
目录
(一)启动Redis:默认配置 + 运行配置 + 配置文件启动
1. 使用 redis-cli shutdown 命令停止 Redis
(五)键过期:expire、expireat、pexpire、pexpireat
干货分享,感谢您的阅读!
Redis,作为一个开源的高性能键值对数据库,广泛应用于缓存、消息队列、实时分析等场景。它凭借着快速的读写性能和丰富的数据结构,成为了开发者在构建高效系统时的重要工具。然而,对于很多开发者而言,虽然 Redis 的基本操作相对简单易用,但要真正掌握它的使用精髓,理解其内部编码机制和适用场景,是提升性能和优化应用的重要一环。
本文将从 Redis 的基本键值 API 使用入手,逐步深入探讨其内部编码方式,并结合实际场景进行详细讲解。无论你是 Redis 新手,还是已经有一定使用经验的开发者,都能通过本文获得对 Redis 更加全面的理解,掌握如何在不同的场景下高效使用 Redis,最大化其性能和优势。
一、Redis的启动、配置、命令行操作和关闭
(一)启动Redis:默认配置 + 运行配置 + 配置文件启动
Redis 启动方式有三种,分别为默认配置启动、运行配置启动以及通过配置文件启动。
1. 默认配置启动
redis-server特点
- 无需额外参数,直接使用 Redis 内置的默认配置启动服务。
- 默认配置适用场景:适合本地开发和调试,不需要任何配置文件或额外设置。
局限性
- 默认端口为
6379,未启用密码(安全性不足)。 - 日志、数据持久化等关键参数使用默认值,不适合生产环境。
- 配置无法动态调整,限制灵活性。
总结: 仅适用于快速启动和测试环境。
2. 运行配置启动
redis-server --configKey1 configValue1 --configKey2 configValue2特点
- 在启动时,通过命令行直接指定配置信息,例如:
redis-server --port 6380 --requirepass "yourpassword" --daemonize yes - 配置覆盖默认值,无需单独的配置文件。
- 适用场景:适合临时测试或小规模部署。
优点
- 灵活性:可以快速调整指定配置。
- 不需要准备额外的配置文件。
局限性
- 如果配置项较多,命令行会变得冗长且难以维护。
- 不适合复杂环境,修改配置需要重启服务。
总结: 适用于开发或测试阶段的临时配置,生产环境中使用不便。
3. 配置文件启动
redis-server /path/to/redis.conf特点
- 配置集中存储在文件中,Redis 启动时加载指定配置文件。例如:
redis-server /root/zyf/redis-4.0.6/redis.conf - 灵活性:可以在配置文件中调整任意参数,支持复杂配置。
- 生产推荐:适合生产环境使用。
优点
- 易维护:所有配置集中于文件,便于修改和记录版本。
- 可读性强:文件结构清晰,方便多人协作。
- 功能完整:配置文件支持 Redis 的全部配置选项。
配置文件关键参数
以下是生产环境中常见的配置选项:
- 端口:
port 6379。修改为非默认端口以提升安全性。 - 密码认证:
requirepass yourpassword。强制密码访问,防止未授权使用。 - 后台运行:
daemonize yes。让 Redis 以守护进程方式运行。 - 日志路径:
logfile /path/to/redis.log。日志文件路径,便于监控。 - 持久化策略:
appendonly yes。启用 AOF 日志记录操作,确保数据可靠性。 - 内存限制:
maxmemory 1gb。限制内存使用,防止 Redis 占用过多系统资源。
总结
- 配置文件启动是生产环境的最佳实践。
- 文件管理更方便,配置参数更全面,支持版本控制。
4.建议:生产环境中使用配置文件启动
理由:
- 安全性:通过配置文件可以细致地设置密码、访问控制等。
- 稳定性:可明确记录 Redis 的所有运行参数,避免遗漏。
- 维护性:配置文件便于修改和保存,方便版本管理。
- 可扩展性:适合处理复杂场景,例如集群部署或内存分配优化。
推荐操作步骤:
- 创建或修改配置文件:
vi /root/zyf/redis-4.0.6/redis.conf - 根据需求修改关键配置项。
- 启动 Redis:
redis-server /root/zyf/redis-4.0.6/redis.conf - 检查日志和运行状态,确保配置生效。
通过上述方式,Redis 可以在生产环境中更加安全、高效地运行。
(二)Redis连接与命令行操作
