
非常感谢邀请,但是只上过第二个,其他的也不太清楚。刚刚大三,下学期才修操作系统,因此无法给出特别好的解答,非常抱歉了!
Computer Organization is realisation of what is specified by the computer architecture. It deals with how operational attributes are linked together to meet the requirements specified by computer architecture.Some organizational attributes are hardware details, control signals, peripherals.
Computer Architecture deals with giving operational attributes of the computer or Processor to be specific. It deals with details like physical memory, ISA of the processor, the no of bits used to represent the data types, Input Output mechanism and technique for addressing memories.
Example:
Say you are constructing a house, design and all low-level details come under computer architecture while building it brick by brick, connecting together keeping basic architecture in mind comes under computer organization
Architecture refers to the attributes of a computer that are visible to the programmer including
-instruction set
-The number of bites used to represent various data types
-I/O mechanism
-memory addressing modes, etc
Organization refers to the operational unites of a computer and their interconnections that realize the architectural specifications. These include
-Control system
-interfaces between the computer and its peripherals
-memory technology used, etc
组成原理关键在cpu和计算机是怎么设计的,cpu中的控制器和机器指令怎么设计的。不考虑性能,只考虑原理,硬件如何设计,机器指令如何设计,不具体特指某一个CPU,同时也涉及存储器的层次结构原理。
体系结构关键在如何设计cpu性能会更高,如何设计指令性能更高,如何设计计算机系统性能更高。
微机原理关键是使用和学习某个已经设计好的cpu(x86,ARM,MIPS,POWERPC等架构),如何设计具体的应用系统,包括汇编语言的学习。
接口技术,学习各种接口的原理,与某个cpu组成具体的应用,设计接口硬件并编程对接口操作,并了解当前微机的体系结构。
- 组成原理:怎么设计CPU,怎么设计计算机系统中的各个部件;
- 体系结构:怎么设计CPU性能会高,怎么设计计算机系统性能会高;
- 微机与接口:世界上已经设计好的CPU有千千万万,选择一个,怎么进行汇编语言程序设计和硬件设计应用,在此学习了一种汇编语言。
曾经,"微型计算机原理"与"计算机接口技术"是两个独立的课,有大神说,要有光,不,要合并,于是就合并出了"微型计算机原理与汇编语言与接口技术",简称"微机原理与接口技术";
也有大神说,要做大,要创新!
于是乎,"计算机组成原理"与"计算机体系结构"两课合并出了"计算机组成原理与体系结构";
于是乎, "模拟电子电路"与"数字逻辑电路"合并出了"模拟与数字电路";
更大的创新,在酝酿中,可能叫"模拟数字与组成原理"。
社会巨变,课程也要适应,时代需要所谓大神来推动。
模拟电路->数字电路->计算机组成原理-计算机体系结构(或微机原理与接口技术,不分先后)。
以上课程为进一步学习操作系统打下了基础。
三门硬件课程中涉及的:
- 汇编语言编程
- 存储器层次结构
- 虚拟存储器管理硬件及其原理
- 中断机制
对进一步学习操作系统有很大的帮助。
汇编语言部分对学习和理解操作系统的引导程序和驱动程序部分理解有帮助;
存储器部分对学习操作系统的储存器管理理解有帮助;
中断机制部分对学习操作系统中的中断机制理解有帮助;
其它,没有了。
三门课程是关于计算机硬件和直接操纵硬件的汇编语言编程,操作系统是关于系统管理的软件,都学好,才算打通任督二脉。
理论上是可以的,计算机体系结构,本身就包含计算机组成原理,而且有些本科也想通过计算机体系结构来替代原来的计算机组成原理。但是目前无论教材还是授课大都是按照学生已经学习过计算机组成原理来安排的,所以又把计算机组成原理给刨出去了。
cpi是平均每条指令的执行周期。它的发展是符合摩尔定律,越来越短的。但是内存的读写速度发展是慢于摩尔定律的。程序中平均每7条指令就会访问一次内存。
在上世纪80年代,访问一次内存大约花4个指令周期;现在访问一次内存要几百个指令周期。没有cache的话,CPU变得更快就没有意义了。
假设7条指令访问一次内存,而这次又是cache miss的。当CPU加速一倍的话,
在上世纪80年代(7*0.5+4)/(7+4)=0.68,提速还是很明显的。
现在(7*0.5+200)/(7+200)=0.98,几乎没有加速。
你就可以看出,cpi变快以后,cache miss的影响变大了。
首先需要明白,作为计算机类专业,不能简单的认为学了某一本书籍就可以出来上班挣钱。尤其《计算机体系结构》。本书是以计算机硬件为基础,辅以计算机相关底层软件作为平台支撑,才能算得上完整的体系结构。而且计算机体系结构其实和计算机处理器、计算机操作系统,计算机软甲体系结构等都具有交叉属性。说人话,就是你仅仅学习了计算机体系结构,任何工作都不能做。
计算机组成侧重于实现,同一个功能可以通过什么方式实现;
计算机体系结构侧重于功能,比如指令集中,是否要添加乘累加的指令;
举个例子,cache,体系结构的角度看,需要几层cache,组成角度看,这层cache通过什么策略实现,组相连还是全相连。
实验环境:Linux
gdb基本指令:
gdb bomb //gdb加载
b 35 //在第35行打断点
run
info stack //栈
info r //查看当前寄存器中值
disas //等价于disassemble main 查看全部的反汇编代码
(gdb) disas phase_1 //查看phase_1函数的汇编代码x命令:可以使用examine命令(简写是x)来查看内存地址中的值。x命令的语法如下所示:
x/[number][format] <addr> //其中number,format和u都是可选参数,addr为查看变量的内存地址。- 参数number: 一个正整数,表示从当前地址向后显示几个地址的内容。例如:
x/24 0x400c90 //表示查看0x400c90到向后0x400c90+24的内容- 参数format:显示的格式不是查看的格式。和c语言中的格式缩写一样,如
d:整数integer s:字符串string c:字符char u:无符号整数 unsigned integer
o:八进制格式显示变量 x:十六进制格式 f: 浮点数格式float
x/s 0x402400 //表示查看0x402400中的值,且以字符串string类型进行显示
0x402400: "Border relations with Canada have never been better."其实还有一个命令可以达到同样的效果
print (char *) 0x402400 //以char格式打印0x402400中的值
$3 = 0x402400 "Border relations with Canada have never been better."汇编的Test指令
Test命令将两个操作数进行逻辑与运算,并根据运算结果设置相关的标志位。但是,Test命令的两个操作数不会被改变。运算结果在设置过相关标记位后会被丢弃。
TEST AX,BX与AND AX,BX命令有相同效果,只是Test指令不改变AX和BX的内容,而AND指令会把结果保存到AX中。
作用详细说明
将两个操作数进行按位AND,设结果是TEMP
1. SF = 将结果的最高位赋给SF标志位,例如结果最高位是1,SF就是1。
2. 看TEMP是不是0,如果TEMP是0,ZF位置1;如果TEMP不是0,ZF位置0
3. PF = 将TEMP的低8位,从第0位开始,逐位取同或。也就是第0位与第1位的同或结果,去和第2位同或,结果再去和第3位同或…直到和第7位同或。PF位是奇偶校验位,如果结果低8位中1的个数是偶数,PF=1;否则PF=0
4. CF位置0
5. OF位置0
Test的一个非常普遍的用法是用来测试一方寄存器是否为空:如果ecx为零,设置ZF零标志为1,jz跳转。
test ecx, ecx
jz somewhere运行后随便输入一个值:isf
BOOM!!! 爆炸了
接下来看一下phase_1的汇编代码
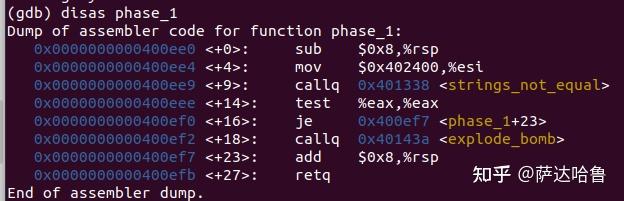
sub $0x8,%rsp分配栈帧 rsp寄存器是存放栈指针的,提供堆栈栈顶单元的偏移地址。mov $0x402400,%esi0x402400是一个立即数,将其放到寄存器esi中,(esi:第二个参数)callq 0x401338 <strings_not_equal>调用strings_not_equaltest %eax,%eax这是test的一个非常普遍的用法,测试一方寄存器是否为空。如果eax为零,设置ZF零标志为1,满足条件,后面的je跳转,否则就顺序执行je 0x400ef7 <phase_1+23>根据上一行的返回值,如果是0就跳到0x400ef7然后恢复栈帧,程序结束;如果不是零,就触发explode_bomb,炸弹爆炸!
