
写着写着写跑题了…把对问题有帮助的部分我加了下划线…
虚拟化有很多等级的
全虚拟化
对普通人来说最常见的是全虚拟化。装个VirtualBox,你就可以在Windows上跑Linux了。这么跑,效率实在太低
半虚拟化
其次则是半虚拟化。对Windows下虚拟化不了解就不说了。
Linux下有很多半虚拟化方案,题主说的xen和kvm都是半虚拟化。
它的好处是,系统之间资源分配相对隔离(一台16G服务器,分给某个xen虚拟机8G,那么在domain0上看见的内存就只剩8G了),分配的资源相对来说不容易互相有影响,并且性能相对全虚拟化来说更高。
缺点则是,Linux内核必须要支持这种虚拟化技术。对xen来说,是citrix维护了一个xen的内核补丁,对kvm来说则是一个kernel module。另外,虽然性能损失不大(你可以理解为,一台100分的机器内存和CPU平均分给两台xen虚拟机,总分能到90分以上),毕竟还是两个不同的OS环境,总会有一部分overhead在里面的。
Container方案
不清楚这个算不算传统意义上的虚拟化了。
虚拟化的主要目的是提高单机的应用密度。也许某个应用设计时就没有考虑到多CPU高内存环境,不能充分利用CPU和内存(比如,某厂用的32bit的JVM,每个应用最多只能使用3G左右内存),那么我可以在一台机器上跑多个虚拟机,每个虚拟机内部跑一个应用,这样就能充分使用CPU和内存了。
但是传统虚拟化的思路是『完整虚拟出整个OS』,带来的overhead还是很大。这个时候各种container方案就出来了。
这些container方案的特点是,只有一个OS,但是有多个container。每个container可以跑ssh server,可以分配单独IP,可以配置单独主机名,可以有独立的文件系统(文件系统这部分,可以想象一下chroot)。当你ssh进去这样一个系统时,你可能看见了一个完整的进程树,有PID为0的进程,等等。但是在宿主机上,你的PID=0的进程可能实际PID是10010,整个进程树都进行了PID的映射,常见系统调用都做了hook,让你以为是在一个单独系统环境下。
上图是heroku这个网站的container环境,甚至都没有PID为0的进程,但是有完整的目录结构
常见的container方案有OpenVZ(是的,网上常见的所谓VPS,甚至不是一台虚拟机)和Linux内核内置的cgroup
1.首先有OS基础,随便操作系统书籍
2.对Linux kernel有全面了解,关键模块有理解(走读kernel源码,对流程有印象)。推荐书籍:深入Linux内核架构(+1)或者深入理解LINUX内核。
3.hypervisor虚拟化, Intel的《系统虚拟化》,很老很实用,看Qemu,KVM,Xen代码。
4.容器虚拟化,读cgroup,lxc,docker代码。
5.换一份虚拟化工作。
有个几个重要区别:
1. KVM内置于Linux,是内核模块;xen是Linux的一个应用。所以KVM可以直接利用Linux来做一些在xen中需要利用hypervisor来做的事情,比如任务调度,内存管理等等。所以相比之下,KVM更轻量,更易管理,并且版本更新也可以随着内核的更新。
2. 从架构中
KVM
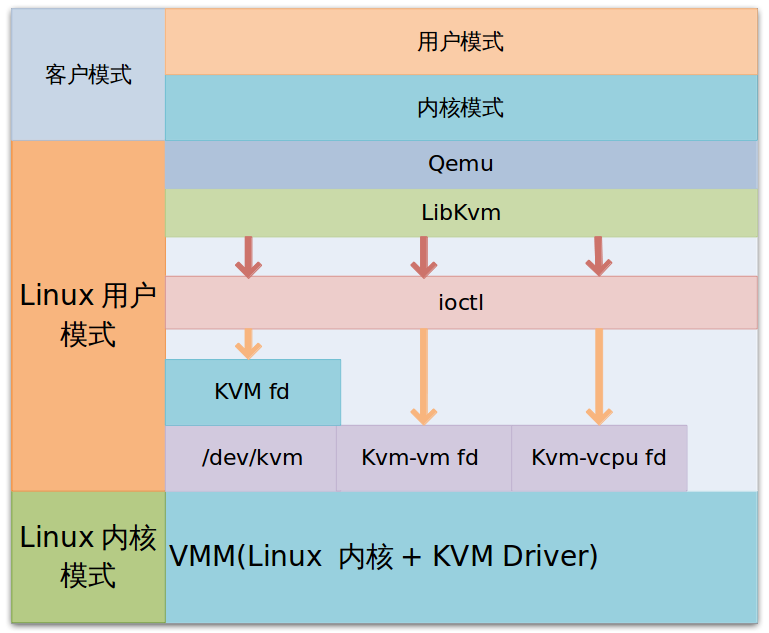
qemu通过libkvm应用程序接口,用fd通过ioctl向设备驱动来发送创建,运行虚机的命令。设备驱动kvm接下来解析命令。
虚机运行时,有三种模式:
-客户模式:执行非io的客户代码,虚机在这个模式下运行;
-用户模式:代表用户执行io操作,qemu运行在这个模式;
-内核模式:实现客户模式的切换,,kvm工作在这个模式。
XEN
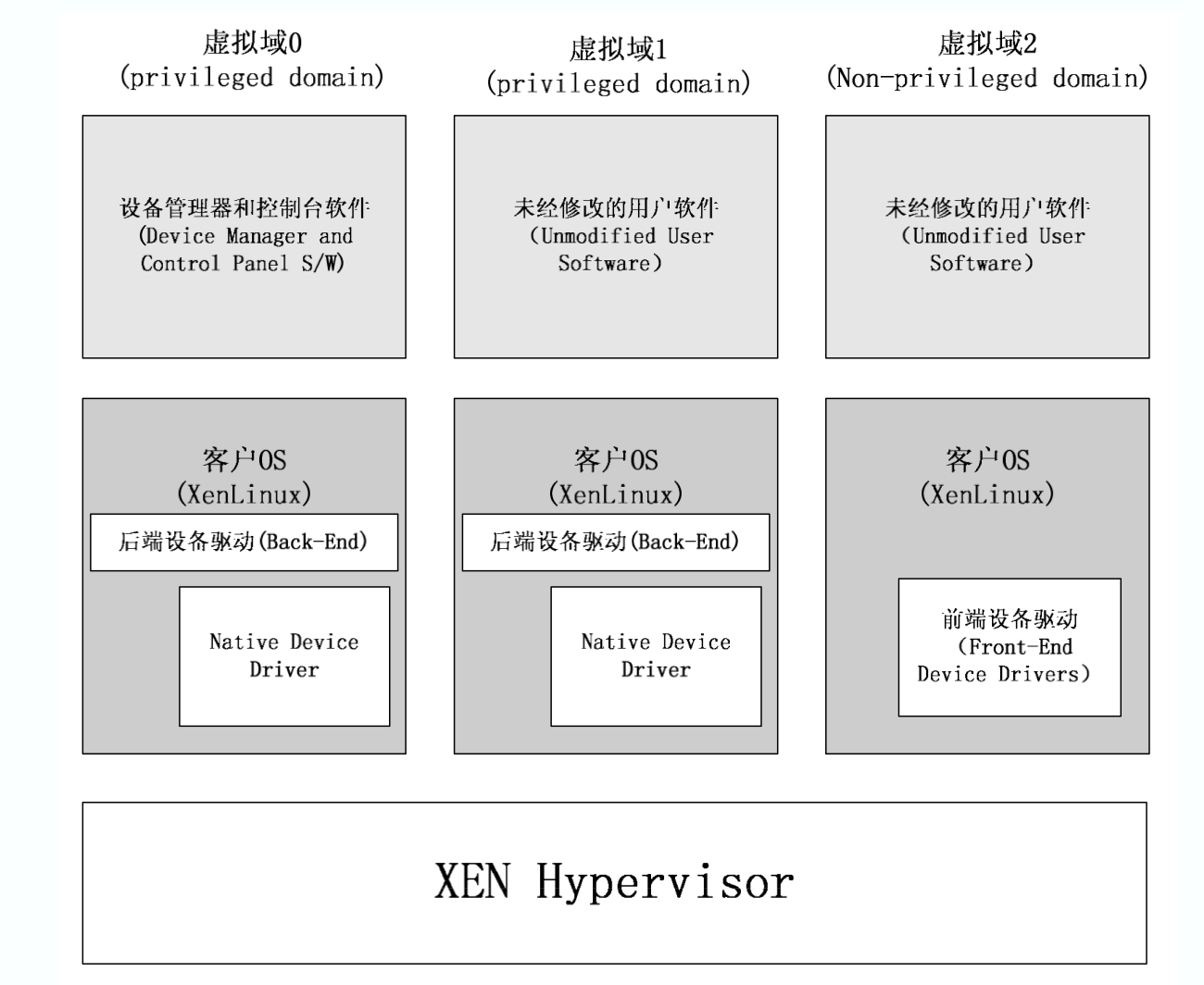
domain0做为对hypervisor的扩充,提供对整个平台的管理,直接拥有系统硬件输入输出设备。domain1是一个设备驱动域,拥有部分物理设备。从domain2开始,是普通的用户虚拟化域,不具有任何物理设备,而是通过虚拟设备向位于domain0的后端设备驱动程序申请服务,从而实现对设备的访问。
泻药,你算是问对人了,正好我两台电脑,其实不用KVM可以基本实现0延迟一套键盘鼠标控制的。废话一下,两台电脑的鼠标键盘可以相互操作哦,还支持相互COPY。是不是很完美。很心动?就不告诉你~哈哈哈
(悄悄告诉你,答案再后边。。。。。。。。。。↓)
开玩笑啦~
方法如下:
方法一、微软其实是有自己的软件支持这个功能的,只是用的人不多,所以知道的人不是很多。名字叫:Microsoft Garage Mouse without Borders 官网链接:Download Microsoft Garage Mouse without Borders from Official Microsoft Download Center 名字是不是很炫酷?无边界鼠标控制~支持两台电脑用其中一套控制,具体还有其他功能你自己探索。
方法二:这个也是一款很不错的跨电脑实现鼠标键盘互相控制的软件,两台电脑都装上之后,不用再过多配置,直接就能使用。可以实现的功能也比较多,软件默认两台台式机电脑是免费使用的,超过两台台式机,或者一台笔记本一台电脑都是要收费使用。并且不限制操作系统!!!可以MAC系统与windows系统跨电脑跨系统的使用,基本0延迟!!!我现在就用的这个软件,名字叫:ShareMouse 官网地址:Mouse and Keyboard Sharing for Mac and Windows 是不是很棒~~
以上方法都是免费的,还有一款收费软件,我也忘了名字了,但是这不重要,因为有上边两个就够了~
这几个概念,一个一个说吧。这里只是我自己的理解,不一定对。
首先要说的是题目隐含的一个概念:硬件虚拟化。硬件虚拟化主要来源于两个前提条件:
- 硬件性能过剩。这个就不详细解释了,消费级电脑的主流配置已经6核的今天,除了3A游戏以及例如视频制作、3D渲染、高性能计算之类的专业应用,大部分电脑的CPU性能闲置率超过90%。
- 业务需要多台主机——这个需求一部分来源于软件冲突,或者版本冲突;另一部分来源于需要不同的操作系统(如果把操作系统看做一个独立的软件,也可以归类为软件冲突)。服务器上的先不说,如果是做web前端的,现在好一点,以前经常要测试网页在不同版本的IE上是否能够正常浏览,然而一台电脑又只能装一个版本的IE,这就是软件版本冲突。
配备多台电脑固然是一个解决方案,但显然成本过高。因此就有硬件虚拟化的提出——用软件仿真一台电脑出来,在这台虚拟出来的电脑上安装操作系统,配置网络,安装运行软件等等。很多人听说过用过的VMware就这么一个软件。这个能够虚拟出一台或者多台电脑,并对这些虚拟机进行管理的软件,就是Hypervisor。
知道VMware的大部分人都听说过两个版本:一个是VMware Workstation,一个是VMware ESXi。这两个版本最大的区别,就是Workstation是运行在某个已有操作系统上的软件,例如Windows或者Linux,由操作系统实现对硬件资源的访问。而ESXi则本身就是一个操作系统,直接运行在硬件之上,省去了Host OS的开销。这就是两种不同的Hypervisor。
+-----+-----+-----+-----+-----+
|App A|App B|App C|App D|App E|
+-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+
|App A|App B|App C|App D|App E| |Guest|Guest|Guest|Guest|Guest|
+-----+-----+-----+-----+-----+ |OS A |OS B |OS C |OS D |OS E |
|Guest|Guest|Guest|Guest|Guest| +-----+-----+-----+-----+-----+
|OS A |OS B |OS C |OS D |OS E | | Hypervisor |
+-----+-----+-----+-----+-----+ +-----------------------------+
| Hypervisor | | Host OS |
+-----------------------------+ +-----------------------------+
| Hardware | | Hardware |
+-----------------------------+ +-----------------------------+
Type I Type ⅡESXi属于Type I,Workstation属于Type II。Windows自带的Hyper-V,Linux上的Xen也属于Type I,Virtual Box之类的属于Type II。
而Linux从2.6.20开始,就从内核支持虚拟化,可以理解为内核就是Hypervisor的一部分,配合Qemu实现完整的Hypervisor功能。所以叫“基于内核的虚拟机(英语:Kernel-based Virtual Machine,缩写为KVM)”[1],不过因为内核部分跟近似于Type I但又不是完整的Hypervisor,Qemu部分则更接近于Type II,所以在维基的Hyperviso词条的Talk页面中,不少人为KVM属于Type I还是Type II而激烈争论。
虚拟机有一个问题,就是虚拟机里面的操作系统本身会占用相当一部分资源。例如最新版的Windows 10,安装完毕什么都不干,就占用20~30G的硬盘空间,2~3G的内存。即使是只有字符终端没有图形界面的Linux,根据发行版和安装软件的不同,往往也需要100M~1G的内存,1~10G的硬盘空间。如果说同时运行2~3台还能接受这个开销的话,同时运行数十台,这个开销就不是少数了。事实上,往往这数十台虚拟机运行的都是相同的操作系统,只是根据业务需求的不同,安装的软件,或者软件版本不同而已。因此,业界提出了操作系统虚拟化(也叫容器,Containerization)的概念——所有的虚拟机使用同一个操作系统内核。容器和Type II的Hypervisor相比,最大的区别就是省去了客户机操作系统的开销,如下图:
+-----+-----+-----+-----+-----+
|App A|App B|App C|App D|App E|
+-----+-----+-----+-----+-----+
|Guest|Guest|Guest|Guest|Guest| +-----+-----+-----+-----+-----+
|OS A |OS B |OS C |OS D |OS E | |App A|App B|App C|App D|App E|
+-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+
| Hypervisor | | Container Engine |
+-----------------------------+ +-----------------------------+
| Host OS | | Host OS |
+-----------------------------+ +-----------------------------+
| Hardware | | Hardware |
+-----------------------------+ +-----------------------------+
Type II Hypervisor Containerization容器技术有很多种,最常见的就是题目所说的Docker,此外还有Linux的LXC、OpenVZ,FreeBSD的Jails,Solaris的Zones等等。值得一提的是各种Unix的chroot命令,也可以看做是一种特殊的容器。
当然,Docker除了实现容器以外,还有相关的一系列概念和组件,例如镜像、仓库等等,大大简化了应用的分发、部署等工作,这些是Docker得以流行的很重要的因素,但这里就不展开了。有兴趣再了解这方面的请参考我的另外一个回答:如何通俗解释Docker是什么?
我们知道,因为性能、安全、容错等等原因,有时候我们需要把若干台物理机组成一个集群来提供服务。同样的,虚拟机和容器也有这样的需求,而容器的集群管理,目前比较流行的就是Kubernetes(简称K8s)。K8s把一个或者多个实现某种业务的容器,组成一个Pod,然后对这些Pods进行监控和管理。
最后,微服务应该算是业务层面的。一般来说,每个完整的业务系统,都可以分为若干个组件,举例来说,我们做一个学校的选课系统,通常可以划分为课程管理、教师管理、学生管理、教室管理以及选课系统这几个耦合比较松散的组件。如果我们把每个组件作为一个独立的系统进行开发,并且对其它系统提供业务接口(服务),那么每个这样的独立系统,就是一个微服务。将来进行业务扩展的时候这些微服务就可以方便的得以复用,例如学生管理服务可以为学籍管理系统提供学生信息服务,教师管理服务可以向学校的OA、财务系统提供教职工信息服务,……,等等。另外,也可以根据业务的不同特点,或者开发小组/团队的技术实力,使用不同的开发技术、架构进行开发。
这些一个个的微服务,可能相当大部分只需要使用很少的硬件资源,但微服务的数量又很多,把一个微服务部署在一个或者多个容器的组合里面就最适合不过了。而每一个微服务,作为K8s的一个Pod,统一进行管理自然也是水到渠成的方案。
2018年6月,Intel当时的CEO Brian Krzanich发表过一个看法——“Intel的任务是阻止AMD在服务器领域获得15%到20%的share。”(https://www.nasdaq.com/articles/intels-ceo-just-validated-amd-data-center-processor-threat-2018-06-17)那时,AMD的服务器市场正处于持续了若干年的黑暗状态的尾端。在Opteron横空出世抢了一波市场之后,AMD在服务器CPU的领域近十年再无建树,似乎已经把这个市场拱手让给了Intel。
而让Intel真正开始正视这个对手,并且严肃对待对手威胁的,就是一年前AMD新推出的服务器CPU——EPYC(霄龙)。
2020年7月,AMD发表2020 Q2财报。现任AMD CEO Dr. Lisa Su表示:“AMD第二季度的表现非常强劲,EPYC(霄龙)的营业额比去年同期增加了超过一倍。”AMD的股票盘后大涨10%,是18年6月份的大约5倍。反观Intel,现在的股价甚至比18年6月份还稍微低一点。狼,真的来了。
帮助AMD啃下来这个Intel将近十年的后花园的,就是EPYC处理器。我们不妨来看看这个撬开服务器市场紧锁大门的CPU,到底是何方神圣。虽然AMD在服务器市场的复苏是从EPYC第一代开始的,但是真正进入高速增长阶段,还是在第二代EPYC(霄龙)推出之后,我们今天也把主要的目光放在第二代EPYC上。
第二代EPYC横空出世的时候,最大的名头莫过于——全世界第一款7nm的服务器CPU。而在当时,Intel还在14nm挤着牙膏。事实上,直到现在,Intel在10nm上依然有些挣扎。制程的重要性就不展开讲了,但是中国现在芯片行业自己就卡在制程上,当一块芯片里面由于制程的领先可以放下更多的晶体管的时候,自然性能和灵活度都会上去。
伴随着先进制程的,是AMD本就擅长的强大的跑分。AMD第二代 EPYC一出来就席卷了各种跑分榜,直至今日还拥有着100多项世界纪录(https://www.amd.com/zh-hans/processors/epyc-world-records)。19年8月的时候,ServeTheHome的主编Patrick Kennedy还用64核128线程的7742创造了新的Geekbench 4的世界纪录(https://www.servethehome.com/geekbench-4-2p-amd-epyc-7742-sets-world-record/)。这里说个关于Patrick Kennedy的趣闻,19年11月的时候,Intel发表了一篇文章说我家的CPU比AMD厉害很多,然后发了benchmark。结果这老哥发了个文章说你们这对比纯属胡扯(https://www.servethehome.com/intel-performance-strategy-team-publishing-intentionally-misleading-benchmarks/)。后来在和Intel的测试人员沟通之后,老哥撤回了他的一部分控诉(https://www.servethehome.com/update-to-the-intel-xeon-platinum-9282-gromacs-benchmarks-piece/),说Intel做的比自己想象的好一些,但是这个对比依然有很多问题,最多可以理解为“Intel在市场推广上做的努力”。简单来说,Intel拿了一个400W TDP的CPU,去和AMD 225W的CPU拼性能……
如果你是一个跑分控,关注geekbench的话,你会发现直到今天,geekbench的Multicore榜上依然是一水的EPYC……
曾经的AMD给人的印象是,专门做Intel不太做的领域,用性价比去攻低端市场,芯片设计也跟着老大哥走,但是EPYC的出现扭转了这种现象。EPYC在服务器CPU端已经开始引领设计了。
首先是之前提到的,第一个7nm的服务端CPU。不仅如此,5nm的Zen 4架构已经摆上台面了,起码在制程上,现在AMD已经是领跑者了。
其次,第二代EPYC率先支持了PCIe 4。和PCIe 3相比,PCIe 4的IO速度翻了个倍,一个lane大约可以到2GB/s的传输速度。而第二代EPYC有128个PCIe 4 lane……在个人电脑领域,我们普通用户对PCIe最常见的需求是插显卡,这几年也包括SSD,WiFi啥的,对这个IO速度的提升可能感受不那么明显。但是对于服务器CPU来说,这是一个潜力很大的点。在云计算这块,有一些是计算密集型的应用,有一些是IO密集型的应用,有很多应用和平时的个人应用是有去别的。举个简单的例子,重要数据的多机甚至多地备份,就需要大量的服务器之间的沟通。尽管现在来看,PCIe 4的重要性还没有那么明显,但是和5G一样,他的出现给了市场可能性,原来一些没法想象的东西现在可以试试了,原来一些知道做不了的东西或许就能做了。
还有一个我关注的EPYC特性就是内存加密,也就是SEV和SME。我们公司本身是做不少安全相关的内容的。在这个领域内,一般来说,当你的底层被攻破的时候,高层的防护都会变得没有价值。所以不管你在应用端的保护做的多好,如果你的OS有漏洞,那一切都白扯。而从2018年开始,安全专家们逐渐发现,硬件本身也可以有漏洞。于是从Meltdown和Spectre开始,各种硬件设计上的漏洞被发现,让OS级别的安全又变得不足够了。
在这之后,无论是Intel还是AMD,都开始在硬件保护上下功夫。Intel做了SGX(Software Guard Extensions),然后画了个饼叫TME(Total Memory Encryption)。而AMD这边已经拿出了SEV(Secure Encrypted Virtualization)和SME(Secure Memory Encryption)。从技术水平上说,SEV和SME可以说领先Intel的SGX很多,而Intel画的TME的大饼,实际上AMD已经做出来了,做的还比他好……
不得不说,在安全的攻守上,很难有大结局。无论是Intel还是AMD,都还没有,也不可能吹响最终胜利的号角。但是在处理器安全,尤其是内存的保护这个领域,Intel现在确实是一个追赶者。
第二代EPYC在性能和价格上的强势逼得Intel不得不应战,在2020年Intel拿出了Cascade Lake Refresh系列,去正面对抗EPYC。
这个系列很有意思,因为这个系列基本就是一个死要面子的降价大甩卖……
拿这个系列最高端的Gold 6258R举例,他和Cascade Lake系列的Platinum 8280几乎一模一样。感兴趣的小伙伴可以看一下对比(https://www.cpu-monkey.com/en/compare_cpu-intel_xeon_gold_6258r-1267-vs-intel_xeon_platinum_8280-1061),这俩CPU的相似程度让人不得不怀疑Intel是不是换了个标就把原来的CPU拿出来了……然而这款Gold 6258R卖多少钱呢?$4000,比参数几乎相同的Platinum 8280便宜了$6000,是的,Platunum 8280卖$10000……而Gold 6258R其实只比Platinum 8280晚出来半年而已。而同系列的其他CPU,基本也都可以找到自己在上个系列的亲戚,只不过发现自己的身价比他们低了好多。
也就是说,Intel为了不太丢面子,把之前标价$10000的CPU打个四折,就干脆推出了一个全新的系列,换汤不换药,然后定价对标AMD。Intel下这一步棋,也是通过增强性价比,希望自己服务器端的CPU可以重新占据市场竞争力,为自己争取时间。而这个应对,其实恰恰体现了当时EPYC的实力。
然而,疯狂降价的Refresh系列,在性价比上就超过EPYC了么?Phoronix做了一个很细致的benchmark,对Intel和AMD的共计20多种setup进行了比较。在比较之前,我们不妨先认识一下参赛选手们:
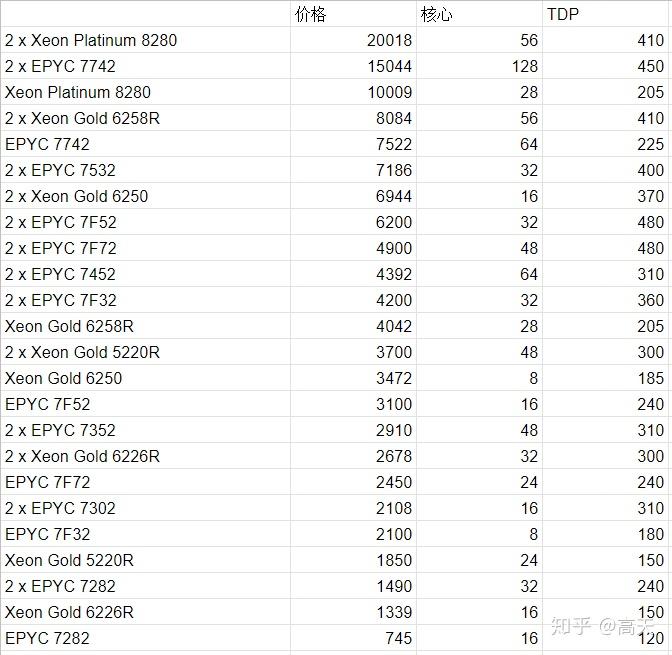
在这张表里,我们把所有的参赛选手按照价格排了个序。这里AMD的参赛选手多一些,Intel还派了几个老年选手(上一代的CPU)出战。公平起见,我们就不太关注老年组的战况了,基本被R字组的完爆。我们把目光主要集中在三个R身上,6258R,5220R和6226R。这也是Intel专门拿出来去和AMD打性价比的产品。在看benchmark的时候,我们除了关注一下跑分的绝对值,也要看这个分数对应的CPU价格和TDP。如果这三个全输了,或者输了两个,另一个差不多,那就可以叫被“完爆”了。
这篇文章跑的benchmark非常多,我们拿一些有代表性的来看。
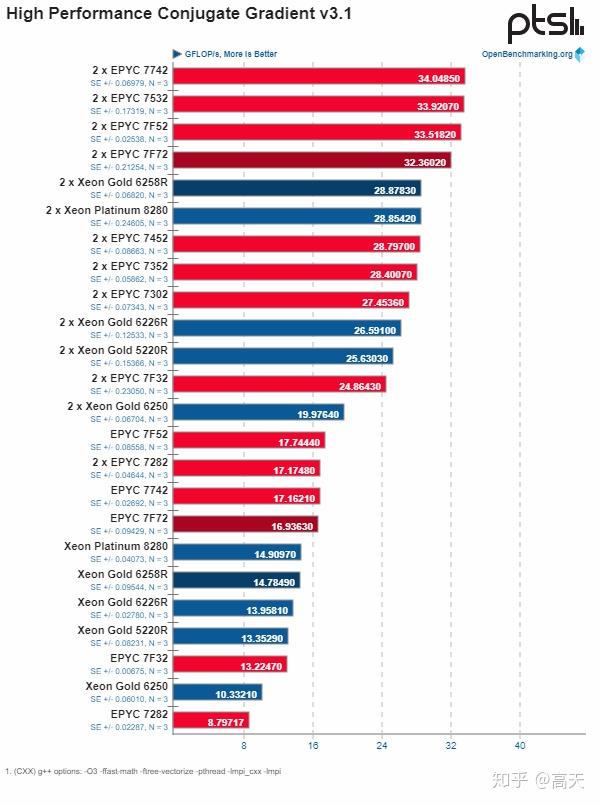
第一种是这个类型的图。从图上就可以看出来,这个benchmark AMD比较强。Intel的R系列最高端的产品6258R被价格低于自己的7532,7F52和7F72大幅度领先。7532甚至TDP也低于6258R。而7F52和7F72的价格都比6258R低20%以上。低端线的5220R也被TDP相近且价格更低7352和7302碾压。
这样的图在42个benchmark大约一共有20个。
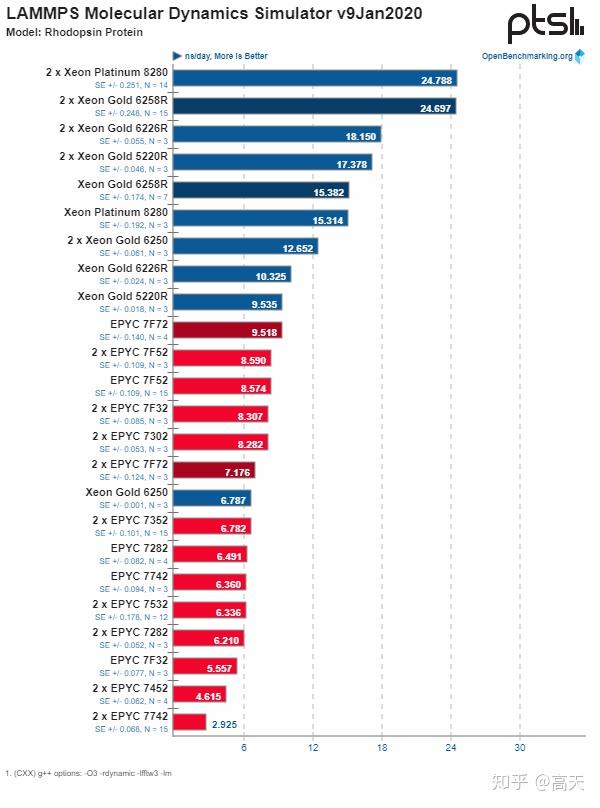
第二个类型就是这样的图,非常明确的Intel完胜,这样的图大约有7张,其中包括了一些Intel自己出的benchmark。
剩下的图就是大家差不多,基本和价格成正比(只看R系列,非R的性价比很低)。比较典型的大概是这样的:
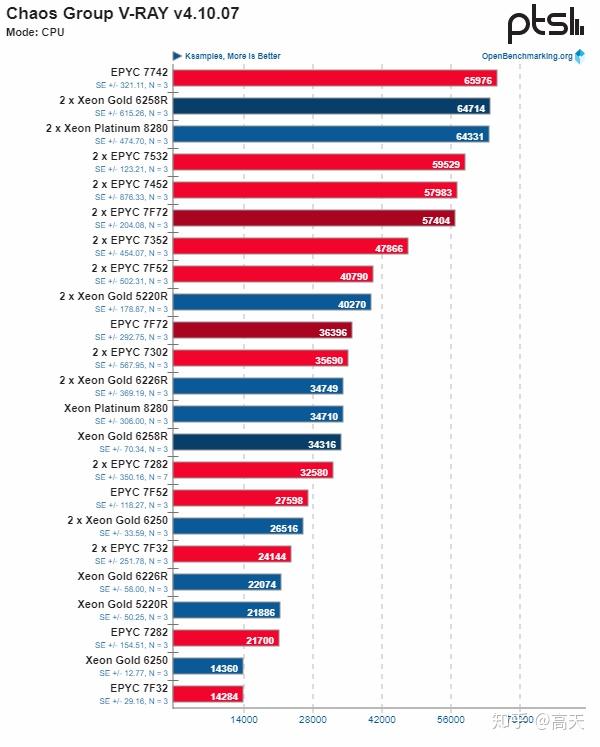
7742经常在跑分绝对值上很高,然后跟着6258R,接下来是一大堆AMD。这也算是个常见的类型。
从这个跑分结果可以看出来,Intel新出的这个R系列的CPU,最多最多算的上和AMD的EPYC系列各有千秋,在更多的领域里,其实是略逊一筹的。
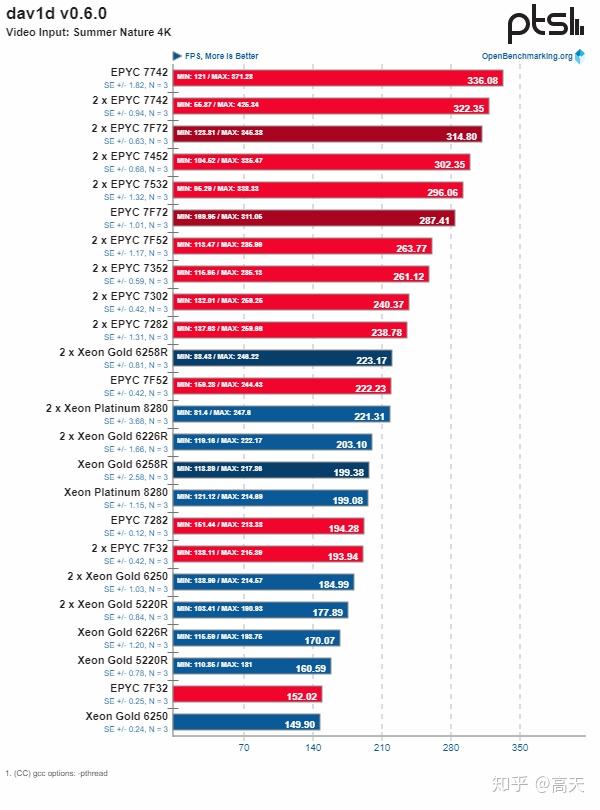
可即使是“各有千秋”,也是完全不够的。对于领先者来说,“各有千秋”是个很危险的事情。当你占据了市场的98%甚至99%的时候,如果你不能建立起用户壁垒(把x86独享),就必须要全面压制。如果你某些应用效果更好,某些应用效果更差,对于细分领域的用户来说,他们是一定会想尝试其他的更好的方案的。我们作为局外人看benchmark就是看个热闹,但是如果你是在某个领域需要买一个云平台,你一定是关注自己领域的benchmark的。假如你是一个做视频网站的,准备找一个云做解码,你看到下面这个benchmark,会去选什么呢?
