

1.1缓存穿透
一个请求,根据id查询文章
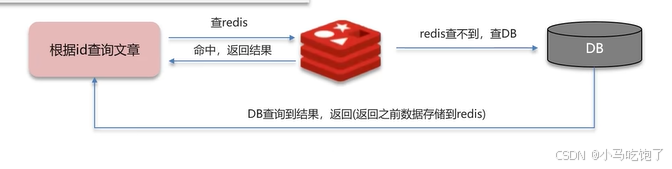
缓存穿透问题:查询一个不存在的数据,mysql查询不到数据也不会写到redis中,就会导致每次都会去查询数据库。
**原因:**有些人恶意查询,请求,将请求路径中的参数恶意设置,在高并发的恶意查询下,会使数据库宕机。
解决办法:
- 缓存空数据,查询数据库的数据为空,仍然把这个空结果进行缓存。 消耗内存,还有可能导致数据不一致的问题。
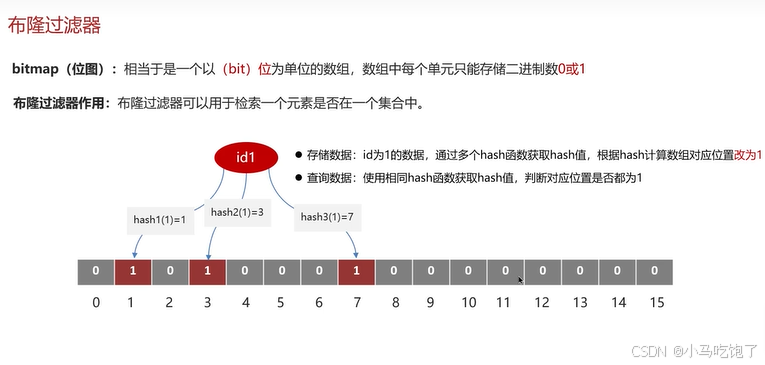
- 布隆过滤器:检索一个元素是否在一个集合中。使用redission实现布隆过滤器。
底层是先去初始化一个比较大的数组,里面存放的二进制0和1,开始都是0,当有key来的时候进行3次hash计算,模于数组长度找到数组下标把原来的0改为1,这样的话3个位置就能找到key的位置就能表明key的存在。查找的过程也是一样的。
缺点是:存在误判,但是初始化数组的时候我们可以设置误判率,一般不会超过5%。

详细实现:bitmap(位图)

1.2缓存击穿
**缓存击穿:**给某一个key设置了过期时间,就在key过期的时候,恰好这个时间点有大量的请求来访问这个key,这些并发的请求可能就会去查询数据库,导致数据库压垮。
解决方法:
-
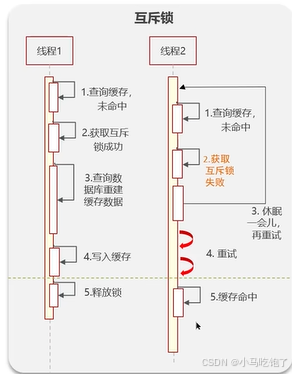
互斥锁:当前线程获取锁直到释放,其他线程就只能等新数据写好。 使用redis的setnx去设置互斥锁2。
保证强一致性。性能差
-
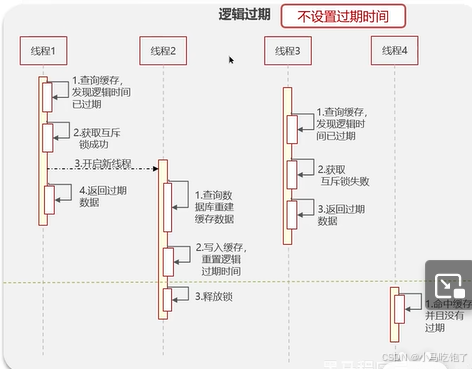
逻辑过期时间:
高可用 性能优 不能保证数据绝对一直
对于热点key不设置过期时间,设置逻辑过期时间
当有请求访问,查询redis中不存在,会在当前线程获取互斥锁,后会创建新的线程,来进行缓存重建,以及将新数据写入redis并设置逻辑过期时间,后释放锁。当前线程会返回过期数据。
其他出线程在锁未释放时,获取锁失败,也会返回过期数据。
只有释放锁成功,查询发现缓存命中,就会返回新数据
。
1.3缓存雪崩
指在同一时间段内redis中的大量key失效,或者redis宕机,导致大量请求来到数据库。
解决方案:
- 给不同的key的TTL添加随机值
- 利用redis的集群服务提高服务的可用性
- 给缓存业务添加降级限流权限
- 给业务添加多级缓存
1.4mysql中的数据如何与redis保持一致(双写一致性)
业务背景:一致性要求较高
允许延迟一致
双写一致:当修改了数据库的数据也要同时更新缓存中的数据。缓存和数据库中的数据要保持一致。
写操作:延迟双删

解决方法:
1.读写锁:强一致,性能差。
共享锁:加锁之后,其他线程可以进行共享读操作
排他锁 :加锁之后,阻塞其他线程的读写操作
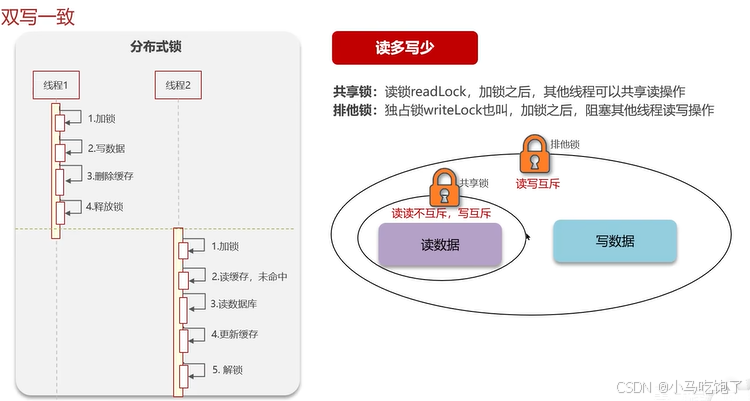
添加读写锁,其他线程可以读,但是不能写。
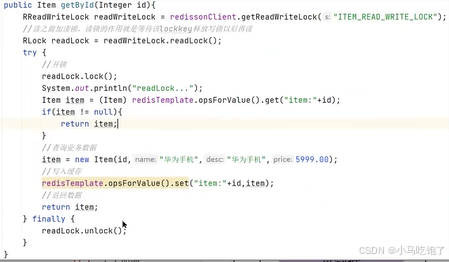
添加读写锁(排他锁)
2.允许短暂不一致
2.1异步通知保证数据的最终一致性
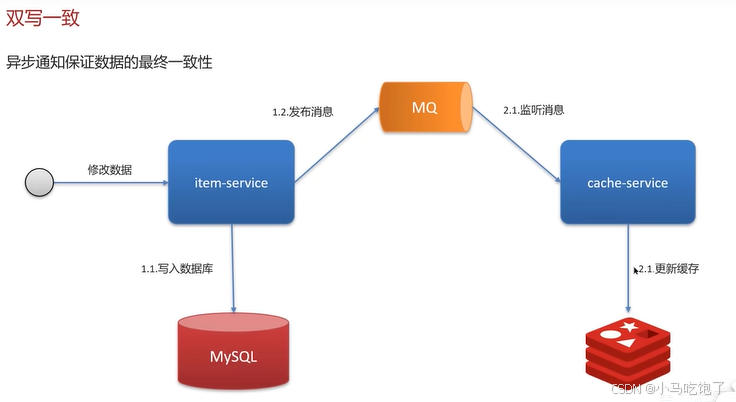
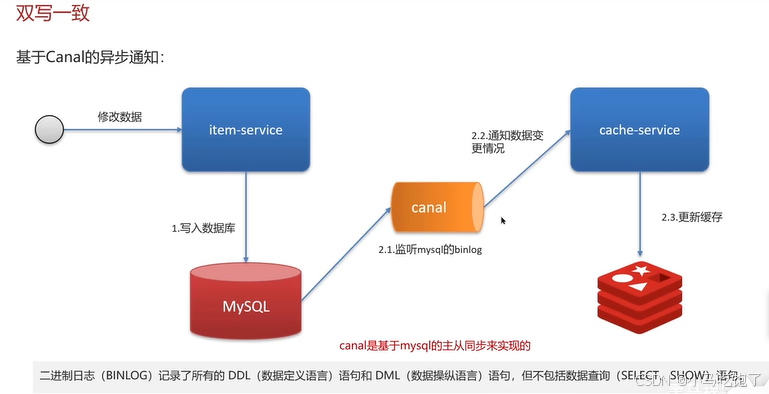
总结:

强一致性业务回答:

最终一致性的解决方式:

1.5redis的数据持久化
Q:redis作为缓存,数据的持久化是怎么做的?
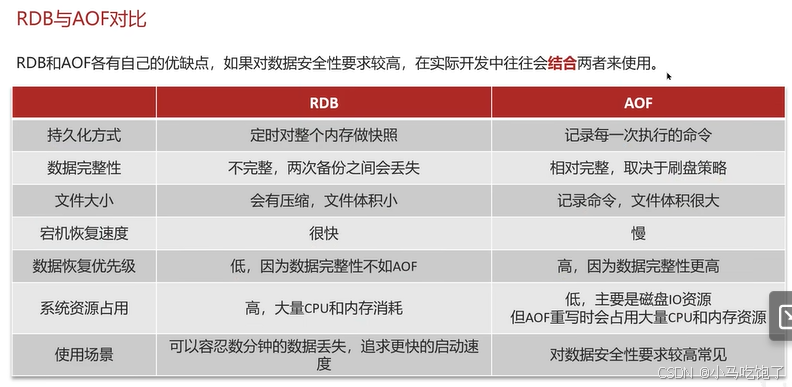
1.RDB
RDB全称Redis Database Backup file(Redis数据备份文件),也叫redis主句快照。简单来说就是把内存中的所有数据都记录在磁盘上。当redis实例故障重启后,从磁盘中读取快照文件,恢复数据。

主动备份:redis.conf文件

RDB执行原理
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入RDB文件。
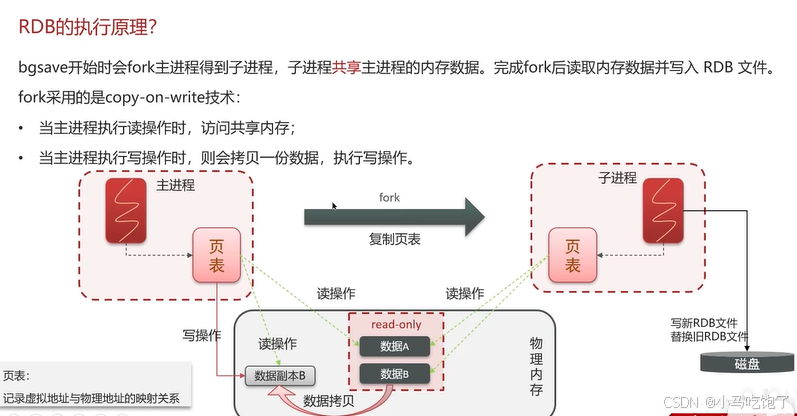
linux系统中,每个进程无法直接读取物理内存,而是由操作系统为每一个进程维护了一个虚拟内存,主进程只能操作虚拟内存,但是操作系统会维护一个,物理内存与虚拟内存之间的关系表,也就是页表(记录虚拟地址与物理地址之间的映射关系),主进程操作虚拟内存,基于虚拟内存与物理内存的映射,主进程就可以完成对物理内存的读和写的操作。
主进程与子进程之间拷贝:页表
2.AOF
AOF简称Append Only File(追加问价)。redis处理的每一条命令都会记录在AOF文件,可以看做是命令日志。
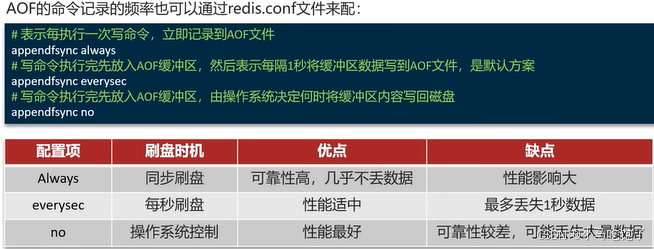
AOF默认是关闭的,修改redis.conf配置文件来开启AOF:

AOF的命令记录频率:刷盘策略
因为是记录命令,AOF文件比RDB文件大得多。而且AOF会记录同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写操作,用最少得命令达到最好的效果。

总结:

1.6redis的数据过期策略
1.惰性删除:当我们为key设置过期时间后,不去管他,当需要key时,我们检查是否过期,如果过期,我们就删掉他,反之返回该key。
优点:对cpu友好
缺点:对内存不友好,因为当key已经过期。但是一直没有使用,那么就会一直占用内存,内存永远不会释放。
2.定期删除:
每隔一段时间,就会对一些key进行删除,删除里面过期的key。
两种模式:
SLOW模式是定时任务,执行频率默认是10hz,每次不超过25ms,可以修改redis.conf的hz选项来调节。
FAST模式执行频率固定,但两次间隔不超过2ms,每次耗时不超过1ms.