因此可以发现,关键就在调用的strings_not_equal函数,其位置为0x401338,查看该函数的汇编代码:
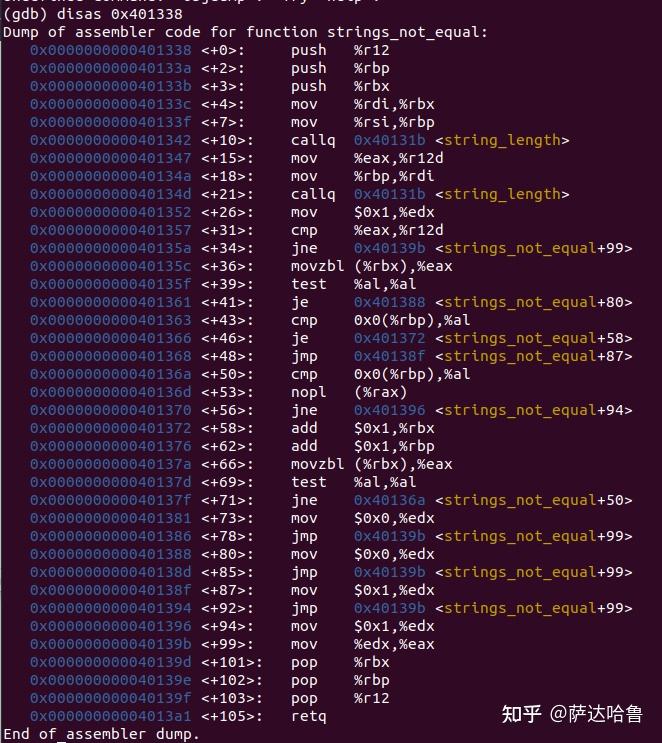
大概意思就是:
strings_not_equal汇编包含两个调用<string_length>函数的部分,这两个<string_length>函数分别计算第一个参数rdi和第二个参数rsi中的字符长度,然后判断这两个长度是否相同,不同的话<strings_not_equal>返回结果1,相同的话的返回结果0,因此,目标就是使两个参数中字符的长度相等。
即:“要判断0x402400位置处的字符串和题目预定输入的字符串是否相同”。
查看0x402400处的值:

因此,将字符串"Border relations with Canada have never been better."输入即可。

可以看到phase1的炸弹已经拆除。
待续~
微机原理重点在于讲解计算机各部件是如何工作的,而组成原理则是介绍计算机各部件是如何组成的。以CPU为例,微机原理介绍cpu是如何执行程序的,而组成原理则介绍cpu是如何构成的。
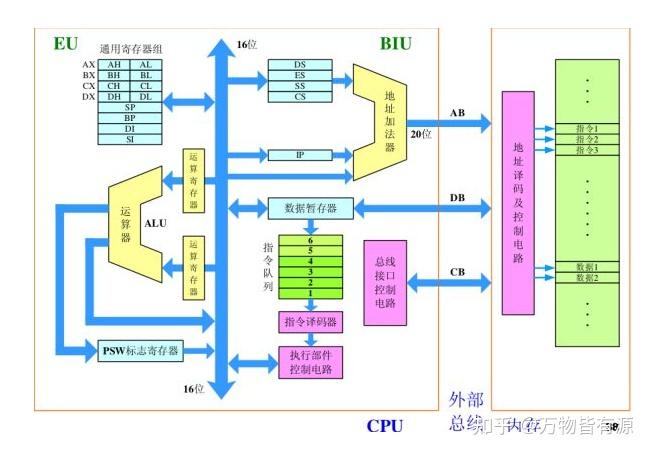
以上图为例,微机原理介绍的是内存中的指令如何被一条一条执行,以及介绍ALU是执行单元,能够对每条指令进行运算和解释;而组成原理则具体介绍ALU是如何构成、如何进行运算的(补码加法、恢复和不恢复余数法等等)。组成原理还对每条指令的执行过程细分到了微指令阶段,使得我们真正了解每条指令的具体执行过程。
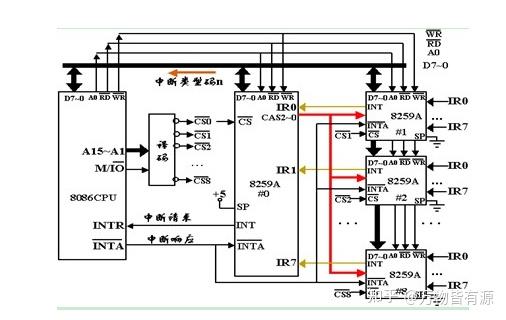
再比如上图中对于中断控制器8259的介绍,微机原理告诉我们,当有多个中断同时发生的时候,这些中断必须进行排队;
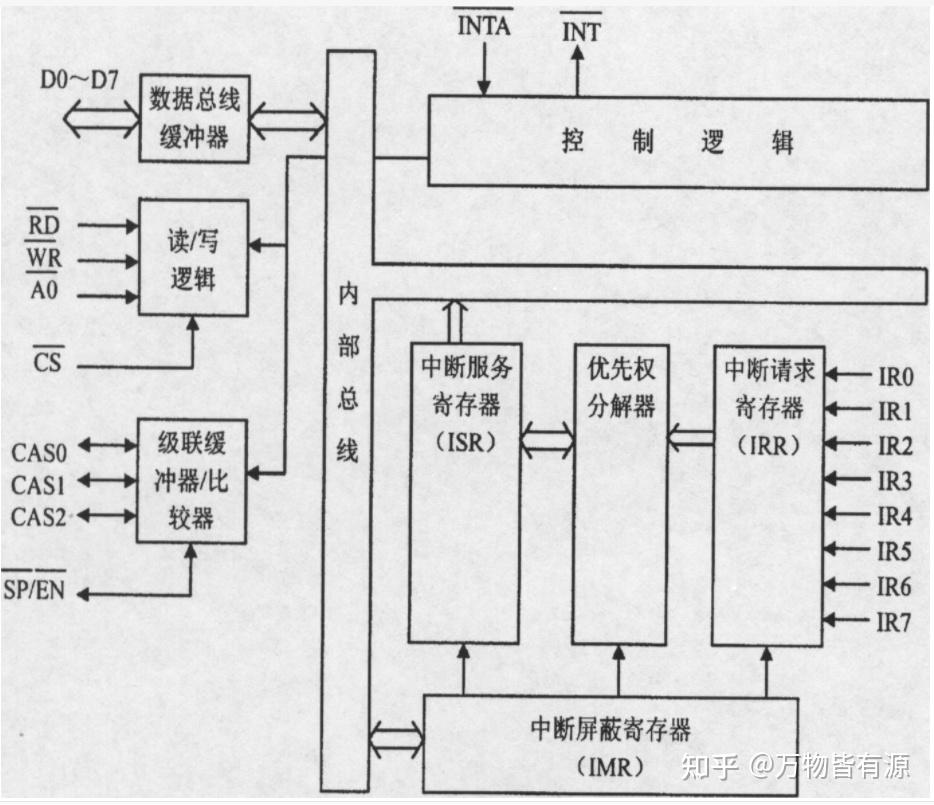
组成原理则告诉我们这些中断具体是怎么排队的(排队器)。

从以上分析似乎可以看出,两者的区别应该在于:
微机原理告诉我们计算机的基本部件有什么功能,如何使用;计算机组成原理则是告诉我们计算机的那些部件是如何组成、如何工作的。
本文使用 Zhihu On VSCode 创作并发布
以IBM 360的浮点处理单元(float point unit,FPU)为例,介绍Tomasulo算法。
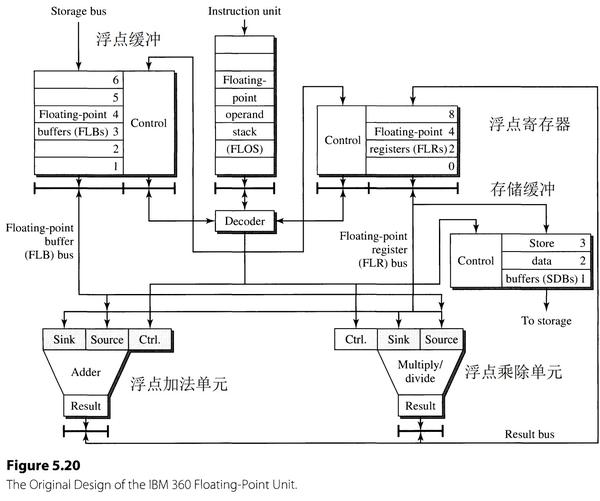
- 设计中有两个执行单元(function unit),浮点加法单元和浮点乘法/除法单元。
- 有三处寄存器堆(register file):Floating-point buffers(FLBs),Floating-point registers(FLRs),Store data buffers(SDBs)。
- FLRs中有四个 FLR 寄存器,编号分别为0,2,4,8。为体系结构寄存器(存储变量)。
- 浮点单元支持数据从存储器加载到寄存器的指令和从寄存器存储到存储器的指令(加载、存储指令),地址产生和访问存储器由外部部件来完成。
- 当数据从存储器中取出,通过总线加载到 FLBs 的寄存器中。
- 当数据需要存入存储器,数据先被存进 SDBs 寄存器中,外部部件访问 SDBs 获得数据存入存储器中。
- 指令单元(Instruction uint)将所有指令译码并将浮点单元指令依次存入浮点操作栈(Floating-point operand stack,FLOS),在浮点处理单元FPU中进行二次译码,并依据指令类型将指令发射到不同的执行单元。
- 浮点加法单元和浮点乘法/除法单元计算不是流水化的,加法需要两个周期计算完毕,乘法需要三个周期计算完毕,除法需要十二个周期计算完毕。
改进目标是能够并发执行多条浮点指令,使流水线达到每周期完成一条指令的吞吐量。由于IBM390的指令集寻址方式极为复杂,执行单元延迟是多周期的,因此设计难度极大,最终修改浮点单元FPU,使用了 Tomasulo 算法。
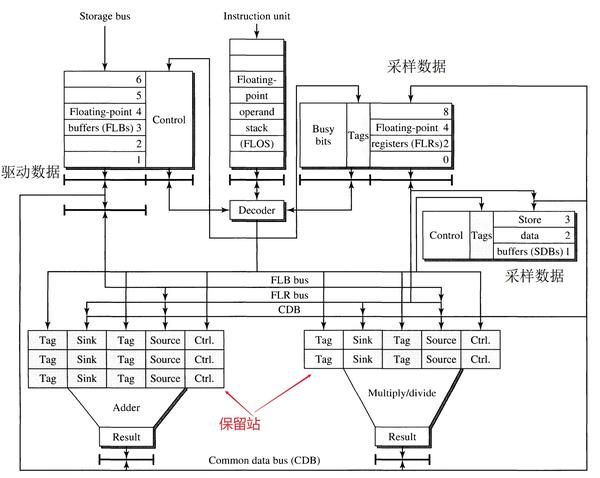
Tomasulo算法在设计中加入了三个组件:保留站(reservation stations),公共数据总线(common data bus, CDB)和寄存器标签(register tags)。
保留站
在之前的设计中,每个执行单元(function unit)入口处都只有一个缓冲区来存储当前需要执行的指令,当该执行单元在计算结果忙碌时,当下一条指令也需要该执行单元时,浮点操作栈(FLOS)发射指令会发生阻塞。为了克服这个结构瓶颈,在功能单元的输入端配置多个输入缓冲区,称之为 保留站(reservation stations)。
加法单元有三个保留站,乘法/除法单元有两个保留站,这些保留站可以看做虚拟的执行部件,即使真正的执行部件阻塞,FLOS也可以将指令发送到该执行单元,等待之前的指令执行完毕,FLOS顺序地发射指令,避免了不同指令之间需要排序带来的停顿。
由于使用了保留站,即使指令的源操作数没有准备好,FLOS依然可以将指令发射到执行单元。这些指令可以在保留站中等待其源操作数有效值的到来,比如该指令的一个源操作数,来自前面某条指令运行的结果。
公共数据总线(common data bus)
公共数据总线(CDB)连接了两个执行单元的输出和保留站、FLRs和SDBs。
- 执行单元的计算结果广播到 CDB上,保留站里需要该结果的指令,会从 CDB 上接收该数据,FLR 和 SDB 如果是该计算结果的目的地,它们同样也会从 CDB上接收该数据。CDB的使用使得可以直接将之前指令运行的结果送到需要使用该结果的指令那去,而不需要再去访问寄存器。同时寄存器也完成了更新。
- 如果一条指令的操作数是来自存储器,访存完成之后,数据将会被送到 FLBs,FLBs也可以将数据广播到 CDB上去,在保留站中等待该数据的指令也会接收该数据得到操作数。
- 执行单元和FLBs可以驱动数据发送到 CDB上去,FLRs 和 SDBs可以从CDB上接收数据。
寄存器标签
当 FLOS 发射一条指令到执行单元时,会给指令分配一个保留站,并检查该指令需要的源操作数是否可用,如果源操作数存在于 FLRs,FLRs中对应寄存器的值将会复制到保留站中去。如果不存在于 FLRs,将会将一个 标签(Tag)送到保留站中去,例如某条指令的操作数,来自于另一条指令的目的寄存器,这样该操作数就是待定状态,将Tag写入保留站。
此Tag表示该待定操作数的来源,来源可以是五个保留站中的指令,也可以是 FLB 的6个寄存器中的一个,即来自存储器。这样对于一个待定操作数,来源可能有11种情况,为确定这11种情况,需要使用一个 4bit 的Tag,如果保留站中,两个源操作数位置有一个是 Tag,表示该指令在等待待定的操作数,当需要的操作数结果已出,执行单元会将结果以及Tag发送到 CDB 上。
保留站中等待待定操作数的指令,使用 tag 来监测 CDB 上的数据,一旦监测到自己的 tag 与总线上的 tag 匹配,那就说明待定操作数结果已出,保留站从总线上接收数据。所以所有接收待定操作数的地方都需要有存放 tag的位置。保留站中需要有存放 tag 的位置,FLRs中的四个通用寄存器中需要有存放tag的位置,SDB中的三个寄存器也需要有 tag 的位置。FLRs 和 SDB从 CDB 上接收待定数据的方式与保留站相同。
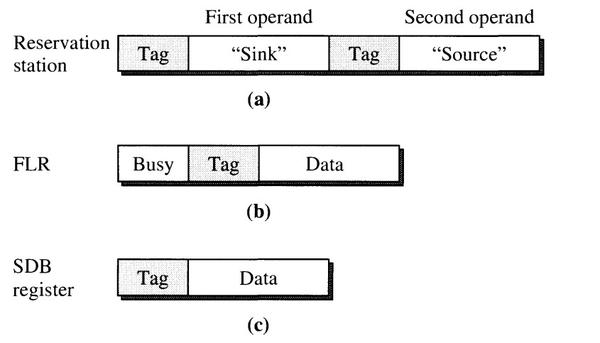
IBM 360 浮点指令是双地址格式,有两个操作数,第一个操作数标识为“sink”,因为它起到源操作数和目的标签的作用。第二个操作数称为“source”,源操作数标识。这些标签实际上就是寄存器编号(地址)。保留站中存在两个操作数,一个是 “sink”,另一个是“source”,同时每个操作数都有一个 tag。如果操作数是一个真实的数据,tag被置为0,如果操作数待定,tag 指定操作数的来源。
当FLOS发射一条指令时,源操作数使用 FLRs 中的寄存器,将其数值复制到保留站中,同时将目的寄存器对应的 FLR 寄存器中的 Busy 置1,表示该寄存器现在是一个待定的,待更新的,同时将该指令所在保留站编号作为 tag 放到目的寄存器的 tag 位置,指定该待定寄存器的来源。如果下一条指令被 FLOS 发射,会检查两个源操作数寄存器的 Busy 位,如果 Busy 位为0,直接将该寄存器的值复制到保留站,如果 Busy 位为1,表示该寄存器的结果还没计算完毕,将寄存器旁边的 tag 复制到保留站,保留站在后续会根据 tag 值接收计算完毕的操作数。
SDB同样也可能是待定操作数的目的地,所以 SDB中也需要一个 tag标签。
一个示例
为简化和便于理解,使用一个和 IBM 360设计稍有不同的例子,一些假设:
- 使用三地址格式指令,即两个源寄存器一个目的寄存器(mips指令集中的常见指令)。
- 使用寄存器-寄存器指令,即两个寄存器运算,将结果写入第三个寄存器中这样的指令。
- FLOS 一个周期可以按序发射两条指令,并在发射的那个周期,指令就已经可以开始执行。
- 加法指令执行需要两个周期,乘法指令执行需要三个周期。
- 在执行的最后一个周期,即可将结果从执行单元中送出,供后续相关指令使用。
- 设置加法执行单元的保留站编号为1,2,3。设置乘法执行单元保留站的编号为4,5。这些编号称为 “ID”。
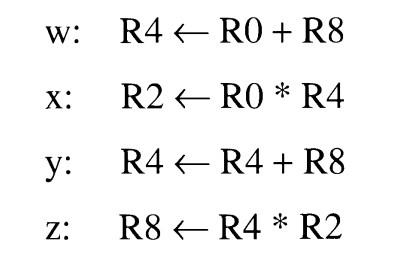
执行的四条指令如上图所示,下面开始一个周期一个周期地分析执行过程。
w: R4 <- R0 + R8
x: R2 <- R0 * R4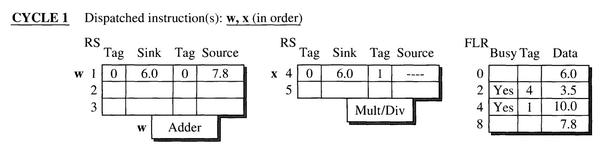
- FLOS在一个周期发射两条指令 w 和 x,分别到保留站1和保留站4。
- 指令w:源操作数 R0、R8 来自 FLRs,直接复制数值到保留站,由于直接使用具体数值,所以保留站中 tag 位置均为0。指令计算的结果会将R4的值更新,所以在 FLRs中将 R4 Busy 位置1,由于用于更新 R4 的数据来自保留站1,所以将 R4 的 tag 置为 1。
- 指令x:源寄存器 R0 可以直接使用 FLRs寄存器中的值,将数值复制到保留站,同样因为直接使用数值,保留站中的 tag 为0。对于源寄存器 R4,依赖于上一条指令w的结果,而结果还没计算出来,FLRs 中 R4 的Busy位为1,此时不能直接使用 R4 的值,因为那是一个旧值,需要使用指令w更新完 R4 的值,所以此时将 FLRs 中 R4 的 tag 值复制到保留站4第二个操作数的 tag 位置,在保留站4中表示该操作数的来源是保留站1。
- 第一个周期,发射同时指令已经开始执行。
y: R4 <- R4 + R8
z: R8 <- R4 * R2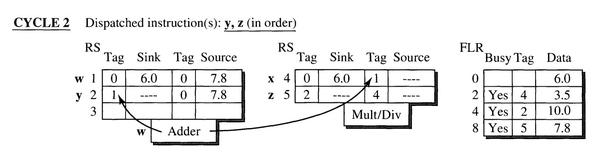
- FLOS在第二个周期发射指令 y 和指令 z 到保留站2 和保留站5。
- 指令y:第一个源操作寄存器 R4 待定,使用 R4 对应的标签1,第二个源寄存器值确定,直接复制数值到保留站。由于目的寄存器为 R4,指令y存在于保留站 2 中,左移更新 FLR 中 R4 对应的 tag,更新为 2 。
- 指令z:源寄存器 R4 和 R2 均待定,将 FLR 中的标签复制到保留站5中,R4 使用标签 2 ,R2 使用标签4。指令 z 会更新寄存器 R8,于是将自己所在的保留站编号赋值给 FLR 中寄存器 R8 的 tag。
- 此周期指令w的计算结果已经得到,执行单元将数据和标签 1 发送到 CDB 上,各个保留站检测 CDB 上的标签和自己的待定操作数是否一致,如果一致,则将 CDB 上的数据接收存在保留站中。
- 图中保留站 2 和保留站 4 需要标签 1 对应的数据,所以将数据读入,此时指令y 和指令 x 的操作数都已经准备好。
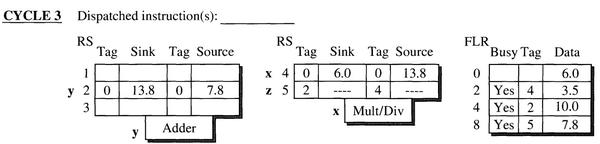
- 第三个周期,指令 y 开始在加法执行单元中执行,将在第四个周期得到结果,指令 x 在乘法/除法执行单元中执行。
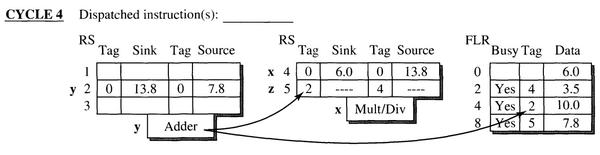
- 第四个周期,指令 y 的结果计算完毕,执行单元将 tag(2) 和计算结果发送到 CDB 总线上。
- 保留站 5 检测到 CDB 总线上的 tag 与其内部待定操作数的 tag 相同,将接收数据作为第一个操作数。FLR 检测到 CDB 上的 tag值与其内部 R4 的 tag 值相等,并且 R4 的 Busy 位是置1的,即 R4 此时是一个待定操作数,所以 FLR 接收 CDB 上的数据更新 R4 的值。同时将 R4 对应的标签和 Busy 位置0。
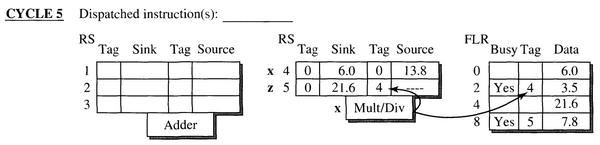
- 第五个周期,指令x的值被计算出来,执行单元将 tag(4) 和数据发送到 CDB 上,保留站 5 根据 tag 接收数据,指令 z 的操作数都准备完毕,FLR 中的 R2 根据 tag 接收数据,更新 R2 的值,并将其 Busy 位和 tag 位清零。
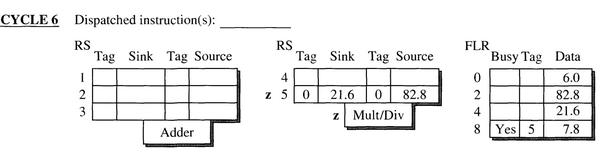
- 第六个周期指令z开始执行,到第八个周期执行完毕,更新 FLR 中寄存器 R8 的值。
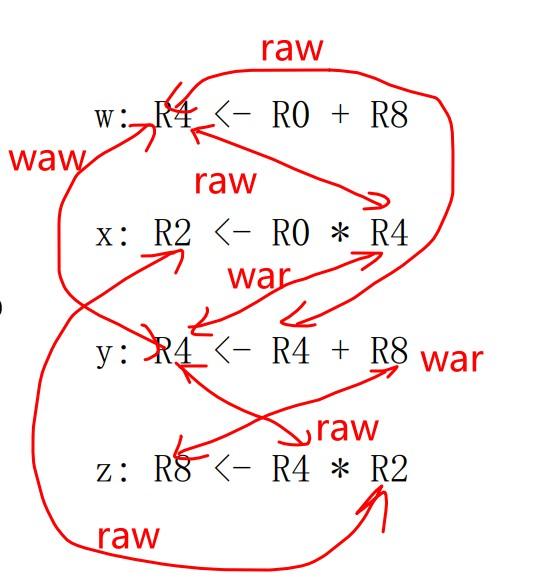
- raw(read after write):第一条指令对寄存器写,第二条指令对寄存器读。指令 y 需要读 R4,必须等待指令 w 的结果写到 R4 以后,指令 y 才可以读。如果乱序执行,指令 y 先读R4,得到的就不是新值,是 R4 的旧值,这会导致程序运行出错。
- waw(write after write):第一条指令对寄存器写,第二条指令对寄存器写,例如指令 w 和指令 y,必须指令w 先写(或者不写),指令y后写,才能使寄存器的值为最新值,如果指令y先写,指令w后写,寄存器的到的就是旧值。
- war(write after read): 第一条指令对寄存器读,第二条指令对寄存器写,指令 x 先读 R4,指令 y 后写 R4,如果指令y先写了R4,指令x后读了 R4,读到的值就是错误的。
我们来看看Tomasulo 算法如何解决数据相关的:
- war: FLOS按指令顺序发射,即肯定是前面的指令读寄存器在前,后面的指令写寄存器在后,解决 war 的问题。(如果乱序发射,就会有 war 的问题)。
- waw: 指令 w 需要对寄存器 R4 写,指令 y 也需要对 R4 写,在第二个周期,指令 y 发射,就将 FLR 中寄存器 R4 的 tag 值从1 更改为 2,表示之前 R4 的结果来自保留站1,现在由于指令 y 的发射,R4 的最新值应该来自保留站 2 了。
- raw: 对于先写后读数据相关,前面的指令将数据写入寄存器,后面的指令需要读取寄存器作为源操作数,必须等待前面的指令执行完毕,后面的指令才可以运算,这种相关性无法解决,因为无法提前得到前面指令的运算结果。但是为了避免发射阻塞,Tomasulo 算法使用标签送入保留站,指定源操作数的来源,等待操作数准备完毕才执行,使得后续的指令可以继续发射。实际上这是一种寄存器重命名的方法。
将 waw 和 war 称为假相关,raw称为真相关,指令相关性如下图所示:
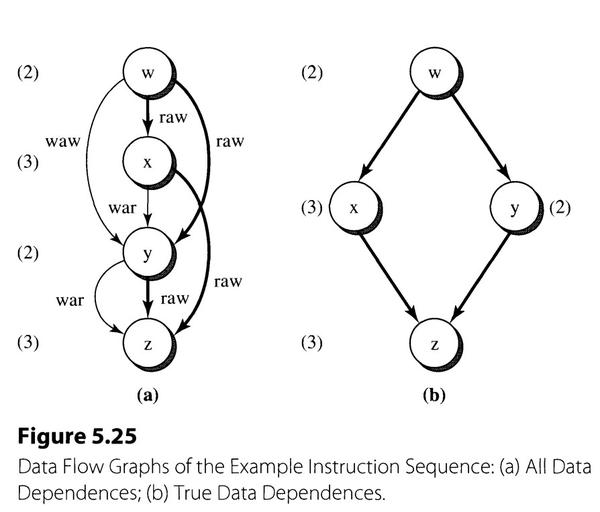
- 所有相关性如图a,真相关性使用加粗线条
- 解决所有假相关后如图b
Tomasulo 算法 引入保留站,寄存器标签,通用数据总线。通过寄存器重命名,即上述当指令操作数为待定的时候,使用 tag 指示其来源, 使得指令可以并行执行,避免 FLOS阻塞,提高处理器运行速度。
中断是指CPU不再接着向下执行,而是转去处理这个特殊信息,这个特殊信息可以是CPU外部发过来的或内部产生的一种特殊信息,CPU在收到中断信息后,应该转去执行该中断信息的处理程序。发生中断时, CPU会收到中断信息,中断信息中包含有标识中断源的类型码,通过中断类型码可以在中断向量表中找到对应的中断处理程序的入口地址。对于8086pc机,中断向量表指定放在内存地址的0处。中断处理完成后,CPU会去执行前面发生中断指令的对应的下一跳指令,所以发生中断时要先保存当前程序的运行环境,再跳到中断处理程序。
assume cs:code,ss:stack
stack segment
dw 4 dup (0)
stack ends
code segment
;安装中断处理程序,将中断处理程序安在0000:0200
start: mov ax,cs
mov ds,ax ;设置ds:si指向源地址
mov si,offset do0 ;offset do0相当于取do0的偏移地址
mov ax,0
mov es,ax
mov di,200h ;设置es:di指向目的地址
mov cx,offset do0end-offset do0 ;设置传输的长度
cld ;设置传输的方向为正,告诉程序向前移动
rep movsb ;将do0的代码送到0:200处,rep是循环传送
;设置中断向量表,我们的中断处理程序就加载在这个地址,div产生的中断类型码为0
mov word ptr es:[0*4],200h
mov word ptr es:[0*4+2],0
;写检测程序
mov dx,152
mov ax,0
mov cx,2
div cx
;编写中断处理程序
do0: jmp short do0start
db 'divide error!'