当然了,除了所谓的用户壁垒之外,惯性也是一个不得不提的因素。每个人,每个行业都有惯性。所谓惯性无非就是,这东西一直用,没啥毛病,用习惯了,就接着用。但是这种巨大新兴市场的市场份额,可不能仅仅靠惯性撑着。曾经Intel一家独霸的云计算市场,现在已经被AMD撬出来一个口子了。
最先拥抱AMD的云服务商是微软Azure,从第一代EPYC出来的时候就开始合作。在第二代EPYC出现之后又新增了若干种VM。在Azure提供的VM列表(https://azure.microsoft.com/en-us/pricing/details/virtual-machines/series/)中可以看出来,EPYC还是出现了若干次的。从general purpose的D系列,到超算云平台的H系列,都有EPYC的身影。而Azure选择EPYC的理由绝不仅仅是性价比,在多个系列中,Azure都强调了EPYC多核多线程以及内存带宽的优势,这让EPYC在一些特殊方向的VM上有着出色的表现。
Azure不是唯一选用超多核高速内存的EPYC做超算云平台的云服务商,Oracle在2020年也推出了BM.Standard.E3.128,128核2TB内存的instance。额外提一句,Oracle的general VM里还有一个VM.Standard.E3.Flex,同样是用的EPYC 7742,提供1-64核,16-1024G内存的flexible VM……
Google Cloud今年7月份推出了一个挺有趣的VM,他们叫Confidential VM,面向数据敏感度很高的用户。而这个Confidential的底层核心,就是AMD的SEV技术。通过每个VM一个encryption key,把用户的数据加密在VM内部。在数据泄露越来越严重的今天,这或许是未来的趋势。
AWS作为业内最大的巨头,在商业决定上的惯性肯定也是最大的。不过在AWS上现在也有AMD based VM。而AWS宣传AMD based VM的方式也很直接——用AMD,省10%(https://aws.amazon.com/ec2/amd/)。和其他几家云服务商相比,AWS现在依然主要盯着的是EPYC的性价比,而非其绝对能力或者特别的feature。但是性价比本身也确实是AMD长久以来的优势,无论是在个人机CPU还是服务器CPU上。
国内这边,腾讯云在18年的时候推出了国内第一款AMD云,当时用的是EPYC第一代。在第二代EPYC发布之后,又就地更新了Sa2。而腾讯宣传的手段和AWS如出一辙——超高性价比。
可以看到,无论是国内还是国外,各大云服务商们都开始逐渐纳入AMD的产品,无论是看重EPYC的性价比,还是其核心数、内存带宽的优势,还是他在内存加密领域的领先。EPYC作为一个强大的产品,已经开始帮AMD蚕食云端市场了。在个人电脑的市场逐渐打开,甚至有和Intel平分天下趋势的情况下,服务器领域AMD又会战况如何呢?
放眼未来,还是不禁要为Intel捏把汗。在Intel用偷偷降价的R系列去正面对抗EPYC第二代的时候,EPYC第三代Milan预计在今年年底就要出现了。和第二代相比,性能上预计有10%到20%的提升。在Intel刚从10nm的泥潭脱身的时候,AMD已经剑指5nm,准备Zen 4了。AMD领先的每一步,都在给自己争取时间,创造机会,让云服务商和他们的用户有时间有机会有欲望尝试AMD的产品。而云服务商们,哪怕就是为了引入竞争,给Intel足够的压力,也会把一定的资源向AMD倾斜。会不会“真香”,就要看AMD的产品本身过硬不过硬了。
只是不知道,两年前那个许下15%到20%市场份额愿望的Brian Krzanich,现在是什么心情。
调研 KVM 下的 VCPU 调度算法(实际上就是 Linux 进程调度算法),与 Xen Credit 算法进行比较,分析两种调度的异同及各自的优缺点。
本文调研的是 Completely Fair Scheduler 算法, 它当前是 Linux 中 SCHED_NORMAL(非实时任务) 一类 task 的默认调度器.
实际上, 运行在 Guest OS 中的应用程序线程还受到 Guest OS 的调度, 分时运行在 vCPU 上, 但这不在本文调研范围内. 本文仅调研 vCPU 被如何调度到 pCPU 上.
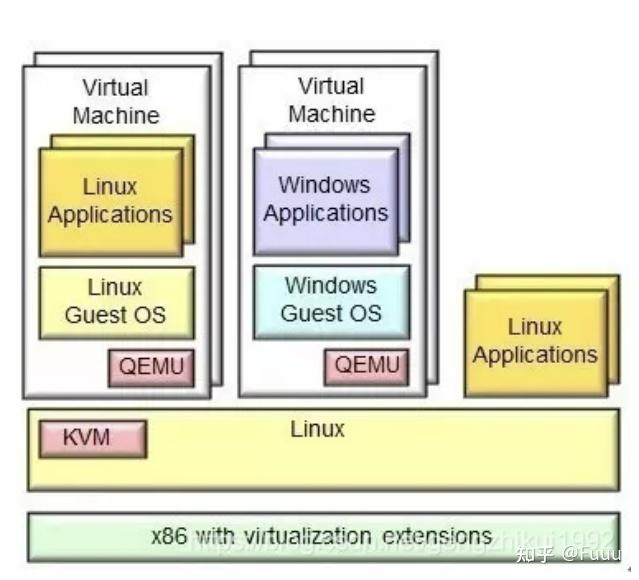
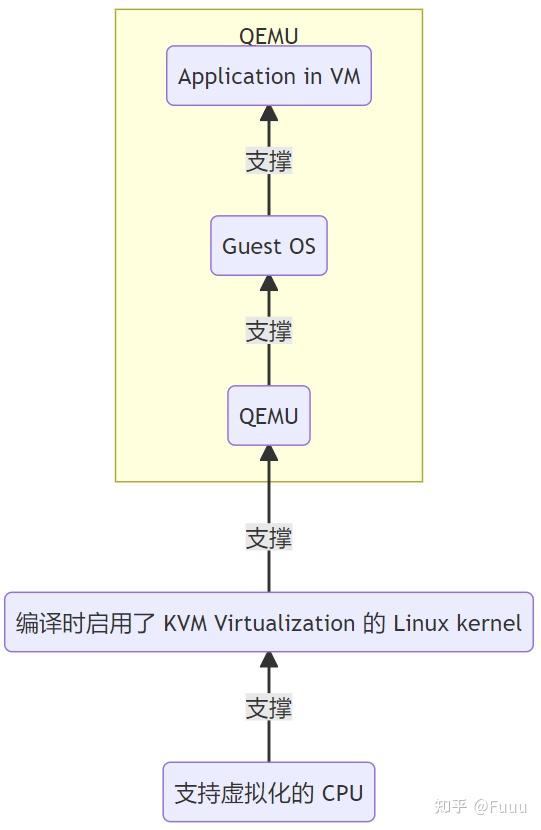
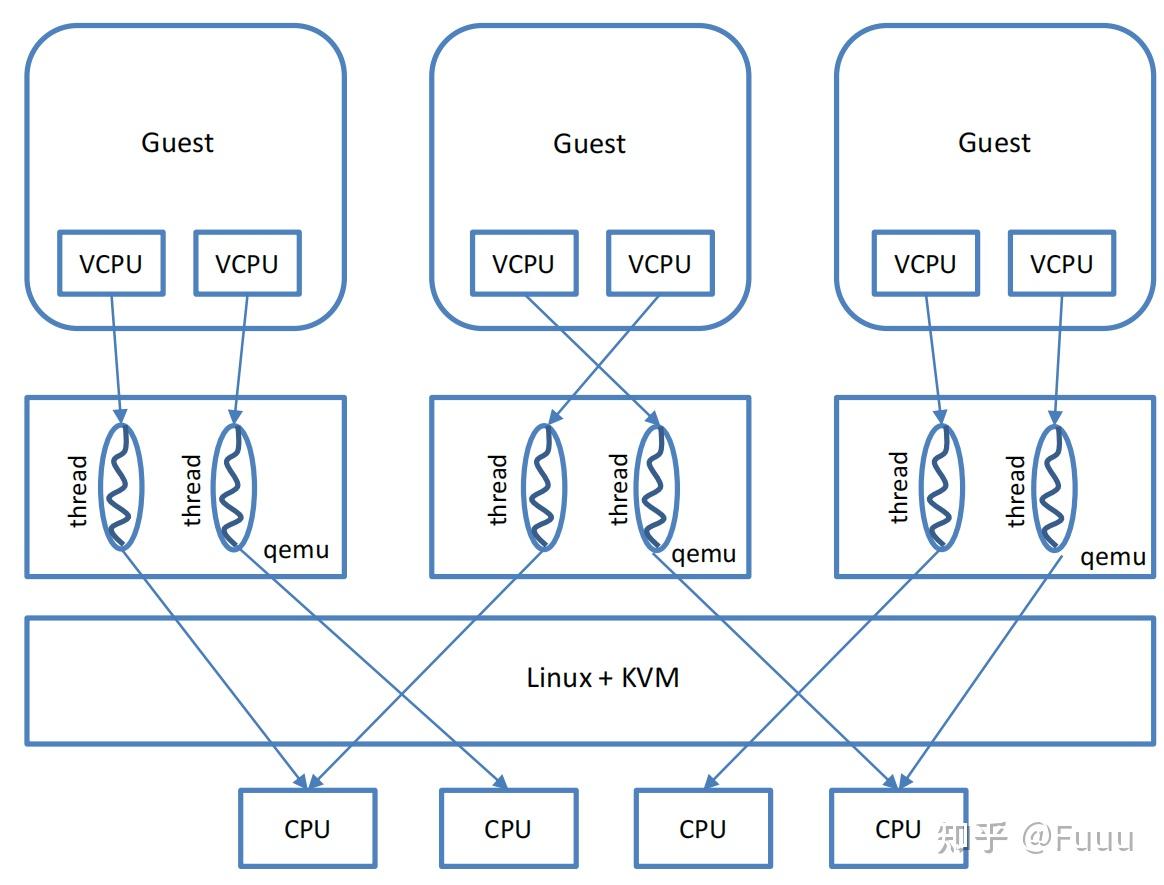
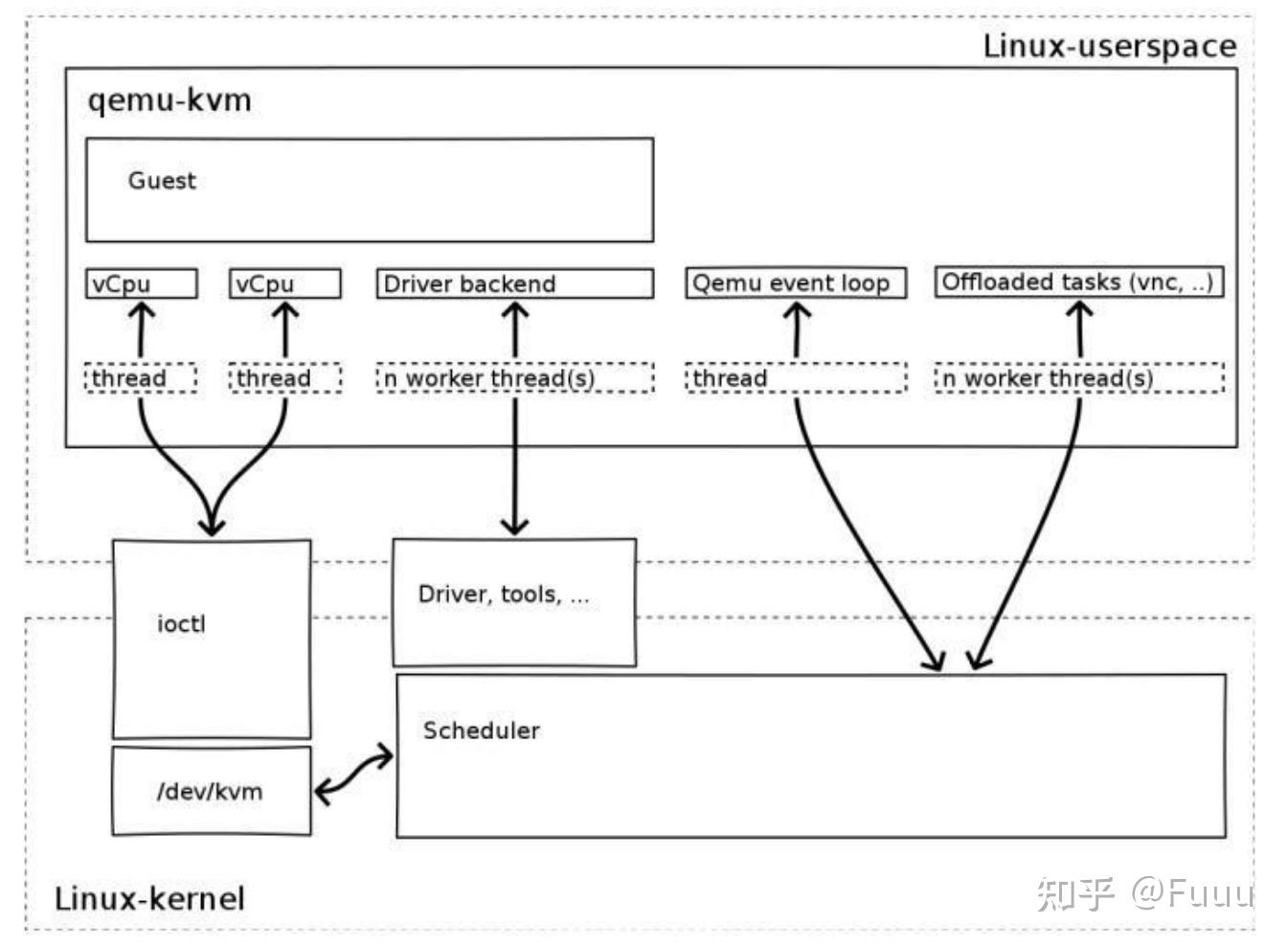
通常, 一个 QEMU 进程创建并服务于一个 VM. QEMU 为 VM 分配一个或多个 vCPU, 每个 vCPU 对应于 QEMU 进程内的一个线程.
所有 QEMU 的线程在 Linux 线程调度上与寻常线程无异, 由 CFS 调度器调度.
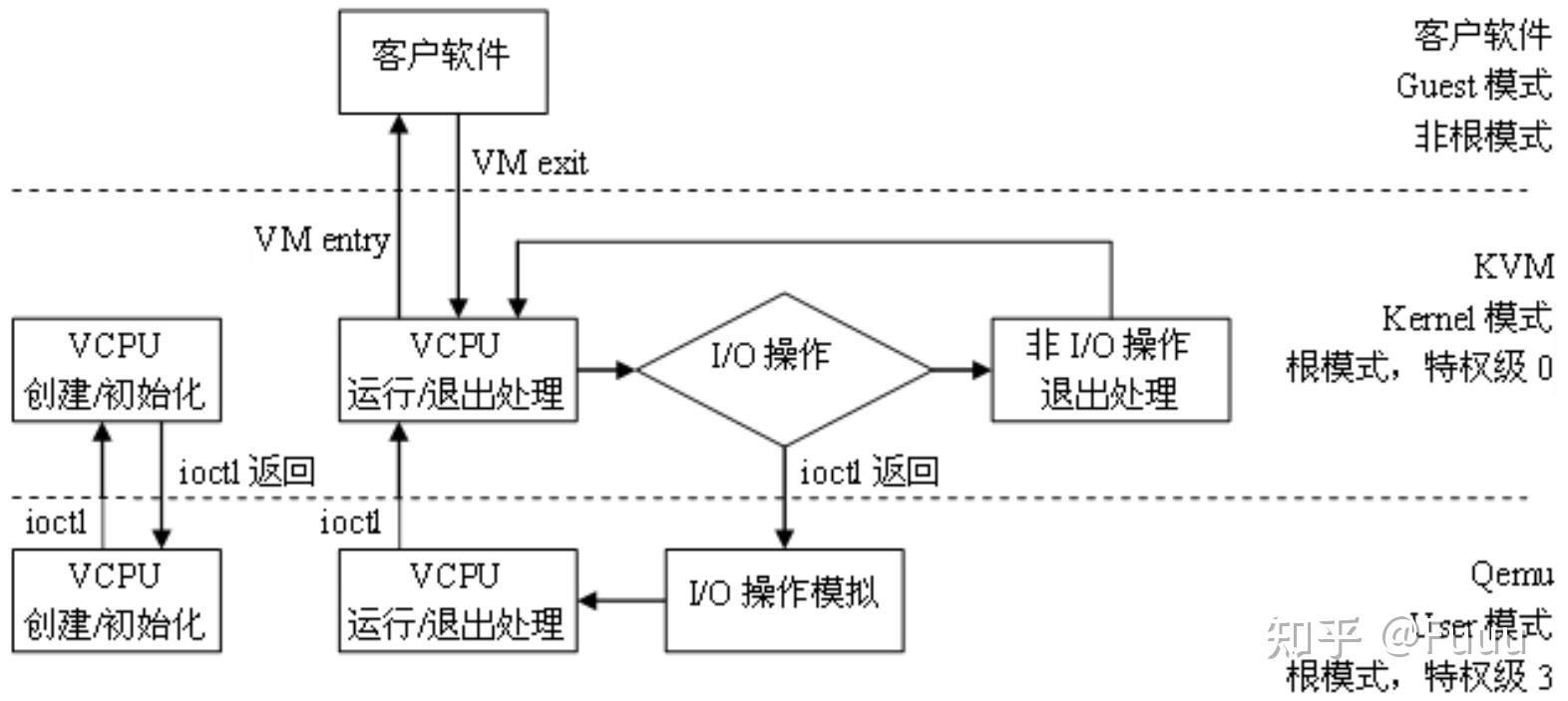
KVM 将自己注册为一个 misc 类的设备, 位于 /dev/kvm 上. 当一个 VM 被创建后, 运行在用户态的 QEMU 通过 ioctl 操作代表 VM, vCPU 的相关文件, 实现与 KVM 通信.
当 QEMU 启动/恢复运行一个 VM 时, pCPU 因 QEMU 发起的系统调用, 由用户态陷入到内核态, 再经由 KVM 调用 VM Entry, 进入到 non-root 模式, 恢复 vCPU 的运行.
(本文参考的 Linux 内核版本为 5.17 )
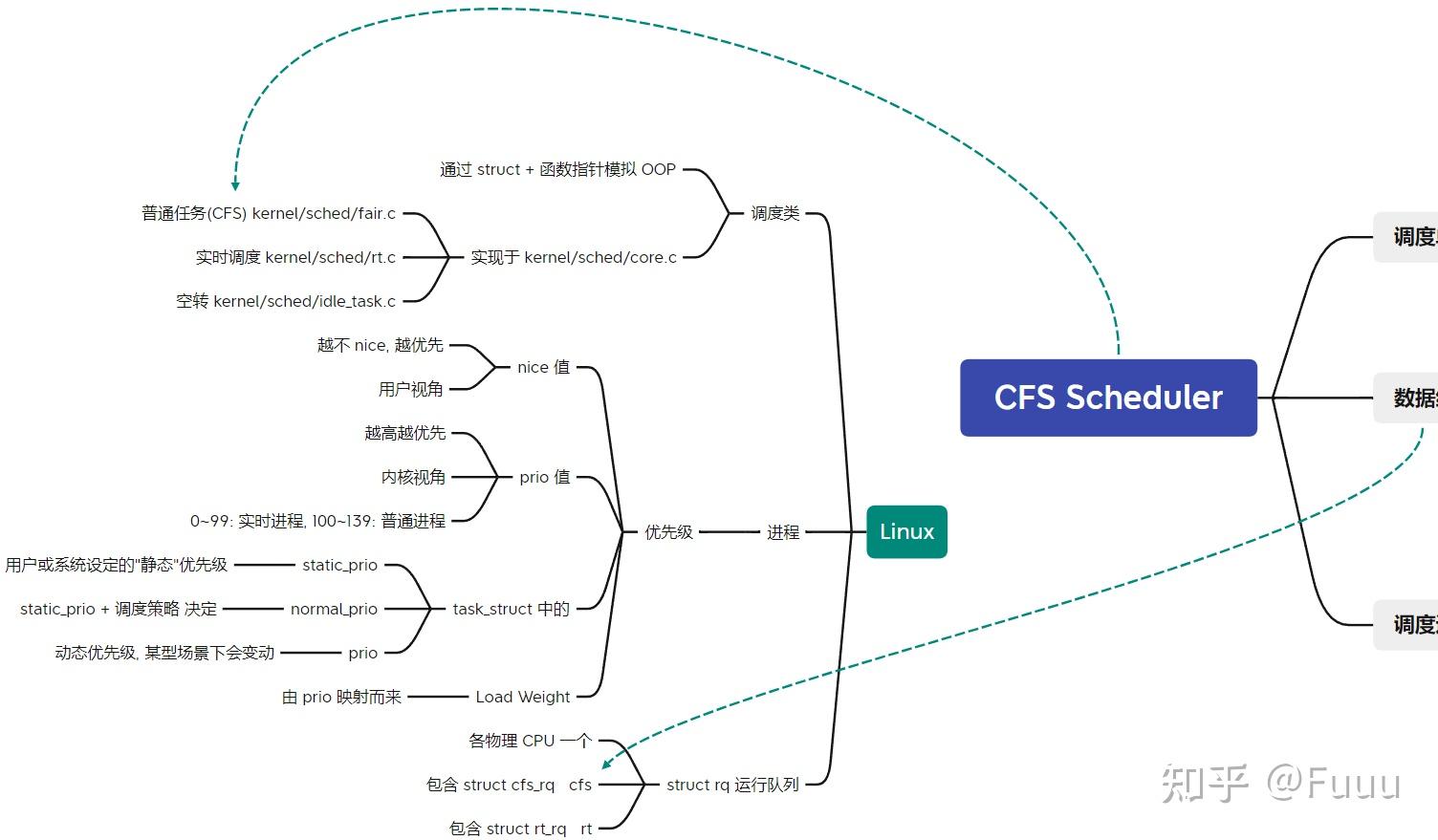
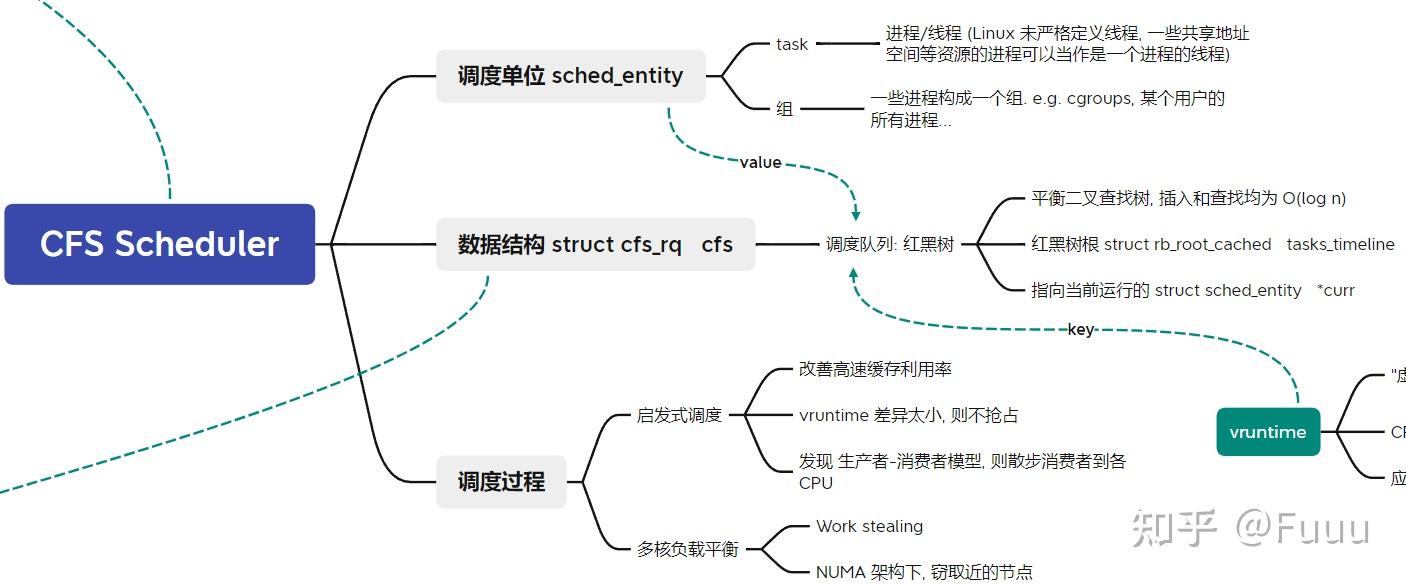

调度周期: 当运行的线程数 ≤ 8 时, 默认的调度时间周期是 48ms. 当多于 8 个线程时, 时间周期 = 6ms * 线程数. CFS 尝试在一个调度周期内运行所有的 task, 防止饥饿.