redis的过期策略:惰性删除+定期删除

1.7redis的数据淘汰策略
Q:因为缓存过多,内存是有限的,内存被占满了怎么办?
**数据的淘汰策略:**当redis的内存不够用时,此时向redis中添加新的key,那么redis就会按照某一种规则将内存中的数据删掉,这种删除规则被称之为内存的淘汰策略。
redis支持8种不同策略来选择要删除的key:
- noeviction:不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略
- volatile-ttl:对设置了TTL的key,比较TTL的剩余TTL值,TTL越小越先被淘汰
- allkeys-random: 对全体的key,随机进行淘汰
- volatile-random:对设置了TTL的key,随机进行淘汰
- allkeys-lru:对全体的key,基于LRU算法进行淘汰。
LRU:最近使用最少,用当前时间-最后一次访问时间,这个值越大则淘汰优先级越高
LFU:最少频率 使用,会统计每个key的访问频率,值越小淘汰优先级越高 - volatile-lru:对设置了TTL的key,基于LRU算法。
- allkeys-lfu:对全体key。基于LFU算法
- volatile-lfu:对设置了TTL的key,基于lfu算法
建议:
优先使用allkeys-lru;
访问频率差别不大:allkeys-random
业务中有顶置的需求:volatile-lru,需要置顶的数据不设置过期时间
业务中有短时高频访问的数据,使用allkeys-lfu或volatile-lfu策略。



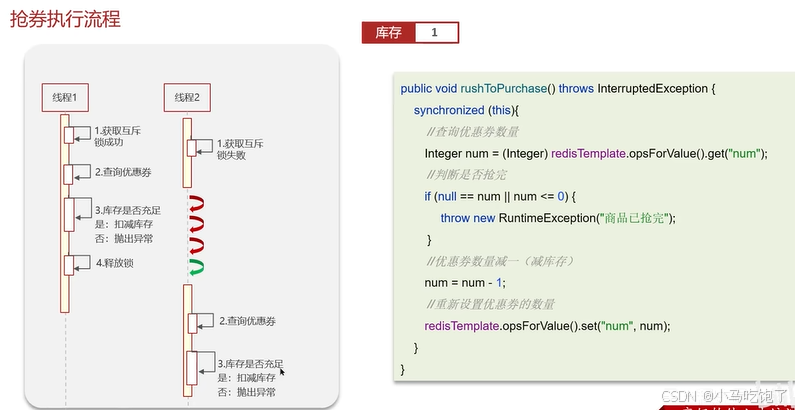
抢券场景:
获取优惠券数量,判断是否抢完,优惠券数量减一,重新设置优惠券数量。
超卖问题:
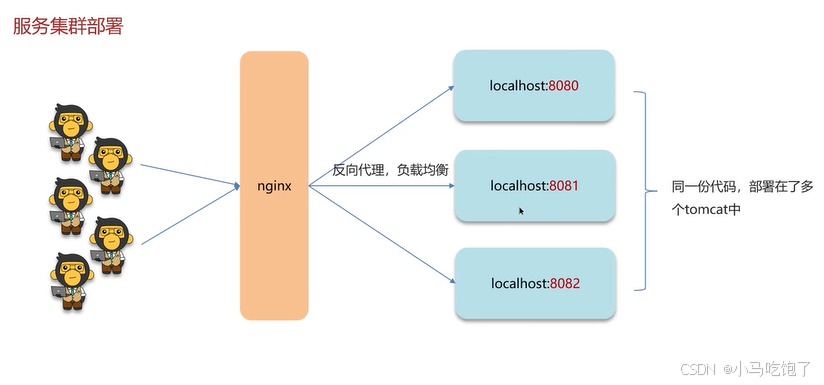
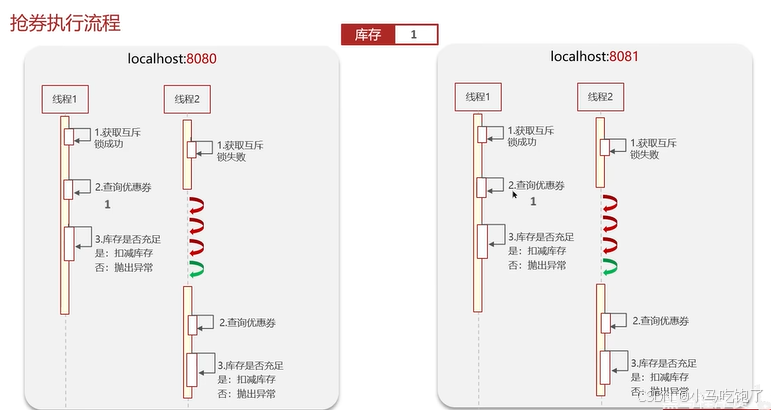
单体项目,加入synchronized,是本地的锁,JVM只能解决同一JVM下线程互斥
多台服务器: 服务集群
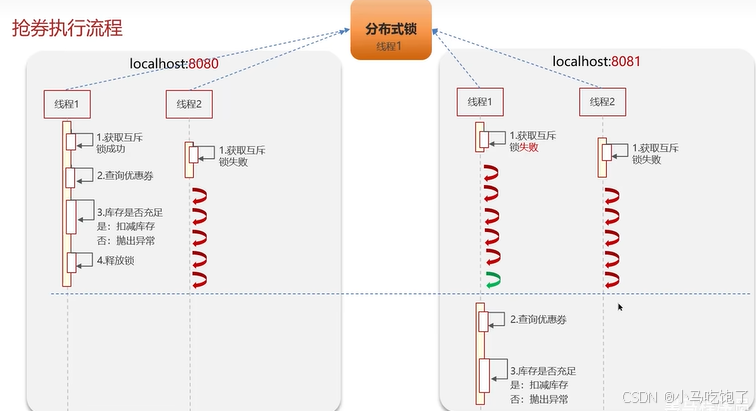
2.1Redis实现分布式锁利用setnx命令
setnx是set if not exists(如果不存在,则set)
警告:如果不设置锁过期时间,很容易造成死锁。
Q:Redis实现的分布式锁如何合理的控制锁的有效时长?
根据业务执行时间预估 给锁续期:用下面的redission实现。
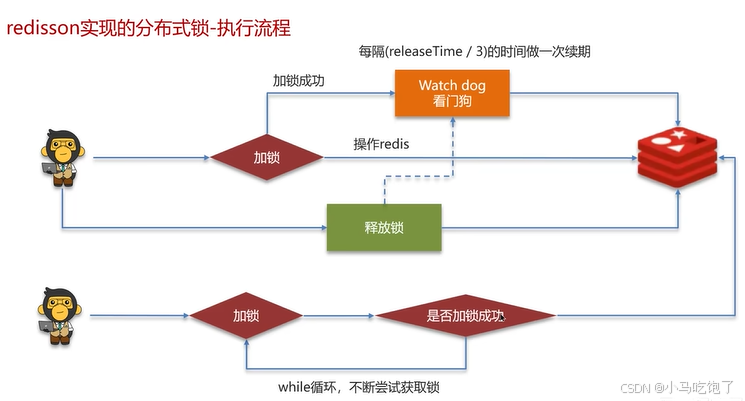
2.2redission实现的分布式锁
执行流程: 看门狗 重试机制
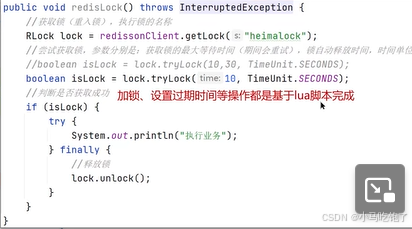
boolean isLock=lock.tryLock(10,30,Time)
boolean isLock=lock.tryLock(10,Time)
不设置过期时间30秒,才能启动看门狗模式。
2.2.1redission实现的分布式锁-可重入
首先是要判断是否为统一线程

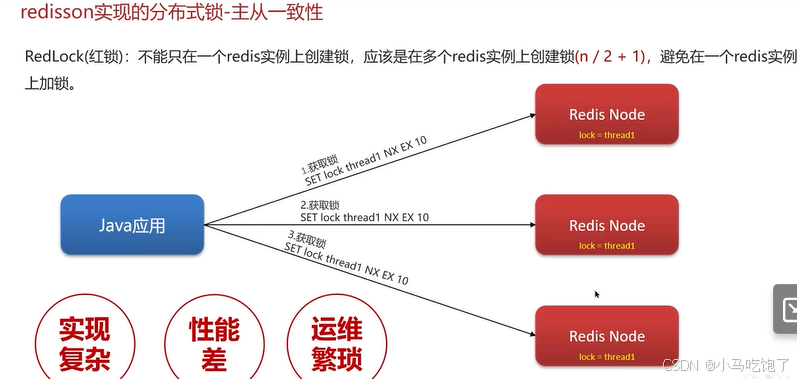
2.2.2redission实现的分布式锁可以实现主从一致
RedLock(红锁):不能只在一个redis中添加锁,要在多个redis中创建(n/2+1)
2.2.3总结
Q:redis是如何实现分布式锁
优惠券秒杀业务中,使用redisssion实现分布式锁(redisClient),底层是setnx和lua脚本(保证原子性)
Q:redission实现分布式锁如何合理的控制锁的有效时长?
在redission的分布式锁中,提供了watchDog(看门狗),一个线程获取锁成功后,WatchDog会给持有锁的线程续期(默认是每隔10秒钟续期一次)
Q:redission这个锁,可重入吗?
可以重入,多个锁重入需要判断是否是当前线程,在redis中进行存储的时候使用hash结构 大key 小key value那种,来存储线程信息和重入次数
Q:redission可以解决主从一致性问题吗?
不能,但是可以使用redission的红锁来解决,但是这样,性能di,维护成本高。如果必须保证强一致性问题,建议适应zookeerer实现分布式锁。

Q:redis集群有哪些方案?
- 主从复制
- 哨兵模式
- 分片集群
3.1主从同步
Q:redis主从数据同步的流程是什么?
主从复制:
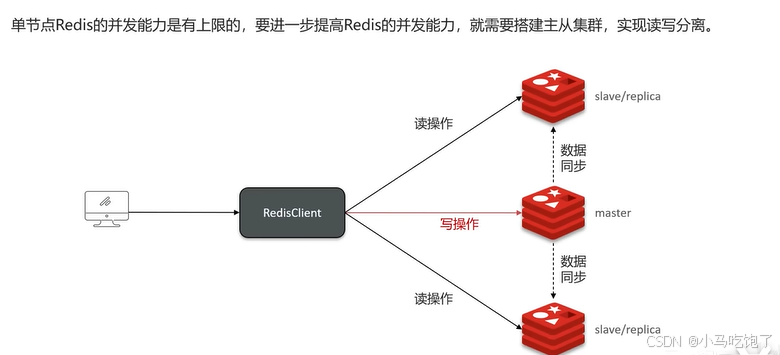
单节点的redis的并发能力是有限的,进一步提高并发能力,就需要搭建主从集群。
主从全量同步:

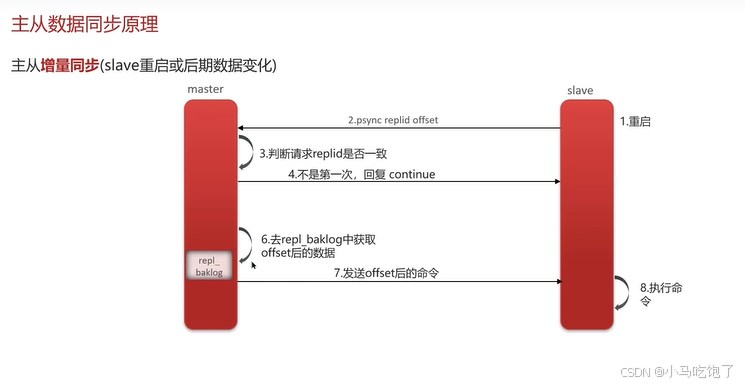
主从增量同步:(slave重启和后期数据变化)
Q:介绍一下redis的主从同步
因为单节点redis的并发能力是有上限的,所以为了提高redis
的并发能力,就需要搭建主从集群,实现读写分离,一般都是一主多从,主节点负责写数据,从节点负责读数据。
Q:介绍一下主从同步数据的流程?
全量同步:
1.从节点请求主节点同步数据(replication id 、offset)
2.主节点判断是否是第一次请求,(根据replication id),是第一次请求就会与从节点同步版本信息(replication id、offset)
3.主节点执行bgsave,生成rdb文件,发送给从节点去执行
4.在rdb文件生成期间,主节点会以命令的方式记录到缓冲区(一个日志文件)
5.把生成之后的命令日志文件发送给从节点进行同步
增量同步:
1.从节点请求主节点同步数据,主节点判断不是第一次请求,不是第一次就会获取从节点的offset值。
2.主节点从命令文件中获取offset值之后的数据,发送给从节点进行数据同步。

