
点击蓝字
关注我们,让开发变得更有趣
作者 | 王国强 苏州嘉树医疗科技有限公司 算法工程师
指导 | 颜国进 英特尔边缘计算创新大使
OpenVINO™
OpenVINO™ Model Server 介绍
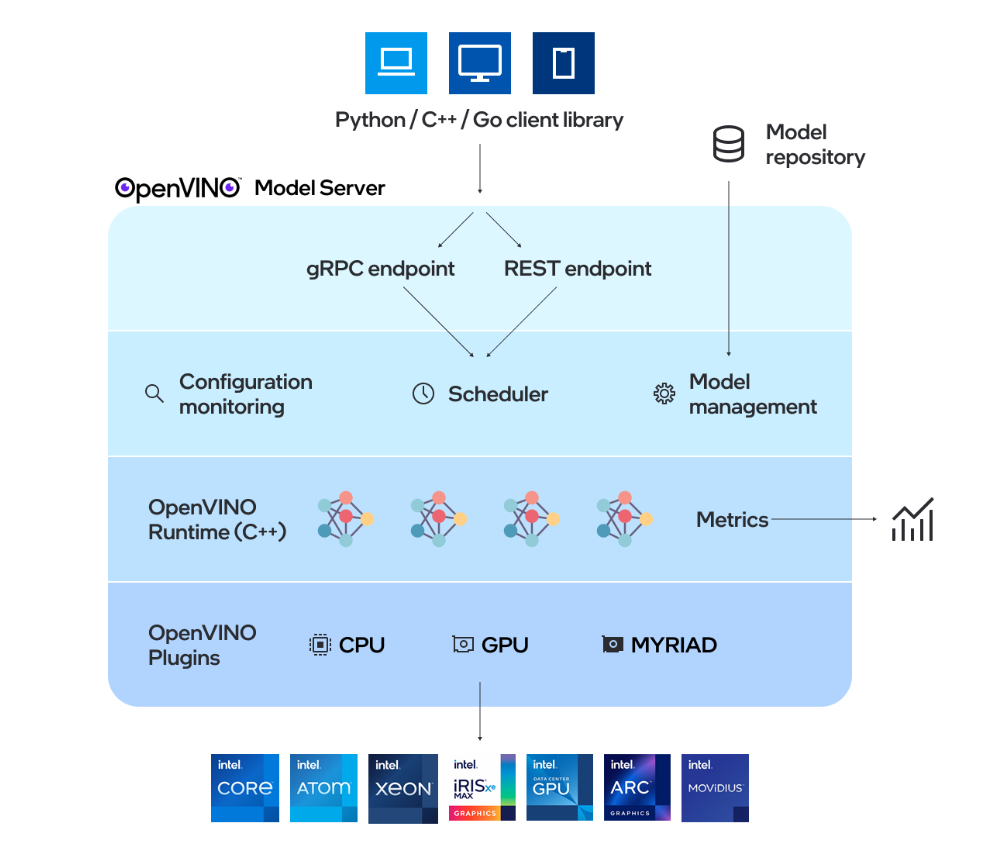
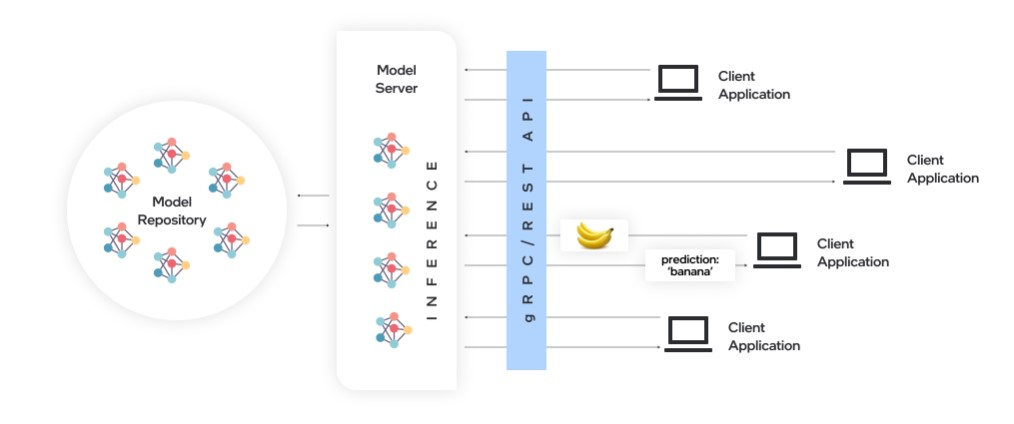
OpenVINO™ Model Server(OVMS)是一个高性能的模型部署系统,使用 C++ 实现,并在 Intel 架构上的部署进行了优化,使用 OpenVINO™ 进行推理,推理服务通过 gPRC 或 REST API 提供,使得部署新算法、AI 实验变得简单。OVMS 可以在 Docker 容器、裸机、Kuberntes 环境中运行,这里我使用的是 Docker 容器。
OpenVINO™
哪吒开发板 Docker 安装
Ubuntu22.04上的Docker安装可以参照官方文档:
https://docs.docker.com/engine/install/
首先安装依赖:
