
Redis(Remote Dictionary Server),远程词典服务器,是一个基于内存的键值型Nosql数据库。
特征:
键值型,value支持多种不同的数据结构,功能丰富
单线程,每个命令具备原子性
低延迟,速度快(基于内存,IO多路复用,良好的编码)
支持数据持久化
支持主从集群、分片集群
支持多语言客户端
安装完成后设置开机自启
redis-cli [options] [commands]
options(选择):
常用的有:-h 127.0.0.1 指定要连接的redis的IP地址,默认是127.0.0.1
-p 6379 :指定节点的端口,默认是6379
-a 123456:指定其访问密码
数据结构介绍:redis是一个key-value数据库,key一般是String类型,但是value类型多种多样
String Hash List Set SortedSet 是五个基本类型
GEO BitMap HyperLog等是特殊类型
通用命令(generic)
常用的有KEYS:查看符合模板的所有key,不建议再生产环境设备上使用
DEL:删除一个指定的key
EXISTS:判断一个key是否存在
EXPIRE:给一个key'设置有效期,有效期到时该key被自动删除
TTL:查看一个key的剩余有效期
String类型
分为三大类:string(普通字符串)、int(整数类型,可以自增自减)、float(浮点类型,可以自增自减),三者底层都是用字节数组去存储,只不过编码方式不同。字符串类型的最大空间不能超过512m。
常见命令:SET:添加或修改
GET:根据key获取value
MSET:批量添加
MGET:根据多个key得到多个value
INCR:让一个整形自增1
INCRBY:自增并指定步长
INCRBYFLOAT:浮点型数字自增,一定要指定步长
SETNX:添加一个,如果不存在才添加
SETEX:添加一个,并指定有效期
key的结构
redis的key允许多个单词形成层级结构,单词之间用“:”隔开
Hash类型
也叫做散列,value是一个无序字典。类似java的hashmap
hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD

List类型
与java中LinkedList类似,可以看成一个双向链表结构。既可以支持正向检索也可以支持反向检索
特征:有序、元素可重复、插入和删除快、查询速度一般


Set类型
与java中的hashset类似,可以看作是一个value为null的hashmap
特征:无序、元素不可重复、查找快、支持交集、并集、差集等功能

SortedSet类型
他的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(skiplist)加hash表。
特性:可排序、元素不重复、查村速度快
由于其可排序特性,经常用来实现排行榜这样的功能。

快速入门:1、引入依赖 2、建立连接 3、测试string 4、释放资源
Jedis连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此推荐使用连接池代替直连。
SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成。


步骤:1、引入依赖 2、配置文件 3、注入RedisTemplate 4、编写测试
SpringDataRedis的序列化方式
RedisTemplate可以接受任意object作为值写入Redis,不过写入前会把其序列化成字节形式,默认是采用JDK序列化,得到的结果可读性差、占用内存较大

什么是缓存?缓存是数据交换的缓冲区(称作Cache),是存储数据的临时地方,一般读写性能较高。
缓存的作用?1、降低后端负载 2、提高读写效率,降低响应时间
缓存的成本?1、数据一致性成本 2、代码维护成本 3、运维成本
内存淘汰:
不用自己维护,利用redis的内存淘汰机制,当内存不足时自动淘汰部分数据。下次查询时更新缓存。
一致性:差
维护成本:无
超时剔除:
给缓存数据添加TTL时间,到期后自动删除缓存。下次查询时更新缓存。
一致性:一般
维护成本:低
主动更新:
编写业务逻辑,再修改数据库的同时,更新缓存。
一致性:好
维护成本:高




客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案:1、缓存空对象(优点:实现简单,维护方便 缺点:额外的内存消耗,可能造成短期的不一致)
2、布隆过滤(优点:内存占用较少,没有多余key 缺点:实现复杂、存在误判可能)