3.2哨兵作用
因为redis的主从服务,无法解决主节点宕机问题
Redis提供了哨兵机制来实现主从集群的自动故障恢复。
哨兵的结构和作用如下:
1.监控:看看主从集群中的redis是否正常工作。sentinel会不断地检查master和slace是否按照预期工作。
2.自动故障恢复问题:如果master故障,sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主。
3.通知:将新的master通知给redis的客户端。
3.2.1服务状态监控
是基于心跳机制检测服务状态,每隔一秒钟向集群的每个实例发送ping命令。
主观下线:如果某个哨兵节点发现某个实例未在规定的时间内响应,则认为该实例主观下线。
客观下线:若超过指定数量的哨兵都认为该实力主观下线,则该实例客观下线。quorum值最好超过哨兵实例数的一半
哨兵选主规则
- 首先判断主与从节点断开时间长短,如超过指定值就排除该节点
- 然后判断从节点的slave-priority值,越小优先级越高
- 如果slave-priority一样,则判断slave节点的ofset值,越大优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高。
3.2.2redis集群(哨兵模式)脑裂
当哨兵模式无法检测到主节点,就会选择新的master,此时就有两个master。但此时客户端与老的master连接,写入的新数据还在老的。老的变为slave后,会发生数据丢失问题。
解决方法:

3.2.3总结
Q:如何保证redis的高并发高可用
哨兵模式:实现主从集群的自动故障恢复(监控、自动故障恢复、通知)
Q:你们使用的redis是单点还是集群,那种集群
主从(一主一从)+哨兵
Q:redis集群脑裂,该怎么解决?
集群脑裂是由于主节点和从节点和哨兵处于不同的网络分区,使得sentinel没有心跳感知到主节点。


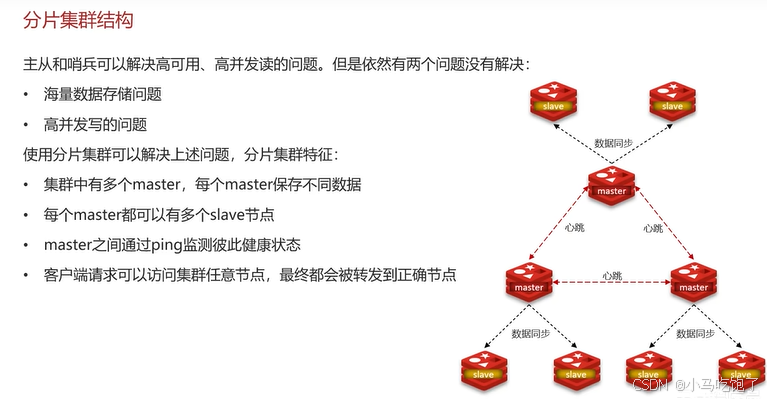
3.3分片集群结构
主从和哨兵可以解决高并发、高可用的问题,但仍然有两个问题:
-
海量数据存储问题
-
高并发写的问题
设置有效部分使得同种数据放在一起
Q:
redis分片集群作用: -
集群中有多个master,每个master保存不同数据,解决海量数据的问题
-
每个maseter都有多个slave,可以解决高并发读的问题
-
master之间通过ping检测彼此健康状态
-
客户端请求可以访问集群任意节点,最终会转发到正确的节点。
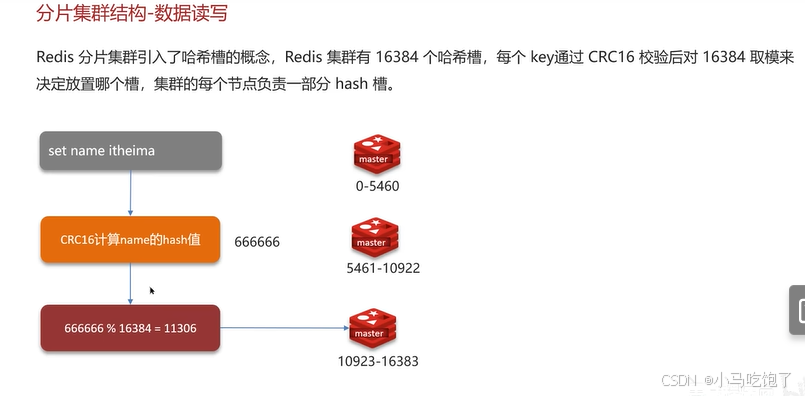
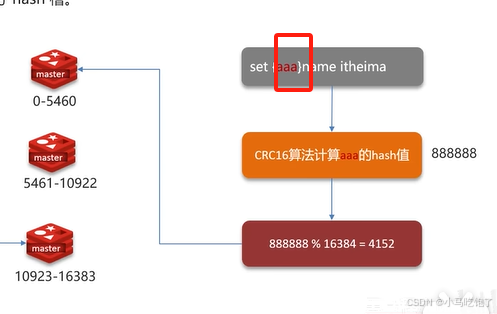
Q:redis分片集群中的数据是怎么存储和读取的?
- redis分片集群采用哈希槽的概念,redis集群中有16384个哈希槽
- 将16384个插槽分配到不同的实例
- 读写数据:根据key的有效部分计算哈希值,对16384取余,余数为插槽,寻找插槽所在实例

3.4redis是单线程的,但是为什么还那么快
- redis是纯内存操作,执行速度非常高
- 采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题
- 使用I/O多路复用模型,非阻塞IO
Q:能解释一下I/O多路复用模型?
redis是纯内存操作,执行速度非常快,他的性能瓶颈是网络延时而不是执行速度,I/O多路复用模型主要就是实现了搞笑的网络请求。
用户空间和内核空间
阻塞I/O
非阻塞I/O
I/O多路复用
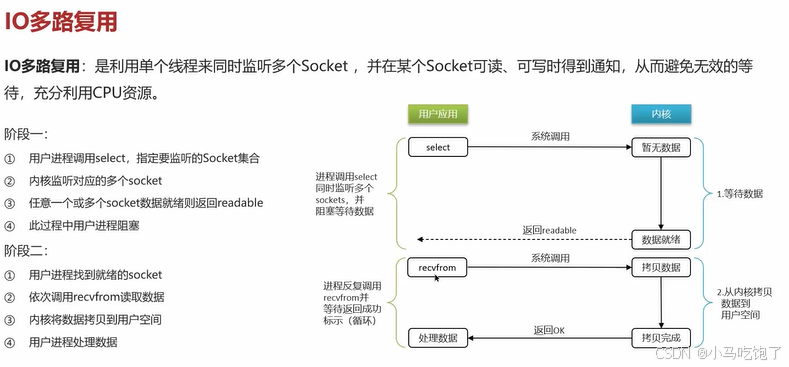
I/O多路复用是利用单线程来同时监听多个scoket。避免无效等待,充分利用cpu。
select
poll
epoll

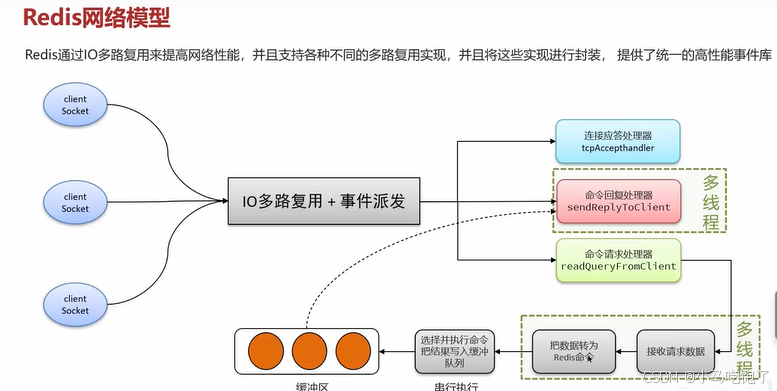
Redis网络模型:I/O多路复用+事件派发



1.1如何定位慢查询
Q:在mysql中如何定位慢查询?
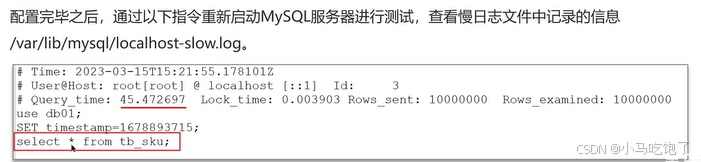
在测试接口时发现非常的慢,我们在mysql中开启了慢日志查询,设置的时间是2秒,一旦执行sql的时间超过2秒就会记录在日志中(调试阶段)
聚合查询
多表查询
表数据量过大查询
深度分页查询
表象:页面加载过慢,接口响应时间过长(超过1秒)
如何知道页面加载慢是因为mysql导致的,并且如何找到是因为哪条sql语句造成的。
方案一:
- 调试工具:Arythas
- 运维工具:Prometheus、Skywalking
方案二:Mysql自带慢日志
慢查询日志记录了所有执行时间超过指定参数的所有sql语句的日志。
如果要开启慢查询日志,需要在Mysql的配置文件(/etc/my.cnf)中配置以下信息:


1.2这条sql执行很慢,如何分析
-
聚合查询
-
多表查询
-
表数据量过大
-
深度分页查询
一个sql语句执行执行很慢,如何分析?
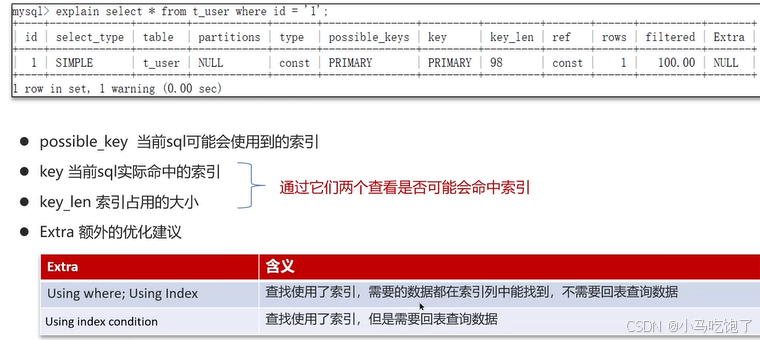
可以采用EXPLAN或者DESC命令获取MySql如何执行select语句的信息
-
type:这条sql的连接的类型,性能由好到差null,system,const,eq_ref,ref,range,index,all
system’:查询系统中的表
const:根据主键查询
eq_ref:主键索引查询或唯一索引查询,只能查询出一条结果
ref:索引查询,能查询出多条结果
range:范围查询
index:索引树扫描
all:全盘扫描
answer:
可以采用Mysql自带的分析工具EXPLAIN
- 通过key和key_len检查是否命中索引
- 通过type字段查看sql是否有进一步优化的空间,是否存在全索引扫描或全盘扫描
- 通过extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或者修改返回字段来修复

1.3索引概念及索引底层数据结构
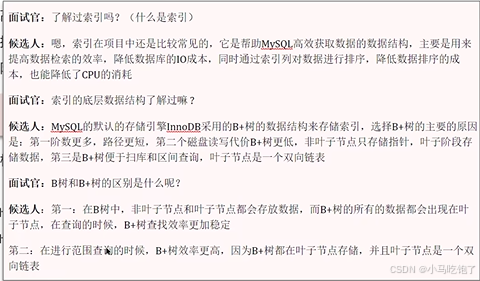
Q:了解过索引吗?(什么是索引)
索引是帮助Mysql高效获取数据的数据结构(有序),在数据之外,数据库系统还维护者满足特定算法的数据结构(B+树),这些数据结构是以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就叫做索引。
Q:索引的底层数据结构?
B+树
B+树更适合实现外存储索引结构,InnoDB存储引擎就是使用B+树实现其索引结构。
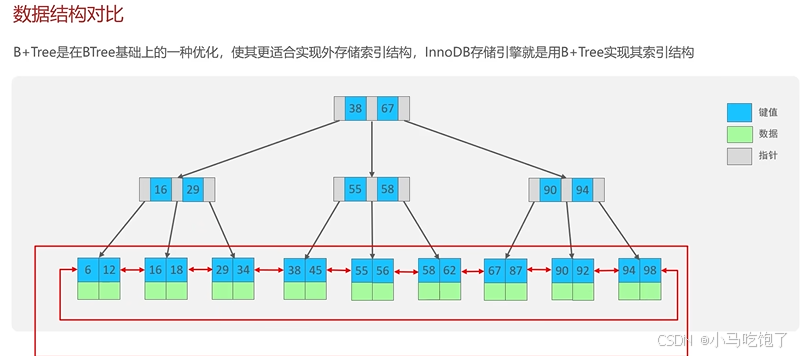
非叶子结点只存储指针,叶子结点才回存储数据
B树与B+树对比:
1.磁盘读写代价B+树更低
2.查询效率B+树更稳定
3.B+树更方便于扫库和区间查询
Q:什么是索引?
- 索引是帮助Mysql高效获取数据的数据结构(有序)
- 提高数据检索的效率,降低数据库的IO成本(不需要全表扫描)
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
Q:索引的底层数据结构了解过吗?
B+树
- 阶数更多,路径更短
- 磁盘的读写代价B+树更低,非叶子节点只存储指针,叶子节点存储数据
- B+树便于扫库和区间查询,叶子结点是一个双向链表
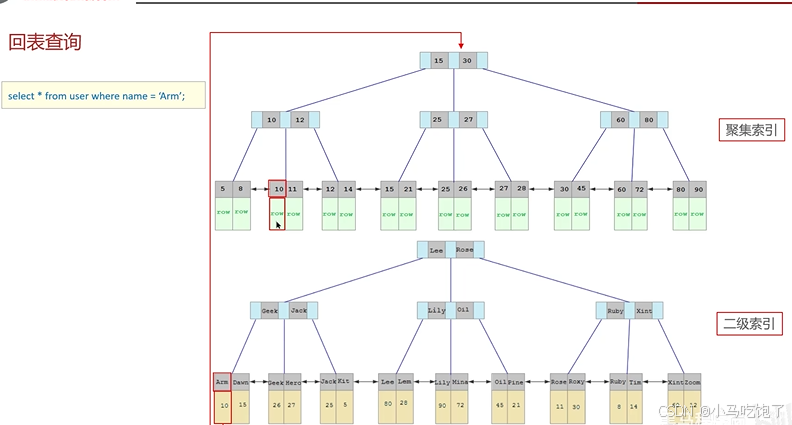
1.4聚簇索引和非聚簇索引
或者是什么是聚集索引,什么是二级索引(非聚集索引)?
什么是回表?
聚集索引:将数据存储与索引放到一块,索引结构的叶子节点保存了行数据。 必须要有,而且只有一个

