
先列出主要观点,有时间再补充细节:
“学习Linux内核”对不同的人有不同的含义,学习方法、侧重点、投入的精力也大不相同。我大致分三类:reader、writer、hacker。reader 就是了解某个功能在内核的大致实现 how does it work,一般不关心某些极端情况下(内存不足、受到攻击)的处理方法,对于看不懂的地方也可以跳过。我自己最多算半个 reader,只看我感兴趣的一小部分代码(我只关心 TCP 收发数据,不管 IP routing/forwarding/fragment 等,更不会去关心 ethernet 层),而且读一个函数一般只看主干(happy path),不管 security/debugging/tracing,经常忽略错误处理分支。writer 是给内核加feature和改bug的人,需要更进一步的知识,写代码要考虑 how not to break it(哪些地方需要加锁,按照什么顺序加锁以避免死锁,如何正确释放分配的资源等等)。hacker 是通过分析代码找出安全漏洞并加以利用的人,研究 how to break it,读代码恐怕更注意找出error handling分支没有覆盖的case。
内核向用户态提供的接口很稳定,但是内核的具体实现变化很快,你深入钻研获得的知识很容易就过时。比方说 Linux 的 TCP 实现在2015年3月新加了 TCP_NEW_SYN_RECV 这个非标准的 TCP state,同年6月发布的 kernel 4.1 才开始用它。如果你学的是一年前的 kernel,那么建立TCP连接这方面的细节知识对于今年发布的 Ubuntu 16.04 可能已经过时了。
Linux内核的编码风格不值得效仿。比如 tcp_v4_rcv 这个函数,有很多 goto:
tcp_ipv4.c [linux/net/ipv4/tcp_ipv4.c]
Linux内核的一些做法在 C 语言中是合理的(比方说用包含函数指针的各种 xxx_ops struct 来手工实现虚函数表,通过控制 struct 内存布局来模拟继承:tcp_sock 继承 inet_connection_sock 继承 inet_sock 继承 sock 继承 sock_common),在其他高级语言中往往有更简便的实现方式,不必生搬硬套。遇到 xxx_ops->some_func(arg) 这种代码,思路容易断线,这个 xxx_ops 到底指向哪个具体实现?最好能把代码跑起来,用调试器单步跟踪,一下子就定位到了 callee。当然,读 OO 代码也会遇到这个困难,传进来的这个 interface 在运行时到底是哪份实现?读 Python 代码就更难了,函数参数光有个名字,连 type 都没有。
Linux内核比较注重代码的通用性和复用性,要照顾那些虽然你用不到但少数人会用的需求。通用性方面,虽然现在大家都用以太网,但是网络协议栈的代码还在支持 FDDI、Token Ring(从 3.5 版起已删除)、ATM 等,偶尔会扰乱视线,更在原本简单直接的做法上增加间接层,加大了理解代码的负担。复用性方面,从 3.17 版开始,IPv4 和 IPv6 共享同一个 tcp_conn_request() 函数[tcp: add tcp_conn_request · torvalds/linux@1fb6f15 · GitHub]。原来的做法是各自有 tcp_v4_conn_request() 和 tcp_v6_conn_request(),新合并的 tcp_conn_request() 为了处理 v4/v6 的不同情况,用了一个 struct tcp_request_sock_ops* 参数,这代码读起来就比原来绕了。虽然我不关心 IPv6 的实现,但读代码的时候却不能排除其干扰。
Linux内核广泛采用的侵入式数据结构设计恐怕很难应用到一般程序开发中。基本上是个高维十字链表,一个节点(struct)可以同时位于多个hash/list/tree中。
如果你本身就要从事内核开发,那么以上这些都不是问题。对于这用户态写server的人,学内核的目的是什么,学到的知识能不能/要不要/如何用到日常开发中,这是值得思考的。
同样的情况也出现在 Java 开发者身上,一般的 Java 程序员要不要读 JVM 的实现?我记得 @RednaxelaFX 对此有过精彩的论述,我完全同意他的看法。特别是当你功力不够时,强行去读源码,结果读错了地方(一个函数有多个实现,你读的那个其实没有被调用,甚至没有被编译),造成了错误的认识,回头来还跟人争论说JVM/kernel里是如何如何实现的,那还不如不读。
逢人就推荐阅读 Linux 内核源码,就像向每个学数据结构的人推荐 TAOCP 一样,是中文网络上特有的现象,我对此是不赞成的。(前几年还有一问C++网络编程就推荐ACE库的现象,现在少多了。)
还是不同层次的问题……
一个网络包从应用程序A发到另一台电脑上的应用程序B,需要经历:
- 从A的业务代码到A的软件框架
- 从A的软件框架到计算机的操作系统内核
- 从A所在计算机的内核到网卡
- 从网卡经过网线发到交换机等设备,层层转发,到达B所在计算机的网卡
- 从B所在计算机的网卡到B所在计算机的内核
- 从B所在计算机的内核到B的程序的用户空间
- 从B的软件框架到B的业务代码
这个层级关系就像是过程调用一样,前一级调用后一级的功能,后一级返回一个结果给前一级(比如:成功,或者失败)。只有在单独一级的调用上,可以说同步还是异步的问题。所谓同步,是指调用协议中结果在调用完成时返回,这样调用的过程中参与双方都处于一个状态同步的过程。而异步,是指调用方发出请求就立即返回,请求甚至可能还没到达接收方,比如说放到了某个缓冲区中,等待对方取走或者第三方转交;而结果,则通过接收方主动推送,或调用方轮询来得到。
从这个定义中,我们看,首先1和7,这取决于软件框架的设计,如果软件框架可以beginXXX,然后立即返回,这就是一种异步调用,再比如javascript当中的异步HTTP调用,传入参数时提供一个回调函数,回调函数在完成时调用,再比如协程模型,调用接口后马上切换到其他协程继续执行,在完成时由框架切换回到协程中,这都是典型的异步接口设计。
而2和6,其他答主已经说得很好了,其实都需要调用方自己把数据在内核和用户空间里搬来搬去,其实都是同步接口,除非是IOCP这样的专门的异步传输接口,所以这一级其实是同步的,阻塞与非阻塞的区别其实是影响调用接口的结果(在特定条件下是否提前返回结果),而不是调用方式。
3和5,内核一般通过缓冲区,使用DMI来传输数据,所以这一步又是异步的。
4,以太网是个同步时序逻辑,随信号传输时钟,必须两边设备同时就绪了才能开始传输数据,这又是同步的。
总结来说,讨论究竟是异步还是同步,一定要严格说明说的是哪一部分。其他答主说非阻塞是同步而不是异步,这毫无疑问是正确的,然而说某个框架是异步IO的框架,这也是正确的,因为说的其实是框架提供给业务代码的接口是异步的,不管是回调还是协程,比如说我们可以说某个库是异步的HTTPClient,并没有什么问题,因为说的是给业务代码的接口。由于通常异步的框架都需要在2中使用非阻塞的接口,的确会有很多人把非阻塞和异步混为一谈。
Python 压根就没有变量的概念。
用C或C++的变量概念去理解python就会一头雾水。
C、C++中的变量
C/C++中的变量的概念是面向内存的。
所以你要声明一个变量:表明空间大小,存储的格式(整数,浮点),以及一个永久不变的名字指向这个变量。
python只有name和object
a = 3
- 这个语句中 a 是一个名字, 3 是一个object
- 这个语句其实并不是什么赋值
- 而是干了以下三件事
- 创建name a
- 创建object 3
- 将name a 关联到 3这个object
- 以后就可以用a来调用3这个object
所有name在创建时必须关联到一个object。
name可以在创建以后指向任何一个object(包括不同类型)。
所以name本身没有类别,他关联的object是有类别的。
在python中可以使用type(name)来查看name关联的object的类型。
进阶回答
Python的数据模型(参见手册章3)
- python所有的数据都用object(对象)表示
- 对象在创建时有以下属性
- 标识,唯一识别,不可改变,通过id(obj)查看
- 类型,不可改变
- 值,根据类型形式分为mutable(可变),immutable(不可变)
Name(参见手册9.1 以及此文)
对象是用来使用的,比如参与表达式运算,或作为函数参数传递
python并不直接使用object,而是使用name的间接方式:
- 将name关联到object,然后name就可以用在表达式。
- 一个object可以被多个name关联。
- name总是存在于特定的namespace中
直观比喻:
- 对象,就像一个人,出生时就分配身份证ID,这个终身不变。
- 人可以有不同的name(小明,儿子,父亲,老公)但在特定情境下(namespace)都指的是同一个人。
- 不同情境下(namespace),name可能指代不同人,比如每个家庭都有一个老公。
python语法 “=”的含义
C语言中的等号是赋值,而python中的等号大不相同
等号有以下几种形式( 参见7.2 assignment operator10.3.1 )
对于等号左边是单一目标的定义
1,name = object
- 目标是indentifier(name)
- 将object关联到当前namespace,
- 如果当前namespace没有这个name就创建
2,mutable.attr=object
- 目标是一个可变对象的属性
- 对象属性被修改为(或者说指向)object
这个与C中的把等号右边的值放入左边的存储空间的概念完全不同。其它的类型赋值语句可以自己看手册。
对象的可变与不可变
python奇特的可变数据
- numbers(整数,浮点,布尔等)不可变,对!不可修改
- list,dict之类的容器类对象,是可变对象
- 注意,容器实际存储的是对象的reference
- 可变是指reference可变,也就是可以把reference指向新的object
- 语法上
- a=list[0]返回的是list的0位置reference关联的object的值
- list[0]=4,实际是将list的0位置reference改成关联到4这个对象
- 也就是说,python压根就不能直接修改基础对象的值,只能修改容器中的renference
几个小实验

这个测试中
- 如果按C语言,对I存储空间赋值理解,id应该不变,但事实是变的
- 以python的name关联来理解,每个循环步骤,i关联到不同的数字object,所以ID不同
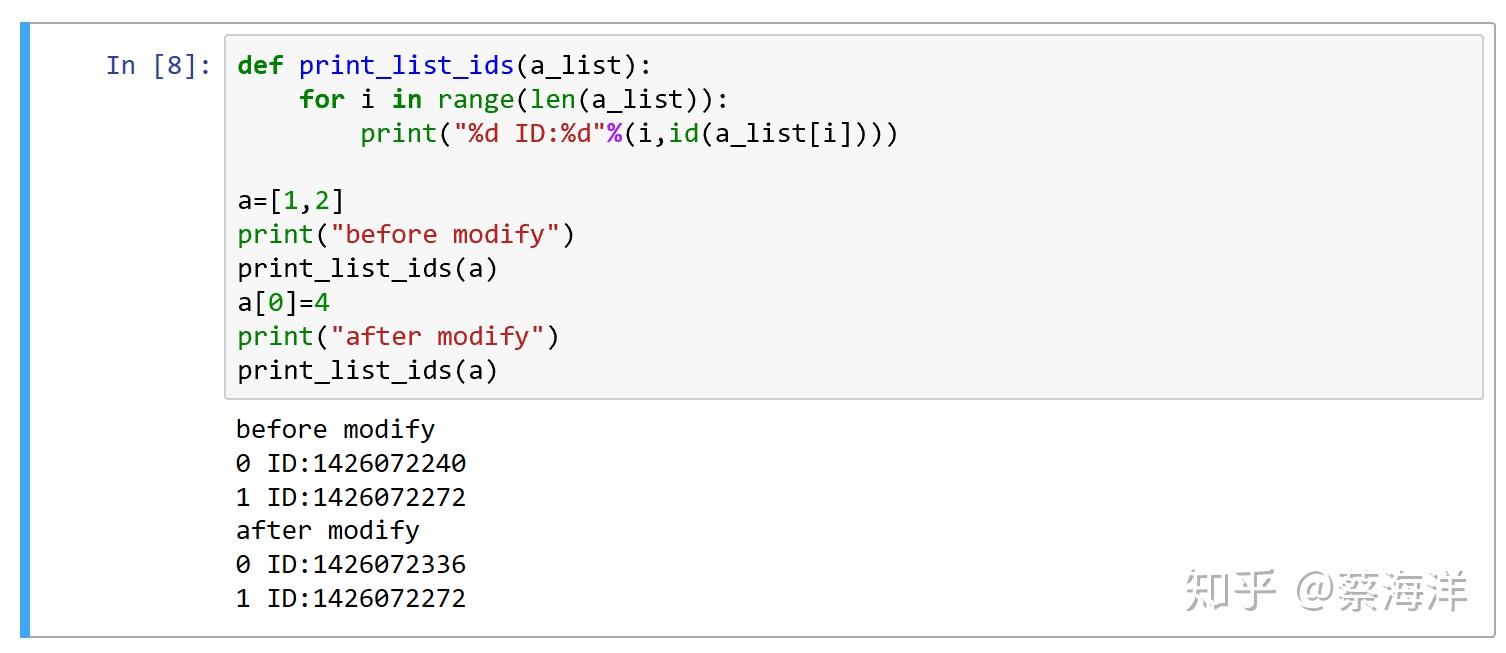
这个试验中
- 修改list,0位置的中的值,导致0位置ID的变化
- 说明list存储的是reference,

这个试验中
- a在做加法后id变了,也就是不是同一个object了
- 这与C语言的赋值大不相同
- python只有对象和name,基础的数据不可修改,所以在加法后创建了新的object用于存储结果,然后重新关联到name a
写在最后
相比C和C++语言,python的概念模型显得很特别。它让编程者,更关注与数据对象的操作,而不是数据存储。这使得编程者能快速的实现想法,而不过多专注于存储细节。
当然要使用好python,就要按它的思维方式去思考,这对于从C、C++这种以内存为基础的编程模式转换过来的人来说,可能是一个挑战。但你只要用python,name vs object的思维,很多疑惑都会消除。
这个问题非常不错,由于side car 模式的兴起,感觉本机网络 IO 用的越来越多了,所以我特地把该问题挖出来答一答。
不过我想把这个问题再丰富丰富,讨论起来更带劲!
- 127.0.0.1 本机网络 IO 需要经过网卡吗?
- 数据包在内核中是个什么走向,和外网发送相比流程上有啥差别?
- 用本机 ip(例如192.168.x.x) 和用 127.0.0.1 性能上有差别吗?
这里先直接把结论抛出来。
- 127.0.0.1 本机网络 IO 不经过网卡
- 本机网络 IO 过程除了不过网卡,其它流程如内核协议栈还都得走。
- 用本机 ip(例如192.168.x.x) 和用 127.0.0.1 性能没有大差别
内容来源于本人公-众-号: 开发内功修炼, 欢迎关注!
另外我把我对网络是如何收包的,如何使用 CPU,如何使用内存的对于内存的都深度分析了一下,还增加了一些性能优化建议和前沿技术展望等,最终汇聚出了这本《理解了实现再谈网络性能》。在此无私分享给大家。
下载链接传送门:《理解了实现再谈网络性能》
好了,继续讨论今天的问题!
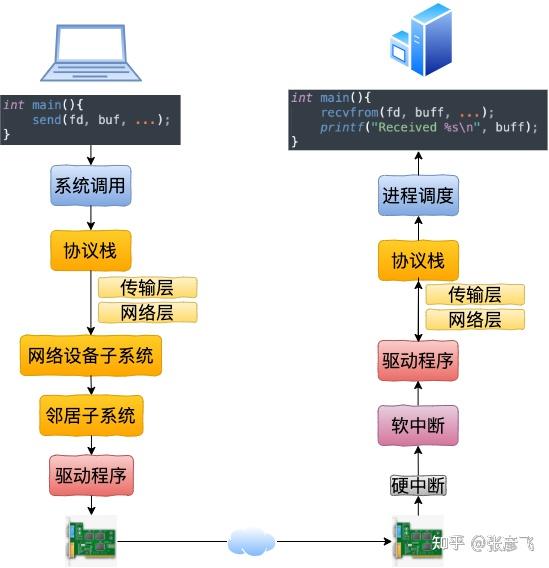
在开始讲述本机通信过程之前,我们还是先回顾一下跨机网络通信。
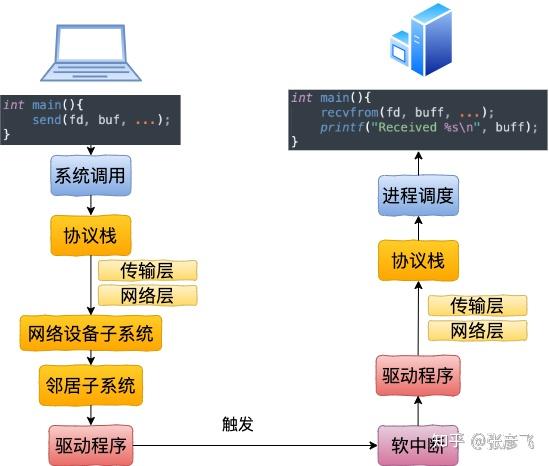
从 send 系统调用开始,直到网卡把数据发送出去,整体流程如下:
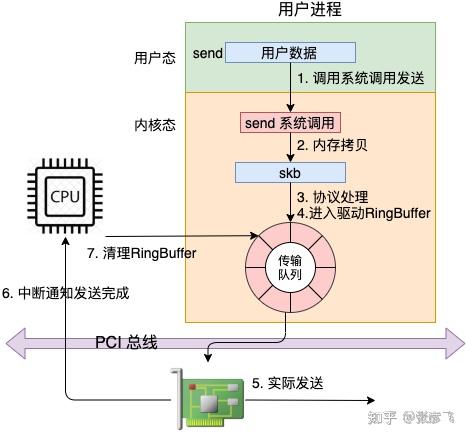
在这幅图中,我们看到用户数据被拷贝到内核态,然后经过协议栈处理后进入到了 RingBuffer 中。随后网卡驱动真正将数据发送了出去。当发送完成的时候,是通过硬中断来通知 CPU,然后清理 RingBuffer。
不过上面这幅图并没有很好地把内核组件和源码展示出来,我们再从代码的视角看一遍。

等网络发送完毕之后。网卡在发送完毕的时候,会给 CPU 发送一个硬中断来通知 CPU。收到这个硬中断后会释放 RingBuffer 中使用的内存。
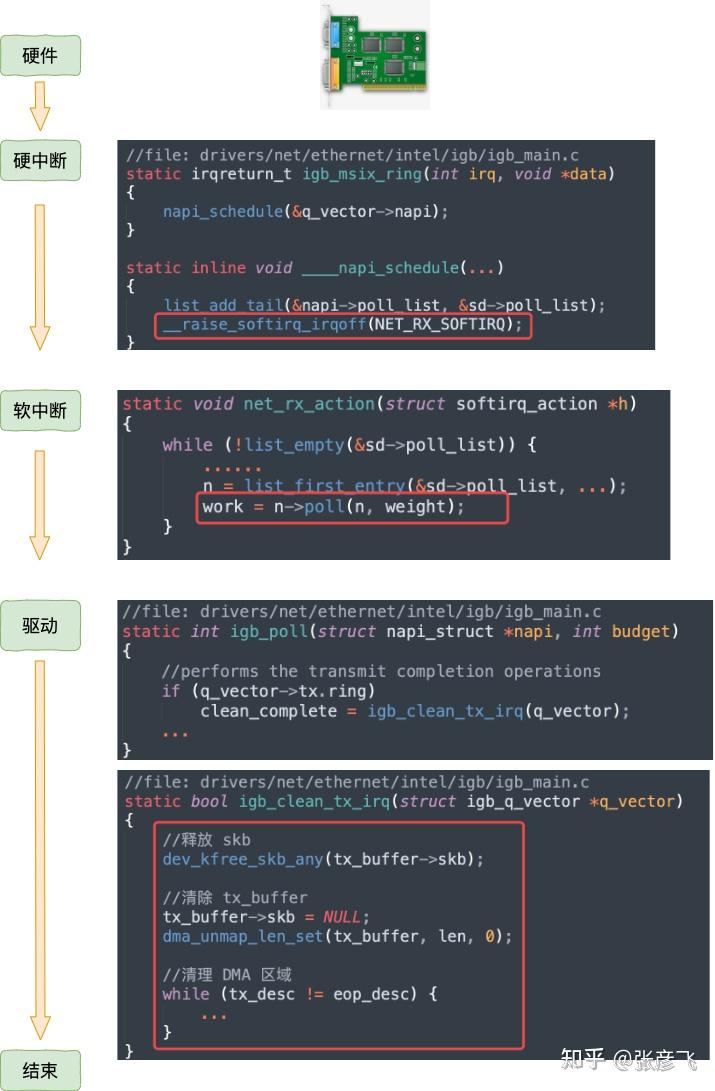
更详细的分析过程参见:
25 张图,一万字,拆解 Linux 网络包发送过程
当数据包到达另外一台机器的时候,Linux 数据包的接收过程开始了。
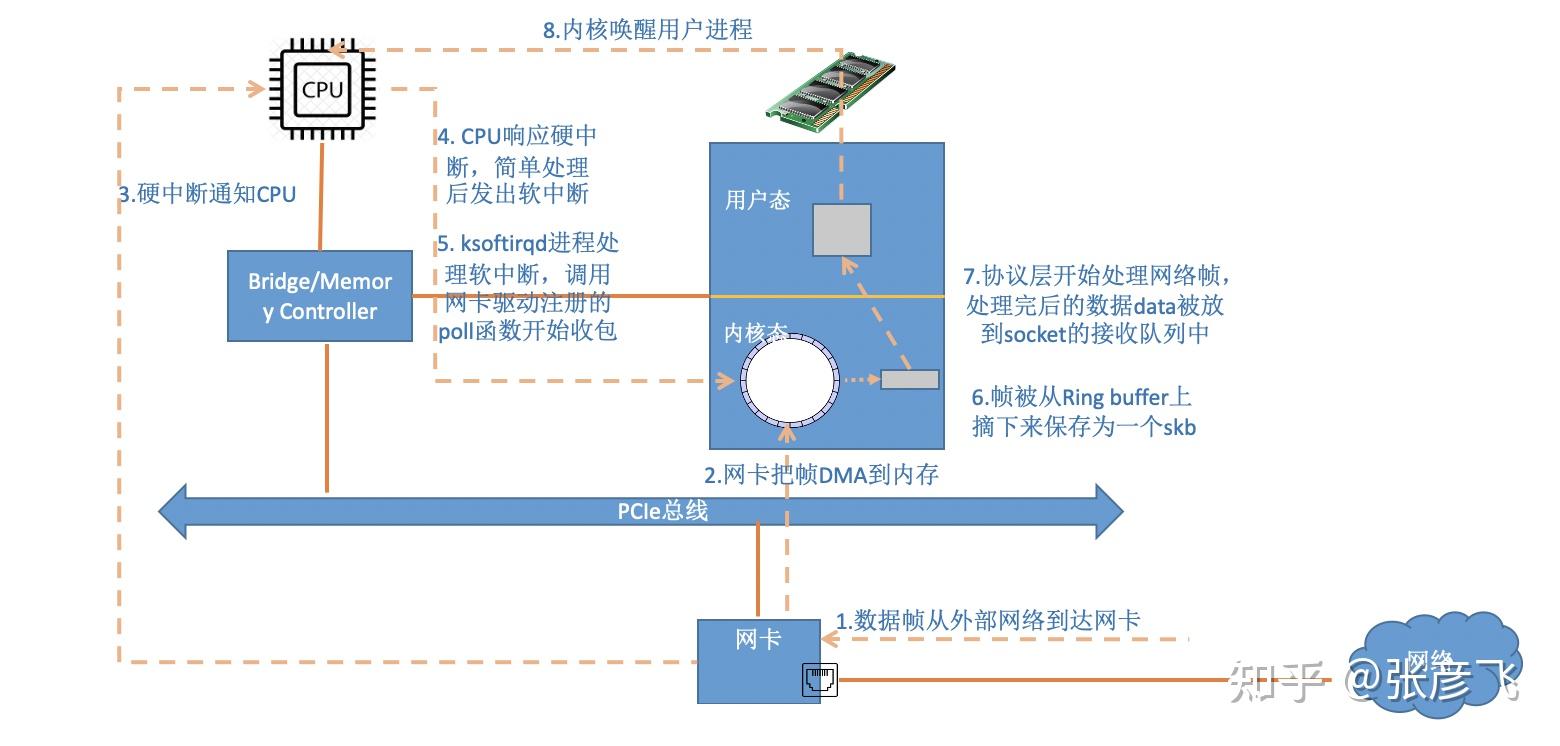
当网卡收到数据以后,向 CPU 发起一个中断,以通知 CPU 有数据到达。当CPU收到中断请求后,会去调用网络驱动注册的中断处理函数,触发软中断。ksoftirqd 检测到有软中断请求到达,开始轮询收包,收到后交由各级协议栈处理。当协议栈处理完并把数据放到接收队列的之后,唤醒用户进程(假设是阻塞方式)。
我们再同样从内核组件和源码视角看一遍。
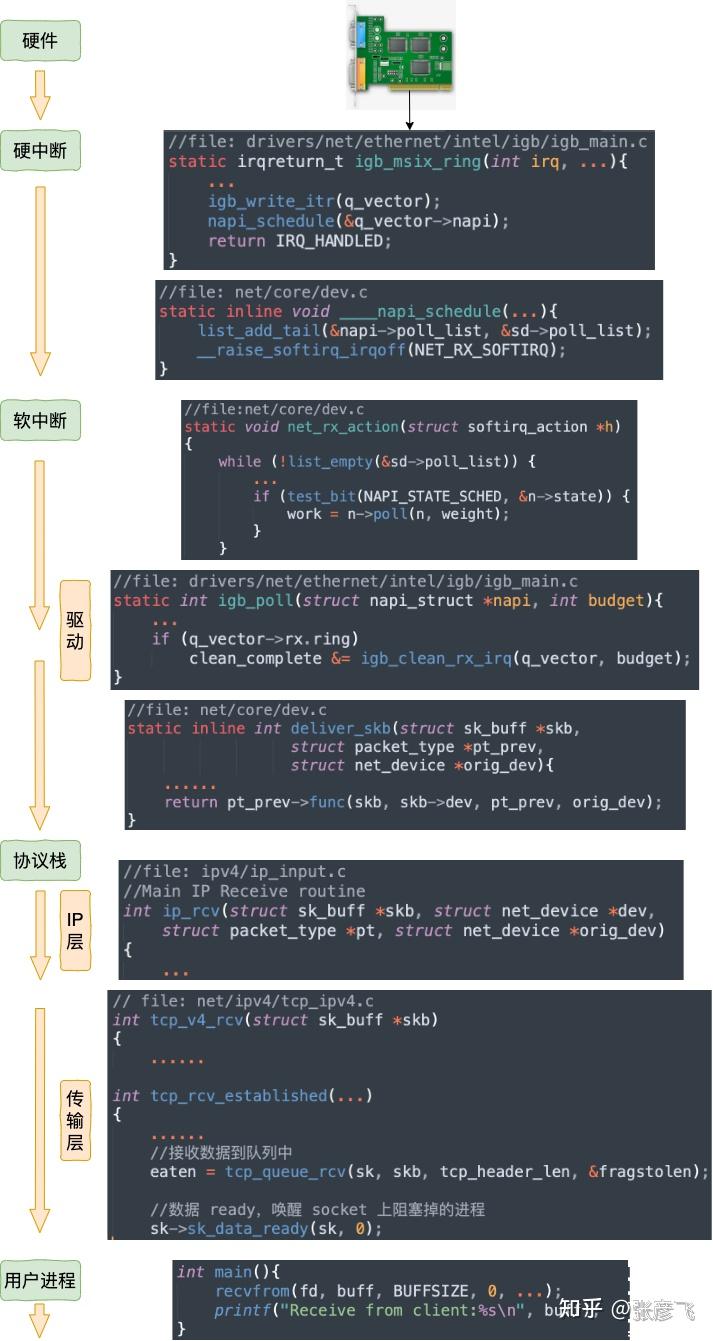
详细的接收过程参见这篇文章:图解Linux网络包接收过程
在第一节中,我们看到了跨机时整个网络发送过程(嫌第一节流程图不过瘾,想继续看源码了解细节的同学可以参考 拆解 Linux 网络包发送过程) 。
在本机网络 IO 的过程中,流程会有一些差别。为了突出重点,将不再介绍整体流程,而是只介绍和跨机逻辑不同的地方。有差异的地方总共有两个,分别是路由和驱动程序。
发送数据会进入协议栈到网络层的时候,网络层入口函数是 ip_queue_xmit。在网络层里会进行路由选择,路由选择完毕后,再设置一些 IP 头、进行一些 netfilter 的过滤后,将包交给邻居子系统。
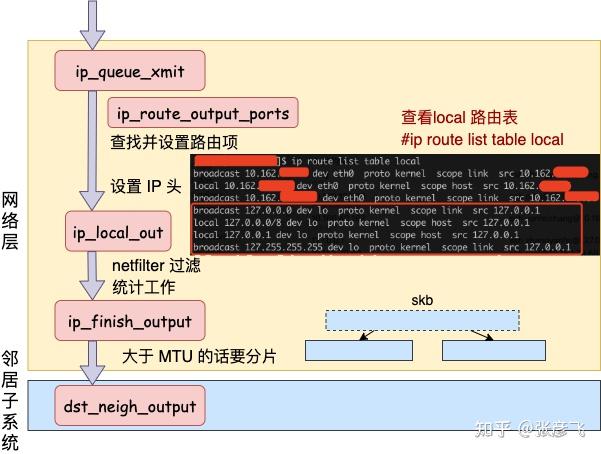
对于本机网络 IO 来说,特殊之处在于在 local 路由表中就能找到路由项,对应的设备都将使用 loopback 网卡,也就是我们常见的 lo。
我们来详细看看路由网络层里这段路由相关工作过程。从网络层入口函数 ip_queue_xmit 看起。
//file: net/ipv4/ip_output.c
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
{
//检查 socket 中是否有缓存的路由表
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (rt == NULL) {
//没有缓存则展开查找
//则查找路由项, 并缓存到 socket 中
rt = ip_route_output_ports(...);
sk_setup_caps(sk, &rt->dst);
}查找路由项的函数是 ip_route_output_ports,它又依次调用到 ip_route_output_flow、__ip_route_output_key、fib_lookup。调用过程省略掉,直接看 fib_lookup 的关键代码。
//file:include/net/ip_fib.h
static inline int fib_lookup(struct net *net, const struct flowi4 *flp,
struct fib_result *res)
{
struct fib_table *table;
table = fib_get_table(net, RT_TABLE_LOCAL);
if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
table = fib_get_table(net, RT_TABLE_MAIN);
if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
return -ENETUNREACH;
}在 fib_lookup 将会对 local 和 main 两个路由表展开查询,并且是先查 local 后查询 main。我们在 Linux 上使用命令名可以查看到这两个路由表, 这里只看 local 路由表(因为本机网络 IO 查询到这个表就终止了)。
#ip route list table local
local 10.143.x.y dev eth0 proto kernel scope host src 10.143.x.y
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1从上述结果可以看出,对于目的是 127.0.0.1 的路由在 local 路由表中就能够找到了。fib_lookup 工作完成,返回__ip_route_output_key 继续。
//file: net/ipv4/route.c
struct rtable *__ip_route_output_key(struct net *net, struct flowi4 *fl4)
{
if (fib_lookup(net, fl4, &res)) {
}
if (res.type == RTN_LOCAL) {
dev_out = net->loopback_dev;
...
}
rth = __mkroute_output(&res, fl4, orig_oif, dev_out, flags);
return rth;
}对于是本机的网络请求,设备将全部都使用 net->loopback_dev,也就是 lo 虚拟网卡。
接下来的网络层仍然和跨机网络 IO 一样,最终会经过 ip_finish_output,最终进入到 邻居子系统的入口函数 dst_neigh_output 中。
本机网络 IO 需要进行 IP 分片吗?因为和正常的网络层处理过程一样会经过 ip_finish_output 函数。在这个函数中,如果 skb 大于 MTU 的话,仍然会进行分片。只不过 lo 的 MTU 比 Ethernet 要大很多。通过 ifconfig 命令就可以查到,普通网卡一般为 1500,而 lo 虚拟接口能有 65535。
在邻居子系统函数中经过处理,进入到网络设备子系统(入口函数是 dev_queue_xmit)。
开篇我们提到的第三个问题的答案就在前面的网络层路由一小节中。但这个问题描述起来有点长,因此单独拉一小节出来。
问题:用本机 ip(例如192.168.x.x) 和用 127.0.0.1 性能上有差别吗?
前面看到选用哪个设备是路由相关函数 __ip_route_output_key 中确定的。
//file: net/ipv4/route.c
struct rtable *__ip_route_output_key(struct net *net, struct flowi4 *fl4)
{
if (fib_lookup(net, fl4, &res)) {
}
if (res.type == RTN_LOCAL) {
dev_out = net->loopback_dev;
...
}
rth = __mkroute_output(&res, fl4, orig_oif, dev_out, flags);
return rth;
}这里会查询到 local 路由表。
# ip route list table local
local 10.162.*.* dev eth0 proto kernel scope host src 10.162.*.*
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1很多人在看到这个路由表的时候就被它给迷惑了,以为上面 10.162. 真的会被路由到 eth0(其中 10.162.. 是我的本机局域网 IP,我把后面两段用 * 号隐藏起来了)。
但其实内核在初始化 local 路由表的时候,把 local 路由表里所有的路由项都设置成了 RTN_LOCAL,不仅仅只是 127.0.0.1。这个过程是在设置本机 ip 的时候,调用 fib_inetaddr_event 函数完成设置的。
static int fib_inetaddr_event(struct notifier_block *this,
unsigned long event, void *ptr)
{
switch (event) {
case NETDEV_UP:
fib_add_ifaddr(ifa);
break;
case NETDEV_DOWN:
fib_del_ifaddr(ifa, NULL);
//file:ipv4/fib_frontend.c
void fib_add_ifaddr(struct in_ifaddr *ifa)
{
fib_magic(RTM_NEWROUTE, RTN_LOCAL, addr, 32, prim);
}所以即使本机 IP,不用 127.0.0.1,内核在路由项查找的时候判断类型是 RTN_LOCAL,仍然会使用 net->loopback_dev。也就是 lo 虚拟网卡。
为了稳妥起见,飞哥再抓包确认一下。开启两个控制台窗口,一个对 eth0 设备进行抓包。因为局域网内会有大量的网络请求,为了方便过滤,这里使用一个特殊的端口号 8888。如果这个端口号在你的机器上占用了,那需要再换一个。
#tcpdump -i eth0 port 8888另外一个窗口使用 telnet 对本机 IP 端口发出几条网络请求。
#telnet 10.162.*.* 8888
Trying 10.162.129.56...
telnet: connect to address 10.162.129.56: Connection refused这时候切回第一个控制台,发现啥反应都没有。说明包根本就没有过 eth0 这个设备。
再把设备换成 lo 再抓。当 telnet 发出网络请求以后,在 tcpdump 所在的窗口下看到了抓包结果。
# tcpdump -i lo port 8888
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 65535 bytes
08:22:31.956702 IP 10.162.*.*.62705 > 10.162.*.*.ddi-tcp-1: Flags [S], seq 678725385, win 43690, options [mss 65495,nop,wscale 8], length 0
08:22:31.956720 IP 10.162.*.*.ddi-tcp-1 > 10.162.*.*.62705: Flags [R.], seq 0, ack 678725386, win 0, length 0网络设备子系统的入口函数是 dev_queue_xmit。简单回忆下之前讲述跨机发送过程的时候,对于真的有队列的物理设备,在该函数中进行了一系列复杂的排队等处理以后,才调用 dev_hard_start_xmit,从这个函数 再进入驱动程序来发送。在这个过程中,甚至还有可能会触发软中断来进行发送,流程如图:
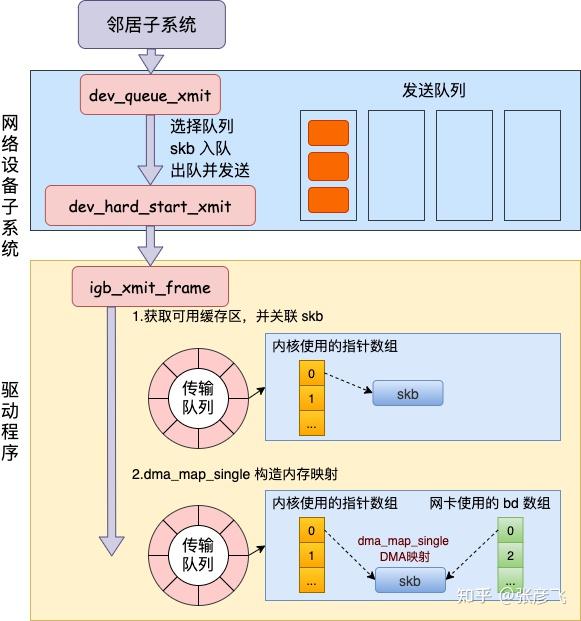
但是对于启动状态的回环设备来说(q->enqueue 判断为 false),就简单多了。没有队列的问题,直接进入 dev_hard_start_xmit。接着中进入回环设备的“驱动”里的发送回调函数 loopback_xmit,将 skb “发送”出去。
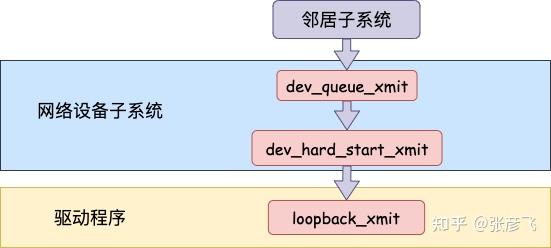
我们来看下详细的过程,从 网络设备子系统的入口 dev_queue_xmit 看起。
//file: net/core/dev.c
int dev_queue_xmit(struct sk_buff *skb)
{
q = rcu_dereference_bh(txq->qdisc);
if (q->enqueue) {//回环设备这里为 false
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
//开始回环设备处理
if (dev->flags & IFF_UP) {
dev_hard_start_xmit(skb, dev, txq, ...);
...
}
}在 dev_hard_start_xmit 中还是将调用设备驱动的操作函数。
//file: net/core/dev.c
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq)
{
//获取设备驱动的回调函数集合 ops
const struct net_device_ops *ops = dev->netdev_ops;
//调用驱动的 ndo_start_xmit 来进行发送
rc = ops->ndo_start_xmit(skb, dev);
...
}
对于真实的 igb 网卡来说,它的驱动代码都在 drivers/net/ethernet/intel/igb/igb_main.c 文件里。顺着这个路子,我找到了 loopback 设备的“驱动”代码位置:drivers/net/loopback.c。 在 drivers/net/loopback.c
//file:drivers/net/loopback.c
static const struct net_device_ops loopback_ops = {
.ndo_init = loopback_dev_init,
.ndo_start_xmit= loopback_xmit,
.ndo_get_stats64 = loopback_get_stats64,
};所以对 dev_hard_start_xmit 调用实际上执行的是 loopback “驱动” 里的 loopback_xmit。为什么我把“驱动”加个引号呢,因为 loopback 是一个纯软件性质的虚拟接口,并没有真正意义上的驱动。
//file:drivers/net/loopback.c
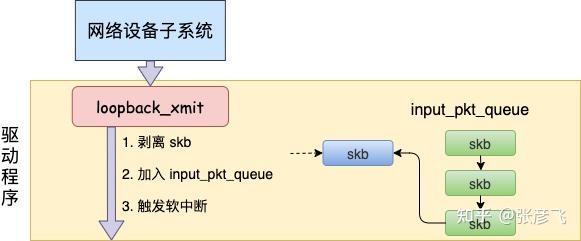
static netdev_tx_t loopback_xmit(struct sk_buff *skb,
struct net_device *dev)
{
//剥离掉和原 socket 的联系
skb_orphan(skb);
//调用netif_rx
if (likely(netif_rx(skb) == NET_RX_SUCCESS)) {
}
}在 skb_orphan 中先是把 skb 上的 socket 指针去掉了(剥离了出来)。
注意,在本机网络 IO 发送的过程中,传输层下面的 skb 就不需要释放了,直接给接收方传过去就行了。总算是省了一点点开销。不过可惜传输层的 skb 同样节约不了,还是得频繁地申请和释放。
接着调用 netif_rx,在该方法中 中最终会执行到 enqueue_to_backlog 中(netif_rx -> netif_rx_internal -> enqueue_to_backlog)。
//file: net/core/dev.c
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
sd = &per_cpu(softnet_data, cpu);
...
__skb_queue_tail(&sd->input_pkt_queue, skb);
...
____napi_schedule(sd, &sd->backlog);
在 enqueue_to_backlog 把要发送的 skb 插入 softnet_data->input_pkt_queue 队列中并调用 ____napi_schedule 来触发软中断。
//file:net/core/dev.c
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}只有触发完软中断,发送过程就算是完成了。
在跨机的网络包的接收过程中,需要经过硬中断,然后才能触发软中断。而在本机的网络 IO 过程中,由于并不真的过网卡,所以网卡实际传输,硬中断就都省去了。直接从软中断开始,经过 process_backlog 后送进协议栈,大体过程如图。
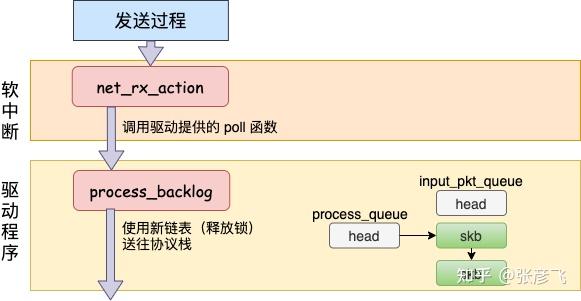
接下来我们再看更详细一点的过程。
在软中断被触发以后,会进入到 NET_RX_SOFTIRQ 对应的处理方法 net_rx_action 中(至于细节参见 图解Linux网络包接收过程 一文中的 3.2 小节)。
//file: net/core/dev.c
static void net_rx_action(struct softirq_action *h){
while (!list_empty(&sd->poll_list)) {
work = n->poll(n, weight);
}
}我们还记得对于 igb 网卡来说,poll 实际调用的是 igb_poll 函数。那么 loopback 网卡的 poll 函数是谁呢?由于poll_list 里面是 struct softnet_data 对象,我们在 net_dev_init 中找到了蛛丝马迹。
//file:net/core/dev.c
static int __init net_dev_init(void)
{
for_each_possible_cpu(i) {
sd->backlog.poll = process_backlog;
}
}原来struct softnet_data 默认的 poll 在初始化的时候设置成了 process_backlog 函数,来看看它都干了啥。
static int process_backlog(struct napi_struct *napi, int quota)
{
while(){
while ((skb = __skb_dequeue(&sd->process_queue))) {
__netif_receive_skb(skb);
}
//skb_queue_splice_tail_init()函数用于将链表a连接到链表b上,
//形成一个新的链表b,并将原来a的头变成空链表。
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen)
skb_queue_splice_tail_init(&sd->input_pkt_queue,
&sd->process_queue);
}
}这次先看对 skb_queue_splice_tail_init 的调用。源码就不看了,直接说它的作用是把 sd->input_pkt_queue 里的 skb 链到 sd->process_queue 链表上去。
然后再看 __skb_dequeue, __skb_dequeue 是从 sd->process_queue 上取下来包来处理。这样和前面发送过程的结尾处就对上了,发送过程是把包放到了 input_pkt_queue 队列里。

最后调用 __netif_receive_skb 将数据送往协议栈。在此之后的调用过程就和跨机网络 IO 又一致了。
送往协议栈的调用链是 __netif_receive_skb => __netif_receive_skb_core => deliver_skb 后 将数据包送入到 ip_rcv 中(详情参见图解Linux网络包接收过程 一文中的 3.3 小节)。
网络再往后依次是传输层,最后唤醒用户进程。
我们来总结一下本机网络 IO 的内核执行流程。
回想下跨机网络 IO 的流程是

我们现在可以回顾下开篇的三个问题啦。
1)127.0.0.1 本机网络 IO 需要经过网卡吗? 通过本文的叙述,我们确定地得出结论,不需要经过网卡。即使了把网卡拔了本机网络是否还可以正常使用的。
2)数据包在内核中是个什么走向,和外网发送相比流程上有啥差别? 总的来说,本机网络 IO 和跨机 IO 比较起来,确实是节约了驱动上的一些开销。发送数据不需要进 RingBuffer 的驱动队列,直接把 skb 传给接收协议栈(经过软中断)。但是在内核其它组件上,可是一点都没少,系统调用、协议栈(传输层、网络层等)、设备子系统整个走了一个遍。连“驱动”程序都走了(虽然对于回环设备来说只是一个纯软件的虚拟出来的东东)。所以即使是本机网络 IO,切忌误以为没啥开销就滥用。
3)用本机 ip(例如192.168.x.x) 和用 127.0.0.1 性能上有差别吗? 很多人的直觉是走网卡,但正确结论是和 127.0.0.1 没有差别,都是走虚拟的环回设备 lo。
这是因为内核在设置 ip 的时候,把所有的本机 ip 都初始化 local 路由表里了,而且类型写死 RTN_LOCAL。在后面的路由项选择的时候发现类型是 RTN_LOCAL 就会选择 lo 了。还不信的话你也动手抓包试试!
最后再提一下,业界有公司基于 ebpf 的 sockmap 和 sk redirect 功能研发了自己的 sockops 组件,用来加速 istio 架构中 sidecar 代理和本地进程之间的通信。通过引入 BPF,才算是绕开了内核协议栈的开销,原理如下。
飞哥写了一本电子书。这本电子书是对网络性能进行拆解,把性能拆分为三个角度:CPU 开销、内存开销等。
具体到某个角度比如 CPU,那我需要给自己解释清楚网络包是怎么从网卡到内核中的,内核又是通过哪些方式通知进程的。只有理解清楚了这些才能真正把握网络对 CPU 的消耗。
对于内存角度也是一样,只有理解了内核是如何使用内存,甚至需要哪些内核对象都搞清楚,也才能真正理解一条 TCP 连接的内存开销。
除此之外我还增加了一些性能优化建议和前沿技术展望等,最终汇聚出了这本《理解了实现再谈网络性能》。在此无私分享给大家。
下载链接传送门:《理解了实现再谈网络性能》
另外飞哥经常会收到读者的私信,询问可否推荐一些书继续深入学习内功。所以我干脆就写了篇文章。把能搜集到的电子版也帮大家汇总了一下,取需!
答读者问,能否推荐几本有价值的参考书(含下载地址)
Github: https://github.com/yanfeizhang/
------------------------------ 华丽的分割线 ----------------------------------------
2021-12-22 日追更
在上次回答完后,有读者在评论区里希望飞哥能再分析一下 Unix Domain Socket。最近终于抽空把这个也深入研究了一下。
今天我们将分析 Unix Domain Socket 的连接建立过程、数据发送过程等内部工作原理。你将理解为什么这种方式的性能比 127.0.0.1 要好很多。最后我们还给出了实际的性能测试对比数据。
相信你已经迫不及待了,别着急,让我们一一展开细说!
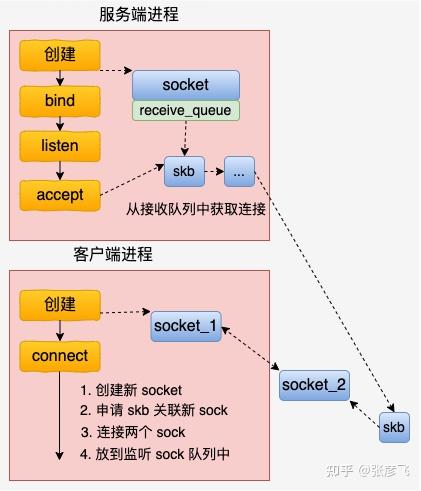
总的来说,基于 UDS 的连接过程比 inet 的 socket 连接过程要简单多了。客户端先创建一个自己用的 socket,然后调用 connect 来和服务器建立连接。
在 connect 的时候,会申请一个新 socket 给 server 端将来使用,和自己的 socket 建立好连接关系以后,就放到服务器正在监听的 socket 的接收队列中。 这个时候,服务器端通过 accept 就能获取到和客户端配好对的新 socket 了。
总的 UDS 的连接建立流程如下图。
内核源码中最重要的逻辑在 connect 函数中,我们来简单展开看一下。 unix 协议族中定义了这类 socket 的所有方法,它位于 net/unix/af_unix.c 中。
//file: net/unix/af_unix.c
static const struct proto_ops unix_stream_ops = {
.family = PF_UNIX,
.owner = THIS_MODULE,
.bind = unix_bind,
.connect = unix_stream_connect,
.socketpair = unix_socketpair,
.listen = unix_listen,
...
};我们找到 connect 函数的具体实现,unix_stream_connect。
//file: net/unix/af_unix.c
static int unix_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags)
{
struct sockaddr_un *sunaddr = (struct sockaddr_un *)uaddr;
...
// 1. 为服务器侧申请一个新的 socket 对象
newsk = unix_create1(sock_net(sk), NULL);
// 2. 申请一个 skb,并关联上 newsk
skb = sock_wmalloc(newsk, 1, 0, GFP_KERNEL);
...
// 3. 建立两个 sock 对象之间的连接
unix_peer(newsk) = sk;
newsk->sk_state = TCP_ESTABLISHED;
newsk->sk_type = sk->sk_type;
...
sk->sk_state = TCP_ESTABLISHED;
unix_peer(sk) = newsk;
// 4. 把连接中的一头(新 socket)放到服务器接收队列中
__skb_queue_tail(&other->sk_receive_queue, skb);
}主要的连接操作都是在这个函数中完成的。和我们平常所见的 TCP 连接建立过程,这个连接过程简直是太简单了。没有三次握手,也没有全连接队列、半连接队列,更没有啥超时重传。
直接就是将两个 socket 结构体中的指针互相指向对方就行了。就是 unix_peer(newsk) = sk 和 unix_peer(sk) = newsk 这两句。
//file: net/unix/af_unix.c
#define unix_peer(sk) (unix_sk(sk)->peer)当关联关系建立好之后,通过 __skb_queue_tail 将 skb 放到服务器的接收队列中。注意这里的 skb 里保存着新 socket 的指针,因为服务进程通过 accept 取出这个 skb 的时候,就能获取到和客户进程中 socket 建立好连接关系的另一个 socket。
怎么样,UDS 的连接建立过程是不是很简单!?
看完了连接建立过程,我们再来看看基于 UDS 的数据的收发。这个收发过程一样也是非常的简单。发送方是直接将数据写到接收方的接收队列里的。