do0start:mov ax,cs
mov ax,cs
mov ds,ax
mov si,202h ;设置ds:si指向字符串,前提是我们把程序安装在200h开始的内存中
mov ax,0b800h ;设置es:di指向显存中的位置,下面的指令是对字符串做显色处理
mov es,ax
mov di,160*12+34*2
mov cx,13 ;设置字符串的长度
dnext: mov al,[si]
mov es:[di],al
mov byte ptr es:[di+1],81h
inc si
add di,2
loop dnext
mov ah,4ch
int 21h
do0end:nop
code ends
end start下面来debug一下上面的程序。
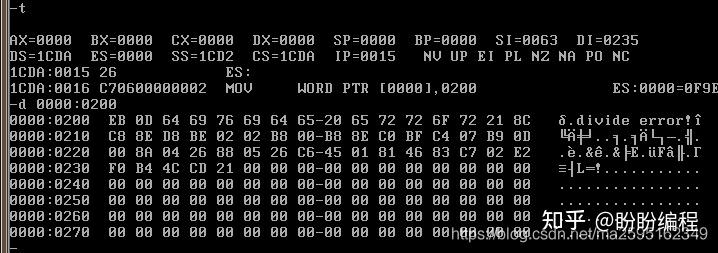
上面是rep movsb执行完后,内存0000:02000的结果,可以看到程序已经被送到这里了。

上面是设置了中断向量表之后的结果,00 00 02 00刚好是中断程序对应的段地址和偏移地址。
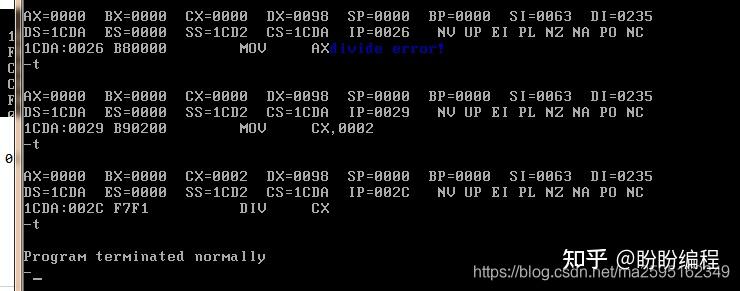
执行到div发生了中断,调用了中断处理程序。
最近被拉去debug与多核相关的问题,在core内追信号丝毫没有头绪,就想着趁此机会系统地学习一下Memory Consistency & Cache Coherence。工程师推荐了《A Primer on Memory Consistency and Cache Coherence》这本书,我看书的时候很喜欢“抄书”,“抄”的时候会将书中内容转化成更容易让自己理解的表述方式。后面我将把“抄”的内容分享出来,供不想看英文版的同学阅读,也希望大家多多讨论纠错。
本书第一章首先介绍了现代多核处理器广泛采用shared memory,处理器不断追求更好指标(PPA)的前提是不出错,而shared Memory system想不出错,就必须深入理解Memory Consistency和Cache Coherence,也就是这本书的两大主题。这两个概念的定义如下:
- Memory consistency (consistency, memory consistency model, or memory model) is a precise, architecturally visible definition of shared memory correctness.
- Consistency definitions provide rules about loads and stores (or memory reads and writes) and how they act upon memory.
现在不明白没关系,后边章节全是这俩相关的东西,本章的目的就是想让大家知道Memory Consistency和Cache Coherence很重要。
然后作者介绍了本书剩余章节的内容以及这么安排章节顺序的用意,章节之间的承前启后性已经很强了,无需在这赘述。
剩余章节指路(持续更新):
Chapter2: Coherence Basics
Chapter3: Memory Consistency Motivation and Sequential Consistency
Chapter4: Total Store Order and the x86 Memory Model
Chapter5: Relaxed Memory Consistency
处理器使用流水线来重叠指令的执行并提高性能,指令之间的这种潜在重叠被称为指令级并行,因为指令可以并行计算。
1.依靠硬件来帮助动态地发现和利用并行性的方法(桌面端CPU常用,例如酷睿系列);
2. 依靠软件技术在编译时静态地发现并行性的方法(移动端追求能效,设计师利用较低水平的ILP,不过未来如Cortex-A9正在使用动态方法)。
数据依赖性会限制我们可以利用的指令级并行性的数量,本章的主要重点是克服这些限制。可以通过两种不同的方式克服依赖关系:(1)维护依赖关系,但避免危险;(2)通过转换代码消除依赖关系。对代码进行调度是在不改变依赖关系的情况下避免危险的主要方法,这种调度可以由编译器和硬件完成。
- 数据依赖:指令i产生的结果被指令j使用(真数据依赖)
- 名字依赖:当两个指令使用相同的寄存器或内存位置时必须保证顺序。(1)指令 i 读后指令 j 写(反依赖)(2)指令 i 和 j 先后写(输出依赖)
只要指令之间存在依赖关系且足够接近,就会导致执行期间重叠改变访问顺序,就会存在危险。
- 写后读RAW:真数据依赖
- 写后写WAW:输出依赖
- 读后写WAR:反依赖
决定指令 i 相对分支指令的顺序,以便正确执行。通常施加两条约束:
- 受分支影响的指令不能放在控制指令之前,否则无法对其进行控制;
- 不受分支影响的指令不能放在控制指令之后,否则它的执行会受到控制;
为了尽可能避免流水线的停滞,可以寻找指令间的依赖关系并重叠不相关指令序列。
循环展开可以减少分支指令次数,使用不同的寄存器来避免不必要的约束,更多的指令也可以更方便进行指令调度。但是需要调整循环终止和迭代代码。
所有这些转换背后的关键需求是理解一条指令如何依赖于另一条指令,以及如何根据依赖关系更改或重新排序指令。三个因素限制了循环展开的收益
- 每次展开时平摊的开销减少
- 代码大小限制:对于较大的循环,指令数的增多会导致cache miss增加,过度展开也会导致寄存器不足;
- 编译器限制
1bit准确率不够,4K-entry 2-bits BPB准确率能够达到80%以上,且与无限entry的准确率相当。
BPB的典型实现为cache,在IF阶段PC更新后就计算目标地址,如果taken直接跳转,否则顺序执行。这也叫局部分支预测器(Local Branch Predictor),因为每条分支指令只能看到自己的历史情况。
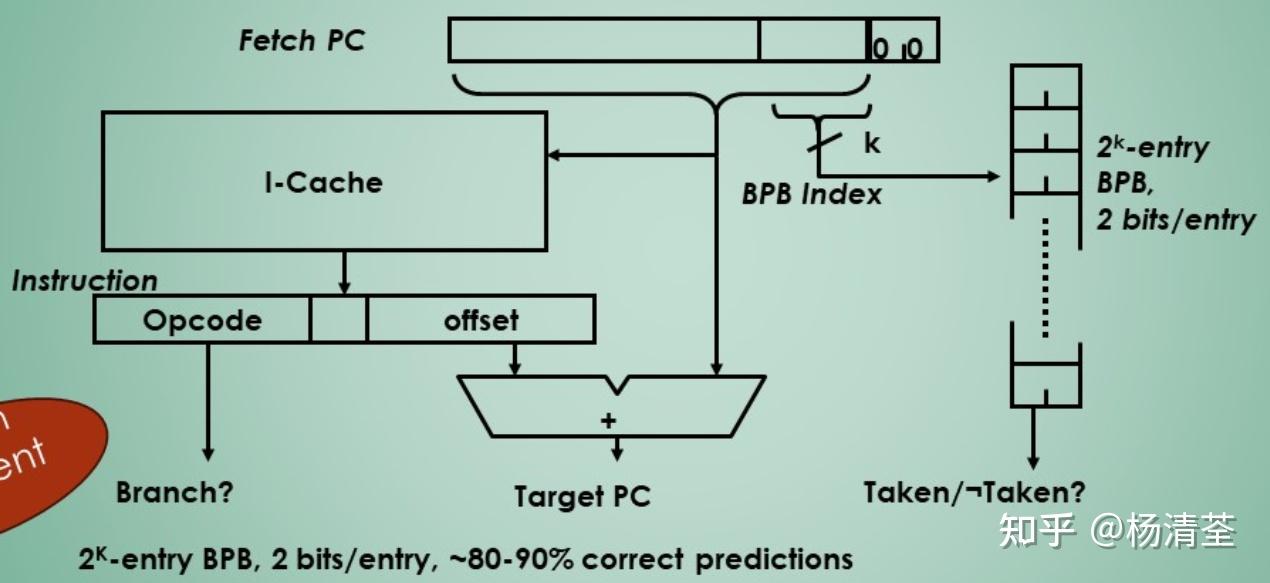
简单的BPB方案仅使用单个分支的最近行为来预测该分支的未来行为,不能联系其他分支的行为来共同预测(特别是当分支之间还有相互关联的时候,如下所示:
if (aa==2) aa=0;
if (bb==2) bb=0;
if (aa!=bb) ...;如果我们也观察其他分支的近期行为,这可能会提高预测的准确性。因此提出了关联分支预测器(两级预测器),即使用其他分支的行为进行预测的分支预测器。
(m,n)预测器使用最后m个分支的行为从  个分支预测器中进行选择(所以也叫全局预测器),每个分支预测器是单个分支的n位预测器。相关分支预测器的优势在于,它只需要增加少量硬件就能够可以产生比2bit BPB方案更高的预测率。
个分支预测器中进行选择(所以也叫全局预测器),每个分支预测器是单个分支的n位预测器。相关分支预测器的优势在于,它只需要增加少量硬件就能够可以产生比2bit BPB方案更高的预测率。