二级索引:将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键。 可以存在多个
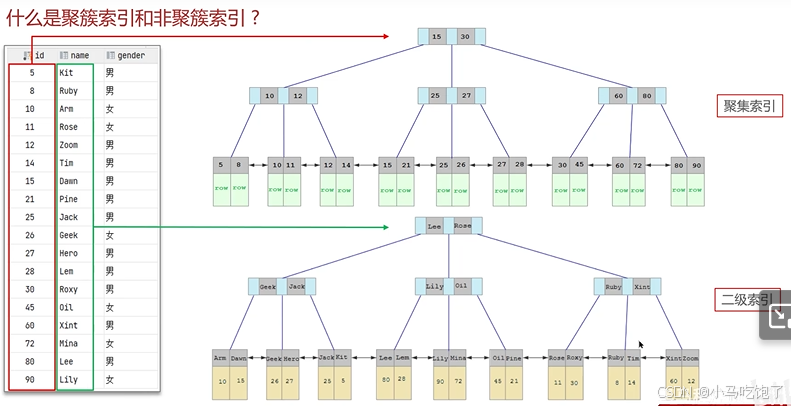
回表查询:
先通过二级索引查询到主键值,后根据主键值在聚集索引中查询到整行的数据。


1.5索引覆盖,超大分页优化
Q:知道什么叫覆盖索引吗?
覆盖索引是指查询使用了索引,并且需要返回的列(信息),在该索引中已经全部能够找到。

Q:什么是覆盖索引
- 使用id查询,直接走聚簇索引查询,一次索引扫描,直接返回数据,性能高
- 如果返回的列中没有创建索引,有可能就会触发回表查询,尽量避免使用select *
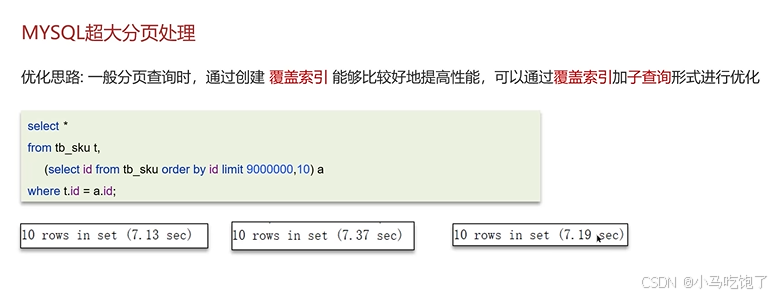
Q:Mysql超大分页怎么处理?
可以使用覆盖索引解决
在数据量大的时候,limit分页查询,需要对数据进行排序,效率低。
解决方案:覆盖索引+子查询

优化思路:一般分页查询时,通过创建覆盖索引能够比较好的提高性能,可以通过覆盖索引加子查询像是进行优化。

1.6索引创建原则
1.针对于数据量较大,且查询比较频繁的表建立索引。
(单表超过10万数据,增加用户体验)
2.针对于常用于作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3.尽量使用区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
4.如果说存储类型是字符串,字段长度较长,可以针对字段的特点,建立前缀索引。
5.尽量使用联合索引,减少单列索引,查询时,使用联合索引很多时候可以覆盖索引,节省空间存储,避免回表,提高查询效率。
6.控制索引数量
7.如果索引列不能存储null值,在创建表时使用not null约束他。当优化器知道每列是否包含null值是,他能更好的确定那个索引能更好的用于查询。


1.7什么情况下索引会失效


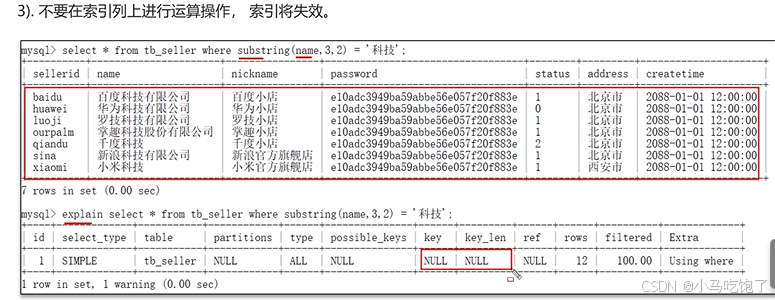


1.违反最左前缀法则
2.范围查询的右边的条件索引不能使用
3.不要再索引上使用运算操作,索引会失效
4.字符串不加单引号,造成索引失效
5.模糊查询中,以%开头的like,索引会失效

1.7sql优化的经验
- 表的设计优化(参考阿里开发手册《嵩山版》)
- 索引优化
- SQL语句优化
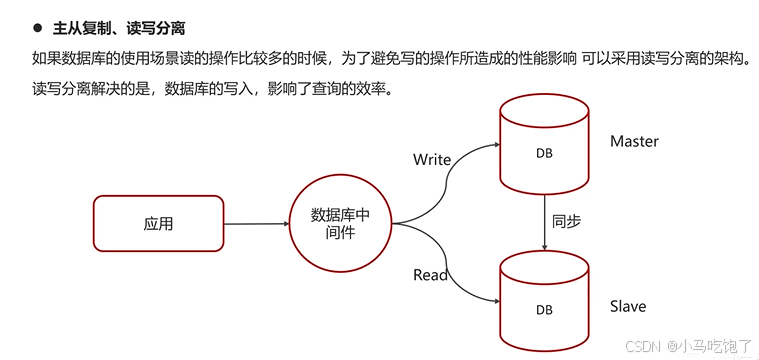
- 主从复制、读写分离
- 分库分表
1.
Q:谈一谈你对sql优化的经验
1.表的设计的优化
2.索引优化,索引创建的原则
3.sql语句的优化,避免索引失效,避免使用select* ,避免在where查询中使用运算操作,优先选择innerjoin
4.主从复制,读写分离,不让数据的写入,影响读操作
5.分库分表



2.1事务的特性 ACID
- 原子性:事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性:事务完成时,必须使所有的数据都保持一致的状态
- 隔离性:数据库系统提供的隔离机制,保证事务在不收外部并发影响的独立环境下进行。
- 持久性:事务一但提交或者回滚,他对数据库中的数据的改变就是永久的。 保存在磁盘中
转账案例:A->B 原子性要么都成功,要么都失败,在转账过程中A必须减少1000,B增加1000,

2.2并发事务带来的问题
问题:脏读,不可重复读,幻读
隔离级别:读未提交,读已提交,可重复读,串行化
1.脏读:一个事务读到了另一个事务还没提交的数据。
2.不可重复读:一个事务先后读取同一条数据,但两次读取的数据不同,称之为不可重复读。
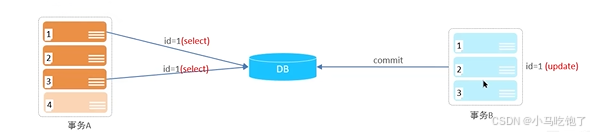
3.幻读:一个事务按照条件查询时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在了,好像出现了幻影。
第一次与第四次查询的数据相同。

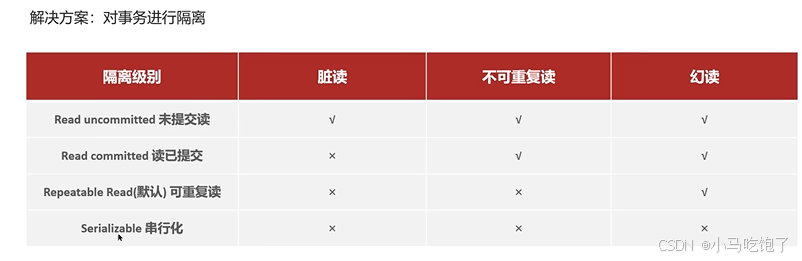
2.3解决并发事务问题 隔离级别


2.4undo Log 和redo Log的区别
1.redo log重做日志 记录的是事务提交时数据页的物理修改,是用来实现事务的持久化。
当事务提交之后,会把修改的信息都存在该日志文件中,用于当刷新脏页到磁盘,发生错误时,进行数据恢复使用。
2.undo log回滚日志 用于记录数据被修改前的操作,作用包含 提供回滚和MVCC 逻辑日志

Q:undo log 和 redo log 的区别
- redo log记录的是物理页的变化,服务宕机用来同步数据
- undo log记录的是逻辑日志,当事务回滚后,通过你操作恢复原来的数据
- redo log保证了事务的持久性 undo log保证事务的一致性和原子性

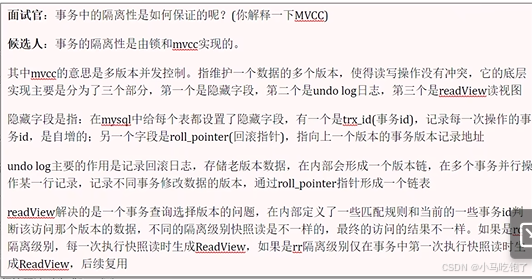
2.5事物的隔离性是如何保证的 锁 MVCC
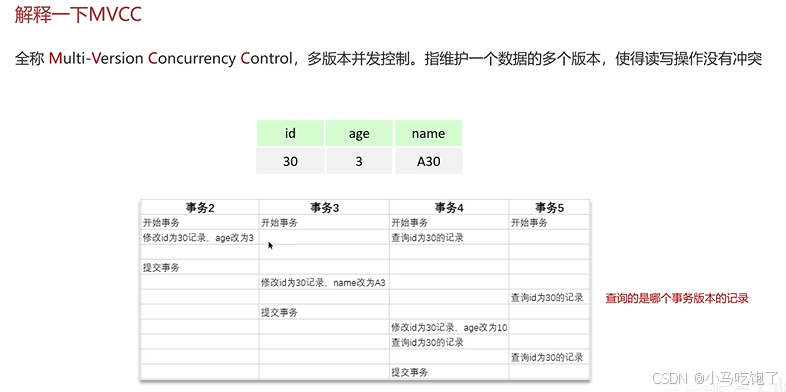
2.5.1MVCC实现原理
- 记录中的隐藏字段
- undo log
- undo log版本链
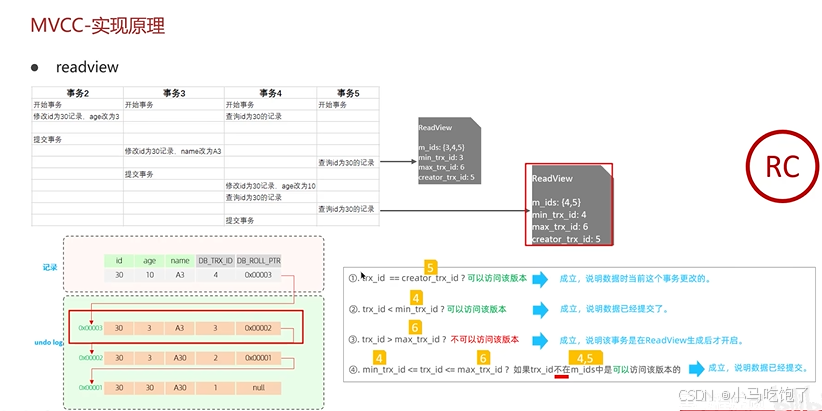
- readview