同一时段大量的缓存key同时失效或者reids服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:1、给不同的key的TTL添加随机值
2、利用Redis集群提高服务的可用性
3、给缓存业务添加降级限流策略
4、给业务添加多级缓存
也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较为复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
解决方案:1、互斥锁(优点:没有额外的内存消耗、保证一致性、实现简单 缺点:线程需要等待,性能受影响、可能有死锁风险)
2、逻辑过期(优点:线程无需等待,性能较好 缺点:不保证一致性、有额外内存消耗、实现复杂)
********************************
待补充
********************************
超卖问题是一个典型的多线程安全问题,针对这一问题的常见解决方案就是加锁:
悲观锁
认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行。
例如Synchronized、Lock都属于悲观锁
乐观锁
认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时去判断有没有其他线程对数据做了修改。
(如果没有修改则认为是安全的,自己才更新数据)
(如果已经被其他线程修改说明发生了安全问题,此时可以重试或异常)
方法:1、版本号法,在表中加一个字段(版本),每次更改之前都要判断版本号是否被修改
2、CAS法(Compare and Set)
将原本就有的字段作为版本号
在单机模式下加锁可以解决一人一单的安全问题,但是在集群模式下就不行了。
分布式锁
满足分布式系统或集群模式下多进行可见并且互斥的锁
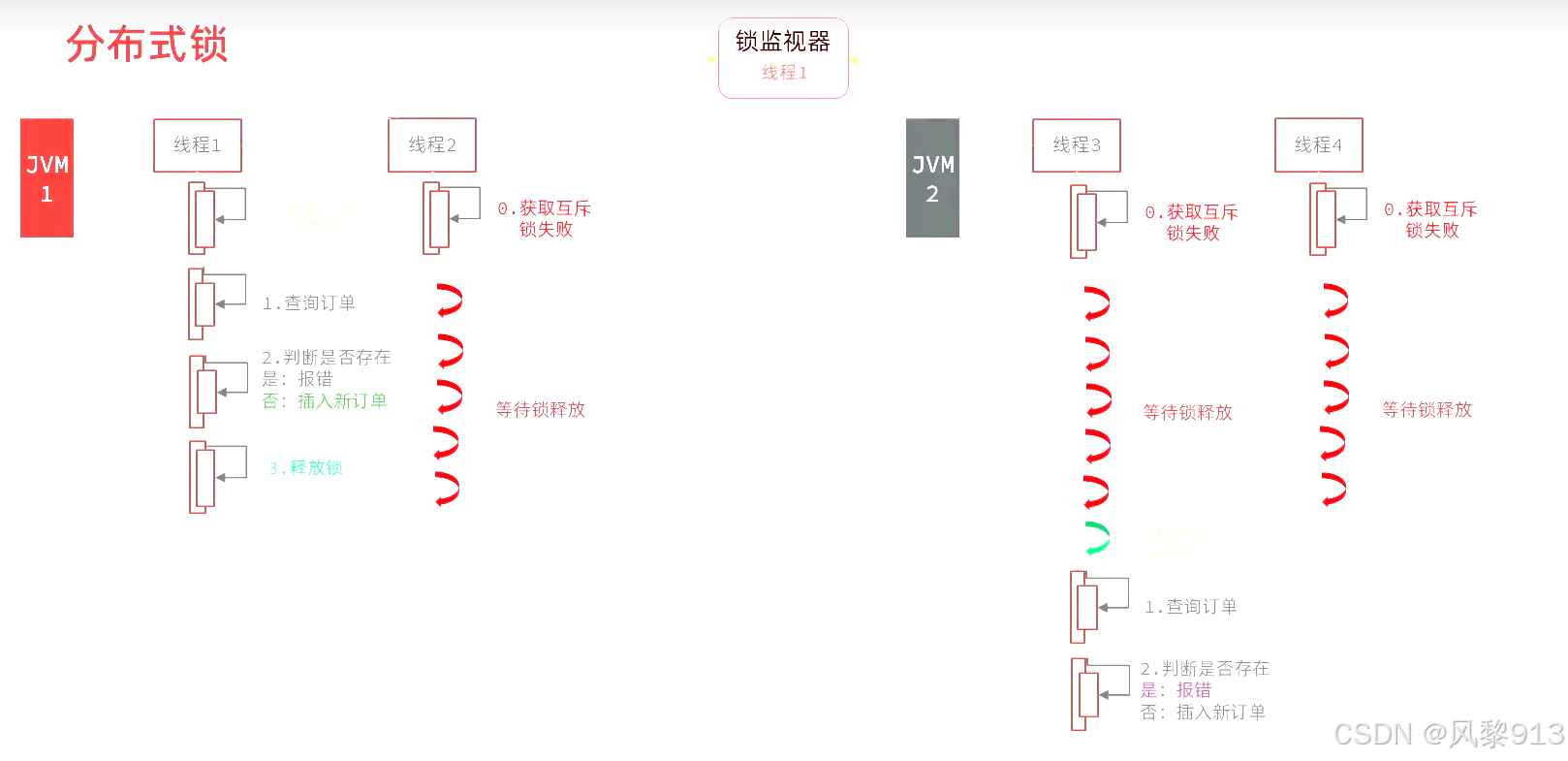
特点:多进程可见、互斥、高可用、高性能、安全性
分布式锁的核心是多进程之间的互斥,常用的方式有三种:
好
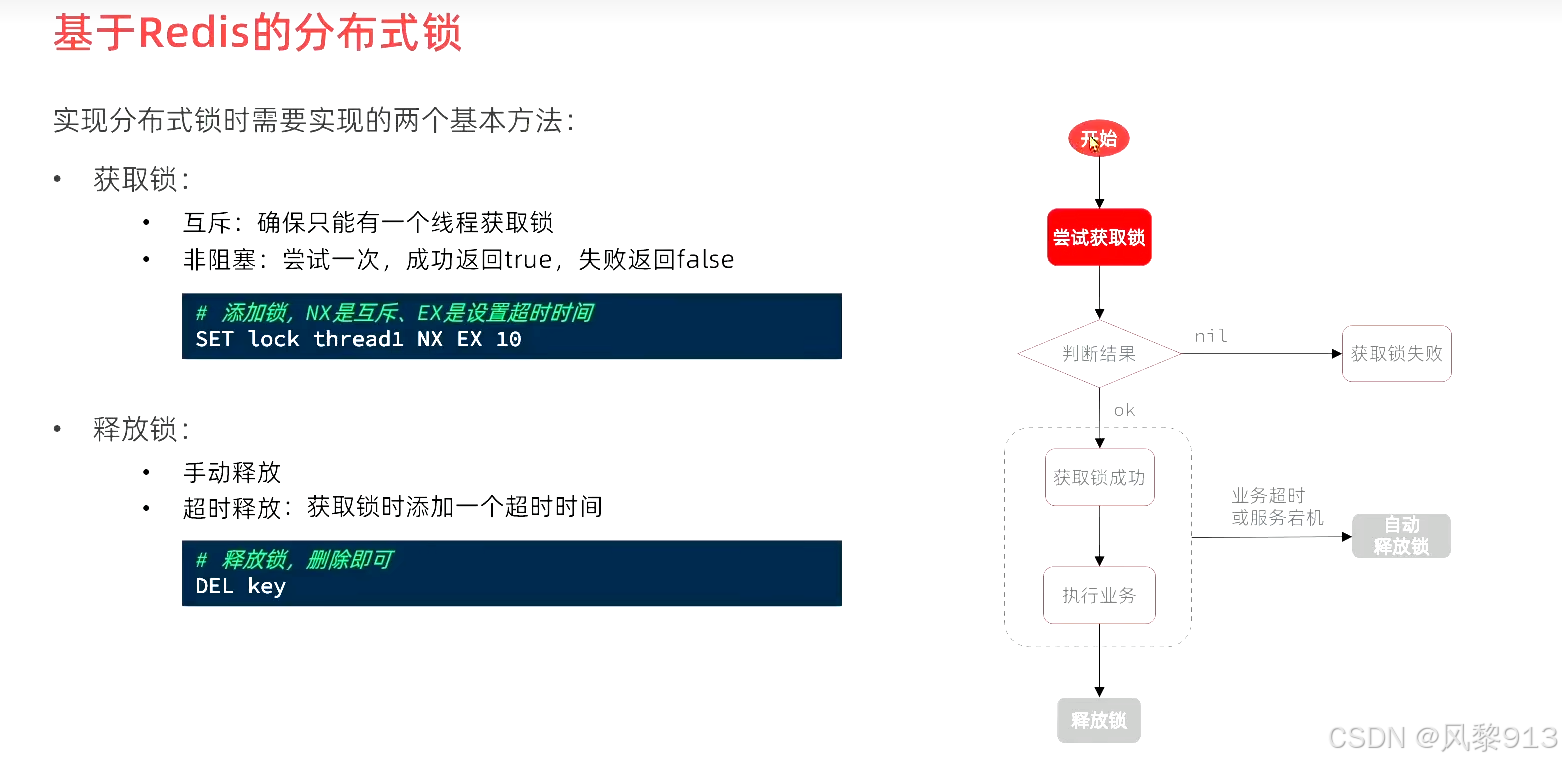
基于Redis的分布式锁
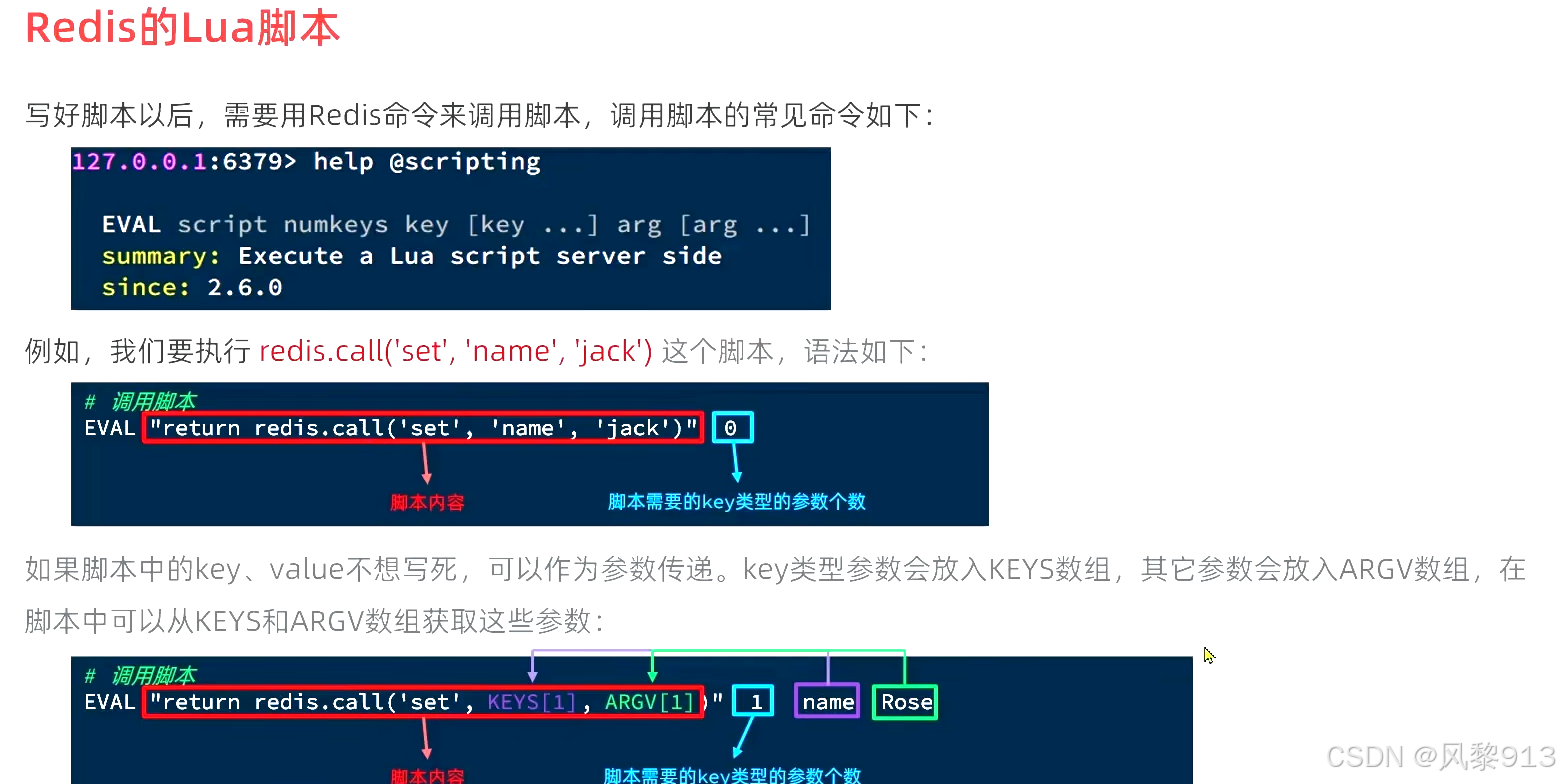
Redis的Lua脚本
在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。Lua是一种编程语言。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/47606.html