我们从 send 函数来看起。send 系统调用的源码位于文件 net/socket.c 中。在这个系统调用里,内部其实真正使用的是 sendto 系统调用。它只干了两件简单的事情,
第一是在内核中把真正的 socket 找出来,在这个对象里记录着各种协议栈的函数地址。 第二是构造一个 struct msghdr 对象,把用户传入的数据,比如 buffer地址、数据长度啥的,统统都装进去. 剩下的事情就交给下一层,协议栈里的函数 inet_sendmsg 了,其中 inet_sendmsg 函数的地址是通过 socket 内核对象里的 ops 成员找到的。大致流程如图。
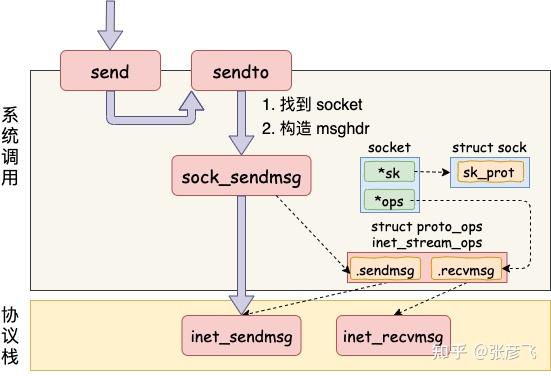
在进入到协议栈 inet_sendmsg 以后,内核接着会找到 socket 上的具体协议发送函数。对于 Unix Domain Socket 来说,那就是 unix_stream_sendmsg。 我们来看一下这个函数
//file:
static int unix_stream_sendmsg(struct kiocb *kiocb, struct socket *sock,
struct msghdr *msg, size_t len)
{
// 1.申请一块缓存区
skb = sock_alloc_send_skb(sk, size, msg->msg_flags&MSG_DONTWAIT,
&err);
// 2.拷贝用户数据到内核缓存区
err = memcpy_fromiovec(skb_put(skb, size), msg->msg_iov, size);
// 3. 查找socket peer
struct sock *other = NULL;
other = unix_peer(sk);
// 4.直接把 skb放到对端的接收队列中
skb_queue_tail(&other->sk_receive_queue, skb);
// 5.发送完毕回调
other->sk_data_ready(other, size);
}和复杂的 TCP 发送接收过程相比,这里的发送逻辑简单简单到令人发指。申请一块内存(skb),把数据拷贝进去。根据 socket 对象找到另一端,直接把 skb 给放到对端的接收队列里了
接收函数主题是 unix_stream_recvmsg,这个函数中只需要访问它自己的接收队列就行了,源码就不展示了。所以在本机网络 IO 场景里,基于 Unix Domain Socket 的服务性能上肯定要好一些的。
为了验证 Unix Domain Socket 到底比基于 127.0.0.1 的性能好多少,我做了一个性能测试。 在网络性能对比测试,最重要的两个指标是延迟和吞吐。我从 Github 上找了个好用的测试源码:https://github.com/rigtorp/ipc-bench。 我的测试环境是一台 4 核 CPU,8G 内存的 KVM 虚机。
在延迟指标上,对比结果如下图。
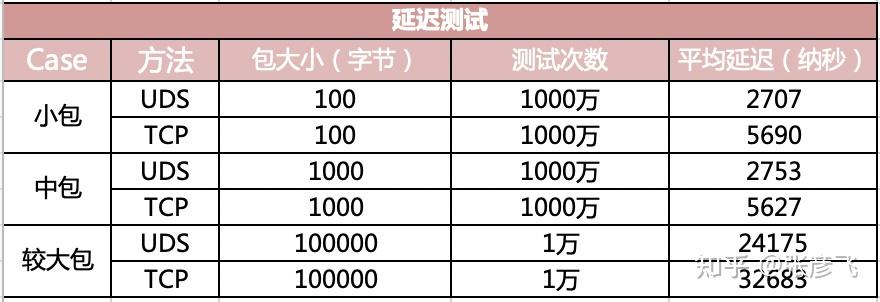
可见在小包(100 字节)的情况下,UDS 方法的“网络” IO 平均延迟只有 2707 纳秒,而基于 TCP(访问 127.0.0.1)的方式下延迟高达 5690 纳秒。耗时整整是前者的两倍。
在包体达到 100 KB 以后,UDS 方法延迟 24 微秒左右(1 微秒等于 1000 纳秒),TCP 是 32 微秒,仍然高一截。这里低于 2 倍的关系了,是因为当包足够大的时候,网络协议栈上的开销就显得没那么明显了。
再来看看吞吐效果对比。
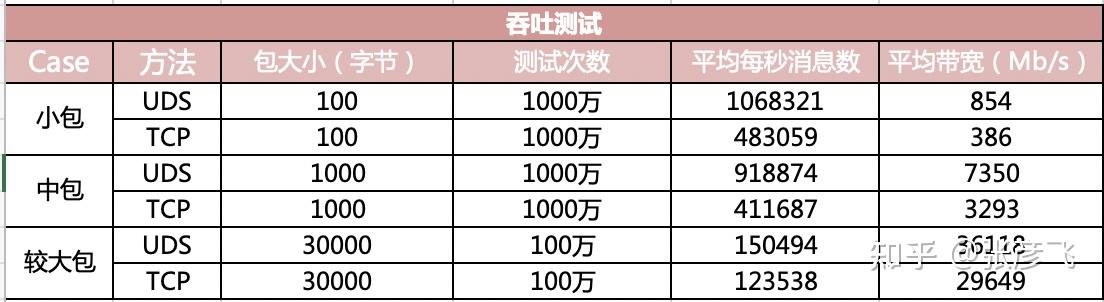
在小包的情况下,带宽指标可以达到 854 M,而基于 TCP 的 IO 方式下只有 386。
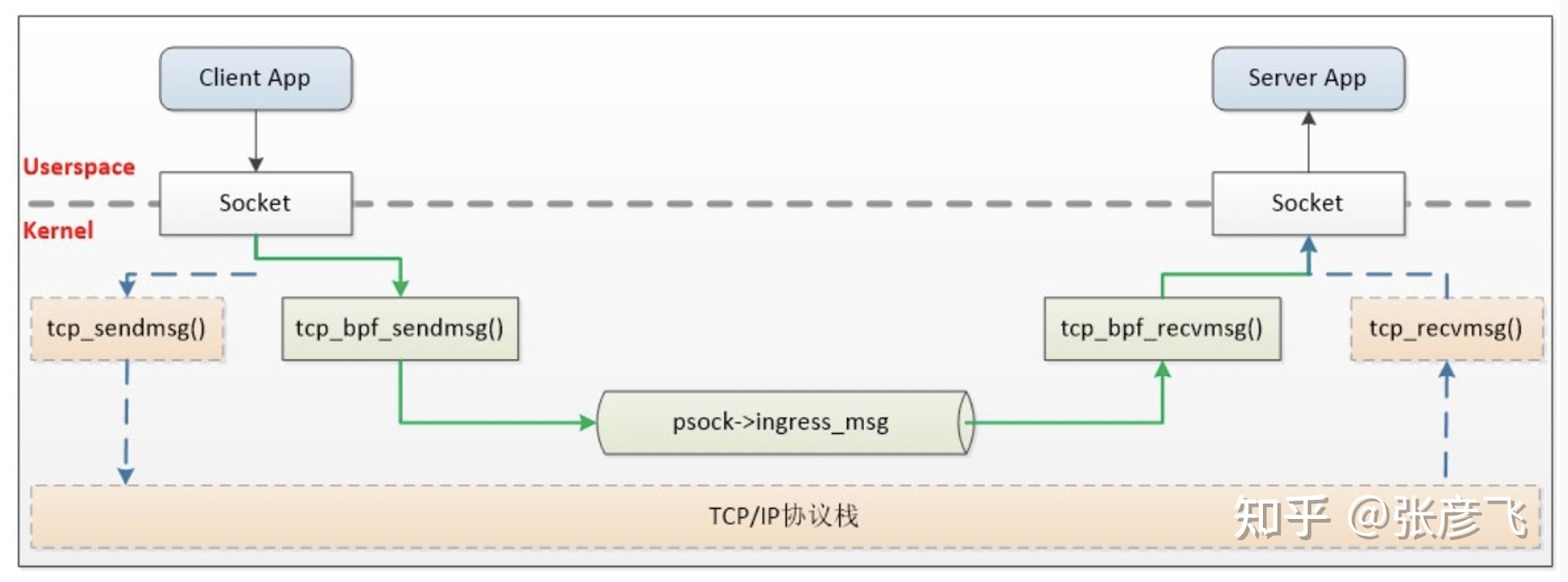
本文分析了基于 Unix Domain Socket 的连接创建、以及数据收发过程。其中数据收发的工作过程如下图。
相对比本机网络 IO 通信过程上,它的工作过程要清爽许多。其中 127.0.0.1 工作过程如下图。

我们也对比了 UDP 和 TCP 两种方式下的延迟和性能指标。在包体不大于 1KB 的时候,UDS 的性能大约是 TCP 的两倍多。所以,在本机网络 IO 的场景下,如果对性能敏感,可考虑使用 Unix Domain Socket。
看到这里留个赞再走呗!
也欢迎关注飞哥的公众号:开发内功修炼
没有人比我更有资格回答这一题,说多了都是泪.....
先说结论,很多高赞回答都不全面,本机相互通讯的流量是有可能通过物理网卡,这取决于目的地址使用哪类本机IP,具体来说很多高赞回答都提到了使用挂载到本地网卡上的IP进行通讯,比如下面的192.168.0.192和127.0.0.1都不会过物理网卡,这个结论是没问题的。
[root@ecs-a4d3 ~]# ifconfig -a
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.192 netmask 255.255.255.0 broadcast 192.168.0.255
inet6 fe80::f816:3eff:fe1c:ef05 prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:1c:ef:05 txqueuelen 1000 (Ethernet)
RX packets 5867068 bytes 5515844902 (5.1 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4003988 bytes 554388151 (528.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 15 bytes 1416 (1.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 15 bytes 1416 (1.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
但是如果你用的是云服务器ECS,并使用弹性IP与本机通讯,那流量就是要过物理网卡了。
可能有细心的小伙伴会问ECS大多是虚拟机,过虚拟机的网卡又不一定过宿主机的物理网卡.....算了我直说了吧,我的个人博客没什么人访问,一直按流量计费,之前我一直用每小时curl弹性IP一次的方式进行健康监测,上个月一时手抽把sleep注掉了,结果半天不到就欠费了。
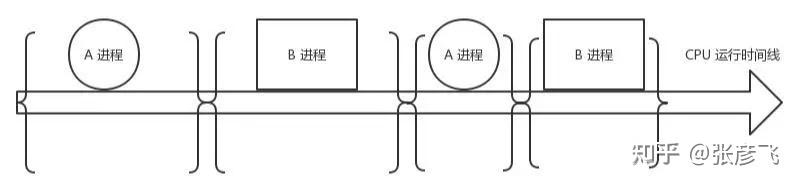
我猜你是想了解 epoll 为啥高性能吧!?
其实在理解 epoll 之前,得先理解一个事情,那就是进程阻塞切换的 CPU 开销。在高并发的网络 IO 下,性能的最大绊脚石就是 socket 在阻塞后导致的进程上下文切换。关于这个,我进行过实际的测试。大约一次进程上下文切换的开销是 3-5 微秒左右。
张彦飞:进程/线程上下文切换会用掉你多少CPU?
至于说同步阻塞网络 IO 下的进程上下文切换是如何发生的,我也写过这么一篇
图解 | 深入理解高性能网络开发路上的绊脚石 - 同步阻塞网络 IO
可能有的同学会说,3 - 5 微秒的开销看起来还好啊。但是你要知道的是,从我们开发工程师的角度来看,这段时间里 CPU 吭哧吭哧的执行的切换工作对我们来说其实是无用功。
所以 epoll 作为多路复用技术中的代表,和传统的阻塞网络 IO 相比,最大的性能提升就是节约掉了大量的进程上下文切换。 epoll 内部又涉及出了一套复杂的数据结构,包括一棵红黑树和一个就绪链表(以及一个epollwait等待队列)。全部都工作在内核态。通过红黑树,高效地管理海量的连接。在数据到来的时候,不断地将数据 Ready 的socket 放到就绪链表中。
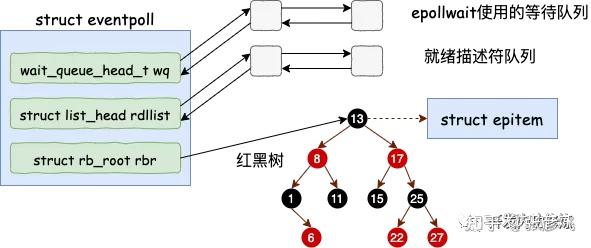
这样应用层和内核态协作的时候就非常的容易了,最少只需要一个进程就可以维护成千上万甚至是百万级别的连接。这个进程的简单地去就绪队列中查看有没有 Ready,需要被处理的 socket。有就拿走处理。只要活儿足够的多,epoll_wait 根本都不会让进程阻塞。用户进程会一直干活,一直干活,直到 epoll_wait 里实在没活儿可干的时候才主动让出 CPU。大量地减少了进程切换次数,这就是 epoll 高效的地方所在!
当然,上面我只是描述的简单的过程,epoll 的完整实现来看下面这篇文章吧。虽然源码很复杂,但是我在文章中都替你整理好了,看起来不会很费力。
图解 | 深入揭秘 epoll 是如何实现 IO 多路复用的!
这是 epoll 工作原理的一张汇总图,供你参考。
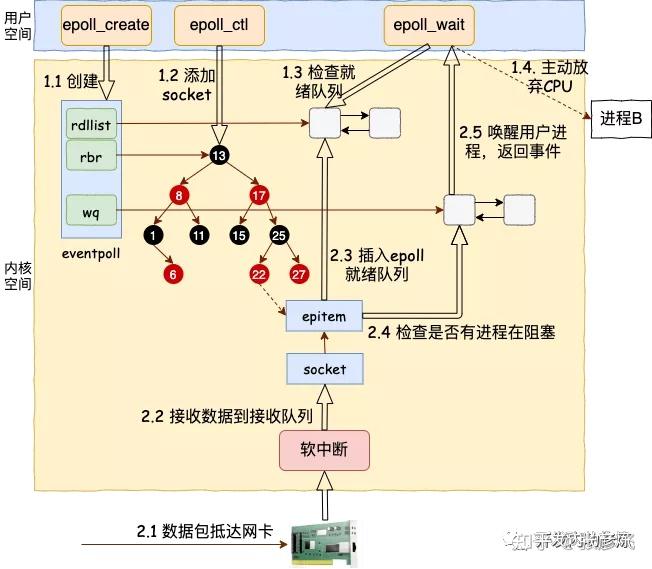
最后再说说 epoll 中的红黑树,有的人误以为 epoll 高效的全部因为这棵红黑树,这就有点夸大红黑树的作用了。其实红黑树的作用是仅仅是在管理大量连接的情况下,添加和删除 socket 非常的高效。如果 epoll 管理的 socket 固定的话,在数据收发的事件管理过程中其实红黑树是没有起作用的。内核在socket上收到数据包以后,可以直接找到 epitem(epoll item),并把它插入到就绪队列里,然后等用户进程把事件取走。这个过程中,红黑树的作用并不会得到体现。
关于网络实现,我还写了好多文章,都整理到我的Github上了。
https://github.com/yanfeizhang/coder-kung-fu
不要把 socket 想得太复杂,它其实和一般的文件读写没有太大区别。
只不过一个是用 fopen 打开,读写模式作为参数传进去;一个是用 socket 打开,服务器还是客户通过 connect / listen 设置。
一个是 fread/fwrite 读写,一个是 recv 和 send 读写(在 Linux 下你用 read 和 write 的话,文件和 socket 两者都能读写,只是无法直接设置一些特殊的 flag)。
一般的文件以及 socket 客户端读写的都是数据,而 socket 服务端 accept 读出来的是可以读写的客户端文件。
我觉得新手知道这些就可以大胆地去做 socket 编程了。
题主题目中提到的网络编程模型(socket建立套接字->bind绑定ip->listen监听->accept接受连接)是服务器端的编程模型。
//服务端核心代码
int main(int argc, char const *argv[])
{
int fd = socket(AF_INET, SOCK_STREAM, 0);
bind(fd, ...);
listen(fd, 128);
accept(fd, ...);
...
}每一个来自客户端的TCP请求在服务器端都会对应一个 socket。事实上,这个新 socket 的创建实机既不是在 listen 的时候,也不是在 accept 的时候,而是在三次握手成功之后创建的,然后放在对应的全连接队列中。
这个结论是我挖掘过 Linux 3.10 内核里三次握手的源码后的出来的结论。我把内核源码整个三次握手工作过程汇总整理成了一张图了。
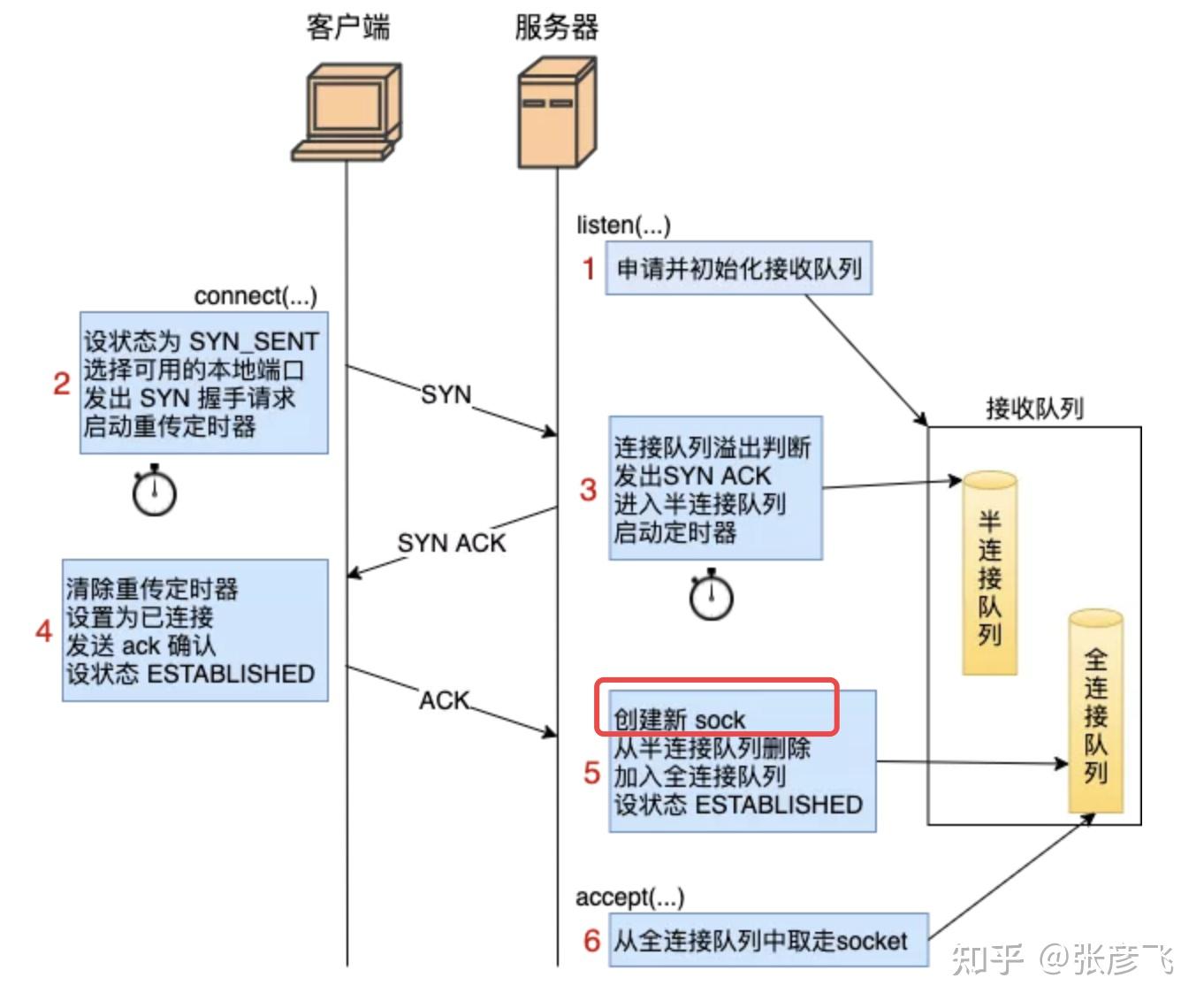
从这张图中的右侧(服务器部分)来看,服务器在 listen 状态的时候可以接收来自客户端的握手请求。当客户端发出的第三次 ack 到达时,服务器创建了新的 sock 对象(socket 的核心),然后加入到了全连接队列中。然后accept的时候,仅仅只是从全连接队列里把 sock 取出来而已。
为了严谨起见,我还是给你简单展示一下 3.10 内核的源码。这些我处理过,放心很容易理解的。服务器响应第三次握手的 ack 时会进入到 tcp_v4_do_rcv。
//file: net/ipv4/tcp_ipv4.c
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
...
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_hnd_req(sk, skb);
}
......
}在这里判断当前socket(正在 listen 的socket)的状态为监听,那么进入握手处理 tcp_v4_hnd_req。
//file:net/ipv4/tcp_ipv4.c
static struct sock *tcp_v4_hnd_req(struct sock *sk, struct sk_buff *skb)
{
...
struct request_sock *req = inet_csk_search_req(sk, &prev, th->source,
iph->saddr, iph->daddr);
if (req)
return tcp_check_req(sk, skb, req, prev, false);
...
}在握手处理中,inet_csk_search_req 这一行是在查找半连接队列。如果查找到了,那就说明是第三次握手,返回一个半连接 request_sock 对象。
然后进入到 tcp_check_req 中。你所要问的问题的关键就是在 tcp_check_req 这里。
//file:net/ipv4/tcp_minisocks.c
struct sock *tcp_check_req(struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct request_sock **prev,
bool fastopen)
{
...
//创建子 socket
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
...
//添加全连接队列
inet_csk_reqsk_queue_add(sk, req, child);
return child;
}在 inet_csk(sk)->icsk_af_ops->syn_recv_sock 这一行中就是题主问题的答案。 Socket 的核心部分就是在这里创建的。该函数又调用了 tcp_create_openreq_child => inet_csk_clone_lock => sk_clone_lock => sk_prot_alloc
static struct sock *sk_prot_alloc(struct proto *prot, gfp_t priority,
int family)
{
struct sock *sk;
struct kmem_cache *slab;
slab = prot->slab;
if (slab != NULL) {
sk = kmem_cache_alloc(slab, priority & ~__GFP_ZERO);
...
} else {
sk = kmalloc(prot->obj_size, priority);
}
}在 sk_prot_alloc 这里给 socket 申请了内存。kmalloc 和 kmem_cache_alloc 和大家平时用的 malloc 类似,是用来分配内存的。
其中 slab 内存我在这篇讲过: 内核在内存上给自己开了个小灶
大部分的开发同学都和题主一样(包括我自己),虽然网络协议学了很多,网络编程也用不了少。但就是二者之间没有打通。比如题主的这个问题,究竟新 socket 是啥时候创建的,好像讲到的资料并不多。
我类似的困惑还有,服务器listen的时候到底干了啥,客户端connect时的端口号是如何确定的,全连接队列半连接队列到底长度多长。 对于这些我都深入挖掘内核源码后整理了出来,献给大家。
- 为什么服务端程序都需要先 listen 一下?
- TCP连接中客户端的端口号是如何确定的?
- 能将三次握手理解到这个深度,面试官拍案叫绝!
- 深入解析常见三次握手异常
- 如何正确查看线上半/全连接队列溢出情况?
类似的问题还有,比如同步阻塞到底是咋回事,epoll到底是怎么工作的。
- 图解 | 深入理解高性能网络开发路上的绊脚石 - 同步阻塞网络 IO
- 图解 | 深入揭秘 epoll 是如何实现 IO 多路复用的!
一个网络包是如何从网卡接收到进程里的,网络包的发送过程又是怎么样的。这些问题都困惑了我一段时间。不过后来我都把它们趟平了。
- 图解Linux网络包接收过程
- 25 张图,一万字,拆解 Linux 网络包发送过程
127.0.0.1 之本机网络通信过程知多少 ?!
最后分享下我整理出来的网络电子书,《理解了实现再谈网络性能》。
该书目前正在出版流程中。需要的该电子版的同学戳这里下载,传送门:
《理解了实现再谈网络性能》电子书发布啦!
最后祝大家都能打通理论与实践的任督二脉!
举个通俗易懂的例子吧
你去餐馆吃饭,你作为顾客相当于应用程序,餐馆厨房相当于系统内核,服务员相当于内核和应用层之间的接口。
你点好菜写下来,交给服务员,相当于调用内核接口,这时你就阻塞了,一直等待上菜。
服务员把你点的菜交给厨房,相当于给了内核一个请求,这个订单进入了内核的任务队列。服务员没有一直等待这个订单,他就去招待其他客人了。
如果有空闲的厨师,他就会接受一个订单开始做菜,相当于响应请求。
厨师做好了一个菜,就召唤服务员上菜,如果某个服务员有空就会去上菜,相当于请求完成通知。
顾客得到一个菜,一次系统调用完成。
你看,这个过程里,只有顾客是一只在等待的,服务员和厨师一直都在工作,没有死循环。当然聪明的顾客其实也没有死等,他会去刷手机,等服务员上菜,他才放下手机开始吃。
现实世界里都不会有真的死循环。
本系列Netty源码解析文章基于 4.1.56.Final版本
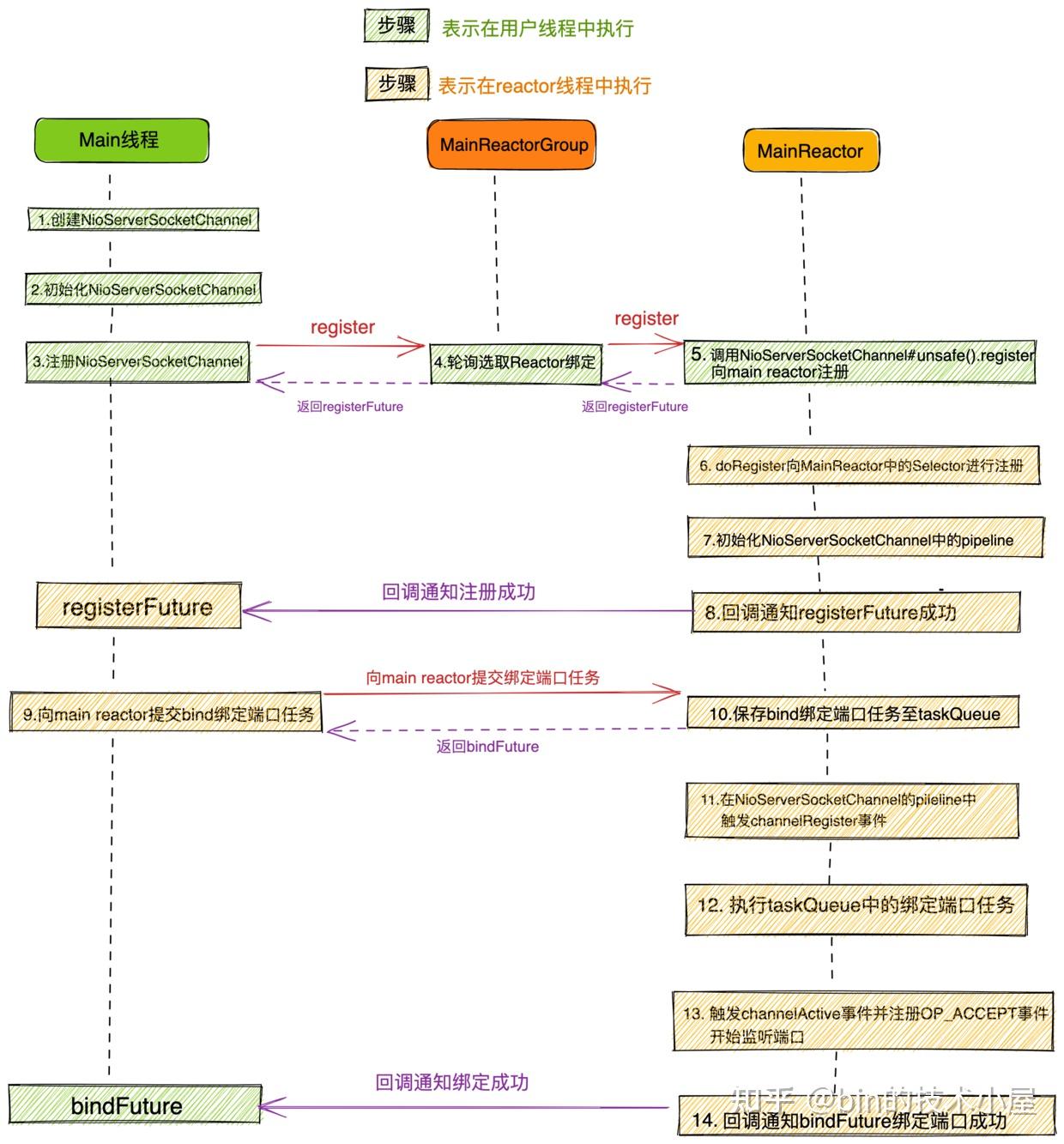
大家第一眼看到这幅流程图,是不是脑瓜子嗡嗡的呢?

大家先不要惊慌,问题不大,本文笔者的目的就是要让大家清晰的理解这幅流程图,从而深刻的理解Netty Reactor的启动全流程,包括其中涉及到的各种代码设计实现细节。

在上篇文章《聊聊Netty那些事儿之Reactor在Netty中的实现(创建篇)》中我们详细介绍了Netty服务端核心引擎组件主从Reactor组模型 NioEventLoopGroup以及Reactor模型 NioEventLoop的创建过程。最终我们得到了netty Reactor模型的运行骨架如下:
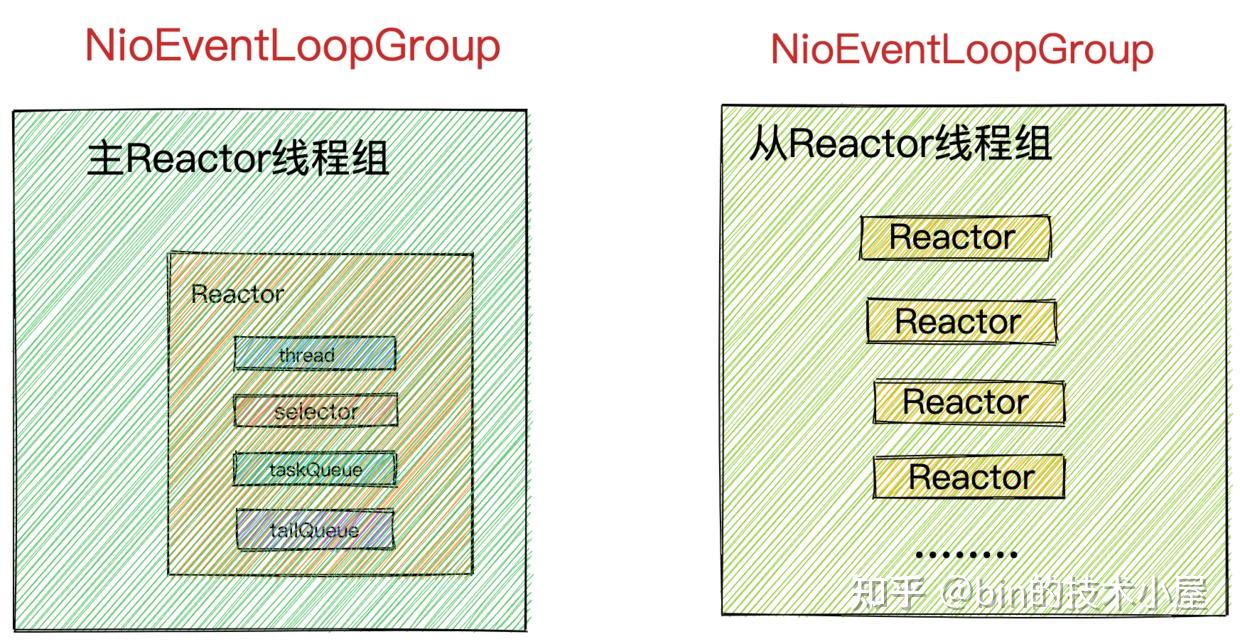
现在Netty服务端程序的骨架是搭建好了,本文我们就基于这个骨架来深入剖析下Netty服务端的启动过程。
我们继续回到上篇文章提到的Netty服务端代码模板中,在创建完主从Reactor线程组:bossGroup,workerGroup后,接下来就开始配置Netty服务端的启动辅助类ServerBootstrap了。
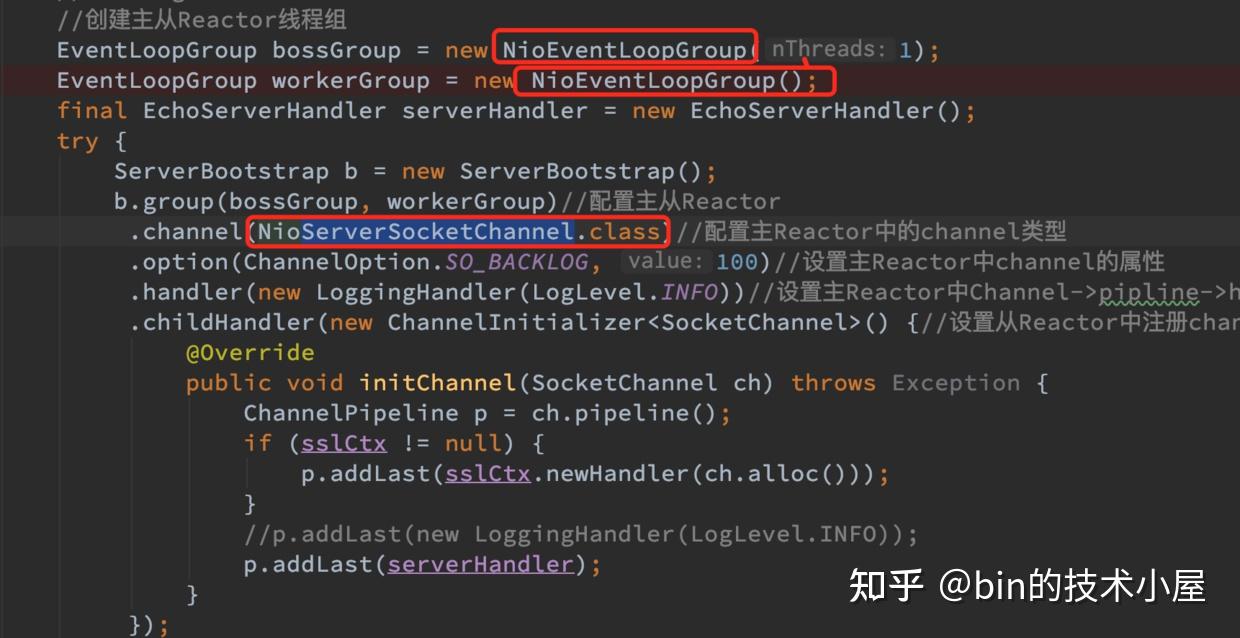
public final class EchoServer {
static final int PORT = Integer.parseInt(System.getProperty("port", "8007"));
public static void main(String[] args) throws Exception {
// Configure the server.
//创建主从Reactor线程组
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
final EchoServerHandler serverHandler = new EchoServerHandler();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)//配置主从Reactor
.channel(NioServerSocketChannel.class)//配置主Reactor中的channel类型
.option(ChannelOption.SO_BACKLOG, 100)//设置主Reactor中channel的option选项
.handler(new LoggingHandler(LogLevel.INFO))//设置主Reactor中Channel->pipline->handler
.childHandler(new ChannelInitializer<SocketChannel>() {//设置从Reactor中注册channel的pipeline
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
//p.addLast(new LoggingHandler(LogLevel.INFO));
p.addLast(serverHandler);
}
});
// Start the server. 绑定端口启动服务,开始监听accept事件
ChannelFuture f = b.bind(PORT).sync();
// Wait until the server socket is closed.
f.channel().closeFuture().sync();
} finally {
// Shut down all event loops to terminate all threads.
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}在上篇文章中我们对代码模板中涉及到ServerBootstrap的一些配置方法做了简单的介绍,大家如果忘记的话,可以在返回去回顾一下。
ServerBootstrap类其实没有什么特别的逻辑,主要是对Netty启动过程中需要用到的一些核心信息进行配置管理,比如:
- Netty的核心引擎组件
主从Reactor线程组: bossGroup,workerGroup。通过ServerBootstrap#group方法配置。
- Netty服务端使用到的Channel类型:
NioServerSocketChannel,通过ServerBootstrap#channel方法配置。 以及配置NioServerSocketChannel时用到的SocketOption。SocketOption用于设置底层JDK NIO Socket的一些选项。通过ServerBootstrap#option方法进行配置。
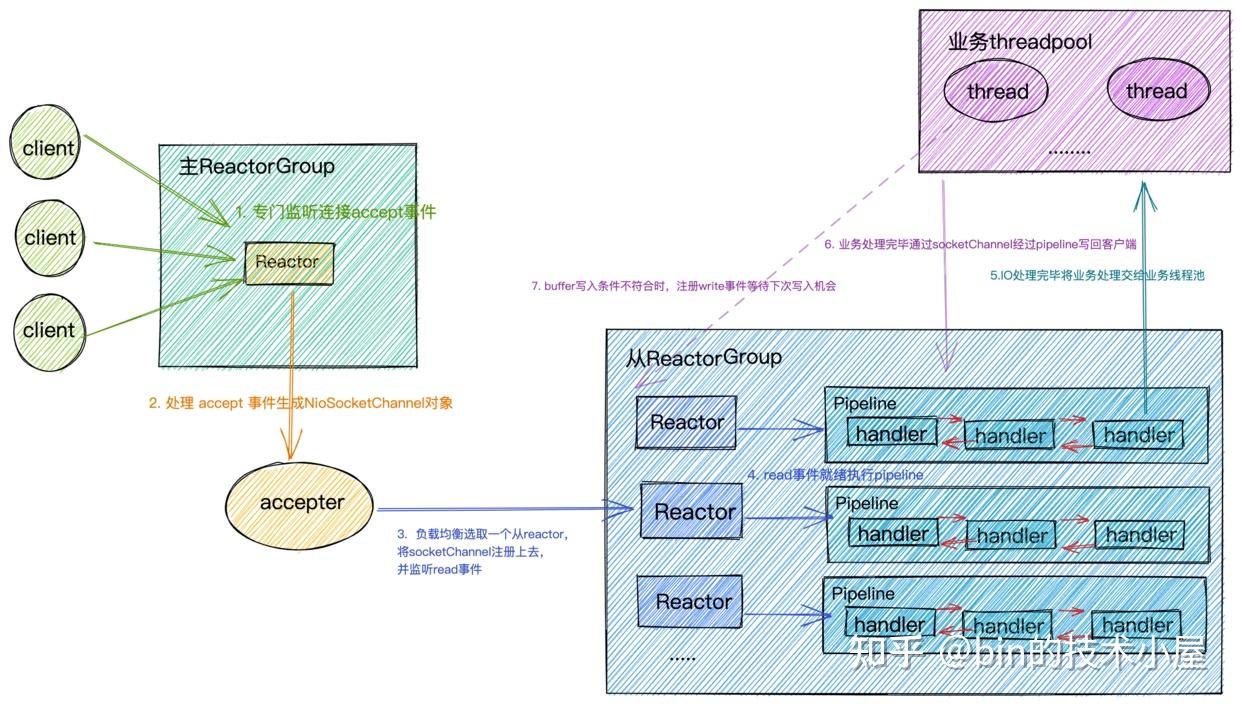
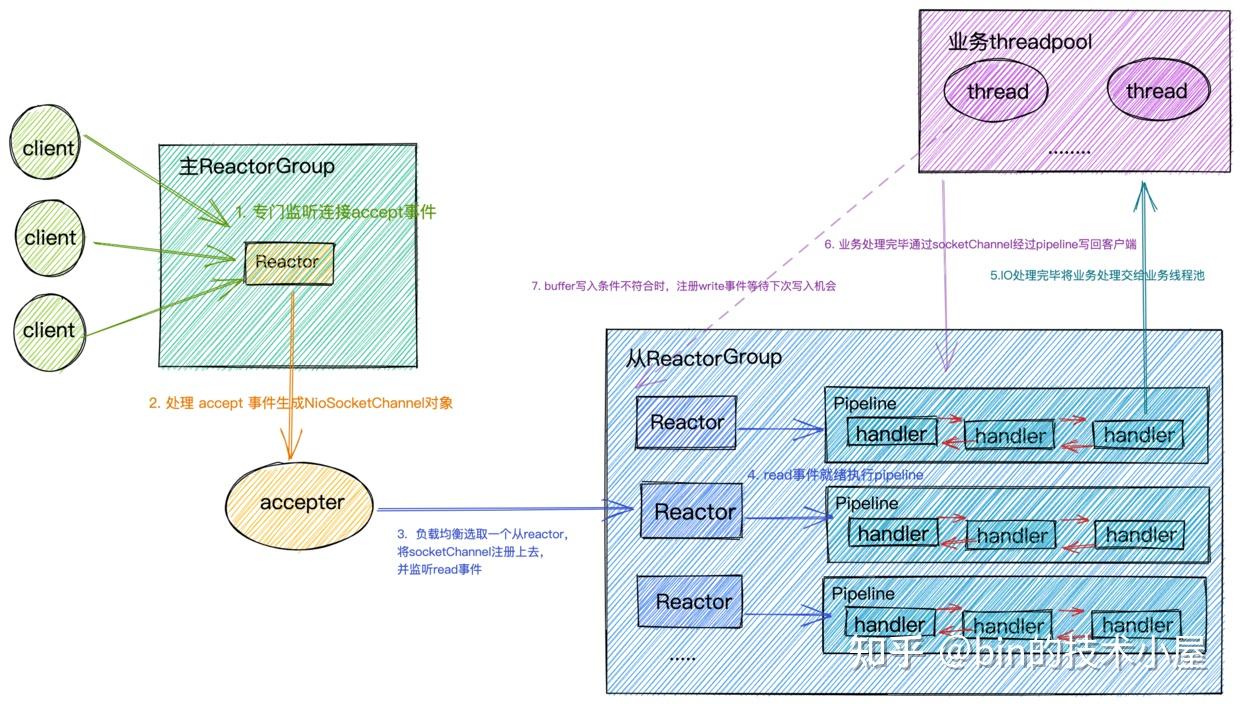
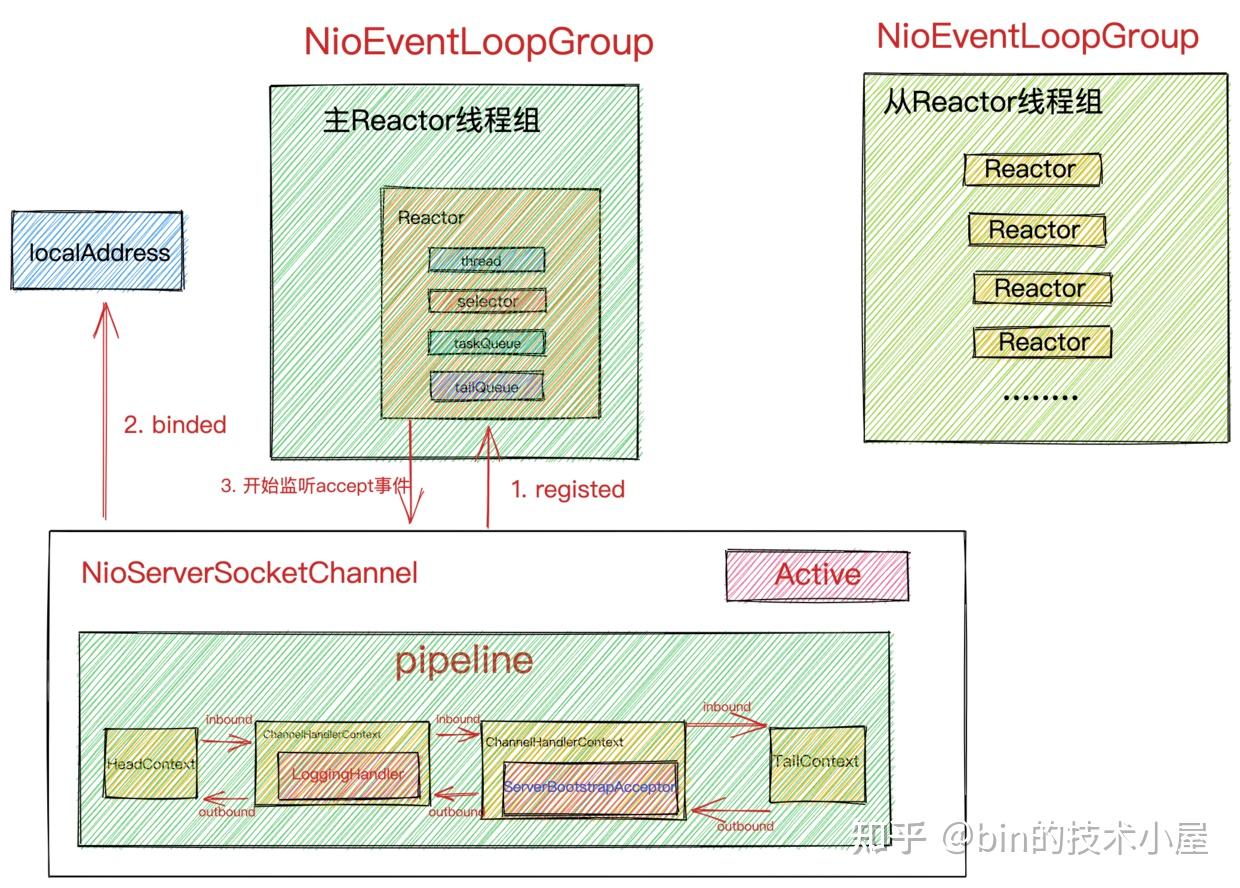
主ReactorGroup中的MainReactor管理的Channel类型为NioServerSocketChannel,如图所示主要用来监听端口,接收客户端连接,为客户端创建初始化NioSocketChannel,然后采用round-robin轮询的方式从图中从ReactorGroup中选择一个SubReactor与该客户端NioSocketChannel进行绑定。
从ReactorGroup中的SubReactor管理的Channel类型为NioSocketChannel,它是netty中定义客户端连接的一个模型,每个连接对应一个。如图所示SubReactor负责监听处理绑定在其上的所有NioSocketChannel上的IO事件。
- 保存服务端
NioServerSocketChannel和客户端NioSocketChannel对应pipeline中指定的ChannelHandler。用于后续Channel向Reactor注册成功之后,初始化Channel里的pipeline。
不管是服务端用到的NioServerSocketChannel还是客户端用到的NioSocketChannel,每个Channel实例都会有一个Pipeline,Pipeline中有多个ChannelHandler用于编排处理对应Channel上感兴趣的IO事件。
ServerBootstrap结构中包含了netty服务端程序启动的所有配置信息,在我们介绍启动流程之前,先来看下ServerBootstrap的源码结构:
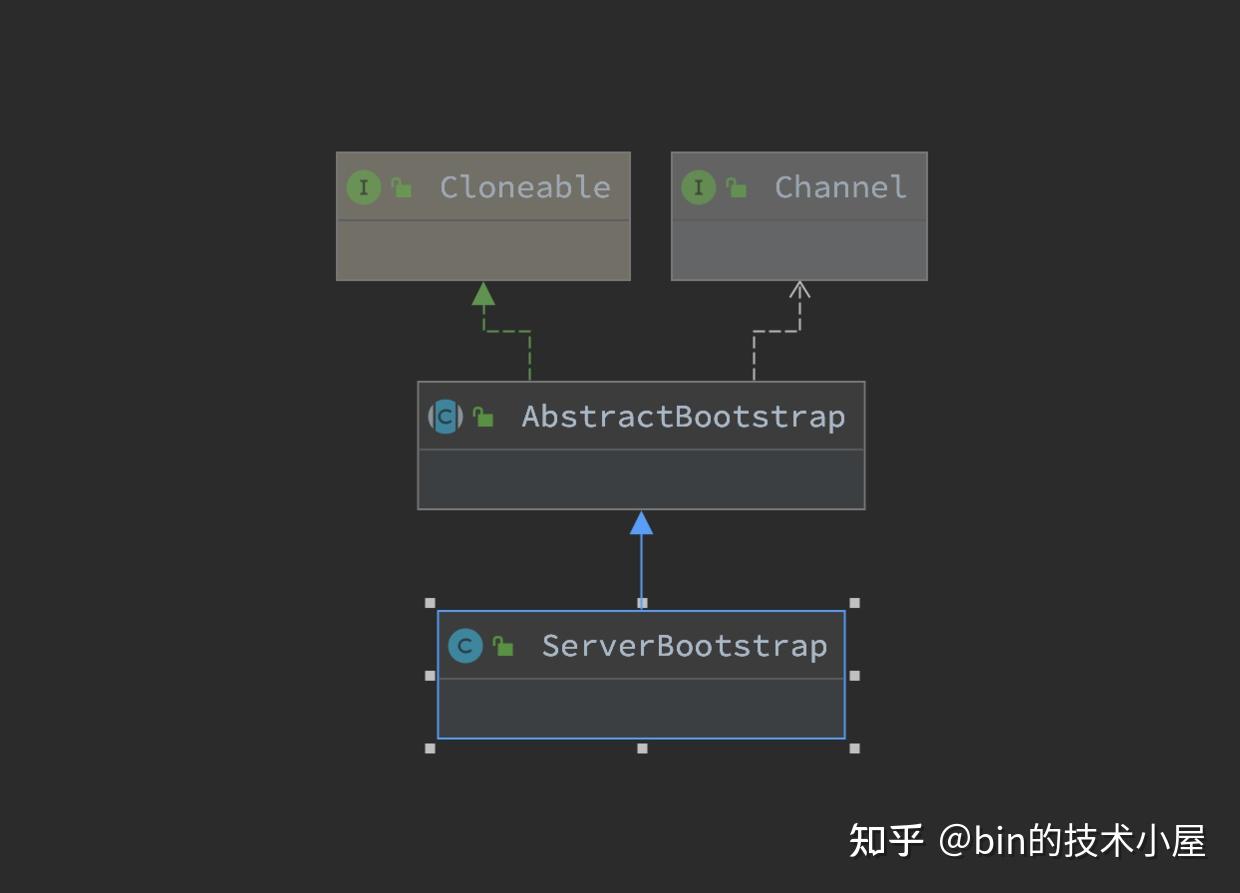
ServerBootstrap的继承结构比较简单,继承层次的职责分工也比较明确。
ServerBootstrap主要负责对主从Reactor线程组相关的配置进行管理,其中带child前缀的配置方法是对从Reactor线程组的相关配置管理。从Reactor线程组中的Sub Reactor负责管理的客户端NioSocketChannel相关配置存储在ServerBootstrap结构中。
父类AbstractBootstrap则是主要负责对主Reactor线程组相关的配置进行管理,以及主Reactor线程组中的Main Reactor负责处理的服务端ServerSocketChannel相关的配置管理。
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)//配置主从Reactor
public class ServerBootstrap extends AbstractBootstrap<ServerBootstrap, ServerChannel> {
//Main Reactor线程组
volatile EventLoopGroup group;
//Sub Reactor线程组
private volatile EventLoopGroup childGroup;
public ServerBootstrap group(EventLoopGroup parentGroup, EventLoopGroup childGroup) {
//父类管理主Reactor线程组
super.group(parentGroup);
if (this.childGroup != null) {
throw new IllegalStateException("childGroup set already");
}
this.childGroup = ObjectUtil.checkNotNull(childGroup, "childGroup");
return this;
}
}ServerBootstrap b = new ServerBootstrap();
b.channel(NioServerSocketChannel.class);
public class ServerBootstrap extends AbstractBootstrap<ServerBootstrap, ServerChannel> {
//用于创建ServerSocketChannel ReflectiveChannelFactory
private volatile ChannelFactory<? extends C> channelFactory;
public B channel(Class<? extends C> channelClass) {
return channelFactory(new ReflectiveChannelFactory<C>(
ObjectUtil.checkNotNull(channelClass, "channelClass")
));
}
@Deprecated
public B channelFactory(ChannelFactory<? extends C> channelFactory) {
ObjectUtil.checkNotNull(channelFactory, "channelFactory");
if (this.channelFactory != null) {
throw new IllegalStateException("channelFactory set already");
}
this.channelFactory = channelFactory;
return self();
}
}在向ServerBootstrap配置服务端ServerSocketChannel的channel方法中,其实是创建了一个ChannelFactory工厂实例ReflectiveChannelFactory,在Netty服务端启动的过程中,会通过这个ChannelFactory去创建相应的Channel实例。
我们可以通过这个方法来配置netty的IO模型,下面为ServerSocketChannel在不同IO模型下的实现:

EventLoopGroupReactor线程组在不同IO模型下的实现:

我们只需要将IO模型的这些核心接口对应的实现类前缀改为对应IO模型的前缀,就可以轻松在Netty中完成对IO模型的切换。
public class ReflectiveChannelFactory<T extends Channel> implements ChannelFactory<T> {
//NioServerSocketChannelde 构造器
private final Constructor<? extends T> constructor;
public ReflectiveChannelFactory(Class<? extends T> clazz) {
ObjectUtil.checkNotNull(clazz, "clazz");
try {
//反射获取NioServerSocketChannel的构造器
this.constructor = clazz.getConstructor();
} catch (NoSuchMethodException e) {
throw new IllegalArgumentException("Class " + StringUtil.simpleClassName(clazz) +
" does not have a public non-arg constructor", e);
}
}
@Override
public T newChannel() {
try {
//创建NioServerSocketChannel实例
return constructor.newInstance();
} catch (Throwable t) {
throw new ChannelException("Unable to create Channel from class " + constructor.getDeclaringClass(), t);
}
}
}从类的签名我们可以看出,这个工厂类是通过泛型加反射的方式来创建对应的Channel实例。
- 泛型参数
T extends Channel表示的是要通过工厂类创建的Channel类型,这里我们初始化的是NioServerSocketChannel。 - 在
ReflectiveChannelFactory的构造器中通过反射的方式获取NioServerSocketChannel的构造器。 - 在
newChannel方法中通过构造器反射创建NioServerSocketChannel实例。
注意这时只是配置阶段,NioServerSocketChannel此时并未被创建。它是在启动的时候才会被创建出来。
ServerBootstrap b = new ServerBootstrap();
//设置被MainReactor管理的NioServerSocketChannel的Socket选项
b.option(ChannelOption.SO_BACKLOG, 100)
public abstract class AbstractBootstrap<B extends AbstractBootstrap<B, C>, C extends Channel> implements Cloneable {
//serverSocketChannel中的ChannelOption配置
private final Map<ChannelOption<?>, Object> options = new LinkedHashMap<ChannelOption<?>, Object>();
public <T> B option(ChannelOption<T> option, T value) {
ObjectUtil.checkNotNull(option, "option");
synchronized (options) {
if (value == null) {
options.remove(option);
} else {
options.put(option, value);
}
}
return self();
}
}无论是服务端的NioServerSocketChannel还是客户端的NioSocketChannel它们的相关底层Socket选项ChannelOption配置全部存放于一个Map类型的数据结构中。
由于客户端NioSocketChannel是由从Reactor线程组中的Sub Reactor来负责处理,所以涉及到客户端NioSocketChannel所有的方法和配置全部是以child前缀开头。
ServerBootstrap b = new ServerBootstrap();
.childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE)
public class ServerBootstrap extends AbstractBootstrap<ServerBootstrap, ServerChannel> {
//客户端SocketChannel对应的ChannelOption配置
private final Map<ChannelOption<?>, Object> childOptions = new LinkedHashMap<ChannelOption<?>, Object>();
public <T> ServerBootstrap childOption(ChannelOption<T> childOption, T value) {
ObjectUtil.checkNotNull(childOption, "childOption");
synchronized (childOptions) {
if (value == null) {
childOptions.remove(childOption);
} else {
childOptions.put(childOption, value);
}
}
return this;
}
}相关的底层Socket选项,netty全部枚举在ChannelOption类中,笔者这里就不一一列举了,在本系列后续相关的文章中,笔者还会为大家详细的介绍这些参数的作用。
public class ChannelOption<T> extends AbstractConstant<ChannelOption<T>> {
..................省略..............
public static final ChannelOption<Boolean> SO_BROADCAST = valueOf("SO_BROADCAST");
public static final ChannelOption<Boolean> SO_KEEPALIVE = valueOf("SO_KEEPALIVE");
public static final ChannelOption<Integer> SO_SNDBUF = valueOf("SO_SNDBUF");
public static final ChannelOption<Integer> SO_RCVBUF = valueOf("SO_RCVBUF");
public static final ChannelOption<Boolean> SO_REUSEADDR = valueOf("SO_REUSEADDR");
public static final ChannelOption<Integer> SO_LINGER = valueOf("SO_LINGER");
public static final ChannelOption<Integer> SO_BACKLOG = valueOf("SO_BACKLOG");
public static final ChannelOption<Integer> SO_TIMEOUT = valueOf("SO_TIMEOUT");
..................省略..............
}//serverSocketChannel中pipeline里的handler(主要是acceptor)
private volatile ChannelHandler handler;
public B handler(ChannelHandler handler) {
this.handler = ObjectUtil.checkNotNull(handler, "handler");
return self();
}向NioServerSocketChannel中的Pipeline添加ChannelHandler分为两种方式:
显式添加:显式添加的方式是由用户在main线程中通过ServerBootstrap#handler的方式添加。如果需要添加多个ChannelHandler,则可以通过ChannelInitializer向pipeline中进行添加。
关于ChannelInitializer后面笔者会有详细介绍,这里大家只需要知道ChannelInitializer是一种特殊的ChannelHandler,用于初始化pipeline。适用于向pipeline中添加多个ChannelHandler的场景。
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)//配置主从Reactor
.channel(NioServerSocketChannel.class)//配置主Reactor中的channel类型
.handler(new ChannelInitializer<NioServerSocketChannel>() {
@Override
protected void initChannel(NioServerSocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
p.addLast(channelhandler1)
.addLast(channelHandler2)
......
.addLast(channelHandler3);
}
})隐式添加:隐式添加主要添加的就是主ReactorGroup的核心组件也就是下图中的acceptor,Netty中的实现为ServerBootstrapAcceptor,本质上也是一种ChannelHandler,主要负责在客户端连接建立好后,初始化客户端NioSocketChannel,在从Reactor线程组中选取一个Sub Reactor,将客户端NioSocketChannel注册到Sub Reactor中的selector上。
隐式添加ServerBootstrapAcceptor是由Netty框架在启动的时候负责添加,用户无需关心。
在本例中,NioServerSocketChannel的PipeLine中只有两个ChannelHandler,一个由用户在外部显式添加的LoggingHandler,另一个是由Netty框架隐式添加的ServerBootstrapAcceptor。
其实我们在实际项目使用的过程中,不会向netty服务端NioServerSocketChannel添加额外的ChannelHandler,NioServerSocketChannel只需要专心做好自己最重要的本职工作接收客户端连接就好了。这里额外添加一个LoggingHandler只是为了向大家展示ServerBootstrap的配置方法。
final EchoServerHandler serverHandler = new EchoServerHandler();
serverBootstrap.childHandler(new ChannelInitializer<SocketChannel>() {//设置从Reactor中注册channel的pipeline
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
p.addLast(new LoggingHandler(LogLevel.INFO));
p.addLast(serverHandler);
}
});
//socketChannel中pipeline中的处理handler
private volatile ChannelHandler childHandler;
public ServerBootstrap childHandler(ChannelHandler childHandler) {
this.childHandler = ObjectUtil.checkNotNull(childHandler, "childHandler");
return this;
}向客户端NioSocketChannel中的Pipeline里添加ChannelHandler完全是由用户自己控制显式添加,添加的数量不受限制。
由于在Netty的IO线程模型中,是由单个Sub Reactor线程负责执行客户端NioSocketChannel中的Pipeline,一个Sub Reactor线程负责处理多个NioSocketChannel上的IO事件,如果Pipeline中的ChannelHandler添加的太多,就会影响Sub Reactor线程执行其他NioSocketChannel上的Pipeline,从而降低IO处理效率,降低吞吐量。
所以Pipeline中的ChannelHandler不易添加过多,并且不能再ChannelHandler中执行耗时的业务处理任务。
在我们通过ServerBootstrap配置netty服务端启动信息的时候,无论是向服务端NioServerSocketChannel的pipeline中添加ChannelHandler,还是向客户端NioSocketChannel的pipeline中添加ChannelHandler,当涉及到多个ChannelHandler添加的时候,我们都会用到ChannelInitializer,那么这个ChannelInitializer究竟是何方圣神,为什么要这样做呢?我们接着往下看~~
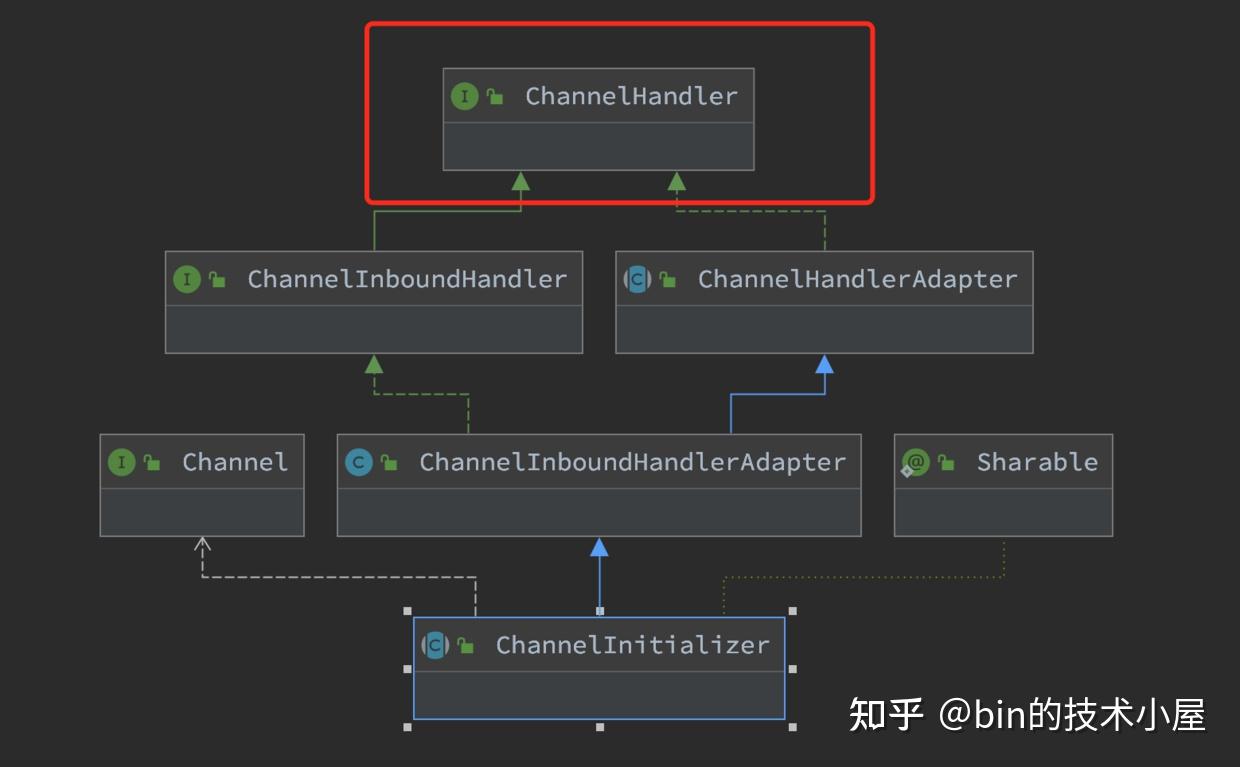
首先ChannelInitializer它继承于ChannelHandler,它自己本身就是一个ChannelHandler,所以它可以添加到childHandler中。
其他的父类大家这里可以不用管,后面文章中笔者会一一为大家详细介绍。
那为什么不直接添加ChannelHandler而是选择用ChannelInitializer呢?
这里主要有两点原因:
- 前边我们提到,客户端
NioSocketChannel是在服务端accept连接后,在服务端NioServerSocketChannel中被创建出来的。但是此时我们正处于配置ServerBootStrap阶段,服务端还没有启动,更没有客户端连接上来,此时客户端NioSocketChannel还没有被创建出来,所以也就没办法向客户端NioSocketChannel的pipeline中添加ChannelHandler。
- 客户端
NioSocketChannel中Pipeline里可以添加任意多个ChannelHandler,但是Netty框架无法预知用户到底需要添加多少个ChannelHandler,所以Netty框架提供了回调函数ChannelInitializer#initChannel,使用户可以自定义ChannelHandler的添加行为。
当客户端NioSocketChannel注册到对应的Sub Reactor上后,紧接着就会初始化NioSocketChannel中的Pipeline,此时Netty框架会回调ChannelInitializer#initChannel执行用户自定义的添加逻辑。
public abstract class ChannelInitializer<C extends Channel> extends ChannelInboundHandlerAdapter {
@Override
@SuppressWarnings("unchecked")
public final void channelRegistered(ChannelHandlerContext ctx) throws Exception {
//当channelRegister事件发生时,调用initChannel初始化pipeline
if (initChannel(ctx)) {
.................省略...............
} else {
.................省略...............
}
}
private boolean initChannel(ChannelHandlerContext ctx) throws Exception {
if (initMap.add(ctx)) { // Guard against re-entrance.
try {
//此时客户单NioSocketChannel已经创建并初始化好了
initChannel((C) ctx.channel());
} catch (Throwable cause) {
.................省略...............
} finally {
.................省略...............
}
return true;
}
return false;
}
protected abstract void initChannel(C ch) throws Exception;
.................省略...............
}这里由netty框架回调的ChannelInitializer#initChannel方法正是我们自定义的添加逻辑。
final EchoServerHandler serverHandler = new EchoServerHandler();
serverBootstrap.childHandler(new ChannelInitializer<SocketChannel>() {//设置从Reactor中注册channel的pipeline
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
p.addLast(new LoggingHandler(LogLevel.INFO));
p.addLast(serverHandler);
}
});到此为止,Netty服务端启动所需要的必要配置信息,已经全部存入ServerBootStrap启动辅助类中。
接下来要做的事情就是服务端的启动了。
// Start the server. 绑定端口启动服务,开始监听accept事件
ChannelFuture f = serverBootStrap.bind(PORT).sync();经过前面的铺垫终于来到了本文的核心内容----Netty服务端的启动过程。
如代码模板中的示例所示,Netty服务端的启动过程封装在io.netty.bootstrap.AbstractBootstrap#bind(int)函数中。
接下来我们看一下Netty服务端在启动过程中究竟干了哪些事情?
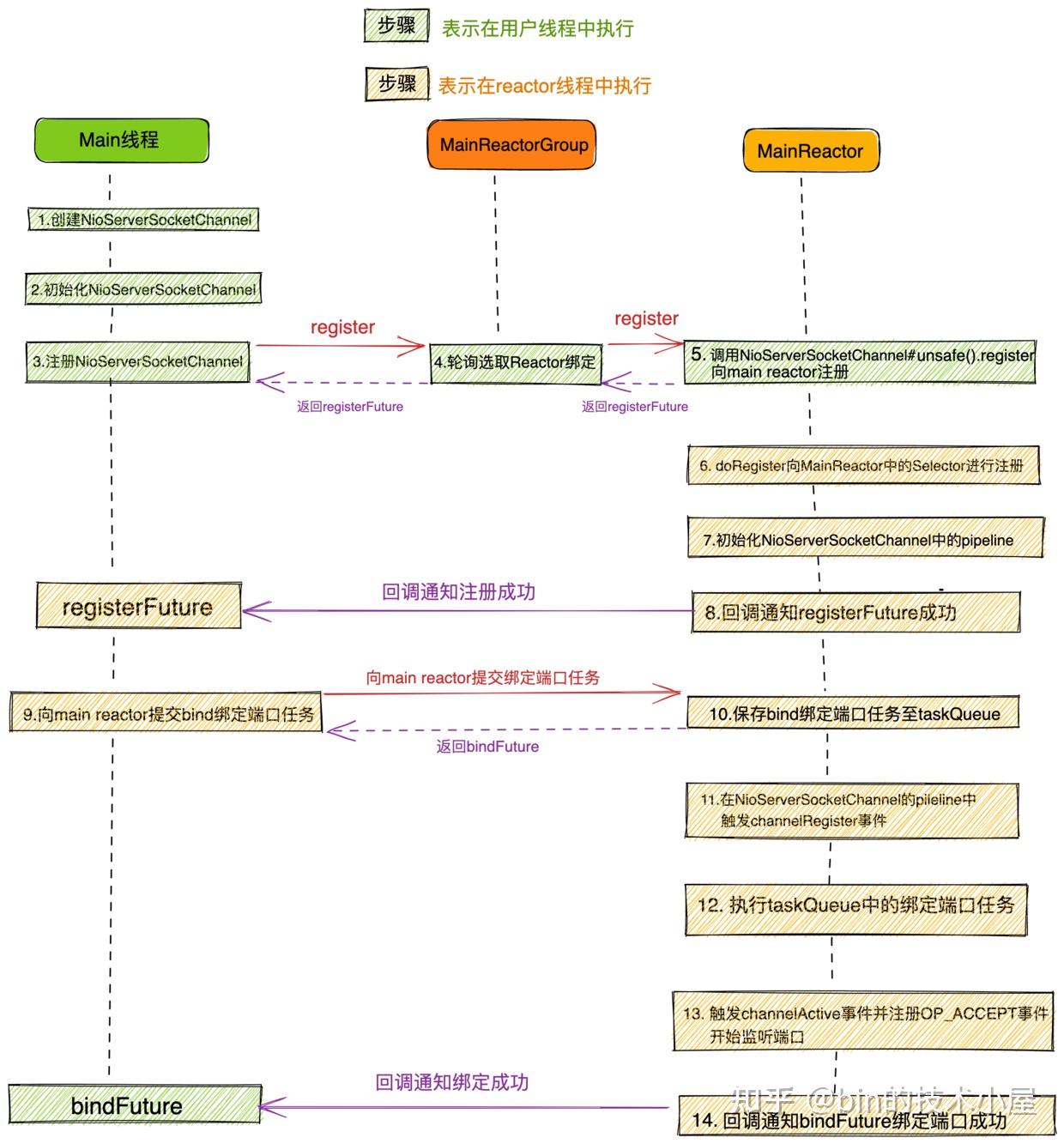
大家看到这副启动流程图先不要慌,接下来的内容笔者会带大家各个击破它,在文章的最后保证让大家看懂这副流程图。
我们先来从netty服务端启动的入口函数开始我们今天的源码解析旅程:
public ChannelFuture bind(int inetPort) {
return bind(new InetSocketAddress(inetPort));
}
public ChannelFuture bind(SocketAddress localAddress) {
//校验Netty核心组件是否配置齐全
validate();
//服务端开始启动,绑定端口地址,接收客户端连接
return doBind(ObjectUtil.checkNotNull(localAddress, "localAddress"));
}
private ChannelFuture doBind(final SocketAddress localAddress) {
//异步创建,初始化,注册ServerSocketChannel到main reactor上
final ChannelFuture regFuture = initAndRegister();
final Channel channel = regFuture.channel();
if (regFuture.cause() != null) {
return regFuture;
}
if (regFuture.isDone()) {
........serverSocketChannel向Main Reactor注册成功后开始绑定端口....,
} else {
//如果此时注册操作没有完成,则向regFuture添加operationComplete回调函数,注册成功后回调。
regFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
........serverSocketChannel向Main Reactor注册成功后开始绑定端口....,
});
return promise;
}
}Netty服务端的启动流程总体如下:
- 创建服务端
NioServerSocketChannel并初始化。
- 将服务端
NioServerSocketChannel注册到主Reactor线程组中。
- 注册成功后,开始初始化
NioServerSocketChannel中的pipeline,然后在pipeline中触发channelRegister事件。
- 随后由
NioServerSocketChannel绑定端口地址。
- 绑定端口地址成功后,向
NioServerSocketChannel对应的Pipeline中触发传播ChannelActive事件,在ChannelActive事件回调中向Main Reactor注册OP_ACCEPT事件,开始等待客户端连接。服务端启动完成。
当netty服务端启动成功之后,最终我们会得到如下结构的阵型,开始枕戈待旦,准备接收客户端的连接,Reactor开始运转。
接下来,我们就来看下Netty源码是如何实现以上步骤的~~
final ChannelFuture initAndRegister() {
Channel channel = null;
try {
//创建NioServerSocketChannel
//ReflectiveChannelFactory通过泛型,反射,工厂的方式灵活创建不同类型的channel
channel = channelFactory.newChannel();
//初始化NioServerSocketChannel
init(channel);
} catch (Throwable t) {
..............省略.................
}
//向MainReactor注册ServerSocketChannel
ChannelFuture regFuture = config().group().register(channel);
..............省略.................
return regFuture;
}从函数命名中我们可以看出,这个函数主要做的事情就是首先创建NioServerSocketChannel,并对NioServerSocketChannel进行初始化,最后将NioServerSocketChannel注册到Main Reactor中。
还记得我们在介绍ServerBootstrap启动辅助类配置服务端ServerSocketChannel类型的时候提到的工厂类ReflectiveChannelFactory吗?
因为当时我们在配置ServerBootstrap启动辅助类的时候,还没到启动阶段,而配置阶段并不是创建具体ServerSocketChannel的时机。
所以Netty通过工厂模式将要创建的ServerSocketChannel的类型(通过泛型指定)以及 创建的过程(封装在newChannel函数中)统统先封装在工厂类ReflectiveChannelFactory中。
ReflectiveChannelFactory通过泛型,反射,工厂的方式灵活创建不同类型的channel
等待创建时机来临,我们调用保存在ServerBootstrap中的channelFactory直接进行创建。
public class ReflectiveChannelFactory<T extends Channel> implements ChannelFactory<T> {
private final Constructor<? extends T> constructor;
@Override
public T newChannel() {
try {
return constructor.newInstance();
} catch (Throwable t) {
throw new ChannelException("Unable to create Channel from class " + constructor.getDeclaringClass(), t);
}
}
}下面我们来看下NioServerSocketChannel的构建过程:
public class NioServerSocketChannel extends AbstractNioMessageChannel
implements io.netty.channel.socket.ServerSocketChannel {
//SelectorProvider(用于创建Selector和Selectable Channels)
private static final SelectorProvider DEFAULT_SELECTOR_PROVIDER = SelectorProvider.provider();
public NioServerSocketChannel() {
this(newSocket(DEFAULT_SELECTOR_PROVIDER));
}
//创建JDK NIO ServerSocketChannel
private static ServerSocketChannel newSocket(SelectorProvider provider) {
try {
return provider.openServerSocketChannel();
} catch (IOException e) {
throw new ChannelException(
"Failed to open a server socket.", e);
}
}
//ServerSocketChannel相关的配置
private final ServerSocketChannelConfig config;
public NioServerSocketChannel(ServerSocketChannel channel) {
//父类AbstractNioChannel中保存JDK NIO原生ServerSocketChannel以及要监听的事件OP_ACCEPT
super(null, channel, SelectionKey.OP_ACCEPT);
//DefaultChannelConfig中设置用于Channel接收数据用的buffer->AdaptiveRecvByteBufAllocator
config = new NioServerSocketChannelConfig(this, javaChannel().socket());
}
}- 首先调用
newSocket创建JDK NIO 原生ServerSocketChannel,这里调用了SelectorProvider#openServerSocketChannel来创建JDK NIO 原生ServerSocketChannel,我们在上篇文章《聊聊Netty那些事儿之Reactor在Netty中的实现(创建篇)》中详细的介绍了SelectorProvider相关内容,当时是用SelectorProvider来创建Reactor中的Selector。大家还记得吗??
- 通过父类构造器设置
NioServerSocketChannel感兴趣的IO事件,这里设置的是SelectionKey.OP_ACCEPT事件。并将JDK NIO 原生ServerSocketChannel封装起来。
- 创建
Channel的配置类NioServerSocketChannelConfig,在配置类中封装了对Channel底层的一些配置行为,以及JDK中的ServerSocket。以及创建NioServerSocketChannel接收数据用的Buffer分配器AdaptiveRecvByteBufAllocator。
NioServerSocketChannelConfig没什么重要的东西,我们这里也不必深究,它就是管理NioServerSocketChannel相关的配置,这里唯一需要大家注意的是这个用于Channel接收数据用的Buffer分配器AdaptiveRecvByteBufAllocator,我们后面在介绍Netty如何接收连接的时候还会提到。
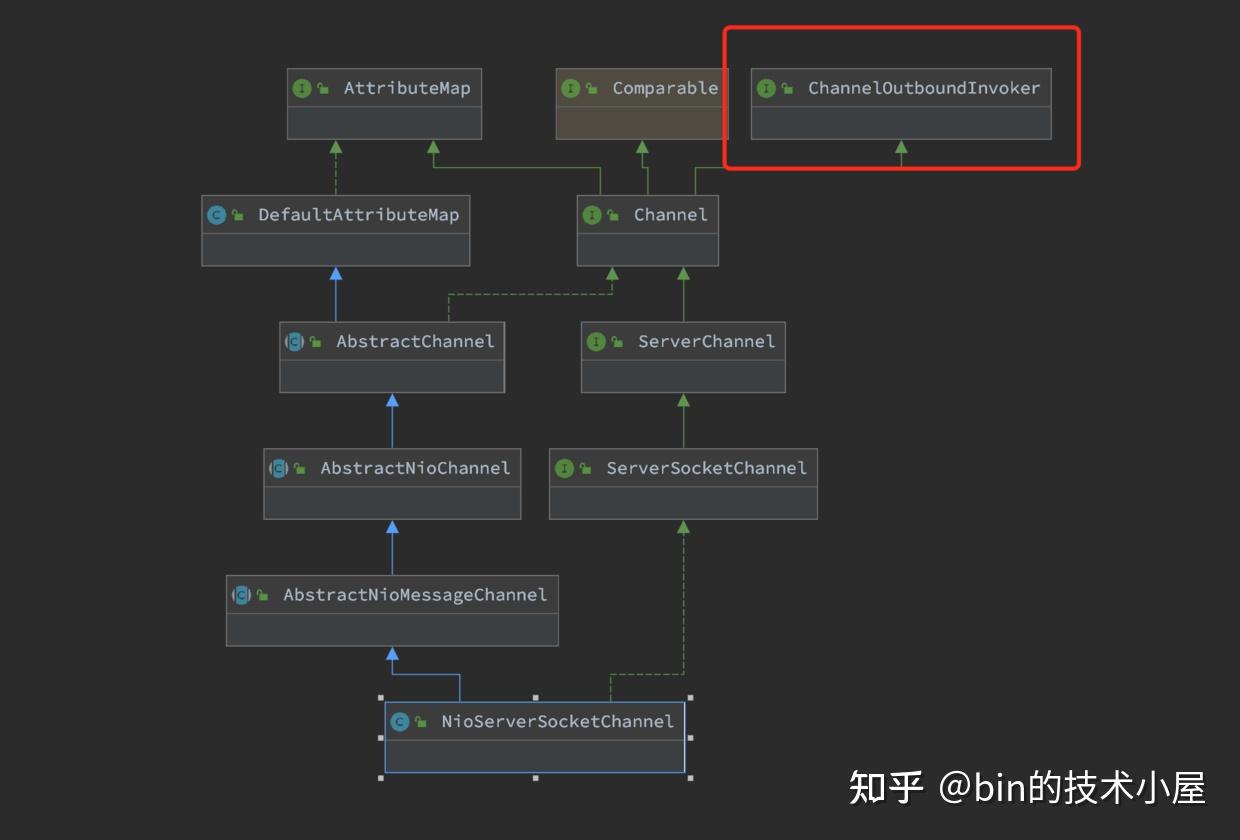
NioServerSocketChannel的整体构建过程介绍完了,现在我们来按照继承层次再回过头来看下NioServerSocketChannel的层次构建,来看下每一层都创建了什么,封装了什么,这些信息都是Channel的核心信息,所以有必要了解一下。
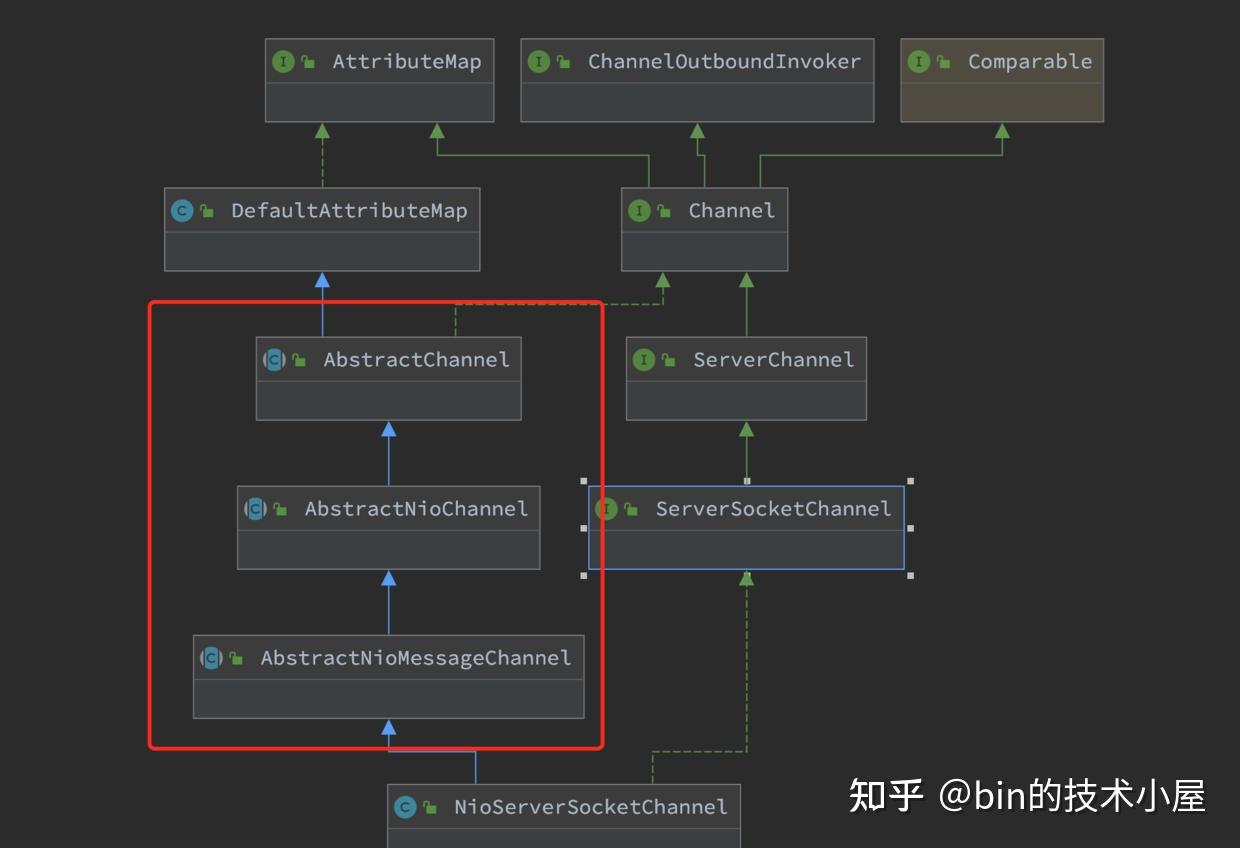
在NioServerSocketChannel的创建过程中,我们主要关注继承结构图中红框标注的三个类,其他的我们占时先不用管。
其中AbstractNioMessageChannel类主要是对NioServerSocketChannel底层读写行为的封装和定义,比如accept接收客户端连接。这个我们后续会介绍到,这里我们并不展开。
public abstract class AbstractNioChannel extends AbstractChannel {
//JDK NIO原生Selectable Channel
private final SelectableChannel ch;
// Channel监听事件集合 这里是SelectionKey.OP_ACCEPT事件
protected final int readInterestOp;
protected AbstractNioChannel(Channel parent, SelectableChannel ch, int readInterestOp) {
super(parent);
this.ch = ch;
this.readInterestOp = readInterestOp;
try {
//设置Channel为非阻塞 配合IO多路复用模型
ch.configureBlocking(false);
} catch (IOException e) {
.............省略................
}
}
}- 封装由
SelectorProvider创建出来的JDK NIO原生ServerSocketChannel。
- 封装
Channel在创建时指定感兴趣的IO事件,对于NioServerSocketChannel来说感兴趣的IO事件为OP_ACCEPT事件。
- 设置JDK NIO原生
ServerSocketChannel为非阻塞模式, 配合IO多路复用模型。
public abstract class AbstractChannel extends DefaultAttributeMap implements Channel {
//channel是由创建层次的,比如ServerSocketChannel 是 SocketChannel的 parent
private final Channel parent;
//channel全局唯一ID machineId+processId+sequence+timestamp+random
private final ChannelId id;
//unsafe用于封装对底层socket的相关操作
private final Unsafe unsafe;
//为channel分配独立的pipeline用于IO事件编排
private final DefaultChannelPipeline pipeline;
protected AbstractChannel(Channel parent) {
this.parent = parent;
//channel全局唯一ID machineId+processId+sequence+timestamp+random
id = newId();
//unsafe用于定义实现对Channel的底层操作
unsafe = newUnsafe();
//为channel分配独立的pipeline用于IO事件编排
pipeline = newChannelPipeline();
}
}- Netty中的
Channel创建是有层次的,这里的parent属性用来保存上一级的Channel,比如这里的NioServerSocketChannel是顶级Channel,所以它的parent = null。客户端NioSocketChannel是由NioServerSocketChannel创建的,所以它的parent = NioServerSocketChannel。
- 为
Channel分配全局唯一的ChannelId。ChannelId由机器Id(machineId),进程Id(processId),序列号(sequence),时间戳(timestamp),随机数(random)构成
private DefaultChannelId() {
data = new byte[MACHINE_ID.length + PROCESS_ID_LEN + SEQUENCE_LEN + TIMESTAMP_LEN + RANDOM_LEN];
int i = 0;
// machineId
System.arraycopy(MACHINE_ID, 0, data, i, MACHINE_ID.length);
i += MACHINE_ID.length;
// processId
i = writeInt(i, PROCESS_ID);
// sequence
i = writeInt(i, nextSequence.getAndIncrement());
// timestamp (kind of)
i = writeLong(i, Long.reverse(System.nanoTime()) ^ System.currentTimeMillis());
// random
int random = PlatformDependent.threadLocalRandom().nextInt();
i = writeInt(i, random);
assert i == data.length;
hashCode = Arrays.hashCode(data);
}- 创建
NioServerSocketChannel的底层操作类Unsafe。这里创建的是io.netty.channel.nio.AbstractNioMessageChannel.NioMessageUnsafe。
Unsafe为Channel接口的一个内部接口,用于定义实现对Channel底层的各种操作,Unsafe接口定义的操作行为只能由Netty框架的Reactor线程调用,用户线程禁止调用。
interface Unsafe {
//分配接收数据用的Buffer
RecvByteBufAllocator.Handle recvBufAllocHandle();
//服务端绑定的端口地址
SocketAddress localAddress();
//远端地址
SocketAddress remoteAddress();
//channel向Reactor注册
void register(EventLoop eventLoop, ChannelPromise promise);
//服务端绑定端口地址
void bind(SocketAddress localAddress, ChannelPromise promise);
//客户端连接服务端
void connect(SocketAddress remoteAddress, SocketAddress localAddress, ChannelPromise promise);
//关闭channle
void close(ChannelPromise promise);
//读数据
void beginRead();
//写数据
void write(Object msg, ChannelPromise promise);
}- 为
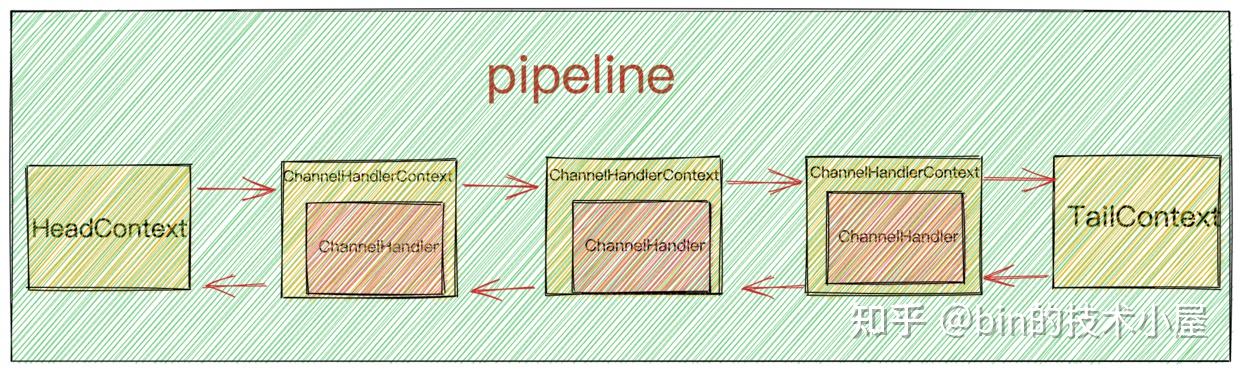
NioServerSocketChannel分配独立的pipeline用于IO事件编排。pipeline其实是一个ChannelHandlerContext类型的双向链表。头结点HeadContext,尾结点TailContext。ChannelHandlerContext中包装着ChannelHandler。
ChannelHandlerContext保存 ChannelHandler上下文信息,用于事件传播。后面笔者会单独开一篇文章介绍,这里我们还是聚焦于启动主线。
这里只是为了让大家简单理解pipeline的一个大致的结构,后面会写一篇文章专门详细讲解pipeline。
protected DefaultChannelPipeline(Channel channel) {
this.channel = ObjectUtil.checkNotNull(channel, "channel");
succeededFuture = new SucceededChannelFuture(channel, null);
voidPromise = new VoidChannelPromise(channel, true);
tail = new TailContext(this);
head = new HeadContext(this);
head.next = tail;
tail.prev = head;
}
到了这里NioServerSocketChannel就创建完毕了,我们来回顾下它到底包含了哪些核心信息。
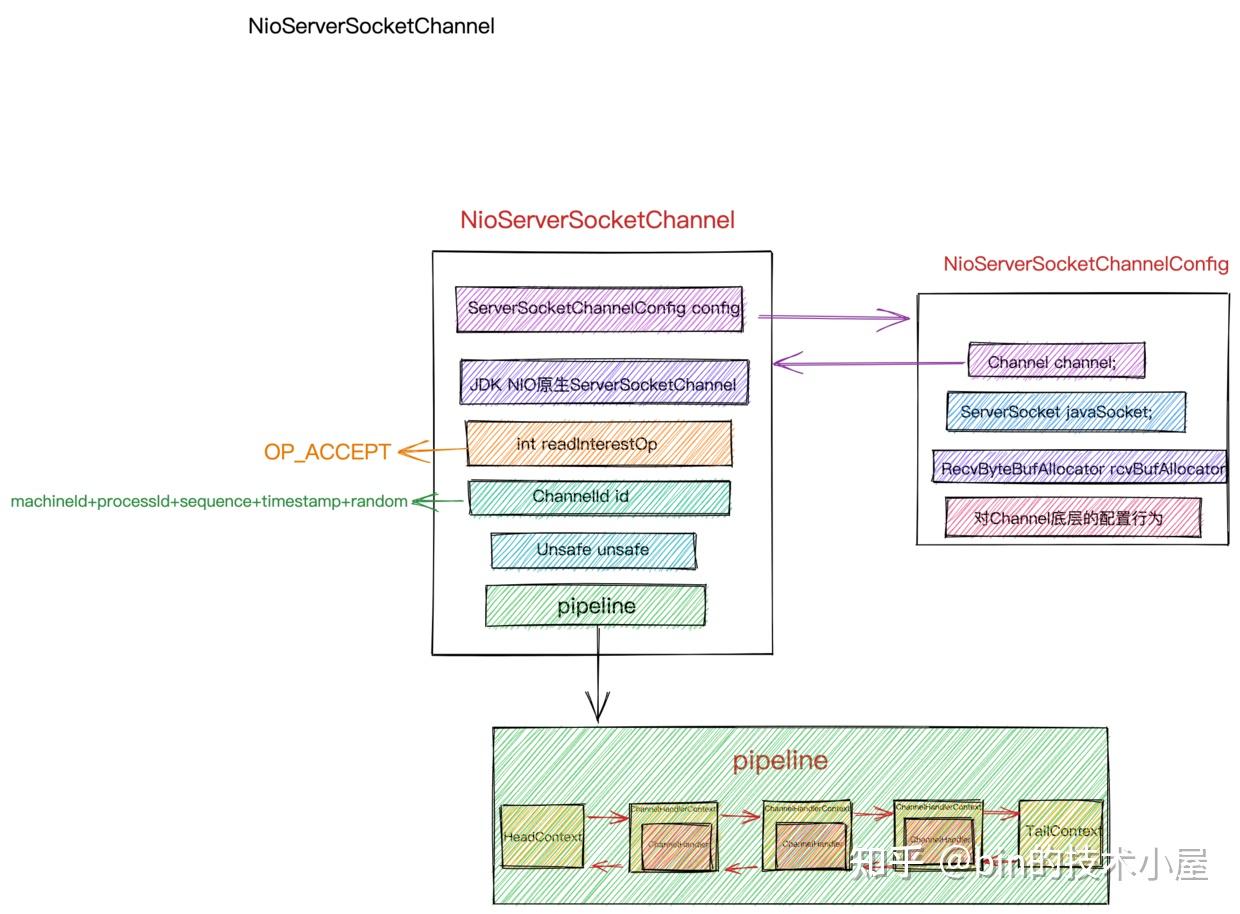
void init(Channel channel) {
//向NioServerSocketChannelConfig设置ServerSocketChannelOption
setChannelOptions(channel, newOptionsArray(), logger);
//向netty自定义的NioServerSocketChannel设置attributes
setAttributes(channel, attrs0().entrySet().toArray(EMPTY_ATTRIBUTE_ARRAY));
ChannelPipeline p = channel.pipeline();
//获取从Reactor线程组
final EventLoopGroup currentChildGroup = childGroup;
//获取用于初始化客户端NioSocketChannel的ChannelInitializer
final ChannelHandler currentChildHandler = childHandler;
//获取用户配置的客户端SocketChannel的channelOption以及attributes
final Entry<ChannelOption<?>, Object>[] currentChildOptions;
synchronized (childOptions) {
currentChildOptions = childOptions.entrySet().toArray(EMPTY_OPTION_ARRAY);
}
final Entry<AttributeKey<?>, Object>[] currentChildAttrs = childAttrs.entrySet().toArray(EMPTY_ATTRIBUTE_ARRAY);
//向NioServerSocketChannel中的pipeline添加初始化ChannelHandler的逻辑
p.addLast(new ChannelInitializer<Channel>() {
@Override
public void initChannel(final Channel ch) {
final ChannelPipeline pipeline = ch.pipeline();
//ServerBootstrap中用户指定的channelHandler
ChannelHandler handler = config.handler();
if (handler != null) {
//LoggingHandler
pipeline.addLast(handler);
}
//添加用于接收客户端连接的acceptor
ch.eventLoop().execute(new Runnable() {
@Override
public void run() {
pipeline.addLast(new ServerBootstrapAcceptor(
ch, currentChildGroup, currentChildHandler, currentChildOptions, currentChildAttrs));
}
});
}
});
}- 向
NioServerSocketChannelConfig设置ServerSocketChannelOption。
- 向netty自定义的
NioServerSocketChannel设置ChannelAttributes
Netty自定义的SocketChannel类型均继承AttributeMap接口以及DefaultAttributeMap类,正是它们定义了ChannelAttributes。用于向Channel添加用户自定义的一些信息。
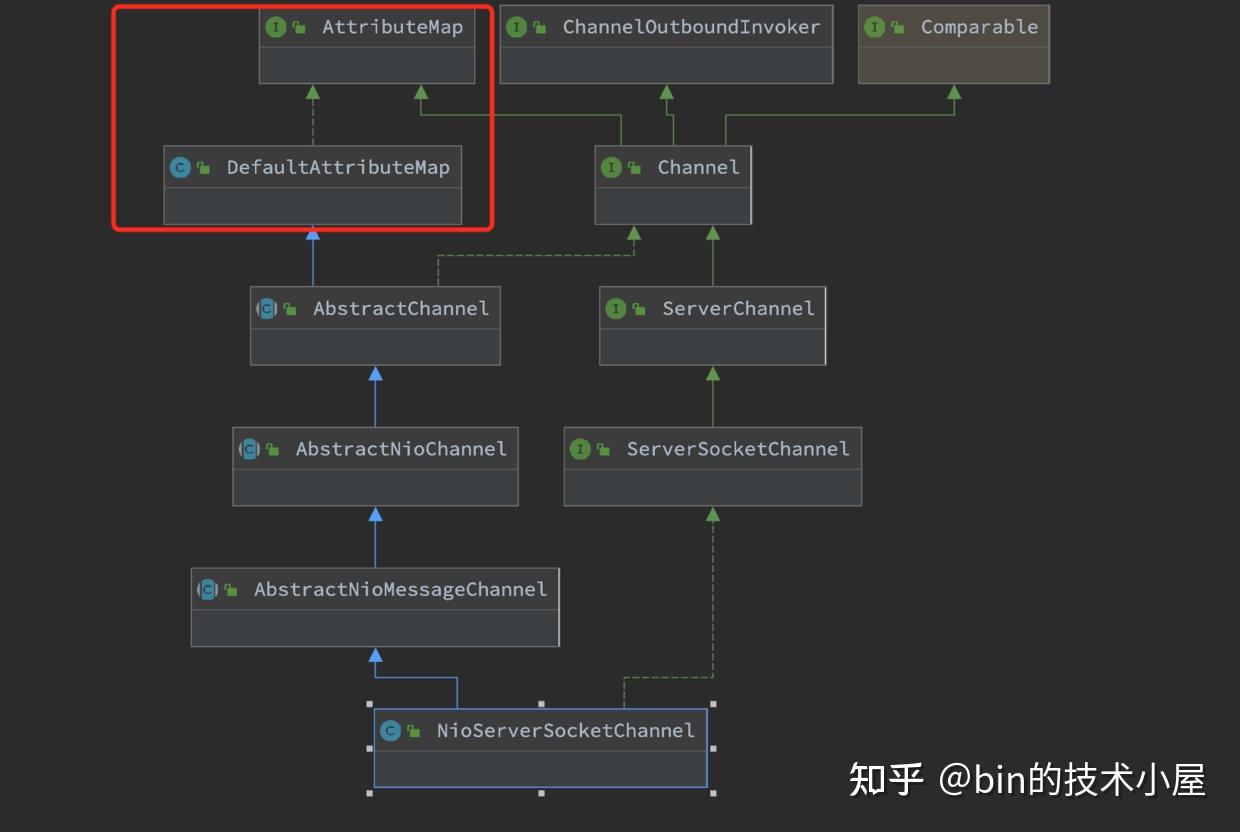
这个ChannelAttributes的用处大有可为,Netty后边的许多特性都是依靠这个ChannelAttributes来实现的。这里先卖个关子,大家可以自己先想一下可以用这个ChannelAttributes做哪些事情?
- 获取从Reactor线程组
childGroup,以及用于初始化客户端NioSocketChannel的ChannelInitializer,ChannelOption,ChannelAttributes,这些信息均是由用户在启动的时候向ServerBootstrap添加的客户端NioServerChannel配置信息。这里用这些信息来初始化ServerBootstrapAcceptor。因为后续会在ServerBootstrapAcceptor中接收客户端连接以及创建NioServerChannel。
- 向
NioServerSocketChannel中的pipeline添加用于初始化pipeline的ChannelInitializer。
问题来了,这里为什么不干脆直接将ChannelHandler添加到pipeline中,而是又使用到了ChannelInitializer呢?
其实原因有两点:
- 为了保证
线程安全地初始化pipeline,所以初始化的动作需要由Reactor线程进行,而当前线程是用户程序的启动Main线程并不是Reactor线程。这里不能立即初始化。
- 初始化
Channel中pipeline的动作,需要等到Channel注册到对应的Reactor中才可以进行初始化,当前只是创建好了NioServerSocketChannel,但并未注册到Main Reactor上。
初始化NioServerSocketChannel中pipeline的时机是:当NioServerSocketChannel注册到Main Reactor之后,绑定端口地址之前。
前边在介绍ServerBootstrap配置childHandler时也用到了ChannelInitializer,还记得吗??
问题又来了,大家注意下ChannelInitializer#initChannel方法,在该初始化回调方法中,添加LoggingHandler是直接向pipeline中添加,而添加Acceptor为什么不是直接添加而是封装成异步任务呢?
这里先给大家卖个关子,笔者会在后续流程中为大家解答~~~~~
此时NioServerSocketChannel中的pipeline结构如下图所示:
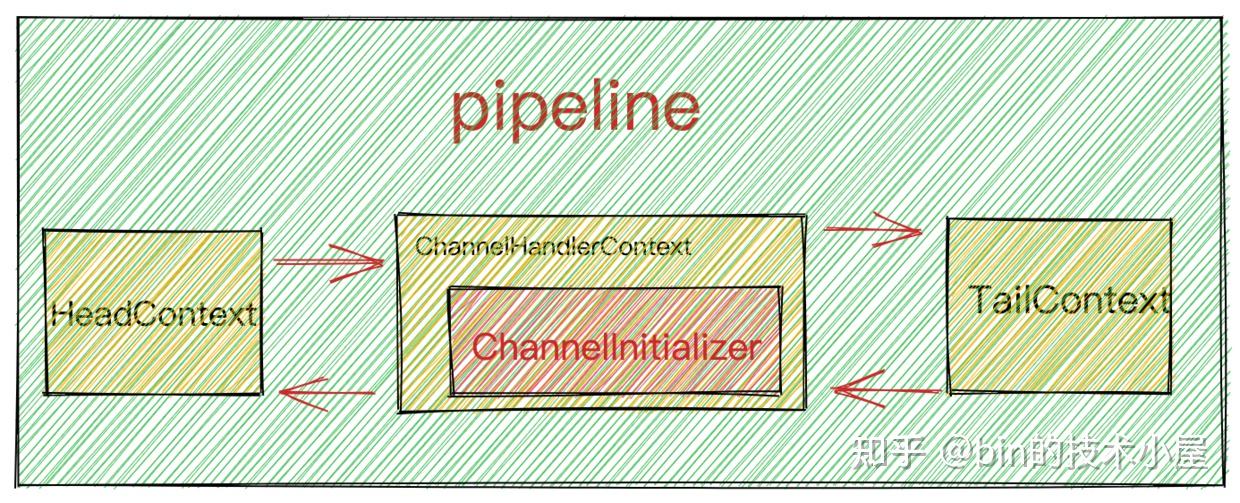
从ServerBootstrap获取主Reactor线程组NioEventLoopGroup,将NioServerSocketChannel注册到NioEventLoopGroup中。
ChannelFuture regFuture = config().group().register(channel);下面我们来看下具体的注册过程:
@Override
public ChannelFuture register(Channel channel) {
return next().register(channel);
}
@Override
public EventExecutor next() {
return chooser.next();
}
//获取绑定策略
@Override
public EventExecutorChooser newChooser(EventExecutor[] executors) {
if (isPowerOfTwo(executors.length)) {
return new PowerOfTwoEventExecutorChooser(executors);
} else {
return new GenericEventExecutorChooser(executors);
}
}
//采用轮询round-robin的方式选择Reactor
@Override
public EventExecutor next() {
return executors[(int) Math.abs(idx.getAndIncrement() % executors.length)];
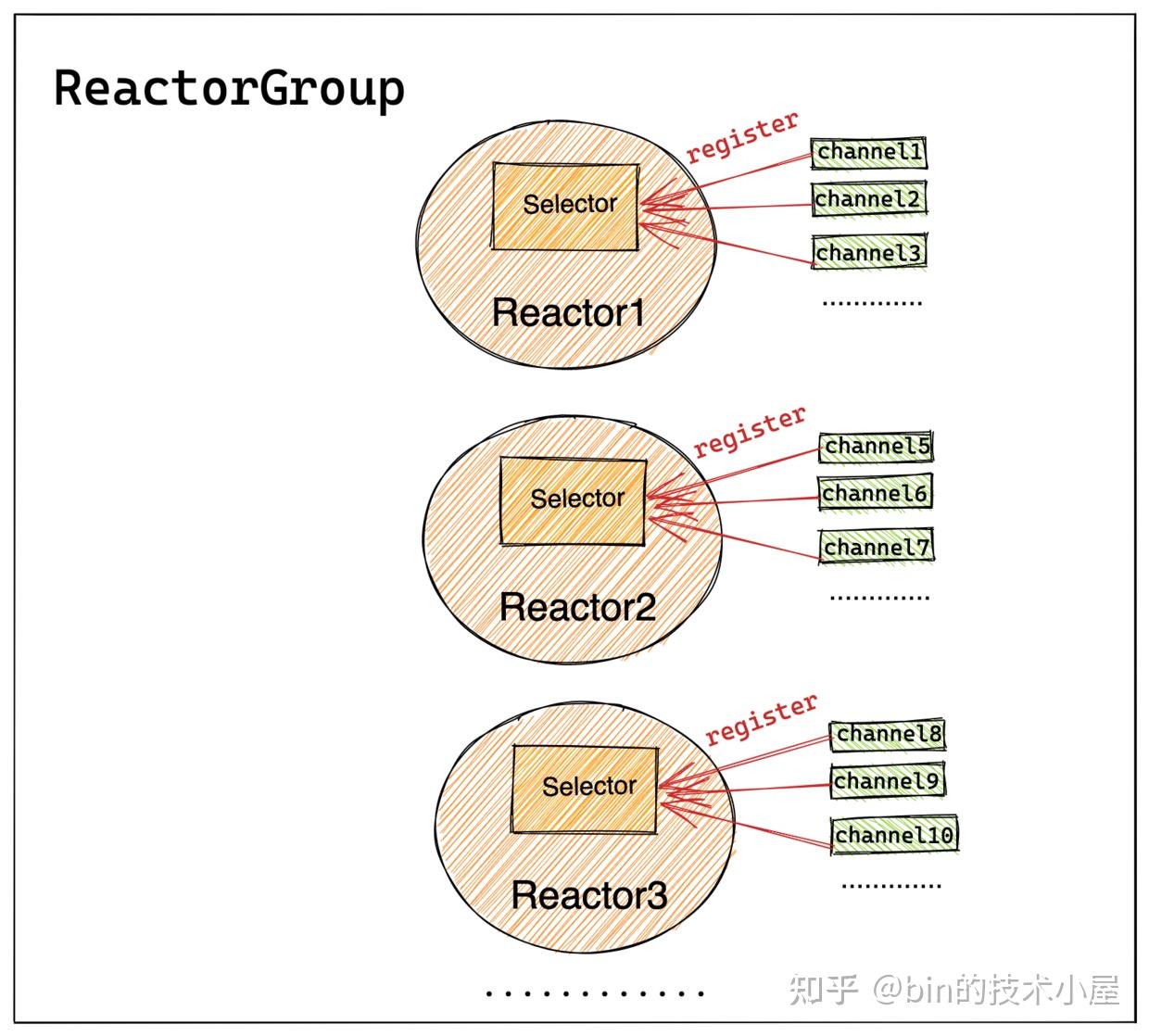
}Netty通过next()方法根据上篇文章《聊聊Netty那些事儿之Reactor在Netty中的实现(创建篇)》提到的channel到reactor的绑定策略,从ReactorGroup中选取一个Reactor进行注册绑定。之后Channel生命周期内的所有IO 事件都由这个Reactor 负责处理,如 accept、connect、read、write等 IO 事件。
一个channel只能绑定到一个Reactor上,一个Reactor负责监听多个channel。
由于这里是NioServerSocketChannle向Main Reactor进行注册绑定,所以Main Reactor主要负责处理的IO事件是OP_ACCEPT事件。
向Reactor进行注册的行为定义在NioEventLoop的父类SingleThreadEventLoop中,印象模糊的同学可以在回看下上篇文章中的NioEventLoop继承结构小节内容。
public abstract class SingleThreadEventLoop extends SingleThreadEventExecutor implements EventLoop {
@Override
public ChannelFuture register(Channel channel) {
//注册channel到绑定的Reactor上
return register(new DefaultChannelPromise(channel, this));
}
@Override
public ChannelFuture register(final ChannelPromise promise) {
ObjectUtil.checkNotNull(promise, "promise");
//unsafe负责channel底层的各种操作
promise.channel().unsafe().register(this, promise);
return promise;
}
}通过NioServerSocketChannel中的Unsafe类执行底层具体的注册动作。
protected abstract class AbstractUnsafe implements Unsafe {
/**
* 注册Channel到绑定的Reactor上
* */
@Override
public final void register(EventLoop eventLoop, final ChannelPromise promise) {
ObjectUtil.checkNotNull(eventLoop, "eventLoop");
if (isRegistered()) {
promise.setFailure(new IllegalStateException("registered to an event loop already"));
return;
}
//EventLoop的类型要与Channel的类型一样 Nio Oio Aio
if (!isCompatible(eventLoop)) {
promise.setFailure(
new IllegalStateException("incompatible event loop type: " + eventLoop.getClass().getName()));
return;
}
//在channel上设置绑定的Reactor
AbstractChannel.this.eventLoop = eventLoop;
/**
* 执行channel注册的操作必须是Reactor线程来完成
*
* 1: 如果当前执行线程是Reactor线程,则直接执行register0进行注册
* 2:如果当前执行线程是外部线程,则需要将register0注册操作 封装程异步Task 由Reactor线程执行
* */
if (eventLoop.inEventLoop()) {
register0(promise);
} else {
try {
eventLoop.execute(new Runnable() {
@Override
public void run() {
register0(promise);
}
});
} catch (Throwable t) {
...............省略...............
}
}
}
}- 首先检查
NioServerSocketChannel是否已经完成注册。如果以完成注册,则直接设置代表注册操作结果的ChannelPromise为fail状态。
- 通过
isCompatible方法验证Reactor模型EventLoop是否与Channel的类型匹配。NioEventLoop对应于NioServerSocketChannel。
上篇文章我们介绍过 Netty对三种IO模型:Oio,Nio,Aio的支持,用户可以通过改变Netty核心类的前缀轻松切换IO模型。isCompatible方法目的就是需要保证Reactor和Channel使用的是同一种IO模型。
- 在
Channel中保存其绑定的Reactor实例。
- 执行
Channel向Reactor注册的动作必须要确保是在Reactor线程中执行。
- 如果当前线程是
Reactor线程则直接执行注册动作register0 - 如果当前线程不是
Reactor线程,则需要将注册动作register0封装成异步任务,存放在Reactor中的taskQueue中,等待Reactor线程执行。
当前执行线程并不是Reactor线程,而是用户程序的启动线程Main线程。
上篇文章中我们在介绍NioEventLoopGroup的创建过程中提到了一个构造器参数executor,它用于启动Reactor线程,类型为ThreadPerTaskExecutor。
当时笔者向大家卖了一个关子~~“Reactor线程是何时启动的?”