硬件开销低的分析:最近m个分支的全局历史记录在一个m位移位寄存器中,其中每bit记录该分支是否taken。然后可以使用分支指令PC低位截取与m位全局历史记录的来索引BPB。以(2,2)的预测器为例,分支指令PC截取k bits+2 bits的选择位,共同组成k+2 bits进行索引,如下图所示。
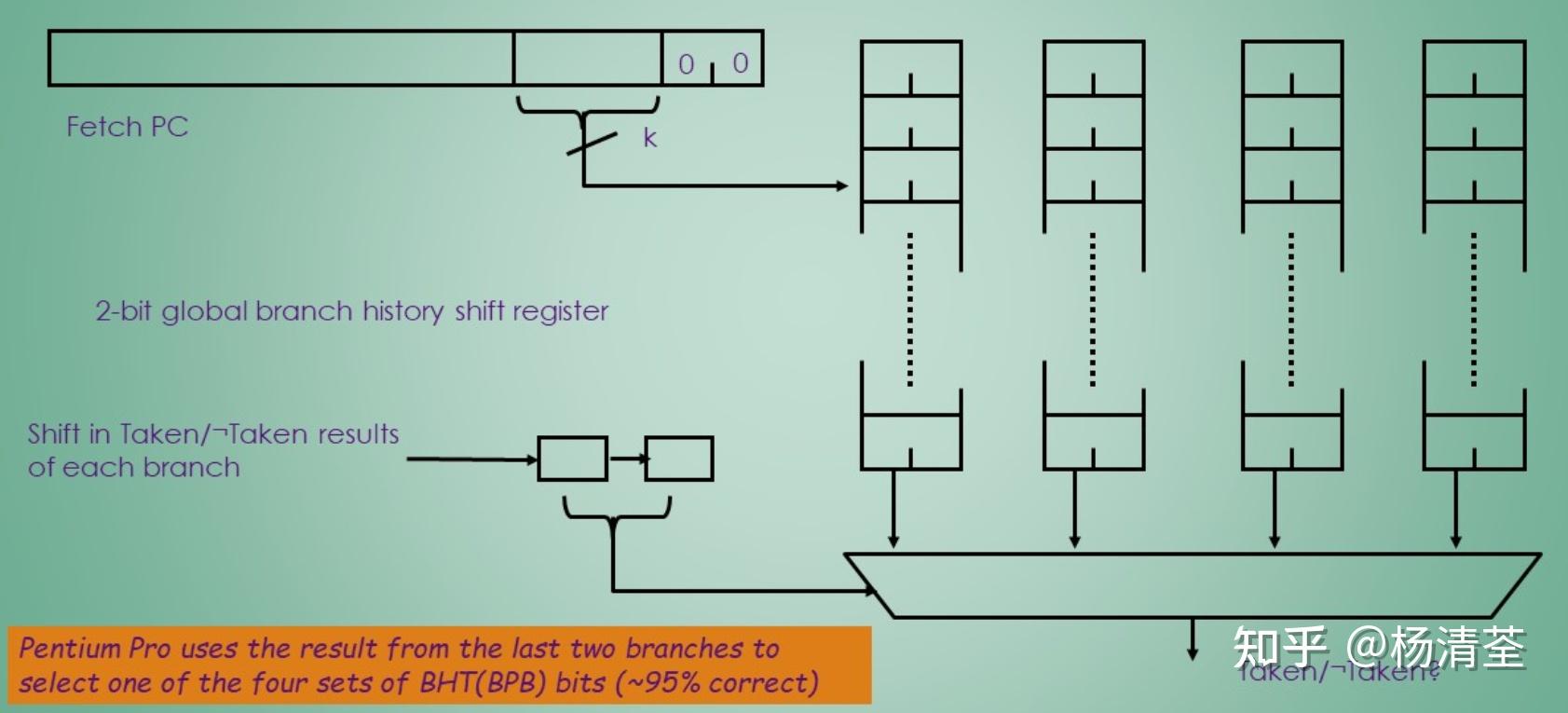
仅使用本地信息的标准2位预测器会在一些重要分支上失败,而添加全局信息,性能可以得到改善。Tournament预测器通过使用多个预测器(通常一个基于全局,另一个基于本地)并将它们与选择器结合起来,将性能提升到了一个新的水平,可以在中等大小(8K-32Kb)下实现更好的准确性。
典型的例子是FP测试集和Int测试集对于分支的情况是不一样的,Int有40%的情况选择全局,FP有15%的情况选择全局。
全局预测与局部预测独立进行,由选择器选择其中一个方法的预测结果作为最终预测结果,对于选择器中的一个状态,如果全局预测和局部预测结果一致,状态不变;否则:对于该状态,如果局部预测正确就+1,全局预测正确就-1;
- 优点:综合全局和局部历史信息,精度较高;
- 缺点:Tournament预测器的空间占用是比较大的,因为不仅有两个预测器,还有一个选择器;
本节将探讨动态调度,硬件重新安排指令执行以减少停顿,同时保持数据流和异常行为。基于硬件的动态调度有几个优点。
- 它允许汇编代码在不同流水线上运行,避免二进制文件对不同微体系结构重新编译的需要。
- 可以处理编译时依赖项未知的情况。
- 允许处理器容忍不可预测的延迟,比如缓存丢失,在等待缓存丢失解决的同时执行其他代码。
动态调度的优势是以显著增加硬件复杂性为代价获得的,尽管动态调度的处理器不能更改数据流,但它会尝试在存在依赖项时避免停机。相比之下,编译器的静态调度试图通过分离相关指令来最小化延迟。
使指令在数据准备好后立刻执行,意味着乱序执行、乱序完成,这会带来WAR WAW的危险。动态调度就会带来不精确中断,使异常的现场恢复很麻烦。为了实现乱序执行,ID阶段被拆成两个部分——Issue(译码,检查数据危险)Read Operands(等到没有数据危险读数)
我们区分指令何时开始执行和何时完成执行;在这之间,指令正在执行。流水线允许多个指令同时执行,需要多个功能单元,所有指令依次通过发布阶段(有序发布);然而,它们可能在第二阶段(读取操作数)停滞或相互绕过,从而进入无序执行。
RAW:跟踪指令操作数的有效性;
WAR、WAW:寄存器重命名,实现寄存器拓展。使用了一个加载功能单元,所以不需要进行重大的修改来添加寄存器-内存寻址模式。
基本思想是保留站在操作数可用时立即获取并缓冲操作数,从而消除了从寄存器获取操作数的需要。危险检测和执行控制是分布式的,在每个功能单元的保留站中保存的信息决定了指令何时可以在该单元开始执行。其次,结果直接从被缓冲的保留站传递到功能单元,而不是通过寄存器(通过公共数据总线CDB)。
Load Buffer功能:
- 保存有效地址的组成部分,直到它被计算出来;
- 跟踪正在内存上等待的未完成负载;
- 保存正在等待CDB的已完成负载的结果。
Store Buffer功能:
- 保存有效地址的组成部分,直到它被计算出来;
- 保存等待数据值存储的未完成存储的目标内存地址;
- 保存要存储的地址和值,直到内存单元可用。
三个步骤:
- Issue:从指令队列的头部获取下一条指令
如果有一个匹配的预留站是空的,则向具有操作数值的站点发出指令。如果操作数不在寄存器中,则跟踪将产生操作数的功能单元(方便Execute阶段接收)。存在WAR和WAW时重命名寄存器。
- Execute
如果一个或多个操作数还不可用,在等待计算公共数据总线时监视它。当一个操作数可用时,它被放置到任何等待它的保留站。当所有的操作数都可用时,操作就可以在相应的功能单元上执行。通过延迟指令执行直到操作数可用,可以避免RAW危险。对一个功能单元,几个指令可能在相同的时钟周期内准备就绪。对于计算单元可能影响不大,但是存储单元的选择有很大影响。
- Write result
当结果可用时,将其写入CDB,并从CDB写入寄存器和等待该结果的任何保留站(包括存储缓冲区)
保留站从CDB检索结果实现了静态调度管道中使用的转发和绕过机制。但是动态调度方案在源和结果之间引入了一个延迟周期,因为直到写入结果阶段才能完成结果及其使用的匹配。因此,在动态调度的流水线中,产生指令和消费指令之间的有效延迟至少比产生结果的功能单元的延迟长一个周期。
优势
- 记分牌每条通路只能存一条指令,而Tomasulo引入保留站之后每条通路可以缓冲下多条指令;
- 对于WAW,记分牌过度纠结寄存器名字,会把所有指令的结果都写进寄存器堆,会因为写后写冒险阻塞指令发射,而Tomasulo只保存最新的写入值,这样既保证了正确的结果,又减少了无谓的工作;
- 对于WAR,记分牌过度纠结寄存器名字,指令在执行之前一直检测的是寄存器堆,一旦数据准备好,就会从寄存器堆中取数,这样的后果就是后序指令即使计算完结果也可能不能立刻写回寄存器堆,而Tomasulo则在发射时就拷贝数据,贯彻数据流的思想——“寄存器名字不重要,寄存器里的数据才重要”;
缺点
- 每一个执行单元对应一个保留站,保留站中缓冲多条指令,所以有可能在同一周期有多条指令准备好数据,但是执行单元同时只能执行一条指令,所以就需要从中选择一条指令,简单的解决办法是为保留站的每一行增加一个年龄位,每次出现冲突,就选择最老的指令送到执行单元。
- 电路里的CDB总线只有一组,这意味着每一个周期只能写回一条指令,如果同时有多条指令完成,那就只能选择一条指令进行广播,别的指令等待;第二种办法是增加CDB总线,支持多指令广播,但是这会让电路面积大增,
- Tomasulo算法没办法实现精确中断,重排序缓冲可以改进Tomasulo算法,从而实现处理器的按序发射-乱序执行-按序提交。
- 分布式危险检测逻辑。分布式保留站和CDB实现,如果多个指令正在等待单个结果,并且每个指令已经有了它的其他操作数,那么可以通过在CDB上广播结果来同时释放这些指令。如果使用集中式寄存器文件,当寄存器总线可用时,这些单元必须从寄存器中读取它们的结果。
- 消除了WAW和WAR的延迟。重命名寄存器以及在操作数可用时将其存储到保留站。
- Load和Store先要通过功能单元进行地址计算,再将操作放入独立的Load和Store Buffer中。
- Load指令在第二个执行步骤访存,并将结果写回寄存器并广播在CDB中发送给保留站。
- Store指令在写回阶段完成。无论目标是寄存器还是内存,所有写操作都发生在写结果中,这一限制简化了Tomasulo算法。
- 如果操作数在寄存器中可用,则将它们存储在V字段中。否则,将Q字段设置为指示将生成作为源操作数所需值的保留站。