Redis 提供了两种主要的客户端交互方式来连接和操作 Redis 服务器,分别是交互式操作模式和命令行操作模式。
1. Redis 连接工具简介
redis-cli 是 Redis 官方提供的命令行客户端工具,用于与 Redis 服务器交互。
主要作用:
- 检查 Redis 服务器是否正常运行。
- 执行 Redis 的各种命令,支持数据操作、配置管理、监控等。
常用连接参数
-h:指定服务器主机名或 IP 地址,默认127.0.0.1。-p:指定服务器端口号,默认6379。-a:指定连接密码,用于有密码认证的 Redis。--raw:使返回结果以原始字符串格式显示。
2. 交互式操作模式
命令格式:
redis-cli -h {host} -p {port}使用方法:
- 启动 Redis 服务后,运行上述命令即可进入交互式命令行。
- 示例:
redis-cli -h 127.0.0.1 -p 6379输出:
127.0.0.1:6379>127.0.0.1:6379>表示成功连接到 Redis 服务器。 - 交互中直接输入 Redis 命令即可,例如:
127.0.0.1:6379> SET key "value" OK 127.0.0.1:6379> GET key "value"
特点
- 类似于数据库的 REPL(Read-Eval-Print Loop)环境。
- 适合手动调试和测试:可以连续输入多条命令,查看实时结果。
- 支持命令补全,方便输入。
优点
- 实时交互:快速验证命令是否正确执行。
- 易用性:支持简单的上下文操作和返回值查看。
局限性
- 不适合批量操作:无法一次性执行多个命令。
- 需要人工输入,效率低。
3. 命令行操作模式
命令格式:
redis-cli -h {host} -p {port} {command}使用方法:
- 直接在命令行中运行 Redis 命令,无需进入交互式环境。
- 示例:
redis-cli -h 127.0.0.1 -p 6379 SET key "value" OK redis-cli -h 127.0.0.1 -p 6379 GET key "value" - 可以通过脚本批量执行命令:
for i in {1..5}; do redis-cli -h 127.0.0.1 -p 6379 SET key$i "value$i"; done
特点
- 单次命令执行:每次运行执行一条命令后退出。
- 支持直接使用系统 Shell 的功能,例如脚本批处理和管道操作。
优点
- 高效:无需进入交互环境,适合自动化任务。
- 批量执行:通过 Shell 脚本完成多条命令操作。
- 易集成:可以集成到监控或运维工具中。
局限性
- 不支持上下文操作:命令结果返回后退出。
- 执行多条命令需要依赖外部脚本。
4. 使用场景对比
| 功能 | 交互式操作模式 | 命令行操作模式 |
|---|---|---|
| 使用目的 | 手动调试、测试 | 自动化任务、批处理操作 |
| 操作效率 | 较低:手动输入单条命令 | 高效:一次运行一条或多条命令 |
| 灵活性 | 高:支持上下文连续操作 | 较低:单次执行,需多次调用 |
| 适用场景 | 命令调试、临时查看状态 | 脚本任务、自动化运维 |
| 依赖环境 | 需要交互式终端 | 无需交互,直接在命令行执行 |
5. 推荐使用方式
调试和日常查看:使用交互式模式(redis-cli -h -p)。
- 适合开发人员进行手动调试,例如测试命令执行、查看数据状态等。
- 示例:
redis-cli -h 127.0.0.1 -p 6379 127.0.0.1:6379> KEYS *
批量任务和自动化运维:使用命令行模式(redis-cli -h -p {command})。
- 适合运维人员在脚本中集成 Redis 命令。
- 示例:
redis-cli -h 127.0.0.1 -p 6379 CONFIG GET maxmemory
生产环境连接:
- 如果 Redis 开启了密码认证,务必使用
-a参数指定密码:redis-cli -h 127.0.0.1 -p 6379 -a yourpassword - 建议结合脚本检查 Redis 的状态,确保服务正常运行。
通过熟练使用 redis-cli 的这两种模式,可以在调试、维护和自动化任务中灵活处理 Redis 服务器的各种操作。
(三)停止Redis服务
停止 Redis 服务时,需选择合适的方法以确保服务安全关闭并避免数据丢失。
1. 使用 redis-cli shutdown 命令停止 Redis
基本命令
redis-cli shutdown工作原理