那么现在就到了为大家揭晓谜底的时候了~~
Reactor线程的启动是在向Reactor提交第一个异步任务的时候启动的。
Netty中的主Reactor线程组NioEventLoopGroup中的Main ReactorNioEventLoop是在用户程序Main线程向Main Reactor提交用于注册NioServerSocketChannel的异步任务时开始启动。
eventLoop.execute(new Runnable() {
@Override
public void run() {
register0(promise);
}
});接下来我们关注下NioEventLoop的execute方法
public abstract class SingleThreadEventExecutor extends AbstractScheduledEventExecutor implements OrderedEventExecutor {
@Override
public void execute(Runnable task) {
ObjectUtil.checkNotNull(task, "task");
execute(task, !(task instanceof LazyRunnable) && wakesUpForTask(task));
}
private void execute(Runnable task, boolean immediate) {
//当前线程是否为Reactor线程
boolean inEventLoop = inEventLoop();
//addTaskWakesUp = true addTask唤醒Reactor线程执行任务
addTask(task);
if (!inEventLoop) {
//如果当前线程不是Reactor线程,则启动Reactor线程
//这里可以看出Reactor线程的启动是通过 向NioEventLoop添加异步任务时启动的
startThread();
.....................省略.....................
}
.....................省略.....................
}
}- 首先将异步任务
task添加到Reactor中的taskQueue中。
- 判断当前线程是否为
Reactor线程,此时当前执行线程为用户程序启动线程,所以这里调用startThread启动Reactor线程。
public abstract class SingleThreadEventExecutor extends AbstractScheduledEventExecutor implements OrderedEventExecutor {
//定义Reactor线程状态
private static final int ST_NOT_STARTED = 1;
private static final int ST_STARTED = 2;
private static final int ST_SHUTTING_DOWN = 3;
private static final int ST_SHUTDOWN = 4;
private static final int ST_TERMINATED = 5;
//Reactor线程状态 初始为 未启动状态
private volatile int state = ST_NOT_STARTED;
//Reactor线程状态字段state 原子更新器
private static final AtomicIntegerFieldUpdater<SingleThreadEventExecutor> STATE_UPDATER =
AtomicIntegerFieldUpdater.newUpdater(SingleThreadEventExecutor.class, "state");
private void startThread() {
if (state == ST_NOT_STARTED) {
if (STATE_UPDATER.compareAndSet(this, ST_NOT_STARTED, ST_STARTED)) {
boolean success = false;
try {
doStartThread();
success = true;
} finally {
if (!success) {
STATE_UPDATER.compareAndSet(this, ST_STARTED, ST_NOT_STARTED);
}
}
}
}
}
}Reactor线程初始化状态为ST_NOT_STARTED,首先CAS更新状态为ST_STARTED
doStartThread启动Reactor线程
- 启动失败的话,需要将
Reactor线程状态改回ST_NOT_STARTED
//ThreadPerTaskExecutor 用于启动Reactor线程
private final Executor executor;
private void doStartThread() {
assert thread == null;
executor.execute(new Runnable() {
@Override
public void run() {
thread = Thread.currentThread();
if (interrupted) {
thread.interrupt();
}
boolean success = false;
updateLastExecutionTime();
try {
//Reactor线程开始启动
SingleThreadEventExecutor.this.run();
success = true;
}
................省略..............
}这里就来到了ThreadPerTaskExecutor类型的executor的用武之地了。
Reactor线程的核心工作之前介绍过:轮询所有注册其上的Channel中的IO就绪事件,处理对应Channel上的IO事件,执行异步任务。Netty将这些核心工作封装在io.netty.channel.nio.NioEventLoop#run方法中。

- 将
NioEventLoop#run封装在异步任务中,提交给executor执行,Reactor线程至此开始工作了就。
public final class ThreadPerTaskExecutor implements Executor {
private final ThreadFactory threadFactory;
@Override
public void execute(Runnable command) {
//启动Reactor线程
threadFactory.newThread(command).start();
}
}此时Reactor线程已经启动,后面的工作全部都由这个Reactor线程来负责执行了。
而用户启动线程在向Reactor提交完NioServerSocketChannel的注册任务register0后,就逐步退出调用堆栈,回退到最开始的启动入口处ChannelFuture f = b.bind(PORT).sync()。
此时Reactor中的任务队列中只有一个任务register0,Reactor线程启动后,会从任务队列中取出任务执行。
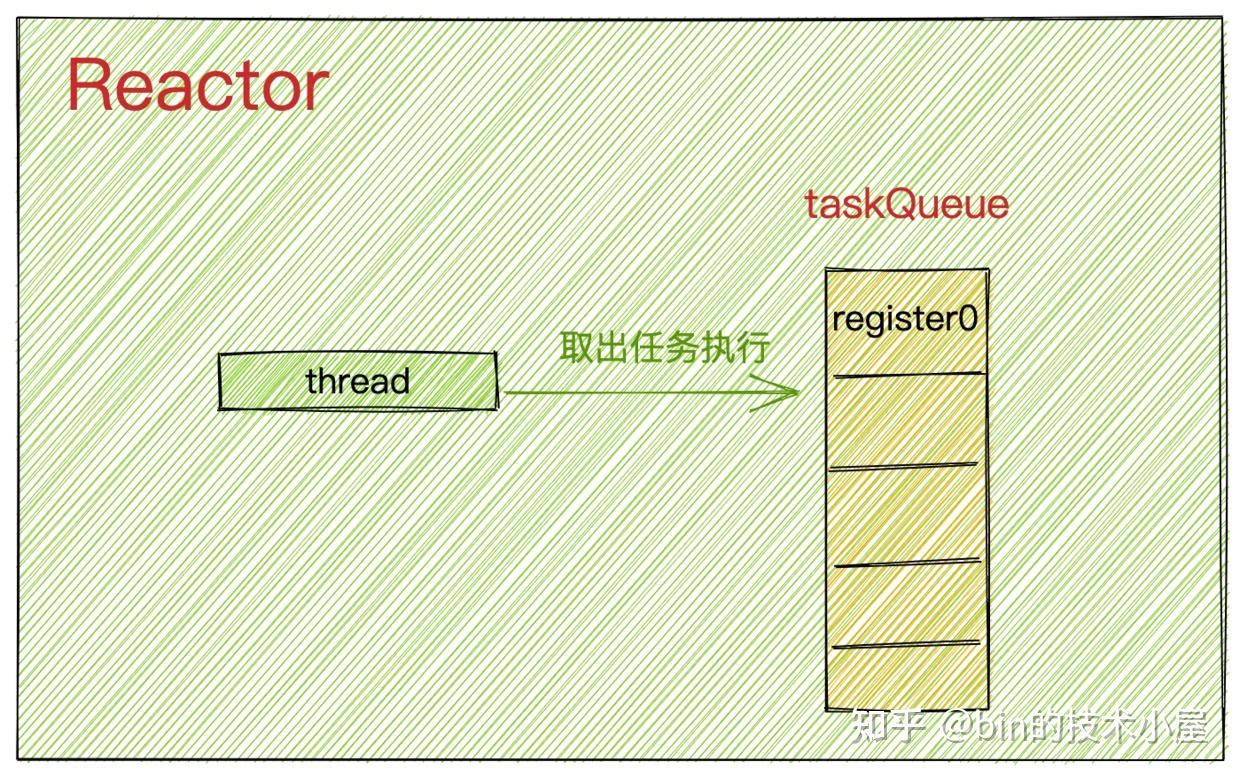
至此NioServerSocketChannel的注册工作正式拉开帷幕~~
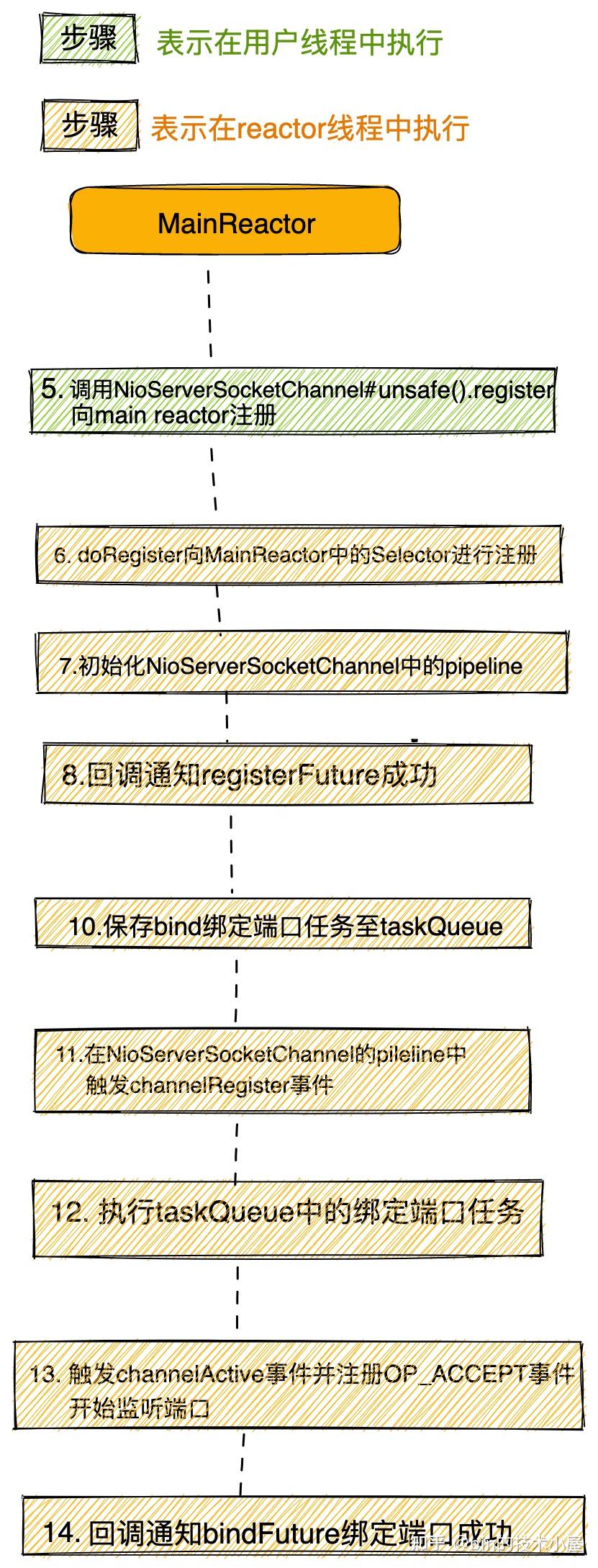
//true if the channel has never been registered, false otherwise
private boolean neverRegistered = true;
private void register0(ChannelPromise promise) {
try {
//查看注册操作是否已经取消,或者对应channel已经关闭
if (!promise.setUncancellable() || !ensureOpen(promise)) {
return;
}
boolean firstRegistration = neverRegistered;
//执行真正的注册操作
doRegister();
//修改注册状态
neverRegistered = false;
registered = true;
//回调pipeline中添加的ChannelInitializer的handlerAdded方法,在这里初始化channelPipeline
pipeline.invokeHandlerAddedIfNeeded();
//设置regFuture为success,触发operationComplete回调,将bind操作放入Reactor的任务队列中,等待Reactor线程执行。
safeSetSuccess(promise);
//触发channelRegister事件
pipeline.fireChannelRegistered();
//对于服务端ServerSocketChannel来说 只有绑定端口地址成功后 channel的状态才是active的。
//此时绑定操作作为异步任务在Reactor的任务队列中,绑定操作还没开始,所以这里的isActive()是false
if (isActive()) {
if (firstRegistration) {
//触发channelActive事件
pipeline.fireChannelActive();
} else if (config().isAutoRead()) {
beginRead();
}
}
} catch (Throwable t) {
............省略.............
}
}register0是驱动整个Channel注册绑定流程的关键方法,下面我们来看下它的核心逻辑:
- 首先需要检查
Channel的注册动作是否在Reactor线程外被取消了已经!promise.setUncancellable()。检查要注册的Channel是否已经关闭!ensureOpen(promise)。如果Channel已经关闭或者注册操作已经被取消,那么就直接返回,停止注册流程。
- 调用
doRegister()方法,执行真正的注册操作。最终实现在AbstractChannel的子类AbstractNioChannel中,这个我们一会在介绍,先关注整体流程。
public abstract class AbstractChannel extends DefaultAttributeMap implements Channel {
/**
* Is called after the {@link Channel} is registered with its {@link EventLoop} as part of the register process.
*
* Sub-classes may override this method
*/
protected void doRegister() throws Exception {
// NOOP
}
}- 当
Channel向Reactor注册完毕后,调用pipeline.invokeHandlerAddedIfNeeded()方法,触发回调pipeline中添加的ChannelInitializer的handlerAdded方法,在handlerAdded方法中利用前面提到的ChannelInitializer初始化ChannelPipeline。
初始化ChannelPipeline的时机是当Channel向对应的Reactor注册成功后,在handlerAdded事件回调中利用ChannelInitializer进行初始化。
- 设置
regFuture为Success,并回调注册在regFuture上的ChannelFutureListener#operationComplete方法,在operationComplete回调方法中将绑定操作封装成异步任务,提交到Reactor的taskQueue中。等待Reactor的执行。
还记得这个regFuture在哪里出现的吗?它是在哪里被创建,又是在哪里添加的ChannelFutureListener呢? 大家还有印象吗?回忆不起来也没关系,笔者后面还会提到
- 通过
pipeline.fireChannelRegistered()在pipeline中触发channelRegister事件。
pipeline中channelHandler的channelRegistered方法被回调。
- 对于Netty服务端
NioServerSocketChannel来说, 只有绑定端口地址成功后 channel的状态才是active的。此时绑定操作在regFuture上注册的ChannelFutureListener#operationComplete回调方法中被作为异步任务提交到了Reactor的任务队列中,Reactor线程还没开始执行绑定任务。所以这里的isActive()是false。
当Reactor线程执行完register0方法后,才会去执行绑定任务。
下面我们来看下register0方法中这些核心步骤的具体实现:
public abstract class AbstractNioChannel extends AbstractChannel {
//channel注册到Selector后获得的SelectKey
volatile SelectionKey selectionKey;
@Override
protected void doRegister() throws Exception {
boolean selected = false;
for (;;) {
try {
selectionKey = javaChannel().register(eventLoop().unwrappedSelector(), 0, this);
return;
} catch (CancelledKeyException e) {
...............省略....................
}
}
}
}调用底层JDK NIO Channel方法java.nio.channels.SelectableChannel#register(java.nio.channels.Selector, int, java.lang.Object),将NettyNioServerSocketChannel中包装的JDK NIO ServerSocketChannel注册到Reactor中的JDK NIO Selector上。
简单介绍下SelectableChannel#register方法参数的含义:
Selector:表示JDK NIO Channel将要向哪个Selector进行注册。
int ops:表示Channel上感兴趣的IO事件,当对应的IO事件就绪时,Selector会返回Channel对应的SelectionKey。
SelectionKey可以理解为Channel在Selector上的特殊表示形式,SelectionKey中封装了Channel感兴趣的IO事件集合~~~interestOps,以及IO就绪的事件集合~~readyOps, 同时也封装了对应的JDK NIO Channel以及注册的Selector。最后还有一个重要的属性attachment,可以允许我们在SelectionKey上附加一些自定义的对象。
Object attachment:向SelectionKey中添加用户自定义的附加对象。
这里NioServerSocketChannel向Reactor中的Selector注册的IO事件为0,这个操作的主要目的是先获取到Channel在Selector中对应的SelectionKey,完成注册。当绑定操作完成后,在去向SelectionKey添加感兴趣的IO事件~~~OP_ACCEPT事件。
同时通过SelectableChannel#register方法将Netty自定义的NioServerSocketChannel(这里的this指针)附着在SelectionKey的attechment属性上,完成Netty自定义Channel与JDK NIOChannel的关系绑定。这样在每次对Selector进行IO就绪事件轮询时,Netty 都可以从JDK NIO Selector返回的SelectionKey中获取到自定义的Channel对象(这里指的就是NioServerSocketChannel)。
当NioServerSocketChannel注册到Main Reactor上的Selector后,Netty通过调用pipeline.invokeHandlerAddedIfNeeded()开始回调NioServerSocketChannel中pipeline里的ChannelHandler的handlerAdded方法。
此时NioServerSocketChannel的pipeline结构如下:
此时pipeline中只有在初始化NioServerSocketChannel时添加的ChannelInitializer。
我们来看下ChannelInitializer中handlerAdded回调方法具体作了哪些事情~~
public abstract class ChannelInitializer<C extends Channel> extends ChannelInboundHandlerAdapter {
@Override
public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
if (ctx.channel().isRegistered()) {
if (initChannel(ctx)) {
//初始化工作完成后,需要将自身从pipeline中移除
removeState(ctx);
}
}
}
//ChannelInitializer实例是被所有的Channel共享的,用于初始化ChannelPipeline
//通过Set集合保存已经初始化的ChannelPipeline,避免重复初始化同一ChannelPipeline
private final Set<ChannelHandlerContext> initMap = Collections.newSetFromMap(
new ConcurrentHashMap<ChannelHandlerContext, Boolean>());
private boolean initChannel(ChannelHandlerContext ctx) throws Exception {
if (initMap.add(ctx)) { // Guard against re-entrance.
try {
initChannel((C) ctx.channel());
} catch (Throwable cause) {
exceptionCaught(ctx, cause);
} finally {
ChannelPipeline pipeline = ctx.pipeline();
if (pipeline.context(this) != null) {
//初始化完毕后,从pipeline中移除自身
pipeline.remove(this);
}
}
return true;
}
return false;
}
//匿名类实现,这里指定具体的初始化逻辑
protected abstract void initChannel(C ch) throws Exception;
private void removeState(final ChannelHandlerContext ctx) {
//从initMap防重Set集合中删除ChannelInitializer
if (ctx.isRemoved()) {
initMap.remove(ctx);
} else {
ctx.executor().execute(new Runnable() {
@Override
public void run() {
initMap.remove(ctx);
}
});
}
}
}ChannelInitializer中的初始化逻辑比较简单明了:
- 首先要判断必须是当前
Channel已经完成注册后,才可以进行pipeline的初始化。ctx.channel().isRegistered()
- 调用
ChannelInitializer的匿名类指定的initChannel执行自定义的初始化逻辑。
p.addLast(new ChannelInitializer<Channel>() {
@Override
public void initChannel(final Channel ch) {
final ChannelPipeline pipeline = ch.pipeline();
//ServerBootstrap中用户指定的channelHandler
ChannelHandler handler = config.handler();
if (handler != null) {
pipeline.addLast(handler);
}
ch.eventLoop().execute(new Runnable() {
@Override
public void run() {
pipeline.addLast(new ServerBootstrapAcceptor(
ch, currentChildGroup, currentChildHandler, currentChildOptions, currentChildAttrs));
}
});
}
});还记得在初始化NioServerSocketChannel时。io.netty.bootstrap.ServerBootstrap#init方法中向pipeline中添加的ChannelInitializer吗?
- 当执行完
initChannel 方法后,ChannelPipeline的初始化就结束了,此时ChannelInitializer就没必要再继续呆在pipeline中了,所需要将ChannelInitializer从pipeline中删除。pipeline.remove(this)
当初始化完pipeline时,此时pipeline的结构再次发生了变化:
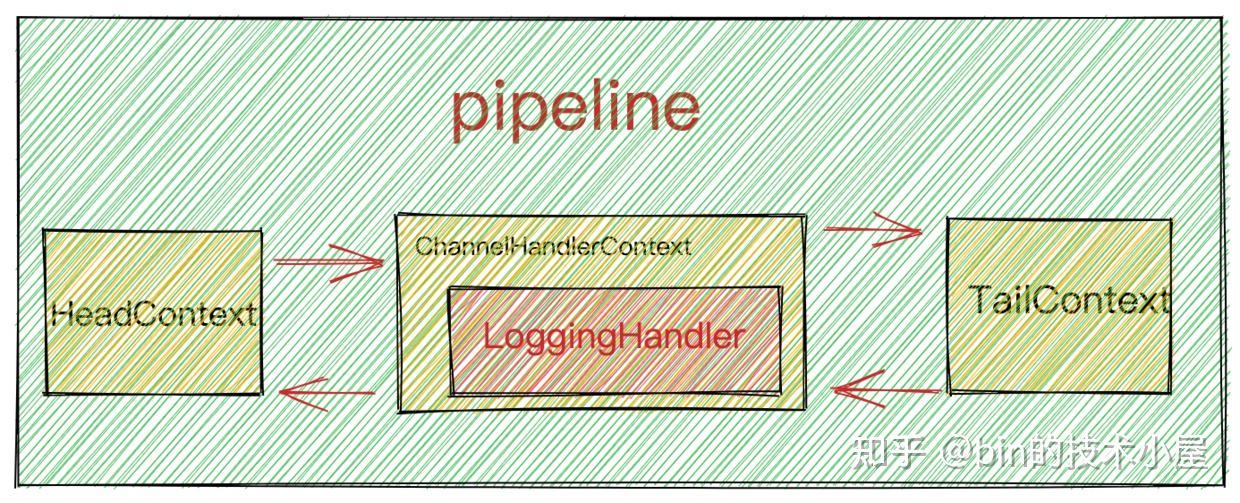
此时Main Reactor中的任务队列taskQueue结构变化为:
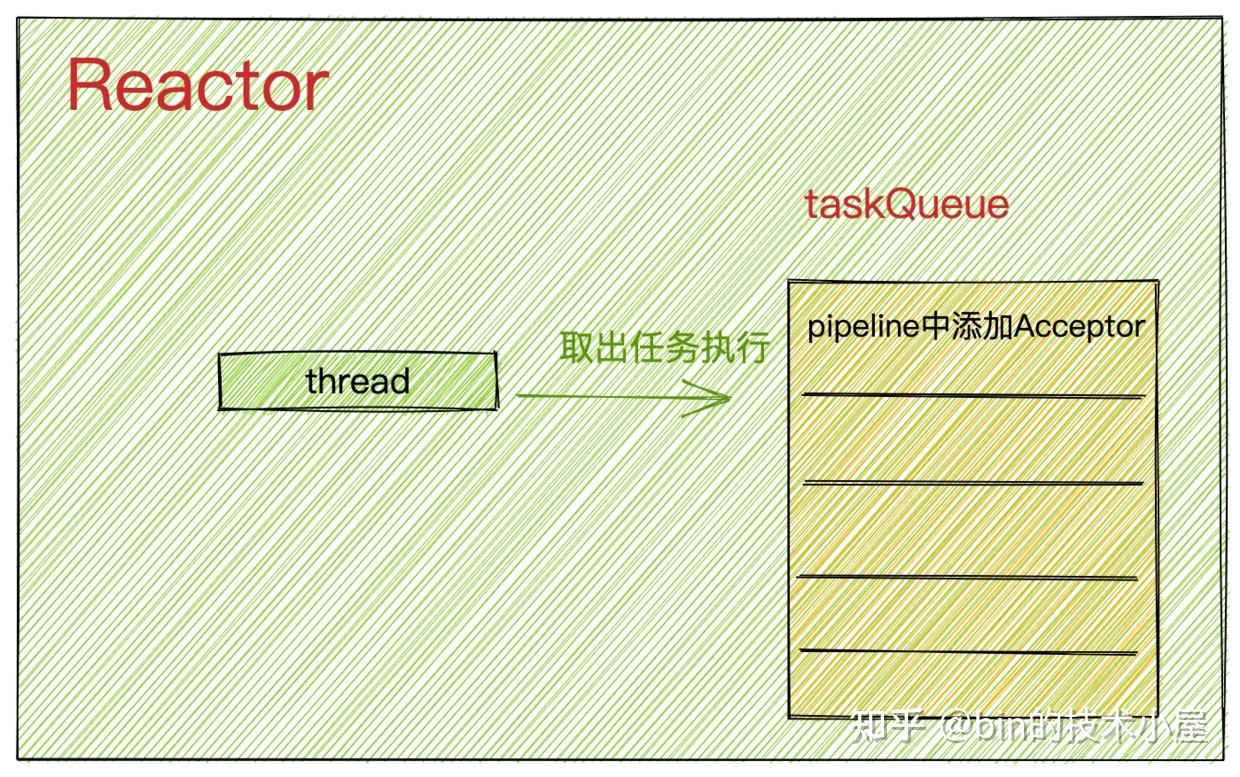
添加ServerBootstrapAcceptor的任务是在初始化NioServerSocketChannel的时候向main reactor提交过去的。还记得吗?
在本小节《Netty服务端的启动》的最开始,我们介绍了服务端启动的入口函数io.netty.bootstrap.AbstractBootstrap#doBind,在函数的最开头调用了initAndRegister()方法用来创建并初始化NioServerSocketChannel,之后便会将NioServerSocketChannel注册到Main Reactor中。
注册的操作是一个异步的过程,所以在initAndRegister()方法调用后返回一个代表注册结果的ChannelFuture regFuture。
public abstract class AbstractBootstrap<B extends AbstractBootstrap<B, C>, C extends Channel> implements Cloneable {
private ChannelFuture doBind(final SocketAddress localAddress) {
//异步创建,初始化,注册ServerSocketChannel
final ChannelFuture regFuture = initAndRegister();
final Channel channel = regFuture.channel();
if (regFuture.cause() != null) {
return regFuture;
}
if (regFuture.isDone()) {
//如果注册完成,则进行绑定操作
ChannelPromise promise = channel.newPromise();
doBind0(regFuture, channel, localAddress, promise);
return promise;
} else {
final PendingRegistrationPromise promise = new PendingRegistrationPromise(channel);
//添加注册完成 回调函数
regFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
...............省略...............
// 注册完成后,Reactor线程回调这里
doBind0(regFuture, channel, localAddress, promise);
}
}
});
return promise;
}
}
}之后会向ChannelFuture regFuture添加一个注册完成后的回调函数~~~~ ChannelFutureListener。在回调函数operationComplete中开始发起绑端口地址流程。
那么这个回调函数在什么时候?什么地方发起的呢??
让我们在回到本小节的主题register0方法的流程中:
当调用doRegister()方法完成NioServerSocketChannel向Main Reactor的注册后,紧接着会调用pipeline.invokeHandlerAddedIfNeeded()方法中触发ChannelInitializer#handlerAdded回调中对pipeline进行初始化。
最后在safeSetSuccess方法中,开始回调注册在regFuture上的ChannelFutureListener。
protected final void safeSetSuccess(ChannelPromise promise) {
if (!(promise instanceof VoidChannelPromise) && !promise.trySuccess()) {
logger.warn("Failed to mark a promise as success because it is done already: {}", promise);
}
}
@Override
public boolean trySuccess() {
return trySuccess(null);
}
@Override
public boolean trySuccess(V result) {
return setSuccess0(result);
}
private boolean setSuccess0(V result) {
return setValue0(result == null ? SUCCESS : result);
}
private boolean setValue0(Object objResult) {
if (RESULT_UPDATER.compareAndSet(this, null, objResult) ||
RESULT_UPDATER.compareAndSet(this, UNCANCELLABLE, objResult)) {
if (checkNotifyWaiters()) {
//回调注册在promise上的listeners
notifyListeners();
}
return true;
}
return false;
}safeSetSuccess的逻辑比较简单,首先设置regFuture结果为success,并且回调注册在regFuture上的ChannelFutureListener。
需要提醒的是,执行safeSetSuccess方法,以及后边回调regFuture上的ChannelFutureListener这些动作都是由Reactor线程执行的。
关于Netty中的Promise模型后边我会在写一篇专门的文章进行分析,这里大家只需清楚大体的流程即可。不必在意过多的细节。
下面我们把视角切换到regFuture上的ChannelFutureListener回调中,看看在Channel注册完成后,Netty又会做哪些事情?
public abstract class AbstractBootstrap<B extends AbstractBootstrap<B, C>, C extends Channel> implements Cloneable {
private static void doBind0(
final ChannelFuture regFuture, final Channel channel,
final SocketAddress localAddress, final ChannelPromise promise) {
channel.eventLoop().execute(new Runnable() {
@Override
public void run() {
if (regFuture.isSuccess()) {
channel.bind(localAddress, promise).addListener(ChannelFutureListener.CLOSE_ON_FAILURE);
} else {
promise.setFailure(regFuture.cause());
}
}
});
}
}这里Netty又将绑定端口地址的操作封装成异步任务,提交给Reactor执行。
但是这里有一个问题,其实此时执行doBind0方法的线程正是Reactor线程,那为什么不直接在这里去执行bind操作,而是再次封装成异步任务提交给Reactor中的taskQueue呢?
反正最终都是由Reactor线程执行,这其中又有什么分别呢?
经过上小节的介绍我们知道,bind0方法的调用是由io.netty.channel.AbstractChannel.AbstractUnsafe#register0方法在将NioServerSocketChannel注册到Main Reactor之后,并且NioServerSocketChannel的pipeline已经初始化完毕后,通过safeSetSuccess方法回调过来的。
这个过程全程是由Reactor线程来负责执行的,但是此时register0方法并没有执行完毕,还需要执行后面的逻辑。
而绑定逻辑需要在注册逻辑执行完之后执行,所以在doBind0方法中Reactor线程会将绑定操作封装成异步任务先提交给taskQueue中保存,这样可以使Reactor线程立马从safeSetSuccess中返回,继续执行剩下的register0方法逻辑。
private void register0(ChannelPromise promise) {
try {
................省略............
doRegister();
pipeline.invokeHandlerAddedIfNeeded();
safeSetSuccess(promise);
//触发channelRegister事件
pipeline.fireChannelRegistered();
if (isActive()) {
................省略............
}
} catch (Throwable t) {
................省略............
}
}当Reactor线程执行完register0方法后,就会从taskQueue中取出异步任务执行。
此时Reactor线程中的taskQueue结构如下:
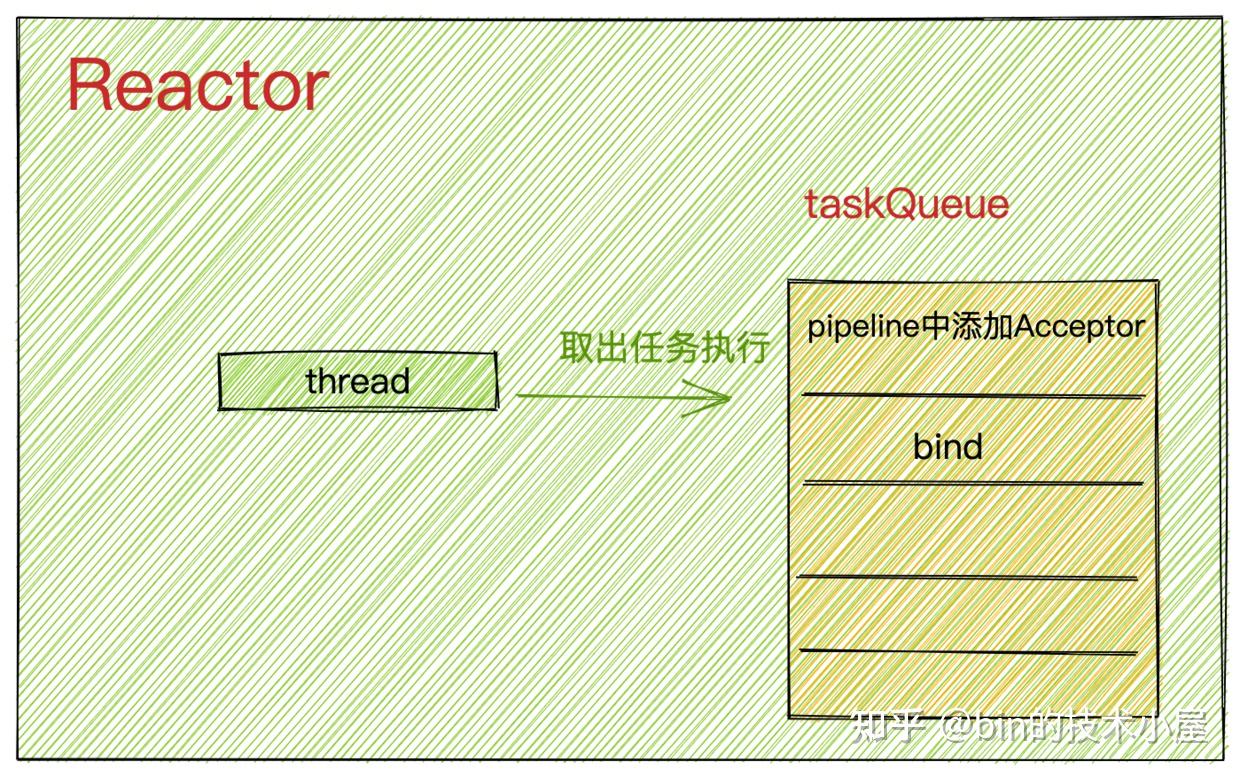
Reactor线程会先取出位于taskQueue队首的任务执行,这里是指向NioServerSocketChannel的pipeline中添加ServerBootstrapAcceptor的异步任务。
此时NioServerSocketChannel中pipeline的结构如下:
Reactor线程执行绑定任务。
对Channel的操作行为全部定义在ChannelOutboundInvoker接口中。
public interface ChannelOutboundInvoker {
/**
* Request to bind to the given {@link SocketAddress} and notify the {@link ChannelFuture} once the operation
* completes, either because the operation was successful or because of an error.
*
*/
ChannelFuture bind(SocketAddress localAddress, ChannelPromise promise);
}bind方法由子类AbstractChannel实现。
public abstract class AbstractChannel extends DefaultAttributeMap implements Channel {
@Override
public ChannelFuture bind(SocketAddress localAddress, ChannelPromise promise) {
return pipeline.bind(localAddress, promise);
}
}调用pipeline.bind(localAddress, promise)在pipeline中传播bind事件,触发回调pipeline中所有ChannelHandler的bind方法。
事件在pipeline中的传播具有方向性:
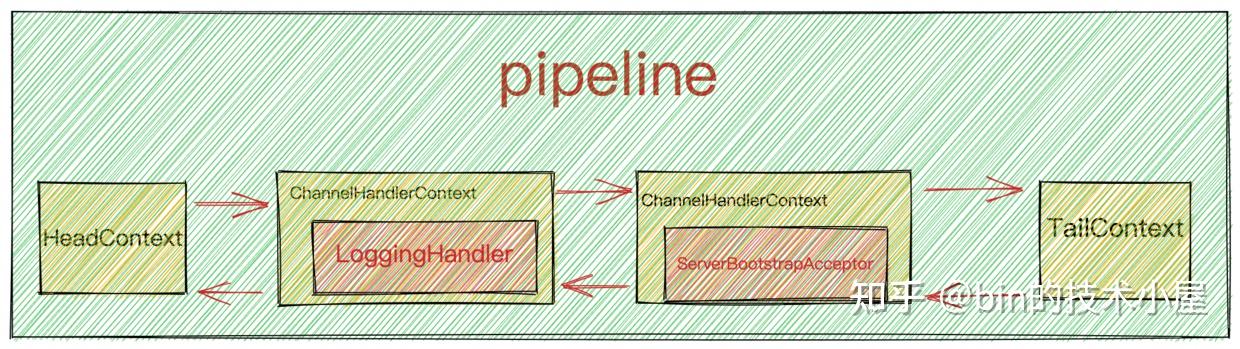
inbound事件从HeadContext开始逐个向后传播直到TailContext。outbound事件则是反向传播,从TailContext开始反向向前传播直到HeadContext。
inbound事件只能被pipeline中的ChannelInboundHandler响应处理outbound事件只能被pipeline中的ChannelOutboundHandler响应处理
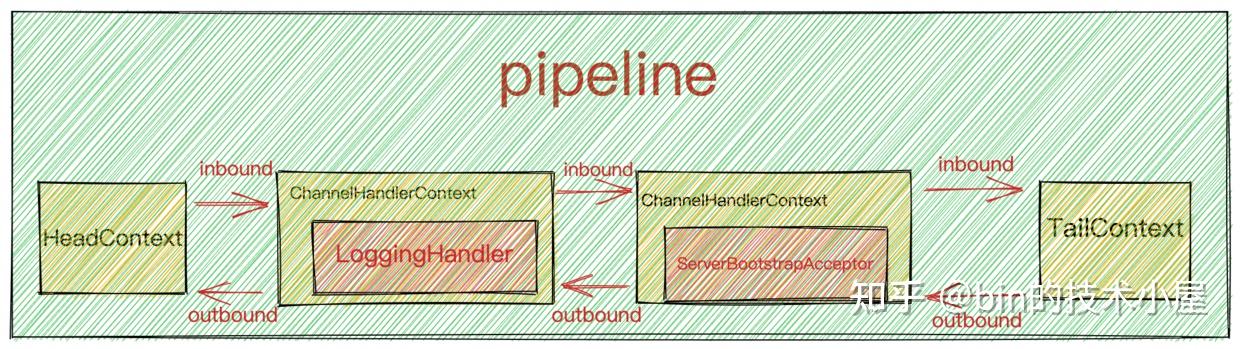
然而这里的bind事件在Netty中被定义为outbound事件,所以它在pipeline中是反向传播。先从TailContext开始反向传播直到HeadContext。
然而bind的核心逻辑也正是实现在HeadContext中。
final class HeadContext extends AbstractChannelHandlerContext
implements ChannelOutboundHandler, ChannelInboundHandler {
@Override
public void bind(
ChannelHandlerContext ctx, SocketAddress localAddress, ChannelPromise promise) {
//触发AbstractChannel->bind方法 执行JDK NIO SelectableChannel 执行底层绑定操作
unsafe.bind(localAddress, promise);
}
}在HeadContext#bind回调方法中,调用Channel里的unsafe操作类执行真正的绑定操作。
protected abstract class AbstractUnsafe implements Unsafe {
@Override
public final void bind(final SocketAddress localAddress, final ChannelPromise promise) {
.................省略................
//这时channel还未激活 wasActive = false
boolean wasActive = isActive();
try {
//io.netty.channel.socket.nio.NioServerSocketChannel.doBind
//调用具体channel实现类
doBind(localAddress);
} catch (Throwable t) {
.................省略................
return;
}
//绑定成功后 channel激活 触发channelActive事件传播
if (!wasActive && isActive()) {
invokeLater(new Runnable() {
@Override
public void run() {
//pipeline中触发channelActive事件
pipeline.fireChannelActive();
}
});
}
//回调注册在promise上的ChannelFutureListener
safeSetSuccess(promise);
}
protected abstract void doBind(SocketAddress localAddress) throws Exception;
}- 首先执行子类
NioServerSocketChannel具体实现的doBind方法,通过JDK NIO 原生 ServerSocketChannel执行底层的绑定操作。
@Override
protected void doBind(SocketAddress localAddress) throws Exception {
//调用JDK NIO 底层SelectableChannel 执行绑定操作
if (PlatformDependent.javaVersion() >= 7) {
javaChannel().bind(localAddress, config.getBacklog());
} else {
javaChannel().socket().bind(localAddress, config.getBacklog());
}
}- 判断是否为首次绑定,如果是的话将
触发pipeline中的ChannelActive事件封装成异步任务放入Reactor中的taskQueue中。
- 执行
safeSetSuccess(promise),回调注册在promise上的ChannelFutureListener。
还是同样的问题,当前执行线程已经是Reactor线程了,那么为何不直接触发pipeline中的ChannelActive事件而是又封装成异步任务呢??
因为如果直接在这里触发ChannelActive事件,那么Reactor线程就会去执行pipeline中的ChannelHandler的channelActive事件回调。
这样的话就影响了safeSetSuccess(promise)的执行,延迟了注册在promise上的ChannelFutureListener的回调。
到现在为止,Netty服务端就已经完成了绑定端口地址的操作,NioServerSocketChannel的状态现在变为Active。
最后还有一件重要的事情要做,我们接着来看pipeline中对channelActive事件处理。
channelActive事件在Netty中定义为inbound事件,所以它在pipeline中的传播为正向传播,从HeadContext一直到TailContext为止。
在channelActive事件回调中需要触发向Selector指定需要监听的IO事件~~OP_ACCEPT事件。
这块的逻辑主要在HeadContext中实现。
final class HeadContext extends AbstractChannelHandlerContext
implements ChannelOutboundHandler, ChannelInboundHandler {
@Override
public void channelActive(ChannelHandlerContext ctx) {
//pipeline中继续向后传播channelActive事件
ctx.fireChannelActive();
//如果是autoRead 则自动触发read事件传播
//在read回调函数中 触发OP_ACCEPT注册
readIfIsAutoRead();
}
private void readIfIsAutoRead() {
if (channel.config().isAutoRead()) {
//如果是autoRead 则触发read事件传播
channel.read();
}
}
//AbstractChannel
public Channel read() {
//触发read事件
pipeline.read();
return this;
}
@Override
public void read(ChannelHandlerContext ctx) {
//触发注册OP_ACCEPT或者OP_READ事件
unsafe.beginRead();
}
}- 在
HeadContext中的channelActive回调中触发pipeline中的read事件。 - 当
read事件再次传播到HeadContext时,触发HeadContext#read方法的回调。在read回调中调用channel底层操作类unsafe的beginRead方法向selector注册监听OP_ACCEPT事件。
protected abstract class AbstractUnsafe implements Unsafe {
@Override
public final void beginRead() {
assertEventLoop();
//channel必须是Active
if (!isActive()) {
return;
}
try {
// 触发在selector上注册channel感兴趣的监听事件
doBeginRead();
} catch (final Exception e) {
.............省略..............
}
}
}
public abstract class AbstractChannel extends DefaultAttributeMap implements Channel {
//子类负责继承实现
protected abstract void doBeginRead() throws Exception;
}- 断言判断执行该方法的线程必须是
Reactor线程。
- 此时
NioServerSocketChannel已经完成端口地址的绑定操作,isActive() = true
- 调用
doBeginRead实现向Selector注册监听事件OP_ACCEPT
public abstract class AbstractNioChannel extends AbstractChannel {
//channel注册到Selector后获得的SelectKey
volatile SelectionKey selectionKey;
// Channel监听事件集合
protected final int readInterestOp;
@Override
protected void doBeginRead() throws Exception {
final SelectionKey selectionKey = this.selectionKey;
if (!selectionKey.isValid()) {
return;
}
readPending = true;
final int interestOps = selectionKey.interestOps();
/**
* 1:ServerSocketChannel 初始化时 readInterestOp设置的是OP_ACCEPT事件
* */
if ((interestOps & readInterestOp) == 0) {
//添加OP_ACCEPT事件到interestOps集合中
selectionKey.interestOps(interestOps | readInterestOp);
}
}
}- 前边提到在
NioServerSocketChannel在向Main Reactor中的Selector注册后,会获得一个SelectionKey。这里首先要获取这个SelectionKey。
- 从
SelectionKey中获取NioServerSocketChannel感兴趣的IO事件集合 interestOps,当时在注册的时候interestOps设置为0。
- 将在
NioServerSocketChannel初始化时设置的readInterestOp = OP_ACCEPT,设置到SelectionKey中的interestOps集合中。这样Reactor中的Selector就开始监听interestOps集合中包含的IO事件了。
Main Reactor中主要监听的是OP_ACCEPT事件。
流程走到这里,Netty服务端就真正的启动起来了,下一步就开始等待接收客户端连接了。大家此刻在来回看这副启动流程图,是不是清晰了很多呢?
此时Netty的Reactor模型结构如下:
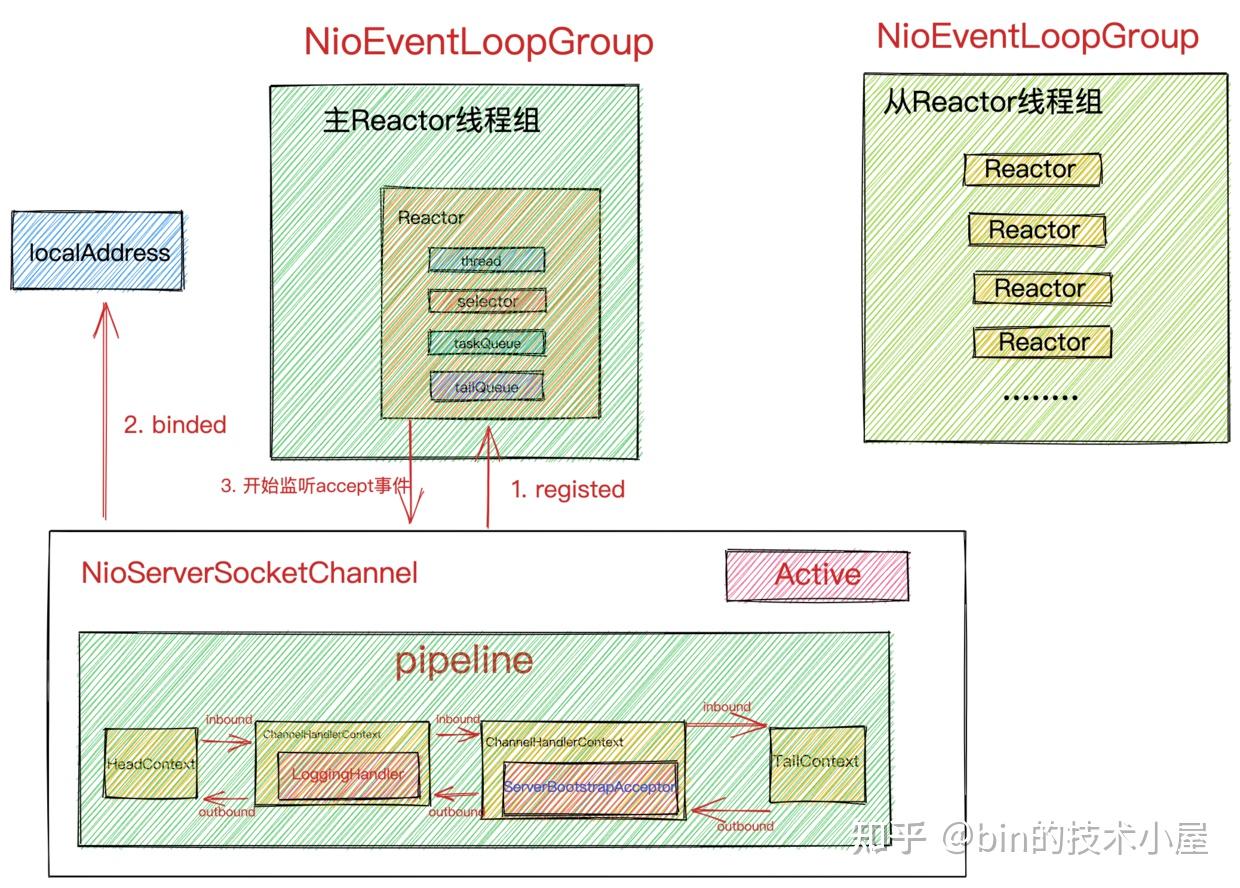
本文我们通过图解源码的方式完整地介绍了整个Netty服务端启动流程,并介绍了在启动过程中涉及到的ServerBootstrap相关的属性以及配置方式。NioServerSocketChannel的创建初始化过程以及类的继承结构。
其中重点介绍了NioServerSocketChannel向Reactor的注册过程以及Reactor线程的启动时机和pipeline的初始化时机。
最后介绍了NioServerSocketChannel绑定端口地址的整个流程。
上述介绍的这些流程全部是异步操作,各种回调绕来绕去的,需要反复回想下,读异步代码就是这样,需要理清各种回调之间的关系,并且时刻提醒自己当前的执行线程是什么?
好了,现在Netty服务端已经启动起来,接着就该接收客户端连接了,我们下篇文章见~~~~
旗帜鲜明说观点,本机之间的Socket通信,有可能走网卡,剩下的全部不走网卡。
这是一道路由(IP Routing)题,所以这道题只和IP Routing有关,即TCP/IP协议栈的IP路由有关。
不走网卡的场景
场景1:服务器IP = 127.0.0.1
服务器IP =127.0.0.1,即IP包的目IP=127.0.0.1,那IP包的源IP地址是什么?
IP模块基于目的IP =127.0.0.1,查询路由表发现最佳路由的出口为虚拟接口(127.0.0.1),于是就用它(127.0.0.1)作为源IP,它距离目的地最近。这是操作系统默认行为,如果用户没有明确指定源IP地址,操作系统选择路由出接口(Exiting Interface)的IP地址。
既然IP包已经完成了封装,IP Routing按照路由查询结果进行发送,并进入Sending Queue,IP Routing有一个判断逻辑,如果IP包的目的IP == 本地接口IP,需要将Sending Queue的该IP包移入Receiving Queue,相当于发送线与接收线短接(loopback)。
然后该IP包按照IP路由提交给虚拟接口(127.0.0.1),IP包没有经过网卡。
场景2:服务器IP = 10.1.1.1,IP绑定一个硬件网卡
同上,由于用户没有指定源IP,系统默认使用10.1.1.1作为源IP。该IP包被IP Routing做了收发短接,IP包在IP Routing模块里即发生了收发,IP包不经过网卡。
场景3:服务器IP = 10.1.1.1(一块网卡),客户端10.1.1.2 (同机另一块网卡),开启多接口路由功能
服务器IP =10.1.1.1,即IP包的目IP=10.1.1.1,源IP = 10.1.1.2 (由用户明确指定)。操作系统开启了多个网络接口IP Routing功能,如下图所示:
此时主机是一台路由器,该IP包被IP Routing做了收发短接,IP包在IP Routing模块里即发生了收发,IP包不经过网卡。
走网卡的场景
场景4:服务器IP = 10.1.1.1(一块网卡),客户端10.1.1.2 (同机另一块网卡),关闭多接口路由功能。
这个场景非常容易让人迷惑,之所以容易迷惑,是因为尽管服务器有两块网卡,但是这两块网卡老死不相往来。如果没有其它网络设备的帮助,是无法通信的,因为两块网卡之间的路由功能已经关闭,如下图所示:
目的IP =10.1.1.1,按照正常查询路由表的决策,最优路由(10.1.1.1/32,匹配长度为32bit)的出接口为10.1.1.1接口,那么应该使用10.1.1.1接口的IP= 10.1.1.1作为源IP地址,但是这和客户端指定的IP = 10.1.1.2并不相同,很显然无法满足客户端的需求。
于是,在次优路由里看看是否有满足用户需求的路由条目,值得欣慰的是,确实有这么一条次优路由(10.1.1.0/24,匹配长度为24bit),这条路由对应的出接口为10.1.1.2,系统会使用该接口的IP =10.1.1.2 作为源IP地址,恰好满足客户的需求。
然后这个IP包完成封装,进入Sending Queue,接下来会发生什么?
有同学说,由于IP包的目的IP地址 = 10.1.1.1, 恰好满足上文的判断逻辑,收发短接,同样不会经过网卡,对吗?
不对!
上文说了,这两块网卡是两个平行世界的接口,所以上文的判断逻辑不再适用。在出接口10.1.1.2的平行世界里,本地只有自己一个接口,接口10.1.1.1并不存在。
所以,接下来的一切主机之间的通信,就仿佛是两个主机之间的通信。需要发ARP广播请求对方的MAC地址,ARP通过网卡到达交换机,然后交换机广播ARP,ARP请求到达10.1.1.1。
服务器10.1.1.1发送ARP回复,经过网卡到达交换机,然后再到达主机10.1.1.2。最后两个主机就可以通信了,整个通信过程都会经过网卡。
上文的Routing的开关,在Windows操作系统使用“Services.msc” 设置”Routing and Remote Access”完成,Linux系统应该也有对应的开关配置。
摘要:Cookie、Session、Token 这三者是不同发展阶段的产物,并且各有优缺点,三者也没有明显的对立关系,反而常常结伴出现,这也是容易被混淆的原因。
作为网友的我们,每天都会使用浏览器来逛各种网站,来满足日常的工作生活需求。
现在的交互体验还是很丝滑的,但早期并非如此,而是一锤子买卖。
无状态的 HTTP 协议是什么鬼?
HTTP 无状态协议,是指协议对于业务处理没有记忆能力,之前做了啥完全记不住。每次请求都是完全独立互不影响的,没有任何上下文信息。
缺少状态意味着如果后续处理需要前面的信息,则它必须重传关键信息,这样可能导致每次连接传送的数据量增大。
假如一直用这种原生无状态的 HTTP 协议,我们每换一个页面可能就得重新登录一次,那还玩个球。
所以必须要解决 HTTP 协议的无状态,提升网站的交互体验,否则星辰大海是去不了的。
整个事情交互的双方只有客户端和服务端,所以必然要在这两个当事者身上下手。
客户端来买单
客户端每次请求时把自己必要的信息封装发送给服务端,服务端查收处理一下就行。
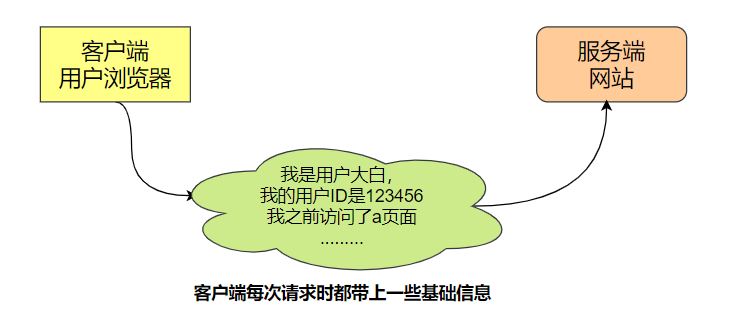
服务端来买单
客户端第一次请求之后,服务端就开始做记录,然后客户端在后续请求中只需要将最基本最少的信息发过来就行,不需要太多信息了。
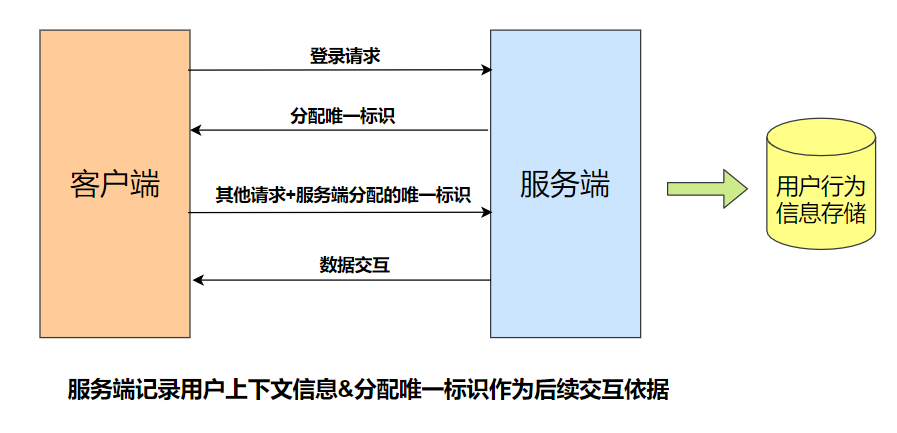
Cookie 总是保存在客户端中。按在客户端中的存储位置,可分为内存 Cookie 和硬盘Cookie。
内存 Cookie 由浏览器维护,保存在内存中,浏览器关闭后就消失了,其存在时间是短暂的。硬盘 Cookie 保存在硬盘里,有一个过期时间。除非用户手工清理或到了过期时间,硬盘Cookie不会被删除,其存在时间是长期的。