- Issue阶段FP操作,当保留站有空的时候就可以发射;如果寄存器状态表中rs寄存器的项目不为零,则表示前面有指令要写rs寄存器,所以把保留站的Qj指向写rs的指令,否则从寄存器中取数,rt同理;同时设busy,更新寄存器状态表。
- Issue阶段Load&Store操作,当Buffer有空的时候就能发射,与FP类似;先算rs得到地址,再用rt存/取数据,所以要先确定rs非空。对于Load还需要更新寄存器状态表,rt是写入,就不用管了,不过对于Store还需要判断rt(源数据);
- Execute阶段,对于FP操作,两个操作数都准备好了就执行;对于Load&Store阶段1,只要Qj为零就表示地址计算已经就绪了,开始算地址;Load一阶段完成后随机进入二阶段访存取数。
- Write Result阶段,对于FP或Load,相当于得到结果了,所以只要计算完成且CDB空闲就可以。此时判断寄存器、保留站是否需要该数据,并释放占用。如果寄存器状态表中仍有该数据,说明没有WAW,所以要写进寄存器中,否则不写寄存器了。
- Write Result阶段,对于Store,相当于把源数据存进内存的目的地址,所以只要算完地址且得到了源数据就可以执行,此时进入Store Buffer,并释放占用。
在Tomasulo的方案中,结合了两种不同的技术:将体系结构寄存器重命名为更大的寄存器集,以及缓冲来自寄存器文件的源操作数。
- 尽管Tomasulo的算法是在缓存之前设计的,但缓存的存在,以及固有的不可预测的延迟,已经成为动态调度的主要动机之一。乱序执行允许处理器在等待缓存丢失完成的同时继续执行指令,从而隐藏了全部或部分缓存丢失惩罚。
- 随着处理器的问题处理能力越来越强,设计人员越来越关注难以调度的代码(如大多数非数字代码)的性能,寄存器重命名、动态调度和推测等技术变得更加重要。
- 它可以实现高性能,而不需要编译器将代码定位到特定的管道结构,这在收缩包装的大众市场软件时代是一个有价值的属性。
Tomasulo算法通过寄存器重命名、设置预留站和使用公共数据总线等方式,优化指令的并行执行,能够处理数据依赖,但在处理控制依赖时存在局限。如果存在分支带来的控制依赖,Tomasulo算法需要等待分支指令的执行结果,(或者不等待,但可能导致中断的不精确,乱序执行本身就会导致中断不精确,要实现完全的精确,就需要额外的机制辅助)。
硬件前瞻技术可以通过分析和预测指令的执行结果,提前执行那些有用的指令,从而减少处理器的空闲时间,并提高整体性能,弥补Tomasulo算法(和Scoreboarding)的不足。
硬件前瞻技术主要基于三点重要思想:
- 动态分支预测用于选择执行哪些指令
- 推测允许在控制依赖项解决之前执行指令(具有撤销错误推测序列的影响的能力)
- 进行动态调度,以应对基本块不同组合方式的调度(意思是硬件前瞻能够跨越基本块的边界进行调度,没有硬件前瞻的动态调度只能在基本块内部进行部分重叠的调度,因为它需要在实际执行后续基本块中的任何指令之前先解析分支指令。基本块是指程序中单入口单出口的代码块,可以理解为for循环的一块或者if-else的两块)
硬件前瞻根据预测来选择何时执行指令,一旦操作数可用就立刻执行计算。为了扩展Tomasulo的算法以支持推测,我们必须将指令结果旁路(这是推测执行指令所需的)与指令的实际完成分开。通过这种分离,我们可以允许一条指令执行并将其结果旁路到其他指令,而不允许该指令执行任何无法撤消的更新,直到我们知道该指令不再具有不确定性。当一条指令确定后再更新寄存器/存储器,这叫做指令提交。
推测后的关键思想是允许指令乱序执行(不用管前面分支指令的结果出来了没有),但强制顺序提交,防止不可挽回的动作(状态更改、触发异常)。因此就引入重排序缓冲(Reorder Buffer, ROB)这个硬件结构。详细可参考不精确中断文章。(Smith 和 Pleszkun, 1985)(注意一下:硬件前瞻技术本身不直接解决中断精确性的问题。硬件前瞻主要用于预测指令的执行结果,并提前执行有用的指令,以提高处理器效率。它更多地关注于指令的执行流程和优化。)
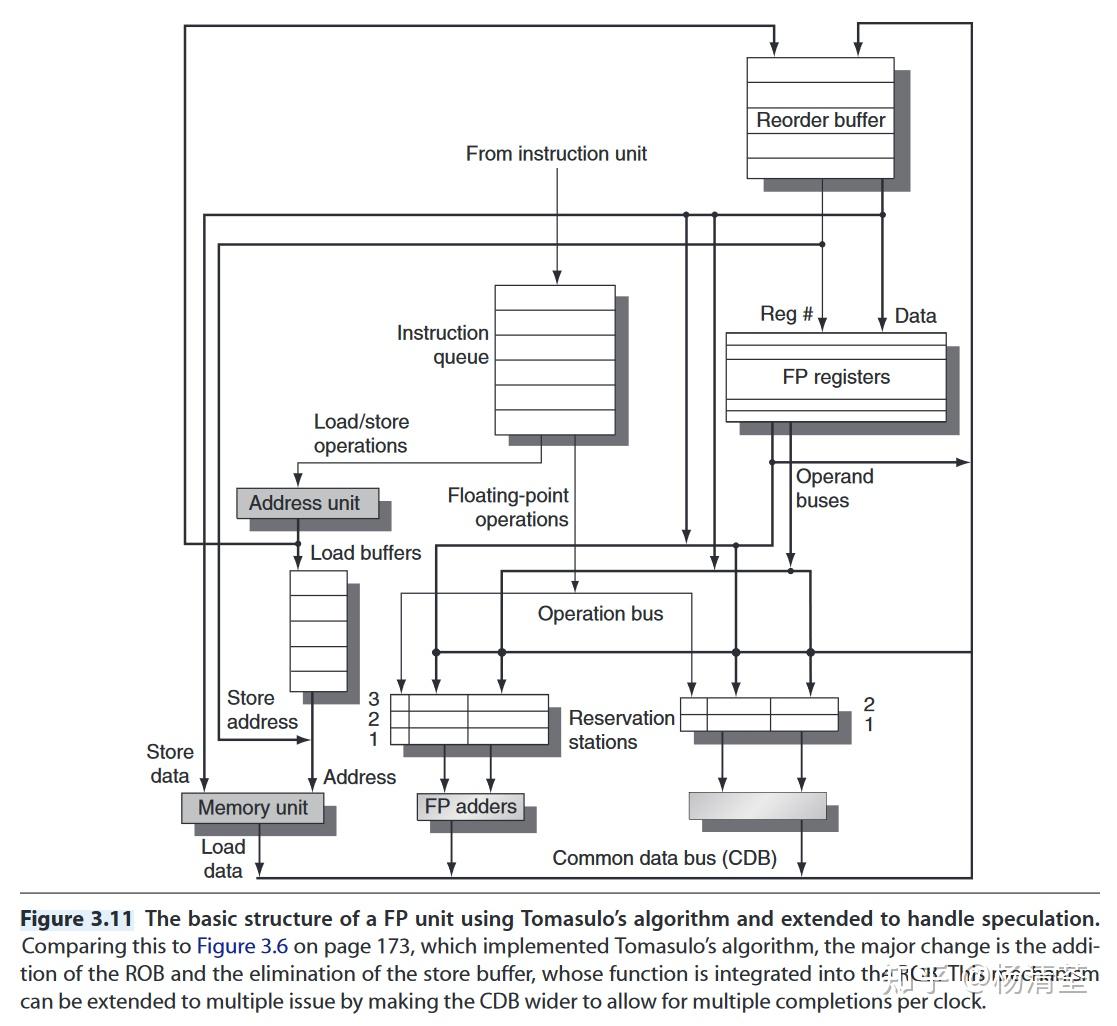
ROB主要包含四个信息:指令类型,目的字段、值字段和就绪,“Figure 3.11” (Hennessy 和 Patterson, p. 185)展示了进行硬件前瞻拓展后的Tomasulo结构,去处理Store Buffer。上往下数据依次从新变旧,因此数据先从ROB拿,没有再找register。拓宽CDB还可以支持多发射。
指令执行的4个步骤:
- Issue:ROB与保留站都有空才发射;
- Execute:操作数都可用时执行,否则监视CDB,避免RAW;
- Write Result:将结果与ROB标签写在CDB上,写到ROB与需要的保留站上;对于Store指令,如果要存的值就绪了,就存入,否则监视CDB;
- Commit:分三种情况,完成后都需要清除ROB对应条目。ROB满了就要停止取指令直到有空。
- 正常提交:当指令到达ROB头部且结果已经写回ROB时,用结果更新寄存器;
- 提交存储指令:类似正常提交,不过更新的是存储器;
- 分支预测错误:ROB被刷新,重新从分支后续正常指令开始执行。

“Figure 3.14” (Hennessy 和 Patterson, p. 191)非常重要,讲清楚了各种操作的具体实现。具体不同体现在以下几点:
- Issue的时候需要多考虑一次ROB中的数据是不是有效的?有效的话直接从ROB里面取(ROB数据比寄存器新);
- 增加了Commit部分的判断;
总而言之,硬件前瞻技术能够带来一下四点好处:
- 提高处理器效率:通过预测指令的执行结果,硬件前瞻技术能够提前执行有用的指令,避免等待无用指令执行完成的时间,从而显著提高处理器的运算效率。
- 优化指令执行顺序:硬件前瞻技术可以分析和预测数据依赖性和控制依赖性,优化指令的执行顺序,使得处理器能够更加高效地利用资源。
- 减少处理器空闲时间:通过提前执行有用的指令,硬件前瞻技术减少了处理器的空闲时间,从而提高了处理器的整体性能。
- 支持更复杂的任务处理:硬件前瞻技术能够处理复杂的数据依赖和控制依赖场景,使得处理器能够更高效地处理复杂任务,满足不断增长的计算需求。
之前所描述的方法虽然可以尽量降低CPI,但是最低为1,如果要为了进一步提高性能,希望将CPI降低到小于1,这就必须要一个时钟周期发射多条指令,即多发射处理器,主要有以下三种方式:
- 静态调度超标量处理器
- VLIW处理器
- 动态调度的超标量处理器
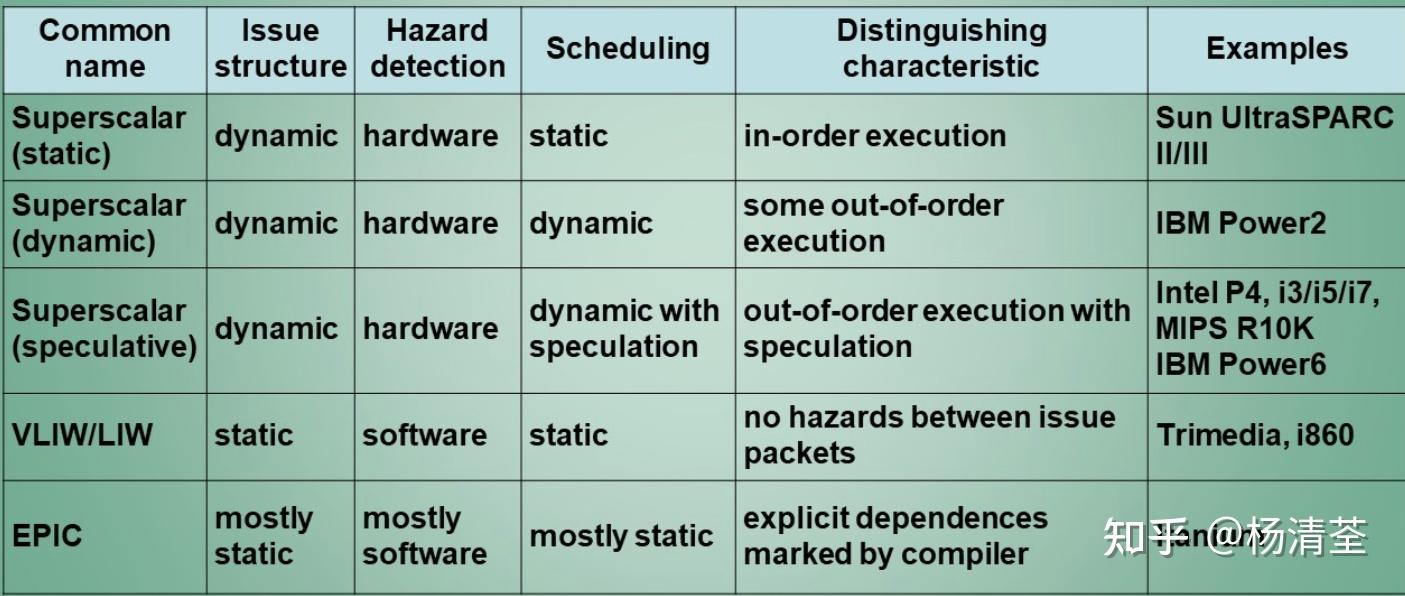
超标量处理器和VLIW处理器实现多发射的方式不一样
- 超标量处理器是通过设置多套“取指令”、“译码”、“执行”和“写回结果”等指令执行部件,能够同时发射并执行完成多条指令。这种设计允许处理器在一个时钟周期内识别和执行多个独立的指令,提高了处理器的并行性和吞吐量。实现需要复杂的硬件支持,增加了处理器的复杂性和成本,一般用于桌面系统中。