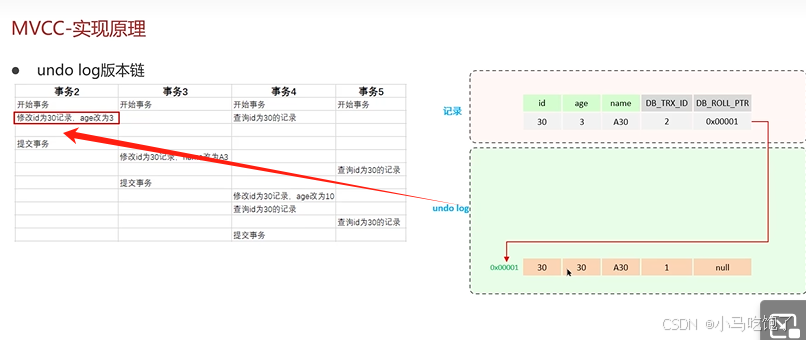
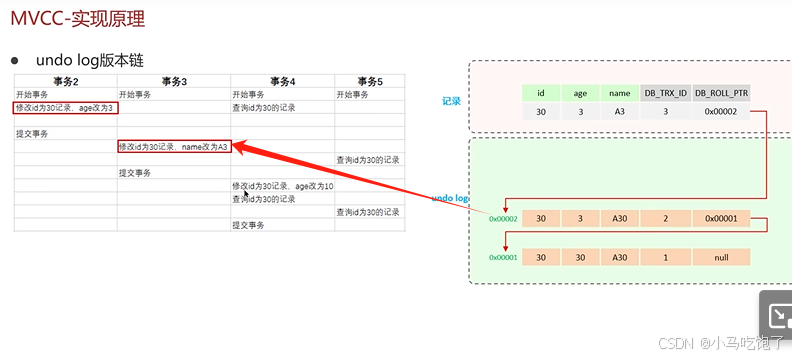
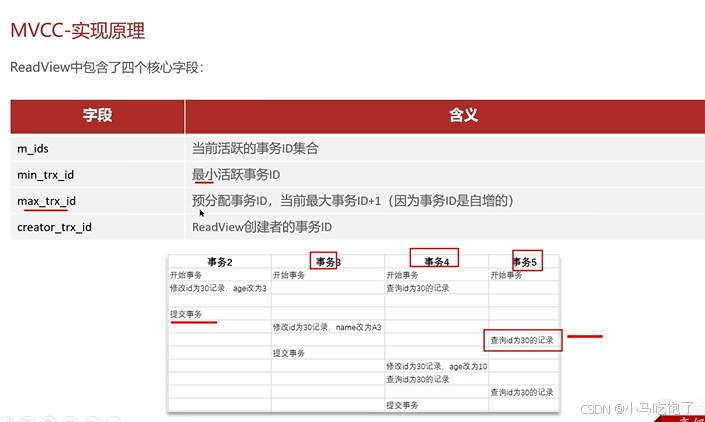
readView读视图是快照读SQL执行时MVCC提供数据的依据,记录并维护系统当前活跃的事务(未提交的)id。
1.当前读:读取的最新版本

2.快照读


2.5.2总结

2.6Mysql主从同步原理
binlog 记录所用的DDL(数据定义语言)语句和DML(数据操纵语言)语句,但是不包括 select 、show语句
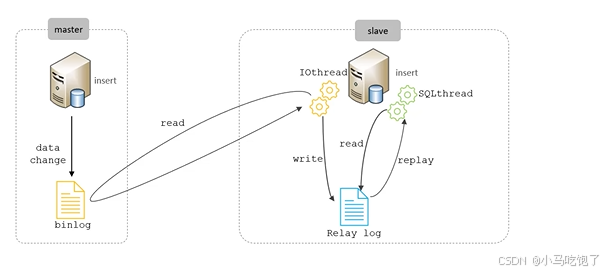
Q:主从同步原理


2.7分库分表

1.1spring框架中的单例bean是线程安全的吗?
Q:spring框架中的bean是单例的吗?
是
每个bean的实例只会被创建一次,并且会被存储在spring容器的缓存中,以便在后续的请求中重复使用。这种单例模式可以提高应用程序的性能和内效率。
Q:spring框架中的单例bean是线程安全的吗?
不是线程安全的
spring框架中有一个@Scope注解,默认的值就是singleton,单例的。
因为一般在spring的bean中都是注入无状态的对象,没有线程安全问题,但是如果在bean中定义了可修改的成员变量,是要考虑线程安全问题的,可以使用多例或者加锁来解决。

1.2AOP
AOP:成为面向切面编程,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装成为一个可冲用的模块,这个模块被称为切面(aspect),减少系统的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。
常见的AOP使用场景:
记录操作日志
缓存处理
spring中内置的事务处理
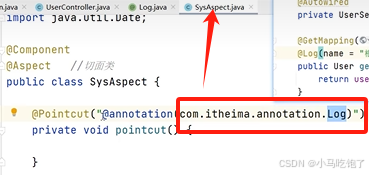
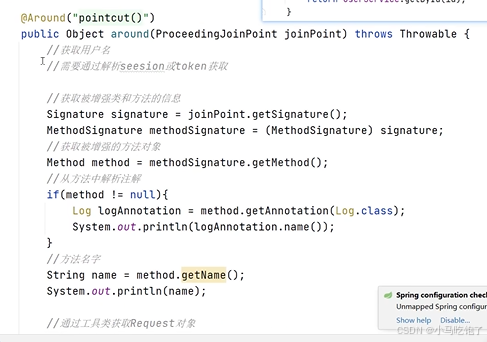
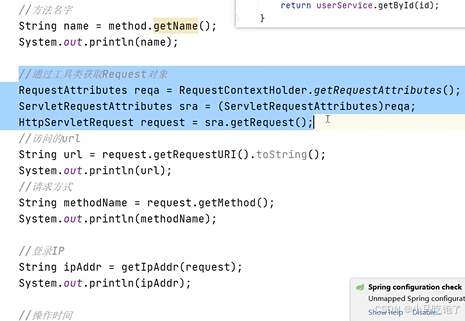
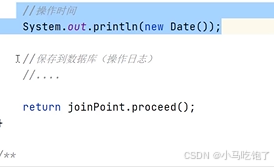
1.记录操作日志思路
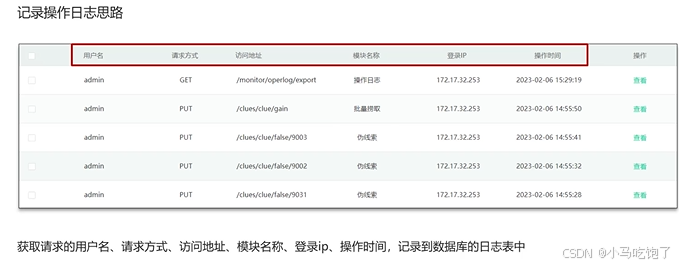
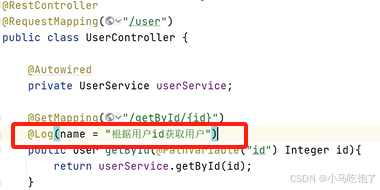
自定义注解Log

1.3spring中的事务是如何实现的
spring支持编程式事务管理和声明式事务管理
- 编程式事务管理:需要使用Translation Template来进行实现,对业务代码有侵入性,项目中很少使用。
- 声明式事务管理:声明式事务管理建立在AOP上。其本质是通过AOP功能,对方法前后进行拦截,将事务处理的功能编制到拦截的方法中,也就是在目标方法之前加入一个事务,在执行玩目标方法后根据执行情况提交或者回滚事务。
Q:什么是AOP?
面向切面编程,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取公共模块复用,降低耦合。
Q:spring的事务是如何实现的?
声明式事务,本质就是AOP功能,对方法进行前后拦截,在执行方法之前开启事务,在执行目标完成之后根据执行情况提交或者回滚事务。
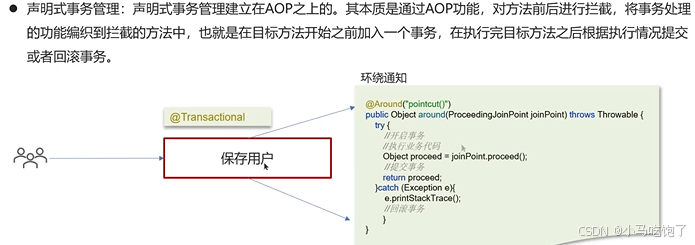

1.4spring中事务失效的场景有哪些
- 异常捕获处理
- 抛出检查异常
- 非public方法
情景一:异常捕获处理
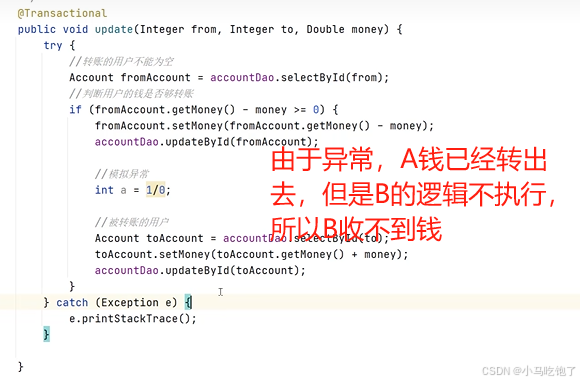
原因:事务通知只有捉到了目标抛出的异常,才能进行后续的回滚处理,如果目标自己处理异常,事务通知无法知悉。
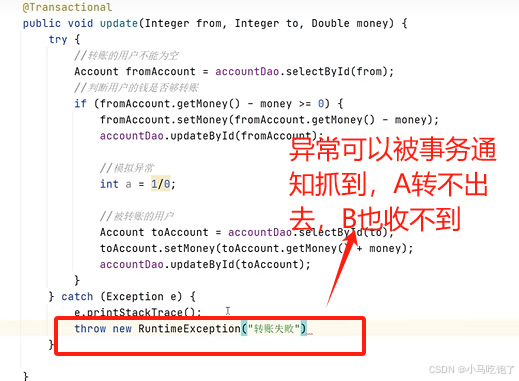
解决:
在catch块中添加throw new runtimeException(e)抛出
实例:
情景二:抛出检查异常
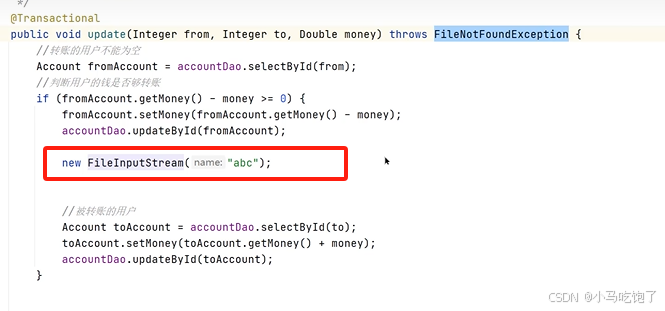
原因:spring默认只会回滚非检查异常
因为A转钱还没检查,所以成功
但是B收钱之前发现检查异常,所以B收钱的事务不回滚
解决:
配置rollbackFor属性
@Transactionl(rollbackFor.class)这时候只要有异常都会回滚,因为有异常,那么A钱不会少,B钱不会多
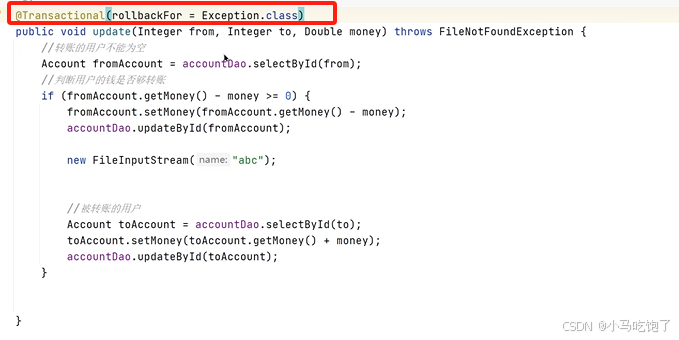
情景三:非public方法导致的事务失效

原因:spring为方法创建代理、添加事务通知、前提条件都是该方法是public的
解决:改为public
1.5spring的bean的生命周期
1.通过BeanDefinition获取bean的定义信息
2.调用构造函数实例化bean
3.bean的依赖注入
4.处理aware接口(BeanNameAware,BeanFactoryAware,ApplicationContextAware)
5.bean的后置处理器BeanPostProcessor前置
6.初始化方法
7.bean的后置处理器BeanPostProcessor后置
8.销毁bean
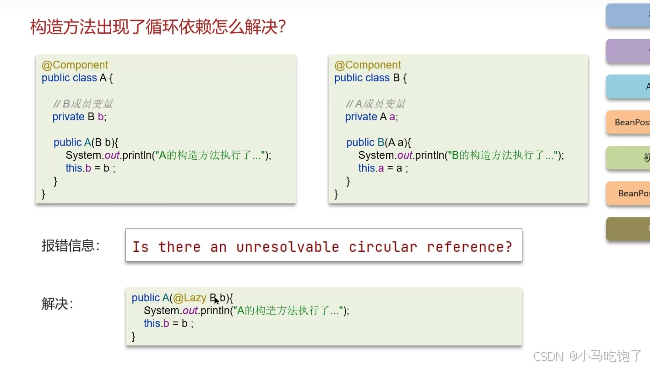
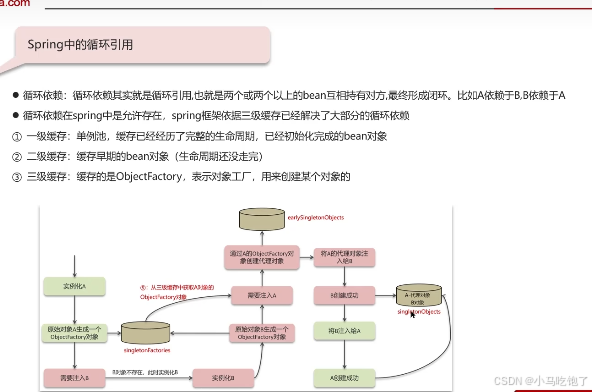
1.6spring的循环引用问题