进程创建时: 若没有设置子进程先运行, 则一般子进程的 vruntime = 父进程的 vruntime + 等价于一个周期的 vruntime 值.
进程唤醒时: vruntime 值会被更新为 ≥ 所有待调度线程中最小的 vruntime. 使用最小 vruntime 还可以保证频繁睡眠的线程优先被调度, 这对于桌面操作系统非常适合, 可减少交互应用的响应延迟.
调度进程时: 将当前进程加入红黑树, 从红黑树摘下最左的节点, 作为下个进程来运行. 过程中有许多规则和特例.
时钟周期中断: 更新当前进程的 vruntime 和实际运行时间. 若超过了调度周期分配的实际运行时间, 会执行 resched_task(*rq). 在单核 CPU 中, 即为设置 CPU need_resched flag; 在 SMP 上需要触发目标 CPU 上的调度器.
虚拟时钟的时间流速:
static inline u64 calc_delta_fair(u64 delta /* 线程真实运行的时间片长 */, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
// NICE_0_LOAD = 1024
// 大致上 = delta_exec * NICE_0_LOAD / cur->load.weight;
// 也就是说, 对于 nice = 0 的进程, vruntime 与真实时间流速一致
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}- 计算所云计算课程 PPT - Ch 2.2
- 韦师兄 PPT 《KVM 虚拟化》
- Linux 5.17
- https://www.kernel.org/doc/html/latest/scheduler/sched-design-CFS.html
- https://developer.ibm.com/tutorials/l-completely-fair-scheduler/
- https://z.itpub.net/article/detail/4D5A28D92B6F801DF6E4C7F793969996
- https://blog.csdn.net/XD_hebuters/article/details/79623130
- https://www.cnblogs.com/tianguiyu/articles/6091378.html
- https://www.daimajiaoliu.com/daima/60fed6172434c00
- https://blog.csdn.net/liuxiaowu19911121/article/details/47070111
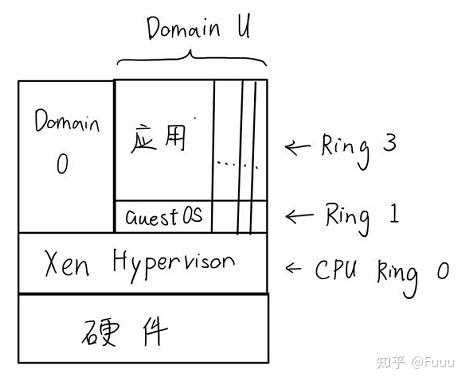
Xen:
- 一个 VM 被称作 Domain
- 隔离不同的 Domain, 为它们提供虚拟化的硬件资源
Domain 0:
- 特殊, 有特权
- 管理其他 Domain
vCPU:
- 每个 VM 拥有一个或多个
- 状态:
- 运行中
- 可运行
- 阻塞 (VM 自己阻塞的)
- 阻塞 (VCPU 睡眠 或 被 VMM 暂停)
(注: Credit 2 算法是 2009 年 George Dunlap 对原算法的一个改进, 包含在 Xen 中, 但默认未启用. 本文调研的是原算法. )
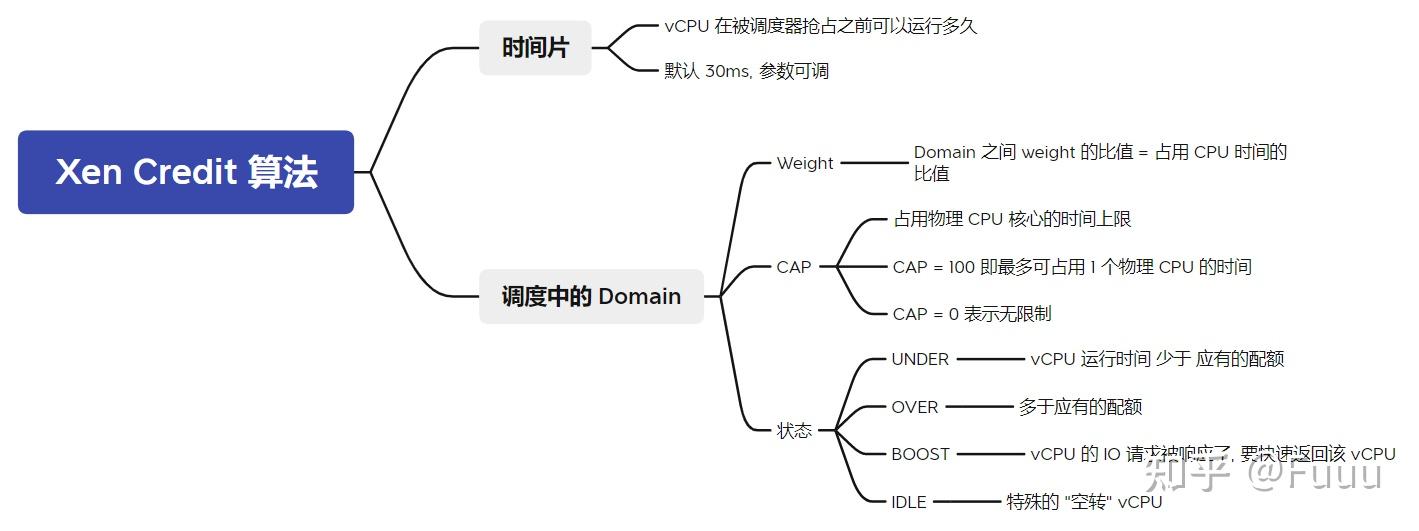
Credit 算法代码实现于 xen/common/sched/credit.c.
(本文参考的 Xen 版本为 4.16, 此时最新的 commit 为 0e03ff97def12b121b5313094a76e5db7bb5c93c)
核心数据结构
// 优先级, 枚举值
#define CSCHED_PRI_TS_BOOST 0 /* time-share waking up */
#define CSCHED_PRI_TS_UNDER -1 /* time-share w/ credits */
#define CSCHED_PRI_TS_OVER -2 /* time-share w/o credits */
#define CSCHED_PRI_IDLE -64 /* idle */
struct csched_dom { // 意为 C scheduled domain
struct domain *dom; // 原 Domain 指针
// dom->sched_priv 指回本 struct
// 它们互相指向
// 附加的数据字段
// ...
uint16_t weight; // Weight
uint16_t cap; // CAP
};
struct csched_unit { // vCPU 结构
// ...
int pri; // 优先级
atomic_t credit; // 当前的 credit
};
struct csched_private { // 系统范围内所有 vCPU
// ...
struct list_head active_sdom; // 所有活跃的 csched_dom, 是循环链表的表头
uint32_t weight;
uint32_t credit;
int credit_balance;
};vCPU 调度的核心过程
初始化时, 设置两个计时器:
- `csched_acct`, 每隔 30ms 执行一次 (全局唯一一个, 所在的物理 CPU 称作 the accounting master)
- `csched_tick`, 每隔 10ms 执行一次 (每个物理 CPU 分别设置了一个, 可能并行执行)// 对每个物理 CPU 初始化
static void init_pdata(struct csched_private *prv, struct csched_pcpu *spc, int cpu)
{
// ...
prv->ncpus++;
// ...
if ( prv->ncpus == 1 ) // 第一个 CPU 作为 the accounting master
{
prv->master = cpu; // 标记为 master
// 设置计时器, 执行 csched_acct
init_timer(&prv->master_ticker, csched_acct, prv, cpu);
set_timer(&prv->master_ticker, NOW() + prv->tslice);
}
// ...
// 设置计时器, 执行 csched_tick
init_timer(&spc->ticker, csched_tick, (void *)(unsigned long)cpu, cpu);
set_timer(&spc->ticker, NOW() + MICROSECS(prv->tick_period_us) );
// ...
}
// 各个物理 CPU 每 10ms 运行一次
static void cf_check csched_tick(void *_cpu)
{
// ...
if ( !is_idle_unit(current->sched_unit) ) // 若当前 vCPU 不是 "空转 vCPU"
csched_unit_acct(prv, cpu); // 执行 "vCPU 审计"
csched_runq_sort(prv, cpu); // 对 run queue(就绪队列) 排序
// ...
}
// 所谓的 vCPU 审计
static void csched_unit_acct(struct csched_private *prv, unsigned int cpu)
{
// ...
if ( svc->pri == CSCHED_PRI_TS_BOOST ) // 若上次醒来特权级是 BOOST
{
svc->pri = CSCHED_PRI_TS_UNDER; // 降级为 UNDER
// ...
}
// 该 vCPU 的 credit 被消耗了 100
burn_credits(svc, NOW());
if ( list_empty(&svc->active_unit_elem) )
{
// 若当前 active vCPU 链表为空, 说明所有 vCPU 的 credit 都为负, 则重新计算credit值
__csched_unit_acct_start(prv, svc);
}
else
{
// ...
// 一些迷惑操作, 不明白作用
if ( new_cpu != cpu )
{
// ...
// 总之发起了一个 CPU 软中断, 将执行 schedule()
// 软中断在 xen/common/sched/core.c: scheduler_enable() 注册
// 本物理 CPU 可能将切换到其他 vCPU
cpu_raise_softirq(cpu, SCHEDULE_SOFTIRQ);
}
}
}
// 在 the accounting master 上, 每 30ms 执行一次
static void csched_acct(void* dummy)
{
struct csched_private *prv = dummy;
// 声明变量...
// 遍历当前活跃的调度中的 Domain 循环链表
list_for_each_safe( iter_sdom, next_sdom, &prv->active_sdom )
{
sdom = list_entry(iter_sdom, struct csched_dom, active_sdom_elem);
// sdom 是刚刚被调度器抢占的那个 Domain 的 csched_dom 结构
// ...
// ...
// ...
// 计算了 weight_left, credit_peak, credit_cap, credit_fair
// credit_peak: 若 Domain 的所有 vCPU 各自独占一个物理 CPU 时, 等价的 credit 值
// credit_cap : 根据 CAP 计算, Domain 能获得的 credit 上限
// credit_fair: 根据 weight 计算, Domain 能获得的 credit
if ( credit_fair < credit_peak )
{
credit_xtra = 1;
}
else
{
// 出大问题, 调整一些东西...
}
// 最后使用 credit_fair 作为 Domain 当前的 credit
// 现在把 credit 除以 Domain 拥有的 vCPU 数量
credit_fair = ( credit_fair + ( sdom->active_unit_count - 1 )
) / sdom->active_unit_count;
// 遍历 Domain 的 vCPU 循环链表
list_for_each_safe( iter_unit, next_unit, &sdom->active_unit )
{
svc = list_entry(iter_unit, struct csched_unit, active_unit_elem);
// svc 表示一个 vCPU
// 原子地 += 和 read vCPU 的 credit
atomic_add(credit_fair, &svc->credit);
credit = atomic_read(&svc->credit);
if ( credit < 0 )
{
// 超出 credit 配额了, 优先级降到 OVER
svc->pri = CSCHED_PRI_TS_OVER;
// 若超出 CAP, 直接靠边停车 (park) ...
// 若 credit 小于了下界, 置为下界 ...
}
else
{
// 超出 credit 配额了, 优先级降到 OVER
svc->pri = CSCHED_PRI_TS_UNDER;
// vCPU 可能此时因为曾超过 cap 而暂停, 现在 credit > 0, 再次启动...
// 若 credit 超过了上界, 直接除以 2, 而且停止继续获得 credit...
}
//...
}
}
// ...
}(纸上谈兵一下, 欢迎批评指正)
综合来看, CFS 调度器的成熟程度比 Xen Credit 算法高很多, 兼顾了更多的设计目标 (也多设置了一大堆编译开关 ). 这可能与 Linux 在服务器、嵌入式设备、大型机和超级计算机不同领域多样化的生态有一定关联.
Credit 算法的调度主要基于 Weight 和 CAP 实现的三级 vCPU 队列. CFS 算法则基于以 vruntime 为 key 的进程红黑树实现.
一般认为, CFS 能提供很好的公平性和可交互性. Xen 不清楚...
W. Jiang et al., "CFS Optimizations to KVM Threads on Multi-Core Environment," 2009 15th International Conference on Parallel and Distributed Systems, 2009, pp. 348-354, doi: 10.1109/ICPADS.2009.83.
这篇 2009 年的文章指出, 若在 VM 中运行多线程程序时 (多线程运行在多个 vCPU 上), 当年的 CFS 调度器性能会变得较差. 这是由于 KVM 线程优先级和 vCPU 线程在 pCPU 上的分配机制不够智能导致的, 以及 KVM 缺乏对 VM 中的自旋锁信息的了解.
不过这些问题都已经被改进了...
它们均对 SMP 有较好的支持.
Credit 算法的 trick 是引入 boost 级别. 但一个 vCPU 进入 BOOST 级别后, pCPU 在 10ms 内不会再被抢占, 这可能会使某些 UI 桌面程序或高实时性程序的响应变得迟缓. 而且, boost 级的 vCPU 是随机分布在系统中, 在不同 CPU 上的分布不一定均匀.
另外, 据官网文档承认, Xen Credit 对于 "重的" 工作负载, 性能很高; 但对于需要低延迟的应用 (e.g. 互联网应用, 音频 ...), 性能不好, 可通过减小时间片大小改善.
CFS 取消了多级队列的概念, 且启用了更细粒度的调度时间片, 相对实时性较好一些.
我在基于archlinux桌面系统上使用过virtualbox和kvm,感觉二者优缺点是刚好是相反的:
virtualbox易用性很强,基本上就是windows上的操作体验,不愧是大公司的产品,而且3D性能也很好,最新版甚至实现了dx11 over vulkan(dxvk)的渲染加速,图形界面很流畅。但是它虚拟化的操作系统稳定性不太好,我时常会遇到莫名的卡顿甚至闪退。
KVM虚拟出来的系统非常稳定,运行任何程序从来没有过卡顿闪退的情况,而且在virtio驱动的加持下io性能基本能达到裸机的水平。但是它的3D加速很差,即便是virtio-gpu驱动也不行,qxl驱动在win10下还算可以,日常办公用像office、微信、qq、写论文、上网这些流畅度还不错,但游戏的话还是算了。主要在于开源社区对KVM的3D加速实现还是基于opengl这个低性能、老旧的api上,而隔壁vmware早就实现了基于vulkan的图形加速了。易用性的话如果配合virt-manager图形操作界面还是挺好配置的。
我开虚拟机主要是在linux下多开win10办公用,在sway平铺式窗口管理器加持下在各个窗口之间快速切换。我个人选择KVM,因为相比于流畅的3D性能我更看重系统的稳定性,毕竟才开没多久的虚拟机时不时就崩掉真是非常烦人的体验。
linux开发出KVM真是极好的决定,通过跑windows虚拟机可以极大的弥补linux软件生态不足的问题,尤其是对桌面系统而言。
我写了一个小项目桃花源(英文名为 peach),该项目是一个迷你虚拟机,用于学习 Intel 硬件虚拟化技术。学习该项目可使读者对 CPU 虚拟化、内存虚拟化技术有个感性、直观的认识,为学习 KVM 打下坚实的基础。peach 实现了如下功能:
- 使用Intel VT-x技术实现CPU虚拟化
- 使用EPT技术实现内存虚拟化
- 支持虚拟x86实模式运行环境
- 支持虚拟CPUID指令
- 支持虚拟HLT指令,Guest利用HLT指令关机
代码仓库如下:
https://github.com/pandengyang/peach.git之前买的host1plus的vps做代理服务器,最近突然不能代理google了,加上之前google搜索老出验证码,于是就买了个新的vps。 之前用kcp加速,效果还不错,想着要体验下 linux kernel 4.9 里新的 tcp 拥塞控制算法,于是买了个便宜的KVM的vps,记录下操作步骤,免得哪天重装系统又忘了。
机器默认安装的是 ubuntu 14.04 kernel 是3.10的,挂ss代理youtube速度在400k/s左右。
首先安装4.9的内核,ubuntu已经为我们编译好了。
cd /tmp/
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.9/linux-headers-4.9.0-040900_4.9.0-040900.201612111631_all.deb
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.9/linux-headers-4.9.0-040900-generic_4.9.0-040900.201612111631_amd64.deb
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.9/linux-image-4.9.0-040900-generic_4.9.0-040900.201612111631_amd64.deb
sudo dpkg -i *.deb
完成之后
dpkg -l | grep linux-image可以看到新装的内核。
我这里安装完内核,并没有自动更新grub引导。手动修改grub启动配置位于 /boot/grub/grub.conf
加入:
title linux-image-4.9.0-040900-generic
root (hd0,0)
kernel /boot/vmlinuz-4.9.0-040900-generic root=LABEL=root ro
initrd /boot/initrd.img-4.9.0-040900-generic原来的3.10内核我还是保留了,免得启动出问题。我这里可以vnc连接,选择启动的内核。
之后 reboot,查看内核版本已经升到4.9了。
~# uname -r
4.9.0-040900-generic升级到4.9之后就可以开启bbr算法了。
echo "net.core.default_qdisc=fq" >> /etc/sysctl.conf
echo "net.ipv4.tcp_congestion_control=bbr" >> /etc/sysctl.conf
sysctl -p
sysctl net.ipv4.tcp_available_congestion_control
开启bbr算法后,我这里看YouTube视频可以达到900k/s,提升显著。
Xen Project,曾经作为唯一的开源虚拟化项目,一直活跃了10几年,但是随着可能是最大的Xen使用者AWS正式宣布下一代C5实例将使用KVM, 这基本也算是正式宣布了Xen的正式落幕,其实,国内的阿里云,华为云,作为比较早的云服务提供商,也都大量的使用了Xen, 大概在3,4年前,大家就纷纷开始动手将Xen替换成KVM, 目前在国内,它们新的云服务器都已经是KVM虚拟化了,AWS的历史包袱更大,要彻底完成Xen向KVM的替换,估计还需要很长一段时间。
我记得大概是从Citrix收购Xen不久,RedHat就正式宣布放弃Xen采用KVM,随后, Intel也全面支持 KVM,很多新技术比如著名的DPDK根本就不支持Xen。即使抛开复杂的商业生态,简单的从技术上看,Xen的架构在Intel推出vt硬件虚拟化技术后,确实显得非常复杂,主要表现在以下两点:
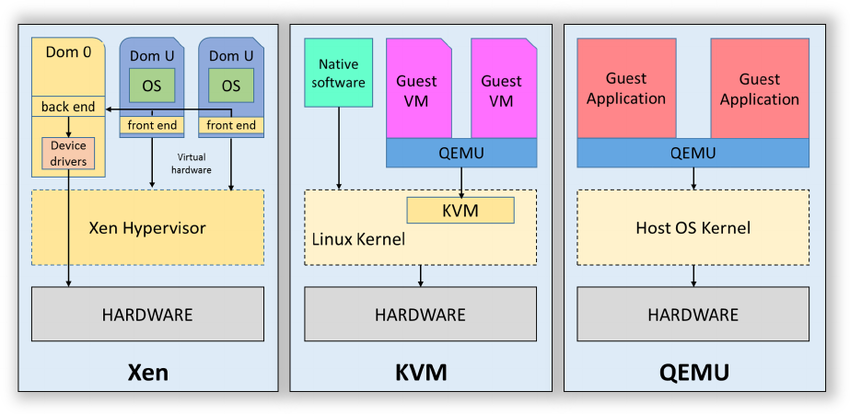
Domain0: 这是Xen在初期引入的一个特权Dom,Xen Hypervisor在收到IO请求后,需要先把请求投递到Domain0,完成调度处理后,通过grant copy或者grant map转发到对应的虚拟机,相比KVM, 整个IO处理路径几乎被拉长了一倍。其次, x86_64的ring模型相比早期的x86_32也发生了较大变换,从而导致ring压缩,进一步恶化了中断处理的性能。
必须重复造轮子: 最新10年来,CPU已经从单核逐步走向了双核,四核,甚至是几十核心,NUMA技术,TB级内存也基本成为现代服务器的标配,众多厂商和Linux社区在内存和CPU调度和管理上做了大量的工作,而Xen Hypervisor采用独立的CPU和内存调度管理,核心实现还停留在Linux 2.4时代,经过了10年的发展后,根本无力去同步这么多的更新,我们今天会发现,Xen已经落后的太多了,比如:
- hugepage:Xen只能提供2M物理页面,而DPDK需要1G的连续物理内存,这是DPDK不能支持Xen的最主要原因。
- KSM:透明页面共享。
- 多核(>128 CPU)调度: 虽然宣称能支持最大192+ core, 但是实际我们发现如果在128 core的4P服务器上创建大规格虚拟机并在其中使用高精度时钟,导致虚拟机频繁陷入陷出调度cpu,Xen就会出现严重问题,这显然是Xen没有经过大规模商业实践的表现。
对于Citrix这样以传统Windows桌面为主要业务的公司,这些高IO,高吞吐,大规格的场景其实并不是他们关心的技术方向。相比之下,VMware也有类似的技术问题,但是在2008年左右,VMware就果断的放弃了基于Domain 0架构的ESX, 转向ESXi。
我们再来看看数据中心的情况,AWS这一代的C5已经进入25GE核心交换时代了,Xen其实在处理10GE转发的时候就已经惨不忍睹,而且更重要的是,没有进一步的技术优化空间,Xen社区其实10年前就知道相关问题了,一直都在做些不痛不痒的优化,不去从根本上解决问题,一手好牌在手,最终却出局了。。。
首先KVM(Kernel Virtual Machine)是Linux的一个内核驱动模块,它能够让Linux主机成为一个Hypervisor(虚拟机监控器)。在支持VMX(Virtual Machine Extension)功能的x86处理器中,Linux在原有的用户模式和内核模式中新增加了客户模式,并且客户模式也拥有自己的内核模式和用户模式,虚拟机就是运行在客户模式中。KVM模块的职责就是打开并初始化VMX功能,提供相应的接口以支持虚拟机的运行。
QEMU(quick emulator)本身并不包含或依赖KVM模块,而是一套由Fabrice Bellard编写的模拟计算机的自由软件。QEMU虚拟机是一个纯软件的实现,可以在没有KVM模块的情况下独立运行,但是性能比较低。QEMU有整套的虚拟机实现,包括处理器虚拟化、内存虚拟化以及I/O设备的虚拟化。QEMU是一个用户空间的进程,需要通过特定的接口才能调用到KVM模块提供的功能。从QEMU角度来看,虚拟机运行期间,QEMU通过KVM模块提供的系统调用接口进行内核设置,由KVM模块负责将虚拟机置于处理器的特殊模式运行。QEMU使用了KVM模块的虚拟化功能,为自己的虚拟机提供硬件虚拟化加速以提高虚拟机的性能。
KVM只模拟CPU和内存,因此一个客户机操作系统可以在宿主机上跑起来,但是你看不到它,无法和它沟通。于是,有人修改了QEMU代码,把他模拟CPU、内存的代码换成KVM,而网卡、显示器等留着,因此QEMU+KVM就成了一个完整的虚拟化平台。
KVM只是内核模块,用户并没法直接跟内核模块交互,需要借助用户空间的管理工具,而这个工具就是QEMU。KVM和QEMU相辅相成,QEMU通过KVM达到了硬件虚拟化的速度,而KVM则通过QEMU来模拟设备。对于KVM来说,其匹配的用户空间工具并不仅仅只有QEMU,还有其他的,比如RedHat开发的libvirt、virsh、virt-manager等,QEMU并不是KVM的唯一选择。
所以简单直接的理解就是:QEMU是个计算机模拟器,而KVM为计算机的模拟提供加速功能。
前文《KVM 虚拟化环境搭建 - ProxmoxVE》已经给大家介绍了开箱即用的 PVE 系统,PVE 是方便,但还是有几点问题:
第一:始终是商用软件,虽然可以免费用,但未来版本还免费么?商用的法律风险呢?