然后添加 Docker 的 GPG 密钥,如果你的网络可以正常访问 Docker 可以通过下面的命令添加 APT 源:
如果无法正常访问,就需要换成国内镜像源,这里以阿里源为例:
之后就可以通过 apt 安装 Docker,命令如下:
安装后可以通过以下命令验证是否安装成功:
OpenVINO™
拉取 OpenVINO™ Model Server 镜像
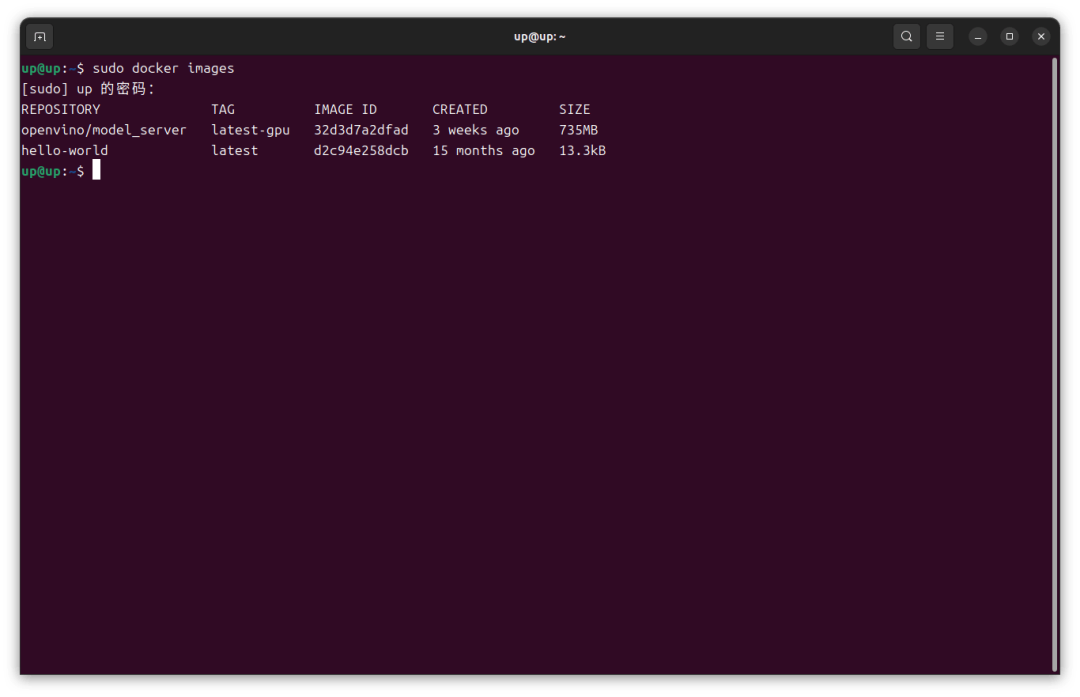
各个版本的镜像可以在 OpenVINO™ 的 Docker Hub 上找到,我拉取了一个最新的带有 GPU 环境的镜像:
https://hub.docker.com/r/openvino/model_server/tags
OpenVINO™
准备模型
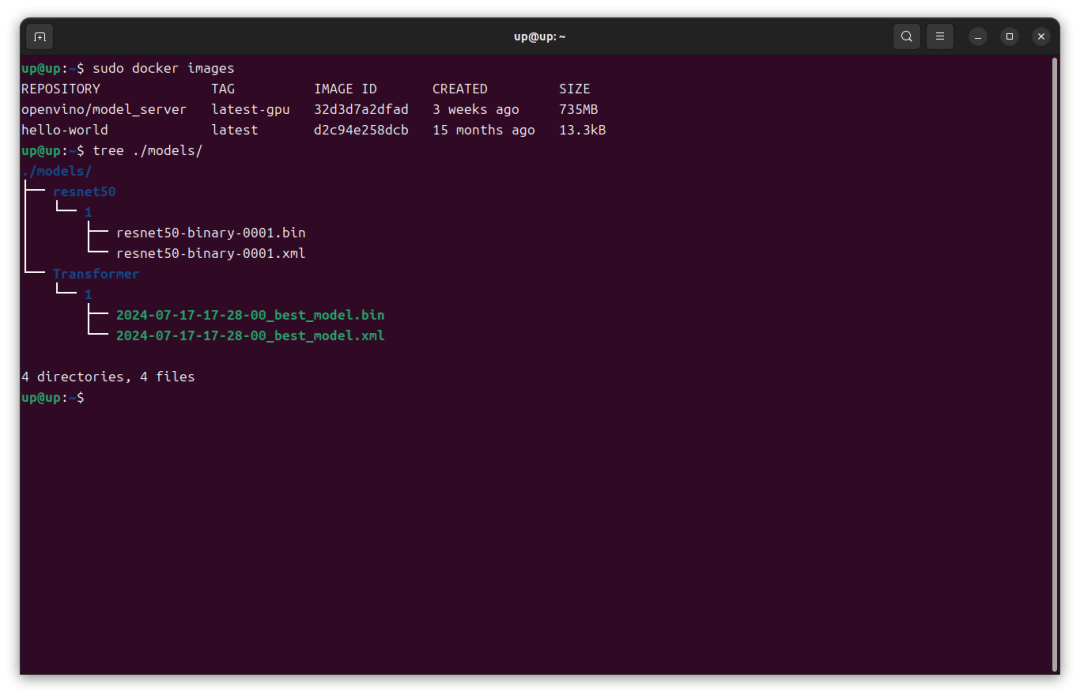
首先在哪吒开发板上新建一个 models 文件夹,文件夹的结构如下,这里我在 models 文件夹下存放了 resnet50 和 Transformer 两个模型,版本都为 1,模型为 OpenVINO™ IR 格式。