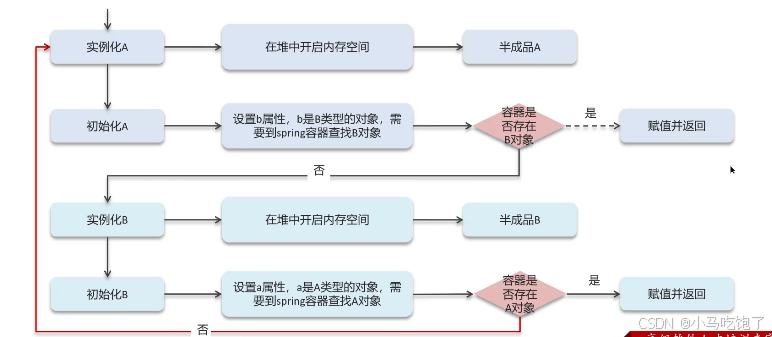
三级缓存解决循环依赖

一级缓存解决不了。
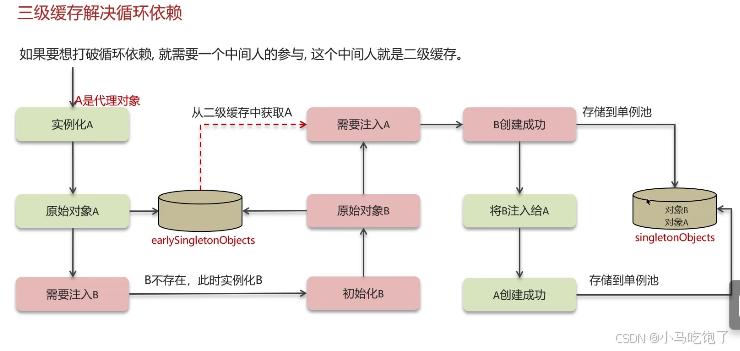
三级缓存
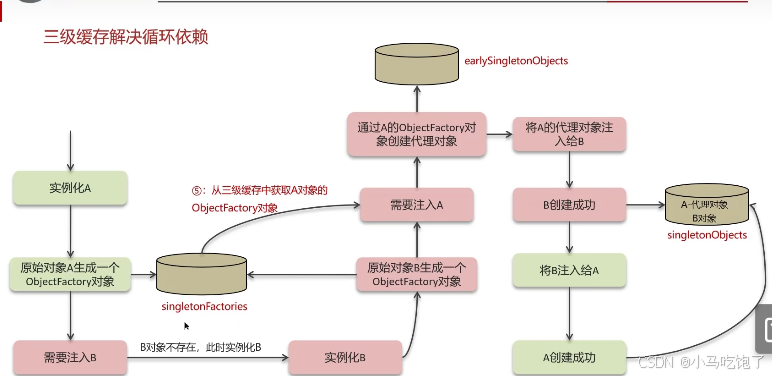
总结

1.7SpringMVC执行流程
SpringMVC最核心的内容
- 视图阶段
- 前后端分离阶段
1.视图阶段
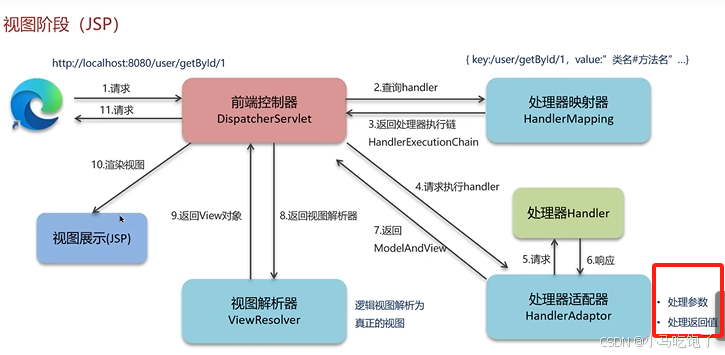
Q:springMVC中的重要组件
前端控制器 DispatcherServlet(接收所有的请求)
处理器映射器HandlerMapping(会根据路径查找对应的方法)
处理器适配器HandlerAdaptor(执行handler,并且处理handler中的参数和返回值)
视图解析器(将逻辑视图转化为真正的视图)
2.前后端分离阶段(接口开发,异步请求)
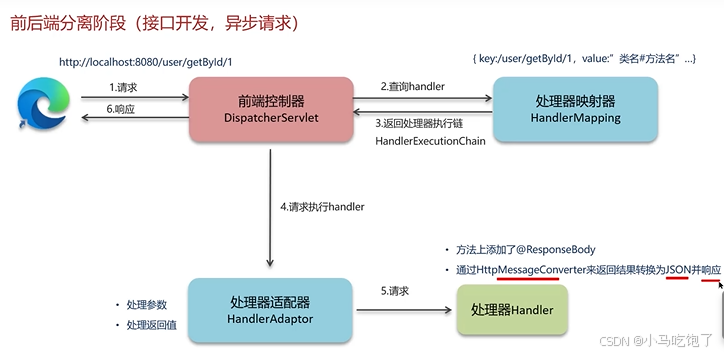
Q:springMVC的执行流程(JSP)
1.用户发送请求到前端控制器dispacterServlet。
2.dispacterServlet收到请求调用处理器映射器HandlerMapping。
3.HandleMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给dispacterServlet。
4.DispatcherServlet调用处理器适配器(HandlerAdapter)
5.HandlerAdapter经过适配器调用具体的处理器(Handler/Handler)
6.Controller执行完成后会返回ModelandView对象
7.HandlerAdapter将Controller返回的modelandview返回给DispatcherServlet
8.DispatcherServlet将modelandview冲送给ViewReslover(视图解析器)
9.ViewReslover解析后返回具体View视图
10.DispatcherServlet根据view进行渲染视图
11.DispatcherServlet响应用户
前后端开发,接口开发
1.用户发送请求到前端控制器dispacterServlet。
2.dispacterServlet收到请求调用处理器映射器HandlerMapping。
3.HandleMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给dispacterServlet。
4.DispatcherServlet调用处理器适配器(HandlerAdapter)
5.HandlerAdapter经过适配调用具体的处理器(Handler/Controller)
6.方法上添加@ResponseBody
7.通过HttpMessageConverter来返回结果转化为JSON并响应
1.8SpringBoot的自动配置原理
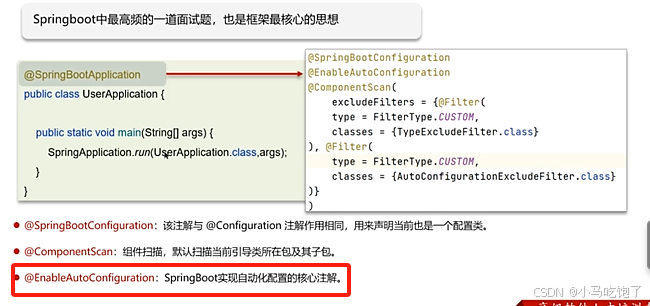
Q:springboot自动装配原理
1.在Spring Boot项目的引导类上有一个注解@SpringBootApplication,这个注解是对三个注解的封装,分别是 @SpringBootConfiguration @EnableAutoConfiguration
@ComponentScan
2.其中@EnableAutoConfiguration是实现自动化配置的核心注解,该注解通过@Import注解导入对应的配置选择器
内部就是读取该项目和该项目引用的jar包的classpath路径下的META-INF/spring.factories文件中的所配置类的全类名,在这些配置类中的所有bean会根据条件注解所之指定的条件来决定是否需要将其导入到spring容器中
3.条件判断回向@ConditionOnClass这样的注解,判断是否有对应的class,如果有则加载给类,把这个配置类的所有bean放入spring容器中使用。
1.9spring框架常见的注解
spring常见注解

springMVC常见注解

springboot相关注解

1.mybatis执行流程
持久层框架
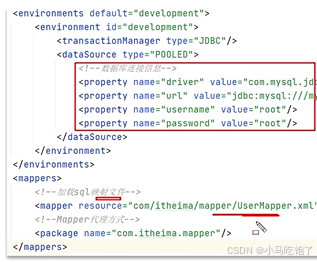
1.读取mybatisconfig.xml
1.1加载环境的配置
1.2加载映射文件
2.创建sqlSessionFactory
会话工厂,全局一个,生成SqlSessionFactory
3.创建会话SqlSession
项目中与数据库的会话,包含执行sql语句的所有方法,每次操作一次还会话,有多个。
4.Executor执行器:真正操作数据库的接口,也负责查询缓存的维护
5.MapperStatement对象 :创建mapper,定义标签中的某些信息
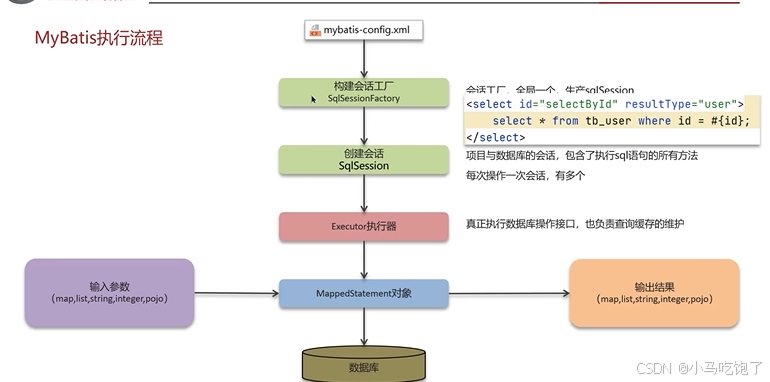
Q:Mybatis执行流程
1.读取mybatis配置文件:mybatis-config.xml加载运行环境和映射文件
2.构建会话工厂
3.构建会话sqlSession(包含执行sql的所有方法)
4.Executor执行器,操作数据库的接口,同时负责查询缓存的维护
5.Executor接口中的执行方法中有一个MapperStatement类型的参数,封装成映射对象。
6.输入参数的映射
7.输出结果映射
2.Mybatis支持延迟加载以及原理
mybatis默认支持延迟加载但是默认是没有开启
什么是延迟加载?

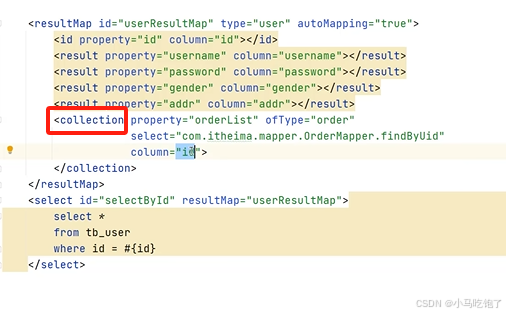

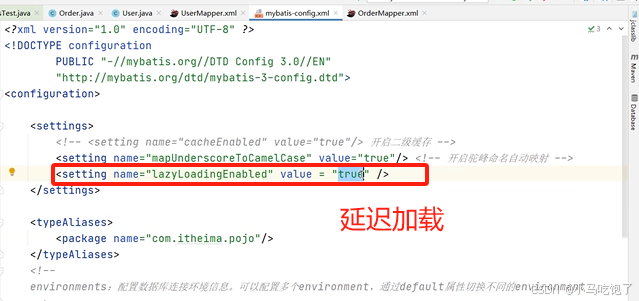
延迟加载的底层实现逻辑
用代理对象完成的(CGLIB)
3.mybatis的一级、二级缓存
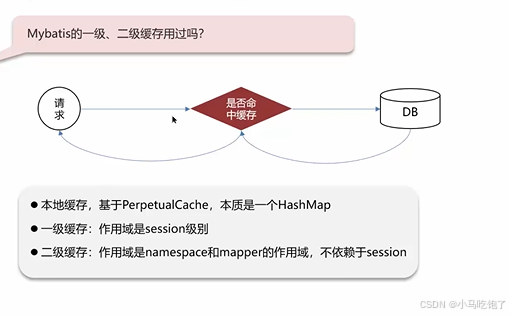
一级 查询数据保存在本地 ,作用域为session

二级 本地
开启二级缓存

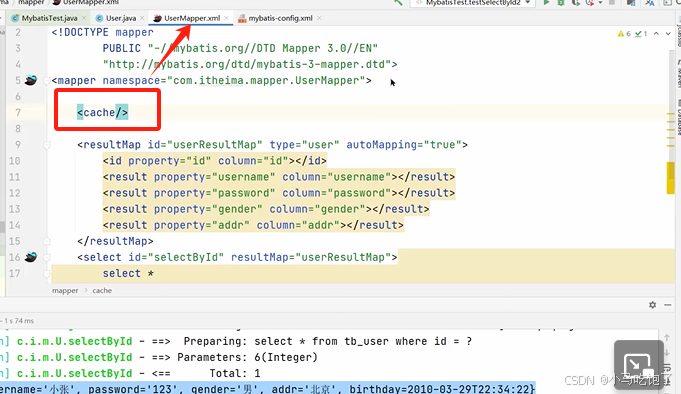
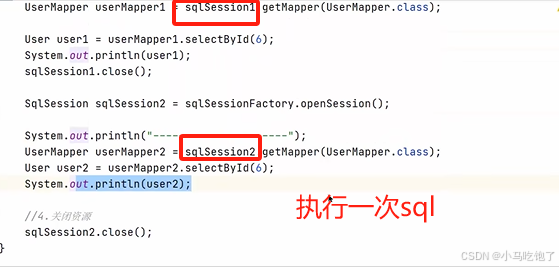