HTTP Cookie(也叫 Web Cookie 或浏览器 Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据。它会在浏览器下次向同一服务器再发起请求时,被携带并发送到服务器上。
通常 Cookie 用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。Cookie 使基于无状态的HTTP协议记录稳定的状态信息成为了可能。
Cookie 主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车等其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
当服务器收到 HTTP 请求时,服务器可以在响应头里面添加一个 Set-Cookie 选项。
浏览器收到响应后通常会保存下 Cookie,之后对该服务器每一次请求中都通过 Cookie 请求头部将 Cookie 信息发送给服务器。另外,Cookie 的过期时间、域、路径、有效期、适用站点都可以根据需要来指定。
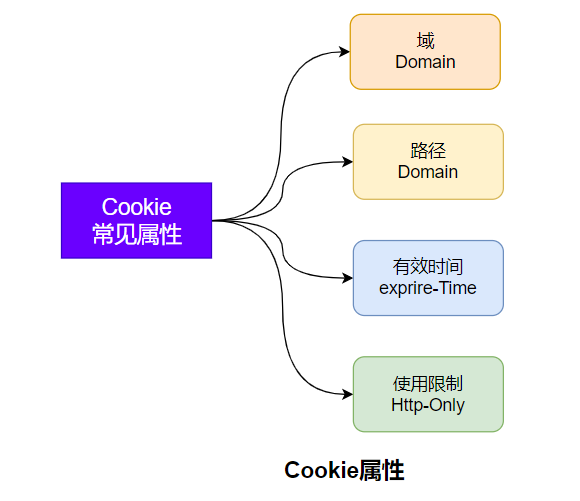
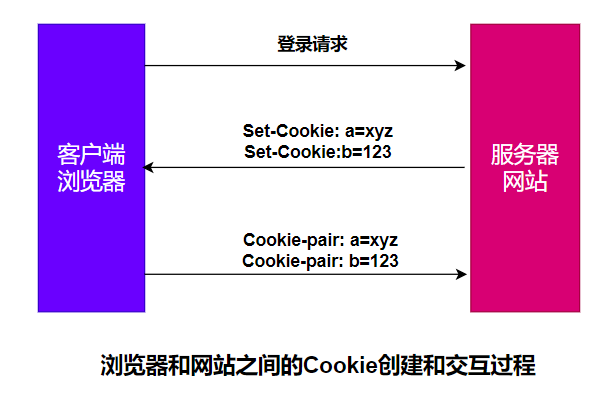
服务器使用 Set-Cookie 响应头部向用户浏览器发送 Cookie信息。
一个简单的 Cookie 可能像这样:
Set-Cookie: <cookie名>=<cookie值>
HTTP/1.0 200 OKContent-type: text/htmlSet-Cookie: yummy_cookie=chocoSet-Cookie: tasty_cookie=strawberry客户端对该服务器发起的每一次新请求,浏览器都会将之前保存的Cookie信息通过 Cookie 请求头部再发送给服务器。
GET /sample_page.html HTTP/1.1Host: www.example.orgCookie: yummy_cookie=choco; tasty_cookie=strawberry我来访问下淘宝网,抓个包看看这个真实的过程:
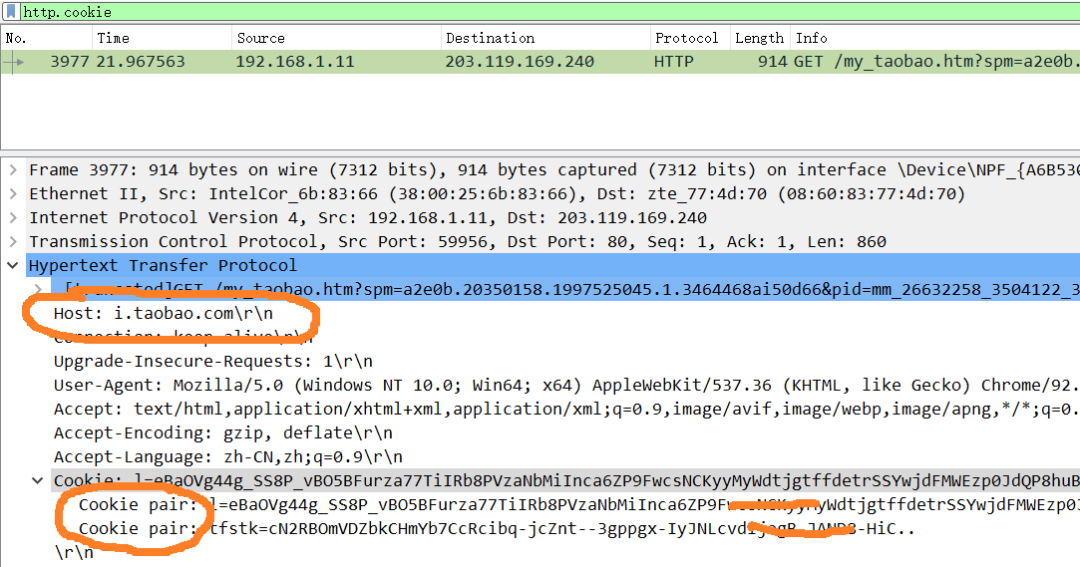
Cookie 常用来标记用户或授权会话,被浏览器发出之后可能被劫持,被用于非法行为,可能导致授权用户的会话受到攻击,因此存在安全问题。
还有一种情况就是跨站请求伪造 CSRF,简单来说 比如你在登录银行网站的同时,登录了一个钓鱼网站,在钓鱼网站进行某些操作时可能会获取银行网站相关的Cookie信息,向银行网站发起转账等非法行为。
跨站请求伪造(英语:Cross-site request forgery),也被称为 one-click attack 或者 session riding,通常缩写为 CSRF 或者 XSRF, 是一种挟制用户在当前已登录的 Web 应用程序上执行非本意的操作的攻击方法。跟跨网站脚本(XSS)相比,XSS 利用的是用户对指定网站的信任,CSRF 利用的是网站对用户网页浏览器的信任。
跨站请求攻击,简单地说,是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并运行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。
由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去运行。这利用了 Web 中用户身份验证的一个漏洞:简单的身份验证只能保证请求发自某个用户的浏览器,却不能保证请求本身是用户自愿发出的。
不过这种情况有很多解决方法,特别对于银行这类金融性质的站点,用户的任何敏感操作都需要确认,并且敏感信息的 Cookie 只能拥有较短的生命周期。
同时 Cookie 有容量和数量的限制,每次都要发送很多信息带来额外的流量消耗、复杂的行为 Cookie 无法满足要求。
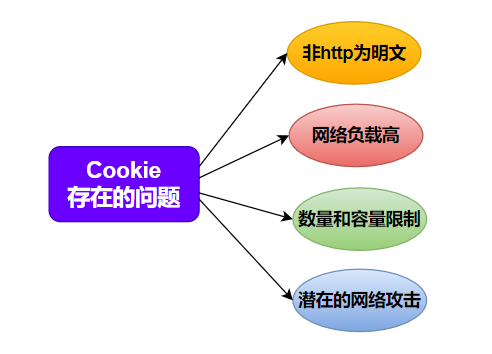
特别注意:以上存在的问题只是 Cookie 被用于实现交互状态时存在的问题,但并不是说 Cookie 本身的问题。
试想一下:菜刀可以用来做菜,也可以被用来从事某些暴力行为,你能说菜刀应该被废除吗?
如果说 Cookie 是客户端行为,那么 Session 就是服务端行为。
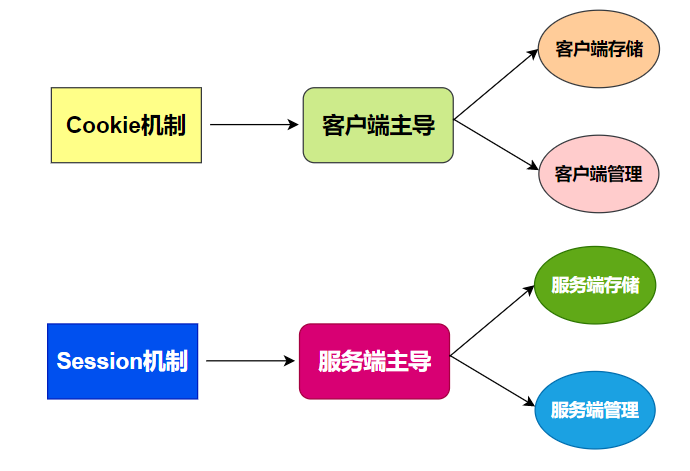
Cookie 机制在最初和服务端完成交互后,保持状态所需的信息都将存储在客户端,后续直接读取发送给服务端进行交互。
Session 代表服务器与浏览器的一次会话过程,并且完全由服务端掌控,实现分配ID、会话信息存储、会话检索等功能。
Session 机制将用户的所有活动信息、上下文信息、登录信息等都存储在服务端,只是生成一个唯一标识 ID 发送给客户端,后续的交互将没有重复的用户信息传输,取而代之的是唯一标识 ID,暂且称之为 Session-ID 吧。
- 当客户端第一次请求 session 对象时候,服务器会为客户端创建一个 session,并将通过特殊算法算出一个 session 的 ID,用来标识该 session 对象;
- 当浏览器下次请求别的资源的时候,浏览器会将 sessionID 放置到请求头中,服务器接收到请求后解析得到 sessionID,服务器找到该 id 的 session 来确定请求方的身份和一些上下文信息。
首先明确一点,Session 和 Cookie 没有直接的关系。可以认为 Cookie 只是实现 Session 机制的一种方法途径而已,没有 Cookie 还可以用别的方法。
Session和Cookie的关系就像加班和加班费的关系,看似关系很密切,实际上没啥关系。
Session 的实现主要两种方式:Cookie 与 URL 重写,而 Cookie 是首选方式。因为各种现代浏览器都默认开通 Cookie 功能,但是每种浏览器也都有允许 Cookie 失效的设置,因此对于 Session 机制来说还需要一个备胎。
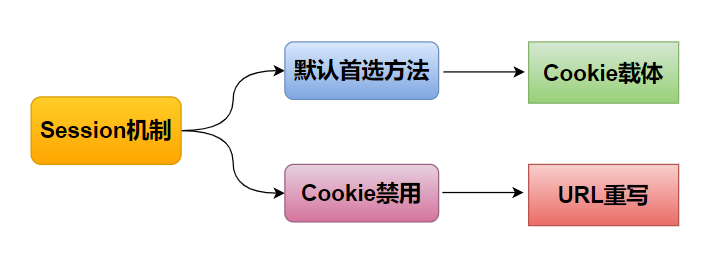
将会话标识号以参数形式附加在超链接的URL地址后面的技术称为 URL 重写
原始 URL:
http://taobao.com/getitem?name=baymax&action=buy重写后的 URL:
http://taobao.com/getitem?sessionid=1wui87htentg&?name=baymax&action=buy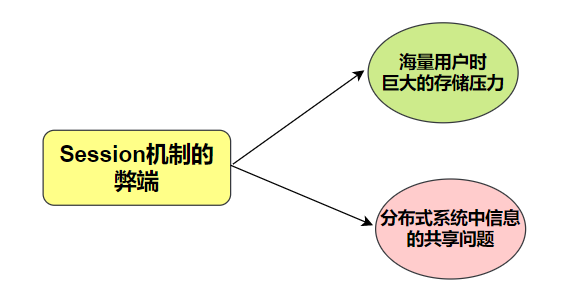
由于 Session 信息是存储在服务端的,因此如果用户量很大的场景,Session 信息占用的空间就不容忽视。
对于大型网站必然是集群化&分布式的服务器配置。如果 Session 信息是存储在本地的,那么由于负载均衡的作用,原来请求机器 A 并且存储了 Session 信息,下一次请求可能到了机器 B,此时机器 B 上并没有 Session 信息。
这种情况下要么在 B 机器重复创建造成浪费,要么引入高可用的 Session 集群方案,引入 Session 代理实现信息共享,要么实现定制化哈希到集群 A,这样做其实就有些复杂了
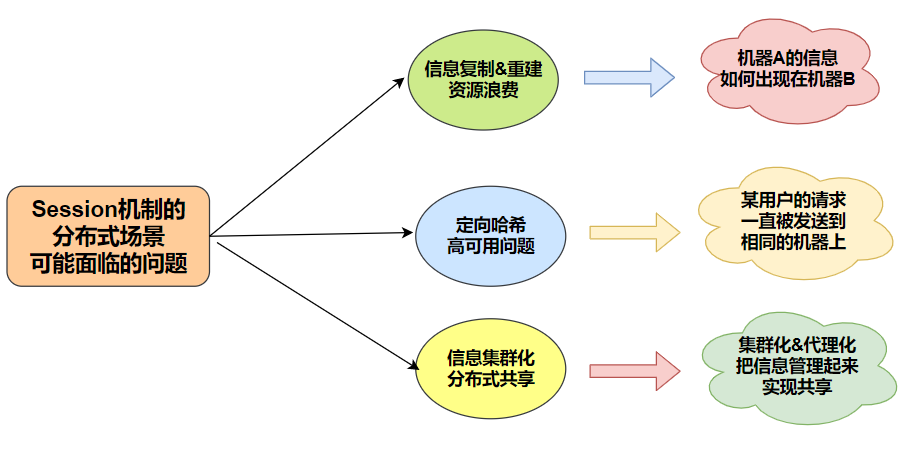
Token 是令牌的意思,由服务端生成并发放给客户端,是一种具有时效性的验证身份的手段。
Token 避免了 Session 机制带来的海量信息存储问题,也避免了 Cookie 机制的一些安全性问题,在现代移动互联网场景、跨域访问等场景有广泛的用途。

- 客户端将用户的账号和密码提交给服务器;
- 服务器对其进行校验,通过则生成一个 token 值返回给客户端,作为后续的请求交互身份令牌;
- 客户端拿到服务端返回的 token 值后,可将其保存在本地,以后每次请求服务器时都携带该 token,提交给服务器进行身份校验;
- 服务器接收到请求后,解析关键信息,再根据相同的加密算法、密钥、用户参数生成 sign 与客户端的 sign 进行对比,一致则通过,否则拒绝服务;
- 验证通过之后,服务端就可以根据该 Token 中的 uid 获取对应的用户信息,进行业务请求的响应。
以 JSON Web Token(JWT)为例,Token主要由三部分组成:
- Header 头部信息:记录了使用的加密算法信息;
- Payload 净荷信息:记录了用户信息和过期时间等;
- Signature 签名信息:根据 header 中的加密算法和 payload 中的用户信息以及密钥key来生成,是服务端验证服务端的重要依据。
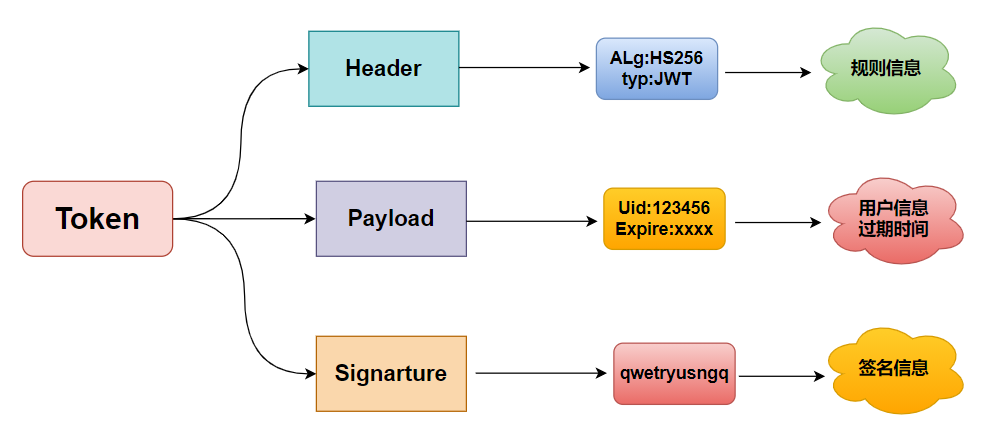
header 和 payload 的信息不做加密,只做一般的 base64 编码。服务端收到 token 后剥离出 header 和 payload 获取算法、用户、过期时间等信息,然后根据自己的加密密钥来生成 sign,并与客户端传来的 sign 进行一致性对比,来确定客户端的身份合法性。
这样就实现了用 CPU 加解密的时间换取存储空间,同时服务端密钥的重要性就显而易见,一旦泄露整个机制就崩塌了,这个时候就需要考虑 HTTPS 了。
- Token 可以跨站共享,实现单点登录;
- Token 机制无需太多存储空间。Token 包含了用户的信息,只需在客户端存储状态信息即可,对于服务端的扩展性很好;
- Token 机制的安全性依赖于服务端加密算法和密钥的安全性;
- Token 机制也不是万金油。
Cookie、Session、Token 这三者是不同发展阶段的产物,并且各有优缺点,三者也没有明显的对立关系,反而常常结伴出现,这也是容易被混淆的原因。
Cookie 侧重于信息的存储,主要是客户端行为。Session 和 Token 侧重于身份验证,主要是服务端行为。
三者方案在很多场景都还有生命力,了解场景才能选择合适的方案。
以上内容分享自华为云社区《Cookie、Session、Token 背后的故事》,作者: 龙哥手记。
点击关注,第一时间了解华为云新鲜技术~
问题很简单,这个回答也很短,耐心点看,你肯定会彻底搞懂。
让我们先摒弃我们原本熟知的各种IO模型流程图,先看一个非常简单的IO流程,不涉及任何阻塞非阻塞、同步异步概念的图。
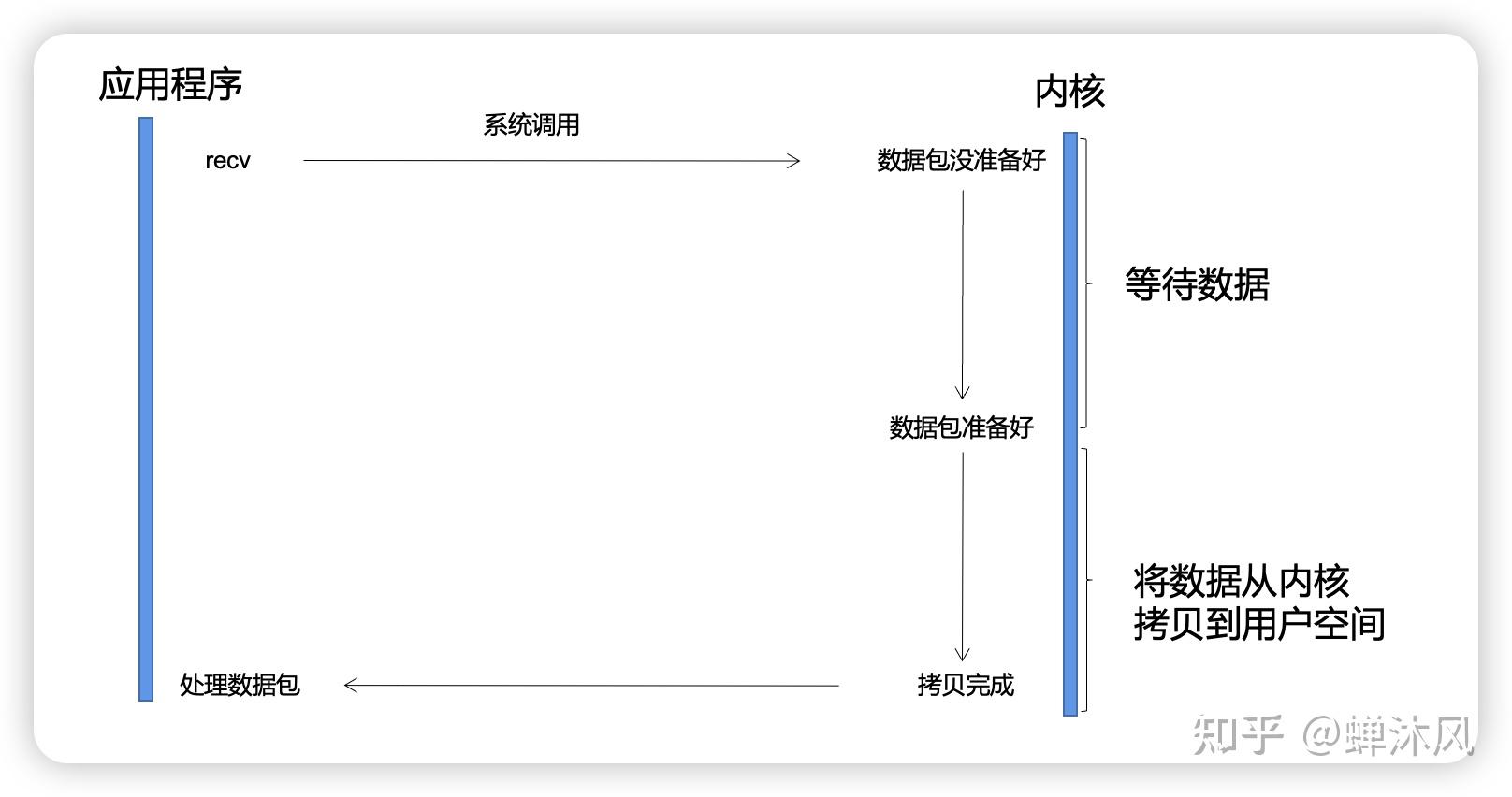
客户端发起系统调用之后,内核的操作可以被分成两步:
- 等待数据
此阶段网络数据进入网卡,然后网卡将数据放到指定的内存位置,此过程CPU无感知。然后经过网卡发起硬中断,再经过软中断,内核线程将数据发送到socket的内核缓冲区中。
- 数据拷贝
数据从socket的内核缓冲区拷贝到用户空间。
阻塞与非阻塞在API上区别在于socket是否设置了SOCK_NONBLOCK这个参数,默认情况下是阻塞的,设置了该参数则为非阻塞。