第二:黑箱化的系统,虽然基于 Debian ,但是深度改造,想搞点别的也不敢乱动。
第三:过分自动化,不能让我操作底层 libvirt/qemu 的各项细节配置。
PVE 是傻瓜相机,智能又复杂,对小白很友好;WebVirtMgr 是机械相机,简单而灵活。多一个选择始终是好事,何况我们说完 PVE 之后还介绍 WebVirtMgr,那肯定是有它不可代替的优势的。
不管你是在中小公司研究 IT 解决方案,还是搭建自己的 HomeLab,虚拟化是一个绕不过去的砍,现在的服务都不会直接启动在物理机上,成熟的架构基本都是:
物理机->虚拟化->容器
这样的三层架构,也就是说虚拟化是一切服务的基础。通过下面的步骤,让你拥有一套完全开源免费的,属于你自己的,没有任何版权和法律问题的虚拟化环境。
操作系统选择
发行版选择主要以 Debian/Ubuntu LTS Server 为主,二者我并无偏好,选择你趁手的即可。Debian 每两年一个大版本,Ubuntu LTS Server 也是每两年一个大版本。也就是说每年都有一个最新的,他们的支持周期都是五年以上,去年发布的 Debian 9 ,今年是 Ubuntu 18.04 LTS,明年又是 Debian 10。
安装依赖
新安装操作系统以后,先安装必备的包:
sudo apt-get install libvirt-daemon-system libvirt-clients
sudo apt-get install sasl2-bin libsasl2-modules bridge-utils将 /etc/default/libvirtd 里面的一行 libvirtd_opts 改为:
libvirtd_opts="-l"修改 /etc/libvirt/libvirtd.conf,保证下列配置生效:
# 允许tcp监听
listen_tcp = 1
listen_tls = 0
# 开放tcp端口
tcp_port = "16509"
# 监听地址修改为 0.0.0.0,或者 127.0.0.1
listen_addr = "0.0.0.0"
# 配置tcp通过sasl认证
auth_tcp = sasl修改 /etc/libvirt/qemu.conf,取消 "# vnc_listen = ..." 前面的 # 注释(如有),变为:
vnc_listen = "0.0.0.0"找到并把 user 和 group 两个选项,取消注释,改为 libvirt-qemu:
user = "libvirt-qemu"
group = "libvirt-qemu"重启并查看服务的状态:
sudo service libvirtd restart
sudo service libvirtd status到了这一步,依赖就准备好了。
创建管理用户
ubuntu 18.04 LTS 得改一下:/etc/sasl2/libvirt.conf 文件,取消最后一行注释,变为:
sasldb_path: /etc/libvirt/passwd.db并保证 mech_list 的值为 digest-md5 ,默认的 gssapi 不能用:
mech_list: digest-md5(注意:如果是 Debian 10,那么单机请使用 unix socket,digest-md5 方式被废除掉了,下面的验证方式可以跳过直接把 www-data 用户加入 libvirt 用户组即可)。
客户端链接 libvirtd 需要用户名和密码,创建很简单:
sudo saslpasswd2 -a libvirt virtadmin可以查看创建了哪些用户:
sudo sasldblistusers2 -f /etc/libvirt/passwd.db继续重启服务:
sudo service libvirtd restart测试用户权限:
virsh -c qemu+tcp://localhost/system list使用 virsh 链接本地的 libvirtd 操作本地虚拟机,输入刚才的用户名和密码检查是否能够顺利执行,如果该命令成功则代表 libvirtd 的服务和权限工作正常。
配置网桥
Debian 9 下面是更改 /etc/network/interfaces,注意设备名称 eth0 需要改为实际的名称:
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto eth0
iface eth0 inet manual
auto br0
iface br0 inet static
address 192.168.0.2
netmask 255.255.255.0
network 192.168.0.0
broadcast 192.168.0.255
gateway 192.168.0.1
dns-nameservers 192.168.0.1
dns-search dell420
bridge_ports eth0
bridge_stp off
bridge_fd 0
bridge_maxwait 0Ubuntu 18.04 中,使用 /etc/netplan 配置网桥,卸载 cloud-init,禁用 cloud-init 配置:
sudo apt-get remove cloud-init
sudo mv /etc/netplan/50-cloud-init.yaml /etc/netplan/50-cloud-init.disable并且新建文件:/etc/netplan/10-libvirtd-bridge.yaml:
network:
ethernets:
enp3s0f0:
dhcp4: false
dhcp6: false
bridges:
br0:
addresses:
- 192.168.1.8/24
gateway4: 192.168.1.1
nameservers:
addresses: [ 192.168.1.1, 114.114.114.114 ]
search: [ msnode ]
interfaces:
- enp3s0f0
version: 2注意上面的设备名称 enp3s0f0 以及 ip 网关等配置应按实际情况更改。
注意接口名字和 ip等,改为对应的内容,改完后:
sudo netplan apply启用新的网络配置,然后重启网络看看网桥,是否正常:
sudo brctl show并且查看网络是否正常。
安装 WebVirtMgr
按照 WebVirtMgr 的官网首页的说明
安装依赖:
sudo apt-get install git python-pip python-libvirt python-libxml2 novnc supervisor nginx克隆仓库:
cd /var/www
sudo git clone git://github.com/retspen/webvirtmgr.git安装 Django 等 python 包:
cd webvirtmgr
sudo pip install -r requirements.txt
sudo https://www.zhihu.com/topic/19607498/manage.py syncdb
sudo https://www.zhihu.com/topic/19607498/manage.py collectstatic按提示输入 root 用户密码,该用户后面将用来登陆 WebVirtMgr。
然后测试:
sudo https://www.zhihu.com/topic/19607498/manage.py runserver 0:8000用浏览器打开 http://your-ip:8000 并用刚才的用户登陆看看行不行,成功的话,会看到:
然后点击右上角添加一个 connection,把 localhost 这个 libvirtd 的链接用 tcp 的方式添加进去,用户名和密码是刚才初始化的 libvirt 的管理员 admin 和密码:
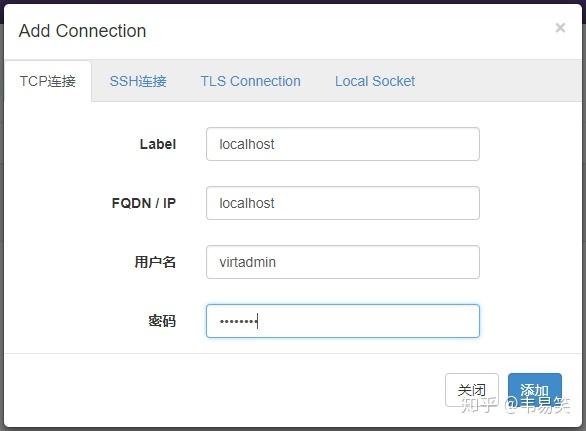
链接如果能够正常添加的话,表明可以正常运行了:
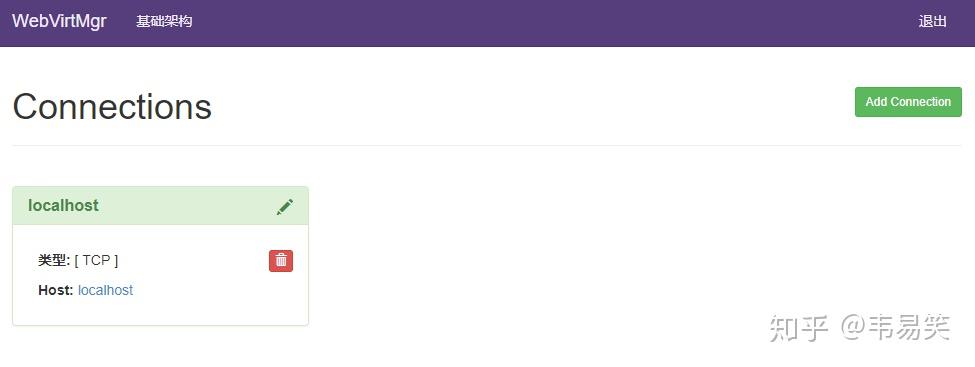
然后 CTRL+C 退出。
安装 Nginx
新建并编辑 /etc/nginx/sites-available/webvirtmgr 文件:
server {
listen 8080 default_server;
server_name $hostname;
location /static/ {
root /var/www/webvirtmgr/webvirtmgr; # or /srv instead of /var
expires max;
}
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-for $proxy_add_x_forwarded_for;
proxy_set_header Host $host:$server_port;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_connect_timeout 600;
proxy_read_timeout 600;
proxy_send_timeout 600;
client_max_body_size 1024M; # Set higher depending on your needs
}
}然后做一个该文件的软连接到 /etc/nginx/sites-enabled 下面,并删除默认软连接:
cd /etc/nginx/sites-enabled
sudo ln -s /etc/nginx/sites-available/webvirtmgr .
sudo rm default然后重启服务
sudo service nginx restart完成安装
新建并编辑 /etc/supervisor/conf.d/webvirtmgr.conf:
[program:webvirtmgr]
command=/usr/bin/python /var/www/webvirtmgr/manage.py run_gunicorn -c /var/www/webvirtmgr/conf/gunicorn.conf.py
directory=/var/www/webvirtmgr
autostart=true
autorestart=true
stdout_logfile=/var/log/supervisor/webvirtmgr.log
redirect_stderr=true
user=www-data
[program:webvirtmgr-console]
command=/usr/bin/python /var/www/webvirtmgr/console/webvirtmgr-console
directory=/var/www/webvirtmgr
autostart=true
autorestart=true
stdout_logfile=/var/log/supervisor/webvirtmgr-console.log
redirect_stderr=true
user=www-data把整个 webvirtmgr 的项目文件所有者改为 www-data:
sudo chown -R www-data:www-data /var/www/webvirtmgr重启并查看结果:
sudo supervisorctl reload
sudo supervisorctl status如果碰到错误,比如 Exited too quickly 那么到 /var/log/supervisor 下面查看日志。
完成后,浏览器打开:http://your-ip:8080/servers/
如果一切工作正常,那么恭喜你,WebVirtMgr 安装成功。
开始使用
在 /home/data 下面创建 kvm 目录,用于放虚拟机磁盘镜像文件和 iso 文件
sudo mkdir -p /home/data/kvm
sudo mkdir -p /home/data/kvm/{images, iso}
sudo chown www-data:www-data /home/data/kvm/iso你可以放在你喜欢的地方,/home 目录一般在 debian 下面会分配比较大的空间,所以把虚拟机相关的东西,放到 /home/data/kvm 下面。
然后浏览器登陆 webvirtmgr 的页面,选择刚才添加的 localhost 链接,webvirtmgr 可以同时管理多台机器的 libvirtd,这里我们以刚才添加的 localhost 链接为例。
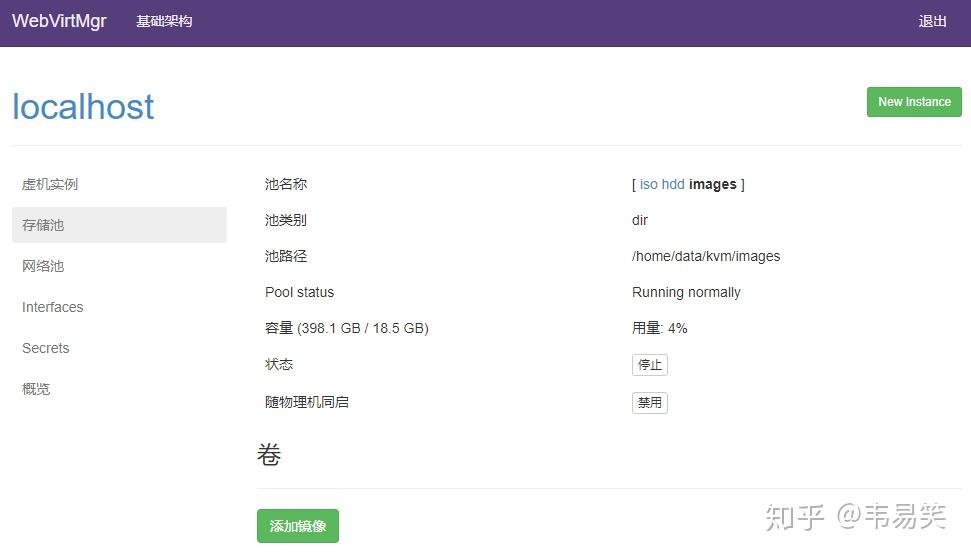
首先到左侧的 “存储池”添加用于保存虚拟机映像的路径:
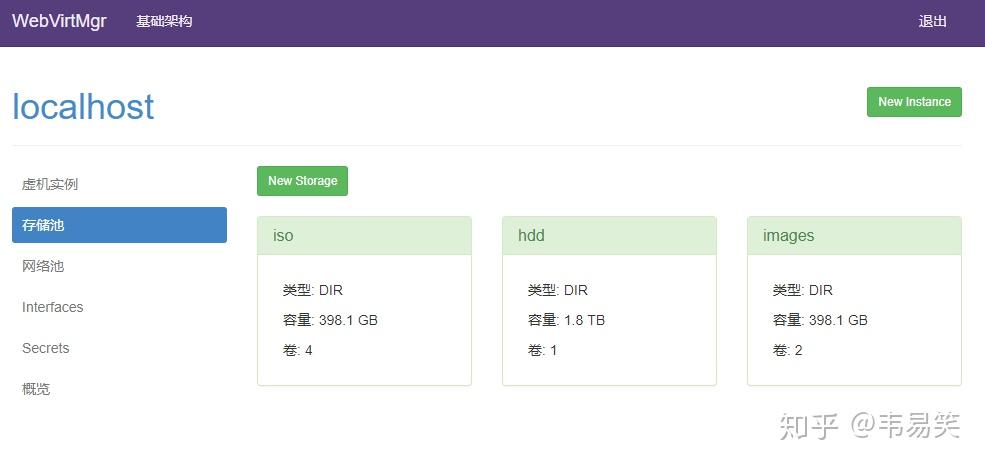
先点击 "New Storage" 添加一个类型为 “目录卷类型”的存储池,名字为 images,指向:
/home/data/kvm/images继续点“New Storage”添加一个类型为 “ISO 镜像卷”的存储池,名字为 iso ,路径为:
/home/data/kvm/iso你如果有多块硬盘,还可以继续添加一些其他位置用于保存虚拟机的磁盘镜像。
还差网络配置就妥了,点击左边 “网络池”:
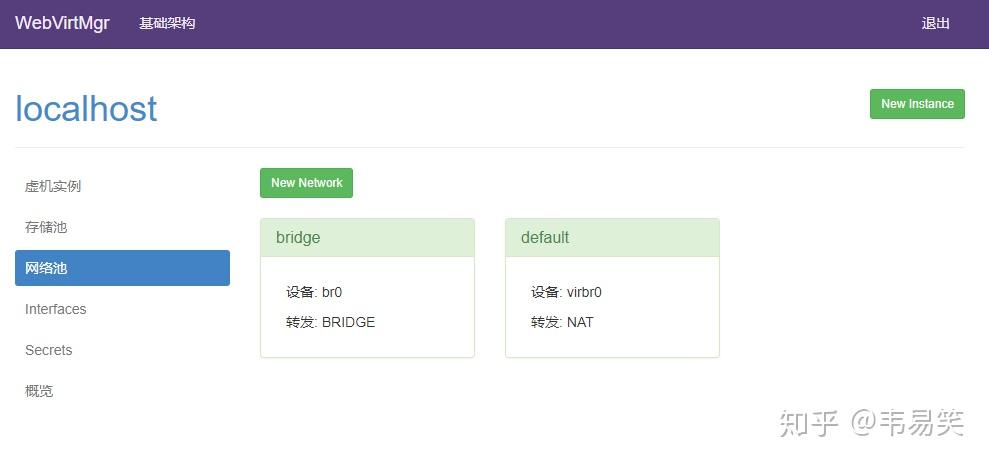
原来只有一个 default 的 NAT 类型网络,那个 bridge 是我们需要点击 "New Network" 添加的桥接网络:
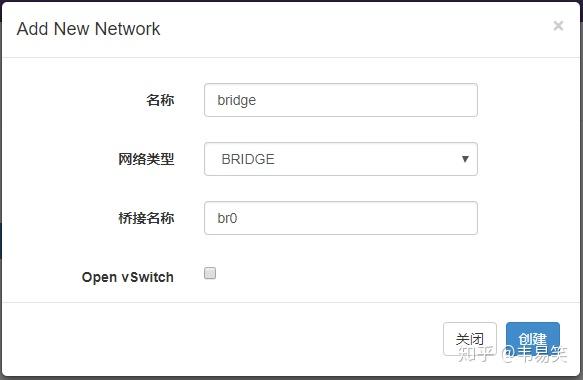
上面这个桥接名称,就是我们前面配置的网桥名称 br0。我们启动的虚拟机一般都会希望和物理机同处于一个内网下,拥有可以直接访问的 IP,因此基本都用桥接模式。
创建虚拟机
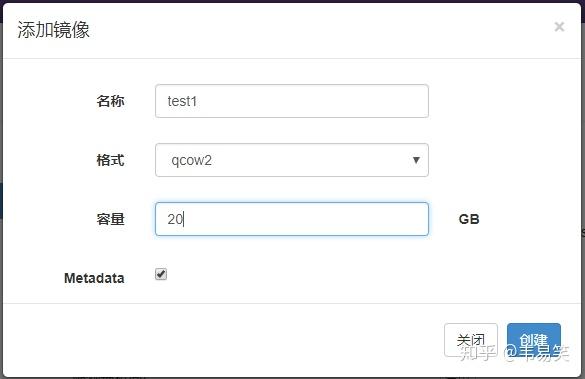
先创建磁盘映像,到左边的 “存储池”,然后选择 images 存储池:
点击最下面的添加镜像,添加一个 20G 的 qcow2,名字为 test1:
然后点击左边的 “虚机实例”,然后点击左上角的 “New Instance”:
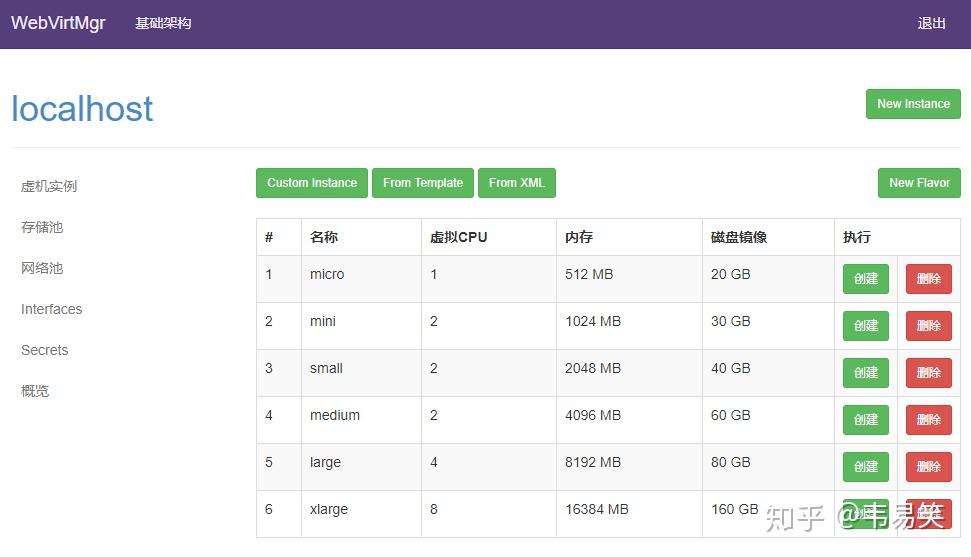
不要使用它那些乱七八糟的模板,直接点击正上方的 “Custom Instance”,创建虚拟机:
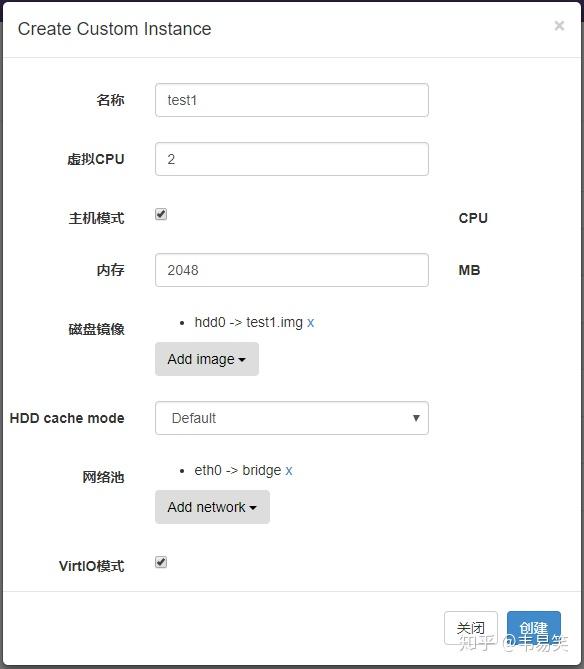
在创建虚拟机的对话框里,点击“Add Image”添加刚才创建的 test1.img 镜像,然后再 "Add network" 添加类型为 bridge 的桥接网络,你如果想要所有虚拟机都处于一个虚拟内网的话,还可以再添加一块类型为 default 的网卡,就是默认的 NAT 类型。
完成后点 “创建”,咱们的虚拟机就有了:
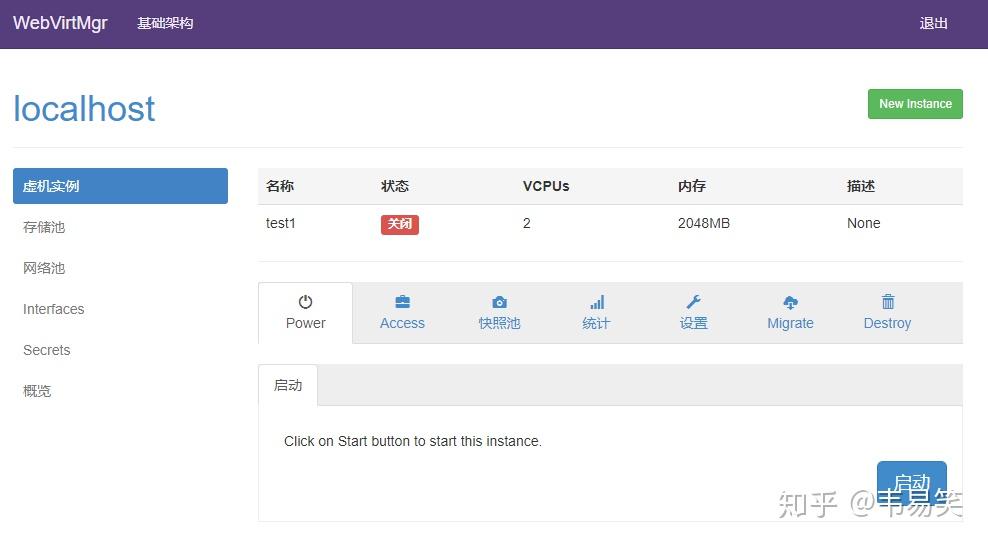
这时候,可以到现前的 “存储池”的 iso 下面,上传两个操作系统的安装盘 iso 文件,然后回来这个 test1 虚拟机主页,选择设置,挂载 iso 文件:
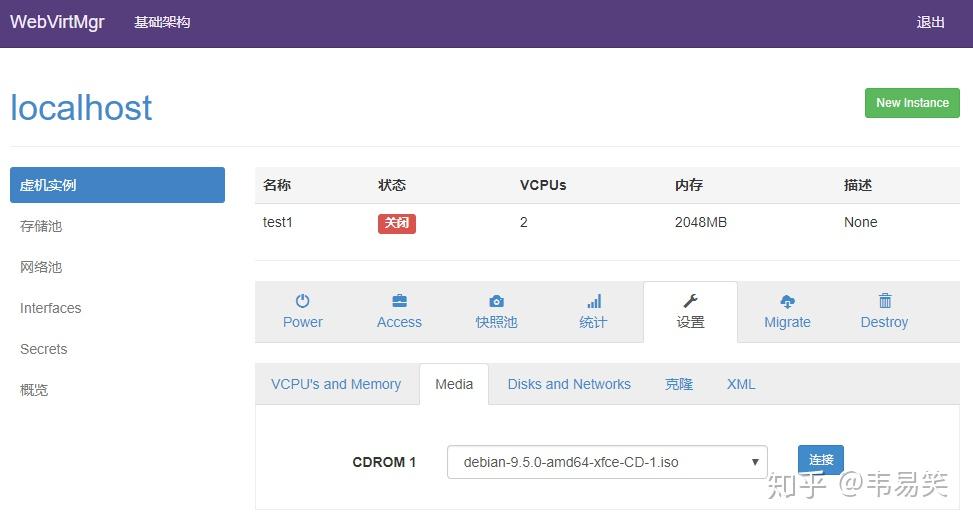
选择我们刚才上传的操作系统 ISO 文件,并点击右边的“链接”按钮,然后可以到“Power”那里使用 “启动”按钮开机了,此时虚拟机出于“开机”状态:
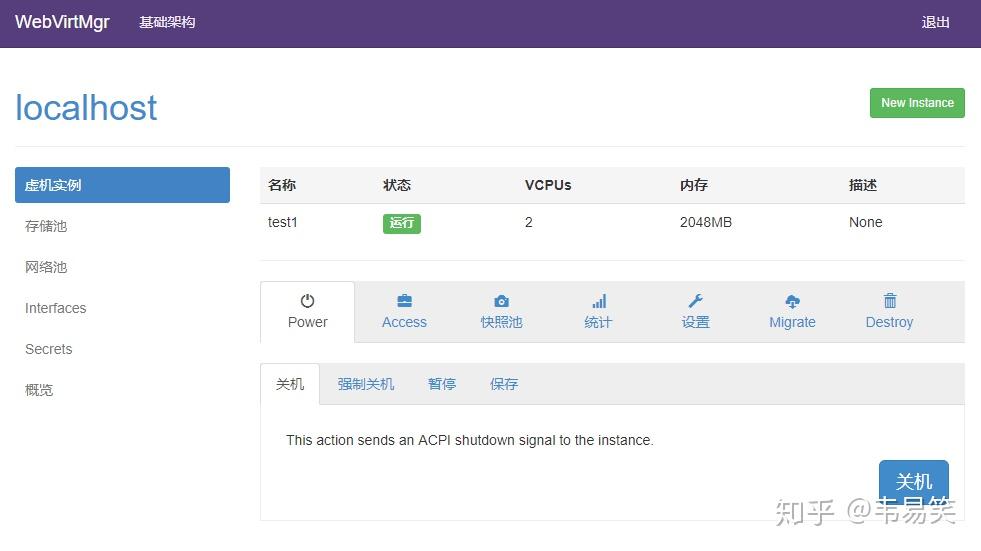
然后选择 Access :
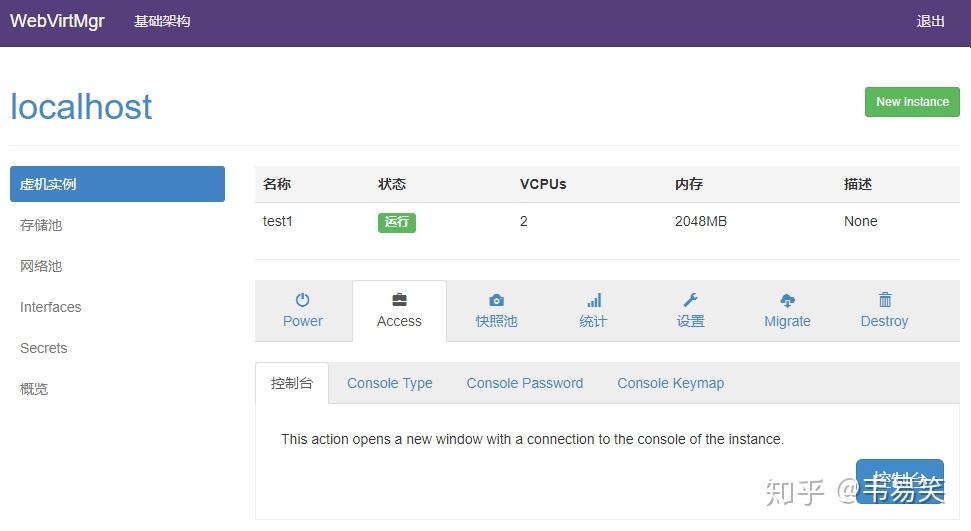
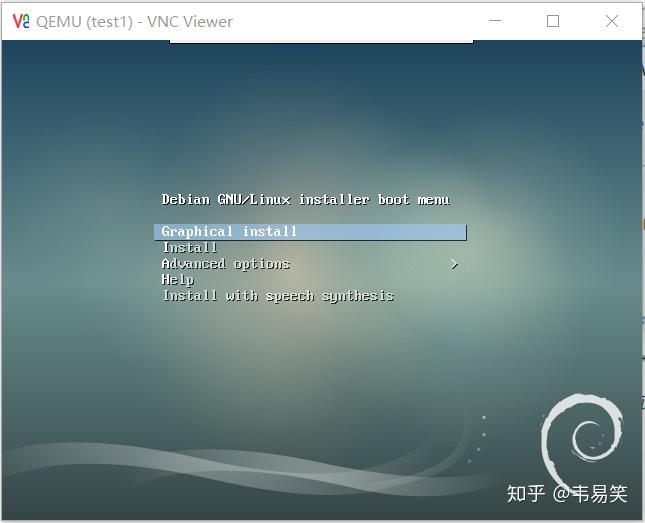
点击 “控制台”,打开虚拟机的 webvnc 终端,开始安装操作系统:
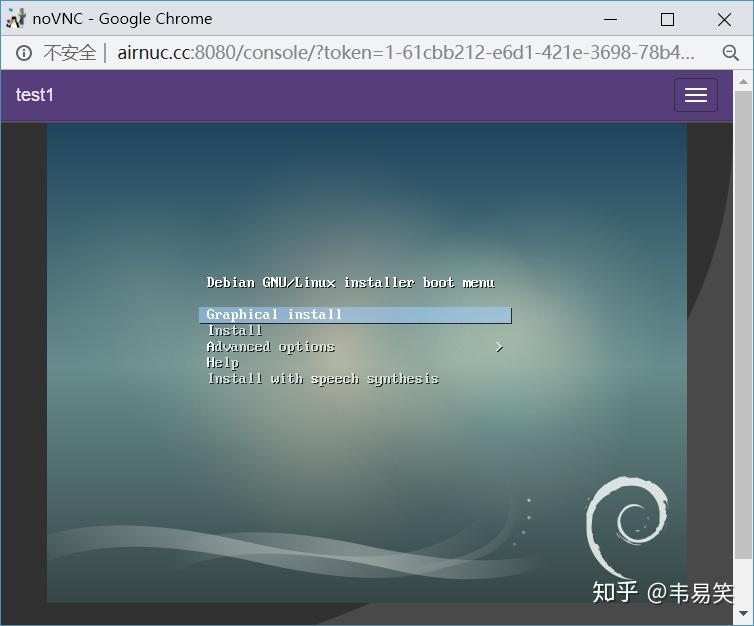
网页版本的 Webvnc 图形性能一般,建议安装操作系统都用普通文本模式安装(可以选择的话),测试虚拟机可以正常启动以后,我们先把它强制结束了,进行一些必要设置。
安全设置
如果的服务器暴露再公网上,一定要到 Access -> Console Password 下面设置个密码:
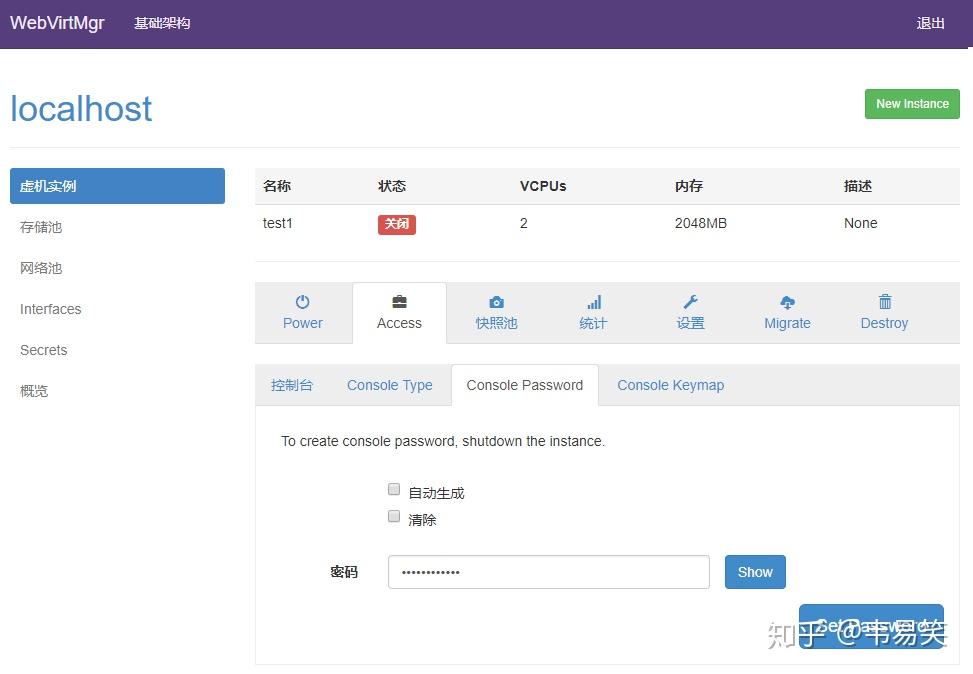
webvirtmgr 里点击控制台它会自动读取该密码,不需要你手工输入,但是这样就比没有密码安全很多了。
然后启动后,你可以到:设置->XML 那里查看一下 VNC 被分配的端口号和设置过的密码:
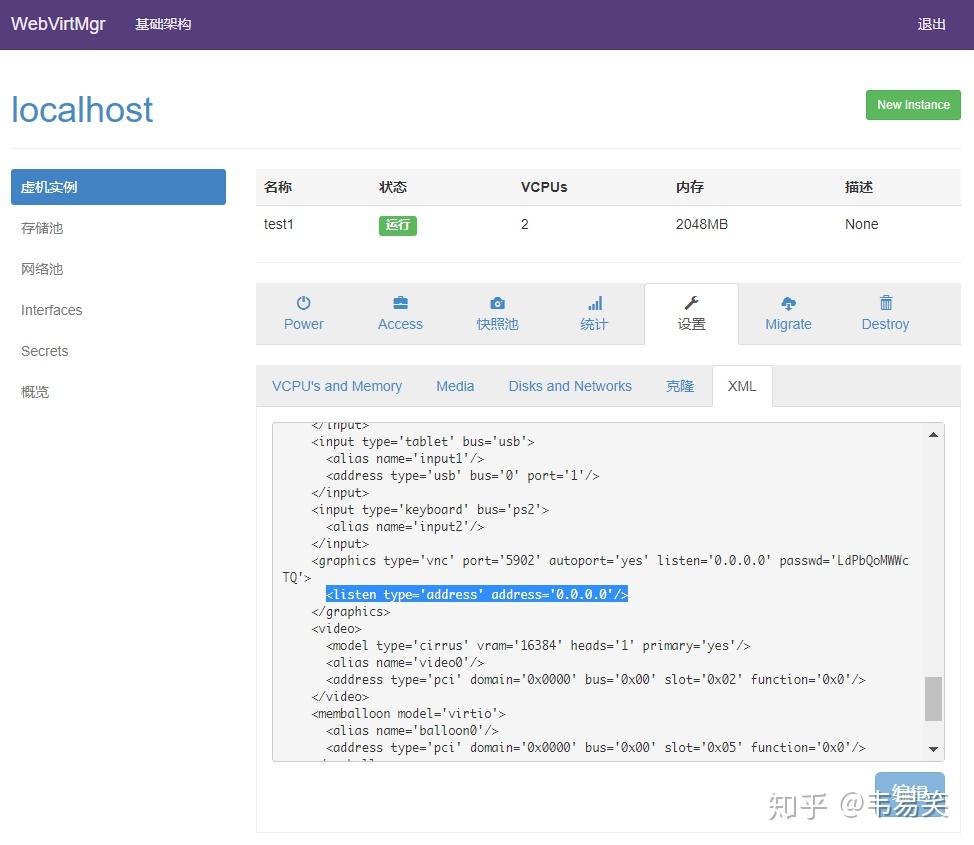
由于默认配置 VNC 都是使用 “自动端口”,这样更安全些,每次虚拟机启动,都会动态分配一个,再 XML 这里可以查看得到,这样你也可以不用 webvnc,而用自己的 VNC 客户端:
比如 Windows 下的 vnc-viewer,填入 ip 地址和端口号,然后点 "connect":