- 有序关闭:
shutdown命令通知 Redis 进行以下操作:- 停止接收新的客户端请求。
- 如果启用了 RDB 或 AOF 持久化,Redis 会将内存中的数据保存到磁盘。
- 关闭所有客户端连接。
- 停止 Redis 服务进程。
- 如果 Redis 配置文件中启用了
appendonly yes或save(RDB 触发条件),shutdown将确保所有数据成功写入持久化文件。
两种模式
- 默认模式(save 模式):Redis 会进行持久化保存操作。适合大多数场景,但如果数据量较大,可能需要更长的关闭时间。
- 强制模式(nosave 模式):忽略持久化步骤,直接关闭服务。适合临时性使用或对数据可靠性要求较低的场景。
redis-cli shutdown nosave
优点
- 数据安全:确保关闭前完成必要的持久化操作。
- 自动化友好:可以通过脚本或运维工具触发。
- 推荐用法:适合所有 Redis 实例的安全关闭,尤其是生产环境。
2. 使用 kill 停止 Redis 进程
基本命令
- 查询 Redis 进程 ID:
ps -ef | grep redis示例结果:
12345是 Redis 服务的进程 ID。redis 12345 1 0 15:02 ? 00:00:02 /usr/bin/redis-server *:6379
- 发送停止信号:
kill 12345
工作原理
kill命令发送信号给 Redis 进程,默认是SIGTERM信号:- SIGTERM(默认信号):通知 Redis 安全关闭,与
redis-cli shutdown效果相同。 - SIGKILL(kill -9):强制终止 Redis 进程,无法触发任何关闭逻辑。
- SIGTERM(默认信号):通知 Redis 安全关闭,与
注意:避免使用 kill -9
kill -9是强制信号,直接终止进程,不执行以下操作:- 数据持久化。
- 释放资源(如文件句柄、网络连接)。
- 可能导致以下问题:
- 数据丢失:未保存到磁盘的内存数据丢失。
- 数据文件损坏:AOF 文件可能处于不一致状态,无法恢复。
- 服务状态异常:Redis 重启时可能遇到错误,需要手动修复。
优点和局限性
- 优点:适合在无法使用
redis-cli时(如网络问题、权限受限)关闭 Redis。 - 局限性:不如
shutdown命令智能,需确保发送的信号正确。
3. 对比与建议
| 方法 | redis-cli shutdown | kill |
|---|---|---|
| 操作复杂度 | 简单:直接输入命令 | 需手动查询进程 ID,适度增加复杂度 |
| 数据安全性 | 高:默认保存数据到磁盘 | 较低:SIGTERM 安全,但 SIGKILL 存在风险 |
| 适用场景 | 生产环境优先,安全关闭 | 用于无法使用 redis-cli 的特殊情况 |
| 数据一致性 | 确保一致性,适合启用持久化的环境 | 如果使用 SIGKILL,可能导致数据不一致 |
4. 正确关闭 Redis 的推荐流程
常规方法:使用 redis-cli shutdown
- 登录到 Redis 服务器:
redis-cli -h {host} -p {port} -a {password} shutdown - 默认保存数据后关闭。如果需要忽略保存,可添加
nosave。
特殊场景:使用 kill 发送 SIGTERM
- 如果无法通过
redis-cli连接服务(例如:网络异常),使用以下方法:ps -ef | grep redis kill {redis-pid} - 确保只发送
SIGTERM信号,避免kill -9。
禁止使用 kill -9:最后手段
- 如果 Redis 进程卡死,且无法通过
shutdown或SIGTERM停止,可以考虑kill -9:kill -9 {redis-pid} - 后续检查:检查数据文件状态(AOF 或 RDB 是否损坏)。检查服务是否能正常重启。
5.总结
- 生产环境推荐:优先使用
redis-cli shutdown,确保数据安全关闭。 - 应急场景使用
kill:发送SIGTERM信号(避免使用kill -9)。 - 禁用
kill -9强制终止,除非确认服务已完全不可恢复。
使用合适的方法停止 Redis 服务可以有效避免数据丢失和服务中断,保障系统稳定运行。
二、对键的基本操作命令讲解
在 Redis 中,键(key)是存储数据的基本单,每个键对应一个值。对键的操作是 Redis 中最常用的功能之一,提供了多种操作命令来管理和操作这些键。下面是对 Redis 中常见的键操作命令的详细讲解:
(一)查看所有的键:keys *
命令:keys *
功能:列出当前数据库中所有的键。* 是通配符,表示匹配所有的键。
注意:该命令在生产环境中应谨慎使用,因为它会遍历整个数据库,可能会造成性能问题,尤其是键的数量非常大的时候。
示例
127.0.0.1:6379> keys * 1) "name" 2) "age" 3) "city"(二)键总数:dbsize
命令:dbsize
功能:返回当前数据库中键的总数。它只统计当前数据库(默认为数据库 0)中的键。
注意:如果 Redis 配置了多个数据库(通过 SELECT 命令切换数据库),dbsize 只会返回当前选中的数据库的键总数。
示例
127.0.0.1:6379> dbsize (integer) 3(三)检查键是否存在:exists key
命令:exists key
功能:检查给定的键是否存在。返回值:
- 1:键存在。
- 0:键不存在。
示例
127.0.0.1:6379> exists name (integer) 1(四)删除键:del key [key ...]
命令:del key [key ...]
功能:删除一个或多个键。如果键存在,则删除该键并返回删除的键的数量。
注意:如果键不存在,del 命令不会对 Redis 造成影响。
示例
127.0.0.1:6379> del name (integer) 1(五)键过期:expire、expireat、pexpire、pexpireat
设置键的过期时间
命令:
expire key seconds:设置键的过期时间(单位:秒)。expireat key timestamp:设置键的过期时间(单位:Unix 时间戳)。pexpire key milliseconds:设置键的过期时间(单位:毫秒)。pexpireat key timestamp:设置键的过期时间(单位:毫秒级 Unix 时间戳)。
示例
127.0.0.1:6379> expire name 60 (integer) 1 127.0.0.1:6379> expireat name (integer) 1清除键的过期时间:persist key
命令:persist key
功能:清除指定键的过期时间,使其不再过期。
注意:若键不存在,返回 0;若键的过期时间为负值,相当于执行 del 命令。
示例
127.0.0.1:6379> persist name (integer) 1(六)查看键剩余时间:ttl、pttl
命令:
ttl key:返回键的剩余过期时间(单位:秒)。如果键没有过期时间,返回-1;如果键不存在,返回-2。pttl key:返回键的剩余过期时间(单位:毫秒)。与ttl命令类似。
示例
127.0.0.1:6379> ttl name (integer) 59 127.0.0.1:6379> pttl name (integer) 59000(七)查看键的数据结构类型:type key
命令:type key
功能:返回键的数据类型。例如,键可能是字符串(string)、列表(list)、集合(set)、有序集合(zset)、哈希(hash)等。
示例
127.0.0.1:6379> type name string(八)键重命名:rename、renamenx
命令:
rename key newkey:将key重命名为newkey,如果newkey已经存在,会被覆盖。renamenx key newkey:将key重命名为newkey,如果newkey已经存在,重命名操作会失败。
示例
127.0.0.1:6379> rename name fullname OK 127.0.0.1:6379> renamenx age newage (integer) 1- 注意:重命名操作期间,底层会执行
del命令,若键对应的值较大,可能会造成阻塞。
(九)随机返回一个键:randomkey
命令:randomkey
功能:从当前数据库中随机返回一个键。该命令适用于测试、调试等场景。
示例
127.0.0.1:6379> randomkey "name"(十)迁移键
1. 在数据库间迁移:move key db
命令:move key db
功能:将键从当前数据库迁移到指定的数据库(通过数据库索引指定)。
注意:生产环境不建议使用此命令,可能会影响性能。
2. 在实例间迁移:migrate
命令:migrate host port key|"" destination-db timeout [copy] [replace] [keys key [key ...]]