假设socket为阻塞模式,则IO调用如下图所示。
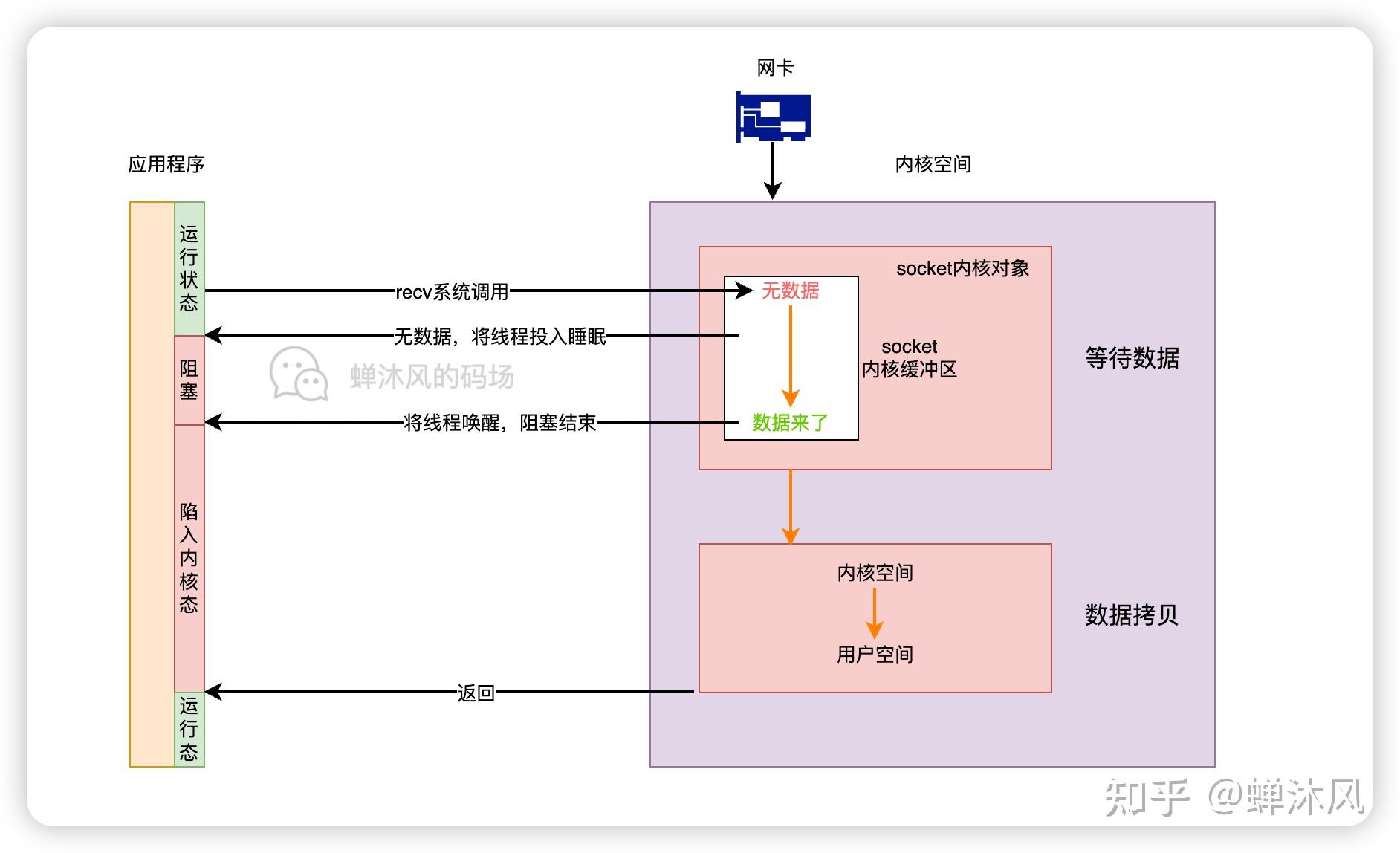
当处于运行状态的用户线程发起recv系统调用时,如果socket内核缓冲区内没有数据,则内核会将当前线程投入睡眠,让出CPU的占用。
直到网络数据到达网卡,网卡DMA数据到内存,再经过硬中断、软中断,由内核线程唤醒用户线程。
此时socket的数据已经准备就绪,用户线程由用户态进入到内核态,执行数据拷贝,将数据从内核空间拷贝到用户空间,系统调用结束。此阶段,开发者通常认为用户线程处于等待(称为阻塞也行)状态,因为在用户态的角度上,线程确实啥也没干(虽然在内核态干得累死累活)。
如果将socket设置为非阻塞模式,调用便换了一副光景。
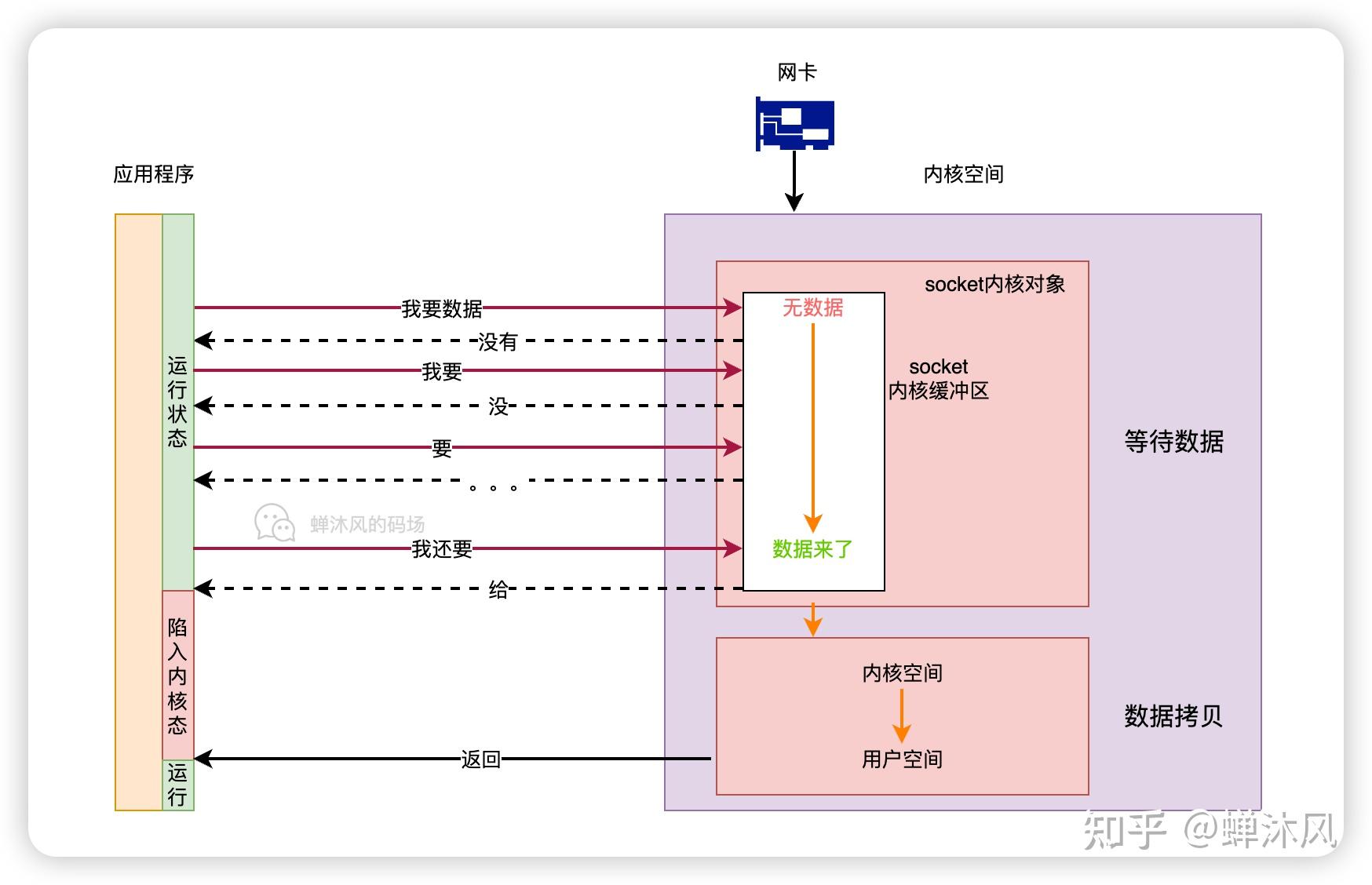
用户线程发起系统调用,如果socket内核缓冲区中没有数据,则系统调用立即返回,不会挂起线程。而线程会继续轮询,直到socket内核缓冲区内有数据为止。
如果socket内核缓冲区内有数据,则用户线程进入内核态,将数据从内核空间拷贝到用户空间,这一步和2.1小节没有区别。
同步和异步主要看请求发起方对消息结果的获取方式,是主动获取还是被动通知。区别主要体现在数据拷贝阶段。
同步我们其实已经见识过了,2.1节和2.2节中的数据拷贝阶段其实都是同步!
注:把同步的流程画在阻塞和非阻塞的第二阶段,并不是说阻塞和非阻塞的第二阶段只能搭配同步手段!
同步指的是数据到达socket内核缓冲区之后,由用户线程参与到数据拷贝过程中,直到数据从内核空间拷贝到用户空间。
因此,
IO多路复用,对于应用程序而言,仍然只能算是一种同步。
因为应用程序仍然花费时间等待IO结果,等待期间CPU要么用于遍历文件描述符的状态,要么用于休眠等待事件发生。
以select为例,用户线程发起select调用,会切换到内核空间,如果没有数据准备就绪,则用户线程阻塞到有数据来为止,select调用结束。结束之后用户线程获取到的只是「内核中有N个socket已经就绪」的这么一个信息,还需要用户线程对着1024长度的描述符数组进行遍历,才能获取到socket中的数据,这就是同步。
举个生活中的例子,我们给物流客服打电话询问我们的包裹是否已到达,如果未到达,我们就先睡一会儿,等到了之后客服给我们打电话把我们喊起来,然后我们屁颠屁颠地去快递驿站拿快递。这就是同步阻塞。
如果我们不想睡,就一直打电话问,直到包裹到了为止,然后再屁颠屁颠地去快递驿站拿快递。这就是同步非阻塞。
问题就是,能不能直接让物流的人把快递直接送到我家,别让我自己去拿啊!这就是异步。
我们理想中的完美异步应该是用户进程发起非阻塞调用,内核直接返回结果之后,用户线程可以立即处理下一个任务,只需要IO完成之后通过信号或回调函数的方式将数据传递给用户线程。如下图所示。
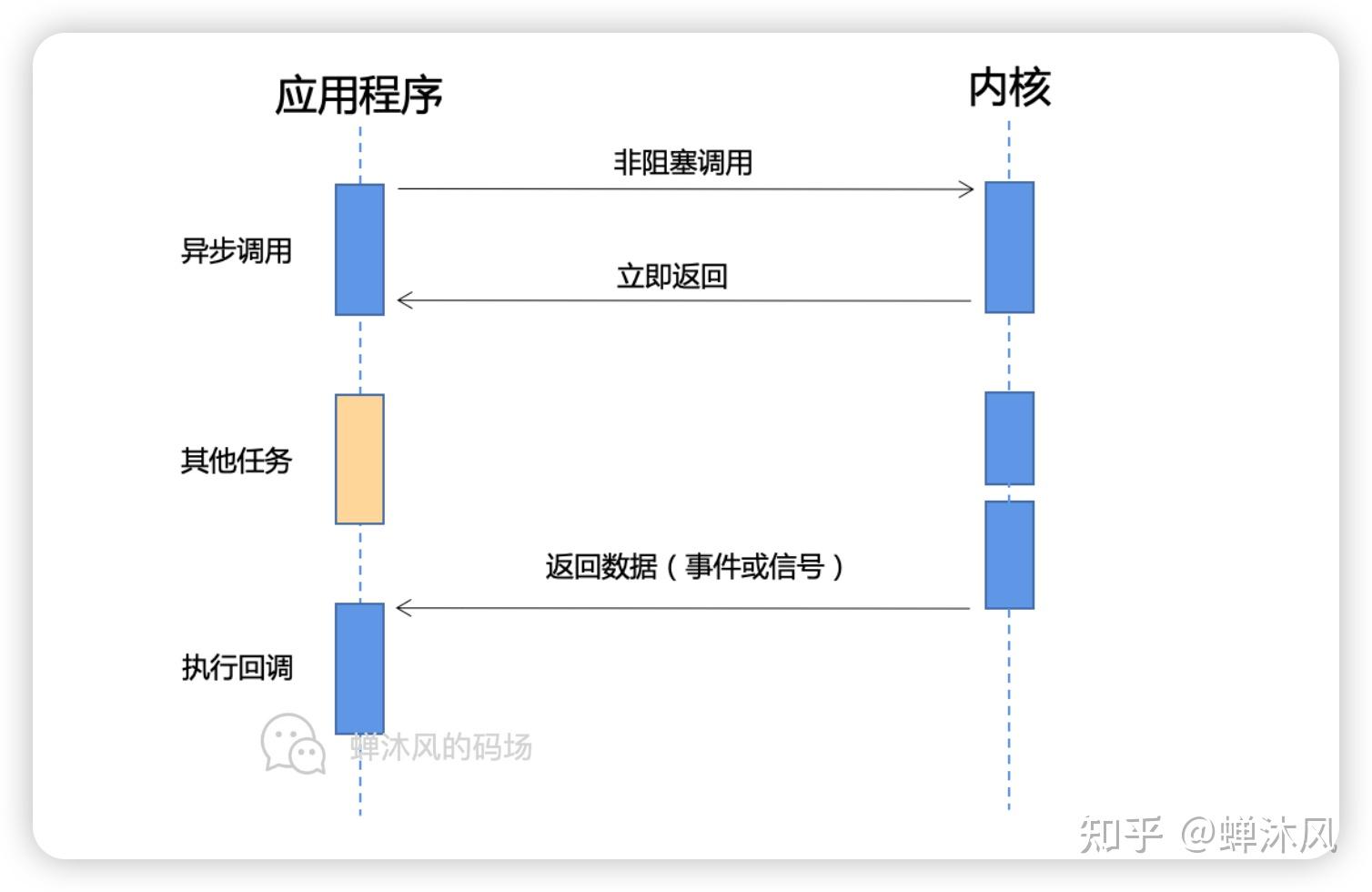
因此,在理想的异步环境下,数据准备阶段和数据拷贝阶段都是由内核完成的,不会对用户线程进行阻塞,这种内核级别的改进自然需要操作系统底层的功能支持。
现实比理想要骨感一些。
Linux内核并没有太惹眼的异步IO机制,这难不倒各路大神,比如Node的作者采用多线程模拟了这种异步效果。
比如让某个主线程执行主要的非IO逻辑操作,另外再起多个专门用于IO操作的线程,让IO线程进行阻塞IO或者非阻塞IO加轮询的方式来完成数据获取,通过IO线程和主线程之间通信进行数据传递,以此来实现异步。
还有一种方案是Windows上的IOCP,它在某种程度上提供了理想的异步,其内部依然采用的是多线程的原理,不过是内核级别的多线程。
遗憾的是,用Windows做服务器的项目并不是特别多,期待Linux在异步的领域上取得更大的进步吧。
说完了同步异步、阻塞非阻塞,一个很自然的操作就是对他们进行排列组合。
- 同步阻塞
- 同步非阻塞
- 异步非阻塞
- 异步阻塞
但是异步阻塞是什么鬼?按照上文的解释,该IO模型在第一阶段应该是用户线程阻塞,等待数据;第二阶段应该是内核线程(或专门的IO线程)处理IO操作,然后把数据通过事件或者回调的方式通知用户线程,既然如此,那么第一步的阻塞完全没有必要啊!非阻塞调用,然后继续处理其他任务岂不是更好。
因此,压根不存在异步阻塞这种模型哦~
最后给各位提个醒,和别人讨论阻塞非阻塞的时候千万要带上主语。
如果我问你,epoll是阻塞还是非阻塞?你怎么回答?
应该说,epoll_wait这个函数本身是阻塞的,但是epoll会将socket设置为非阻塞。因此单纯把epoll认为阻塞是太委屈它,认为其是非阻塞又抬举它。
具体关于epoll的说明可以参见
蝉沐风:彻底搞懂IO多路复用
中的epoll部分。
完~
io uring 作为 linux 异步 io 的首选,目前已经很成熟了,不过要注意,5.12 以前的内核使用 io uring 需要设置足够的 locked memory limit(RLIMIT_MEMLOCK)。
libaio 是古代 linux 的异步 io,仅支持 direct io。
最后是上古时代的 posix aio,是在 glibc 中实现的,从 1999 年 glibc-2.1 就开始支持,内部实现用的是线程池,所以性能肯定有很大牺牲。最坑爹的是,还有 bug,我们就碰到过:
原文链接:ToplingDB posix aio - 知乎 (zhihu.com)
MyTopling 是基于 ToplingDB 的 MySQL,分叉自 MyRocks,ToplingDB 则分叉自 RocksDB,兼容 RocksDB 接口,从而 MyTopling 可以复用 MyRocks 的大部分成果。ToplingDB 和 MyTopling 都已开源。
在 ToplingDB 中,我们通过 fiber + io uring 实现了高效 MultiGet IO 并发,为 MyTopling 的 MRR(Multi Range Read) 提供了强有力的支撑。
虽然 io uring 诞生至今(2023-02-27)已有数年,但是现实世界中仍有很多用户在使用缺乏 io uring 的旧内核。而 linux native aio 又仅支持 direct io,所以,posix aio 就成了一个最后的选择。
posix aio 最早定义在 posix 标准 POSIX.1-2001 中,其原型或变体的出现时间则更早,历史非常悠久。
glibc 对 posix aio 的支持从 2.1 版就开始了(1999年,早于POSIX.1-2001),是用线程池实现的,一直到现在(2023-02-27)的最新版,依然是线程池。
在 ToplingDB 的底层库 topling-zip 中,我在最开始就实现了对 posix aio 的支持,但是在实践中一直没有使用。
在最开始的时候,先调用 aio_read,然后切换到其它 fiber 发起更多 aio_read,等再次切换回当前 fiber 时,调用 aio_error 查看 aio 的执行状态,直到不再是EINPROGRESS。
这种使用方式,是 posix aio 的一个标准用法,我们的单元测试也一切 OK。整合到 MyTopling 中进行测试,除了性能比 io uring 差一点,一切正常。
为了适配旧系统,我们在 centos 7.3 上直接用 MyTopling 测试,不幸的是,很快就炸了,并且炸的时候 stack 全是乱的!
接下来,最合理的诊断就是跑单元测试看看炸在什么位置,结果更加让人崩溃:
- release 版的单元测试跑 10 次,平均下来会挂一两次,其余正常,挂掉的时候,stack 也是乱的
- debug 版的单元测试跑 100 次,会挂 99 次,stack 也是乱的
跟新系统相比,编译器是一样的(均使用自己编译的 gcc-12.1),操作系统内核虽然不同,但是 glibc 线程池最终调用的都是 pread,pread 总不会出问题吧。
所以,最可疑的就是 glibc,但是 glibc 从 2.1 版就开始支持 aio,这个时间(1999)甚至早于 posix aio 标准的发布时间(2001),到 centos 7.3 的 glibc-2.17,期间经历了十几年,如果真有 bug,也该早都修了。
接连好几天时间,这个问题一直是神龙见首不见尾,从来没有抓到过第一现场。就在我快要放弃,准备重新发明一遍轮子,自己用线程池实现一遍 posix aio 的功能时,又 review 了一遍 fiber_aio.cpp,看到 aio_read 相关代码时,觉得这个太丑,特别是,对 io uring 和 linux native aio 都使用 submit → wait → reap 模型实现了单独的派生类,只有 posix aio 使用的是就地 submit → poll。
为了对称,为了美感,把 posix aio 也实现为 submit → wait → reap 模型吧!代码写完之后,确实很符合审美。既然代码都写完了,跑一次看看吧……
bug 居然神奇地消失了!
从执行流程上看,相比之前只是多了 wait 步骤中的 aio_suspend 调用!
int aio_suspend(const struct aiocb * const aiocb_list[],
int nitems, const struct timespec *timeout);aio 的任何文档中都没有说调用 aio_error 之前必须调用 aio_suspend,甚至 aio 文档的示例代码中都没有 aio_suspend 调用。
从效率上来说,submit → wait → reap 必然是最高效的。以前只是偷了一点懒,觉得 aio_read 返回后先是 fiber yield 切换到其它 fiber (会执行其它 aio_read),等回来调用到 aio_error 检查结果时,已经发起放多个 aio_read 了,而不是一直在那里浪费 CPU 时间 busy poll aio_error。
至少在 centos 7.3 使用的 glib-2.17 中,没有在 aio_read 中将 aio_error 设置为 EINPROGRESS,而是在随后的某个地方才设置的,导致用户代码调用 aio_error 返回了 success 并继续执行,然后释放了相应的缓冲区,但实际上该 io 并没有执行,等到 glibc 执行该 io 时,传给 pread 一个已经释放了的 buffer,然后一切都乱了……
我们在追求美感的过程中,无意中调用了 aio_suspend,正是在 aio_suspend 中,glibc 设置了正确的 aio_error,于是就一切正常了……
大概 glib-2.17 之后的某个版本,修复了这个 bug,在 aio_read 中就设置了 EINPROGRESS ,所以不需要调用 aio_suspend
POSIX AIO是一个用户级实现,它在多个线程中执行正常的阻塞I/O,因此给出了I/O异步的错觉.这样做的主要原因是:
- 它适用于任何文件系统
- 它(基本上)在任何操作系统上工作(请记住,gnu的libc是可移植的)
- 它适用于启用了缓冲的文件(即没有设置O_DIRECT标志)
主要缺点是你的队列深度(即你在实践中可以拥有的未完成操作的数量)受到你选择的线程数量的限制,这也意味着一个磁盘上的慢速操作可能会阻止一个操作进入不同的磁盘.它还会影响内核和磁盘调度程序看到的I/O(或多少)。
内核AIO(即io_submit()et.al.)是异步I/O操作的内核支持,其中io请求实际上在内核中排队,按照您拥有的任何磁盘调度程序排序,可能是其中一些被转发(我们希望将实际的磁盘作为异步操作(使用TCQ或NCQ)。这种方法的主要限制是,并非所有文件系统都能很好地工作,或者根本不能使用异步I/O(并且可能会回到阻塞语义),因此必须使用O_DIRECT打开文件,而O_DIRECT还带有许多其他限制。。I/O请求。如果您无法使用O_DIRECT打开文件,它可能仍然"正常",就像您获得正确的数据一样,但它可能不是异步完成,而是回到阻止语义。
还要记住,在某些情况下,io_submit()实际上可以阻塞磁盘。
没有aio_*系统调用(http://linux.die.net/man/2/syscalls)。您在vfs中看到的aio_*函数可能是内核aio的一部分。用户级*aio_*函数不会将1:1映射到系统调用。
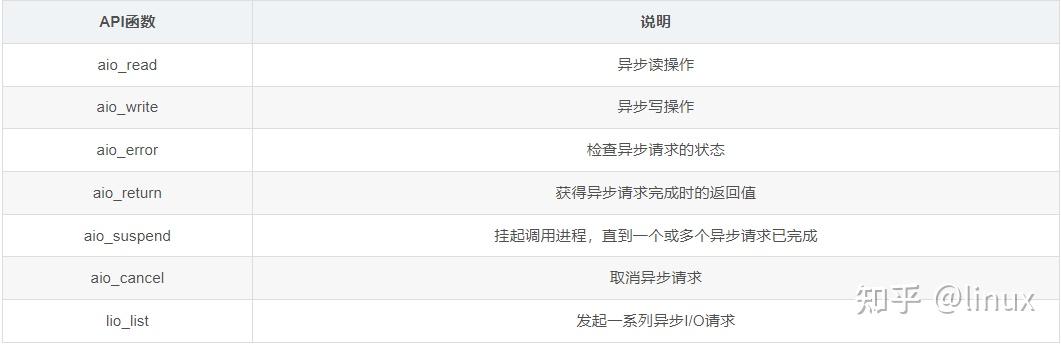
上述API调用都会用到 struct aiocb 结构体:
1 struct aiocb {
2 int aio_fildes; //文件描述符
3 off_t aio_offset; //文件偏移量
4 volatile void *aio_buf; //缓冲区
5 size_t aio_nbytes; //数据长度
6 int aio_reqprio; //请求优先级
7 struct sigevent aio_sigevent; //通知方式
8 int aio_lio_opcode; //要执行的操作
9 };编译时加参数 -lrt
检查异步请求状态
int aio_error(const struct aiocb *aiocbp);
异步读操作,aio_read函数请求对一个文件进行读操作,所请求文件对应的文件描述符可以是文件,套接字,甚至管道。
int aio_error(const struct aiocb *aiocbp);该函数请求对文件进行异步读操作,若请求失败返回-1,成功则返回0,并将该请求进行排队,然后就开始对文件的异步读操作。需要注意的是,我们得先对aiocb结构体进行必要的初始化。
特别提醒在编译上述程序时必须在编译时再加一个-lrt,如gcc test.c -o test -lrt。
1 #include<stdio.h>
2 #include<sys/socket.h>
3 #include<netinet/in.h>
4 #include<arpa/inet.h>
5 #include<assert.h>
6 #include<unistd.h>
7 #include<stdlib.h>
8 #include<errno.h>
9 #include<string.h>
10 #include<sys/types.h>
11 #include<fcntl.h>
12 #include<aio.h>
13
14
15 #define BUFFER_SIZE 1024
16
17 int MAX_LIST = 2;
18
19 int main(int argc,char **argv)
20 {
21 //aio操作所需结构体
22 struct aiocb rd;
23
24 int fd,ret,couter;
25
26 fd = open("test.txt",O_RDONLY);
27 if(fd < 0)
28 {
29 perror("test.txt");
30 }
31
32
33
34 //将rd结构体清空
35 bzero(&rd,sizeof(rd));
36
37
38 //为rd.aio_buf分配空间
39 rd.aio_buf = malloc(BUFFER_SIZE + 1);
40
41 //填充rd结构体
42 rd.aio_fildes = fd;
43 rd.aio_nbytes = BUFFER_SIZE;
44 rd.aio_offset = 0;
45
46 //进行异步读操作
47 ret = aio_read(&rd);
48 if(ret < 0)
49 {
50 perror("aio_read");
51 exit(1);
52 }
53
54 couter = 0;
55 // 循环等待异步读操作结束
56 while(aio_error(&rd) == EINPROGRESS)
57 {
58 printf("第%d次\n",++couter);
59 }
60 //获取异步读返回值
61 ret = aio_return(&rd);
62
63 printf("\n\n返回值为:%d",ret);
64
65
66 return 0;
67 }上述实例中aiocb结构体用来表示某一次特定的读写操作,在异步读操作时我们只需要注意4点内容
- 1.确定所要读的文件描述符,并写入aiocb结构体中(下面几条一样不再赘余)
- 2.确定读所需的缓冲区
- 3.确定读的字节数
- 4.确定文件的偏移量
总结以上注意事项:基本上和我们的read函数所需的条件相似,唯一的区别就是多一个文件偏移量。
运行结果如下:
从上图看出,循环检查了3次异步读写的状态(不同机器的检查次数可能不一样,和具体的计算机性能有关系),指定的256字节才读取完毕,最后返回读取的字节数256。
如果注释掉异步读的状态检查:
1 ...
2
3 //查看异步读取的状态,直到读取请求完成
4 /* for(i = 1;aio_error(&cbp) == EINPROGRESS;i++)
5 {
6 printf("No.%3d\n",i);
7 }
8 ret = aio_return(&cbp);
9 printf("return %d\n",ret);
10 */
11 ...此时的运行结果:

发现什么都没输出,这是因为程序结束的时候,异步读请求还没完成,所以buf缓冲区还没有读进去数据。
如果将上面代码中的 sleep 的注释去掉,让异步请求发起后,程序等待1秒后再输出,就会发现成功读取到了数据。
用GDB单步跟踪上面程序,当发起异步读请求时:
看到发起一个异步请求时,Linux实际上是创建了一个线程去处理,当请求完成后结束线程。
相关视频推荐
40k技术专家的linux服务器性能优化方法论,异步的效率
全网最详细epoll讲解,6种epoll的设计,让你吊打面试官
学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

aio_writr用来请求异步写操作
int aio_write(struct aiocb *paiocb);aio_write和aio_read函数类似,当该函数返回成功时,说明该写请求以进行排队(成功0,失败-1)。
特别提醒在编译上述程序时必须在编译时再加一个-lrt,如gcc test.c -o test -lrt。
1 #include<stdio.h>
2 #include<sys/socket.h>
3 #include<netinet/in.h>
4 #include<arpa/inet.h>
5 #include<assert.h>
6 #include<unistd.h>
7 #include<stdlib.h>
8 #include<errno.h>
9 #include<string.h>
10 #include<sys/types.h>
11 #include<fcntl.h>
12 #include<aio.h>
13
14 #define BUFFER_SIZE 1025
15
16 int main(int argc,char **argv)
17 {
18 //定义aio控制块结构体
19 struct aiocb wr;
20
21 int ret,fd;
22
23 char str[20] = {"hello,world"};
24
25 //置零wr结构体
26 bzero(&wr,sizeof(wr));
27
28 fd = open("test.txt",O_WRONLY | O_APPEND);
29 if(fd < 0)
30 {
31 perror("test.txt");
32 }
33
34 //为aio.buf申请空间
35 wr.aio_buf = (char *)malloc(BUFFER_SIZE);
36 if(wr.aio_buf == NULL)
37 {
38 perror("buf");
39 }
40
41 wr.aio_buf = str;
42
43 //填充aiocb结构
44 wr.aio_fildes = fd;
45 wr.aio_nbytes = 1024;
46
47 //异步写操作
48 ret = aio_write(&wr);
49 if(ret < 0)
50 {
51 perror("aio_write");
52 }
53
54 //等待异步写完成
55 while(aio_error(&wr) == EINPROGRESS)
56 {
57 printf("hello,world\n");
58 }
59
60 //获得异步写的返回值
61 ret = aio_return(&wr);
62 printf("\n\n\n返回值为:%d\n",ret);
63
64 return 0;
65 }上面test.txt文件是以追加的方式打开的,所以不需要设置aio_offset 文件偏移量,不管文件偏移的值是多少都会在文件末尾写入。可以去掉O_APPEND, 不以追加方式打开文件,这样就可以设置 aio_offset ,指定从何处位置开始写入文件。
aio_suspend函数可以将当前进程挂起,直到有向其注册的异步事件完成为止。
1 int aio_suspend(const struct aiocb * const aiocb_list[],
2 int nitems, const struct timespec *timeout);如果在定时时间达到之前,因为完成了IO请求导致函数返回,此时返回值是0;否则,返回值为-1,并且会设置errno。
前面2个例子发起IO请求都是非阻塞的,即使IO请求未完成,也不影响调用程序继续执行后面的语句。但是,我们也可以调用aio_suspend 来阻塞一个或多个异步IO, 只需要将IO请求加入阻塞列表。
1 #include<stdio.h>
2 #include<sys/types.h>
3 #include<sys/stat.h>
4 #include<errno.h>
5 #include<fcntl.h>
6 #include<aio.h>
7 #include<stdlib.h>
8 #include<strings.h>
9
10 #define BUFSIZE 1024
11 #define MAX 2
12
13 //异步读请求
14 int aio_read_file(struct aiocb *cbp,int fd,int size)
15 {
16 int ret;
17 bzero(cbp,sizeof(struct aiocb));
18
19 cbp->aio_buf = (volatile void*)malloc(size+1);
20 cbp->aio_nbytes = size;
21 cbp->aio_offset = 0;
22 cbp->aio_fildes = fd;
23
24 ret = aio_read(cbp);
25 if(ret < 0)
26 {
27 perror("aio_read error\n");
28 exit(1);
29 }
30 }
31
32 int main()
33 {
34 struct aiocb cbp1,cbp2;
35 int fd1,fd2,ret;
36 int i = 0;
37 //异步阻塞列表
38 struct aiocb* aiocb_list[2];
39
40 fd1 = open("test.txt",O_RDONLY);
41 if(fd1 < 0)
42 {
43 perror("open error\n");
44 }
45 aio_read_file(&cbp1,fd1,BUFSIZE);
46
47 fd2 = open("test.txt",O_RDONLY);
48 if(fd2 < 0)
49 {
50 perror("open error\n");
51 }
52 aio_read_file(&cbp2,fd2,BUFSIZE*4);
53
54 //向列表加入两个请求
55 aiocb_list[0] = &cbp1;
56 aiocb_list[1] = &cbp2;
57 //阻塞,直到请求完成才会继续执行后面的语句
58 aio_suspend((const struct aiocb* const*)aiocb_list,MAX,NULL);
59 printf("read1:%s\n",(char*)cbp1.aio_buf);
60 printf("read2:%s\n",(char*)cbp2.aio_buf);
61
62 close(fd1);
63 close(fd2);
64 return 0;
65 }运行结果
可以看到只有read2读到了数据,因为只要有IO请求完成阻塞函数aio_suspend就会直接就返回用户线程了,继续执行下面的语句。
aio同时还为我们提供了一个可以发起多个或多种I/O请求的接口lio_listio。这个函数效率很高,因为我们只需一次系统调用(一次内核上下位切换)就可以完成大量的I/O操作。第一个参数:LIO_WAIT (阻塞) 或 LIO_NOWAIT(非阻塞),第二个参数:异步IO请求列表
int lio_listio(int mode,struct aiocb *list[],int nent,struct sigevent *sig);如果mode是LIO_NOWAIT,当所有IO请求成功入队后返回0,否则,返回-1,并设置errno。如果mode是LIO_WAIT,当所有IO请求完成之后返回0,否则,返回-1,并设置errno。
1 #include<stdio.h>
2 #include<sys/types.h>
3 #include<sys/stat.h>
4 #include<errno.h>
5 #include<fcntl.h>
6 #include<aio.h>
7 #include<stdlib.h>
8 #include<strings.h>
9
10 #define BUFSIZE 100
11 #define MAX 2
12
13 //异步读结构体
14 int aio_read_file(struct aiocb *cbp,int fd,int size)
15 {
16 int ret;
17 bzero(cbp,sizeof(struct aiocb));
18
19 cbp->aio_buf = (volatile void*)malloc(size+1);
20 cbp->aio_nbytes = size;
21 cbp->aio_offset = 0;
22 cbp->aio_fildes = fd;
23 cbp->aio_lio_opcode = LIO_READ;
24 }
25
26 int main()
27 {
28 struct aiocb cbp1,cbp2;
29 int fd1,fd2,ret;
30 int i = 0;
31 //异步请求列表
32 struct aiocb* io_list[2];
33
34 fd1 = open("test.txt",O_RDONLY);
35 if(fd1 < 0)
36 {
37 perror("open error\n");
38 }
39 aio_read_file(&cbp1,fd1,BUFSIZE);
40
41 fd2 = open("test.txt",O_RDONLY);
42 if(fd2 < 0)
43 {
44 perror("open error\n");
45 }
46 aio_read_file(&cbp2,fd2,BUFSIZE*4);
47
48 io_list[0] = &cbp1;
49 io_list[1] = &cbp2;
50
51 lio_listio(LIO_WAIT,(struct aiocb* const*)io_list,MAX,NULL);
52 printf("read1:%s\n",(char*)cbp1.aio_buf);
53 printf("read2:%s\n",(char*)cbp2.aio_buf);
54
55 close(fd1);
56 close(fd2);
57 return 0;
58 }运行结果:
异步与同步的区别就是我们不需要等待异步操作返回就可以继续干其他的事情,当异步操作完成时可以通知我们去处理它。
以下两种方式可以处理异步通知:
- 信号处理
- 线程回调
在发起异步请求时,可以指定当异步操作完成时给调用进程发送什么信号,这样调用收到此信号就会执行相应的信号处理函数。
代码:
1 #include<stdio.h>
2 #include<sys/types.h>
3 #include<sys/stat.h>
4 #include<errno.h>
5 #include<fcntl.h>
6 #include<aio.h>
7 #include<stdlib.h>
8 #include<strings.h>
9 #include<signal.h>
10
11 #define BUFSIZE 256
12
13 //信号处理函数,参数signo接收的对应的信号值
14 void aio_handler(int signo)
15 {
16 int ret;
17 printf("异步操作完成,收到通知\n");
18 }
19
20 int main()
21 {
22 struct aiocb cbp;
23 int fd,ret;
24 int i = 0;
25
26 fd = open("test.txt",O_RDONLY);
27
28 if(fd < 0)
29 {
30 perror("open error\n");
31 }
32
33 //填充struct aiocb 结构体
34 bzero(&cbp,sizeof(cbp));
35 //指定缓冲区
36 cbp.aio_buf = (volatile void*)malloc(BUFSIZE+1);
37 //请求读取的字节数
38 cbp.aio_nbytes = BUFSIZE;
39 //文件偏移
40 cbp.aio_offset = 0;
41 //读取的文件描述符
42 cbp.aio_fildes = fd;
43 //发起读请求
44
45 //设置异步通知方式
46 //用信号通知
47 cbp.aio_sigevent.sigev_notify = SIGEV_SIGNAL;
48 //发送异步信号
49 cbp.aio_sigevent.sigev_signo = SIGIO;
50 //传入aiocb 结构体
51 cbp.aio_sigevent.sigev_value.sival_ptr = &cbp;
52
53 //安装信号
54 signal(SIGIO,aio_handler);
55 //发起异步读请求
56 ret = aio_read(&cbp);
57 if(ret < 0)
58 {
59 perror("aio_read error\n");
60 exit(1);
61 }
62 //暂停4秒,保证异步请求完成
63 sleep(4);
64 close(fd);
65 return 0;
66 }运行结果:

SIGIO 是系统专门用来表示异步通知的信号,当然也可以发送其他的信号,比如将上面的SIGIO替换为 SIGRTMIN+1 也是可以的。安装信号可以使用signal(),但是signal不可以传递参数进去。所以推荐使用sigaction()函数,可以为信号处理设置更多的东西。
顾名思义就是当调用进程收到异步操作完成的通知时,开线程执行设定好的回调函数去处理。无需专门安装信号。在Glibc AIO 的实现中, 用多线程同步来模拟 异步IO ,以上述代码为例,它牵涉了3个线程,
主线程(23908)新建 一个线程(23909)来调用阻塞的pread函数,当pread返回时,又创建了一个线程(23910)来执行我们预设的异步回调函数, 23909 等待23910结束返回,然后23909也结束执行。与信号处理方式相比,如上图,采用线程回调的方式可以使得在处理异步通知的时候不会阻塞当前调用进程。
实际上,为了避免线程的频繁创建、销毁,当有多个请求时,Glibc AIO 会使用线程池,但以上原理是不会变的,尤其要注意的是:我们的回调函数是在一个单独线程中执行的.
Glibc AIO 广受非议,存在一些难以忍受的缺陷和bug,饱受诟病,是极不推荐使用的.
1 #include<stdio.h>
2 #include<sys/types.h>
3 #include<sys/stat.h>
4 #include<errno.h>
5 #include<fcntl.h>
6 #include<aio.h>
7 #include<stdlib.h>
8 #include<strings.h>
9 #include<signal.h>
10
11 #define BUFSIZE 256
12
13 //回调函数
14 void aio_handler(sigval_t sigval)
15 {
16 struct aiocb *cbp;
17 int ret;
18
19 printf("异步操作完成,收到通知\n");
20 //获取aiocb 结构体的信息
21 cbp = (struct aiocb*)sigval.sival_ptr;
22
23 if(aio_error(cbp) == 0)
24 {
25 ret = aio_return(cbp);
26 printf("读请求返回值:%d\n",ret);
27 }
28 while(1)
29 {
30 printf("正在执行回调函数。。。\n");
31 sleep(1);
32 }
33 }
34
35 int main()
36 {
37 struct aiocb cbp;
38 int fd,ret;
39 int i = 0;
40
41 fd = open("test.txt",O_RDONLY);
42
43 if(fd < 0)
44 {
45 perror("open error\n");
46 }
47
48 //填充struct aiocb 结构体
49 bzero(&cbp,sizeof(cbp));
50 //指定缓冲区
51 cbp.aio_buf = (volatile void*)malloc(BUFSIZE+1);
52 //请求读取的字节数
53 cbp.aio_nbytes = BUFSIZE;
54 //文件偏移
55 cbp.aio_offset = 0;
56 //读取的文件描述符
57 cbp.aio_fildes = fd;
58 //发起读请求
59
60 //设置异步通知方式
61 //用线程回调
62 cbp.aio_sigevent.sigev_notify = SIGEV_THREAD;
63 //设置回调函数
64 cbp.aio_sigevent.sigev_notify_function = aio_handler;
65 //传入aiocb 结构体
66 cbp.aio_sigevent.sigev_value.sival_ptr = &cbp;
67 //设置属性为默认
68 cbp.aio_sigevent.sigev_notify_attributes = NULL;
69
70 //发起异步读请求
71 ret = aio_read(&cbp);
72 if(ret < 0)
73 {
74 perror("aio_read error\n");
75 exit(1);
76 }
77 //调用进程继续执行
78 while(1)
79 {
80 printf("主线程继续执行。。。\n");
81 sleep(1);
82 }
83 close(fd);
84 return 0;
85 }运行结果:
上面介绍的aio其实是用户层使用线程模拟的异步io,缺点是占用线程资源而且受可用线程的数量限制。Linux2.6版本后有了libaio,这完全是内核级别的异步IO,IO请求完全由底层自由调度(以最佳次序的磁盘调度方式)。
libaio的缺点是,想要使用该种方式的文件必须支持以O_DIRECT标志打开,然而并不是所有的文件系统都支持。如果你没有使用O_DIRECT打开文件,它可能仍然“工作”,但它可能不是异步完成的,而是变为了阻塞的。
sudo apt-get install libaio-devaiocb结构体:
1 struct aiocb
2 {
3 //要异步操作的文件描述符
4 int aio_fildes;
5 //用于lio操作时选择操作何种异步I/O类型
6 int aio_lio_opcode;
7 //异步读或写的缓冲区的缓冲区
8 volatile void *aio_buf;
9 //异步读或写的字节数
10 size_t aio_nbytes;
11 //异步通知的结构体
12 struct sigevent aio_sigevent;
13 }timespec结构体
1 struct timespec {
2 time_t tv_sec; /* seconds */
3 long tv_nsec; /* nanoseconds [0 .. 999999999] */
4 };tv_sec:秒数
tv_nsec:毫秒数
io_event结构体
1 struct io_event {
2 void *data;
3 struct iocb *obj;
4 unsigned long res;
5 unsigned long res2;
6 };3.3.3.2 成员分析
io_event是用来描述返回结果的:
obj就是之前提交IO任务时的iocb;
res和res2来表示IO任务完成的状态。
3.3.4 io_iocb_common
3.3.4.1 源码
io_iocb_common结构体
1 struct io_iocb_common { // most import structure, either io and iov are both initialized based on this
2
3 PADDEDptr(void *buf, __pad1); // pointer to buffer for io, pointer to iov for io vector
4
5 PADDEDul(nbytes, __pad2); // number of bytes in one io, or number of ios for io vector
6
7 long long offset; //disk offset
8
9 long long __pad3;
10
11 unsigned flags; // interface for set_eventfd(), flag to use eventfd
12
13 unsigned resfd;// interface for set_eventfd(), set to eventfd
14
15 }; /* result code is the amount read or -'ve errno */io_iocb_common是也是异步IO库里面最重要的数据结构,上面iocb数据结构中的联合u,通常就是按照io_iocb_common的格式来初始化的。
3.3.4.2 成员分析
成员 buf: 在批量IO的模式下,表示一个iovector 数组的起始地址;在单一IO的模式下,表示数据的起始地址;
成员 nbytes: 在批量IO的模式下,表示一个iovector 数组的元素个数;在单一IO的模式下,表示数据的长度;
成员 offset: 表示磁盘或者文件上IO开始的起始地址(偏移)
成员 _pad3: 填充字段,目前可以忽略
成员 flags: 表示是否实用eventfd 机制
成员 resfd: 如果使用eventfd机制,就设置成之前初始化的eventfd的值, io_set_eventfd()就是用来封装上面两个域的。
1 struct iocb {
2 PADDEDptr(void *data, __pad1); /* Return in the io completion event */ /// will passed to its io finished events, channel of callback
3
4 PADDED(unsigned key, __pad2); /* For use in identifying io requests */ /// identifier of which iocb, initialized with iocb address?
5
6 short aio_lio_opcode; // io opration code, R/W SYNC/DSYNC/POOL and so on
7
8 short aio_reqprio; // priority
9
10 int aio_fildes; // aio file descriptor, show which file/device the operation will take on
11
12 union {
13 struct io_iocb_common c; // most important, common initialization interface
14
15 struct io_iocb_vector v;
16
17 struct io_iocb_poll poll;
18
19 struct io_iocb_sockaddr saddr;
20
21 } u;
22
23 };iocb是异步IO库里面最重要的数据结构,大部分异步IO函数都带着这个参数。
成员 data: 当前iocb对应的IO完成之后,这个data的值会自动传递到这个IO生成的event的data这个域上去
成员 key: 标识哪一个iocb,通常没用
成员 ail_lio_opcode:指示当前IO操作的类型,可以初始化为下面的类型之一:
1 typedef enum io_iocb_cmd { // IO Operation type, used to initialize aio_lio_opcode
2
3 IO_CMD_PREAD = 0,
4
5 IO_CMD_PWRITE = 1,
6
7 IO_CMD_FSYNC = 2,
8
9 IO_CMD_FDSYNC = 3,
10
11 IO_CMD_POLL = 5, /* Never implemented in mainline, see io_prep_poll */
12
13 IO_CMD_NOOP = 6,
14
15 IO_CMD_PREADV = 7,
16
17 IO_CMD_PWRITEV = 8,
18
19 } io_iocb_cmd_t;成员 aio_reqprio: 异步IO请求的优先级,可能和io queue相关
成员 aio_filds: 接受IO的打开文件描述符,注意返回这个描述符的open()函数所带的CREATE/RDWR参数需要和上面的opcod相匹配,满足读写权限属性检查规则。
成员 u: 指定IO对应的数据起始地址,或者IO向量数组的起始地址
linux kernel 提供了5个系统调用来实现异步IO。文中最后介绍的是包装了这些系统调用的用户空间的函数。
1 int io_setup(unsigned nr_events, aio_context_t *ctxp);
2 int io_destroy(aio_context_t ctx);
3 int io_submit(aio_context_t ctx, long nr, struct iocb *cbp[]);
4 int io_cancel(aio_context_t ctx, struct iocb *, struct io_event *result);
5 int io_getevents(aio_context_t ctx, long min_nr, long nr, struct io_event *events, struct timespec *timeout);1、建立IO任务
int io_setup (int maxevents, io_context_t *ctxp);
io_context_t对应内核中一个结构,为异步IO请求提供上下文环境。注意在setup前必须将io_context_t初始化为0。当然,这里也需要open需要操作的文件,注意设置O_DIRECT标志。
2、提交IO任务
long io_submit (aio_context_t ctx_id, long nr, struct iocb **iocbpp);
提交任务之前必须先填充iocb结构体,libaio提供的包装函数说明了需要完成的工作:
3.获取完成的IO
long io_getevents (aio_context_t ctx_id, long min_nr, long nr, struct io_event *events, struct timespec *timeout);
这里最重要的就是提供一个io_event数组给内核来copy完成的IO请求到这里,数组的大小是io_setup时指定的maxevents。timeout是指等待IO完成的超时时间,设置为NULL表示一直等待所有到IO的完成。
4.销毁IO任务
int io_destrory (io_context_t ctx)
代码:
1 #define _GNU_SOURCE /* syscall() is not POSIX */
2 #include <stdio.h> /* for perror() */
3 #include <unistd.h> /* for syscall() */
4 #include <sys/syscall.h> /* for __NR_* definitions */
5 #include <linux/aio_abi.h> /* for AIO types and constants */
6 inline int io_setup(unsigned nr, aio_context_t *ctxp)
7 {
8 return syscall(__NR_io_setup, nr, ctxp);
9 }
10 inline int io_destroy(aio_context_t ctx)
11 {
12 return syscall(__NR_io_destroy, ctx);
13 }
14 int main()
15 {
16 aio_context_t ctx;
17 int ret;
18 ctx = 0;
19 ret = io_setup(128, &ctx);
20 if (ret < 0) {
21 perror("io_setup error");
22 return -1;
23 }
24 printf("after io_setup ctx:%Ld\n",ctx);
25 ret = io_destroy(ctx);
26 if (ret < 0) {
27 perror("io_destroy error");
28 return -1;
29 }
30 printf("after io_destroy ctx:%Ld\n",ctx);
31 return 0;
32 }系统调用io_setup会创建一个所谓的"AIO上下文"(即aio_context,后文也叫‘AIO context’等)结构体到在内核中。aio_context是用以内核实现异步AIO的数据结构。它其实是一个无符号整形,位于头文件 /usr/include/linux/aio_abi.h。
typedef unsigned long aio_context_t;每个进程都可以有多个aio_context_t。传入io_setup的第一个参数在这里是128,表示同时驻留在上下文中的IO请求的个数;第二个参数是一个指针,内核会填充这个值。io_destroy的作用是销毁这个上下文aio_context_t。上面的例子很简单,创建一个aio_context_t并销毁。
流程:
- 每一个提交的IO请求用结构体struct iocb来表示。
- 首先初始化这个结构体为全零: memset(&cb, 0, sizeof(cb));
- 然后初始化文件描述符(cb.aio_fildes = fd)和AIO 命令(cb.aio_lio_opcode = IOCB_CMD_PWRITE)
- 文件描述符对应上文所打开的文件。本例中是https://www.zhihu.com/topic/19611616/testfile.
代码:
1 #define _GNU_SOURCE /* syscall() is not POSIX */
2 #include <stdio.h> /* for perror() */
3 #include <unistd.h> /* for syscall() */
4 #include <sys/syscall.h> /* for __NR_* definitions */
5 #include <linux/aio_abi.h> /* for AIO types and constants */
6 #include <fcntl.h> /* O_RDWR */
7 #include <string.h> /* memset() */
8 #include <inttypes.h> /* uint64_t */
9 inline int io_setup(unsigned nr, aio_context_t *ctxp)
10 {
11 return syscall(__NR_io_setup, nr, ctxp);
12 }
13
14 inline int io_destroy(aio_context_t ctx)
15 {
16 return syscall(__NR_io_destroy, ctx);
17 }
18
19 inline int io_submit(aio_context_t ctx, long nr, struct iocb **iocbpp)
20 {
21 return syscall(__NR_io_submit, ctx, nr, iocbpp);
22 }
23
24 inline int io_getevents(aio_context_t ctx, long min_nr, long max_nr, struct io_event *events, struct timespec *timeout)
25 {
26 return syscall(__NR_io_getevents, ctx, min_nr, max_nr, events, timeout);
27 }
28
29 int main()
30 {
31 aio_context_t ctx;
32 struct iocb cb; struct iocb *cbs[1];
33 char data[4096];
34 struct io_event events[1];
35 int ret;
36 int fd;
37 int i ;
38 for(i=0;i<4096;i++)
39 {
40 data[i]=i%50+60;
41 }
42 fd = open("https://www.zhihu.com/topic/19611616/testfile", O_RDWR | O_CREAT,S_IRWXU);
43 if (fd < 0)
44 {
45 perror("open error");
46 return -1;
47 }
48
49 ctx = 0;
50 ret = io_setup(128, &ctx);
51 printf("after io_setup ctx:%ld",ctx);
52 if (ret < 0)
53 {
54 perror("io_setup error");
55 return -1;
56 } /* setup I/O control block */
57 memset(&cb, 0, sizeof(cb));
58 cb.aio_fildes = fd;
59 cb.aio_lio_opcode = IOCB_CMD_PWRITE;/* command-specific options */
60 cb.aio_buf = (uint64_t)data;
61 cb.aio_offset = 0;
62 cb.aio_nbytes = 4096;
63 cbs[0] = &cb;
64 ret = io_submit(ctx, 1, cbs);
65 if (ret != 1)
66 {
67 if (ret < 0)
68 perror("io_submit error");
69 else
70 fprintf(stderr, "could not sumbit IOs");
71 return -1;
72 } /* get the reply */
73
74 ret = io_getevents(ctx, 1, 1, events, NULL);
75 printf("%d\n", ret);
76 struct iocb * result = (struct iocb *)events[0].obj;
77 printf("reusult:%Ld",result->aio_buf);
78 ret = io_destroy(ctx);
79 if (ret < 0)
80 {
81 perror("io_destroy error");
82 return -1;
83 }
84 return 0;
85 }内核当前支持的AIO 命令有
1 IOCB_CMD_PREAD 读; 对应系统调用pread().
2 IOCB_CMD_PWRITE 写,对应系统调用pwrite().
3 IOCB_CMD_FSYNC 同步文件数据到磁盘,对应系统调用fsync()
4 IOCB_CMD_FDSYNC 同步文件数据到磁盘,对应系统调用fdatasync()
5 IOCB_CMD_PREADV 读,对应系统调用readv()
6 IOCB_CMD_PWRITEV 写,对应系统调用writev()
7 IOCB_CMD_NOOP 只是内核使用Apache
Apache HTTP服务器是 Robert McCool 在1995年写成,并在1999年开始在Apache软件基金会的 框架下进行开发。由于Apache HTTP服务器是基金会最开始的一个项目也是最为有名的一个项目, 所以通常大家提到Apache这个词都是说的Apache HTTP Server。
Apache web服务器从1996年开始就是互联网上最为流行的HTTP服务器。Apache之所以这么流行 很大程度上是由于相比其他的软件项目,在Apache基金会的精心维护下他的文档十分的详尽还有 集成的支持服务。
Apache由于其可变性、高性能和广泛的支持,经常是系统管理员的首选。他可以通过一系列 的语言相关的扩展模块支持很多解释型语言的后端,而不需要连接一个独立的后端程序。
Apache软件基金会也是利用开源软件盈利的一个范本。时至今日,Apache软件基金会 已经枝繁叶茂,在基金会名下的开源项目我们耳熟能详的有:
- Apache HTTP Server
- Ant(Java的编译工具)
- ActiveMQ(MQ集群)
- Cassandra(强一致的分布式KV数据库)
- CloudStack(OpenStack的劲敌)
- CouchDB(KV数据库)
- Flume(日志收集工具)
- Hadoop、Hbase、Hive
- Kafka(流式计算)
- Lucene(开源搜索引擎)
- Maven(Java编译&依赖管理工具)
- Mesos(分布式协调)
- OpenNLP(开源自然语言处理库)
- OpenOffice(开源的类Office工具)
- Perl(Perl语言)
- Spark(分布式计算集群)
- Storm(流式计算)
- Struts(Java SSH框架的第二个S)
- Subversion(SVN,你懂的)
- Tcl(Tcl语言)
- Thrift(Java网络框架)
- Tomcat(大名鼎鼎的Java容器)
- ZooKeeper(分布式协调集群)
完整的Apache基金会的项目列表参见:Welcome to The Apache Software Foundation!
Nginx
2002年,一个叫Igor Sysoev的俄罗斯哥们儿(貌似俄罗斯叫Igor的人挺多的) 写出了一个叫Nginx(和Engine X谐音,取引擎之义)。 那时候有一个时代背景,当时C10K(Concurrency 10K,1万并发)问题还是困扰绝大多数 web服务器的一个难题。Nginx利用异步事件驱动的架构写成,是C10K问题的一个很好的答卷。 Nginx的第一个公开发行版是在2004年发布的,之前都是作为俄罗斯访问量第二的网站Rambler 的内部使用。
Nginx的主要优势在于“轻、快、活”:
轻
很低的资源占用,甚至能在很多嵌入式设备上运行。
快
响应速度超快,几乎不会由于高并发影响响应速度。
活
配置灵活,广泛的模块支持。
网上关于Apache和Nginx性能比较的文章非常多,基本上有如下的定论:
- Nginx在并发性能上比Apache强很多,如果是纯静态资源(图片、JS、CSS)那么Nginx是不二之选。
- Apache有mod_php、在PHP类的应用场景下比Nginx部署起来简单很多。一些老的PHP项目用Apache 来配置运行非常的简单,例如Wordpress。
- 对于初学者来说Apache配置起来非常复杂冗长的类XML语法,甚至支持在子目录放置.htaccess 文件来配置子目录的属性。Nginx的配置文件相对简单一点。
- Nginx的模块比较容易写,可以通过写C的mod实现接口性质的服务,并且拥有惊人的性能。 分支OpenResty,可以配合lua来实现很多自定义功能,兼顾扩展性和性能。
这里我们要着重讨论的是为什么Nginx在并发性能上比Apache要好很多。
想要了解这个问题,不得不先做一些铺垫,讲讲并发网络编程的一些历史:
壹 最原始
最原始的网络编程的伪代码大致是这样:
00 listen(port) # 监听在接收服务的端口上
01 while True: # 一直循环
02 conn = accept() # 接收连接
03 read_content = read(conn) # 读取连接发送过来的请求
04 response = process(conn) # 执行业务逻辑,并得到给客户端回应的内容
05 conn.write(response) # 将回应写回给连接
我们需要了解,最原始的Linux中accept、read、write调用都是 阻塞的(现在,阻塞也是这些调用的默认行为)。这就导致了以上代码只能同时 处理一个连接,所以就有了下面的方法:
贰 每个连接开一个进程
后来,大家想到了办法:
00 listen(port) # 监听在接收服务的端口上
01 while True: # 一直循环
02 conn = accept() # 接收连接
03 if fork() == 0:
04 # 子进程
05 read_content = read(conn) # 读取连接发送过来的请求
06 response = process(conn) # 执行业务逻辑,并得到给客户端回应的内容
07 conn.write(response) # 将回应写回给连接
用子进程来处理连接,父进程继续等待连接进来。但这种方式有如下两个明显的缺陷:
- fork()调用比较费时,需要对进程进行内存拷贝。即使现在的Linux普遍 引入了COW(Copy On Write)技术(fork的时候不做内存拷贝,只有其中一个 副本发生了write的时候才进行copy)加速了fork的效率,但fork依旧是个 比较“重”的系统调用。
- 较多的内存占用,也是由于上述的内存复制造成的。
叁 引入线程
得益于之前提过的Linux对于线程的引入,上面例子的开进程,被换成了开线程, 这样,上一小节说的两个缺陷都大大的被缓解了。
肆 进程/线程池
计算机领域有很多算法或者是方法都会用到一种智慧:“空间换时间”。 即用使用更多内存的方式换取更快的运行速度:事先创建出很多进程/线程 ,就像一个池子,这样虽然会浪费一部分的内存,但连接过来的时候就省去了 开启进程/线程的时间。
但这种方式会有一个比较显著的缺陷:当并发数大于进程/线程池的大小的时候 性能就会发生很大的下滑,退化成“贰”的情况。
伍 非阻塞&事件驱动
那么,是不是想要达到高性能就一定要付出高系统资源占用呢? 答案是否定的,如果我们注意观察生活中的一个细节,肯德基和麦当劳的不同 服务方式:
- 肯德基
- 服务员在前台问:“先生/小姐,有什么可以帮你?”
- 顾客,思考一下点什么比较好:“我要,xxxxx”
- 服务员去后台配餐、取餐,3分钟过去了:“您的餐齐了,下一位”
- 麦当劳
- 服务员在前台问:“先生/小姐,有什么可以帮你?”
- 顾客:“我要,xxxxx”。如果顾客思考超过5秒:“后面的顾客请先点”; 点完餐,前台服务员继续为下一位顾客点餐。后台有别的服务员完成配餐。
可以思考一下,这两种运作方式那种比较好:
- 在肯德基,如果遇到需要纠结半天吃什么的客户。服务员和后面的顾客 都会陷入较长时间的等候。原因就是如果最前面的客户先让后面的顾客点餐 ,他想好了还需要较长时间的等候。相比之下,麦当劳就更胜一筹。
- 在麦当劳,后面配餐的服务员如果发现有两个订单都要了可乐。他可以 智能地把两个订单的可乐一次性灌好,这样会大大的提高效率。各个岗位上 的服务员可以灵活的采用各种方式优化自己的工作效率。
这里,肯德基的服务方式就是古老的进程/线程池;麦当劳的服务方式 就是一个简单的非阻塞&事件驱动。
那么,非阻塞&事件驱动这么好,为什么大家没有一开始就采用这种方式呢? 原因有二:
- 非阻塞&事件驱动需要系统的支持,提供non-blocking版的整套 系统调用。
- 非阻塞&事件驱动编程难度较大,需要很高的抽象思维能力, 把整个任务拆解;采用有限状态机编程才能实现。
更多精彩,请见 Reboot教育 - 高效你的学习
端口被设计出来主要是为了给协议栈和应用对应:
- 协议栈用端口号将数据分配给不同的应用层程序
- 应用层程序用端口号去区分不同的连接,参见之前提到过的“四元组”
TCP和UDP协议都使用了端口号(Port number)的概念来标识发送方和接收方的应用层。 对每个TCP连接的一端都有一个相关的16位的无符号端口号分配给它们。 即使是UDP这种没有连接的协议,依旧有一个16位的无符号端口号。 可能的、被正式承认的端口号有 2^16 -1 = 65535 个。
端口被分为三类:著名端口、监听端口和动态端口。
著名端口是由因特网赋号管理局(IANA)来分配的,并且通常被用于系统进程。 IANA对于端口号的分配见这里 Service Name and Transport Protocol Port Number Registry 。 系统的/etc/services也有相应端口和服务名的对应,主要是用来给netstat、nmap 等系统命令做端口名反解用。
著名的应用程序作为服务器程序来运行,并侦听经常使用这些端口的连接。 这些端口的一个显著特征就是限定在0~1023,并且在Linux、UNIX平台均需要 Root权限才能监听这些端口。
在UNIX刚刚兴起的年代,服务器资源是十分稀缺的, 通常一台服务器上会有很多的用户,同时这台服务器往往还兼任一个学院、公司的邮件、 网站等服务。为了保证这些服务的端口不被普通用户占用, 当时UNIX的设计者就把使用这些端口的权限限制在系统管理员(Root)手里。
常见的`著名端口`有:FTP:21、SSH:22、SMTP:25、HTTP:80、HTTPS:443等。监听端口通常被用来运行各种用户自己写的服务,服务监听在这些端口下不需要特别的权限。
- BSD使用的监听端口范围是1024到4999。
- IANA建议49152至65535作为“监听端口”。
- 许多Linux内核使用32768至61000范围。 配置文件 /proc/sys/net/ipv4/ip_local_port_range 有当前系统设定。
动态端口通常被用来在主动发起连接时随机分配使用,在任何特定的TCP连接外不具有任何意义。 这是由于TCP等协议是通过四元组来区分不同的网络连接。 当本机主动发起TCP连接的时候如果目的IP、目的端口、本地IP都是一样的, 只能通过占用不同的本地端口来区分不同的连接。
0~65535除去上述著名端口、监听端口两种端口号,剩下的端口都是备用的动态端口。 所以在某些特殊用途的需要主动发起大量连接的服务器上(例如:爬虫、代理), 需要调整 /proc/sys/net/ipv4/ip_local_port_range 的数值,来保留更多的 动态端口以供使用。
端口号里有一个极为特殊的端口,各种文档书籍中都鲜有记载,就是0号端口。
在IANA官方的标准里0号端口是保留端口。