Q:一级缓存是基于PerpetualCache的HashMap本地缓存,起作用域为session,当session进项flush或者close后,该session中的所有cache就会清空,默认一级缓存打开。
二级缓存是基于namespace和mapper的作用域起作用的,不是依赖于SQL session,默认是采用PerpetualCache的HashMap存储,需要单独开启,一个是核心配置,一个是mapper映射文件。
Q:mybatis的二级缓存中的数据什么时候会被清理
当某个作用域进行了增,删,改,操作后,就会清理。
1.RabbitMQ如何保证消息不丢失
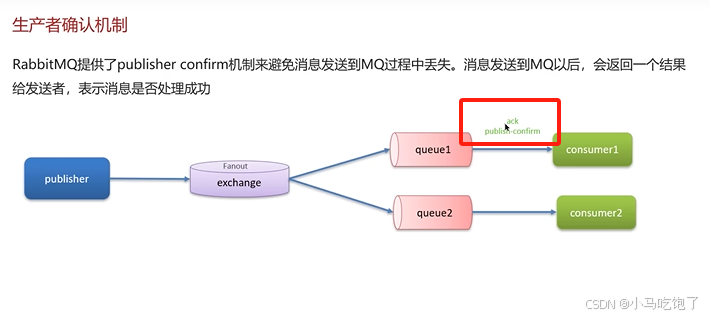
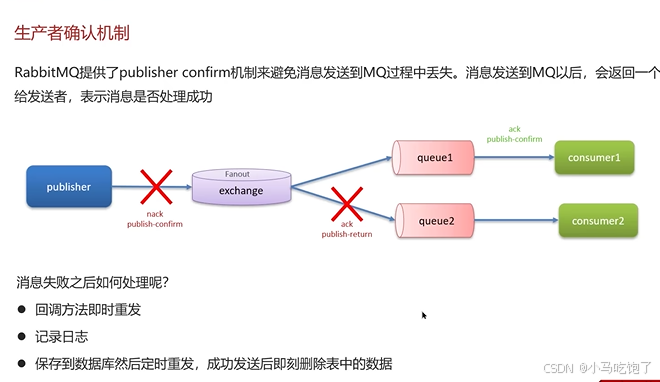
2.消息发送到了队列中,但是MQ宕机
使用持久化功能

3.消费者确认



2.RabbitMQ消息的重复消费问题解决
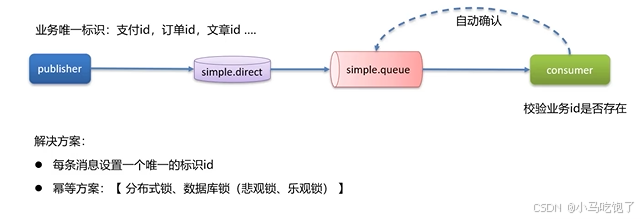
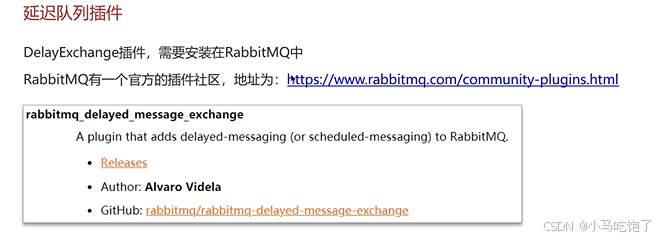
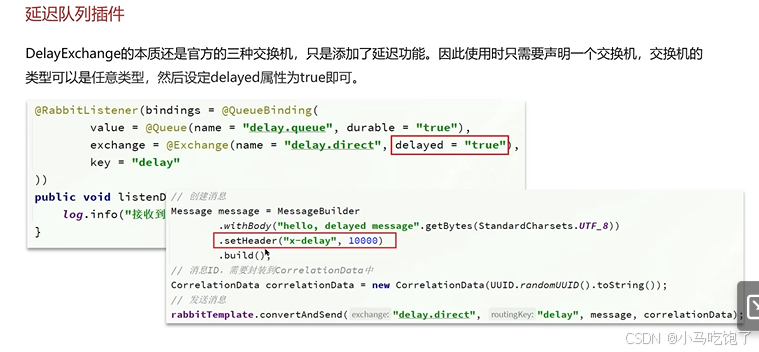
3.RabbitMQ中的死信交换机(RabbitMQ延迟队列)
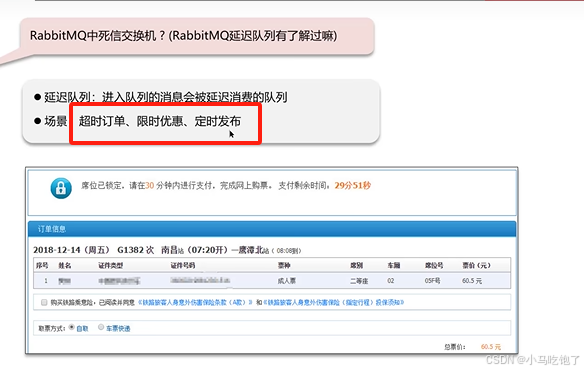

死信交换机:
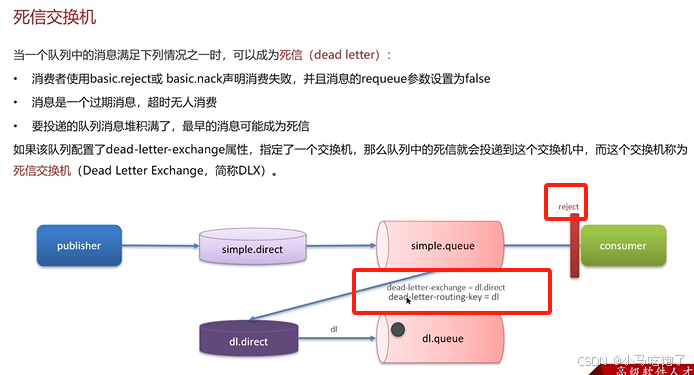

TTL
插件
插件


4.RabbitMQ消息堆积
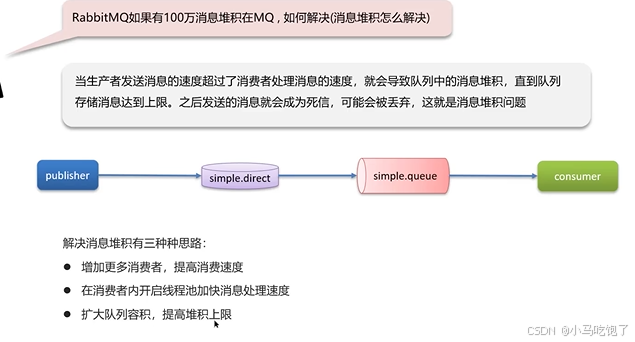
惰性队列 存在磁盘


5.RabbitMQ的高可用


并发与并行的区别
现在都是在多核cpu,在多核cpu下:
并发是时间应对多件事情的能力,每个线程轮流使用一个或多个cpu。
并行是同一时间动手做多件事情的能力,4核cpu同时执行4个线程。
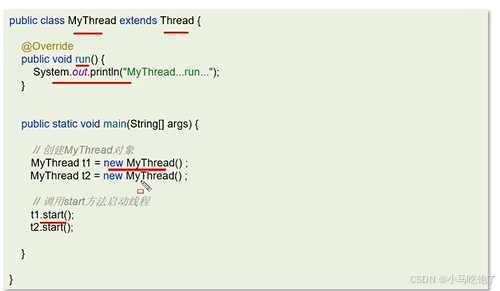
1.创建线程的方式
1.1继承thrend类
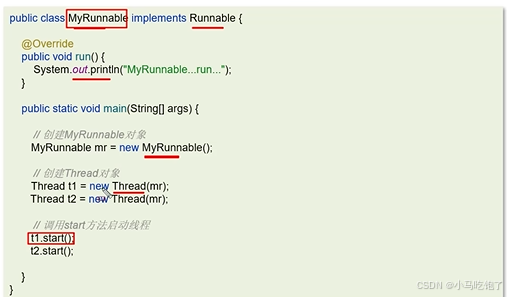
1.2实现runnable接口
1.3实现Callable接口

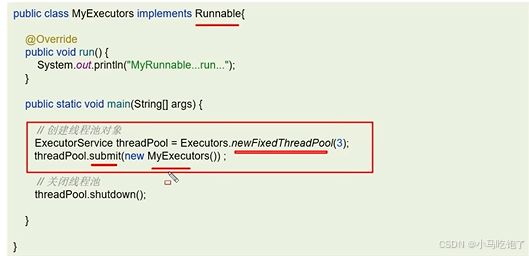
1.4线程池创建
1.5runnable与callable区别
- Runnable接口的run方法没有返回值
- Callable接口call方法有返回值,是个泛型,和Future、FutureTask配合使用可以用来获取异步执行的结果
- Callable接口的call方法可以用来抛出异常,而Ronnable接口的方法上不能抛出异常,只能在内部使用try catch
1.6 run()和start()的区别
1.start()用来启动线程,通过该线程调用run方法来执行代码中的逻辑,只能开启一次
2.run()封装了要被线程执行的代码,可以被调用多次
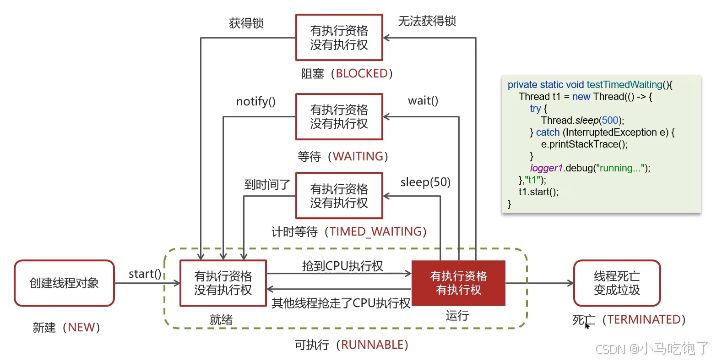
2.线程状态


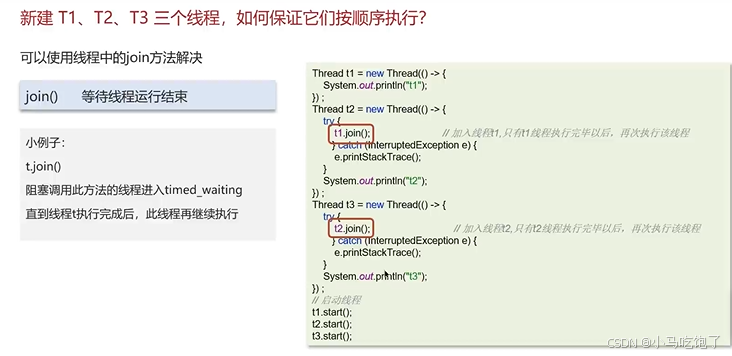
3.线程按序执行
线程中的join方法
t2中有t1.join() 表示t2等待t1执行完成后,才能执行
4.notifyAll与notify区别
notifyAll唤醒所有wait线程
notify随机唤醒一个wait线程
5.wait和sleep区别
共同点:wait(),wait(long)和sleep(long)的效果都是让当前线程暂时放弃cpu的使用权,进入阻塞状态。
不同点:
1.归属方法不同
-
sleep(long)是Thread的静态方法
-
wait(),wait(long)都是object的成员方法,每个对象都有
2.醒来时机不同 -
执行sleep(long)和wait(long)的线程都会在等待相应毫秒后醒来
-
wait(long)和wait还可以被notify唤醒,wait()如果不唤醒就会一直等下去。
-
他们都可以被打断唤醒
3.锁特性不同(重点) -
wait方法的调用必须先获取wait对象的锁,而sleep则无此限制
-
wait方法执行后会释放对象锁,允许其他线程获得对应的锁(我放弃cpu,但你们还可以用)
-
而sleep如果在synchronized代码块中使用,并不会释放锁(我放弃了cpu,你们也用不了)

6.线程中断方式
1.设置标记
2.调用interrupt方法
- 打断阻塞的线程(sleep,join,wait),线程会抛出interruptedException异常
- 打断正常线程是改变标识状态
1.synchronized底层原理
monitor 监视器 有jvm提供
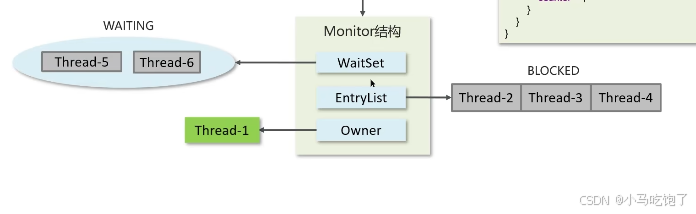
当有线程进入,先检查owner中是否为null’,如果为null,则进行执行。如果不为null,进入entryList中进行等待,此时是阻塞状态。 如果有线程设置了wait(),则进入waitList中进行等待
owner:获取当前存储锁的线程,只能有一个线程
entryList:关联没有抢到锁的线程,处于block状态的线程
waitset: 关联调用wait方法的线程,处于waiting状态的线程
底层原理
synchronized(对象锁):采用互斥的方式让同一时间只有一个线程持有对象锁。
底层是monitor实现,monitor是jvm级别的对象,线程获得锁需要使用对象关联monitor。
montor包括owner,entrylist,waitset
其中owner关联的是获得锁的线程,并且只能获得一个线程。
entrylist是关联的所有阻塞状态的线程,waitset关联的是出于wait状态的线程。
2.进阶
monitor是重量级锁,里面涉及用户态和内核态
JDK 1.6 在所没有竞争的情况下,使用轻量锁。