- VLIW处理器是通过静态调度的方式,使用编译器将多条互相独立的指令打包在一起形成一条超长指令送入处理器的取值模块,寻找独立指令的负担放在编译器上,硬件不解决数据依赖问题,从而简化了硬件结构,因此应用主要在功耗和面积为主要约束的嵌入式场合,例如某些DSP处理器就采用VLIW体系结构。
VLIW使用多个独立的功能单元,将多个操作包装在一个非常长的指令中发射,收益随着最大发射率增大,开销的增长是限制宽发射处理器的主要因素。
早期VLIW是锁步工作的,没有冒险检测硬件。所有功能单元都要保持同步,故任意功能单元在流水线中的停顿都会导致整个处理器停顿。
二进制代码的兼容性是VLIW的主要逻辑问题,当功能单元和单元延迟不同的时候就需要不同的代码版本。旧代码的运行成问题。
指令顺序执行,所有冲突在issue阶段被检测,对当前issue阶段的所有指令和执行阶段的所有指令进行冲突检测;
我们希望将动态调度、多发射和前瞻结合起来,以Tomasulo算法为基础,构建前瞻执行动态调度的多发射处理器。
在动态调度的处理器中,无论是否前瞻,都需要更新控制表,否则会丢失相关性。要实现动态调度的处理器,关键就在于保留站的分配与流水线控制表的更新,有两种方法实现:
- 一个时钟周期内分先后运行多发射的指令;
- 构建必要的逻辑,处理多条指令之间的相关性;
发射步骤是最基本的瓶颈;
- 为发射包中每条指令指定保留站和ROB,如果保留站不够(指令包中全是一种指令类型),将指令包分解,按照程序的原始顺序执指令包的部分指令,剩下的放在下一个指令包执行;
- 分析即将发射的指令之间所有相关性;
- 如果一条指令依赖于指令包之前的指令,且该指令还未commit,则使用指定的ROB编号更新保留表,否则使用已有的信息更新保留表项。
- 从cache取指令:流水线会收到一组指令,称为issue packet;
- 决定发射的指令:发射单元要对指令包进行检查,需要在一周期完成复杂操作(复杂的为W*W*L,W是issue宽度,L是现存指令的周期数)带来较大的延迟,因此流水线时钟周期一般受限于指令发射阶段,所以一般的多发射处理器将issue阶段做成多个stage;
- 发射并更正FUs:如果最多可以一拍发射两条指令,一条为int一条为fp,必须定义int与fp先后顺序(如int先于fp),如果当前fp指令之前没有未执行的int,int就填nop,br不能和其他操作一起发射,除非确保肯定执行;
大量ILP是通过展开浮点程序中的简单循环实现的,原来的循环很可能可以在向量处理器上高效运行,对于此不清楚多发射方法相较于向量处理器究竟能够有多大优势。
而多发射方法相较于向量处理器的主要优势在于能够从结构化程度较低的代码中提取某些并行,以及能够轻松缓存所有形式的数据,这就是多发射方法能够成为利用ILP的主要方法,而向量主要作为拓展。
高性能流水线,特别是多发射流水线中仅能够预测分支还不够,需要传送高带宽的指令流(多发射的取值周期变多,预测要等到译码阶段才知道是否为分支),因此需要使用BTB提高指令传送带宽。同时高级的前瞻技术能够进一步增强ILP。
预测尚未译码的指令是否为分支,如果是分支,则下一个PC是什么,这样能够将分支的代价将为0。分支预测缓存中存储着下一条指令的预取地址,这就是分支目标缓冲BTB。
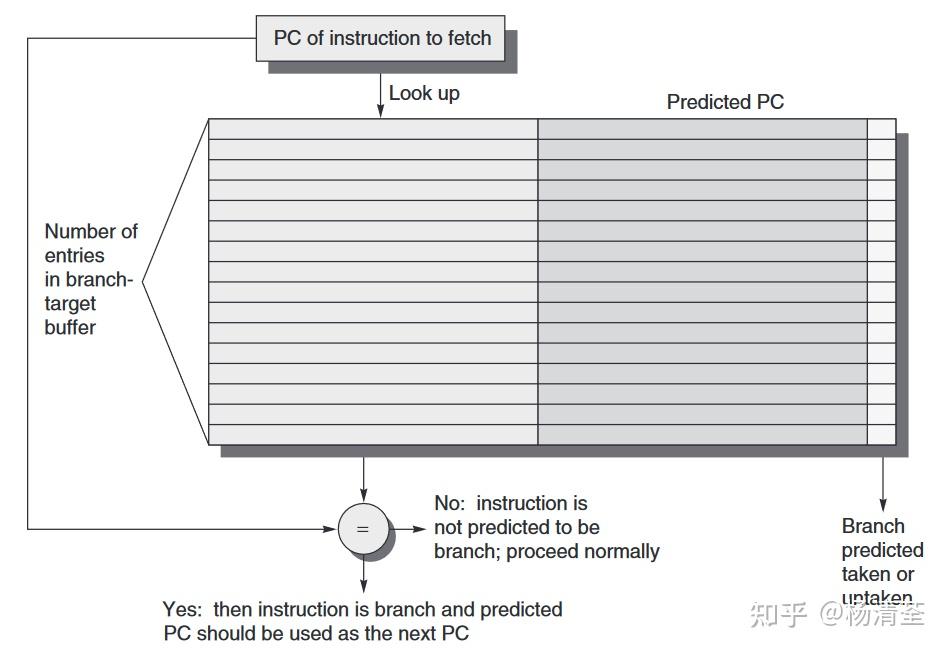
BTB将分支成功的分支指令的地址和它的分支目标地址都放到一个缓冲区中保存起来,缓冲区以分支指令的地址作为标识;取指令阶段,所有指令地址都与保存的标识作比较,一旦相同,就认为本指令为分支指令,且让那位它转移成功,且它的分支目标(下一条指令)地址就是保存在缓冲区中的分支目标地址。
BTB工作流程如下
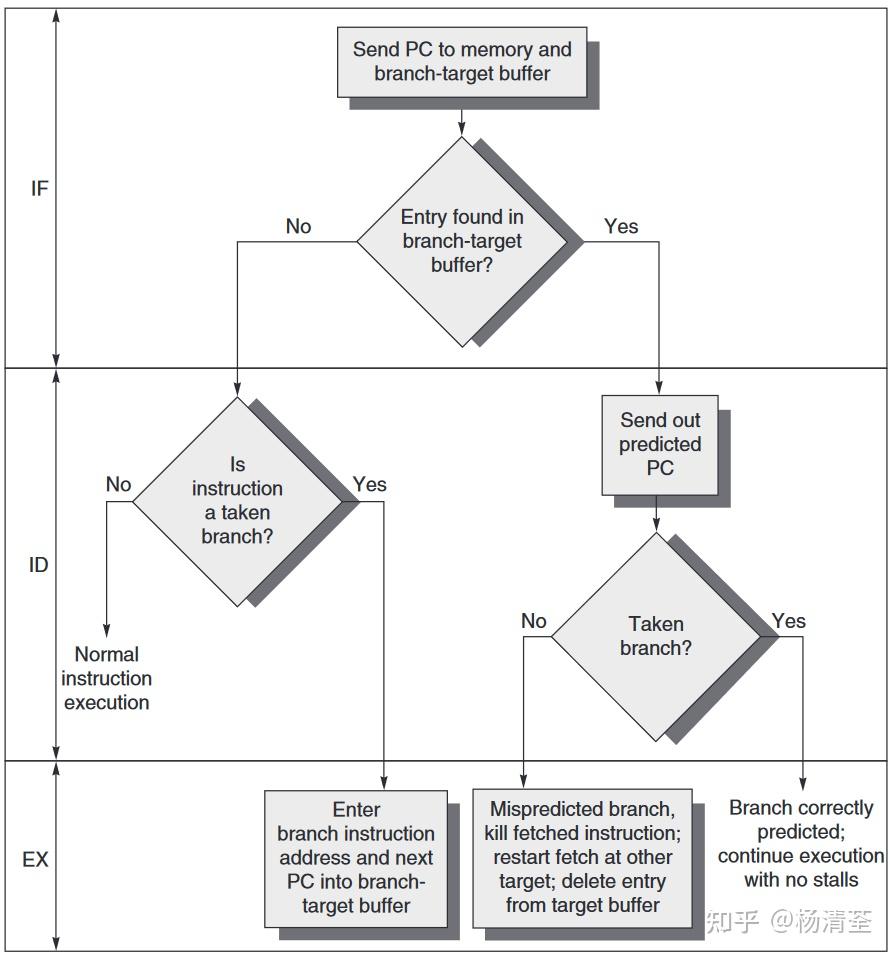
这里需要厘清分支预测缓冲BPB(分支预测器)和分支目标缓冲BTB的区别:
- 相同点:都是解决控制相关的动态分支预测技术,其有两种目标:预测转移是否成功和尽早得到转移目标地址。
- 不同点:
- 分支预测缓冲基于分支操作历史记录预测现在分支是否跳转(在译码阶段,所以还是得有延迟槽)
- 分支目标缓冲直接在取指阶段判断是否为分支,如是则下一个PC应该是什么,延迟更少,特别适用于多发射处理器;
BTB的变体是存储一个或多个目标指令,作为预测目标地址的补充或代替,有两个好处:
- 允许分支目标缓冲访问时间长于两个以上取指周期,从而可以吧BTB做的更大;
- 实际上每条指令都变成了分支指令(后面直接接的跳转后的指令)因此不需要单独的分支指令了,这样就可以实现分支折叠(branch folding)
前面都是解决的直接跳转,而间接跳转需要访问寄存器,主要来源于return操作。尽管return能够使用BTB,但是准确率低(依靠PC判断,而函数可以从多个地方调用,一个地方多次调用的情况很少)。
为了解决这个问题,可以设计一个小型缓冲,类似于一个栈,存储最近的返回地址,函数调用时压栈,返回时弹栈,就能够准确预测return操作。(这也是为什么要避免递归,尽量使用循环)
由于多发射的复杂性,不能再将取值当作一个简单的流水级了,需要一个专门的取值单元。主要功能如下
- 分支预测:变成取值的一部分了
- 指令预取:提前取指令以供每周期发射多条指令,和分支预测配合
- 指令存储器访问与缓存:使用预取隐藏跨缓存模块的成本,并提供缓存,按需向发射单元提供相应数量的指令;
前瞻(Speculation)技术允许在处理器还未判断指令是否能执行之前就提前执行,以克服控制相关,实现前瞻的关键思想是:允许指令乱序执行,但必须顺序确认。加入指令确认阶段需要一套额外的硬件缓冲来保存那些执行完毕但未经确认的指令及其结果,称为重排序缓冲(Reorder Buffer,ROB),它同时还用来在前瞻执行的指令之间传送结果。
ROB方法需要维护保留站、ROB、体系结构寄存器三个数据结构,造成寄存器资源浪费(一个值存在多个地方),因此进一步使用寄存器重命名,明确使用更大的物理寄存器集(体系结构寄存器是物理寄存器的子集),通过维护重命名表指出两者的对应关系即可。拓展后的寄存器取代了ROB和保留站的大部分功能,只需要一个队列来确保顺序完成指令即可。
指令发射时,将体系结构寄存器重命名为物理寄存器,为目的分配一个新的寄存器,因此WAW和WAR都可以通过寄存器重命名来解决。指令提交之前,保存指令目的的物理寄存器不会成为体系结构寄存器,解决了恢复的问题。指令提交时重命名表被更新,用于指示一个物理寄存器和体系结构寄存器对应,完成对处理器状态的更新。
何时撤销寄存器分配会比较复杂,只有当该物理寄存器不在于体系结构寄存器相对应,且后续指令不会用到才可以释放。两种方法
- 处理器通过查看功能单元队列中所有指令的源寄存器说明符,如果没有使用该物理寄存器且该物理寄存器不与体系结构寄存器对应,就可以回收;
- 处理器一直等待,知道对同一体系结构处理器执行写操作的另一指令提交。
比如:
add x1, x2, x3 # x1->p1
...
