学研究中的应用
正如前面所述,心理学研究中得来的大量资料都具有层次结构的特点,数据间复杂的结构关系,使得传统线性回归方法的假设难以满足。多层线性模型的提出为正确解决这一问题提供了可能,它不仅从方法上考虑复杂的变量误差之间的关系,还能更加合理地从理论上解释变量之间的关系。用多层线性模型分析具有嵌套结构的数据主要出于以下几方面的考虑:(1) 多层线性模型能更加合理地估计个体变量对于因变量的影响;(2) 多层线性模型可以考虑不是同一水平的变量间的影响,如可以考虑班级人数对于学生学业成绩的影响;(3) 多层线性模型可以在多水平间分解方差和协方差成分,如可以将一组学生水平变量之间的相关分解为学校内和学校间两个部分。
多层线性模型在处理心理学研究中具有层次结构特点的数据时,与传统方法相比有以下几方面的优点。


 。在对一个学校进行分析时,传统的回归方法可以较好地解释数据之间的关系,但是如果所考察的学生不是来自同一个学校,而我们仍然用公式(13- 1)中的回归模型来表示,如前文所示,这样就不能分析出两个学校之间的差异。在这种情况下,同一个学校的学生之间往往具有比不同学校学生更大的相似性,对所有的学生假设他们的误差项相互独立通常并不合理,方差齐性的假设也不一定成立。多层分析在有多个学校的情况下,同时考虑学生和学校这两个水平,不要求误差相互独立和方差齐性的假设。
。在对一个学校进行分析时,传统的回归方法可以较好地解释数据之间的关系,但是如果所考察的学生不是来自同一个学校,而我们仍然用公式(13- 1)中的回归模型来表示,如前文所示,这样就不能分析出两个学校之间的差异。在这种情况下,同一个学校的学生之间往往具有比不同学校学生更大的相似性,对所有的学生假设他们的误差项相互独立通常并不合理,方差齐性的假设也不一定成立。多层分析在有多个学校的情况下,同时考虑学生和学校这两个水平,不要求误差相互独立和方差齐性的假设。


 表示第j个学校第 i个学生因变量的观测值(如学生的学业成绩),
表示第j个学校第 i个学生因变量的观测值(如学生的学业成绩),
 表示第j个班级第i个学生预测变量的观测值(如学生的学习动机),
表示第j个班级第i个学生预测变量的观测值(如学生的学习动机),
 表示第j个学校的学校特征变量 (如学校的平均社会经济地位)。对于第一水平模型,
表示第j个学校的学校特征变量 (如学校的平均社会经济地位)。对于第一水平模型,
 和
和
 分别表示第 j个学校的平均社会经济地位对学生学业成绩回归直线的截距和斜率,
分别表示第 j个学校的平均社会经济地位对学生学业成绩回归直线的截距和斜率,
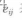 表示第 j 个班级第 i个学生的测量误差。对于第二水平模型,
表示第 j 个班级第 i个学生的测量误差。对于第二水平模型,
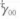 和
和
 分别表示学校变量
分别表示学校变量
 对于截距
对于截距
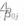 的回归直线的截距和斜率,
的回归直线的截距和斜率,
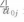 表示由第 j 个学校的学校变量带来的截距上的误差。
表示由第 j 个学校的学校变量带来的截距上的误差。
 和
和
 分 别 表 示 班 级 变 量
分 别 表 示 班 级 变 量
 对 于 截 距
对 于 截 距
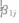 的 回 归 直 线 的 截 距 和 斜 率,
的 回 归 直 线 的 截 距 和 斜 率,
 表 示 由 第j个学校的学校变量带来的斜率上的误差。
表 示 由 第j个学校的学校变量带来的斜率上的误差。








版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/105994.html