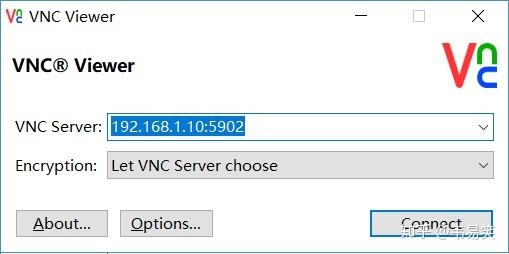
提示输入密码,将上面 XML 里的密码复制粘贴过来即可:
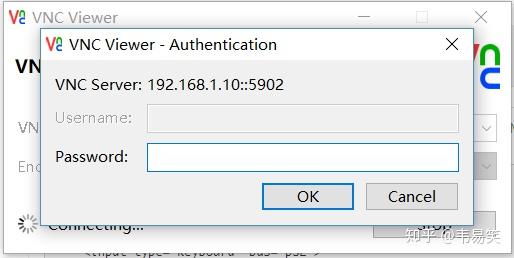
然后点击 OK 开始显示终端屏幕:
共享文件夹
这是个很基本的需求,想省事的话,nfs 共享一下也可以,但是 KVM 本身支持 Hypervisor 和虚拟机共享文件夹的,并且性能很好,可惜 PVE 里居然做不了,因为它不能改 XML。
再 “设置”-> XML 那里点击 “编辑”并在 <devices>... </devices> 中加入下面配置:
<filesystem type='mount' accessmode='mapped'>
<source dir='/home/data/kvm/kfs'/>
<target dir='kfs'/>
</filesystem>accessmode 可以设置成:mapped,passthrough 或 none。物理机准备一下共享目录:
sudo mkdir /home/data/kvm/kfs
sudo chown libvirt-qemu:libvirt-qemu /home/data/kvm/kfs所有虚拟机在物理机上都会以 libvirt-qemu 这个用户来跑(前面设置过 qemu.conf),所以需要保证你物理机上需要共享的路径的权限。同时 accessmode 建议设置成 mapped,这样会用文件信息里的 meta info 来保存虚拟机中的文件权限信息。
虚拟机中编辑 /etc/modules 文件,添加下面几行:
loop
virtio
9p
9pnet
9pnet_virtio加载内核模块:
sudo service kmod start然后测试 mount:
sudo mkdir /mnt/kfs
sudo mount -t 9p -o trans=virtio kfs /mnt/kfs这样,虚拟机中的 /mnt/kfs 就映射到了物理机的 /home/data/kvm/kfs 路径下。
测试成功的话,设置 /etc/fstab:
kfs /mnt/kfs 9p trans=virtio 0 0修改完后,mount -a 测试,测试通过重启虚拟机即可。
后记
可能大家发现了 WebVirtMgr 本质就是一个轻量级的 web 管理后台,可以在一台机器上搭建 webvirtmgr 并管理内网所有的提供 libvirtd 服务的机器。
由于 webvirtmgr 项目本身简单清晰,不少成功项目的代码都是源自它的,比如 QNAP 产品线里的 “虚拟机工作站”,通过前面一番动手,相信你对 kvm/libvirtd/vnc 之类的运作机里已经很熟悉了。
该系统设计的比较好的一个点就是允许我编辑 XML,而前面提到的 PVE 居然不允许我在页面上修改 XML,KVM支持的功能非常丰富,很多都需要通过修改 XML 完成,比如常用的硬件透传,大家可以搜索 "kvm passthrough":该功能可以把 pcie 总线上的设备传递给虚拟机,比如你的物理机上有两个 USB 插口,你可以将其中一个赋予虚拟机。或者把物理机的磁盘阵列全部传递给虚拟机,由虚拟机里面来组 raid,这样虚拟机里面装点黑群晖或者 clearos / openmediavault 之类的 nas 系统的话,可以方便的把磁盘阵列管理起来。
如果物理机有显卡的话,你甚至可以把物理机的 gpu 透传给虚拟机,这样虚拟机里面就可以跑需要 GPU 支持的任务了,比如挖矿之类,这些在 PVE 里都没法支持,这些都是 webvirtmgr 比 PVE 更灵活的地方。
更多的功能,留给大家慢慢探索吧。
Virtio 来源于 virtio: towards a de-facto standard for virtual I/O devices 这篇论文[1]。论文发表于 2008 年,已经十来年了,但是它的设计思想依旧不过时,今天来重读一下此文,看看 virtio 是如何统一半虚拟化的。
在那个时代(2008),Linux 作为 Guest OS 已经被多个系统支持,以及用户模式的 Linux 作为一个单独的进程存在。同时,对于 X86 来说,有 3 种 Hypervisor:Xen,KVM,VMWare。但是,当时每一个平台都想要有自己的网络,块设备,console 驱动程序。每个平台都实现自己的虚拟化仿真设备,它们很多相互重叠但是又有些不同,慢慢的性能优化以及驱动的维护都成为问题,所以,急需一个半虚拟化的统一模型,来解决性能以及分裂的麻烦。
论文提出了几个目标,总结来说就是提供两个通用的 ABI,Virtqueue和 Linux API for virtual IO device,以及提供虚拟设备方便的 feature 协商机制以及维持向后兼容性。
PCI 配置操作分成以下几个部分:
- 读写 feature bits;
- 读写配置空间;
- 读写 status bits;
- Device reset;
- Virtqueue 的创建和销毁
抽象后的操作如下:
struct virtio_config_ops
{
bool (*feature)(struct virtio_device *vdev, unsigned bit);
void (*get)(struct virtio_device *vdev, unsigned offset,
void *buf, unsigned len);
void (*set)(struct virtio_device *vdev, unsigned offset,
const void *buf, unsigned len);
u8 (*get_status)(struct virtio_device *vdev);
void (*set_status)(struct virtio_device *vdev, u8 status);
void (*reset)(struct virtio_device *vdev);
struct virtqueue *(*find_vq)(struct virtio_device *vdev,
unsigned index,
void (*callback)(struct virtqueue *));
void (*del_vq)(struct virtqueue *vq);
};Feature bits
定义了 Guest 和 Host 支持的功能,例如 VIRTIO_NET_F_CSUM bit 表示网络设备是否支持 checksum offload。feature bits 机制提供了未来扩充功能的灵活性,以及兼容旧设备的能力。
配置空间
一般通过一个数据结构和一个虚拟设备关联,Guest 可以读写此空间。
Status bits
这是一个 8 bits 的长度,Guest 用来标识 device probe 的状态,当 VIRIO_CONFIG_S_DRIVE_OK 被设置,那么 Guest 已经完成了 feature 协商,可以跟 host 进行数据交互了。
Device reset
重置设备,配置和 status bits。
Virtqueue 创建和销毁
find_vq 提供了分配 virtqueue 内存,和 Host 的 IO 空间的初始化操作。
Virtqueues 主要包含了数据的操作。一个虚拟设备可能有一个 virtqueue,或者多个。例如 virtio-blk 只有一个 virtqueue,而 virtio-net/virtio-console 有两个 virtqueue,一个用于输入,一个用于输出。
为什么有些只有一个 virtqueue 就可以,有些需要两个呢?
主要差别是:
- 对于 virtio-blk/virtio-scsi,对于读写,IO 发起方都是 Guest OS,所以发起方在进行 IO 操作的时候,均可以通过调用下面的 add_buf,在 avail ring 里面放置请求;
- 对于输入输出的驱动,例如 virtio-net,驱动需要随时准备好接受网络数据的缓冲区,也就是说需要提前准备好 avail ring,所以,需要单独占用一个 virtqueue,提前填满空的请求,hypervisor 在收到数据包之后,可以立即放置到接收的 virtqueue 中,并通知 Guest OS。
同时,为了性能,Qemu 和 Guest driver 可以支持为 virtio-blk 创建多个 virtqueues,来支持 multi queue 特性(注:需要块层的 blk-mq 支持)。
Hypervisor 和 Guest OS 之间初始化如下:
- 首先,Hypervisor(Qemu) 需要有创建对应的 queue 结构;
- 然后 virtio device 通过读取 PCI IO 空间来查询 queue;
- Guest OS 随后分配 virtio 的 3 种描述符的内存空间。
对于 Step 2,3,使用 find_vq 这个接口来抽象。
Virtqueue 的操作如下:
struct virtqueue_ops {
int (*add_buf)(struct virtqueue *vq,
struct scatterlist sg[],
unsigned int out_num,
unsigned int in_num,
void *data);
void (*kick)(struct virtqueue *vq);
void *(*get_buf)(struct virtqueue *vq, unsigned int *len);
void (*disable_cb)(struct virtqueue *vq);
bool (*enable_cb)(struct virtqueue *vq);
};上述五个操作,定义了 virtuque 的 5 个操作,分成 2 类:
- IO 机制实现:add_buf,get_buf
- 通知机制实现:kick,disable_cb,enable_cb
Guest OS driver 初始化 Virtqueue 以及提交一个标准的 IO 流程是:
- Driver 初始化 virtqueue 结构,调用 find_vq,传入 IO 完成时的回调函数;
- 准备请求,调用 add_buf;
- Kick 通知后端有新的请求,Qemu/KVM 后端处理请求,先进行地址转换,然后提取数据以及操作,提交给设备;
- 请求完成,Qemu/KVM 写 IO 空间触发提前定义好的 MSI 中断,进而进入到 VM,Guest OS 回调被调用,接着 get_buf 被调用,一次 IO 到此全部处理完成;
通过 5 个参数的接口定义了所有的通用数据放置的操作。
- vq 表示一个 virtqueue;
- sg 定义了一组 scatterlist,这些 sg 是灵魂,数据或者 header 都可以放在这里,自由定义。
- out_num 表示 sg 中,有多少是 Guest 要丢给 Host 的;
- in_num 表示 sg 中,有多少是 Guest 需要从 Host 拿过来的;
- data 表示 private data,完成时 get_buf 返回此数据,一般代表一个 request 的指针。
add_buf 的通用实现是:
将 sg 放入到描述符 table 里面,并且串在一起,然后将第一个 desc idx 放到 avail ring 里面,并存放 data 到数组里。
get_buf 的通用实现是:
检查 last_used_idx < used.idx,表示有已经完成的请求需要处理,然后返回 add_buf 存放的 data ,修改 last_used_idx。
通过 PCI 来触发一次通知,表示有新的请求已经准备好了。通用的是现实通过 iowrite 操作来写 PCI 对应的 IO 空间,触发 VMEXIT。
设置 avail flags字段为 VRING_AVAIL_F_NO_INTERRUPT,让 Host 在请求完成后不通知 Guest。
disable_cb 的相反操作。
在 virtio 1.1 [2] 之后,有两种内存布局:
- 老的 virtqueue 内存布局称为 Split Virtqueues;
- 新的 virtqueue 内存布局称为 Packed Virtqueues;
本文不关注 packed virtqueues。
下面是 split virtqueue 的 3 种最基本数据结构的示意图:
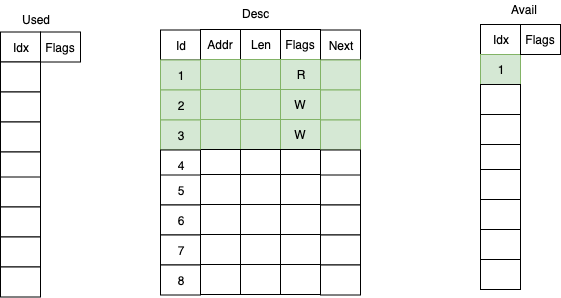
这里面有 3 部分,Desc,Used,Avail。他们在物理内存上是连续的,这样方便寻址和映射。
Desc 定义了数据地址,长度,和 flags 和 Next 指针,可以实现多个 desc 项的串联,如图所示。
Avail 存放已经有数据的 desc 的 idx,Used 存放已经完成的 desc 的 idx,各自都有一个头指针和尾指针,来表示可以消费的区间。
以 virtio-blk 为例,当使用 add_buf 添加一个请求后,描述符变化成下面的结构:
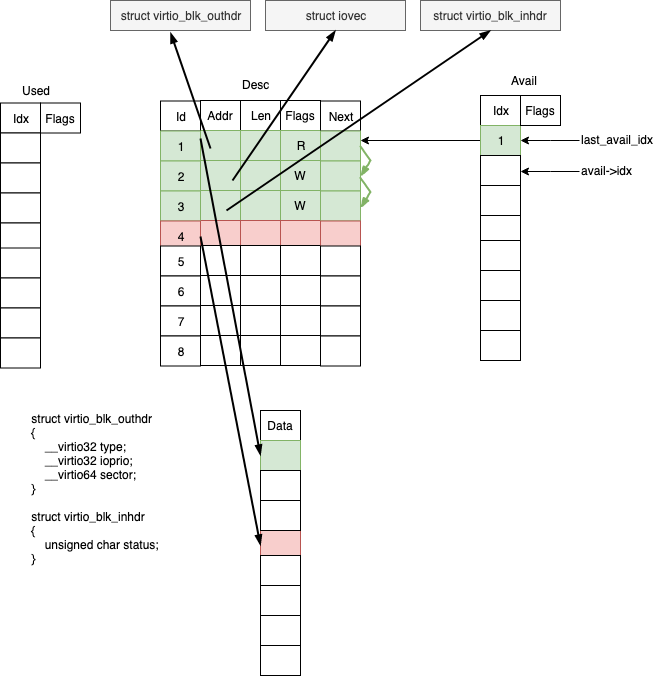
对于 virtio-blk 来说,读写需要知道以下几个问题:
读写的设备的偏移:
- virtio_blk_outhdr 头描述了读写的偏移,以及附加的信息,占用一个描述符项。
数据源或者目的地 buffer:
- Iovec 描述了 buffer 空间的地址和长度,支持 scatter 和 gather IO。对于每一段 scatter/gather 空间,都占用一个描述符项。
操作完成状态:
- Virtio_blk_inhdr 头描述了 IO 的状态,占用一个描述符项。
上图的 Data 数组是用来存放请求的指针,作 callback 用。在处理完成事件时,通过 get_buf 可以拿到这个指针,然后可以执行完成相关的上层回调。
请求的头部,以及状态和数据部分,是不同的地址区间,依次填充到可用的描述符表里面,并标记是读或者写。最后在添加了新的请求后,avail table 里面会添加了一条记录,指向整个请求的第一个描述符的 index。实际上一个请求,占用的描述符项的数量等于(2 + scatter-gather list 的长度),这种结构有很好的扩展性,可以描述任意类型的 IO 请求。
此后通过写 PCI 的 IO 空间来触发 notify 操作,Host 检查 last_avail_idx 跟 avail->idx 来判断有多少请求需要处理。notify 也会触发 KVM 的 VMEXIT 事件,造成较大开销。virtio 可以利用 flags 以及 features 来控制双向的 notify 频率,降低 VMEXIT 的调用,提高性能。
virtio 的一个目标就是提高虚拟设备性能,就要消除数据拷贝,采用共享内存的方式访问数据。virtio 的 virtqueue 在 Guest 和 Host 之间是共享的,但是由于在两个不同的地址空间,一个是 Guest Physical Address, 一个是 Host Virtual Address。virtqueue 在 Guest 端构建并初始化,Host 端只需要经过地址转换来建立对应的 virtqueue 结构即可,不用再重新初始化 virtqueue 结构。
Virtio 在初始化的时候进行第一步的地址映射:
- Guest 构建好 desc table;
- 通过写 PCI IO 空间 VIRTIO_PCI_QUEUE_PFN 来告知 Host ,Guest 的 virtqueue 的 GPA 地址;
- Host 收到了 GPA,然后转换成 Host 的虚拟地址。
因为 Host 是 Qemu 后端,Qemu 给虚拟机提供了内存,所以它知道 Guest OS 的物理地址范围。Qemu 根据自己记录的信息,可以将 gpa 转换成 hva。
Host 在处理完请求之后,将 desc 的 head 编号放到 used table 里面,然后构造 irq,通过 ioctl 通知 KVM,有请求完成了。在 Guest driver 初始化的时候,提前注册了PCI 的 irq 的 handler。handler 调用 get_buf 来获取 last_used_idx 到 used->idx 区间,已经完成的请求,从 data 数组里面找到 request 的指针,调用对应的回调即可。
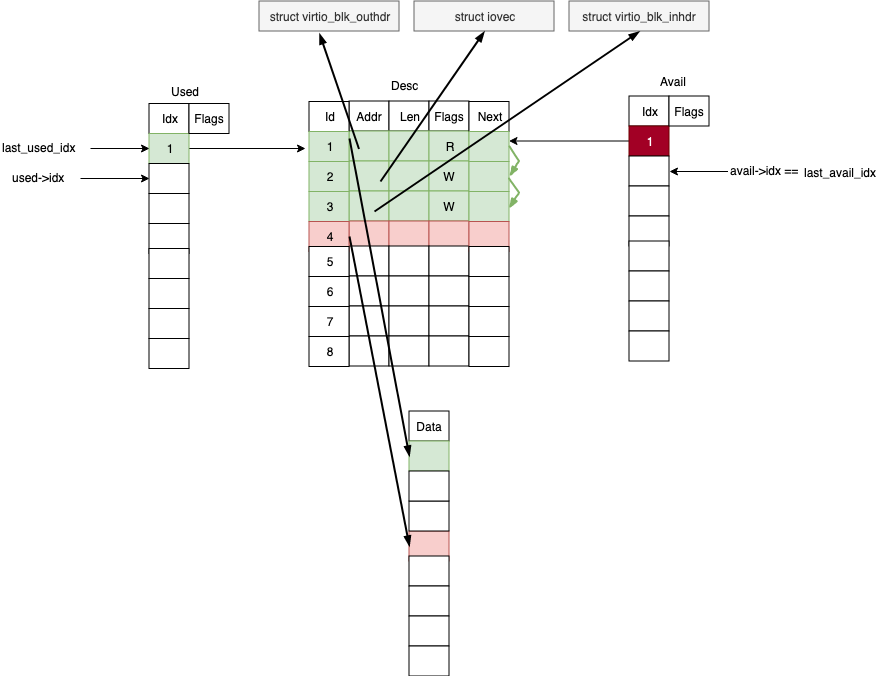
至此,虚拟化设备的数据通路走通了,没有数据拷贝,高效的实现了数据在 Guest 和 Host 的传递。Guest 里面的 driver 一般叫做前端,Host 里面对应的虚拟硬件叫做后端。
下面看一下 virtio 如何处理 block 的虚拟化的呢。
我们先从后端讲起,因为后端相当于一个虚拟的硬件,后端提供什么功能,前端才能使用什么功能。对于 block 设备的虚拟化,后端需要提供 virtio 定义的 PCI 的能力,包括:
- Feature bits
- Status bits
- 配置空间
- reset
- ...