也就是说无论是TCP还是UDP网络通信,0号端口都是不能使用的。
然而,标准归标准,在UNIX/Linux网络编程中0号端口被赋予了特殊的涵义:
如果在bind绑定的时候指定端口0,意味着由系统随机选择一个可用端口来绑定。
用Python实现一个获取可用监听端口的示例:
def findFreePort():
"""
函数返回值是当前可用来监听的一个随机端口。
"""
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('localhost', 0))
# 用getsockname来获取我们实际绑定的端口号
addr, port = s.getsockname()
# 释放端口
s.close()
return port
既然说到了端口,不得不提一下NAT。
NAT是"Network Address Translation"的缩写,直译就是网络地址转换。 1990年代中期,为了应对IPv4地址短缺,NAT技术流行起来。
WikiPedia的解释为:
在一个典型的配置中,一个本地网络使用一个专有网络的指定子网 (比如192.168.x.x或10.x.x.x)和连在这个网络上的一个路由器。 这个路由器占有这个网络地址空间的一个专有地址(比如192.168.0.1), 同时它还通过一个或多个因特网服务提供商提供的公有的IP地址(叫做“过载”NAT) 连接到因特网上。当信息由本地网络向因特网传递时,源地址被立即从专有地址转换为公用地址。 由路由器跟踪每个连接上的基本数据,主要是目的地址和端口。当有回复返回路由器时, 它通过输出阶段记录的连接跟踪数据来决定该转发给内部网的哪个主机; 如果有多个公用地址可用,当数据包返回时,TCP或UDP客户机的端口号可以用来分解数据包。 对于因特网上的一个系统,路由器本身充当通信的源和目的地址。
这个技术能够被广泛使用还要感谢当时端口号的记录字段是2Bytes而不是1Byte。
NAT技术的广泛应用也给很多应用带来了极大的麻烦: 处于NAT网络环境内的服务器很难被外部的网络程序主动连接,受这一点伤害最大的莫过于: 点对点视频、语音、文件传输类的程序。
当然我们聪明的工程师经过长时间的努力,发明了“NAT打洞”技术,一定程度上解决了此类问题。
如果没有他们的努力,我们现在各种QQ视频、微信实时语音、网络电话都是需要用户连接到 服务商的服务器上进行数据传输。这样对服务商的网络消耗将是十分巨大的, 服务质量也是很难以提高的,具体的技术实现,我们以后再表。
我们都有一个计算机网络的常识:不同的进程不能使用同一端口。
如果一个端口正在被使用,无论是TIME_WAIT、CLOSE_WAIT、还是ESTABLISHED状态。 这个端口都不能被复用,这里面自然也是包括不能被用来LISTEN(监听)。
但这件事也不是绝对的,之前跟大家讲进程的创建过程提到过一件事: 当进程调用fork(2)系统调用的时候,会发生一系列资源的复制,其中就包括句柄。 所以,在调用fork(2)之前,打开任何文件,监听端口产生的句柄也将会被复制。
通过这种方式,我们就可以达成"多进程端口监听"。
但,这又有什么用呢?
我们大名鼎鼎的Nginx就是通过这种手法让多个进程同时监听在HTTP的服务端口上的, 这么做的好处就在于,当外部请求到达,Linux内核会保证多个进程只会有一个accept(2) 成功,这种情况下此端口的服务可用性就和单个进程存在与否无关。 Nginx正是利用这一点达成“不停服务reload、restart”的。
要说SO_REUSEADDR,我们需要先需要说一段历史: 记得大学的时候面试我们学校的“星辰工作室”,有一个问题就是
为什么有时候重启Apache会失败,报“Address already in use”?
当时答得不太好,不太明白这个问题的关键点在哪里,后来逐渐明白了。
TCP的原理会导致这样的一个结果:
主动close socket的一方会进入TIME_WAIT,这个状况持续的时间取决于三件事:
- TCP关闭连接的五次挥手包什么时候到达
- SO_LINGER的设置
- /proc/sys/net/ipv4/tcp_tw_recycle 和 /proc/sys/net/ipv4/tcp_tw_reuse 的设置
总之默认情况下,处于TIME_WAIT状态的端口是不能用来LISTEN的。 这就导致,Apache重启时产生80端口TIME_WAIT,进而导致Apache再次尝试LISTEN失败。
在很多开源代码里我们会看到如下代码:
int reuseaddr = 1;
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &reuseaddr, sizeof(int));
有了上面这段神奇的代码,就不会出现上面的惨剧。但SO_REUSEADDR的作用不仅限于上述
Linux 的 SO_REUSEADDR 设置为 1 有四种效果:
当端口处在TIME_WAIT时候,可以复用监听。
可以允许多个进程监听同一端口,但是必须不同IP。
这里说的比较隐晦,如果进程A监听0.0.0.0:80,B进程可以成功监听127.0.0.1:80, 顺序反过来也是可以的。
允许单个进程绑定相同的端口到多个socket上,但每个socket绑定的IP地址不同。
使用UDP时候,可以允许多个实例或者单进程同时监听同个端口同个IP。
服务端网络编程交流群:348904670
公众号:

# 得到书面授权之前,拒绝任何形式的转载
这两天看着大家都在实现无栈的 coroutine 都挺好玩的,但无栈协程限制太多,工程实践上很少用,所以昨天手痒写了个有栈的 coroutine ,接口反照 ucontext 的接口,不比无栈的复杂多少:
int main(void)
{
ctx_context_t r;
int hr;
volatile int mode = 0;
hr = ctx_getcontext(&r);
printf("ctx_getcontext() -> %d\n", hr);
if (mode == 0) {
mode++;
printf("first run\n");
ctx_setcontext(&r);
}
else {
printf("second run\n");
}
printf("endup\n");
return 0;
}
使用 ctx_getcontext / ctx_setcontext 可以实现保存现场,恢复现场的功能,该程序输出:
ctx_getcontext() -> 0
first run
ctx_getcontext() -> 6356604
second run
endup
继续使用 ctx_makecontext / ctx_swapcontext 可以实现初始化协程和切换上下文的功能:
char temp_stack[32768];
ctx_context_t mc, cc;
int raw_thread(void*p) {
printf("remote: hello %s\n", (char*)p);
ctx_swapcontext(&cc, &mc);
printf("remote: back again\n");
ctx_swapcontext(&cc, &mc);
printf("remote: return\n");
return 1024;
}
int main(void)
{
cc.stack = temp_stack;
cc.stack_size = sizeof(temp_stack);
cc.link = &mc;
ctx_getcontext(&cc);
ctx_makecontext(&cc, raw_thread, (char*)"girl");
printf("before switch: %d\n", cc.stack_size);
ctx_swapcontext(&mc, &cc);
printf("local: here\n");
ctx_swapcontext(&mc, &cc);
printf("local: again\n");
ctx_swapcontext(&mc, &cc);
printf("local: end\n");
return 0;
}
这里创建了一个协程,接着主程序和协程互相切换,程序输出:
before switch: 32768
remote: hello girl
local: here
remote: back again
local: again
remote: return
local: end
核心代码其实很简单,就 60多行,没啥复杂的:
asm("\
.globl _ctx_swapcontext \n\
.globl ctx_swapcontext \n\
_ctx_swapcontext: \n\
ctx_swapcontext: \n"
#if CTX_OS_WINDOWS || __CYGWIN__
"movq %rcx, %rax; \n"
#else
"movq %rdi, %rax; \n"
#endif
"\n\
movq %rdx, 24(%rax); \n\
movq %rax, 0(%rax); \n\
movq %rbx, 8(%rax); \n\
movq %rcx, 16(%rax); \n\
movq %rsi, 32(%rax); \n\
movq %rdi, 40(%rax); \n\
leaq 8(%rsp), %rdx; \n\
movq %rdx, 48(%rax); \n\
movq %rbp, 56(%rax); \n\
movq 0(%rsp), %rdx; \n\
movq %rdx, 64(%rax); \n\
pushfq; \n\
popq %rdx; \n\
movq %rdx, 72(%rax); \n\
movq %r8, 80(%rax); \n\
movq %r9, 88(%rax); \n\
movq %r10, 96(%rax); \n\
movq %r11, 104(%rax); \n\
movq %r12, 112(%rax); \n\
movq %r13, 120(%rax); \n\
movq %r14, 128(%rax); \n\
movq %r15, 136(%rax); \n\
movq 24(%rax), %rdx; \n\
stmxcsr 144(%rax); \n\
fnstenv 152(%rax); \n\
fldenv 152(%rax); \n"
#if CTX_OS_WINDOWS || __CYGWIN__
"movq %rdx, %rax\n"
#else
"movq %rsi, %rax\n"
#endif
"\n\
movq 8(%rax), %rbx; \n\
movq 16(%rax), %rcx; \n\
movq 24(%rax), %rdx; \n\
movq 32(%rax), %rsi; \n\
movq 40(%rax), %rdi; \n\
movq 48(%rax), %rsp; \n\
movq 56(%rax), %rbp; \n\
movq 64(%rax), %rdx; \n\
pushq %rdx; \n\
movq 72(%rax), %rdx; \n\
pushq %rdx; \n\
popfq; \n\
movq 80(%rax), %r8; \n\
movq 88(%rax), %r9; \n\
movq 96(%rax), %r10; \n\
movq 104(%rax), %r11; \n\
movq 112(%rax), %r12; \n\
movq 120(%rax), %r13; \n\
movq 128(%rax), %r14; \n\
movq 136(%rax), %r15; \n\
movq 24(%rax), %rdx; \n\
ldmxcsr 144(%rax); \n\
fldenv 152(%rax); \n\
movq 0(%rax), %rax; \n\
ret; \n\
");
就是保存寄存器,保存栈,恢复寄存器,恢复栈,返回就得了,注意额外保存一下浮点数状态,SSE 控制寄存器状态,和 eflag / rflag 即可。
构造协程就是把一个新的栈和寄存器初始化好,需要注意的是 calling convention:
x86 calling conventions
32位下面还好,Linux / Windows 都是可以用统一的 cdecl 约定,4(%esp) 代表第一个参数,8(%esp) 第二个参数,如此类推;64位稍微有点烦,Linux / BSD / OS X / Solaris 都统一使用 System V AMD64 ABI 而微软一如既往的自己发明了一套只能用于 Windows 的 Microsoft x64 calling convention,给所有人添堵。
所以在切换上下文时和构造协程环境的时候需要额外注意一下,除此以外 300行也就搞定了:https://github.com/skywind3000/collection/tree/master/vintage/context
用 ctx_makecontext / ctx_swapcontext 分分钟可以包装出一个 yield,具体包装方法可以见云风的 cloudwu/coroutine 项目。
接着封装下 epoll / socket ,加入些调度逻辑,你基本上就得到个腾讯的 libco 了。
一般有栈的协程主要问题是费内存,每个协程如果使用独立的栈的话,一开始创建过小,程序容易崩溃,特别是64位下面,一个函数调用的 frame 动辄几百字节的占用,你栈开小了就容易崩溃,栈这东西需要协程一开始就把地址确定下来,所以还不能用变长数组来保存,而你初始化很大的栈(比如每个协程1MB),又太费内存了,3000个协程就费 3G的内存,问题3000个协程是很正常的事情。
所以云风的 coroutine 和腾讯的 libco 的解决方法是 “栈拷贝”,初始化一个 4-8MB 的共有栈,每个协程都在这个共有栈上执行,只是进入和退出的时候需要把数据从共有栈备份/恢复到协程自己的变长数组里面,这样解决了空间浪费问题,也保证了协程的栈不会变来变去,但是带来了一个新问题,就是频繁切换时内存拷贝的开销。
所以其实他们都可以再优化一下,引入 stack 分组,初始化比如 100个栈,每个2MB ,协程初始化时选择一组负担轻的组加入进去,同组内的协程公用一个栈。
每个协程的栈有两个状态:ON_STACK / OFF_STACK,表示当前协程的栈是否就在这一组的公有栈上。协程 suspend 的时候,不必马上把栈拷贝回去,可以一直占用着该组的共有栈,直到有新协程恢复的时候,发现该组的共有栈上有一个 ON_STACK 的协程占用了,这时候再把它给踢走。
这样 100个栈上,基本都是被最活跃的几个协程所占用,且来切去很少发生拷贝栈的工作,整个栈拷贝开销基本都能下降 10-100 倍,如此有栈协程的内存开销问题得到解决,并消除了 所引入的副作用。
不过啊,协程着东西,我并不主张直接在 C/C++层次上使用,协程的目的是方便业务开发,降低业务逻辑的复杂度。是否需要在 C/C++ 上做协程,唯一的问题就是你是否需要把所有逻辑用 C/C++来实现?
其实如果你只是为了业务简单这个目的,你该直接去用 go / erlang / gevent / akka,这些封装成熟的库,出点问题调试起来信息也比较丰富,C/C++这种系统级语言本来就不适合写业务逻辑,除去开发效率外,协程出点问题,调试起来你是比较头疼的。
再者,如果不开发业务,而是开发系统级模块,那更应该直接手写状态机,因为系统级开发的 KPI是可靠和高效,并不是开发时间和复杂度。
所以 C/C++ 级别的协程,除非你给某个语言用 C/C++实现一套协程接口,或者自己觉得好玩写了娱乐一下,除此之外,写具体业务想上协程的话,C/C++的协程还是靠边站吧,建议大家直接使用 go / erlang / gevent / akka。
本文原文由作者“张小方”原创发布于“高性能服务器开发”微信公众号,原题《心跳包机制设计详解》,即时通讯网收录时有改动。
一般来说,没有真正动手做过网络通信应用的开发者,很难想象即时通讯应用中的心跳机制的作用。但不可否认,作为即时通讯应用,心跳机制是其网络通信技术底层中非常重要的一环,有没有心跳机制、心跳机制的算法实现好坏,都将直接影响即时通讯应用在应用层的表现——比如:实时性、断网自愈能力、弱网体验等等。
总之,要想真正理解即时通讯应用底层的开发,心跳机制必须掌握,而这也是本文写作的目的,希望能带给你启发。
需要说明的是:本文中涉及的示例代码是使用 C/C++ 语言编写,但是本文中介绍的心跳包机制设计思路和注意事项,都是是些普适性原理,同样适用于其他编程语言。虽然语言可以不同,但逻辑不会有差别!
学习交流:
- 即时通讯/推送技术开发交流4群:101279154[推荐]
- 移动端IM开发入门文章:《新手入门一篇就够:从零开发移动端IM》
(本文同步发布于:http://www.52im.net/thread-2697-1-1.html)
- 《为何基于TCP协议的移动端IM仍然需要心跳保活机制?》(推荐)
- 《微信团队原创分享:Android版微信后台保活实战分享(网络保活篇)》(推荐)
- 《移动端IM实践:实现Android版微信的智能心跳机制》
- 《移动端IM实践:WhatsApp、Line、微信的心跳策略分析》
- 《手把手教你用Netty实现网络通信程序的心跳机制、断线重连机制》
- 《Android端消息推送总结:实现原理、心跳保活、遇到的问题等》
考虑以下两种典型的即时通讯网络层问题情型:
1)情形一:一个客户端连接服务器以后,如果长期没有和服务器有数据来往,可能会被防火墙程序关闭连接,有时候我们并不想要被关闭连接。例如,对于一个即时通讯软件来说,如果服务器没有消息时,我们确实不会和服务器有任何数据交换,但是如果连接被关闭了,有新消息来时,我们再也没法收到了,这就违背了“即时通讯”的设计要求。
2)情形二:通常情况下,服务器与某个客户端一般不是位于同一个网络,其之间可能经过数个路由器和交换机,如果其中某个必经路由器或者交换器出现了故障,并且一段时间内没有恢复,导致这之间的链路不再畅通,而此时服务器与客户端之间也没有数据进行交换,由于 TCP 连接是状态机,对于这种情况,无论是客户端或者服务器都无法感知与对方的连接是否正常,这类连接我们一般称之为“死链”。
对于上述问题情型,即时通讯应用通常的解决思路:
1)针对情形一:此应用场景要求必须保持客户端与服务器之间的连接正常,就是我们通常所说的“保活“。如上所述,当服务器与客户端一定时间内没有有效业务数据来往时,我们只需要给对端发送心跳包即可实现保活。
2)针对情形二:要解决死链问题,只要我们此时任意一端给对端发送一个数据包即可检测链路是否正常,这类数据包我们也称之为”心跳包”,这种操作我们称之为“心跳检测”。顾名思义,如果一个人没有心跳了,可能已经死亡了;一个连接长时间没有正常数据来往,也没有心跳包来往,就可以认为这个连接已经不存在,为了节约服务器连接资源,我们可以通过关闭 socket,回收连接资源。
总之,心跳检测机制一般有两个作用:
1)保活;
2)检测死链。
针对以上问题情型,即时通讯网的另一篇:《为何基于TCP协议的移动端IM仍然需要心跳保活机制?》,也非常值得一读。
PS:如你还不了解tcp的keepalive是什么,建议先阅读:《TCP/IP详解 - 第23章·TCP的保活定时器》
操作系统的 TCP/IP 协议栈其实提供了这个的功能,即 keepalive 选项。在 Linux 操作系统中,我们可以通过代码启用一个 socket 的心跳检测(即每隔一定时间间隔发送一个心跳检测包给对端)。
代码如下:
//on 是 1 表示打开 keepalive 选项,为 0 表示关闭,0 是默认值
inton = 1;
setsockopt(fd, SOL_SOCKET, SO_KEEPALIVE, &on, sizeof(on));
但是,即使开启了这个选项,这个选项默认发送心跳检测数据包的时间间隔是 7200 秒(2 小时),这时间间隔实在是太长了,一定也不使用。
我们可以通过继续设置 keepalive 相关的三个选项来改变这个时间间隔,它们分别是 TCP_KEEPIDLE、TCP_KEEPINTVL 和 TCP_KEEPCNT。
示例代码如下:
//发送 keepalive 报文的时间间隔
intval = 7200;
setsockopt(fd, IPPROTO_TCP, TCP_KEEPIDLE, &val, sizeof(val));
//两次重试报文的时间间隔
intinterval = 75;
setsockopt(fd, IPPROTO_TCP, TCP_KEEPINTVL, &interval, sizeof(interval));
intcnt = 9;
setsockopt(fd, IPPROTO_TCP, TCP_KEEPCNT, &cnt, sizeof(cnt));
TCP_KEEPIDLE 选项设置了发送 keepalive 报文的时间间隔,发送时如果对端回复 ACK。则本端 TCP 协议栈认为该连接依然存活,继续等 7200 秒后再发送 keepalive 报文;如果对端回复 RESET,说明对端进程已经重启,本端的应用程序应该关闭该连接。
如果对端没有任何回复,则本端做重试,如果重试 9 次(TCP_KEEPCNT 值)(前后重试间隔为 75 秒(TCP_KEEPINTVL 值))仍然不可达,则向应用程序返回 ETIMEOUT(无任何应答)或 EHOST 错误信息。
我们可以使用如下命令查看 Linux 系统上的上述三个值的设置情况:
[root@iZ238vnojlyZ ~]# sysctl -a | grep keepalive
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 7200
在 Windows 系统设置 keepalive 及对应选项的代码略有不同:
//开启 keepalive 选项
constcharon = 1;
setsockopt(socket, SOL_SOCKET, SO_KEEPALIVE, (char*)&on, sizeof(on);
// 设置超时详细信息
DWORDcbBytesReturned;
tcp_keepalive klive;
// 启用保活
klive.onoff = 1;
klive.keepalivetime = 7200;
// 重试间隔为10秒
klive.keepaliveinterval = 1000 * 10;
WSAIoctl(socket, SIO_KEEPALIVE_VALS, &klive, sizeof(tcp_keepalive), NULL, 0, &cbBytesReturned, NULL, NULL);
由于 keepalive 选项需要为每个连接中的 socket 开启,这不一定是必须的,可能会产生大量无意义的带宽浪费,且 keepalive 选项不能与应用层很好地交互,因此一般实际的服务开发中,还是建议读者在应用层设计自己的心跳包机制。
那么如何设计呢?
从技术来讲:心跳包其实就是一个预先规定好格式的数据包,在程序中启动一个定时器,定时发送即可,这是最简单的实现思路。
但是,如果通信的两端有频繁的数据来往,此时到了下一个发心跳包的时间点了,此时发送一个心跳包。这其实是一个流量的浪费,既然通信双方不断有正常的业务数据包来往,这些数据包本身就可以起到保活作用,为什么还要浪费流量去发送这些心跳包呢?
所以,对于用于保活的心跳包,我们最佳做法是:设置一个上次包时间,每次收数据和发数据时,都更新一下这个包时间,而心跳检测计时器每次检测时,将这个包时间与当前系统时间做一个对比,如果时间间隔大于允许的最大时间间隔(实际开发中根据需求设置成 15 ~ 45 秒不等),则发送一次心跳包。总而言之,就是在与对端之间,没有数据来往达到一定时间间隔时才发送一次心跳包。
发心跳包的伪码示例:
bool CIUSocket::Send()
{
intnSentBytes = 0;
intnRet = 0;
while(true)
{
nRet = ::send(m_hSocket, m_strSendBuf.c_str(), m_strSendBuf.length(), 0);
if(nRet == SOCKET_ERROR)
{
if(::WSAGetLastError() == WSAEWOULDBLOCK)
break;
else
{
LOG_ERROR("Send data error, disconnect server:%s, port:%d.", m_strServer.c_str(), m_nPort);
Close();
returnfalse;
}
}
elseif(nRet < 1)
{
//一旦出现错误就立刻关闭Socket
LOG_ERROR("Send data error, disconnect server:%s, port:%d.", m_strServer.c_str(), m_nPort);
Close();
returnfalse;
}
m_strSendBuf.erase(0, nRet);
if(m_strSendBuf.empty())
break;
::Sleep(1);
}
{
//记录一下最近一次发包时间
std::lock_guard<std::mutex> guard(m_mutexLastDataTime);
m_nLastDataTime = (long)time(NULL);
}
returntrue;
}
bool CIUSocket::Recv()
{
intnRet = 0;
charbuff[10 * 1024];
while(true)
{
nRet = ::recv(m_hSocket, buff, 10 * 1024, 0);
if(nRet == SOCKET_ERROR) //一旦出现错误就立刻关闭Socket
{
if(::WSAGetLastError() == WSAEWOULDBLOCK)
break;
else
{
LOG_ERROR("Recv data error, errorNO=%d.", ::WSAGetLastError());
//Close();
returnfalse;
}
}
elseif(nRet < 1)
{
LOG_ERROR("Recv data error, errorNO=%d.", ::WSAGetLastError());
//Close();
returnfalse;
}
m_strRecvBuf.append(buff, nRet);
::Sleep(1);
}
{
std::lock_guard<std::mutex> guard(m_mutexLastDataTime);
//记录一下最近一次收包时间
m_nLastDataTime = (long)time(NULL);
}
returntrue;
}
voidCIUSocket::RecvThreadProc()
{
LOG_INFO("Recv data thread start...");
intnRet;
//上网方式
DWORDdwFlags;
BOOLbAlive;
while(!m_bStop)
{
//检测到数据则收数据
nRet = CheckReceivedData();
//出错
if(nRet == -1)
{
m_pRecvMsgThread->NotifyNetError();
}
//无数据
elseif(nRet == 0)
{
longnLastDataTime = 0;
{
std::lock_guard<std::mutex> guard(m_mutexLastDataTime);
nLastDataTime = m_nLastDataTime;
}
if(m_nHeartbeatInterval > 0)
{
//当前系统时间与上一次收发数据包的时间间隔超过了m_nHeartbeatInterval
//则发一次心跳包
if(time(NULL) - nLastDataTime >= m_nHeartbeatInterval)
SendHeartbeatPackage();
}
}
//有数据
elseif(nRet == 1)
{
if(!Recv())
{
m_pRecvMsgThread->NotifyNetError();
continue;
}
DecodePackages();
}// end if
}// end while-loop
LOG_INFO("Recv data thread finish...");
}
同理,检测心跳包的一端,应该是在与对端没有数据来往达到一定时间间隔时才做一次心跳检测。
心跳检测一端的伪码示例如下:
voidBusinessSession::send(constchar* pData, intdataLength)
{
boolsent = TcpSession::send(pData, dataLength);
//发送完数据更新下发包时间
updateHeartbeatTime();
}
voidBusinessSession::handlePackge(char* pMsg, intmsgLength, bool& closeSession, std::vector<std::string>& vectorResponse)
{
//对数据合法性进行校验
if(pMsg == NULL || pMsg[0] == 0 || msgLength <= 0 || msgLength > MAX_DATA_LENGTH)
{
//非法刺探请求,不做任何应答,直接关闭连接
closeSession = true;
return;
}
//更新下收包时间
updateHeartbeatTime();
//省略包处理代码...
}
voidBusinessSession::updateHeartbeatTime()
{
std::lock_guard<std::mutex> scoped_guard(m_mutexForlastPackageTime);
m_lastPackageTime = (int64_t)time(nullptr);
}
boolBusinessSession::doHeartbeatCheck()
{
constConfig& cfg = Singleton<Config>::Instance();
int64_t now = (int64_t)time(nullptr);
std::lock_guard<std::mutex> lock_guard(m_mutexForlastPackageTime);
if(now - m_lastPackageTime >= cfg.m_nMaxClientDataInterval)
{
//心跳包检测,超时,关闭连接
LOGE("heartbeat expired, close session");
shutdown();
returntrue;
}
return false;
}
void TcpServer::checkSessionHeartbeat()
{
int64_t now = (int64_t)time(nullptr);
if(now - m_nLastCheckHeartbeatTime >= m_nHeartbeatCheckInterval)
{
m_spSessionManager->checkSessionHeartbeat();
m_nLastCheckHeartbeatTime = (int64_t)time(nullptr);
}
}
voidSessionManager::checkSessionHeartbeat()
{
std::lock_guard<std::mutex> scoped_lock(m_mutexForSession);
for(constauto& iter : m_mapSessions)
{
//这里调用 BusinessSession::doHeartbeatCheck()
iter.second->doHeartbeatCheck();
}
}
需要注意的是:一般是客户端主动给服务器端发送心跳包,服务器端做心跳检测决定是否断开连接,而不是反过来。从客户端的角度来说,客户端为了让自己得到服务器端的正常服务有必要主动和服务器保持连接状态正常,而服务器端不会局限于某个特定的客户端,如果客户端不能主动和其保持连接,那么就会主动回收与该客户端的连接。当然,服务器端在收到客户端的心跳包时应该给客户端一个心跳应答。
上面介绍的心跳包是从纯技术的角度来说的,在实际应用中,有时候我们需要定时或者不定时从服务器端更新一些数据,我们可以把这类数据放在心跳包中,定时或者不定时更新。
这类带业务数据的心跳包,就不再是纯粹技术上的作用了(这里说的技术的作用指的上文中介绍的心跳包起保活和检测死链作用)。
这类心跳包实现也很容易,即在心跳包数据结构里面加上需要的业务字段信息,然后在定时器中定时发送,客户端发给服务器,服务器在应答心跳包中填上约定的业务数据信息即可。
通常情况下,多数应用场景下,与服务器端保持连接的多个客户端中,同一时间段活跃用户(这里指的是与服务器有频繁数据来往的客户端)一般不会太多。当连接数较多时,进出服务器程序的数据包通常都是心跳包(为了保活)。所以为了减轻网络代码压力,节省流量,尤其是针对一些 3/4 G 手机应用,我们在设计心跳包数据格式时应该尽量减小心跳包的数据大小。
如前文所述,对于心跳包,服务器端的逻辑一般是在一定时间间隔内没有收到客户端心跳包时会主动断开连接。在我们开发调试程序过程中,我们可能需要将程序通过断点中断下来,这个过程可能是几秒到几十秒不等。等程序恢复执行时,连接可能因为心跳检测逻辑已经被断开。
调试过程中,我们更多的关注的是业务数据处理的逻辑是否正确,不想被一堆无意义的心跳包数据干扰实线。
鉴于以上两点原因,我们一般在调试模式下关闭或者禁用心跳包检测机制。
代码示例大致如下:
ChatSession::ChatSession(conststd::shared_ptr<TcpConnection>& conn, intsessionid) :
TcpSession(conn),
m_id(sessionid),
m_seq(0),
m_isLogin(false)
{
m_userinfo.userid = 0;
m_lastPackageTime = time(NULL);
//这里设置了非调试模式下才开启心跳包检测功能
#ifndef _DEBUG
EnableHearbeatCheck();
#endif
}
当然,你也可以将开启心跳检测的开关做成配置信息放入程序配置文件中。
实际生产环境,我们一般会将程序收到的和发出去的数据包写入日志中,但是无业务信息的心跳包信息是个例外,一般会刻意不写入日志,这是因为心跳包数据一般比较多,如果写入日志会导致日志文件变得很大,且充斥大量无意义的心跳包日志,所以一般在写日志时会屏蔽心跳包信息写入。
我这里的建议是:可以将心跳包信息是否写入日志做成一个配置开关,一般处于关闭状态,有需要时再开启。
例如,对于一个 WebSocket 服务,ping 和 pong 是心跳包数据,下面示例代码按需输出心跳日志信息:
void BusinessSession::send(std::string _view strResponse)
{
boolsuccess = WebSocketSession::send(strResponse);
if(success)
{
boolenablePingPongLog = Singleton<Config>::Instance().m_bPingPongLogEnabled;
//其他消息正常打印,心跳消息按需打印
if(strResponse != "pong"|| enablePingPongLog)
{
LOGI("msg sent to client [%s], sessionId: %s, session: 0x%0x, clientId: %s, accountId: %s, frontId: %s, msg: %s",
getClientInfo(), m_strSessionId.c_str(), (int64_t)this, m_strClientID.c_str(), m_strAccountID.c_str(), BusinessSession::m_strFrontId.c_str(), strResponse.data());
}
}
}
[1] 有关IM/推送的心跳保活处理:
《应用保活终极总结(一):Android6.0以下的双进程守护保活实践》
《应用保活终极总结(二):Android6.0及以上的保活实践(进程防杀篇)》
《应用保活终极总结(三):Android6.0及以上的保活实践(被杀复活篇)》
《Android进程保活详解:一篇文章解决你的所有疑问》
《Android端消息推送总结:实现原理、心跳保活、遇到的问题等》
《深入的聊聊Android消息推送这件小事》
《为何基于TCP协议的移动端IM仍然需要心跳保活机制?》
《微信团队原创分享:Android版微信后台保活实战分享(进程保活篇)》
《微信团队原创分享:Android版微信后台保活实战分享(网络保活篇)》
《移动端IM实践:实现Android版微信的智能心跳机制》
《移动端IM实践:WhatsApp、Line、微信的心跳策略分析》
《Android P正式版即将到来:后台应用保活、消息推送的真正噩梦》
《全面盘点当前Android后台保活方案的真实运行效果(截止2019年前)》
《一文读懂即时通讯应用中的网络心跳包机制:作用、原理、实现思路等》
>> 更多同类文章 ……
[2] 网络编程基础资料:
《TCP/IP详解-第11章·UDP:用户数据报协议》
《TCP/IP详解-第17章·TCP:传输控制协议》
《TCP/IP详解-第18章·TCP连接的建立与终止》
《TCP/IP详解-第21章·TCP的超时与重传》
《技术往事:改变世界的TCP/IP协议(珍贵多图、手机慎点)》
《通俗易懂-深入理解TCP协议(上):理论基础》
《通俗易懂-深入理解TCP协议(下):RTT、滑动窗口、拥塞处理》
《理论经典:TCP协议的3次握手与4次挥手过程详解》
《理论联系实际:Wireshark抓包分析TCP 3次握手、4次挥手过程》
《计算机网络通讯协议关系图(中文珍藏版)》
《UDP中一个包的大小最大能多大?》
《P2P技术详解(一):NAT详解——详细原理、P2P简介》
《P2P技术详解(二):P2P中的NAT穿越(打洞)方案详解》
《P2P技术详解(三):P2P技术之STUN、TURN、ICE详解》
《通俗易懂:快速理解P2P技术中的NAT穿透原理》
《高性能网络编程(一):单台服务器并发TCP连接数到底可以有多少》
《高性能网络编程(二):上一个10年,著名的C10K并发连接问题》
《高性能网络编程(三):下一个10年,是时候考虑C10M并发问题了》
《高性能网络编程(四):从C10K到C10M高性能网络应用的理论探索》
《高性能网络编程(五):一文读懂高性能网络编程中的I/O模型》
《高性能网络编程(六):一文读懂高性能网络编程中的线程模型》
《不为人知的网络编程(一):浅析TCP协议中的疑难杂症(上篇)》
《不为人知的网络编程(二):浅析TCP协议中的疑难杂症(下篇)》
《不为人知的网络编程(三):关闭TCP连接时为什么会TIME_WAIT、CLOSE_WAIT》
《不为人知的网络编程(四):深入研究分析TCP的异常关闭》
《不为人知的网络编程(五):UDP的连接性和负载均衡》
《不为人知的网络编程(六):深入地理解UDP协议并用好它》
《不为人知的网络编程(七):如何让不可靠的UDP变的可靠?》
《不为人知的网络编程(八):从数据传输层深度解密HTTP》
《网络编程懒人入门(一):快速理解网络通信协议(上篇)》
《网络编程懒人入门(二):快速理解网络通信协议(下篇)》
《网络编程懒人入门(三):快速理解TCP协议一篇就够》
《网络编程懒人入门(四):快速理解TCP和UDP的差异》
《网络编程懒人入门(五):快速理解为什么说UDP有时比TCP更有优势》
《网络编程懒人入门(六):史上最通俗的集线器、交换机、路由器功能原理入门》
《网络编程懒人入门(七):深入浅出,全面理解HTTP协议》
《网络编程懒人入门(八):手把手教你写基于TCP的Socket长连接》
《网络编程懒人入门(九):通俗讲解,有了IP地址,为何还要用MAC地址?》
《技术扫盲:新一代基于UDP的低延时网络传输层协议——QUIC详解》
《让互联网更快:新一代QUIC协议在腾讯的技术实践分享》
《现代移动端网络短连接的优化手段总结:请求速度、弱网适应、安全保障》
《聊聊iOS中网络编程长连接的那些事》
《移动端IM开发者必读(一):通俗易懂,理解移动网络的“弱”和“慢”》
《移动端IM开发者必读(二):史上最全移动弱网络优化方法总结》
《IPv6技术详解:基本概念、应用现状、技术实践(上篇)》
《IPv6技术详解:基本概念、应用现状、技术实践(下篇)》
《从HTTP/0.9到HTTP/2:一文读懂HTTP协议的历史演变和设计思路》
《脑残式网络编程入门(一):跟着动画来学TCP三次握手和四次挥手》
《脑残式网络编程入门(二):我们在读写Socket时,究竟在读写什么?》
《脑残式网络编程入门(三):HTTP协议必知必会的一些知识》
《脑残式网络编程入门(四):快速理解HTTP/2的服务器推送(Server Push)》
《脑残式网络编程入门(五):每天都在用的Ping命令,它到底是什么?》
《脑残式网络编程入门(六):什么是公网IP和内网IP?NAT转换又是什么鬼?》
《以网游服务端的网络接入层设计为例,理解实时通信的技术挑战》
《迈向高阶:优秀Android程序员必知必会的网络基础》
《全面了解移动端DNS域名劫持等杂症:技术原理、问题根源、解决方案等》
《美图App的移动端DNS优化实践:HTTPS请求耗时减小近半》
《Android程序员必知必会的网络通信传输层协议——UDP和TCP》
《IM开发者的零基础通信技术入门(一):通信交换技术的百年发展史(上)》
《IM开发者的零基础通信技术入门(二):通信交换技术的百年发展史(下)》
《IM开发者的零基础通信技术入门(三):国人通信方式的百年变迁》
《IM开发者的零基础通信技术入门(四):手机的演进,史上最全移动终端发展史》
《IM开发者的零基础通信技术入门(五):1G到5G,30年移动通信技术演进史》
《IM开发者的零基础通信技术入门(六):移动终端的接头人——“基站”技术》
《IM开发者的零基础通信技术入门(七):移动终端的千里马——“电磁波”》
《IM开发者的零基础通信技术入门(八):零基础,史上最强“天线”原理扫盲》
《IM开发者的零基础通信技术入门(九):无线通信网络的中枢——“核心网”》
《IM开发者的零基础通信技术入门(十):零基础,史上最强5G技术扫盲》
《IM开发者的零基础通信技术入门(十一):为什么WiFi信号差?一文即懂!》
《IM开发者的零基础通信技术入门(十二):上网卡顿?网络掉线?一文即懂!》
《IM开发者的零基础通信技术入门(十三):为什么手机信号差?一文即懂!》
《IM开发者的零基础通信技术入门(十四):高铁上无线上网有多难?一文即懂!》
《IM开发者的零基础通信技术入门(十五):理解定位技术,一篇就够》
《百度APP移动端网络深度优化实践分享(一):DNS优化篇》
《百度APP移动端网络深度优化实践分享(二):网络连接优化篇》
《百度APP移动端网络深度优化实践分享(三):移动端弱网优化篇》
《技术大牛陈硕的分享:由浅入深,网络编程学习经验干货总结》
《可能会搞砸你的面试:你知道一个TCP连接上能发起多少个HTTP请求吗?》
>>更多同类文章 ……
(本文同步发布于:http://www.52im.net/thread-2697-1-1.html)

