
Parameter and Embedding Personalized Network (PEPNet)
背景
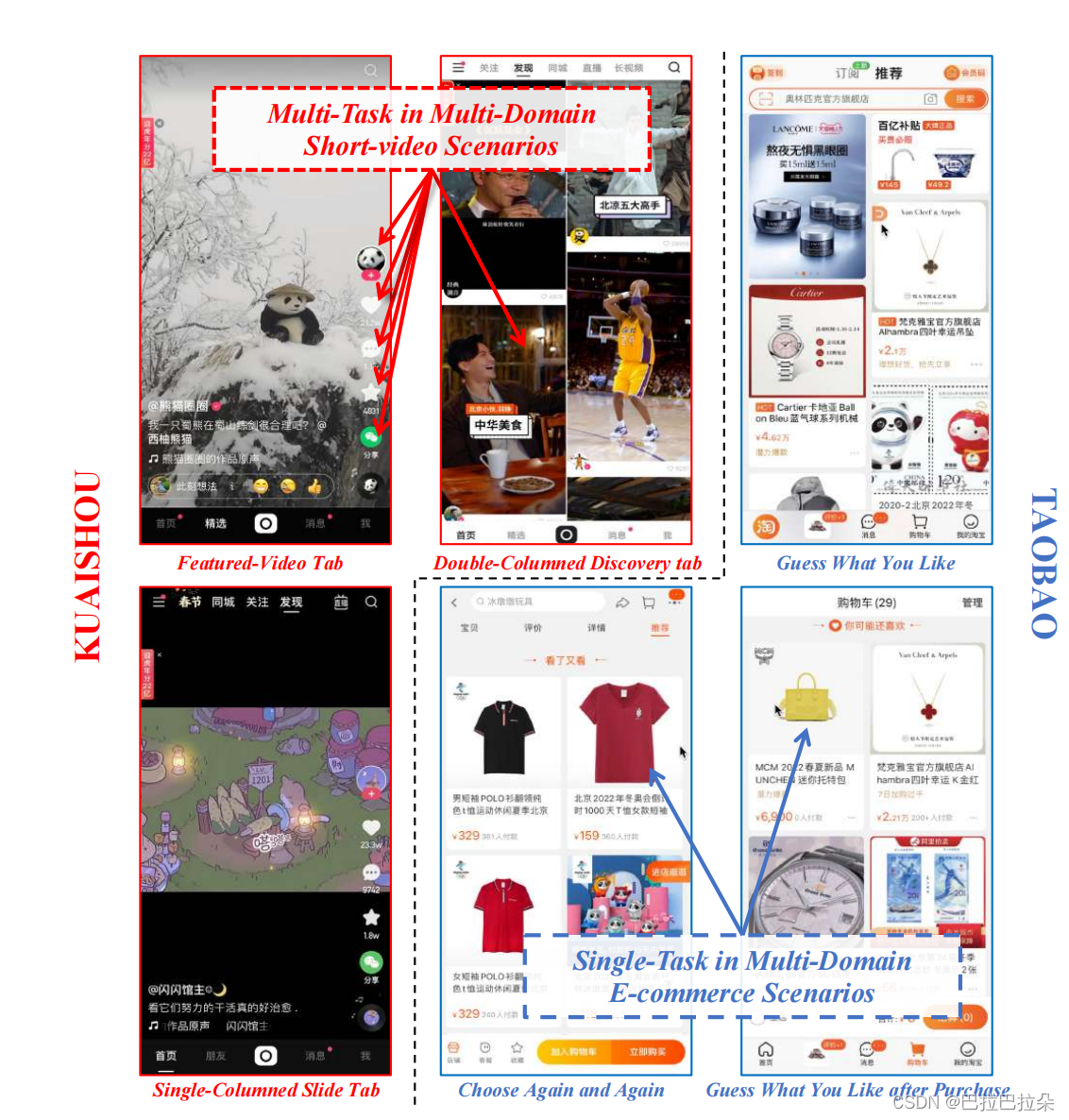
user及item在不同场景有交叉重叠,场景之间存在共性;任务之间也存在相互关系,单独为每个场景训练单独的模型既耗费人力也无法利用全量的数据,忽略了场景之间的共性,因此需要多场景多任务建模。
业务挑战&难点:
双跷跷板效应
- 所有样本混合在一起训练,不同场景有不同的数据分布,容易出现场景跷跷板效应(domain seesaw)
- 不同的目标有不同的稀疏性,而且目标之间有相关性,会相互影响,容易出现任务跷跷板效应(task seesaw)
解决方案
点评:通过输入的个性化先验信息通过gate机制动态缩放底层的Embedding参数以及上层的DNN隐层参数
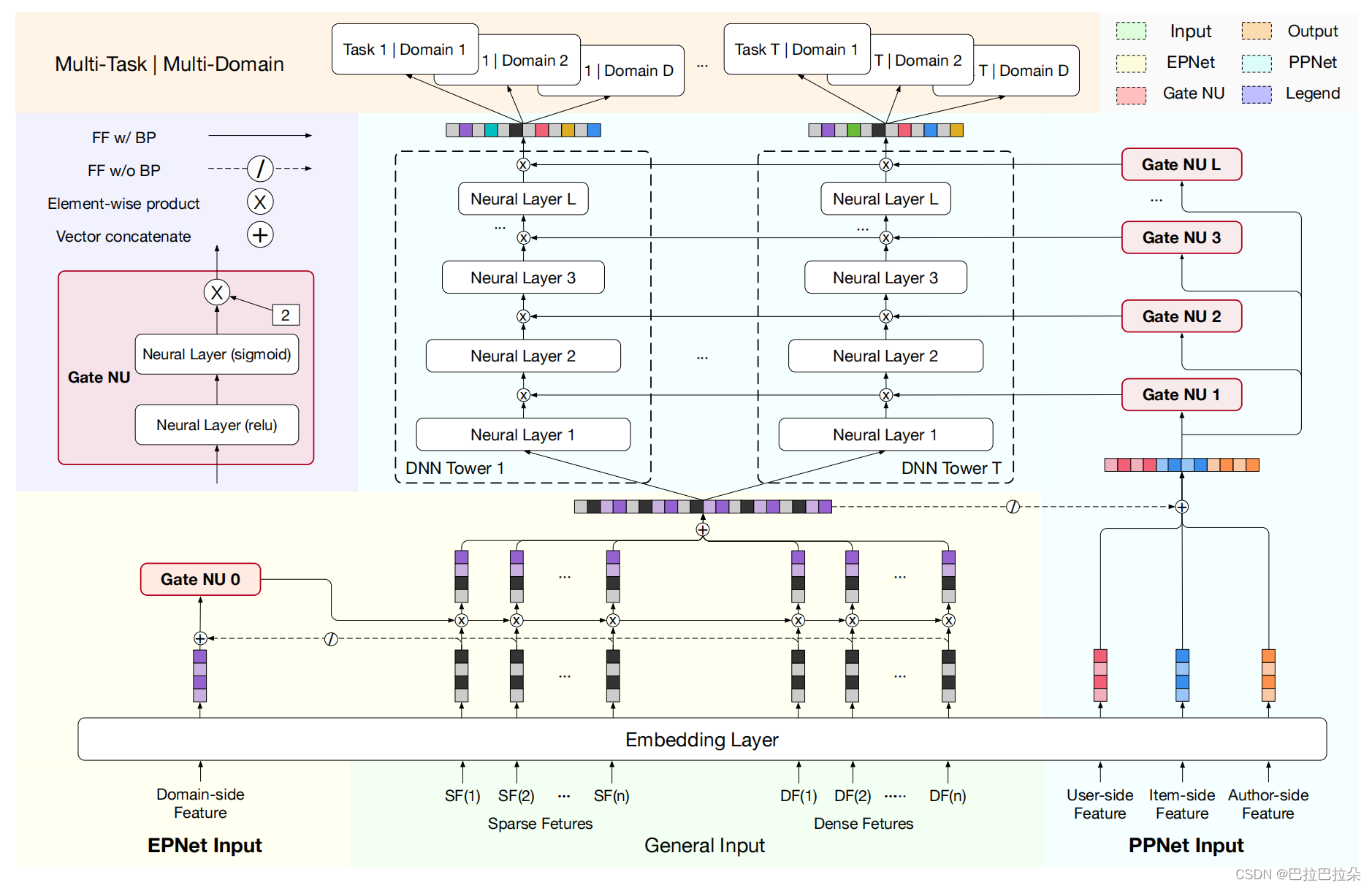
方案详情:
Gate NU是由两层网络结构实现,第一层目的是交叉输入的先验信息 x \mathbf x x,通过非线性函数relu进行激活,第二层通过sigmoid函数产生gate缩放分数,用 γ \gamma γ来调节缩放的程度
x ′ = R e l u ( x W + b ) \mathbf x^{'} = Relu(\mathbf x \mathbf W + \mathbf b) x′=Relu(xW+b)