其中配置空间比较重要,通过 PCI 提供了Guest 访问 virtio 虚拟硬件的一些参数。对于 virtio-blk,包括基本的磁盘布局信息。
struct virtio_blk_config
{
uint64_t capacity;
uint32_t size_max;
uint32_t seg_max;
uint16_t cylinders;
uint8_t heads;
uint8_t sectors;
uint32_t blk_size;
uint8_t physical_block_exp;
uint8_t alignment_offset;
uint16_t min_io_size;
uint32_t opt_io_size;
} __attribute__((packed));当 Guest OS 需要访问以上配置信息的时候,只需要调用 ioread 读对应的 offset,就可以读到数值。
同理,Guest OS 也可以通过 iowrite 来写对应的 offset,修改结构。
当完成 PCI 设置注册之后,前端 virtio-blk 调用 probe 来装载驱动。进行 feature 协商,以及基本的 IO 空间配置,此时前后端就可以进行数据传递。
当收到 Guest 的 notify 时,如图所示,Host 根据 last_used_idx 从 desc 表中重构 request,包括 virtio_blk_outhdr,iovec 等,这个过程需要进行地址空间转换,然后提交给 backend,就完成了,过程非常简单。当 IO 完成后,注入中断通知 Guest OS。
这是 Linux kernel 里面的一个 PCI 驱动,在 probe 阶段完成:
- Virtqueue 的创建;
- Feature 的协商;
- PCI 配置空间读取 block 设备的空间布局等信息;
在完成 probe 之后,此时前后端就可以进行数据传递。
请求从 block 层到达 virtio-blk 驱动之后,构造 virtio_blk_outhdr,以及 scatterlist,然后通过 add_buf 放入描述符表以及notify host,至此 IO 提交完成。完成事件由中断触发。一个基本的 virtio-blk Guest driver 只需要 300 行左右就可以完成。
Virtio 作者的目标是设计一套通用的,隐藏细节的,前后端方便实现,共享通用代码的虚拟化框架,从分析看来,通过 PCI 和 virtqueue 的抽象,的确能达到目的。
本文对部分细节只进行简单的说明,后续会在以下几个话题开展:
- Qemu 和 virtio 的内存映射
- 中断注入的实现
- Virtio 流控以及性能优化
- Vhost-user
当前,距离 virtio 问世已经十年有余,现在 virtio 的发展还在继续,包括增加更多的 feature bits,新的内存布局,以及 vhost-user,目的是提供更好的性能,以及更强大的功能。
- https://www.ozlabs.org/~rusty/virtio-spec/virtio-paper.pdf
- http://docs.oasis-open.org/virtio/virtio/v1.0/virtio-v1.0.html
- https://www.kernel.org/
- https://www.qemu.org/
@panic,SmartX 存储研发工程师。SmartX拥有国内最顶尖的分布式存储和超融合架构研发团队,是国内超融合领域的技术领导者。
KVM虚拟化详解
目录
1. KVM虚拟化架构
1.1主流虚拟化架构
1.2 KVM虚拟化架构
2 CPU虚拟化
2.1 pCPU与vCPU
2.2 虚拟化类型对比
2.3 KVM CPU虚拟化
3 内存虚拟化
3.1 EPT与VPID
3.2 透明大页THB
3.3 内存超分Over-commit
4 IO设备虚拟化
4.1 IO设备虚拟化概述
4.2 设备模拟与virtio驱动
4.3 设备直通与设备共享
4.4 其他IO设备特性
--
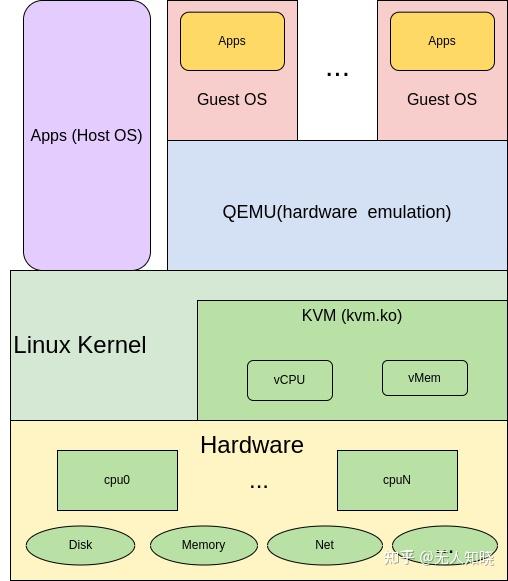
服务器虚拟化是云计算最核心的技术,而KVM是当前最主流的开源的服务器虚拟化技术。从Linux2.6.20起,KVM作为内核的一个模块 集成到Linux主要发行版本中。从技术架构(代码量、功能特性、调度管理、性能等)、社区活跃度,以及应用广泛度来看,KVM显现出明显优势,已逐渐替换另一开源虚拟化技术Xen。在公有云领域,2017年之后AWS、阿里云、华为云等厂商都逐渐从Xen转向KVM,而Google、腾讯云、百度云等也使用KVM。在私有云领域,目前VMware ESXi是领导者,微软Hyper-V不少应用,随着公有云厂商不断推进专有云/私有云方案,未来KVM应用也会逐渐增加。KVM目前已支持x86、PowerPC、S/390、ARM等平台。本文参考《KVM实战:原理、进阶与性能调优》等材料,简要梳理总结KVM在x86平台的关键技术原理。
1. KVM 虚拟化架构
1.1 主流虚拟化架构
图1对比了几种主流虚拟化技术架构:ESXi、Xen与KVM,其主要差别在与各组件(CPU、内存、磁盘与网络IO)的虚拟化与调度管理实现组件有所不同。在ESXi中,所有虚拟化功能都在内核实现。Xen内核仅实现CPU与内存虚拟化, IO虚拟化与调度管理由Domain0(主机上启动的第一个管理VM)实现。KVM内核实现CPU与内存虚拟化,QEMU实现IO虚拟化,通过Linux进程调度器实现VM管理。
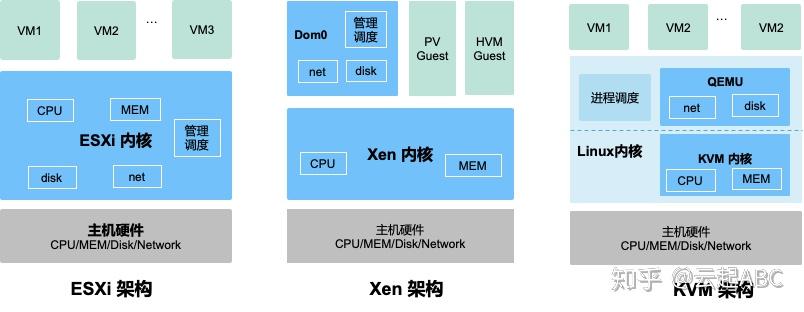
图1:虚拟化架构对比
1.2 KVM虚拟化架构
如图2,KVM虚拟化有两个核心模块:
1)KVM内核模块:主要包括KVM虚拟化核心模块KVM.ko,以及硬件相关的KVM_intel或KVM_AMD模块;负责CPU与内存虚拟化,包括VM创建,内存分配与管理、vCPU执行模式切换等。
2)QEMU设备模拟:实现IO虚拟化与各设备模拟(磁盘、网卡、显卡、声卡等),通过IOCTL系统调用与KVM内核交互。KVM仅支持基于硬件辅助的虚拟化(如Intel-VT与AMD-V),在内核加载时,KVM先初始化内部数据结构,打开CPU控制寄存器CR4里面的虚拟化模式开关,执行VMXON指令将Host OS设置为root模式,并创建的特殊设备文件/dev/kvm等待来自用户空间的命令,然后由KVM内核与QEMU相互配合实现VM的管理。KVM会复用部分Linux内核的能力,如进程管理调度、设备驱动,内存管理等。
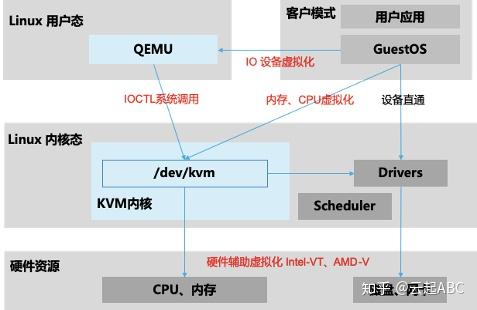
图2:KVM虚拟化架构
2. CPU虚拟化
2.1 pCPU与vCPU
如图3,物理服务器上通常配置2个物理pCPU(Socket),每个CPU有多个核(core);开启超线程Hyper-Threading技术后,每个core有2个线程(Thread);在虚拟化环境中一个Thread对应一个vCPU。在KVM中每一个VM就是一个用户空间的QEMU进程,分配给Guest的vCPU就是该进程派生的一个线程Thread,由Linux内核动态调度到基于时分复用的物理pCPU上运行。KVM支持设置CPU亲和性,将vCPU绑定到特定物理pCPU,如通过libvirt驱动指定从NUMA节点为Guest分配vCPU与内存。KVM支持vCPU超分(over-commit)使得分配给Guest的vCPU数量超过物理CPU线程总量。
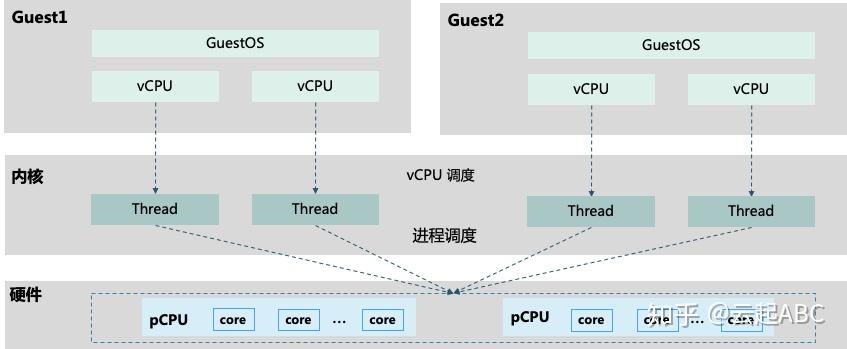
图3:pCPU与vCPU关系
2.2 虚拟化类型对比
Intel对x86 CPU指定了4种特权级别Ring0 - Ring3,其中Ring 0是内核态,运行OS内核,权限最高,可执行特权或敏感指令,对系统资源进行管理与分配等;ring 3权限最低,运行用户应用。如图4,ESXi属于全虚拟化,VMM运行在Ring0完整模拟底层硬件; GuestOS运行在ring1,无需任何修改即可运行,执行特权指令时需要通过VMM进行异常捕获、二进制翻译BT(Binary Translation)和模拟执行。Xen支持全虚拟化(HVM Guest)与半虚拟化(PV Guest);使用半虚拟化时,GuestOS运行在Ring 0需要进行修改(如安装PV Driver),通过Hypercall调用VMM处理特权指令,无需异常捕获与模拟执行。
KVM是依赖于硬件辅助的全虚拟化(如Inter-VT、AMD-V),目前也通过virtio驱动实现半虚拟化以提升性能。Inter-VT引入新的执行模式:VMM运行在VMX Root模式, GuestOS运行在VMX Non-root模式,执行特权指令时两种模式可以切换。
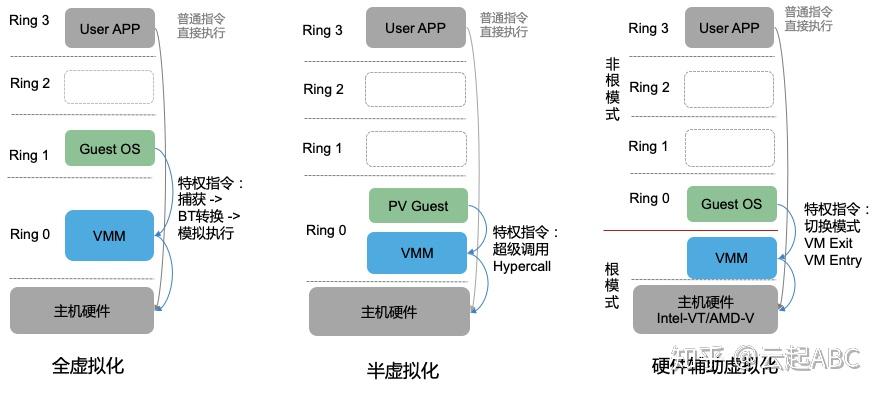
图4:x86 CPU 特权级别与虚拟化分类
2.3 KVM CPU虚拟化
KVM中vCPU在三种模式下执行:
1) 客户模式(Guest Mode)运行GuestOS,执行Guest非IO操作指令。
2) 用户模式(User Mode)运行QEMU,实现IO模拟与管理。
3) 内核模式(Kernel Mode)运行KVM内核,实现模式的切换(VM Exit/VM Entry),执行特权与敏感指令。
如图5,KVM内核加载时执行VMXON指令进入VMX操作模式,VMM进入VMX Root模式,可执行VMXOFF指令退出。GuestOS执行特权或敏感指令时触发VM Exit,系统挂起GuestOS,通过VMCALL调用VMM切换到Root模式执行,VMExit开销是比较大的。VMM执行完成后,可执行VMLANCH或VMRESUME指令触发VM Entry切换到Non-root模式,系统自动加载GuestOS运行。
VMX定义了VMCS(Virtual Machine Control Structure)数据结构来记录vCPU相关的寄存器内容与控制信息,发生VMExit或VMEntry时需要查询和更新VMCS。VMM为每个vCPU维护一个VMCS,大小不超过4KB,存储在内存中VMCS区域,通过VMCS指针进行管理。VMCS主要包括3部分信息,control data主要保存触发模式切换的事件及原因;Guest state 保存Guest运行时状态,在VM Entry时加载;Host state保存VMM运行时状态,在VM Exit时加载。通过读写VMCS结构对Guest进行控制。
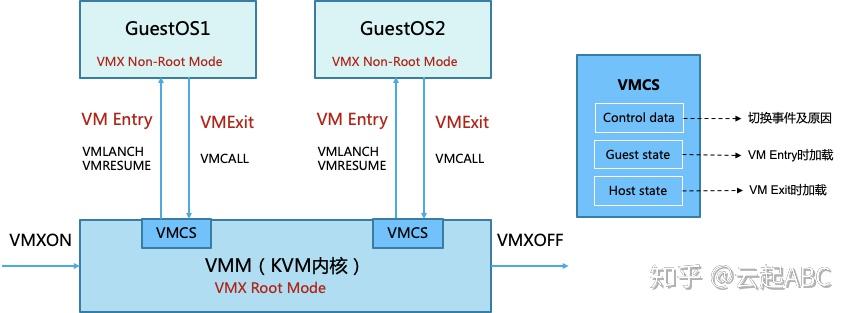
图5:VMX Root/Non-Root 模式切换
3. 内存虚拟化
3.1 EPT与VPID
内存存放CPU将要执行的指令或数据,内存大小与访问效率对系统性能至关重要。内存虚拟化目标是保障内存空间的合理分配、管理,隔离,以及高效可靠地使用。需要将Guest线性虚拟内存地址GVA(Guest Virtual Address)转换为Host上的物理内存地址HPA(Host Physical Address )。没有硬件辅助虚拟化之前,VMM为每个Guest维护一份影子页表(Shadow Page Table),通过软件维护GVA到HPA的映射,由于内存访问与更新频繁导致影子页表的维护复杂,开销较大。
Intel引入了硬件辅助内存虚拟化扩展页表EPT(Extend Page Table),AMD 的是嵌入页表NPT(Nested Page Table),作为CPU内存管理单元MMU的扩展,通过硬件来实现GVA、GPA到HPA的转换。如图6,首先Guest通过CR3寄存器将GVA转换为GPA,然后查询EPT将GPA转换为HPA。EPT的控制权在VMM上,只有CPU工作在Non-Root模式时才参与该内存转换。引入EPT后,Guest读写CR3寄存器或Guest Page Fault,执行INVLPG指令等不会触发VM Exit,由此降低了内存转换复杂度,提升转换效率。
另外,CPU使用TLB(Translation Lookaside Buffer)缓存线性虚拟地址到物理地址的映射,地址转换时CPU先根据GPA先查找TLB,如果未找到映射的HPA,将根据页表中的映射填充TLB,再进行地址转换。不同Guest的vCPU切换执行时需要刷新TLB,影响了内存访问效率。Intel引入了VPID(Virtual-Processor Identifier)技术在硬件上为TLB增加一个标志,每个TLB表项与一个VPID关联,唯一对应一个vCPU,当vCPU切换时可根据VPID找到并保留已有的TLB表项,减少TLB刷新。
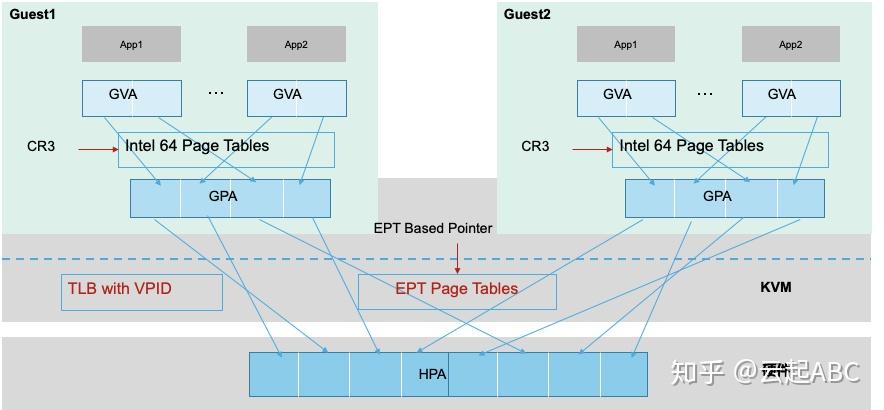
图6:基于EPT的内存地址转换
3.2 透明大页THP
x86 CPU默认使用4KB的内存页面,目前已经支持2MB,1GB的内存大页(Huge Page)。使用大页内存可减少内存页数与页表项数,节省了页表所占用的CPU缓存空间,同时也减少内存地址转换次数,以及TLB失效和刷新的次数,从而提升内存使用效率与性能。但使用内存大页也有一些弊端:如大页必须在使用前准备好;应用程序必须显式地使用大页(一般是调用mmap、shmget或使用libhugetlbfs库进行封装);需要超级用户权限来挂载hugetlbfs文件系统;如果大页内存没有实际使用会造成内存浪费等。2009年实现的透明大页THP(Transparent Hugepage)技术创建了一个抽象层,能够自动创建、管理和使用传统大页,实现发挥大页优势同时也规避以上弊端。当前主流的Linux版本都默认支持。KVM中可以在Host和Guest中同时使用THB技术。
3.3 内存超分Over-Commit
由于Guest使用内存时采用瘦分配按需增加的模式,KVM支持内存超分(Over-Commit)使得分配给Guest的内存总量大于实际物理内存总量,从系统访问性能与稳定性考虑,在生产环境中一般不建议使用内存超分。内存超分有三种实现方式:
1) 内存交换(Swapping):当系统内存不够用时,把部分长时间未操作的内存交换到磁盘上配置的Swap分区,等相关程序需要运行时再恢复到内存中。
2) 气球(Ballooning):通过virtio_balloon驱动实现动态调整Guest与Host的可用内存空间。气球中的内存是Host可使用,Guest不能使用。当Host内存不足时,可以使气球膨胀,从而回收部分已分配给Guest的内存。当Guest内存不足时可请求压缩气球,从Host申请更多内存使用。
3) 页共享(Page Sharing):通过KSM(Kernel Samepage Merging)让内核扫描正在运行进程的内存。如果发现完全相同的内存页就会合并为单一内存页,并标志位写时复制COW(Copy On Write)。如果有进程尝试修改该内存页,将复制一个新的内存页供其使用。KVM中QEMU通过madvise系统调用告知内核那些内存可以合并,通过配置开关控制是否企业KSM功能。Guest就是QEMU进程,如果多个Guest运行相同OS或应用,且不常更新,使用KSM能大幅提升内存使用效率与性能。当然扫描和对比内存需要消耗CPU资源对性能会有一定影响。
4. IO设备虚拟化
4.1 IO设备虚拟化概述
在虚拟化环境中,Guest的IO操作需要经过特殊处理才能在底层IO设备上执行。如表1,KVM支持5种IO虚拟化技术。
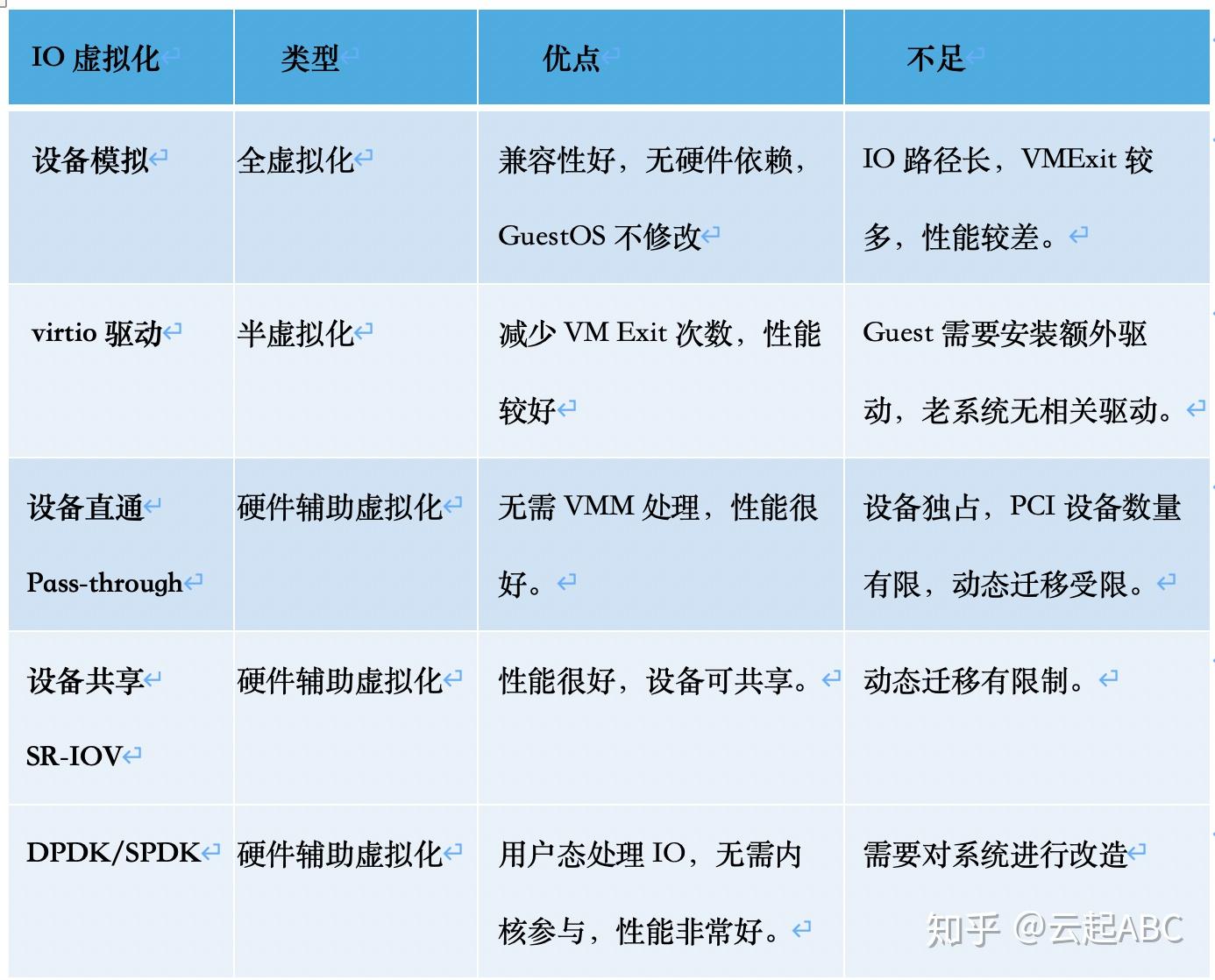
表1:虚拟化环境IO处理方式对比
4.2 设备模拟与virtio驱动
如图7,全虚拟化的设备模拟与半虚拟化的virtio驱动都是通过软件实现IO虚拟化。
设备模拟
KVM中通过QEMU来模拟网卡或磁盘设备。Guest发起IO操作时被KVM的内核捕获,处理后发送到IO共享页并通知QEMU;QEMU获取IO交给硬件模拟代码模拟IO操作,并发送IO请求到底层硬件处理,处理结果返回到IO共享页;然后通知IO捕获代码,读取结果并返回到Guest中。
Virtio驱动
在Guest中部署virtio前端驱动,如virtio-net、virtio-blk、virtio_pci、virtio_balloon、virtio_scsi、virtio_console等,然后在QEMU中部署对应的后端驱动,前后端之间定义了虚拟环形缓冲区队列virtio-ring,用于保存IO请求与执行信息。Guest的IO从前端驱动发送到virtio-ring,然后后端驱动或去IO并转发到底层设备处理,处理完后返回结果。目前主流的Linux与windows都支持virtio,以获得更好的IO性能。
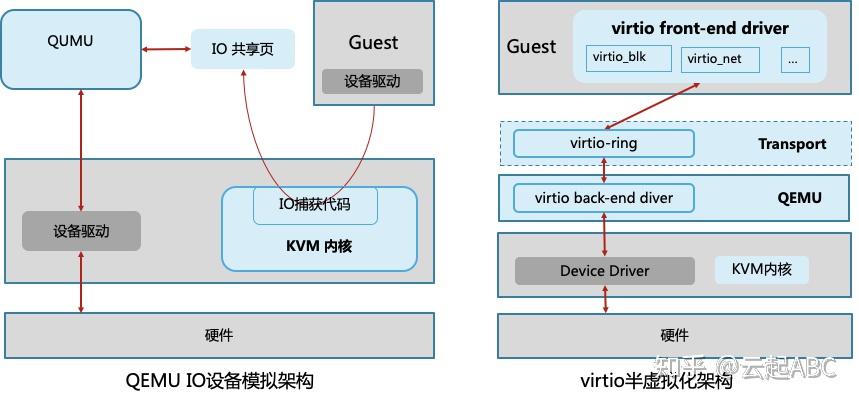
图7:基于软件的IO虚拟化
vhost-net与vhost-user
virtio中后端驱动由用户空间的QEMU提供,但网络协议栈处于内核中,如果通过内核空间来处理网络IO,可以减少了网络IO处理过程中的多次上下文切换,从而提高网络吞吐量与性能。所以,新的内核中提供vhost-net驱动,使前端网络驱动virtio-net的后端处理任务从用户态的QEMU改到Host内核空间执行。
大规模云计算环境中会使用OVS(Open vSwitch)或SDN方案,而进程运行在用户态,如果继续用使用内核态的vhost-net,依然存在大量用户态与内核态的切换,所以引入了vhost-user(内核态vhost功能在用户态实现)。vhost-user定义了Master(QEMU进程)和slave(OVS进程)作为通信两端,Master与slave之间控制面通过共享的虚拟队列virtqueure交换控制逻辑,数据面通过共享内存交换信息。结合vhost-user、vSwitch与DPDK可以在用户态完成网络数据包交换处理,从而大幅提升了网络虚拟化性能。
4.3 设备直通与共享
通过软件方式实现IO虚拟化存在一定系统开销与性能损耗,所以Intel推出了硬件辅助虚拟化技术(AMD-V类似)。

表2:Intel 硬件辅助虚拟化技术
设备直通PCI Pass-through
基于硬件辅助虚拟化技术,KVM支持将Host的PCI/PCI-E物理设备(如网卡、磁盘、USB、显卡、GPU等)直接分配给Guest使用。Guest的对该设备的IO操作与物理设备一样,不经过QEMU/KVM处理。直通设备不能共享给多个Guest使用,且不能随Guest进行动态迁移,需要通过热插拔或libvirt工具来解决。
设备共享SR-IOV
为了实现多个Guest可以共享同一个物理设备,PCI-SIG发布了SR-IOV(Single Root-IO Virtualization)标准,让一个物理设备支持多个虚拟功能接口,可以独立分配给不同的Guest使用。SR-IOV定义了两个功能:
1) 物理功能PF(Physical Function):拥有物理PCI-e设备的完整功能,可独立使用;以及SR-IOV扩展能力,可配置管理VF。
2) 虚拟功能VF(Virtual Function):由PF衍生的轻量级PCI-e功能,包括数据传送的必要资源。不同的VF可以分配给不同的Guest,SR-IOV为Guest独立使用VF提供了独立的内存、中断与DMA流,数据传输过程无需VMM介入。
DPDK/SPDK
为了更好地提升虚拟化网络或磁盘IO性能,Intel等公司推出了数据平面开发工具集DPDK(Data Plance Development Kit)与存储性能开发工具集SPDK(Storage Performace Development Kit)。DPDK、vhost-user、OVS结合使用,可跳过Linux内核,直接在用户态完成网络数据包交换处理。SPDK通过环境抽象层EAL与UIO将存储驱动放在用户态处理,同时通过PMD轮询机制代替传统中断模式来处理IO。DPDK与SPDK大幅缩短了IO处理路径与系统开销, IO性能提升非常明显。DPDK与SPDK详情参考云网络介绍与云存储介绍部分。
4.4 其他IO设备特性
图像与声音
QEMU中对Guest的图像显示默认使用SDL(Simple DirectMedia Layer)实现。SDL是一个基于C语言的、跨平台的,开源的多媒体程序库,提供了简单的接口用于操作硬件平台的图形显示、声音、输入设备等,广泛应用于各种操作系统。同时在虚拟化环境中也广泛使用虚拟网络控制台VNC(Virtual Network Computing),采用RFB(Remote Frame Buffer)协议将客户端(浏览器或VNC Viewer)的键盘与鼠标输入传递到远程服务端VNC Server中,并返回输出结果。VNC不依赖操作系统,在VNC窗口断开后,已发出操作仍然会在服务端继续执行。由于VNC是GPL授权,衍生出多个版本RealVNC、TightVNC与UltraVNC,其对比如表3。

表3:VNC版本对比
热插拔Hot Plugging
热插拔就是在服务器运行时插上或拔出硬件,以保障服务器的扩展性与灵活性。热插拔需要总线电气特性、主板BIOS、操作系统以及设备驱动的支持。目前支服务器持硬盘、CPU、内存、网卡、USB设备与风扇等部件热插拔。在KVM中在Guest不关机情况下支持PCI设备(如模拟、半虚拟化或直通的网卡、硬盘、USB设备)。CPU和内存热插拔硬件平台和OS层面的限制还比较多。
---
参考书籍:《KVM实战原理、进阶与性能调优》,任永杰、程舟著。
相关阅读:
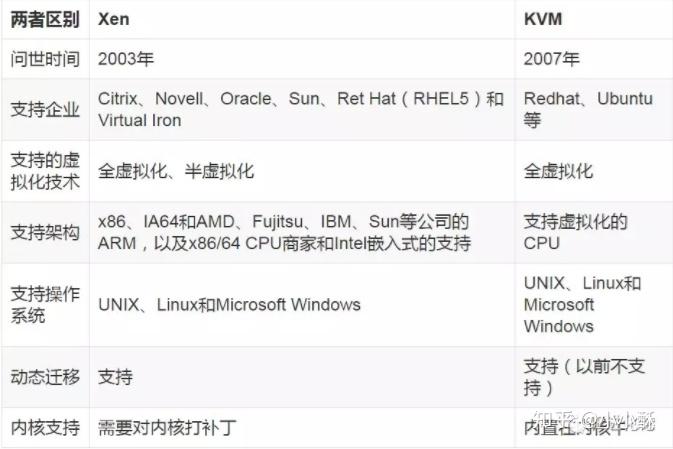
https://zhuanlan.zhihu.com/p/102256101https://zhuanlan.zhihu.com/p/98827611https://zhuanlan.zhihu.com/p/100526650https://zhuanlan.zhihu.com/p/97402658KVM和XEN都是开源的虚拟化技术。
一、Xen 虚拟化技术简介
XEN最初是剑桥大学Xensource的一个开源研究项目,2003年9月发布了首个版本Xen 1.0,2007年Xensource被Citrix公司收购,开源Xen转由http://www.xen.org继续推进,该组织成员包括个人和公司(如Citrix、Oracle等)。2014年03月11日,Xen发布4.4版本,更好地支持ARM架构。
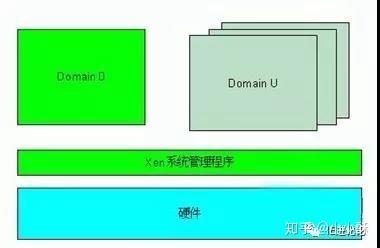
Xen是运行在裸机上的虚拟化管理程序(HyperVisor),是半虚拟化(Para-Virtualization)技术的典型代表。英文前缀“Para”直译为“侧”、“旁”、“近旁”的意思,“Para-Virtualization”可以理解为“在Guest VM旁边运行着的管理VM”,Xen称这个特别的VM为Dom0,虚拟机操作系统被称做DomU。管理VM负责管理整个硬件平台上的所有输入输出设备驱动,半虚拟化中的Hypervisor不对I/O设备作模拟,而仅仅对CPU和内存做模拟,这就是“Para-Virtualization”被翻译成“半虚拟化”的原因。半虚拟化还有一个叫法:操作系统辅助虚拟化(OS Assisted Virtualization),这是因为Guest VM自身不带设备驱动,需要向“管理VM”寻求帮助。这种虚拟化技术允许虚拟化操作系统感知到自己运行在XEN HyperVisor上而不是直接运行在硬件上,同时也可以识别出其他运行在相同环境中的虚拟机。