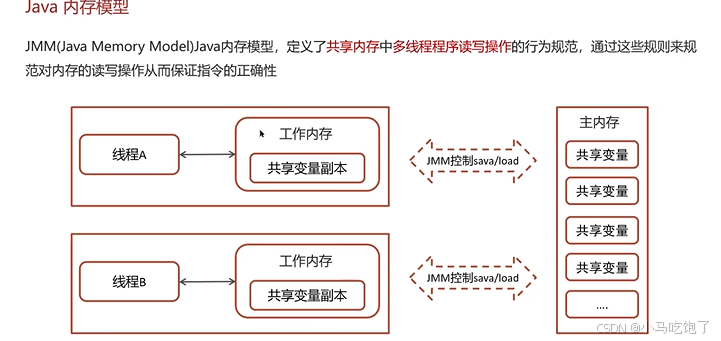
3. jmm
共享内存中多线程程序读写操作

4.CAS
cas数据交换流程
自旋锁:因为没有加锁,所以线程不会阻塞,效率较高
如果竞争激烈,重试频繁发生,效率会受影响
cas底层实现
CAS底层依赖于一个Unsafe类来直接调用操作系统底层的cas指令。
乐观锁和悲观锁
CAS是基于了乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改变了也没有关系,可以进行重试。
synchronized:是基于悲观锁实现的,最悲观的估计,防着其他线程来修改共享变量,我们上了锁,你们都别想修改,我改完了解开锁,你们才有机会。

5.volatile
1.保证线程间的可见性
用volatile修饰的共享变量,能够防止编译器等优化发生,让一个线程对共享变量的修改对另一个线程可见。

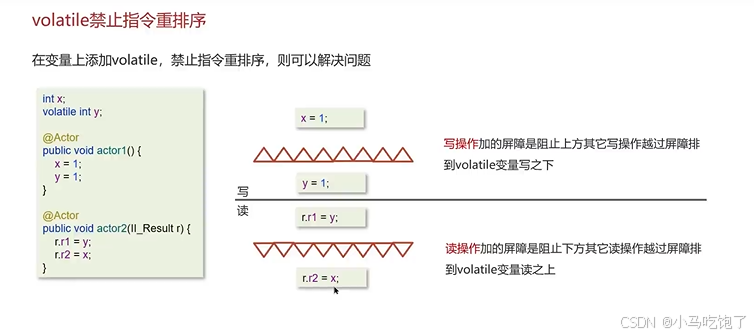
2.禁止指令重排序
多线程测试工具 jcstress
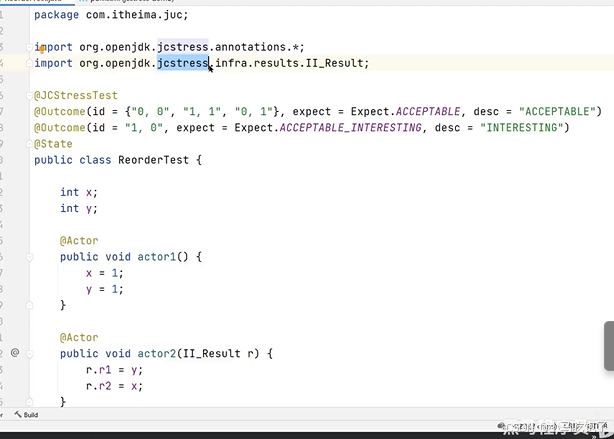
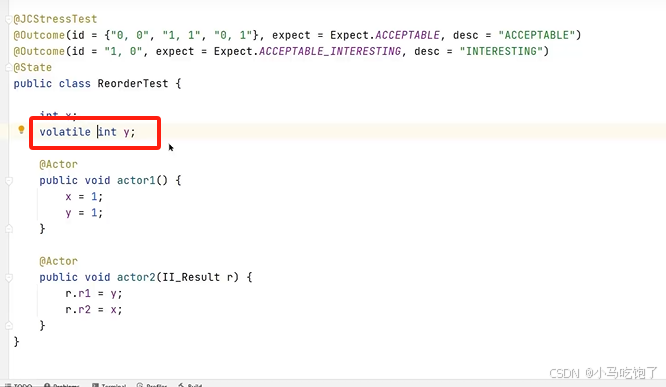

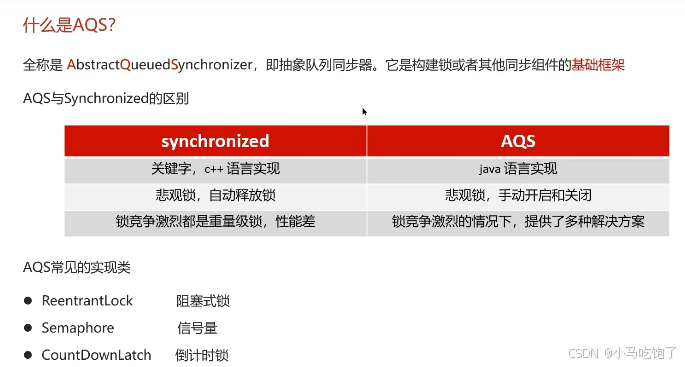
6.什么是AQS
抽象队列同步器,他是构建锁或者其他同步组件的基础框架
基本工作机制
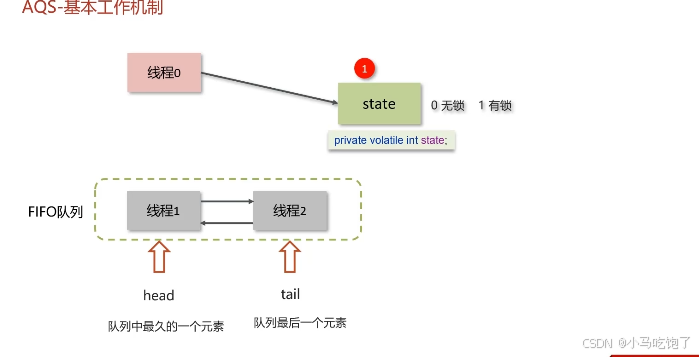
多个进程抢一个锁,怎么执行
保证原子性 是cas
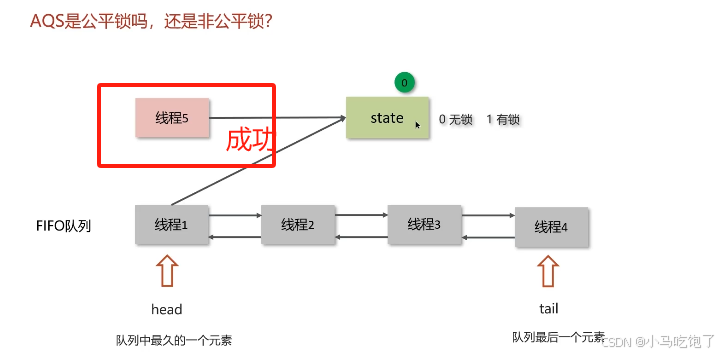
AOS实现非公平锁 新的线程与队列中的线程共同来抢资源
公平锁 新的线程要到队列中等待,只让队列中的head线程获取锁。 先来的先去获得锁。
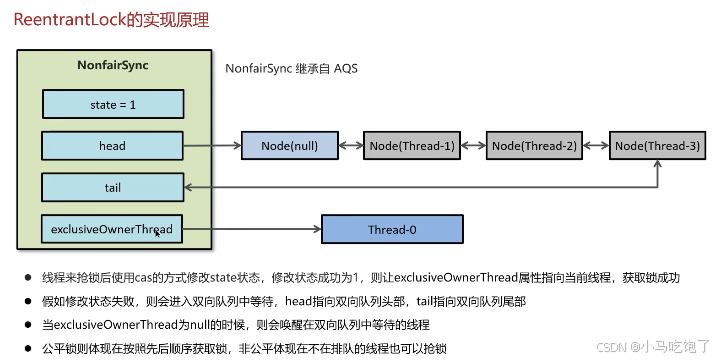
7.reentrantLock可重入锁
可中断
可设置超时时间
可以设置公平锁
支持多个条件变量
与synchorinzed一样,都支持重入
CAS+AQS

8.synchorinzed与lock区别

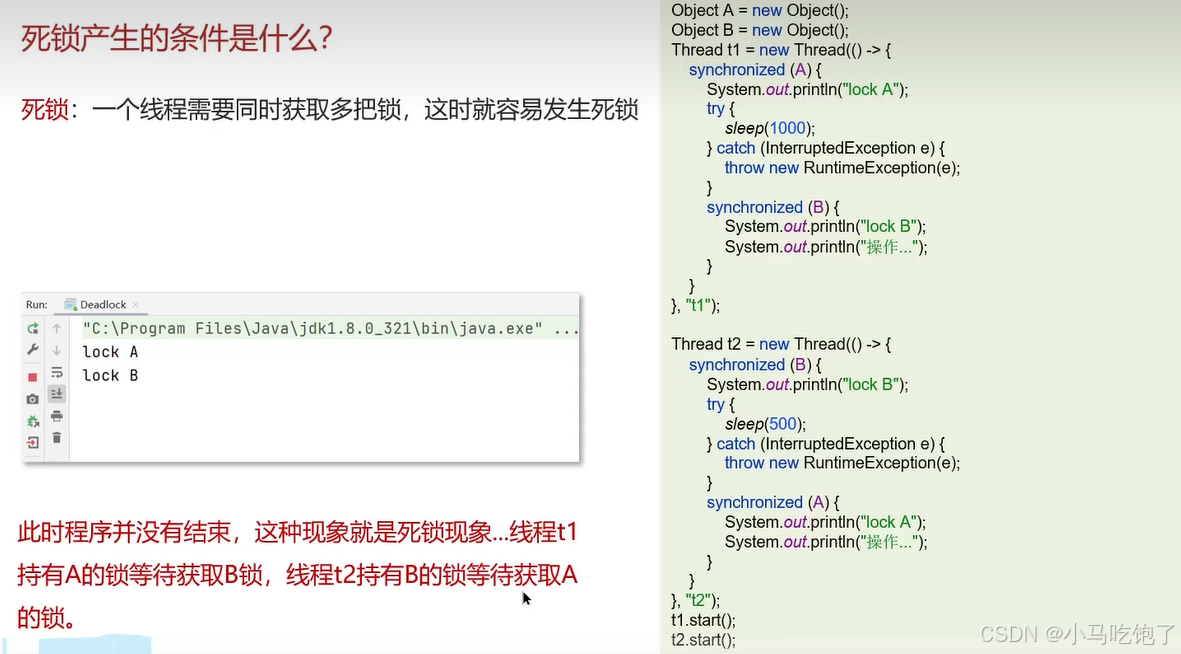
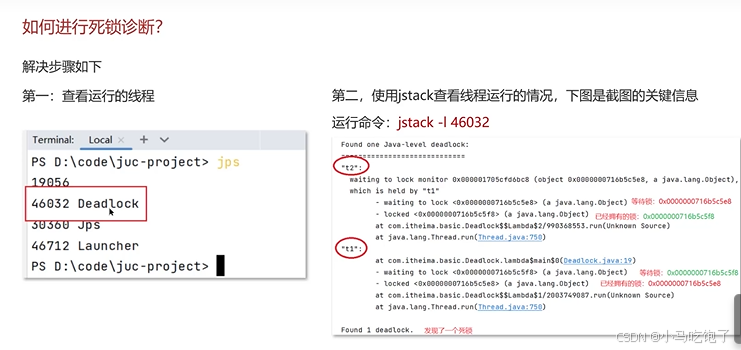
9.死锁



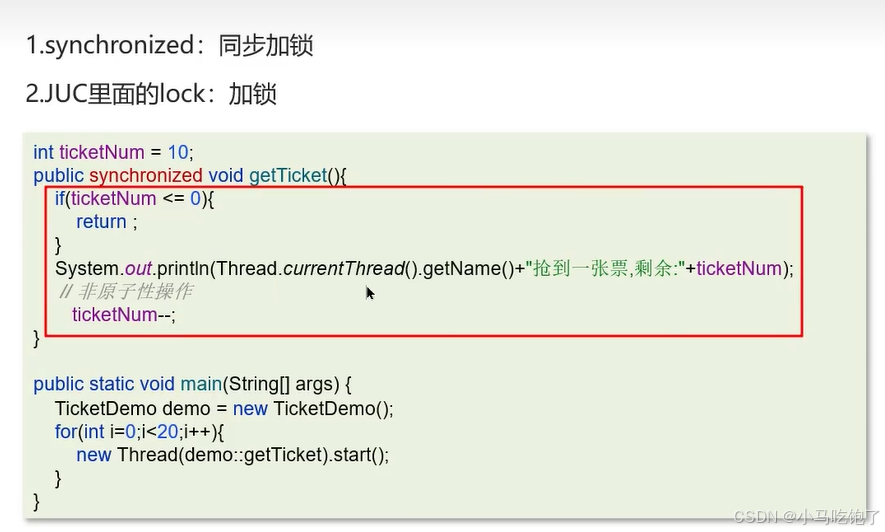
10.concurrentHashMap


版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/22947.html