Nginx 是开源、高性能、高可靠的 Web 和反向代理服务器,而且支持热部署,几乎可以做到 7 * 24 小时不间断运行,即使运行几个月也不需要重新启动,还能在不间断服务的情况下对软件版本进行热更新。性能是 Nginx 最重要的考量,其占用内存少、并发能力强、能支持高达 5w 个并发连接数,最重要的是, Nginx 是免费的并可以商业化,配置使用也比较简单。
官网对各个模块参数配置的解释说明网址:https://www.nginx.cn/doc/index.htmlNginx中文文档
- 高并发、高性能;
- 模块化架构使得它的扩展性非常好;
- 异步非阻塞的事件驱动模型这点和 Node.js 相似;
- 相对于其它服务器来说它可以连续几个月甚至更长而不需要重启服务器使得它具有高可靠性;
- 热部署、平滑升级;
- 完全开源,生态繁荣;
Nginx 的最重要的几个使用场景:
- 静态资源服务,通过本地文件系统提供服务;
- 反向代理服务,延伸出包括缓存、负载均衡等;
- API 服务, OpenResty ;
对于前端来说 Node.js 并不陌生, Nginx 和 Node.js 的很多理念类似, HTTP 服务器、事件驱动、异步非阻塞等,且 Nginx 的大部分功能使用 Node.js 也可以实现,但 Nginx 和 Node.js 并不冲突,都有自己擅长的领域。 Nginx 擅长于底层服务器端资源的处理(静态资源处理转发、反向代理,负载均衡等), Node.js 更擅长上层具体业务逻辑的处理,两者可以完美组合。
用一张图表示:
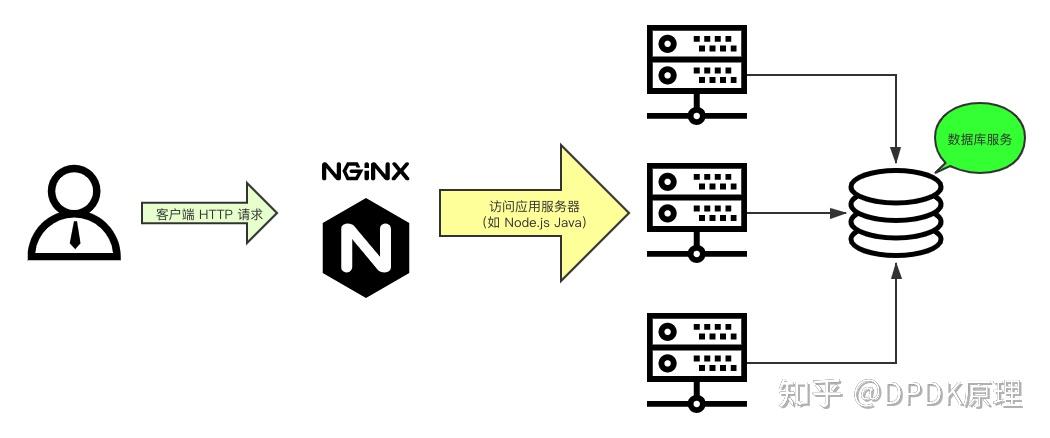
nginx -s reload # 向主进程发送信号,重新加载配置文件,热重启
nginx -s reopen # 重启 Nginx
nginx -s stop # 快速关闭
nginx -s quit # 等待工作进程处理完成后关闭
nginx -T # 查看当前 Nginx 最终的配置
nginx -t # 检查配置是否有问题Nginx 的典型配置示例:
# main段配置信息
user nginx; # 运行用户,默认即是nginx,可以不进行设置
worker_processes auto; # Nginx 进程数,一般设置为和 CPU 核数一样
error_log /var/log/nginx/error.log warn; # Nginx 的错误日志存放目录
pid /var/run/nginx.pid; # Nginx 服务启动时的 pid 存放位置
# events段配置信息
events {
use epoll; # 使用epoll的I/O模型(如果你不知道Nginx该使用哪种轮询方法,会自动选择一个最适合你操作系统的)
worker_connections 1024; # 每个进程允许最大并发数
}
# http段配置信息
# 配置使用最频繁的部分,代理、缓存、日志定义等绝大多数功能和第三方模块的配置都在这里设置
http {
# 设置日志模式
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main; # Nginx访问日志存放位置
sendfile on; # 开启高效传输模式
tcp_nopush on; # 减少网络报文段的数量
tcp_nodelay on;
keepalive_timeout 65; # 保持连接的时间,也叫超时时间,单位秒
types_hash_max_size 2048;
include /etc/nginx/mime.types; # 文件扩展名与类型映射表
default_type application/octet-stream; # 默认文件类型
include /etc/nginx/conf.d/*.conf; # 加载子配置项
# server段配置信息
server {
listen 80; # 配置监听的端口
server_name localhost; # 配置的域名
# location段配置信息
location / {
root /usr/share/nginx/html; # 网站根目录
index index.html index.htm; # 默认首页文件
deny 172.168.22.11; # 禁止访问的ip地址,可以为all
allow 172.168.33.44;# 允许访问的ip地址,可以为all
}
error_page 500 502 503 504 /50x.html; # 默认50x对应的访问页面
error_page 400 404 error.html; # 同上
}
}- main 全局配置,对全局生效;
- events 配置影响 Nginx 服务器与用户的网络连接;
- http 配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置;
- server 配置虚拟主机的相关参数,一个 http 块中可以有多个 server 块;
- location 用于配置匹配的 uri ;
- upstream 配置后端服务器具体地址,负载均衡配置不可或缺的部分;
用一张图清晰的展示它的层级结构:
nginx.conf 配置文件的语法规则:
- 配置文件由指令与指令块构成
- 每条指令以 “;” 分号结尾,指令与参数间以空格符号分隔
- 指令块以 {} 大括号将多条指令组织在一起
- include 语句允许组合多个配置文件以提升可维护性
- 通过 # 符号添加注释,提高可读性
- 通过 $ 符号使用变量
- 部分指令的参数支持正则表达式,例如常用的 location 指令
指定运行 Nginx 的 woker 子进程的属主和属组,其中组可以不指定。
#语法:user USERNAME [GROUP]
user nginx lion; # 用户是nginx;组是lion指定运行 Nginx master 主进程的 pid 文件存放路径。
pid /opt/nginx/logs/nginx.pid # master主进程的的pid存放在nginx.pid的文件指定worker子进程可以打开的最大文件句柄数。
worker_rlimit_nofile 20480; # 可以理解成每个worker子进程的最大连接数量。指定 worker 子进程异常终止后的 core 文件,用于记录分析问题。
worker_rlimit_core 50M; # 存放大小限制
working_directory /opt/nginx/tmp; # 存放目录指定 Nginx 启动的 worker 子进程数量。
worker_processes 4; # 指定具体子进程数量
worker_processes auto; # 与当前cpu物理核心数一致将每个 worker 子进程与我们的 cpu 物理核心绑定。
worker_cpu_affinity 0001 0010 0100 1000; # 4个物理核心,4个worker子进程
将每个 worker 子进程与特定 CPU 物理核心绑定,优势在于,避免同一个 worker 子进程在不同的 CPU 核心上切换,缓存失效,降低性能。但其并不能真正的避免进程切换。
指定 worker 子进程的 nice 值,以调整运行 Nginx 的优先级,通常设定为负值,以优先调用 Nginx 。
worker_priority -10; # 120-10=110,110就是最终的优先级Linux 默认进程的优先级值是120,值越小越优先; nice 值范围为 -20 到 +19 。
备注:应用的默认优先级值是120加上 nice 值等于它最终的值,这个值越小,优先级越高。
指定 worker 子进程优雅退出时的超时时间。
worker_shutdown_timeout 5s;worker 子进程内部使用的计时器精度,调整时间间隔越大,系统调用越少,有利于性能提升;反之,系统调用越多,性能下降。
timer_resolution 100ms;在 Linux 系统中,用户需要获取计时器时需要向操作系统内核发送请求,有请求就必然会有开销,因此这个间隔越大开销就越小。
指定 Nginx 的运行方式,前台还是后台,前台用于调试,后台用于生产。
daemon off; # 默认是on,后台运行模式Nginx 使用何种事件驱动模型。
use method; # 不推荐配置它,让nginx自己选择method 可选值为:select、poll、kqueue、epoll、/dev/poll、eventport
worker 子进程能够处理的最大并发连接数。
worker_connections 1024 # 每个子进程的最大连接数为1024是否打开负载均衡互斥锁。
accept_mutex on # 默认是off关闭的,这里推荐打开指定虚拟主机域名。
#语法:server_name name1 name2 name3
# 示例:
server_name www.nginx.com;域名匹配的四种写法:
- 精确匹配: server_name http://www.nginx.com ;
- 左侧通配: server_name *.http://nginx.com ;
- 右侧统配: server_name www.nginx.* ;
- 正则匹配: server_name ~^www\.nginx\.*$ ;
匹配优先级:精确匹配 > 左侧通配符匹配 > 右侧通配符匹配 > 正则表达式匹配
server_name 配置实例:
1、配置本地 DNS 解析 hosts
# 添加如下内容,其中 121.42.11.34 是阿里云服务器IP地址
121.42.11.34 www.nginx-test.com
121.42.11.34 mail.nginx-test.com
121.42.11.34 www.nginx-test.org
121.42.11.34 doc.nginx-test.com
121.42.11.34 www.nginx-test.cn
121.42.11.34 fe.nginx-test.club注意:这里使用的是虚拟域名进行测试,因此需要配置本地 DNS 解析,如果使用阿里云上购买的域名,则需要在阿里云上设置好域名解析。
2、配置阿里云Nginx,vim /etc/nginx/nginx.conf
# 这里只列举了http端中的sever端配置
# 左匹配
server {
listen 80;
server_name *.nginx-test.com;
root /usr/share/nginx/html/nginx-test/left-match/;
location / {
index index.html;
}
}
# 正则匹配
server {
listen 80;
server_name ~^.*\.nginx-test\..*$;
root /usr/share/nginx/html/nginx-test/reg-match/;
location / {
index index.html;
}
}
# 右匹配
server {
listen 80;
server_name www.nginx-test.*;
root /usr/share/nginx/html/nginx-test/right-match/;
location / {
index index.html;
}
}
# 完全匹配
server {
listen 80;
server_name www.nginx-test.com;
root /usr/share/nginx/html/nginx-test/all-match/;
location / {
index index.html;
}
}3、访问分析
- 当访问 http://www.nginx-test.com 时,都可以被匹配上,因此选择优先级最高的“完全匹配”;
- 当访问 http://mail.nginx-test.com 时,会进行“左匹配”;
- 当访问 http://www.nginx-test.org 时,会进行“右匹配”;
- 当访问 http://doc.nginx-test.com 时,会进行“左匹配”;
- 当访问 http://www.nginx-test.cn 时,会进行“右匹配”;
- 当访问 fe.nginx-test.club 时,会进行“正则匹配”;
指定静态资源目录位置,它可以写在 http 、 server 、 location 等配置中。
#root path
#例如:
location /image {
root /opt/nginx/static;
}
#当用户访问 www.test.com/image/1.png 时,实际在服务器找的路径是 /opt/nginx/static/image/1.png注意:root 会将定义路径与 URI 叠加, alias 则只取定义路径。
它也是指定静态资源目录位置,它只能写在 location 中。
location /image {
alias /opt/nginx/static/image/;
}
#当用户访问 www.test.com/image/1.png 时,实际在服务器找的路径是 /opt/nginx/static/image/1.png注意: 使用 alias 末尾一定要添加 / ,并且它只能位于 location 中。
配置路径。
location [ = | ~ | ~* | ^~ ] uri {
...
}匹配规则:
- = 精确匹配;
- ~ 正则匹配,区分大小写;
- ~* 正则匹配,不区分大小写;
- ^~ 匹配到即停止搜索;
匹配优先级: = > ^~ > ~ > ~* > 不带任何字符。
实例:
server {
listen 80;
server_name www.nginx-test.com;
# 只有当访问 www.nginx-test.com/match_all/ 时才会匹配到/usr/share/nginx/html/match_all/index.html
location = /match_all/ {
root /usr/share/nginx/html
index index.html
}
# 当访问 www.nginx-test.com/1.jpg 等路径时会去 /usr/share/nginx/images/1.jpg 找对应的资源
location ~ \.(jpeg|jpg|png|svg)$ {
root /usr/share/nginx/images;
}
# 当访问 www.nginx-test.com/bbs/ 时会匹配上 /usr/share/nginx/html/bbs/index.html
location ^~ /bbs/ {
root /usr/share/nginx/html;
index index.html index.htm;
}
}location /test {
...
}
location /test/ {
...
}- 不带 / 当访问 http://www.nginx-test.com/test 时, Nginx 先找是否有 test 目录,如果有则找 test 目录下的 index.html ;如果没有 test 目录, nginx 则会找是否有 test 文件。
- 带 / 当访问 http://www.nginx-test.com/test 时, Nginx 先找是否有 test 目录,如果有则找 test 目录下的 index.html ,如果没有它也不会去找是否存在 test 文件。
停止处理请求,直接返回响应码或重定向到其他 URL ;执行 return 指令后, location 中后续指令将不会被执行。
#return code [text];
#return code URL;
#return URL;
#例如:
location / {
return 404; # 直接返回状态码
}
location / {
return 404 "pages not found"; # 返回状态码 + 一段文本
}
location / {
return 302 /bbs ; # 返回状态码 + 重定向地址
}
location / {
return https://www.baidu.com ; # 返回重定向地址
}根据指定正则表达式匹配规则,重写 URL 。
#语法:rewrite 正则表达式 要替换的内容 [flag];
#上下文(标签):server、location、if
#示例:rewirte /images/(.*\.jpg)$ /pic/$1; # $1是前面括号(.*\.jpg)的反向引用flag 可选值的含义:
- last 重写后的 URL 发起新请求,再次进入 server 段,重试 location 的中的匹配;
- break 直接使用重写后的 URL ,不再匹配其它 location 中语句;
- redirect 返回302临时重定向;
- permanent 返回301永久重定向;
server{
listen 80;
server_name fe.lion.club; # 要在本地hosts文件进行配置
root html;
location /search {
rewrite ^/(.*) https://www.baidu.com redirect;
}
location /images {
rewrite /images/(.*) /pics/$1;
}
location /pics {
rewrite /pics/(.*) /photos/$1;
}
location /photos {
}
}按照这个配置我们来分析:
- 当访问 fe.lion.club/search 时,会自动帮我们重定向到 https://www.baidu.com。
- 当访问 fe.lion.club/images/1.jpg 时,第一步重写 URL 为 fe.lion.club/pics/1.jpg ,找到 pics 的 location ,继续重写 URL 为 fe.lion.club/photos/1.jpg ,找到 /photos 的 location 后,去 html/photos 目录下寻找 1.jpg 静态资源。
#语法:if (condition) {...}
#上下文:server、location
#示例:
if($http_user_agent ~ Chrome){
rewrite /(.*)/browser/$1 break;
}condition 判断条件:
- $variable 仅为变量时,值为空或以0开头字符串都会被当做 false 处理;
- = 或 != 相等或不等;
- ~ 正则匹配;
- ! ~ 非正则匹配;
- ~* 正则匹配,不区分大小写;
- -f 或 ! -f 检测文件存在或不存在;
- -d 或 ! -d 检测目录存在或不存在;
- -e 或 ! -e 检测文件、目录、符号链接等存在或不存在;
- -x 或 ! -x 检测文件可以执行或不可执行;
实例:
server {
listen 8080;
server_name localhost;
root html;
location / {
if ( $uri = "/images/" ){
rewrite (.*) /pics/ break;
}
}
}当访问 localhost:8080/images/ 时,会进入 if 判断里面执行 rewrite 命令。
用户请求以 / 结尾时,列出目录结构,可以用于快速搭建静态资源下载网站。
autoindex.conf 配置信息:
server {
listen 80;
server_name fe.lion-test.club;
location /download/ {
root /opt/source;
autoindex on; # 打开 autoindex,,可选参数有 on | off
autoindex_exact_size on; # 修改为off,以KB、MB、GB显示文件大小,默认为on,以bytes显示出⽂件的确切⼤⼩
autoindex_format html; # 以html的方式进行格式化,可选参数有 html | json | xml
autoindex_localtime off; # 显示的⽂件时间为⽂件的服务器时间。默认为off,显示的⽂件时间为GMT时间
}
}当访问 http://fe.lion.com/download/ 时,会把服务器 /opt/source/download/ 路径下的文件展示出来,如下图所示:

nginx 常用的内置全局变量,你可以在配置中随意使用:

实例演示:
server{
listen 8081;
server_name var.lion-test.club;
root /usr/share/nginx/html;
location / {
return 200 "
remote_addr: $remote_addr
remote_port: $remote_port
server_addr: $server_addr
server_port: $server_port
server_protocol: $server_protocol
binary_remote_addr: $binary_remote_addr
connection: $connection
uri: $uri
request_uri: $request_uri
scheme: $scheme
request_method: $request_method
request_length: $request_length
args: $args
arg_pid: $arg_pid
is_args: $is_args
query_string: $query_string
host: $host
http_user_agent: $http_user_agent
http_referer: $http_referer
http_via: $http_via
request_time: $request_time
https: $https
request_filename: $request_filename
document_root: $document_root
";
}
}当我们访问 http://var.lion-test.club:8081/test?pid=121414&cid=sadasd 时,由于 Nginx 中写了 return 方法,因此 chrome 浏览器会默认为我们下载一个文件,下面展示的就是下载的文件内容:
remote_addr: 27.16.220.84
remote_port: 56838
server_addr: 172.17.0.2
server_port: 8081
server_protocol: HTTP/1.1
binary_remote_addr: 茉
connection: 126
uri: /test/
request_uri: /test/?pid=121414&cid=sadasd
scheme: http
request_method: GET
request_length: 518
args: pid=121414&cid=sadasd
arg_pid: 121414
is_args: ?
query_string: pid=121414&cid=sadasd
host: var.lion-test.club
http_user_agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36
http_referer:
http_via:
request_time: 0.000
https:
request_filename: /usr/share/nginx/html/test/
document_root: /usr/share/nginx/html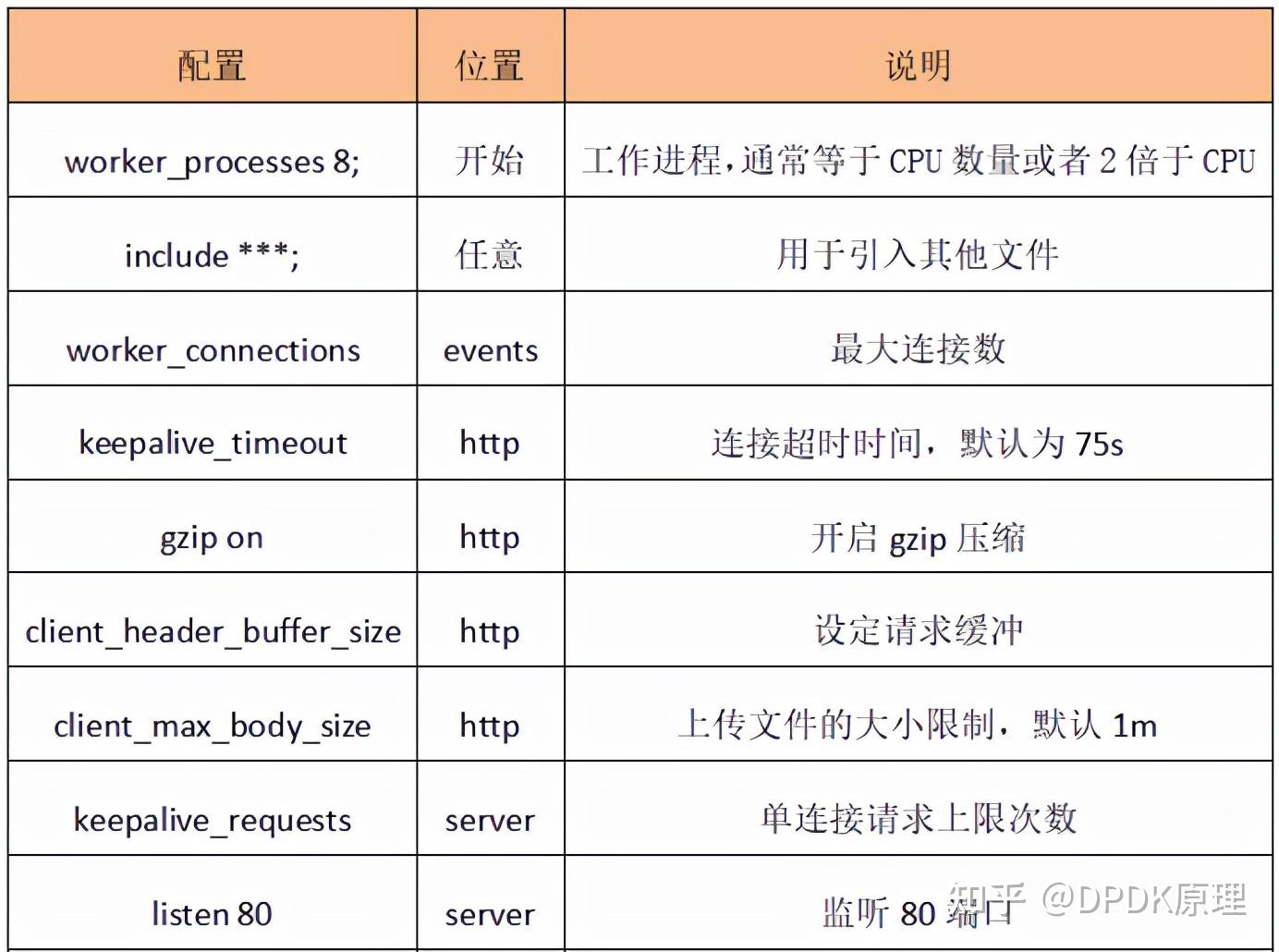
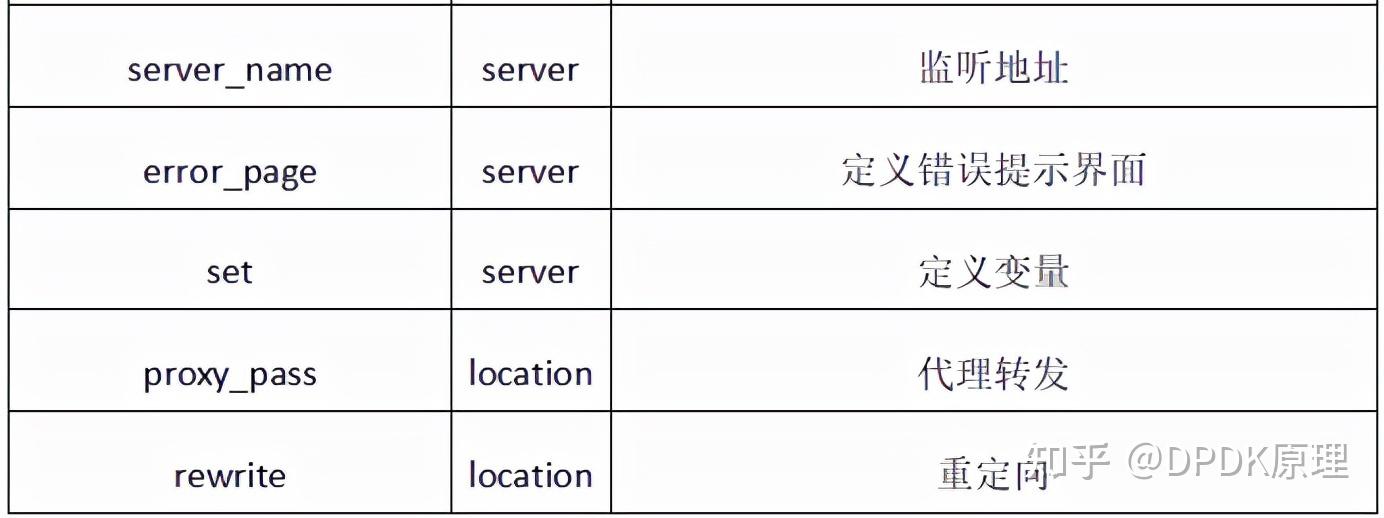
代理是在服务器和客户端之间假设的一层服务器,代理将接收客户端的请求并将它转发给服务器,然后将服务端的响应转发给客户端。
不管是正向代理还是反向代理,实现的都是上面的功能。
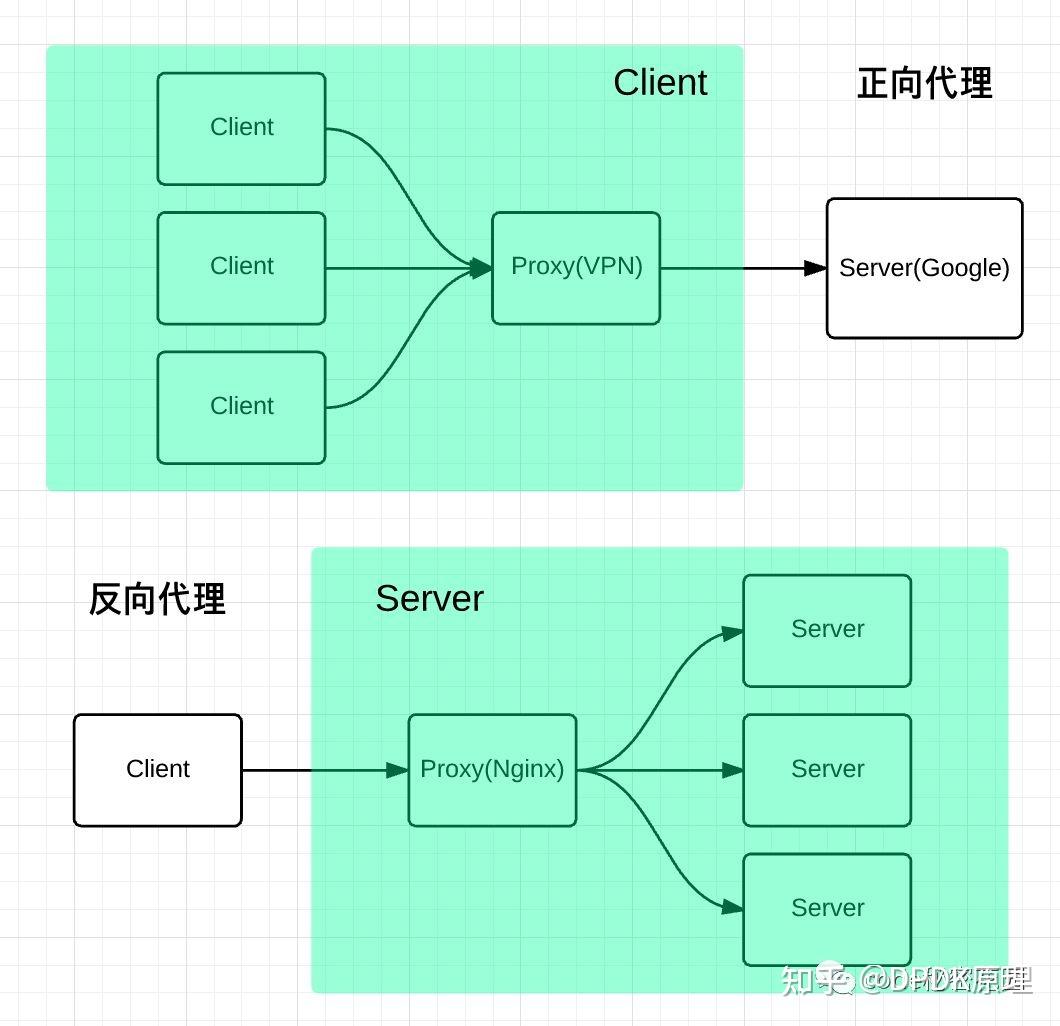
正向代理,意思是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。
正向代理是为我们服务的,即为客户端服务的,客户端可以根据正向代理访问到它本身无法访问到的服务器资源。
正向代理对我们是透明的,对服务端是非透明的,即服务端并不知道自己收到的是来自代理的访问还是来自真实客户端的访问。
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
反向代理是为服务端服务的,反向代理可以帮助服务器接收来自客户端的请求,帮助服务器做请求转发,负载均衡等。
反向代理对服务端是透明的,对我们是非透明的,即我们并不知道自己访问的是代理服务器,而服务器知道反向代理在为它服务。
反向代理的优势:
- 隐藏真实服务器;
- 负载均衡便于横向扩充后端动态服务;
- 动静分离,提升系统健壮性;
那么“动静分离”是什么?负载均衡又是什么?
动静分离是指在 web 服务器架构中,将静态页面与动态页面或者静态内容接口和动态内容接口分开不同系统访问的架构设计方法,进而提示整个服务的访问性和可维护性。
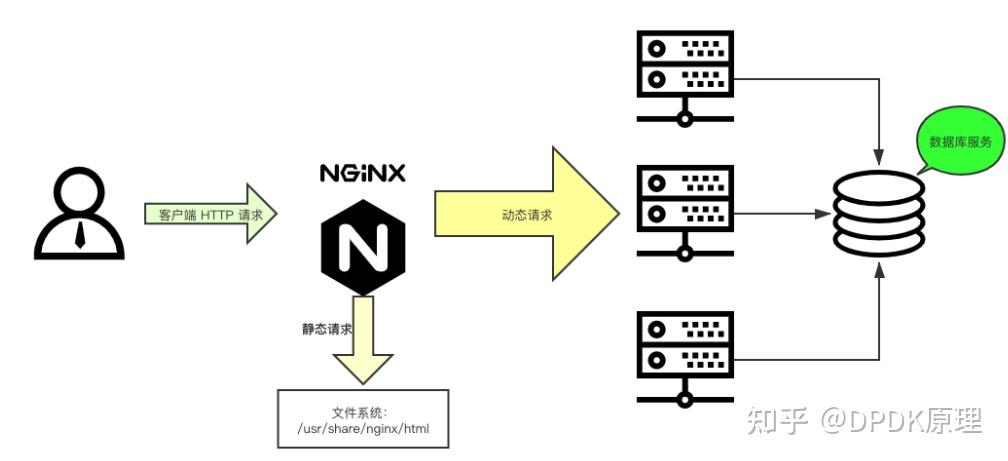
一般来说,都需要将动态资源和静态资源分开,由于 Nginx 的高并发和静态资源缓存等特性,经常将静态资源部署在 Nginx 上。如果请求的是静态资源,直接到静态资源目录获取资源,如果是动态资源的请求,则利用反向代理的原理,把请求转发给对应后台应用去处理,从而实现动静分离。
使用前后端分离后,可以很大程度提升静态资源的访问速度,即使动态服务不可用,静态资源的访问也不会受到影响。
一般情况下,客户端发送多个请求到服务器,服务器处理请求,其中一部分可能要操作一些资源比如数据库、静态资源等,服务器处理完毕后,再将结果返回给客户端。
这种模式对于早期的系统来说,功能要求不复杂,且并发请求相对较少的情况下还能胜任,成本也低。随着信息数量不断增长,访问量和数据量飞速增长,以及系统业务复杂度持续增加,这种做法已无法满足要求,并发量特别大时,服务器容易崩。
很明显这是由于服务器性能的瓶颈造成的问题,除了堆机器之外,最重要的做法就是负载均衡。
请求爆发式增长的情况下,单个机器性能再强劲也无法满足要求了,这个时候集群的概念产生了,单个服务器解决不了的问题,可以使用多个服务器,然后将请求分发到各个服务器上,将负载分发到不同的服务器,这就是负载均衡,核心是「分摊压力」。 Nginx 实现负载均衡,一般来说指的是将请求转发给服务器集群。
举个具体的例子,晚高峰乘坐地铁的时候,入站口经常会有地铁工作人员大喇叭“请走 B 口, B 口人少车空....”,这个工作人员的作用就是负载均衡。
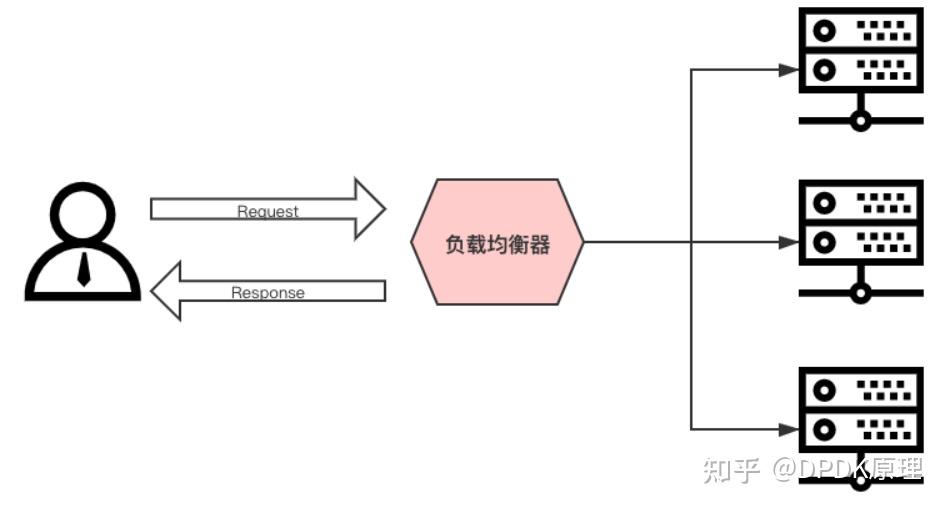
Nginx 实现负载均衡的策略:
- 轮询策略:默认情况下采用的策略,将所有客户端请求轮询分配给服务端。这种策略是可以正常工作的,但是如果其中某一台服务器压力太大,出现延迟,会影响所有分配在这台服务器下的用户。
- 最小连接数策略:将请求优先分配给压力较小的服务器,它可以平衡每个队列的长度,并避免向压力大的服务器添加更多的请求。
- 最快响应时间策略:优先分配给响应时间最短的服务器。
- 客户端 ip 绑定策略:来自同一个 ip 的请求永远只分配一台服务器,有效解决了动态网页存在的 session 共享问题。
用于定义上游服务器(指的就是后台提供的应用服务器)的相关信息。
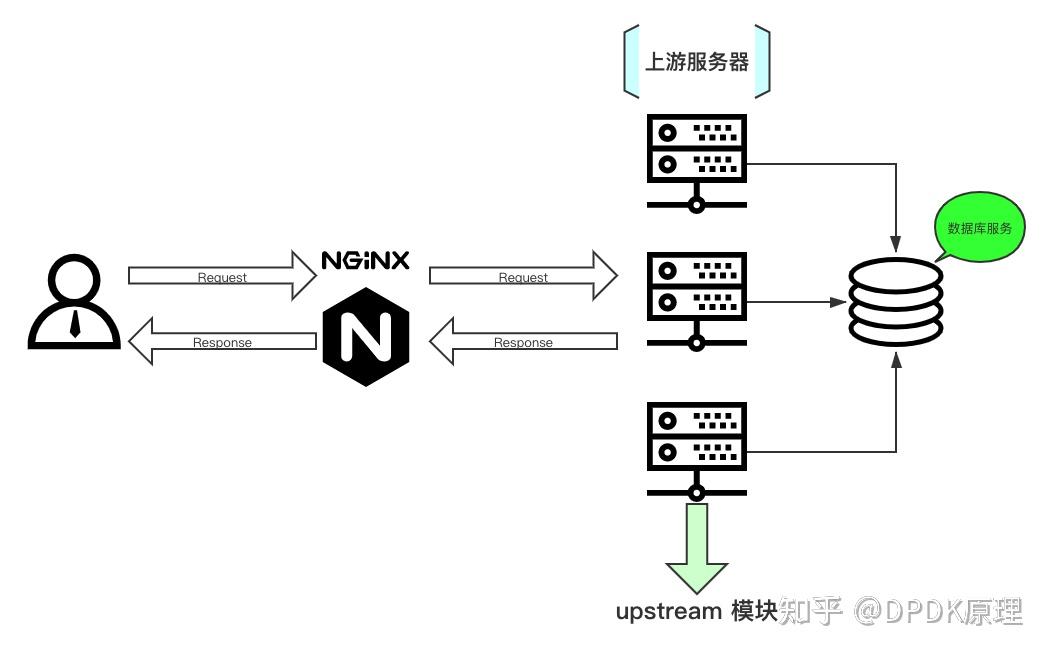
语法:upstream name {
...
}
上下文:http
示例:
upstream back_end_server{
server 192.168.100.33:8081
}在 upstream 内可使用的指令:
- server 定义上游服务器地址;
- zone 定义共享内存,用于跨 worker 子进程;
- keepalive 对上游服务启用长连接;
- keepalive_requests 一个长连接最多请求 HTTP 的个数;
- keepalive_timeout 空闲情形下,一个长连接的超时时长;
- hash 哈希负载均衡算法;
- ip_hash 依据 IP 进行哈希计算的负载均衡算法;
- least_conn 最少连接数负载均衡算法;
- least_time 最短响应时间负载均衡算法;
- random 随机负载均衡算法;
定义上游服务器地址。
语法:server address [parameters]
上下文:upstreamparameters 可选值:
- weight=number 权重值,默认为1;
- max_conns=number 上游服务器的最大并发连接数;
- fail_timeout=time 服务器不可用的判定时间;
- max_fails=numer 服务器不可用的检查次数;
- backup 备份服务器,仅当其他服务器都不可用时才会启用;
- down 标记服务器长期不可用,离线维护;
限制每个 worker 子进程与上游服务器空闲长连接的最大数量。
keepalive connections;
上下文:upstream
示例:keepalive 16;单个长连接可以处理的最多 HTTP 请求个数。
语法:keepalive_requests number;
默认值:keepalive_requests 100;
上下文:upstream空闲长连接的最长保持时间。
语法:keepalive_timeout time;
默认值:keepalive_timeout 60s;
上下文:upstream【文章福利】:C/C++Linux服务器开发/后台架构师【公开课学习】(C/C++,Linux,golang技术,内核,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg,大厂面试题 等)有需要的可以点击793599096加群领取哦~

upstream back_end{
server 127.0.0.1:8081 weight=3 max_conns=1000 fail_timeout=10s max_fails=2;
keepalive 32;
keepalive_requests 50;
keepalive_timeout 30s;
}用于配置代理服务器。
语法:proxy_pass URL;
上下文:location、if、limit_except
示例:
proxy_pass http://127.0.0.1:8081
proxy_pass http://127.0.0.1:8081/proxyURL 参数原则:
- URL 必须以 http 或 https 开头;
- URL 中可以携带变量;
- URL 中是否带 URI ,会直接影响发往上游请求的 URL ;
接下来让我们来看看两种常见的 URL 用法:
- proxy_pass http://192.168.100.33:8081
- proxy_pass http://192.168.100.33:8081/
这两种用法的区别就是带 / 和不带 / ,在配置代理时它们的区别可大了:
- 不带 / 意味着 Nginx 不会修改用户 URL ,而是直接透传给上游的应用服务器;
- 带 / 意味着 Nginx 会修改用户 URL ,修改方法是将 location 后的 URL 从用户 URL 中删除;
不带 / 的用法:
location /bbs/{
proxy_pass http://127.0.0.1:8080;
}分析:
- 用户请求 URL:/bbs/abc/test.html
- 请求到达 Nginx 的 URL:/bbs/abc/test.html
- 请求到达上游应用服务器的 URL:/bbs/abc/test.html
带 / 的用法:
location /bbs/{
proxy_pass http://127.0.0.1:8080/;
}分析:
- 用户请求 URL: /bbs/abc/test.html
- 请求到达 Nginx 的 URL: /bbs/abc/test.html
- 请求到达上游应用服务器的URL: /abc/test.html
并没有拼接上 /bbs ,这点和 root 与 alias 之间的区别是保持一致的。
这里为了演示更加接近实际,作者准备了两台云服务器,它们的公网 IP 分别是:121.42.11.34 与 121.5.180.193 。
我们把 121.42.11.34 服务器作为上游服务器,做如下配置:
# /etc/nginx/conf.d/proxy.conf
server{
listen 8080;
server_name localhost;
location /proxy/ {
root /usr/share/nginx/html/proxy;
index index.html;
}
}
# /usr/share/nginx/html/proxy/index.html
<h1> 121.42.11.34 proxy html </h1>配置完成后重新加载配置文件 nginx -s reload 。
把 121.5.180.193 服务器作为代理服务器,做如下配置:
# /etc/nginx/conf.d/proxy.conf
upstream back_end {
server 121.42.11.34:8080 weight=2 max_conns=1000 fail_timeout=10s max_fails=3;
keepalive 32;
keepalive_requests 80;
keepalive_timeout 20s;
}
server {
listen 80;
server_name proxy.lion.club;
location /proxy {
proxy_pass http://back_end/proxy;
}
}本地机器要访问 proxy.lion.club 域名,因此需要配置本地 hosts ,通过命令:vim /etc/hosts 进入配置文件,添加如下内容:
121.5.180.193 proxy.lion.club
分析:
- 当访问 proxy.lion.club/proxy 时通过 upstream 的配置找到 121.42.11.34:8080 ;
- 因此访问地址变为 http://121.42.11.34:8080/proxy ;
- 连接到 121.42.11.34 服务器,找到 8080 端口提供的 server ;
- 通过 server 找到 /usr/share/nginx/html/proxy/index.html 资源,最终展示出来。
配置负载均衡主要是要使用 upstream 指令。
我们把 121.42.11.34 服务器作为上游服务器,做如下配置:
server{
listen 8020;
location / {
return 200 'return 8020 \n';
}
}
server{
listen 8030;
location / {
return 200 'return 8030 \n';
}
}
server{
listen 8040;
location / {
return 200 'return 8040 \n';
}
}把 121.5.180.193 服务器作为代理服务器,做如下配置:
upstream demo_server {
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}配置完成后重启 Nginx 服务器。并且在需要访问的客户端配置好 ip 和域名的映射关系。
# /etc/hosts
121.5.180.193 balance.lion.club在客户端机器执行 curl http://balance.lion.club/balance/ 命令:
不难看出,负载均衡的配置已经生效了,每次给我们分发的上游服务器都不一样。就是通过简单的轮询策略进行上游服务器分发。
接下来,我们再来了解下 Nginx 的其它分发策略。
通过指定关键字作为 hash key ,基于 hash 算法映射到特定的上游服务器中。关键字可以包含有变量、字符串。
upstream demo_server {
hash $request_uri;
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}hash $request_uri 表示使用 request_uri 变量作为 hash 的 key 值,只要访问的 URI 保持不变,就会一直分发给同一台服务器。
根据客户端的请求 ip 进行判断,只要 ip 地址不变就永远分配到同一台主机。它可以有效解决后台服务器 session 保持的问题。
upstream demo_server {
ip_hash;
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}各个 worker 子进程通过读取共享内存的数据,来获取后端服务器的信息。来挑选一台当前已建立连接数最少的服务器进行分配请求。
语法:least_conn;
上下文:upstream;示例:
upstream demo_server {
zone test 10M; # zone可以设置共享内存空间的名字和大小
least_conn;
server 121.42.11.34:8020;
server 121.42.11.34:8030;
server 121.42.11.34:8040;
}
server {
listen 80;
server_name balance.lion.club;
location /balance/ {
proxy_pass http://demo_server;
}
}缓存可以非常有效的提升性能,因此不论是客户端(浏览器),还是代理服务器( Nginx ),乃至上游服务器都多少会涉及到缓存。可见缓存在每个环节都是非常重要的。下面让我们来学习 Nginx 中如何设置缓存策略。
存储一些之前被访问过、而且可能将要被再次访问的资源,使用户可以直接从代理服务器获得,从而减少上游服务器的压力,加快整个访问速度。
语法:proxy_cache zone | off ; # zone 是共享内存的名称
默认值:proxy_cache off;
上下文:http、server、location设置缓存文件的存放路径。
语法:proxy_cache_path path [level=levels] ...可选参数省略,下面会详细列举
默认值:proxy_cache_path off
上下文:http参数含义:
- path 缓存文件的存放路径;
- level path的目录层级;
- keys_zone 设置共享内存;
- inactive 在指定时间内没有被访问,缓存会被清理,默认10分钟;
设置缓存文件的 key 。
语法:proxy_cache_key
默认值:proxy_cache_key $scheme$proxy_host$request_uri;
上下文:http、server、location配置什么状态码可以被缓存,以及缓存时长。
语法:proxy_cache_valid [code...] time;
上下文:http、server、location
配置示例:proxy_cache_valid 200 304 2m;; # 说明对于状态为200和304的缓存文件的缓存时间是2分钟定义相应保存到缓存的条件,如果字符串参数的至少一个值不为空且不等于“ 0”,则将不保存该响应到缓存。
语法:proxy_no_cache string;
上下文:http、server、location
示例:proxy_no_cache $http_pragma $http_authorization;定义条件,在该条件下将不会从缓存中获取响应。
语法:proxy_cache_bypass string;
上下文:http、server、location
示例:proxy_cache_bypass $http_pragma $http_authorization;它存储了缓存是否命中的信息,会设置在响应头信息中,在调试中非常有用。
MISS: 未命中缓存
HIT: 命中缓存
EXPIRED: 缓存过期
STALE: 命中了陈旧缓存
REVALIDDATED: Nginx验证陈旧缓存依然有效
UPDATING: 内容陈旧,但正在更新
BYPASS: X响应从原始服务器获取我们把 121.42.11.34 服务器作为上游服务器,做如下配置:
server {
listen 1010;
root /usr/share/nginx/html/1010;
location / {
index index.html;
}
}
server {
listen 1020;
root /usr/share/nginx/html/1020;
location / {
index index.html;
}
}把 121.5.180.193 服务器作为代理服务器,做如下配置:
proxy_cache_path /etc/nginx/cache_temp levels=2:2 keys_zone=cache_zone:30m max_size=2g inactive=60m use_temp_path=off;
upstream cache_server{
server 121.42.11.34:1010;
server 121.42.11.34:1020;
}
server {
listen 80;
server_name cache.lion.club;
location / {
proxy_cache cache_zone; # 设置缓存内存,上面配置中已经定义好的
proxy_cache_valid 200 5m; # 缓存状态为200的请求,缓存时长为5分钟
proxy_cache_key $request_uri; # 缓存文件的key为请求的URI
add_header Nginx-Cache-Status $upstream_cache_status # 把缓存状态设置为头部信息,响应给客户端
proxy_pass http://cache_server; # 代理转发
}
}缓存就是这样配置,我们可以在 /etc/nginx/cache_temp 路径下找到相应的缓存文件。
对于一些实时性要求非常高的页面或数据来说,就不应该去设置缓存,下面来看看如何配置不缓存的内容。
...
server {
listen 80;
server_name cache.lion.club;
# URI 中后缀为 .txt 或 .text 的设置变量值为 "no cache"
if ($request_uri ~ \.(txt|text)$) {
set $cache_name "no cache"
}
location / {
proxy_no_cache $cache_name; # 判断该变量是否有值,如果有值则不进行缓存,如果没有值则进行缓存
proxy_cache cache_zone; # 设置缓存内存
proxy_cache_valid 200 5m; # 缓存状态为200的请求,缓存时长为5分钟
proxy_cache_key $request_uri; # 缓存文件的key为请求的URI
add_header Nginx-Cache-Status $upstream_cache_status # 把缓存状态设置为头部信息,响应给客户端
proxy_pass http://cache_server; # 代理转发
}
}在学习如何配置 HTTPS 之前,我们先来简单回顾下 HTTPS 的工作流程是怎么样的?它是如何进行加密保证安全的?
- 客户端(浏览器)访问 https://www.baidu.com 百度网站;
- 百度服务器返回 HTTPS 使用的 CA 证书;
- 浏览器验证 CA 证书是否为合法证书;
- 验证通过,证书合法,生成一串随机数并使用公钥(证书中提供的)进行加密;
- 发送公钥加密后的随机数给百度服务器;
- 百度服务器拿到密文,通过私钥进行解密,获取到随机数(公钥加密,私钥解密,反之也可以);
- 百度服务器把要发送给浏览器的内容,使用随机数进行加密后传输给浏览器;
- 此时浏览器可以使用随机数进行解密,获取到服务器的真实传输内容;
这就是 HTTPS 的基本运作原理,使用对称加密和非对称机密配合使用,保证传输内容的安全性。
关于HTTPS更多知识,可以查看另外一篇文章《学习 HTTP 协议》。
下载证书的压缩文件,里面有个 Nginx 文件夹,把 xxx.crt 和 xxx.key 文件拷贝到服务器目录,再进行如下配置:
server {
listen 443 ssl http2 default_server; # SSL 访问端口号为 443
server_name lion.club; # 填写绑定证书的域名(我这里是随便写的)
ssl_certificate /etc/nginx/https/lion.club_bundle.crt; # 证书地址
ssl_certificate_key /etc/nginx/https/lion.club.key; # 私钥地址
ssl_session_timeout 10m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2; # 支持ssl协议版本,默认为后三个,主流版本是[TLSv1.2]
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
}同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。通常不允许不同源间的读操作。
如果两个页面的协议,端口(如果有指定)和域名都相同,则两个页面具有相同的源。
下面给出了与 URL http://store.company.com/dir/page.html 的源进行对比的示例:
http://store.company.com/dir2/other.html 同源
https://store.company.com/secure.html 不同源,协议不同
http://store.company.com:81/dir/etc.html 不同源,端口不同
http://news.company.com/dir/other.html 不同源,主机不同不同源会有如下限制:
- Web 数据层面,同源策略限制了不同源的站点读取当前站点的 Cookie 、 IndexDB 、 LocalStorage 等数据。
- DOM 层面,同源策略限制了来自不同源的 JavaScript 脚本对当前 DOM 对象读和写的操作。
- 网络层面,同源策略限制了通过 XMLHttpRequest 等方式将站点的数据发送给不同源的站点。
例如:
- 前端 server 的域名为: http://fe.server.com
- 后端服务的域名为: http://dev.server.com
现在我在 http://fe.server.com 对 http://dev.server.com 发起请求一定会出现跨域。
现在我们只需要启动一个 Nginx 服务器,将 server_name 设置为 http://fe.server.com 然后设置相应的 location 以拦截前端需要跨域的请求,最后将请求代理回 http://dev.server.com 。如下面的配置:
server {
listen 80;
server_name fe.server.com;
location / {
proxy_pass dev.server.com;
}
}这样可以完美绕过浏览器的同源策略: http://fe.server.com 访问 Nginx 的 http://fe.server.com 属于同源访问,而 Nginx 对服务端转发的请求不会触发浏览器的同源策略。
GZIP 是规定的三种标准 HTTP 压缩格式之一。目前绝大多数的网站都在使用 GZIP 传输 HTML 、CSS 、 JavaScript 等资源文件。
对于文本文件, GZiP 的效果非常明显,开启后传输所需流量大约会降至 1/4~1/3 。
并不是每个浏览器都支持 gzip 的,如何知道客户端是否支持 gzip 呢,请求头中的 Accept-Encoding 来标识对压缩的支持。
启用 gzip 同时需要客户端和服务端的支持,如果客户端支持 gzip 的解析,那么只要服务端能够返回 gzip 的文件就可以启用 gzip 了,我们可以通过 Nginx 的配置来让服务端支持 gzip 。下面的 respone 中 content-encoding:gzip ,指服务端开启了 gzip 的压缩方式。
# # 默认off,是否开启gzip
gzip on;
# 要采用 gzip 压缩的 MIME 文件类型,其中 text/html 被系统强制启用;
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript;
# ---- 以上两个参数开启就可以支持Gzip压缩了 ---- #
# 默认 off,该模块启用后,Nginx 首先检查是否存在请求静态文件的 gz 结尾的文件,如果有则直接返回该 .gz 文件内容;
gzip_static on;
# 默认 off,nginx做为反向代理时启用,用于设置启用或禁用从代理服务器上收到相应内容 gzip 压缩;
gzip_proxied any;
# 用于在响应消息头中添加 Vary:Accept-Encoding,使代理服务器根据请求头中的 Accept-Encoding 识别是否启用 gzip 压缩;
gzip_vary on;
# gzip 压缩比,压缩级别是 1-9,1 压缩级别最低,9 最高,级别越高压缩率越大,压缩时间越长,建议 4-6;
gzip_comp_level 6;
# 获取多少内存用于缓存压缩结果,16 8k 表示以 8k*16 为单位获得;
gzip_buffers 16 8k;
# 允许压缩的页面最小字节数,页面字节数从header头中的 Content-Length 中进行获取。默认值是 0,不管页面多大都压缩。建议设置成大于 1k 的字节数,小于 1k 可能会越压越大;
# gzip_min_length 1k;
# 默认 1.1,启用 gzip 所需的 HTTP 最低版本;
gzip_http_version 1.1;如果把局域网外的Internet想象成一个巨大的资源库,则局域网中的客户端要访问Internet,则需要通过代理服务器来访问,这种代理服务就称为正向代理。
Nginx正向代理涉及到的指令较少,下面直接贴上其配置文件内容:
...
server {
resolver 192.168.1.1; #指定DNS服务器IP地址
listen 8080;
location / {
proxy_pass http://$http_host$request_uri; #设定代理服务器的协议和地址
}
}
...其中:
resolver 必须的,表示DNS服务器
location 表示匹配用户访问的资源,并作进一步转交和处理,可用正则表达式匹配
proxy_pass 表示需要代理的地址
$http_host 表示用户访问资源的主机部分
$request_uri 表示用户访问资源的URI部分。
如,http://nginx.org/download/nginx-1.6.3.tar.gz,则$http_host=http://nginx.org,$request_uri=/download/nginx-1.6.3.tar.gz。
可以不设置监听端口号,nginx默认监听80端口,除非你要修改监听端口,可以用listen字段指定。
可以看出,对于正向代理,只是对用户的访问进行一个转发,不做其他处理。
Nginx利用deny和allow指令来实现黑白名单的配置,利用黑白名单进行安全配置。
#语法
allow address | CIDR | all;
deny address | CIDR | all;
#模块:http/server/location
#参数说明:
#allow:允许访问。
#deny:禁止访问。
#address:具体的ip地址。
#CIDR:ip加掩码形式地址。
#all:所有ip地址。1、黑名单

在这个配置下,234、235和236的ip访问不了服务器,会显示403 Forbidden,而其他ip都可以访问。
2、白名单
配置策略:白名单配置逻辑是配置允许的ip访问,禁止其他所有的地址访问。

配置详解:在这个配置下,234、235和236的ip可以访问服务器,而其他所有ip都不允许访问,显示403 Forbidden。
location ^~ /project/deny.txt {
alias /webroot/proj/;
deny all;
}- ^~ /project/ 意思是接受从外部访问(如浏览器)的 URL 地址,比如http://www.domain.com/project;
- ^~ /project/deny.txt 意思是这一条 location 明确是对其起作用的;
- alias /webroot/proj/ 意思是将 对 /project 的访问解析到 /webroot/proj 目录;
- deny all 意思是屏蔽任何来源
也可以把 deny all 改换成 return 404,这样将返回 404 而不是 403 Forbidden,更有“欺骗性”。
一般是Nginx + Keepalived来实现Nginx的高可用。
Keepalived是一个免费开源的,用C编写的类似于layer3, 4 & 7交换机制软件,具备我们平时说的第3层、第4层和第7层交换机的功能。主要提供loadbalancing(负载均衡)和 high-availability(高可用)功能,负载均衡实现需要依赖Linux的虚拟服务内核模块(ipvs),而高可用是通过VRRP协议实现多台机器之间的故障转移服务。
Keepalived的所有功能是配置keepalived.conf文件来实现的。
配置优化 – NGINX.CONF
- 本文作者: 百里浅暮
- 本文链接: https://www.cnblogs.com/xfeiyun/p/15877678.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/48034.html