δ = γ ∗ S i g m o i d ( x ′ W + b ′ ) \mathbf \delta = \gamma * Sigmoid(\mathbf x^{'} \mathbf W + \mathbf b^{'}) δ=γ∗Sigmoid(x′W+b′)
Embedding Personalized Network(EPNet)
这里 ⊘ \oslash ⊘表示GateNU不对原来的Embedding层做梯度回传,也就是说虽然GateNU会缩放改变Embedding,但是不对Embedding进行梯度回传,避免和主体网络的梯度回传冲突混乱。GateNU这种参数缩放的方式,其实是一种注入的方式,还是尽量减少对原始Embedding的影响。
Parameter Personalized Network(PPNet)
user、item、author的相关特征表示为 F u F_u Fu/ F i F_i Fi/ F a F_a Fa,这部分先验输入拼接起来再和底层经过场景先验注入的Embedding拼接在一起作为PPNet的网络输入
这里 H \mathbf H H表示DNN的隐层 H = [ H 1 , H 2 , . . . , H T ] \mathbf H=[H_1,H_2,...,H_T] H=[H1,H2,...,HT],其中 H t ∈ R h H_t \in R^h Ht∈Rh表示任务 t t t任务塔的隐层单数量, δ t a s k ∈ R h ∗ T \mathbf \delta_{task} \in R^{h*T} δtask∈Rh∗T需要split拆分成 T T T个 h h h维度的向量,这样好乘到任务的隐层单上面,达到改变任务塔隐层的目的。
对DNN每一层进行这样的处理,假设有 L L L层
O l = δ t a s k l ⊗ H l \mathbf O^l = \mathbf \delta_{task}^l \otimes \mathbf H^l Ol=δtaskl⊗Hl
H l + 1 = f ( O l W + b l ) l ∈ { 1 , 2 , . . . , L } \mathbf H^{l+1} = f( \mathbf O^l \mathbf W + \mathbf b^l ) \ \ \ l \in \{1,2,...,L\} Hl+1=f(OlW+bl) l∈{
1,2,...,L}
消融分析
超参数分析
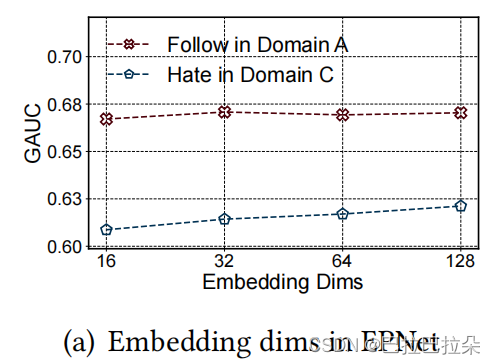
Embedding维度,维度在16维的时候已经能取得较好的效果
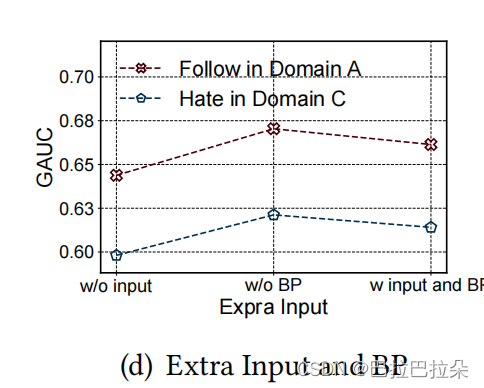
把GateNU对input的后向梯度传播加/不加进来,说明不对主网络进行更新效果更好
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/4638.html