
实验复现来源
https://zhuanlan.zhihu.com/p/603486955
该文章主要解决问题:
1.加深对图神经网络数据集的理解
2.加深对图神经网络模型中喂数据中维度变化的理解
原理问题在另一篇文章分析:
介绍数据集:cora数据集
其中的主要内容表示为一堆文章,有自己的特征内容,有自己的编号,有自己的类别(标签),相互引用的关系构成了图。
cora.content:包含特征编号,特征内容,特征类别(标签)
1.其中左面第一列表示特征编号
2.中间的内容表示特征内容(1433维)
3.右面的最后一列表示标签
cora.cite:引用关系,也称作边
左面第一列表示起始点(序号),右面表示终止点(序号),其中一行表示一个边,表示两个点的连接
以点作为主要特征进行分类
首先先看一下GCN网络的参数部分


主要参数就是输入的维度,输出的维度

主要的参数为结点的特征矩阵与图的连接关系
也就是说数据需要预处理成结点的特征矩阵,然后单独的标签,再预处理出图的连接关系
分为三个部分。
1.数据预处理
其中
node_features表示所有点的特征结合在一起
node_labels表示所有标签集中在一起
node_ids表示特征点的个数
首先是从数据集中抽取特征矩阵的过程
从数据集中提取边的集合
转换成data对象
简易的模型
第一种:主要关注结点的特征,所以不需要手工的对结点与边的特征进行融合,直接输入到卷积层即可。
训练测试过程
数据集划分
训练
测试
第二种:主要关注边的特征,该模型主要是将边的两端的两个结点特征进行拼接
整体代码块
3.按照图分类的方式进行计算,输入多个小图进行分类
数据集:ENZYMES
包含文件:
在该代码中,主要用到了以下几个文件:
-
ENZYMES_graph_indicator.txt:用于指示每个节点所属的图。PyTorch Geometric 会自动将每个节点分配到对应的图中,以便在训练和测试时能够分辨哪些节点属于同一个图。
-
ENZYMES_A.txt:用于定义每个图的边(即节点之间的连接关系),这个文件中的数据会被转换成 参数,用于图卷积层 的输入。
-
ENZYMES_node_labels.txt:用于给每个节点分配标签(标签只有 1 和 0),在一些任务中可能作为节点特征或属性被使用。
-
ENZYMES_graph_labels.txt:提供每个图的标签(类别)。这是最终分类任务的标签,也就是每个图所属的类别。在代码中,损失函数 会用到该标签进行监督学习。
此外,如果数据集中包含以下文件,它们也可能被使用:
-
ENZYMES_node_attributes.txt:每个节点的属性或特征,作为输入特征矩阵 ,即 。如果存在这个文件,它会被用作节点的特征数据。
-
ENZYMES_edge_attributes.txt:每条边的属性或特征。在该代码中没有直接用到这个文件,因为 层没有使用边特征
ENZYMES_A:表示边的集合

ENZYMES_graph_indicator:表示结点属于哪一个图
ENZYMES_graph_labels:图的标签
ENZYMES_node_attributes:结点特征

ENZYMES_node_labels:结点的标签
对于结点的标签。解释如下

1.加载数据集
模型结构
在图神经网络(GNN)中, 参数用于指示每个节点属于哪个图。通常情况下,在图神经网络的训练过程中,模型会处理一批(batch)图数据。 参数在这种情况下非常重要,因为它帮助模型在批次(batch)处理中区分不同的图。
例如:
在这个示例中, 表示一共有 3 个图:
- 前 3 个节点(索引 0、1、2)属于第一个图(标记为 0)。
- 接下来的 2 个节点(索引 3、4)属于第二个图(标记为 1)。
- 最后 4 个节点(索引 5、6、7、8)属于第三个图(标记为 2)。
2. 参数的作用
在图神经网络中, 参数的主要作用是帮助处理多个图的批量计算。在该代码中, 参数配合 函数使用。 会按照 参数,将属于同一个图的节点聚合起来,计算每个图的特征表示。
例如:
- 会根据 将节点特征 按照图来划分,计算每个图的节点特征的平均值,从而得到图级别的表示。
3. 参数的生成
在使用 PyTorch Geometric 的 时,每次加载一批图时会自动生成 参数。例如,代码中的 和 会将多个图放入一个批次,并自动生成 参数。
总结
参数的作用是标记每个节点属于哪个图,以便在批次处理中区分不同的图,特别是在使用聚合函数(如 )时,用于生成每个图的全局特征表示。
简而言之,batch就是把不同图的特征聚合分别聚合在不同图上,这样每个图都有自己的特征。
训练与测试代码
注意区分不同图的话增加batch参数
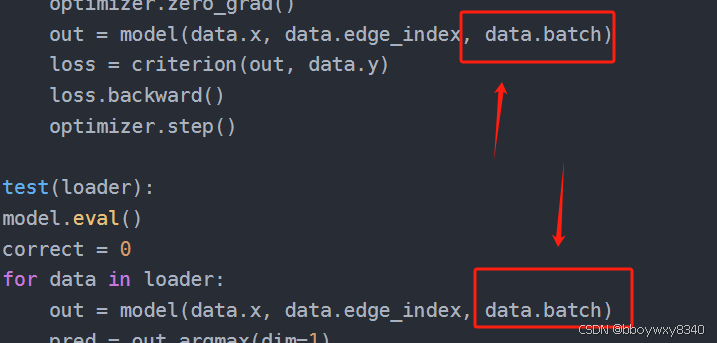
综合上面所有的内容,最重要的是以下两点:
①不同GNN的本质区别是他们的消息传递机制不同,如GCN/GraphSAGE/GIN/GAT等等,只需要修改层的名称即可,目前已经达到了高度的集成化,不需要进行手撸,除非你的研究需要。
②三种不同的任务,他们的本质区别就是:Output层的输入不一样。
●对于节点层面的任务而言
可以直接self.conv = GCNConv(16, dataset.num_classes) ————这是直接把任务融合到卷积层
也可以在卷积获取特征之后,后面加几个线性层
●对于边层面的任务而言
通过GNN提取出节点信息,输入Output层之前需要进行边特征的融合(在这里是Concat节点特征)
边特征融合之后再跟几个线性层
●对于图层面的任务而言
通过GNN提取出节点信息,输入Output层之前需要进行图特征的融合(在这里是对节点特征进行全局平均池化)
图特征融合之后再跟几个线性层
如果你认真看完上述所有内容,你已经初步掌握了GNN的概念和使用方法。若想进阶,请使用自己的Graph_data进行尝试。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/45621.html