功能:将键从一个 Redis 实例迁移到另一个实例,支持多个键的迁移,且支持原子性操作。
示例
127.0.0.1:6379> migrate 192.168.1.2 6379 name 0 5000 OK(十一)全量遍历键:keys pattern
命令:keys pattern
功能:全量遍历数据库中的键,支持使用 glob 风格的通配符来匹配键名。例如,可以列出所有以 video 开头的键。
注意:keys 命令会阻塞 Redis,性能较差,在生产环境中不推荐频繁使用。
示例
127.0.0.1:6379> keys video* 1) "video123" 2) "video456"(十二) 渐进式遍历键:scan
命令:scan cursor [match pattern] [count number]
功能:渐进式地遍历数据库中的键,避免一次性阻塞 Redis,适合大规模数据的遍历。
注意:scan 命令每次返回一部分结果,并可以指定匹配模式和扫描的数量。由于是渐进式的遍历,不能保证返回所有键,因此需要多次调用。
示例
127.0.0.1:6379> scan 0 match video* count 100 1) "2" 2) 1) "video123" 2) "video456"- 该命令支持哈希(hscan)、集合(sscan)、有序集合(zscan)等数据结构的渐进式扫描。
这些键的操作命令是 Redis 的基础功能,涵盖了从键的查看、删除、过期控制、重命名、数据迁移到键的遍历等操作。在开发和运维中,合理使用这些命令可以帮助你高效地管理 Redis 数据库,优化性能,避免一些潜在的性能问题。
三、对值的基本操作命令讲解
实际上每种数据结构都有自己底层的内部编码实现,而且是多种实现,redis会在合适的场景选择合适的编码,通过object encoding查看内部编码,这样做有两个好处:①可以改进内部编码,可保证对外的数据结构和命令没有影响;②多种内部编码实现可以在不同场景下发挥各自优势。
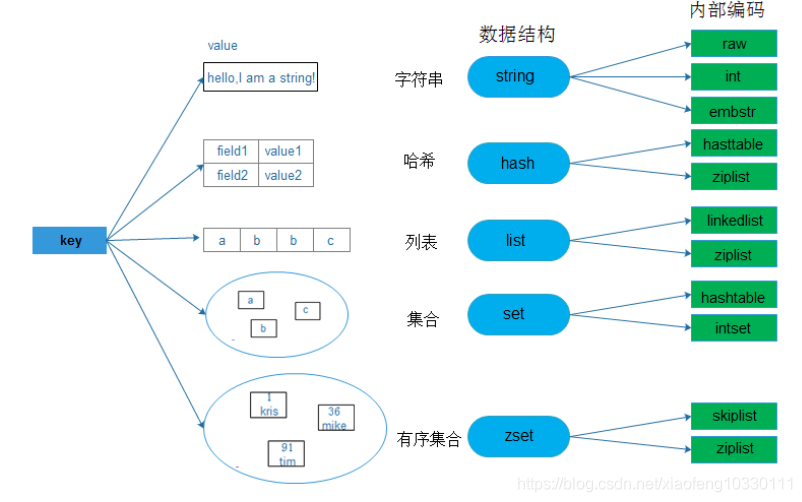
(一)字符串数据结构讲解
字符串类型的值实际上可以是字符串(简单字符串+复杂字符串JSON、XML等)、数字、甚至是二进制(图片、音频、视频),但是值不能超过512MB。
1.基本命令
◎设置值 set key value [ex seconds] [px milliseconds] [nx|xx]
--ex与px都是用来设置过期时间的,代表秒级和毫秒级
--nx 键必须不存在,用于添加
--xx 键必须存在,用于更新
setex key seconds value == set key value nx 可作为分布式锁的实现方案
setnx key value == set key value xx
◎获取值 get key --键不存在返回nil
◎批量设置值 mset key value [key value ...]
