
激活函数总结(四):Hard系列激活函数补充
1 引言
2 激活函数
2.1 HardSigmoid激活函数
2.2 HardTanh激活函数
2.3 Hardswish激活函数
3. 总结
1 引言
在前面的文章中已经介绍了过去大家较为常见的激活函数 (Sigmoid、Tanh、ReLU、Leaky ReLU、PReLU、Swish、ELU、SELU、GELU、Softmax、Softplus、Mish、Maxout)。在这篇文章中,会接着上文提到的众多激活函数继续进行介绍,给大家带来更多不常见的激活函数的介绍。这里放一张激活函数的机理图:
最后,对于文章中没有提及到的激活函数,大家可以通过评论指出,作者会在后续的文章中进行添加补充。
2 激活函数
2.1 HardSigmoid激活函数
HardSigmoid(硬Sigmoid)激活函数是一种近似于Sigmoid函数的非线性激活函数。HardSigmoid 激活函数通过对Sigmoid函数进行修剪和缩放,使其更加接近于一个分段线性函数。其数学表达式和数学图像分别如下所示:
H a r d S i g m o i d ( x ) = m a x ( 0 , m i n ( 1 , α ∗ x + β ) ) HardSigmoid(x) = max(0, min(1, α * x + β))
HardSigmoid(x)=max(0,min(1,α∗x+β))
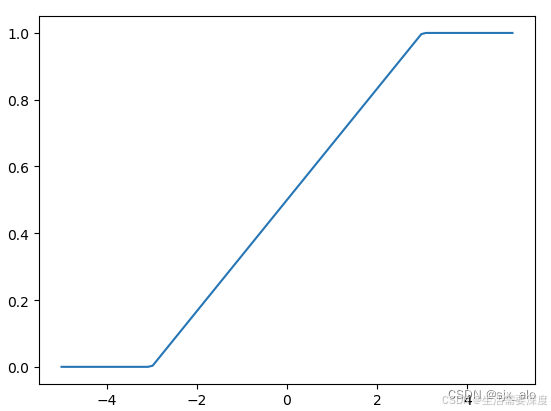
其中,α αα 是斜率参数,β ββ 是偏移参数。通常情况下,α αα 取值为1/6,β ββ 取值为1/3,这样 HardSigmoid 函数在x取值在[-3, 3]范围内比较接近于Sigmoid函数。对于超出这个范围的输入,其输出将被限制在0和1之间。
优点:
更加高效:相比于Sigmoid函数,HardSigmoid函数计算更加简单,因为它只涉及最大值、最小值和简单的线性变换。这使得HardSigmoid函数在一些资源有限的设备上更容易实现,并且可以减少计算负担。
计算稳定:sigmoid函数的输入在绝对值较大时,其输出会趋近于0或1,导致梯度消失;而hardsigmoid的输出在0和1之间波动,避免了这种情况
增加稀疏性:由于hardsigmoid的输出是截断的,超过一定阈值的输入将被截断成1,从而增加了神经元对输入的敏感程度,有利于网络产生稀疏表示
缺点:
非光滑性:HardSigmoid是一个分段线性函数,在某些点上存在不连续性。这意味着在这些点上梯度不连续,可能导致优化过程中出现问题。在反向传播时,梯度的不连续性可能会影响训练的稳定性,增加收敛时间,甚至导致模型无法收敛。
信息丢失:由于HardSigmoid对输入进行硬剪裁,将超过一定范围的值限制在0和1之间,因此它会导致部分信息的丢失。这可能会对模型的表达能力产生一定的负面影响,尤其是对于那些需要更精确输出的任务。
缺乏灵活性:HardSigmoid是一个固定形状的激活函数,其斜率和偏移参数在大多数情况下是固定的。这使得它相对缺乏灵活性,难以适应复杂的数据分布或任务。
不适用于梯度爆炸问题:HardSigmoid虽然在某些情况下有助于缓解梯度消失问题,但对于梯度爆炸问题并没有提供明显的改进。在深度神经网络中,梯度爆炸问题可能导致训练不稳定或无法收敛。
当前还是ReLU的天下,连续的激活函数往往更令人喜欢!!!HardSigmoid几乎没见人用过。。。
2.2 HardTanh激活函数
HardTanh(硬切线激活函数)是一种非线性激活函数,它是Tanh函数的一种变体。与标准的Tanh函数相比,HardTanh函数进行了简单的截断和缩放,使其更接近于一个分段线性函数。其数学表达式和数学图像分别如下所示:
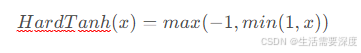
H a r d T a n h ( x ) = m a x ( − 1 , m i n ( 1 , x ) ) HardTanh(x) = max(-1, min(1, x))
HardTanh(x)=max(−1,min(1,x))
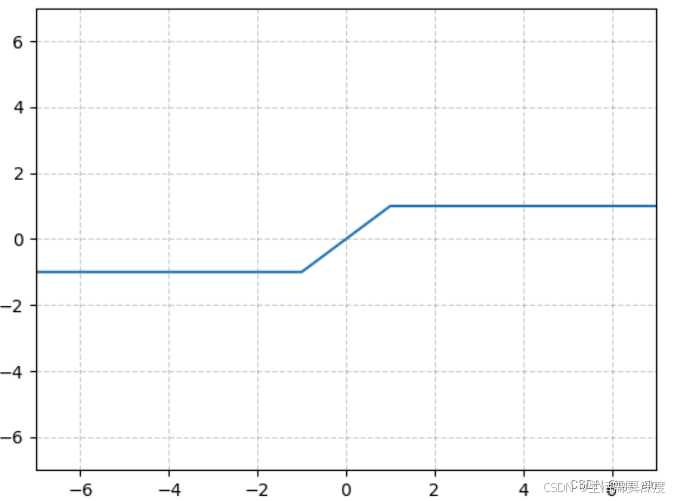
该函数将输入x限制在区间[-1, 1]之间。在输入小于-1时,输出值将被固定为-1,在输入大于1时,输出值将被固定为1。只有当输入在[-1, 1]之间时,HardTanh函数才对输入进行线性变换。