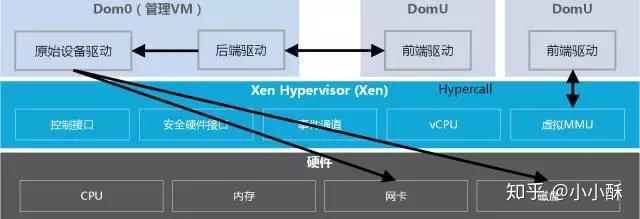
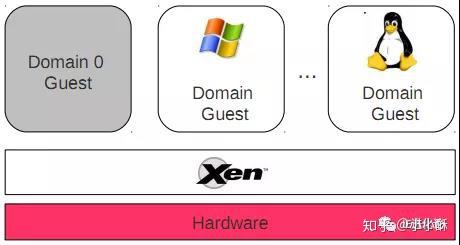
相对于VMwareESX/ESXi和微软Hyper-V来说,Xen支持更广泛的CPU架构,前两者只支持CISC的X86/X86_64 CPU架构,Xen除此之外还支持RISC CPU架构,如IA64、ARM等。Xen的Hypervisor是服务器经过BIOS启动之后载入的首个程序,然后启动一个具有特定权限的虚拟机(即Dom 0)。Dom 0的操作系统可以是Linux或Unix,它实现对Hypervisor控制和管理功能。在所承载的虚拟机中,Dom0是唯一可以直接访问物理硬件(如存储和网卡)的虚拟机,它通过本身加载的物理驱动,为其它虚拟机(即DomU)提供访问存储和网卡的桥梁。
Xen最重要的优势在于半虚拟化,能让虚拟机有效运行而不需要仿真,因此虚拟机能感知到hypervisor,而不需要模拟虚拟硬件,从而能实现高性能。同时半虚拟化架构的最大缺点是需要特定内核的操作系统,XEN需要修改操作系统内核,Windows操作系统由于其封闭性,不能被Xen的半虚拟化所支持。
为了解决这个问题,Xen也支持全虚拟化(FullVirtualization)。Xen称其为HVM(Hardware Virtual Machine)。这种虚拟化技术指运行在虚拟环境上的虚拟机在运行过程中始终感知到自己是直接运行在硬件之上的,并且感知不到在相同硬件环境下运行着其他虚拟机。Xen的全虚拟化要求CPU具备硬件辅助虚拟化,它修改的QEMU(Quick Emulator)仿真所有硬件,包括BIOS、IDE控制器、VGA显示卡、USB控制器和网卡等。为了提升I/O性能,全虚拟化特别针对磁盘和网卡采用半虚拟化设备来代替仿真设备,这些设备驱动称之为PV on HVM。为了使PV on HVM有最佳性能,CPU应具备MMU硬件辅助虚拟化。
Xen的Hypervisor层非常精简,少于15万行的代码量,不包含任何物理设备驱动,这一点与Hyper-V是非常类似的,物理设备的驱动均是驻留在Dom 0中,可以重用现有的Linux设备驱动程序。因此,Xen对硬件兼容性也是非常广泛的,Linux支持的,它就支持。
二、KVM虚拟化技术简介
KVM(Kernel-based Virtual Machine,基于内核的虚拟机)是一个基于Linux环境的开源虚拟化解决方案,最早由以色列Qumranet公司开发,在2006年10月出现在Linux内核的邮件列表上,并于2007年2月被集成到Linux 2.6.20内核中,成为内核的一部分。2008年,Qumranet被RedHat所收购,但KVM本身仍是一个开源项目,由RedHat、IBM等厂商支持。
与VMwareESX/ESXi、微软Hyper-V和Xen等虚拟化产品不同,KVM的思想是在Linux内核的基础上添加虚拟机管理模块,重用Linux内核中已经完善的进程调度、内存管理、IO管理等代码,使之成为一个可以支持运行虚拟机的Hypervisor。因此,KVM并不是一个完整的模拟器,而只是一个提供了虚拟化功能的内核插件,具体的模拟器工作需要借助QEMU来完成。
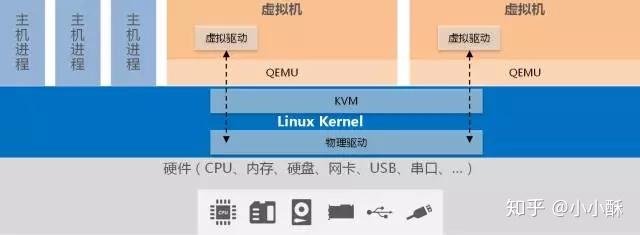
通过KVM模块的加载将Linux内核转变成Hypervisor,KVM在Linux内核的用户(User)模式和内核(Kernel)模式基础上增加了客户(Guest)模式。Linux本身运行于内核模式,主机进程运行于用户模式,虚拟机则运行于客户模式,使得转变后的Linux内核可以将主机进程和虚拟机进行统一的管理和调度,这也是KVM名称的由来。
KVM利用修改的QEMU提供BIOS、显卡、网络、磁盘控制器等的仿真,但对于I/O设备(主要指网卡和磁盘控制器)来说,则必然带来性能低下的问题。因此,KVM也引入了半虚拟化的设备驱动,通过虚拟机操作系统中的虚拟驱动与主机Linux内核中的物理驱动相配合,提供近似原生设备的性能。从此可以看出,KVM支持的物理设备也即是Linux所支持的物理设备。
KVM是基于硬件辅助虚拟化技术(Intel的VT-x或者AMD-V)的虚拟化解决方案,Guest OS能够不经过修改直接在KVM 的虚拟机中运行,每一台虚拟机能够享有独立的虚拟硬件资源,如网卡、磁盘、图形适配器等。“基于Linux内核”是KVM在软件实现上不同于其它VMM实现的最重要特点,使得KVM在实现上能获得如下好处:
(1) 充分利用现有硬件的虚拟化功能。KVM的设计是在硬件辅助虚拟化技术成熟之后,它没有必要实现当前主流硬件已经实现的虚拟化相关功能。
(2) 充分利用现有软件的虚拟化功能。Hypervisor除了要虚拟CPU和内存外还需要其它的核心功能组件,如内存管理器、进程调度程序、I/O控制器、设备驱动、网络控制器等。Linux的内核已经包含了上述的功能模块,KVM利用Linux内核已有的成熟功能和基础服务,减少不必要的重新开发,如任务调度、物理内存管理、内存空间虚拟化、电源管理等功能。
(3) 充分利用现有硬件的软件驱动程序。在KVM的系统构架中,虚拟机以普通Linux的进程的方式来实现,由标准的Linux进程调度器来调度。实际上每个vCPU都是以一个常规的Linux进程呈现的。硬件设备的模拟则是通过一个修改过的QEMU来进行,提供了BIOS,PCI总线,USB总线和其他标准设备(如IDE和SCSI硬盘控制器以及网络控制器等)的模拟。KVM将Linux内核转化为Hypervisor,通常情况下支持Linux的硬件设备就可以被KVM支持。
三、QEMU技术简介
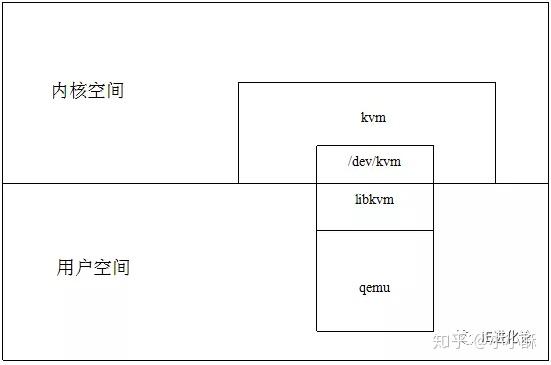
KVM并不是一个完整的模拟器,而只是一个提供了虚拟化功能的内核插件,具体的模拟器工作需要借助QEMU来完成。KVM是Linux kernel的一个模块,可以用命令modprobe去加载KVM模块。加载了模块后,才能进一步通过其他工具创建虚拟机。但仅有KVM模块是远远不够的,因为用户无法直接控制内核模块去作事情,你还必须有一个运行在用户空间的工具才行。这个用户空间的工具,KVM开发者选择了已经成型的开源虚拟化软件 QEMU。QEMU也是一个虚拟化软件,它的特点是可虚拟不同的CPU。比如说在x86的CPU上可虚拟一个Power的CPU,并可利用它编译出可运行在Power上的程序。KVM使用了QEMU的一部分,并稍加改造,就成了可控制KVM的用户空间工具了。所以你会看到,官方提供的KVM下载有两大部分(qemu和kvm)三个文件(KVM模块、QEMU工具以及二者的合集)。也就是说,你可以只升级KVM模块,也可以只升级QEMU工具。这就是KVM和QEMU 的关系。
四、KVM与Xen的技术优劣对比
Xen发展的时间相对较长,理论上应该更成熟,但受限于Citrix未知的战略和其半虚拟化架构;KVM起步的时间相对较晚,但具有后发优势,比如天生支持硬件辅助虚拟化等。在技术路线的选择问题上,需要考虑选型的三大原则:第一,平台,开源是未来软件行业发展的必然趋势,需要选择的是一个更具开放特质的开源平台,谁的开放性更好就选择谁;第二,架构,架构设计的优劣决定后续开发与维护的难度,更决定了性能的优劣;第三,性能,虚拟化是承载客户业务系统的底层平台,没有性能的保障就没有业务虚拟化的可能性。基于这三条选型原则, KVM应该是更佳的虚拟化软件开发的平台。自从Citrix公司将其虚拟化战略重心转移到桌面之后,Xen开源社区的活跃程度迅速降低。
对比Xen, KVM已经被Linux核心组织放入Linux的内核里面,而 Xen是一个外部的Hypervisor程序(虚拟机管理程序),其工作环境的补丁包不能够和Linux内核兼容;另一方面,KVM是Linux的一部分,长期享受着Linux内核技术不断成熟与进步带来的好处,可使用通常的Linux调度器和内存管理,在任何场景下都可以直接进行交互,而不需要修改虚拟化操作系统,这意味着KVM更小更易使用;另外I/O性能方面,KVM也优于Xen。2014年9月Xen被爆出了3个安全漏洞,包括AWS、Rackspace、SoftLayer在内的Iaas提供商均遭受了不同时间停机影响,重启服务对云计算带来的负面影响是无法抹去的。
现如今越来越来的厂商诸如AWS、IBM、Ubuntu、腾讯云、阿里云、华为都逐渐在规划或已经转向KVM,越来越多的虚拟化与云计算玩家向KVM转型,说明了KVM获得了更多的社区支持。而业界包括各大公有云及私有云甚至虚拟化厂商均将技术路线向KVM进行切换更是说明了这一点,未来的趋势也将会是属于KVM的。
五、参考及声明
从AWS转向KVM,再看KVM与XEN的技术路线之争!
https://mp.weixin.qq.com/s/5IhlRot-jiEg3gQ7I6MEbw
虚拟化 - KVM 和 Xen 比较
https://www.cnblogs.com/sammyliu/articles/4389981.html
声明:本文部分文章来源于网络,版权归原作者所有,如有侵权,请与公众号联系删除。
首先要简单介绍下虚拟化,广义的定义是在一台物理机上可以模拟出多台虚拟机(Virtual Machine,简称VM),每个虚拟机中都可以运行一个操作系统(OS)。
Type1:Hypervisor 直接运行在硬件设备上的模式,也叫做 Bare-Metal Hardware Virtualization(裸机虚拟化环境)
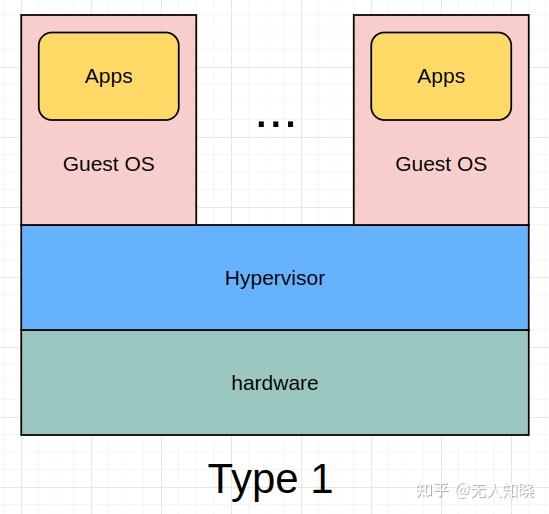
典型的Type1虚拟化有 Xen
Type2:主机托管型,也叫做 Hosted Virtualization (主机虚拟化环境)
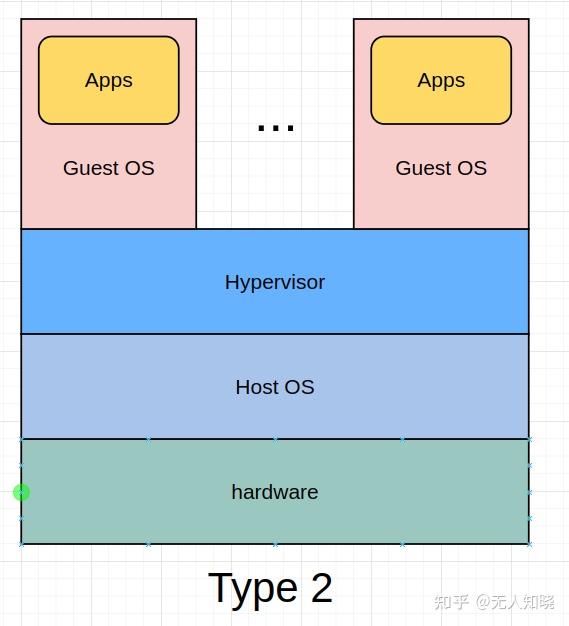
如:Vmware workstations、qemu(kvm方案), QNX hypervisor(目前车载的应用场景), 架构图如下:
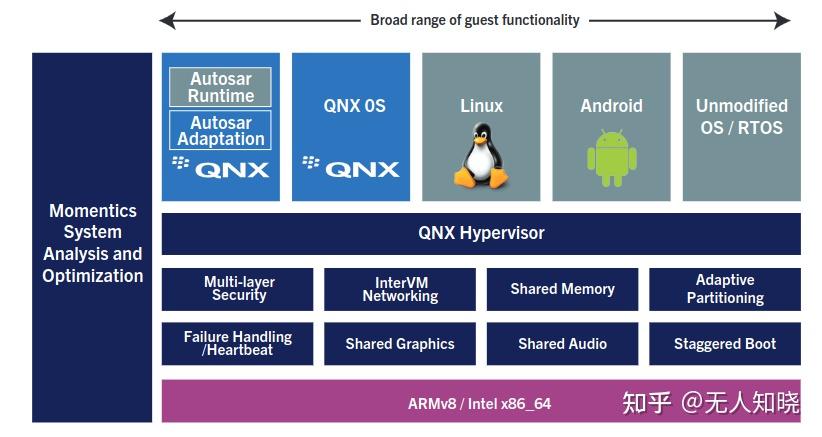
上面的QNX图有些误导,实际上QNX hypervisor 是在QNX OS内的
Type1 型的 Hypervisor 不依赖主机操作系统,其自身具备操作系统的基础功能。设计上更简洁,直接运行于硬件之上,整体代码量和架构更为精简,对内存和存储资源要求更少,可满足功能安全等级要求,也具备进行形式化验证的条件,Type1非常适合自动驾驶系统领域(常说的舱驾一体方案)。
Type2 型 Hypervisor 需要借助宿主操作系统来管理 CPU、内存、网络等资源,由于 Hypervisor 和硬件之间存在一个宿主操作系统,Hypervisor 及 VM 的所有操作都要经过宿主操作系统,所以就不可避免地会存在延迟、性能损耗,同时宿主操作系统的安全缺陷及稳定性问题都会影响到运行在之上的 VM(虚拟机),所以 , Type-2 型 Hypervisor 主要用于对性能和安全要求不高的场合,比如 : 个人 PC 系统。
kvm技术框图:
KVM是Type 2 , KVM是在host os中的一个ko,虽然在性能上做了优化但目前使用kvm的方案还是混合的,部分虚拟化在usersapce空间,CPU和MMU的虚拟化虽然利用kvm做了优化,但是混合技术还是算在Host OS之上;典型的如:QEMU 。
下面还是用一个X86的KVM sample代码来学习下KVM的相关知识,实验环境依赖:
确认使用的测试机环境打开了kvm, 存在节点/dev/kvm,如果没有请检查下kernel config是否打开:
CONFIG_KVM=y
一个虚拟机测试程序分成下面两部分:
/*
* write "Hello"(ASCII) to port 0xf1
* compile:
* as -32 test.S -o test.o
* objcopy -O binary test.o test.bin
*/
start:
mov $0x48, %al
outb %al, $0xf1
mov $0x65, %al
outb %al, $0xf1
mov $0x6c, %al
outb %al, $0xf1
mov $0x6c, %al
outb %al, $0xf1
mov $0x6f, %al
outb %al, $0xf1
mov $0x0a, %al
outb %al, $0xf1
hlt上面一段汇编将Hello的ASCII码写入AL寄存器(RAX寄存器的低8位),每次写入一个ASCII码后,马上利用outb指令写入到地址0xf1

#include <stdio.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <linux/kvm.h>
#include <unistd.h>
#include <sys/mman.h>
#define KVM_DEV "/dev/kvm"
#define MEM_SIZE 4096
int main(void)
{
struct kvm_sregs sregs;
int ret;
int kvmfd = open(KVM_DEV, O_RDWR);
//1. create vm and get the vm fd handler
int vmfd = ioctl(kvmfd, KVM_CREATE_VM, 0);
unsigned char *ram = mmap(NULL, MEM_SIZE, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
//2. load the vm running program to buffer 'ram'
int kfd = open("test.bin", O_RDONLY);
read(kfd, ram, MEM_SIZE);
struct kvm_userspace_memory_region mem = {
.slot = 0,
.guest_phys_addr = 0,
.memory_size = MEM_SIZE,
.userspace_addr = (unsigned long)ram,
};
//3. set the vm userspace program ram to vm fd handler
ret = ioctl(vmfd, KVM_SET_USER_MEMORY_REGION, &mem);
if(ret < 0) {
printf("set user memory region failed\n");
return -1;
}
//4. create vcpu
int vcpufd = ioctl(vmfd, KVM_CREATE_VCPU, 0);
if(vcpufd < 0) {
printf("create vcpu failed\n");
return -1;
}
int mmap_size = ioctl(kvmfd, KVM_GET_VCPU_MMAP_SIZE, NULL);
if(mmap_size < 0) {
printf("get vcpu mmap size failed\n");
return -1;
}
//5. get kvm_run status from vcpu
struct kvm_run *run = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE, MAP_SHARED, vcpufd, 0);
//6. change the vcpu register info, first get then set
ret = ioctl(vcpufd, KVM_GET_SREGS, &sregs);
sregs.cs.base = 0;
sregs.cs.selector = 0;
ret = ioctl(vcpufd, KVM_SET_SREGS, &sregs);
struct kvm_regs regs = {
.rip = 0, //指令寄存器 (RIP)
};
ret = ioctl(vcpufd, KVM_SET_REGS, ®s);
//7. run the vcpu and get the vcpu result
while(1) {
ret = ioctl(vcpufd, KVM_RUN, NULL);
if (ret == -1)
{
printf("exit unknow\n");
return -1;
}
switch(run->exit_reason)
{
case KVM_EXIT_HLT:
puts("KVM_EXIT_HLT");
return 0;
break;
case KVM_EXIT_IO:
putchar(*(((char*)run) + run->io.data_offset));
break;
case KVM_EXIT_FAIL_ENTRY:
puts("entry error");
return -1;
default:
puts("other error");
printf("exit_reason: %d\n", run->exit_reason);
return -1;
}
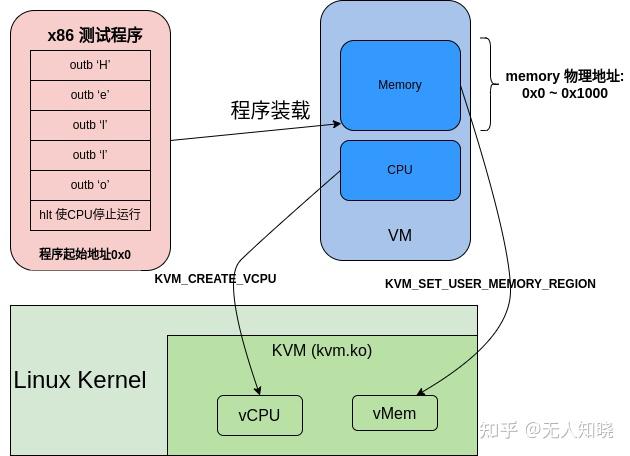
}
}1、打开/dev/kvm获取系统KVM子系统的文件句柄,然后通过这个句柄创建一个虚拟机(VM),并返回一个vmfd的文件句柄,通过这个vmfd可以控制虚拟机的内存,vcpu等
2、分配一个用户空间的内存,然后通过结构体kvm_userspace_memory_region 将内存信息传递给vm, 这一步相当于给虚拟机指定了内存条
3、下一步就是给虚拟机创建一个VCPU了,通过struct kvm_run结构体来在用户空间和内核空间传递VCPU的状态和数据
4、设置VCPU的寄存器信息,在X86平台,段寄存器和控制寄存器等特殊寄存器在kvm_sregs中;通用寄存器信息通过kvm_regs传递;
代码涉及的结构体及宏定义代码在:arch/x86/include/uapi/asm/kvm.h
上面的例子中,虚拟地址及IP还有物理地址都是0,所以虚拟机VCPU运行的时候直接从地址0处取指令开始运行;虚拟机内核向端口写数据会产生KVM_EXIT_IO的退出,表示虚拟机内部读写了端口,在输出了端口数据之后让虚拟机继续执行,执行到最后一个hlt指令时,会产生KVM_EXIT_HLT类型的退出,此时虚拟机运行结束。
all:
as -32 test.S -o test.o
objcopy -O binary test.o test.bin
gcc kvm_sample.c -g -o kvm_sample
上面一个简单的sample程序来自《QEMU/KVM源码解析与应用》一书, 这个例子很好的介绍了一个最简单的虚拟机构成的部分,我这边简单整理了一下,也算是自己在kvm学习的第一课
参考:
https://blackberry.qnx.com/content/dam/qnx/products/hypervisor/hypervisor-product-brief.pdf
兰新宇:虚拟化技术 - 概览 [一]
智能汽车虚拟化(Hypervisor)技术详解_腾讯新闻
KVM再次引爆Type 1与Type 2 hypervisor战争
《QEMU/KVM源码解析与应用》 -- 李强
x86_64汇编之二:x86_64的基本架构(寄存器、寻址模式、指令集概览)_x86_64 如何表示 某个段的地址-CSDN博客
本文基于QEMU-KVM看一下创建虚拟机的大致过程,及其关键机制。
特别喜欢这张图,清晰又简单的勾勒了QEMU、KVM、GEUST三者之间的关系,及它们所处的处理器模式,还有各自包含的重要组件。
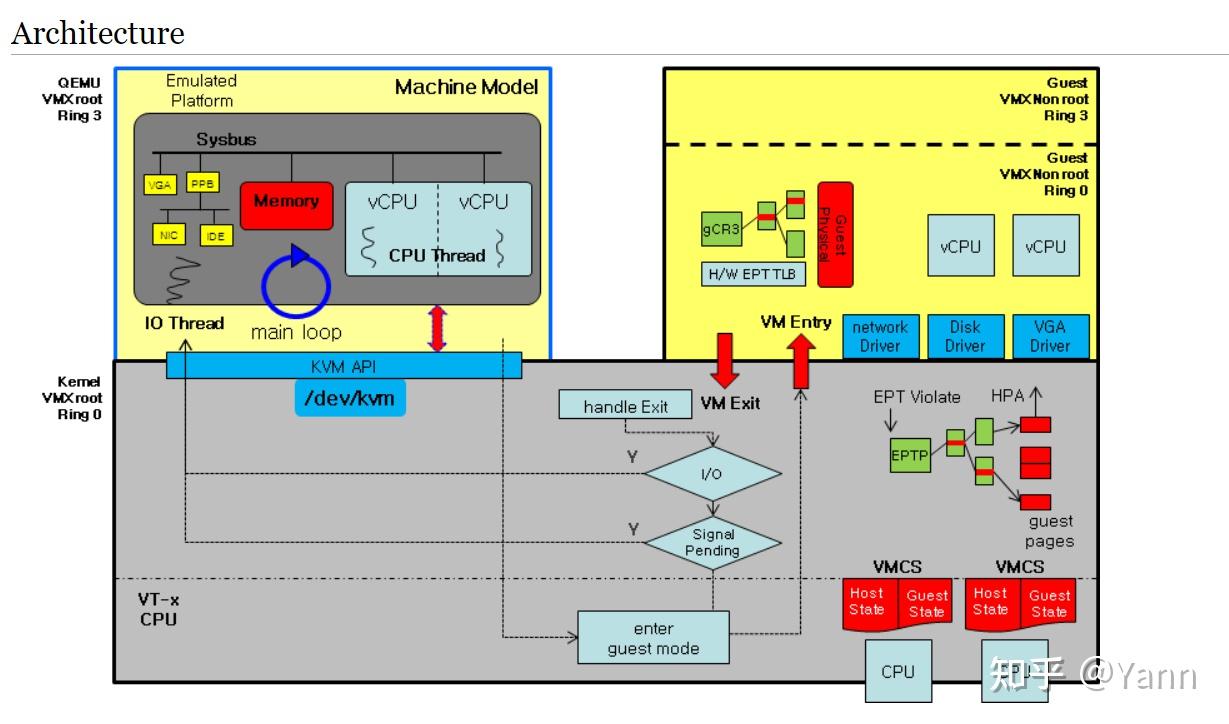
关于模式,Intel处理器的VT-x虚拟化技术,在原有的处理器模式上引入了root mode和non-root mode的概念。上图可以看到KVM和QEMU均运行在VMX root模式(KVM为root ring0,QEMU为root ring3);Guest运行在VMX non-root模式(ring0或ring3)。
关于VM-exit:
观察上图,Guest进出non-root模式有两个通道:VM exit和VM entry。造成VM-exit的情况有多种:
(1) 敏感指令,分两类:一类是必定导致VM-exit(unconditional)的敏感指令,例:CPUID、INVD等;另一类是可通过VMCS的vm-execution控制域配置是否需截获并模拟的(conditional),例如:HLT INVPG WBINVD RDMSR WRMSR IN OUT等;
(2) 外部事件,"中断、NMI" 造成的VM-exit。VMCS的vm-execution控制域中有对应的field来控制是否一定VM-exit。
(3) 各种异常,比方说各种原因的EPT violation:硬件走表碰到未映射的EPT页表;访问MMIO导致的misconfig类型的EPT violation。
(4) 访问MSR(默认全部vm-exit),除非在vm-execution控制域中指定是否用一个msr bitmap来标记哪些MSR的读写产生vm-exit,并在vm exit的handle中模拟访问该MSR的结果,如下
[EXIT_REASON_MSR_READ] = kvm_emulate_rdmsr,
[EXIT_REASON_MSR_WRITE] = kvm_emulate_wrmsr,
举例:kvm_emulate_wrmsr->kvm_set_msr_with_filter->kvm_set_msr_ignored_check->__kvm_set_msr->static_call(kvm_x86_set_msr)
->vmx_set_msr:1.判断并操作各种msr;2.若1中不包含该msr,则kvm_set_msr_common;3.若kvm_set_msr_common中不包含则大概
率是pmu相关的寄存器,调用kvm_pmu_set_msr。关于VM-exit的处理画了张简图:
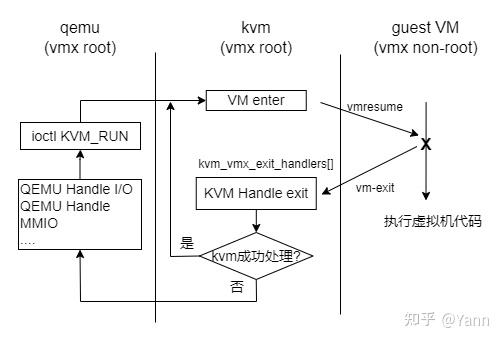
通过上图可以看到,VM-exit的处理会先在kvm中检查并handle,如果kvm处理不了,则返回到用户态进程qemu中,即vcpu的ioctl(KVM_RUN)系统调用返回,再又qemu处理。 qemu中通常处理设备相关的IO操作。
虚机的创建由QEMU发起,通过OOB的编程模型实现了对计算机各部分硬件的模拟,根据qemu接收到的参数将其组织成指定规格的虚机。比方说主板,用户可通过-machine参数指定主板是i440x或q35,再或者通过-driver和-device创建一个virtio设备。
- qemu程序主干
main
qemu_init(argc, argv, envp); //重要函数1:创建虚拟机
qemu_main_loop(); //重要函数2:qemu的事件循环机制
qemu_cleanup();如代码,函数1和函数2都非常重要,且内容很多。本文重点介绍函数1:qemu_init() 虚机的创建。下次介绍函数2,事件循环机制。
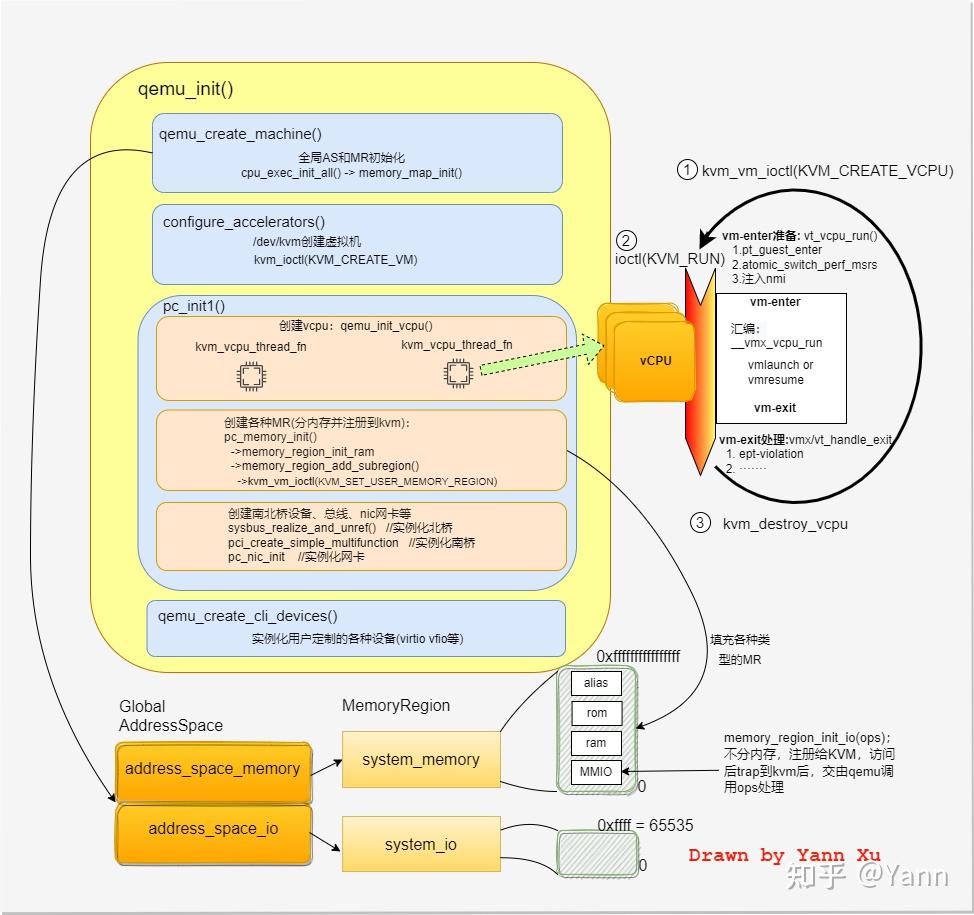
- qemu_init函数主干
qemu_init()函数大体划分为三部分,对应代码中的[1][2][3][4],分别是:
[1]为虚机的地址空间分配全局数据结构。
[2]根据虚机的加速器种类(本文为kvm),创建虚机的外壳(确定汽车品牌,通过ioctl向kvm车厂申请个车的外壳)
[3]根据虚机的machine类型初始化主板上的"必要设备",如桥设备 网卡设备,及总线并创建vcpu线程(选定汽车底盘,并搭建传动轴、方向盘,同时安装vcpu发动机)。
[4]根据qemu的入参,定制用户所需的设备,比如virtio、vfio、fw_cfg等(根据用户的需求,定制汽车的座椅、敞篷、车灯、内饰等)。
qemu_init
qemu_add_opts //qemu中定义了大量的QemuOptsList来表示所支持的参数,通过定义可看到描述,类似meson option
qemu_init_subsystems //初始化各个子系统
for(switch-case) //提取qemu参数
[1]qemu_create_machine
cpu_exec_init_all //qemu内存布局初始化
io_mem_init
memory_map_init
[2]configure_accelerators //配置使用kvm加速类 ##do_configure_accelerator->do_configure_accelerator->acc->init_machine->... (早期MODULE_INIT_QOM中将kvm的回调设置为init_machine=kvm_init)
kvm_init //创建虚拟机
kvm_ioctl(KVM_CREATE_VM)
kvm_arch_init
kvm_confidential_guest_init //如果是AMD SEV或Intel TDX则进行额外的初始化
sev_kvm_init
tdx_kvm_init
tdx_machine_done_notify
tdx_finalize_vm //TD guest的内存分配和normal guest一样. 转为private的奥秘在此
kvm_memory_listener_register(kvm_memory_listener)
memory_listener_register(kvm_io_listener)
qmp_x_exit_preconfig //--preconfig指初始化VM前暂停VM并进入preconfig状态,然后QMP命令单步启动
qemu_init_board
machine_run_board_init
machine_class->init(machine) //主板类型为i440x(又称pc),可通过-machine(或-M)切换
[3]pc_init1 //i440x(又称pc)主板上的初始化; q35的话是pc_q35_init
[3.1]x86_cpus_init
for(cpu_nr)x86_cpu_new //循环创建指定数量的vcpu(先创建vcpu线程,然后ioctl创建vcpu,最后ioctl启动vcpu)
x86_cpu_realizefn
cpu_exec_realizefn
...host_cpu_realizefn //accel_cpu_realizefn->cpu_realizefn->kvm_cpu_realizefn->...
mce_init
qemu_init_vcpu //创建一个入口为kvm_vcpu_thread_fn的线程
create_vcpu_thread
kvm_start_vcpu_thread //创建vcpu线程,线程名为"CPU %d/KVM"
qemu_thread_create //调用pthread_create创建vcpu线程,入口为kvm_vcpu_thread_fn
(kvm_vcpu_thread_fn) //kvm_vcpu_thread_fn是vcpu的本体,后面重点分析 ^_^
[3.2]sysbus_realize_and_unref //实例化一个i440fx北桥芯片组
[3.3]pc_memory_init //初始化内存、io、加载kernel镜像等,见[补充1]
(1)初始化system_memory MR
*分配alias MR:ram_below_4g,并调用memory_region_init_alias初始化并分配内存
*分配alias MR:ram_above_4g,并调用memory_region_init_alias初始化并分配内存
*将以上两个MR作为sub MR加入system_memory MR中,memory_region_add_subregion
*将新分配的内存region注册到guest的E820表中,e820_add_entry
(2)初始化system_memory MR
*分配device的MR:device-memory,并调用memory_region_init初始化并分配内存
*将device的MR作为sub MR加入system_memory MR中,memory_region_add_subregion
(3)初始化system_memory MR
*分配并初始化cxl的MR
(4)初始化rom MR
memory_region_init_ram
memory_region_add_subregion ->..->..MEMORY_LISTENER_CALL_GLOBAL(commit)
kvm_region_commit
kvm_set_phys_mem
kvm_set_user_memory_region
kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem)
e820_add_entry
[3.3]pci_create_simple_multifunction //创建一个南桥芯片组PIIX3
pc_nic_init //在指定的总线上创建一个pci网卡
pci_nic_init_nofail
pci_realize_and_unref
phase_advance(PHASE_MACHINE_INITIALIZED) //至此初始化基本完成
[4]qemu_create_cli_devices
qemu_opts_foreach(qemu_find_opts("fw_cfg"), parse_fw_cfg)
qemu_opts_foreach(qemu_find_opts("device"), device_init_func)补充1:qemu中有两个全局的AddressSpace (address_space_memory + address_space_io),他俩分别包含两个root指针,指向两个全局memory region (system_memory + system_io),这两个MR会有alias MR和sub MR,代码中的pc_memory_init()围绕这块展开。
补充2:代码针对的是machine类型为i440x类型的pc,硬件拓扑如下。
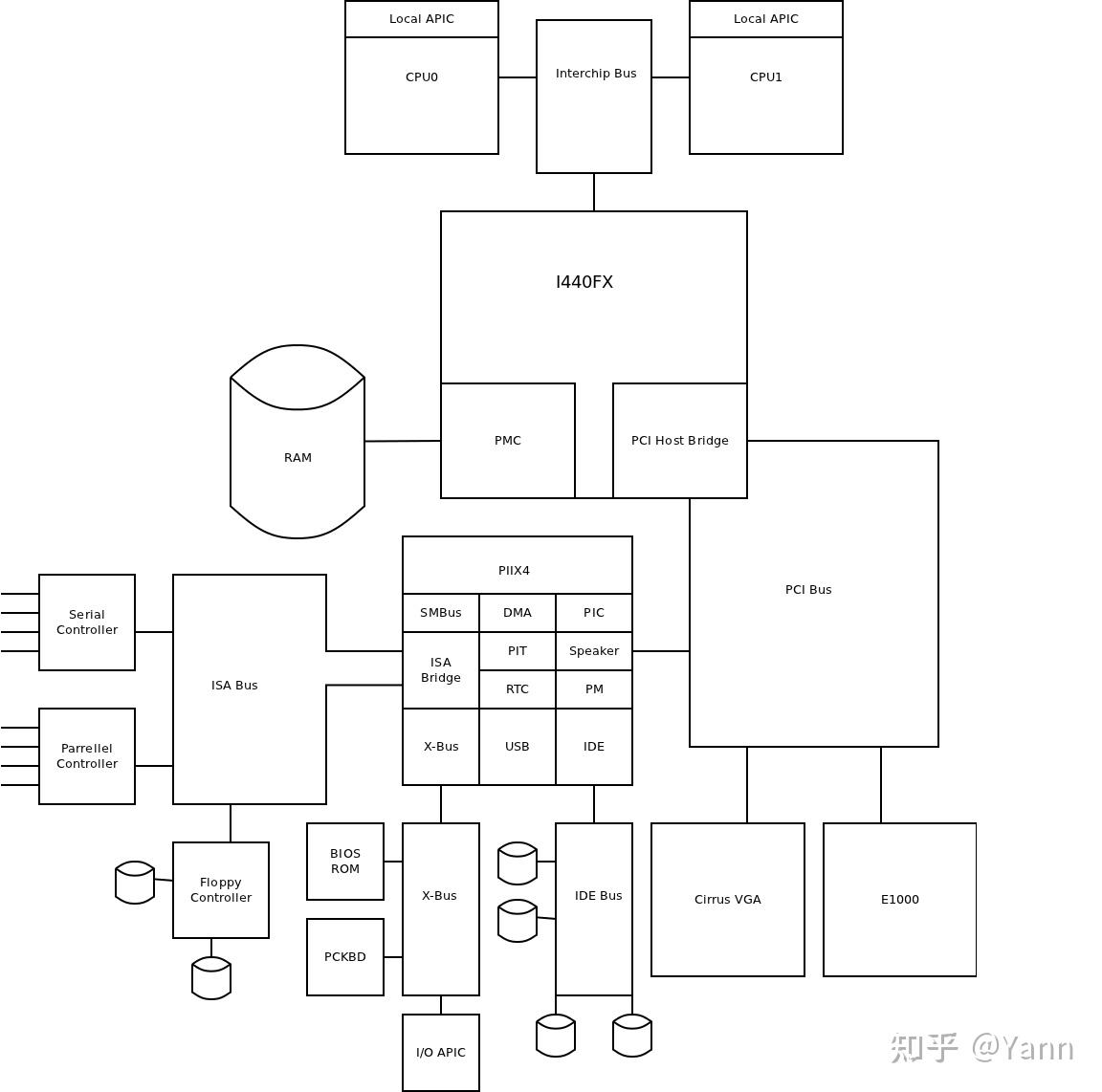
补充3:根据qemu_init( )创建虚机的整套流程画了幅图:
左侧蓝框是创建虚机的4步;右侧循环是vcpu线程的关键3步;
上面我们说到在初始化主板的时候会创建vcpu线程。这里我们展开看一下vcpu的本体:
pc_init1->x86_cpus_init...->kvm_vcpu_thread_fn()
kvm_vcpu_thread_fn //线程入口
kvm_init_vcpu
kvm_arch_pre_create_vcpu //创建TDX vcpu前特有的准备工作
tdx_pre_create_vcpu
tdx_vm_ioctl(KVM_TDX_INIT_VM) //重要.kernel操作包括 TDH_MNG_CREATE TDH_MNG_KEY_CONFIG TDH_MNG_ADDCX TDH_MNG_INIT
kvm_get_vcpu
从stop的vcpu缓存链表中取vcpu //先从vcpu缓存中遍历,看有没有需要的vcpu
//commit:4c055ab54fa vcpu被destroy的时候是被加入vcpu的缓存链表的
kvm_vm_ioctl(KVM_CREATE_VCPU) //若vcpu缓存中没有所需vcpu,则通过vm的ioctl创建vcpu。详见kvm章节分析
kvm_arch_init_vcpu //TDX VM的cpuid相关
kvm_init_cpu_signals
cpu_thread_signal_created
qemu_guest_random_seed_thread_part2
do-while //除非vcpu被unplug或stop,否则无限循环kvm_cpu_exec
kvm_cpu_exec
do-while //不断循环。通过ioctl执行vm-entry进入kvm,若vm-exit返回到qemu则根据退出原因处理事务。
kvm_arch_pre_run //进入kvm前的准备
kvm_vcpu_ioctl(KVM_RUN) //通过vcpu的ioctl调用vm entry进入kvm。详见kvm章节分析
kvm_arch_post_run //从kvm退出后的收尾工作,即vm-exit后的收尾操作
switch-case //根据导致vm-exit的原因,通过switch-case分别处理。
KVM_EXIT_IO:kvm_handle_io //若是访问IO导致的vm-exit则调用kvm_handle_io由qemu处理IO
...
kvm_destroy_vcpu //从上面的死循环中退出了,销毁vcpu主要做了两件事:1.通过ioctl()创建vcpu;2.进入循环,不断的调用ioctl去run vcpu,处理kvm无法handle的vm-exit(例如 kvm_handle_io)
根据上面大图知道了qemu的初始化分为三大块,以及根据代码知道各种device/总线等的初始化在pc_init1中创建,但是没找到启动参数里的virtio设备在什么时候创建的。通过gdb看一下,在virtio_device_realize函数上打了断点:
(gdb) bt
#0 virtio_device_realize (dev=0x5555576330d0, errp=0x7fffffffd660) at https://www.zhihu.com/topic/hw/virtio/virtio.c:3628
#1 0x0000555555c9c91b in device_set_realized (obj=<optimized out>, value=<optimized out>, errp=0x7fffffffd800) at https://www.zhihu.com/topic/hw/core/qdev.c:510
#2 0x0000555555ca08ac in property_set_bool (obj=0x5555576330d0, v=<optimized out>, name=<optimized out>, opaque=0x555556802620, errp=0x7fffffffd800) at https://www.zhihu.com/topic/qom/object.c:2285
#3 0x0000555555ca3a3b in object_property_set (obj=obj@entry=0x5555576330d0, name=name@entry=0x555555f989b7 "realized", v=v@entry=0x55555763d820, errp=errp@entry=0x7fffffffd800)
at https://www.zhihu.com/topic/qom/object.c:1420
#4 0x0000555555ca6ef3 in object_property_set_qobject
(obj=obj@entry=0x5555576330d0, name=name@entry=0x555555f989b7 "realized", value=value@entry=0x55555763d760, errp=errp@entry=0x7fffffffd800) at https://www.zhihu.com/topic/qom/qom-qobject.c:28
#5 0x0000555555ca4068 in object_property_set_bool (obj=0x5555576330d0, name=0x555555f989b7 "realized", value=<optimized out>, errp=0x7fffffffd800) at https://www.zhihu.com/topic/qom/object.c:1489
#6 0x00005555559ce04e in pci_qdev_realize (qdev=<optimized out>, errp=<optimized out>) at https://www.zhihu.com/topic/hw/pci/pci.c:2124
#7 0x0000555555c9c91b in device_set_realized (obj=<optimized out>, value=<optimized out>, errp=0x7fffffffda30) at https://www.zhihu.com/topic/hw/core/qdev.c:510
#8 0x0000555555ca08ac in property_set_bool (obj=0x55555762ad00, v=<optimized out>, name=<optimized out>, opaque=0x555556802620, errp=0x7fffffffda30) at https://www.zhihu.com/topic/qom/object.c:2285
#9 0x0000555555ca3a3b in object_property_set (obj=obj@entry=0x55555762ad00, name=name@entry=0x555555f989b7 "realized", v=v@entry=0x555557637ac0, errp=errp@entry=0x7fffffffda30)
at https://www.zhihu.com/topic/qom/object.c:1420
#10 0x0000555555ca6ef3 in object_property_set_qobject
(obj=obj@entry=0x55555762ad00, name=name@entry=0x555555f989b7 "realized", value=value@entry=0x555557633690, errp=errp@entry=0x7fffffffda30) at https://www.zhihu.com/topic/qom/qom-qobject.c:28
#11 0x0000555555ca4068 in object_property_set_bool (obj=obj@entry=0x55555762ad00, name=name@entry=0x555555f989b7 "realized", value=value@entry=true, errp=errp@entry=0x7fffffffda30)
at https://www.zhihu.com/topic/qom/object.c:1489
#12 0x0000555555c9d3e0 in qdev_realize (dev=dev@entry=0x55555762ad00, bus=bus@entry=0x555556c5e430, errp=errp@entry=0x7fffffffda30) at https://www.zhihu.com/topic/hw/core/qdev.c:292
#13 0x0000555555a8bd53 in qdev_device_add_from_qdict (opts=opts@entry=0x555557629ce0, from_json=from_json@entry=false, errp=0x7fffffffda30, errp@entry=0x555556765518 <error_fatal>)
at https://www.zhihu.com/topic/softmmu/qdev-monitor.c:714
#14 0x0000555555a8c1b5 in qdev_device_add (opts=0x5555567ff0d0, errp=errp@entry=0x555556765518 <error_fatal>) at https://www.zhihu.com/topic/softmmu/qdev-monitor.c:733
#15 0x0000555555a90ec3 in device_init_func (opaque=<optimized out>, opts=<optimized out>, errp=0x555556765518 <error_fatal>) at https://www.zhihu.com/topic/softmmu/vl.c:1152
#16 0x0000555555e26cc1 in qemu_opts_foreach
(list=<optimized out>, func=func@entry=0x555555a90eb0 <device_init_func>, opaque=opaque@entry=0x0, errp=errp@entry=0x555556765518 <error_fatal>) at https://www.zhihu.com/topic/util/qemu-option.c:1135
#17 0x0000555555a9369a in qemu_create_cli_devices () at https://www.zhihu.com/topic/softmmu/vl.c:2573
#18 qmp_x_exit_preconfig (errp=<optimized out>) at https://www.zhihu.com/topic/softmmu/vl.c:2641
#19 0x0000555555a975ac in qmp_x_exit_preconfig (errp=<optimized out>) at https://www.zhihu.com/topic/softmmu/vl.c:2635
#20 qemu_init (argc=<optimized out>, argv=<optimized out>) at https://www.zhihu.com/topic/softmmu/vl.c:3648
#21 0x000055555587c0dd in main (argc=<optimized out>, argv=<optimized out>) at https://www.zhihu.com/topic/softmmu/main.c:47
整理一下:
main
qemu_init
qmp_x_exit_preconfig
qemu_create_cli_devices
qemu_opts_foreach(qemu_find_opts("device"),device_init_func, NULL, &error_fatal)
device_init_func
qdev_device_add
qdev_device_add_from_qdict
qdev_realize
object_property_set_bool
object_property_set_qobject
object_property_set
property_set_bool
device_set_realized
pci_qdev_realize
object_property_set_bool
object_property_set_qobject
object_property_set
property_set_bool
device_set_realized
virtio_device_realize //创建vritio设备这调用栈是真深啊,直接翻代码没找到也正常。
每台虚机对应一个qemu进程,qemu进程又会包含vcpu线程,vnc线程,热迁移线程等等。其中vcpu线程和vnc线程都会在qemu_init()创建虚机时被创建,热迁移线程会在hmp或qmp收到热迁指令时创建(I/O thread监听指令事件)。除了以上,qemu主进程会进入一个loop作为I/O thread监听各种各样的事件(对应代码qemu_main_loop),下图是qemu的线程模型的overview:
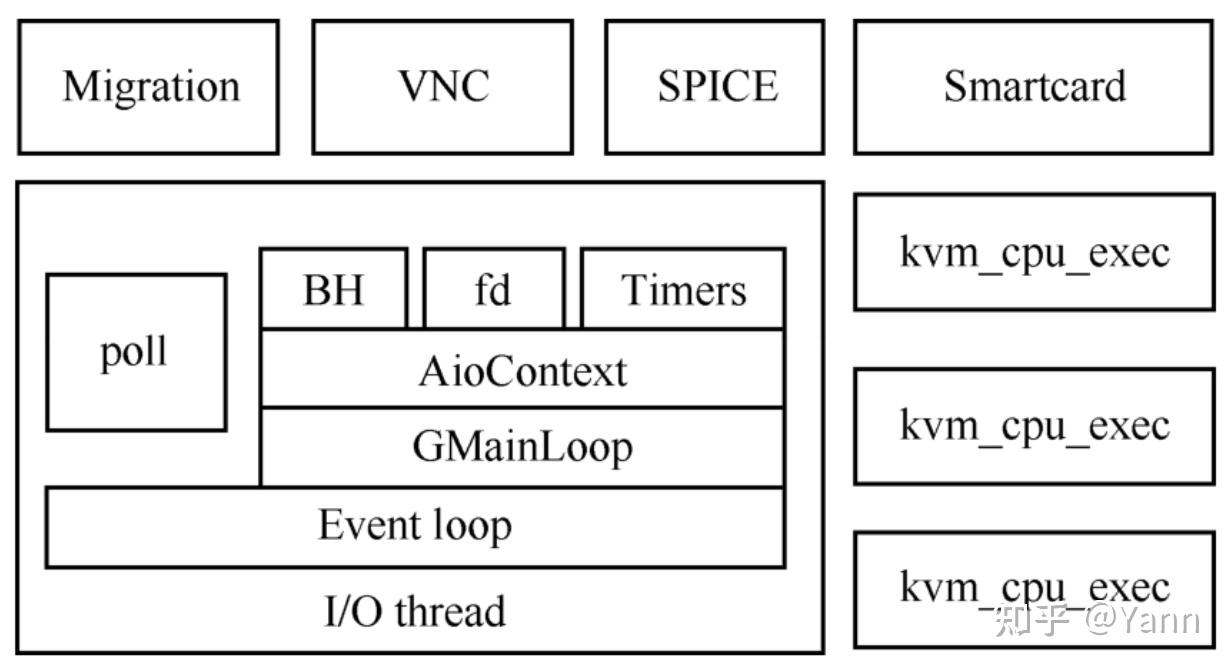
QEMU的线程模型利用了gmainloop机制,不过仔细阅读主进程这部分代码时会发现qemu并非原封不动使用,qemu也定义了自己的事件源AioContext(本质是GSource的拓展版,看结构体定义是GSource套壳),基于AioContext定义了两个事件源qemu_aio_context和iohandler_ctx。iohandler_ctx用来监听各种事件,qemu_aio_context用来监听块设备的异步I/O请求。这里以AioContext类型的iohandler_ctx的创建和使用举例:
signal事件就是依附于iohandler_ctx的,其创建和添加过程如下:
qemu_init
qemu_init_main_loop
qemu_signal_init
qemu_signalfd 【1】//为当前进程创建一个能接收信号的fd,并返回fd
qemu_set_fd_handler
iohandler_init 【2】//分配一个名为iohandler_ctx的AioContext变量(gsource套壳)
aio_context_new
aio_set_fd_handler 【3】//将signal的fd添加给iohandler_ctx,并设置其sigfd读事件的回调为sigfd_handler,写事件回调为NULL
g_source_add_poll //可见底层还是gmainloop机制的API上面我们看到了virtio设备的实例化过程。这里本想以virtio-blk为例看一下aio在virtio设备的实现中扮演什么角色,但限于内容较多,有空单独写一篇,这里说下基本流程:
guest OS的virtio前端准备好IO buffer后,然后前端访问特定的MMIO(QEMU提前为virtio设备设置好的)触发misconfig EPT violation类型的vm-exit,并退到KVM,KVM用ioeventfd机制通知QEMU说有IO buffer填好了,main loop检测到对应的ioevent后dispatch对应的callback处理。处理完成后QEMU通过irqfd注入中断给Guest通知其已经IO buffer已经处理完成。
原创文章,转载和引用请注明出处。
Yann Xu
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/47468.html