◎批量获取值 mget key [key ...]
◎计数 incr key
decr key
decrby key increment
incrby key increment
incrbyfloat key increment
--值不是整数,返回错误
--键不存在,按照值为0处理
◎追加值 append key value
◎字符串长度 strlen key (中文占用3字节)
◎设置并返回原值 getset key value
◎设置指定位置字符 setrange key offset value
◎获取部分字符串 get key start end
2.内部编码
◎int :8个字节的长整形 set key 8653 + object encoding key
◎embstr:≤39个字节的字符串 set key “hello,zters!” + object encoding key
◎raw:>39个字节的字符串
3.使用场景
①缓存功能:(防止键冲突和有助可维护性,推荐使用 业务名:对象名:id:[属性])
public UserInfo getUserInfo(long id) { String userRedisKey = "user:info:" + id; Object value = redis.get(userRedisKey); UserInfo userInfo; if(null != value) { userInfo = deserialize(value); } else { userInfo = mysql.get(id); if(null != userInfo ) { redis.setex(userRedisKey, 3600, serialize(userInfo )); } } return userInfo ; }②计数:(视频播放数等)
public long incrVideoCounter(long id) { String key = "video:playCount:" + id; return redis.incr(key); }③共享session;
④短信验证码限速(限制一个IP地址不能在一秒内访问n次)
String phoneNum = ""; String key = "shoortMsg:limit:" + phoneNum; Object isExists = redis.set(key, 1, "ex 60", "nx"); if(null != isExists || redis.incr(key) <= 5) { //通过 } else { //不通过 }(二)哈希数据结构讲解
哈希类型键值本身又是一个键值对结构。
1.基本命令
◎设置值 hset key field value (有类似hsetnx命令,和前面的功能一样)
◎获取值 hget ket field
◎删除field hdel key field [field...]
◎计算field 个数 hlen key
◎批量设置或获取field-value hmget key field [field ...]
hmset key field value [field value ...]
◎判断field是否存在 hexists key field
◎获取所有field hkeys key
◎获取所有value hvals key
◎获取所有field-value hgetall key
--使用hgetall时,若哈希素过多,有堵塞可能
--若只获取部分field,可使用hmget
◎计数 hincrby key field
hincrbyfloat key field
◎计算value长度 hstrlen key field
2.内部编码
◎ziplist(压缩列表) :哈希素个数<512&&值都<64, 节省内存;
◎hashtable(哈希表):不满足ziplist条件。
3.使用场景
关系型数据库数据转换为redis数据库,比如缓存用户信息
public UserInfo getUserInfoByDB(long id) { String userRedisKey = "user:info:" + id; Map userInfoMap = redis.hgetAll(userRedisKey); UserInfo userInfo; if(null != userInfoMap) { userInfo = transferMapToUserInfo(userInfoMap); } else { userInfo = mysql.get(id); if(null != userInfo ) { redis.hmset(userRedisKey,transferMapToUserInfo(userInfoMap)); redis.expire(userRedisKey, 3600); } } return userInfo ; } (三)列表数据结构讲解
一个列表最多可以存储 -1个素,对两端可以插入和弹出,可充当栈和队列。
-1个素,对两端可以插入和弹出,可充当栈和队列。
1.基本命令
◎右边插入 rpush key value [value ...]