优点:
简单性:HardTanh函数的计算非常简单,只涉及最大值、最小值和简单的线性变换,因此在硬件加速或资源受限的设备上实现起来相对容易。
非线性性:尽管HardTanh函数在输入在[-1,1]之间是线性的,但它在输入小于-1和大于1时是非线性的,因此可以引入一些非线性特性,有助于提高模型的表达能力。
有界输出:HardTanh函数的输出范围被限制在[-1, 1]之间,这有助于避免梯度爆炸和梯度消失问题,并提供更稳定的训练过程。
缺点:
非光滑性:HardTanh是一个分段线性函数,在某些点上存在不连续性。这意味着在这些点上梯度不连续,可能导致优化过程中出现问题。类似于HardSigmoid,梯度的不连续性可能会影响训练的稳定性,并增加收敛时间。
信息丢失:HardTanh对输入进行硬剪裁,将超过一定范围的值限制在固定的范围内(通常为-1和1之间)。这会导致一些信息的丢失,特别是对于那些需要更大范围输出的任务,HardTanh可能无法准确地表示输出。
硬剪裁的影响:HardTanh的硬剪裁可能导致梯度的消失问题,尤其是在较深的神经网络中。当输入位于硬剪裁的边界附近时,梯度可能变得非常小,导致模型的学习速度减慢甚至停止学习。
不适用于梯度爆炸问题:类似于HardSigmoid,HardTanh对于梯度爆炸问题并没有提供明显的改进。在深度神经网络中,梯度爆炸问题可能导致训练不稳定或无法收敛。
参数缺少:HardTanh激活函数通常不具有可调整的参数,这使得它在某些情况下缺乏灵活性。无法调整参数可能会导致HardTanh难以适应复杂的数据分布或任务。
同样地,对于不连续的HardTanh激活函数,几乎没有人使用。。。
2.3 Hardswish激活函数
论文链接:https://arxiv.org/abs/1905.02244
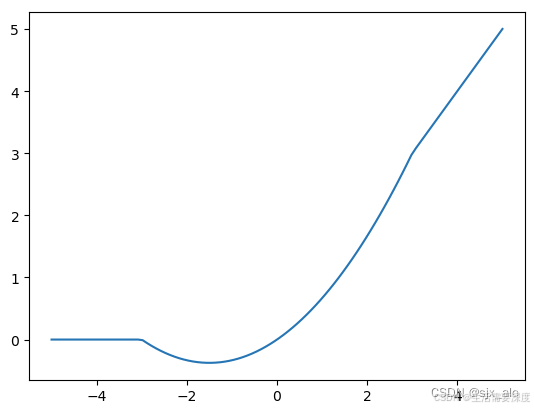
HardSwish(硬切线激活函数)是一种近似于Swish激活函数的非线性激活函数。HardSwish激活函数在2017年提出,是对Swish函数进行修剪和缩放,使其更加接近于一个分段线性函数。其数学表达式和数学图像分别如下所示:
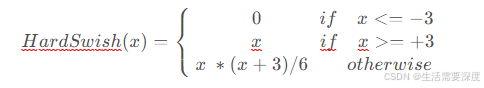
H a r d S w i s h ( x ) = { 0 i f x < = − 3 x i f x > = + 3 x ∗ ( x + 3 ) / 6 o t h e r w i s e HardSwish(x)=left{
0ifx<=−3xifx>=+3x ∗(x+3)/6otherwise
0ifx<=−3xifx>=+3x ∗(x+3)/6otherwise
ight.
HardSwish(x)=
⎩
⎨
⎧
0ifx<=−3
xifx>=+3
x ∗(x+3)/6otherwise
优点:
可在嵌入式上使用:swish非线性激活函数提高了检测精度,但不适合在嵌入式移动设备上使用,因为“S”型函数在嵌入式移动设备上的计算成本更高,求导较为复杂,在量化时计算较慢。而hardswish非线性激活函数与swish函数相比:在准确性上没有明显差别,但从部署在嵌入式移动设备上而言具有多重优势。
数值稳定性好:在量化模式下,它消除了由于近似Sigmoid形的不同实现而导致的潜在数值精度损失。
计算速度快:在实践中,hardswish激活函数可以实现为分段功能,以减少内存访问次数,从而大大降低了等待时间成本。
缺点:
虽然相比于swish具有较快的计算速度,但是相比ReLU6仍存在计算量较大的问题。
设计之初是为了应用于移动端,在MobileNetV3、YOLOv5中都有应用。其本身具有与Swish差不多的性能,且更快。因此,是一个当前较为流行的激活函数。
3. 总结
到此,使用 激活函数总结(四) 已经介绍完毕了!!! 如果有什么疑问欢迎在评论区提出,对于共性问题可能会后续添加到文章介绍中。如果存在没有提及的激活函数也可以在评论区提出,后续会对其进行添加!!!!
如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_36758270/article/details/132153698
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/29238.html