sub x1, x3, x4 # p1释放当一个进程必须知道特定体系结构寄存器的内容时(如操作系统),可以一段时间不发射指令,让体系结构寄存器和物理寄存器映射关系稳定下来,再查看。
寄存器重命名的多发射策略
- 为整个指令包预留物理寄存器(4条指令最多4个)
- 判断包中存在的相关
- 如果包中指令依赖于之前的指令,则使用存放结果的物理寄存器更新指令发射信息
前瞻的重要优势就是尽早发现使流水线停顿的事件如cache miss,但是如果前瞻导致代价很大的事件如TLB miss就会得不偿失,因此只用前瞻模式处理低成本异常,如L1 cache miss。
三种情况可以通过同时推测多个分支获益
- 分支频率高
- 分支高度聚集
- 功能单元延迟长
- 前瞻执行了却不需要该结果
- 撤销前瞻并恢复处理器状态
尝试预测一条指令可能产生的值,但成功率很有限,仅对一些特定的指令会比较好(从常数池中取值)。
乱序执行的核心思想就是乱序执行,顺序确认(commit),这有可能导致当前指令提交时后续指令早已完成,而安全检查是在提交的时候进行的,这就给攻击者创造了一个很短的窗口时间,彻底攻破原本由硬件保证的内存隔离,使得一个仅仅具有普通进程权限的攻击者可以用简单的方法来读取内核内存。
- 准备阶段:黑客首先需要找到并利用一个特定的漏洞或弱点,这个漏洞或弱点是操作系统或硬件中的。这个漏洞是Meltdown攻击的核心,它允许黑客访问不应该被直接访问的内存区域。
- 创建虚拟地址空间:黑客使用恶意代码创建一个虚拟地址空间。这个空间是黑客用来执行攻击的一部分,它允许黑客映射到操作系统核心内存区域。
- 读取敏感信息:在虚拟地址空间中,黑客使用另一个程序来读取敏感信息。这个程序可能是黑客自己编写的,也可能是利用现有的漏洞或弱点。
- 触发Meltdown攻击:当该程序执行时,处理器的乱序执行机制开始工作。这个机制是CPU为了提高执行效率而采用的一种技术。然而,在Meltdown攻击中,这个机制被利用来读取不应该被直接访问的内存内容。
- 缓存读取:处理器将未经验证的内存内容缓存在缓存中。这个缓存是CPU为了提高读取速度而使用的一种技术。黑客利用Meltdown漏洞,从处理器缓存中读取敏感数据。
前瞻执行是为了解决控制相关,提前执行当前不是到是否要执行的指令,假设该指令是正确的,并继续执行后续的指令。如果该指令是错误的,处理器会回滚到之前的正确状态,并重新执行正确的指令。然而,在Spectre攻击中,黑客可以通过利用这个前瞻执行功能,让处理器误读一条指令,从而读取不应该被直接访问的内存内容,例如,黑客可以通过构造一个特殊的程序,让处理器在执行一条指令时误读为另一个指令,从而读取另一个程序的内存内容。具体而言,攻击者可以通过训练处理器的分支预测器,使得当x不满足if判断条件时也执行if内的语句,由此产生array的越界访问。攻击者通过在特定的代码段中利用分支预测的误读和越界访问来获取敏感信息。具体流程类似Meltdown攻击。
晓源Galois:《计算机体系结构:量化研究方法》第一章 Fundamentals of Quantitative Design and Analysisn量化设计与分析的基础晓源Galois:《计算机体系结构:量化研究方法》第三章 Instruction-Level Parallelism and Its Exploitation指令级并行晓源Galois:《计算机体系结构:量化研究方法》第四章 Data-Level Parallelism in Vector, SIMD, and GPU Architectures数据级并行晓源Galois:《计算机体系结构:量化研究方法》第五章 Thread-Level Parallelism线程级并行TLP晓源Galois:《计算机体系结构:量化研究方法》附录C 流水线:基础和中级概念晓源Galois:《计算机体系结构:量化研究方法》附录F Interconnection Networks互联网络晓源Galois:《计算机体系结构:量化研究方法》附录G Vector Processors in More Depth向量处理器的深入探讨
Language Execution Continuum: 编程语言的执行方式可以从纯解释执行到完全编译执行
- 解释器 (Interpreter): 一种可以直接执行用编程语言编写的指令,而不需要将它们编译成机器语言的程序
- 当效率不是十分重要的时候,选择解释高级语言
- 编译低级语言以获得能好的性能
预处理器 (Preprocessor): 在编译器实际编译源代码之前运行,处理 #define, #include, 条件语句 (if, #endif, #ifdef, #else, etc.), 宏 (Macros). 预处理器处理完所有的指令后,输出一个纯C语言文件 (pure C file),不再包含预处理指令,而包含了所有通过宏定义和文件包含所引入的内容
输入 => 输出: C / 低级语言 ==> RISC-V / 其他汇编语言,源代码被转换成了机器能够理解的指令集
e.g. foo.c ==> foo.s
优化: 改善生成的代码,以提高其性能和效率,编译过程中的一个瓶颈
输出包含: 标签 (Label) 与伪指令 (Pseudo-instructions)
输入 => 输出: 优化后的RISC-V汇编代码 (*.s) ==> 目标文件 (object file, *.o)
*.o(object) files:
- 文件头 (File header): 包含了目标文件其他部分的大小和位置信息,有助于链接器识别和处理文件的不同部分
- 文本段 (Text segment): 包含了编译后的机器码,由汇编器从汇编代码转换而来
- 数据段 (Data segment): 包含了所有静态数据的二进制表示,静态数据不会在程序运行时改变
- 符号表 (Symble table): 包含了标签和它们的相对地址 (可能被当前文件或其他文件使用),标签可以是函数名,变量名等,使得链接器和调试器可以识别和定位
- 重定位表 (Relocation table): 包含了需要定位的值,包括内部和外部到原生文件的定位信息 e.g. 同一二进制模块内定义的符号所需的调整或在其他模块或共享库中定义的符号所需要的调整
- 调试信息 (Debugging information): 包含了帮助调试器理解程序如何从源代码转换为机器码的信息 e.g. 源代码文件名、行号和变量名等
汇编器指令 (Assembler Directives): 向汇编器提供指令,但并不直接产生机器指令的二进制输出的一些关键字和指令,通常用于组织代码和数据,以及提供额外的信息
- .text: 后续的项目应该被放置在用户文本段 (机器码)中,通常包括所有的代码,并且是大多数汇编文件的最后一个段
- .data: 后续的项目放置在用户数据段 (源文件数据的二进制形式)中,是定义跨源文件的静态和全局变量的常见位置
- globl sym: 声明符号
sym为全局符号,可以在多个文件中被引用 - .string str: 将字符串
str存储在内存中,并在末尾添加一个空字符作为结束的标志 - .word w1..wn: 存储n个32位的量,连续地放在内存字节中
符号表:
- 本地文件使用符号表来替换前向引用 (在定义之前就被使用的标签)
- 其他文件用符号表来替换文件的外部引用 (没有在文件中定义而被使用的标签),C语言中,外部引用可能包括调用需要导入预定义的C头文件或自定义的函数 e.g.
#include<stdio.h>#include"yourown.h" - 符号表通常包含的内容:
- 标签:用于函数调用
- 数据:在
.data段中的任何内容 - 变量:可能在文件之间访问的变量
重定位表:
- 任何绝对标签跳转:如
jal(跳转到子例程)和jalr(跳转到寄存器地址)等控制流指令,用于执行函数调用或跳转到程序的不同部分 - 有时包括在同一个文件中定义的标签
- 外部标签:总是包括在其他文件或库文件中定义的标签
la指令:当由lui(加载上半字)定义时- 静态段中的任何数据:静态段包含程序中不会改变的数据,如全局变量和字符串常量
伪代码转换为实际指令:

- 在计算偏移量之前,要先将伪指令转化为实际的汇编指令
- 前向引用问题 (Forward Reference): 进行两次遍历,第一次遍历记录每个标签在程序中出现的具体位置,但不会立即生成对应的机器码 (符号表);第二次遍历时所有的标签位置都已知,汇编器可以准确计算出指令所需的偏移量,或者确定对静态数据的引用 (重定位)
输入 => 输出: 目标文件 (*.o) ==> 可执行文件 (.out)
链接器将每个对象文件中的代码块按顺序分类和分组,顺序由链接器决定,通常包括文本段和数据段
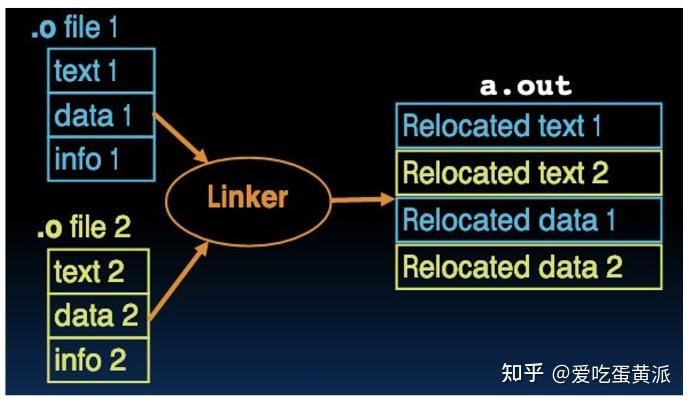
解引用 (Resolves all references):
- 符号表 ==> 对文件的引用
- 外部引用
- 遍历所有重定位项,更新地址
执行步骤 (Linker Execution):
- 合并文本段: 从每个对象文件中提取文本段 (text segment) 并将其排列组合为连续的文本段
- 合并数据段: 从每个对象文件中提取数据段 (data segment),包含了程序的初始化静态和全局变量,重新排列组合为新的连续的数据段,链接到文本的末尾
- 解引用
结果: 所有的绝对地址都被填充,程序中的所有跳转、分支和数据引用都已经被正确地解析到了最终的内存地址
*.out(executable) files:
- Header: 文本段和数据段的大小
- 文本段 + 数据段
地址的四种类型:
- PC-Relative Addressing (beq, bne, jal; auipc/addi): 相对于程序计数器 (PC) 的地址,使用当前PC值加上一个偏移量来计算目标地址,不需要重定位
- Absolute Function Address (auipc/jalr): 函数地址是指函数在内存中的确切位置,总是需要重定位,这些地址在不同程序加载是可能会发生变化
- External Function Reference (auipc/jalr; jal ext_label): 如果函数程序中引用了其他文件或库中的函数,在链接时,链接器必须解析这些外部引用并将它们转化为正确的地址,总是需要重定位
- Static Data Reference (often lui/addi): 静态数据在程序的整个生命周期保持不变,其地址需要在链接的时候被确定,总是需要重定位
解引用的方式:
- 链接器假设第一个文本段的第一个单词位于地址
0x10000处 (for RV32)或者0x40000000(for RV64) -- 这种假设用到了虚拟内存 (Virtual Memory)的概念,是通过将内存空间映射到物理内存地址来实现的 (后面会提到) - 链接器知道每个文本段和数据段的长度和顺序
- 链接器计算每个需要跳转的标签 (无论是内部还是外部)和数据引用的绝对地址
- 链接器首先在用户符号表中搜索引用的数据或者标签 (包括函数名称以及全局变量等),如果没有找到,则在库文件中搜索 e.g.
mallocorprintf,一旦找到了相应的绝对地址,就填入适当的机器码
静态和动态链接库 Static vs Dynamically Linked Libraries:
静态链接库 (上述讨论的范畴):
- 库文件的内容被复制并整合到最终的可执行文件中,包含了整个库文件 (不管函数有没有被使用)
- 如果库文件更新,这些更新不会反映到已经生成的可执行文件中,或者根据更新后的原文件重新编译
- 静态链接的可执行文件是自包含 (self-contained)的,意味着它们不需要依赖于系统中的其他库文件,从而提高了可移植性 (portable)
动态链接库:
- 节省储存空间 (不需要包含所有的库文件),减少传输时间 (可执行文件更小),减少内存占用 (多个程序可以共享同一个库代码),具有运行时开销 (run-time cost),因为需要额外的时间完成链接过程
- 如果库文件更新,所有使用该库的程序都会得到自动更新,但仅有可执行文件不够,还依赖动态链接库文件
- 主流的动态链接方法使用机器码 (machine code)作为基本的链接单位,且链接器在进行动态链接时不关心程序或库是如何编译的,即不关心使用了那个编译器或编程语言
将可执行文件 (executable)加载到内存:
可执行文件 (*.out)被加载到内存中,具体为为文本段和数据段设置相应的空间,并将它们从磁盘复制到内存空间中
初始化栈 (Stack Initialization): 初始化栈,并使用程序参数进行配置,栈指针设置在参数下方的最高位置,栈寄存器被设置为栈指针的地址
寄存器的清理和设置: 大多数其他寄存器被清零,赋予栈指针第一个空闲栈位置的地址
跳转到启动例程 (Jump to Start-up Routine):
跳转到一个启动例程,这个例程负责将程序的参数从栈复制到寄存器,并设置程序计数器 (PC),程序计数器是一类特殊用途的寄存器,保存当前正在执行的代码行的内存地址,但是不在32个通用寄存器之内
程序返回和终止: 如果主程序返回,启动例程也会使用退出系统调用来终止程序
系统依赖行为: 加载过程是系统依赖的,是操作系统的一部分
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/51157.html