◎左边插入 lpush key value [value ...]
◎某处插入 linsert key before|after pivot value
◎查找 lrange key start end (0→N-1)
◎获取指定下标素 lindex key index
◎获取列表长度 llen key
◎从右侧弹出 rpop key
◎从左侧弹出 lpop key
◎删除指定素 lrem key count value
--count>0,从左到右删除最多count个素;
--count<0,从右到左删除最多count个素;
--count=0,删除所有素;
◎按照范围截取列表 ltrim key start end
◎修改指定下标的素 lset key index newValue
◎堵塞操作 blpop key [key ...] timeout
brpop key [key ...] timeout
2.内部操作
◎ziplist(压缩列表) :列表素个数<512&&值都<64, 节省内存;
◎linkedlist(链表):不满足ziplist(压缩列表)时。
3.使用场景
①消息队列:使用lpush+brpop组合实现;

②文章列表:每个用户有自己的文章列表,分页展示文章列表
a 每篇文章使用哈希结构存储
hmset article:1 title xx timstamp content xxxx
.......
hmset article:n title xx timstamp content xxxx
b 向用户文章列表添加文章
lpush user:1:articles article:1 article:3 article:16
.....
lpush user:k:articles article:45 article:85 article:92
c 分页获取用户文章列表
articles = lrange user:1:articles 0 9
for article in {articles}
hgetall {article}
(四)集合数据结构讲解
集合中不允许有重复素,且集合素无序,最多可以存储 -1个素,支持集合内的增删改查,还支持集合间交并差。
1.基本命令
集合内增删改查
◎添加素 sadd key element [element ...]
◎删除素 srem key element [element ...]
◎计算素个数 scard key
◎判断素是否在集合中 sismember key element
◎随机从集合返回指定个数素 srandommenber key [count] count默认为1
◎从集合中随机弹出素 spop key --注意这个操作后,随机弹出的素将被删除
◎获取所有素 smembers key
集合间交并差
◎多个集合的交集 sinter key [key ...]
◎多个集合并集 sunion key [key ...]
◎多个集合差集 sdiff key [key ...]
◎将交集结果保存 sinterstore destination key [key ...]
◎将并集结果保存 sunionstore destination key [key ...]
◎将差集结果保存 sdiffstore destination key [key ...]
2.内部编码
◎intset(整数集合):素都是整数且素个数<512,减少内存使用;
◎hashtable(哈希表):不满足intset条件。
3.使用场景
①典型就是标签,举例一个用户可能对娱乐、体育比较感兴趣,另一个可能对历史、新闻比较感兴趣,这些兴趣点就是标签,以此可以得到喜欢同一个标签的人,以及用户共同喜欢的标签,对于增强用户体验和用户粘度比较重要。
a 给用户添加标签
sadd user:1:tags tag1 tag2 tag3 tag5 tag7 tag8
sadd user:2:tags tag3 tag6 tag9 tag10 tag12 tag15
.....
sadd user:k:tags tag2 tag4 tag6 tag8 tag10 tag17
.....
b 给标签添加用户
sadd tag1:users user:1 user:3
sadd tag2:users user:1 user:3 user:5 user:8 user:12 user:k
.....
sadd tagk:users user:3 user:7 user:21 user:35
.....
c 删除用户下的标签
srem user:1:tags tag1 tag5
.....
d 删除标签下的用户
srem tag1:users user:1
srem tag5:users user:5 user:9 user:8 user:15 user:56
.....