OpenVINO™
启动 OpenVINO™ Model Server 容器
在哪吒开发板上启动带有 iGPU 环境的 OpenVINO™ Model Server 容器命令如下:
各个参数的含义可在官方文档查看:
https://docs.openvino.ai/2024/ovms_docs_parameters.html
容器启动后可以通过以下命令查看容器ID、状态信息等。
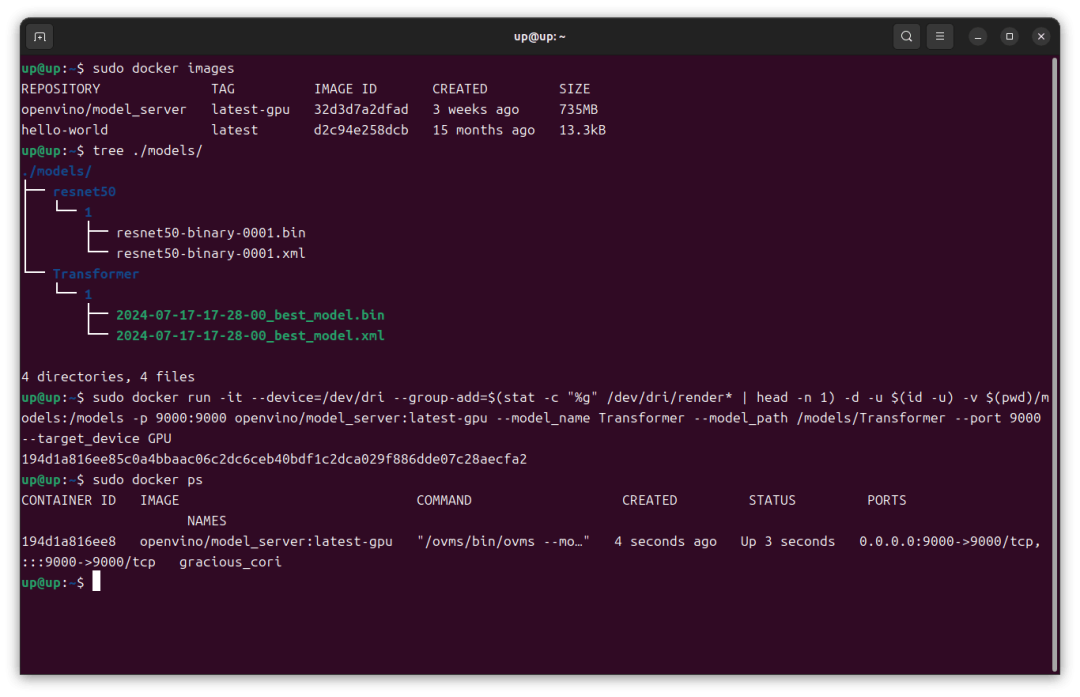
这样 Transformer 模型就通过 OpenVINO™ Model Server 部署在了哪吒开发板上。
OpenVINO™
请求推理服务
接下来通过 gRPC API 访问推理服务,以 python 为例,首先安装 ovmsclient 包。
请求推理的代码如下,这里在局域网的另一台机器上请求哪吒开发板上的推理服务,10.0.70.164为哪吒开发板的 ip 地址。
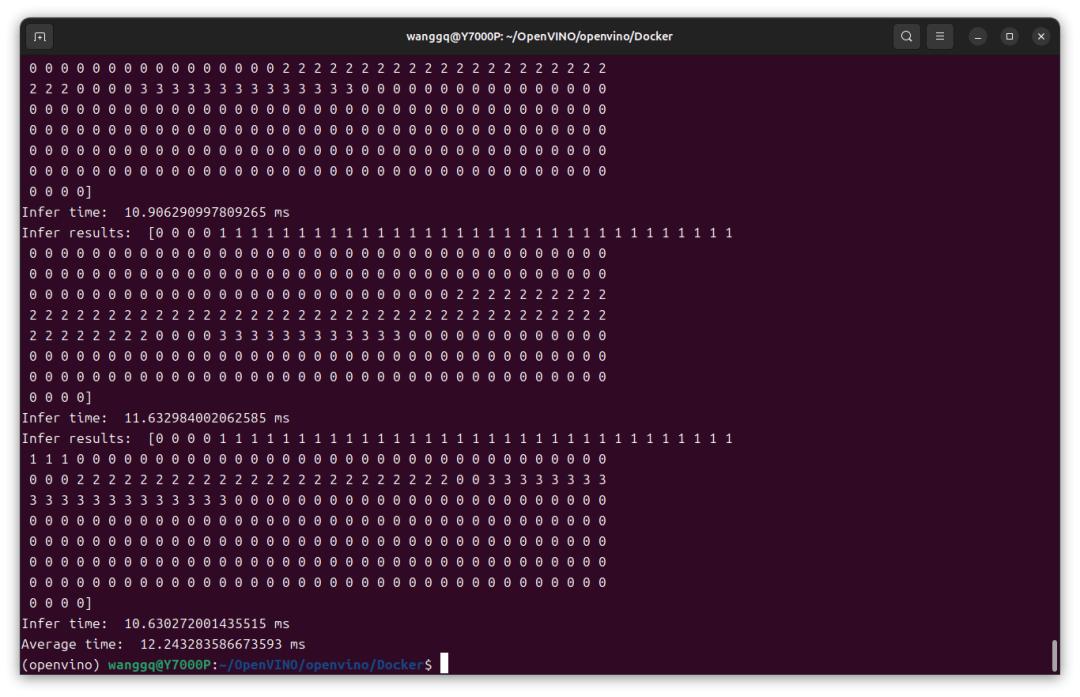
推理结果成功返回,平均推理时间 12ms,如果换成更稳定的以太网速度应该会更快。
OpenVINO™
总结
以上就是在哪吒开发板上使用 OpenVINO(C++) 推理模型,并通过 OpenVINO™ Model Server 进行模型部署的过程,可以看出 OpenVINO™ 的使用还是比较方便、简洁的,推理速度也很快。
OpenVINO™
---------------------------------------
*OpenVINO and the OpenVINO logo are trademarks of Intel Corporation or its subsidiaries.
-----------------------------
OpenVINO 中文社区
微信号 : openvinodev
B站:OpenVINO中文社区
“开放、开源、共创”
致力于通过定期举办线上与线下的沙龙、动手实践及开发者交流大会等活动,促进人工智能开发者之间的交流学习。
○ 点击 “ 在看 ”,让更多人看见
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/36539.html