注:c和d要放在一个事物里面执行
e 计算用户共同感兴趣的标签
sinter user:1:tags user:3:tags user:5:tags user:7:tags
②其他通用场景
spop/srandomember = random item (生成随机数,不如抽奖)
sadd + sinter = social graph(社交需求)
(五)有序集合数据结构讲解
有序集合保留了集合不能有重复素的特性,但素可以排序,其为每个素设置了一个分数作为排序依据,支持集合内的增删改查,还支持集合间交并差。
1.基本命令
集合内增删改查
◎添加素 zadd key score meneber [score meneber ...]
---redis3.2为zadd添加了nx/xx/ch/incr
---nx member必须不存在,用于添加
---xx member必须存在,用于更新
---ch 返回此次操作后素和个数发生变化的个数
---incr 对score做增加
◎计算成员个数 zcard key
◎计算某个成员的分数 zscore key menber
◎计算成员排名 zrank key member
zrevrank key member
--zrank分数从低到高,zrevrank 反之;
--排名从0开始计算。
◎删除成员 zrem key menber [member ...]
◎增加成员个数 zincrby key increment member
◎返回指定排名范围的成员 zrange key start end [withscores]
zrevrange key start end [withscores]
◎返回指定分数范围的成员 zrangebyscore key min max [withscores] [limit offset count]
zrevrangebyscore key min max [withscores] [limit offset count]
◎返回指定分数范围成员个数 zcount key min max
◎删除指定排名内的升序素 zremrangebyrank key start end
◎删除指定分数范围的成员 zremrangebyscore key min max
集合间交并差
◎交集 zinterstore destination numkeys key [key ...] [weights weight [weight ...]] [aggregate sum|min|max]
◎并集 zunionstore destination numkeys key [key ...] [weights weight [weight ...]] [aggregate sum|min|max]
2.内部编码
◎ziplist(压缩列表) :有序集合素个数<512&&值都<64, 节省内存;
◎skiplist(跳跃表):不满足ziplist(压缩列表)时。
3.使用场景
典型的就是排行榜系统。举例视频网站需要对用户上传的视频做排行榜,榜单的维度可以使多面的:按照时间、按照播放数量、按照获得的赞数。
a 添加用户赞数
zadd user:ranking:2018-09-18 666 zyf
若再次获赞
zincrby user:ranking:2018-09-18 1 zyf
b 取消用户的赞数
zrem user:ranking:2018-09-18 zyf
c 展示获取赞数最多的十个用户
zrevrangebyrank user:ranking:2018-09-18 0 9
d 展示用户信息以及用户分数
hgetall user:info:zyf
zscore user:ranking:2018-09-18 zyf
zrank user:ranking:2018-09-18 zyf
四、总结
通过本文的讲解,我们深入了解了 Redis 的基本键值 API 使用、内部编码机制以及常见的使用场景。掌握 Redis 的基本操作不仅能帮助我们高效地管理数据,还能通过合理选择 Redis 的不同数据结构与命令,提升应用系统的性能。
具体而言,了解 Redis 如何通过不同的内部编码方式(如压缩列表、哈希表、跳表等)来优化内存使用和性能,是开发高效 Redis 应用的关键。而在实际使用中,根据不同场景选择合适的数据类型和操作,不仅能够确保系统性能的稳定性,还能充分发挥 Redis 的优势,帮助开发者构建快速响应、可靠的应用。
随着 Redis 在现代互联网应用中扮演越来越重要的角色,本文为你提供了一个扎实的基础,帮助你在今后的项目中更加自如地使用 Redis。在缓存优化、数据存储、消息队列等不同场景中,掌握其内部机制与使用技巧,能够显著提升系统的效率和可扩展性。
希望本文能够帮助你更好地理解 Redis,带领你在 Redis 的世界中不断探索、实践,从而提升自己在开发中的技术水平与解决问题的能力。
今天的文章 Redis键值操作全景解析:API、编码方式与应用场景分享到此就结束了,感谢您的阅读。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/86320.html