
AINode 是 IoTDB 在ConfigNode、DataNode后提供的第三种内生节点,该节点通过与 IoTDB 集群的 DataNode、ConfigNode 的交互,扩展了对时间序列进行机器学习分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
系统架构如下图所示:
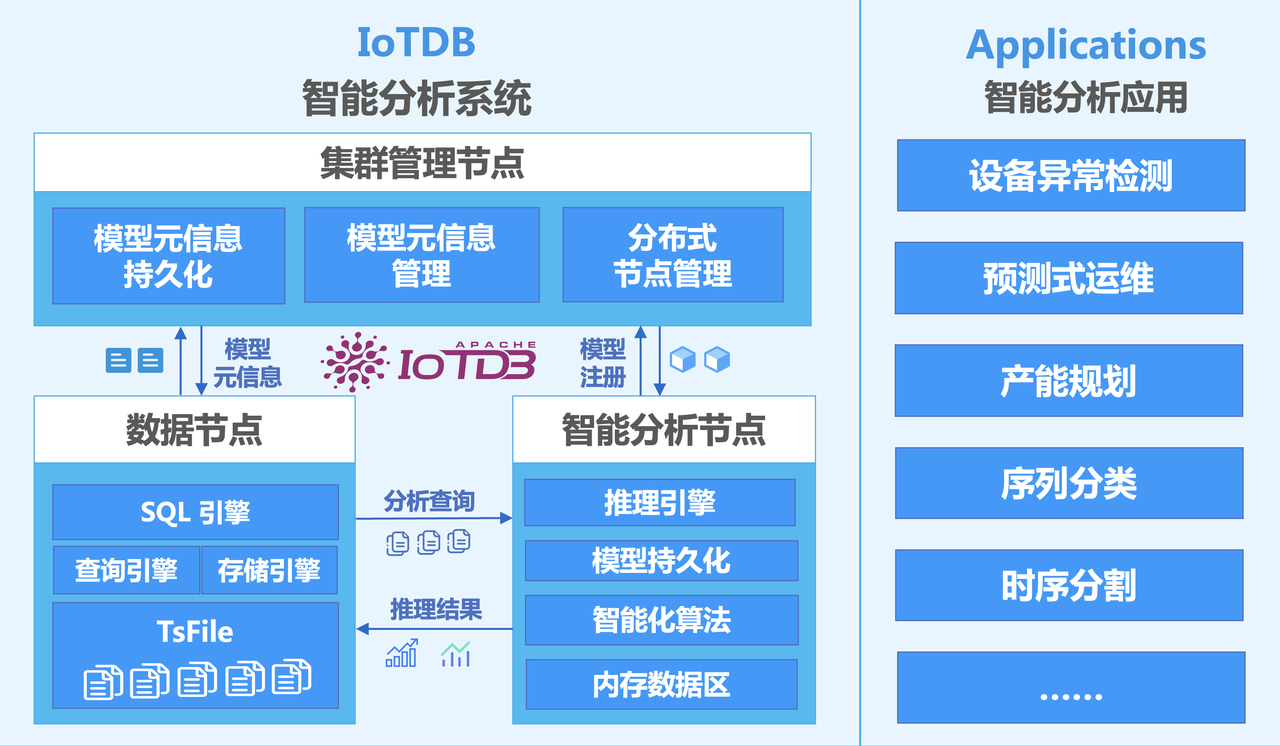
三种节点的职责如下:
- ConfigNode:负责保存和管理模型的元信息;负责分布式节点管理。
- DataNode:负责接收并解析用户的 SQL请求;负责存储时间序列数据;负责数据的预处理计算。
- AINode:负责模型文件的导入创建以及模型推理。
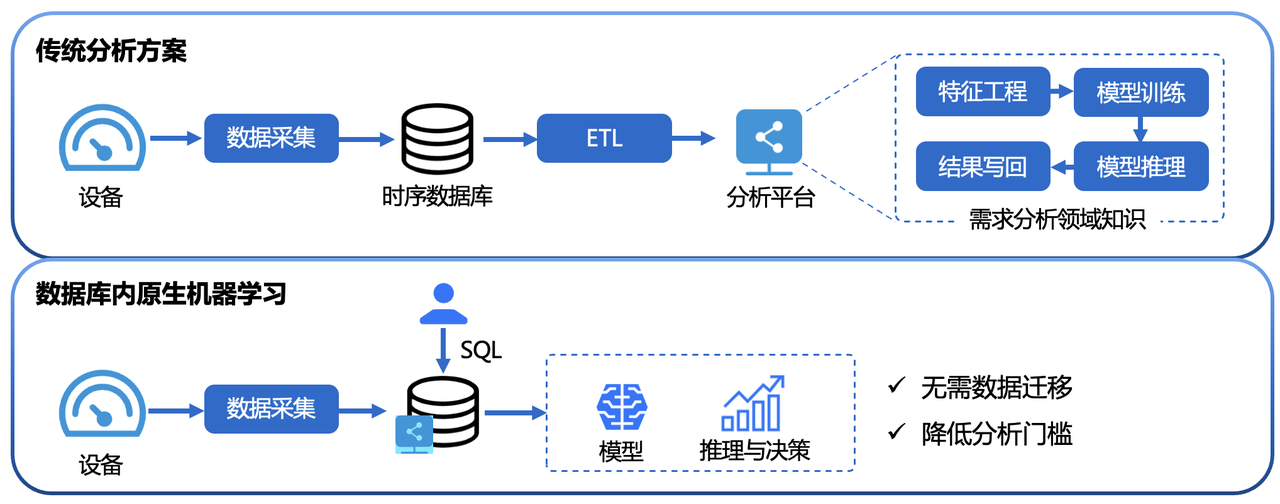
与单独构建机器学习服务相比,具有以下优势:
简单易用:无需使用 Python 或 Java 编程,使用 SQL 语句即可完成机器学习模型管理与推理的完整流程。如创建模型可使用CREATE MODEL语句、使用模型进行推理可使用CALL INFERENCE(...)语句等,使用更加简单便捷。
避免数据迁移:使用 IoTDB 原生机器学习可以将存储在 IoTDB 中的数据直接应用于机器学习模型的推理,无需将数据移动到单独的机器学习服务平台,从而加速数据处理、提高安全性并降低成本。
- 内置先进算法:支持业内领先机器学习分析算法,覆盖典型时序分析任务,为时序数据库赋能原生数据分析能力。如:
- 时间序列预测(Time Series Forecasting):从过去时间序列中学习变化模式;从而根据给定过去时间的观测值,输出未来序列最可能的预测。
- 时序异常检测(Anomaly Detection for Time Series):在给定的时间序列数据中检测和识别异常值,帮助发现时间序列中的异常行为。
- 时间序列标注(Time Series Annotation):为每个数据点或特定时间段添加额外的信息或标记,例如事件发生、异常点、趋势变化等,以便更好地理解和分析数据。
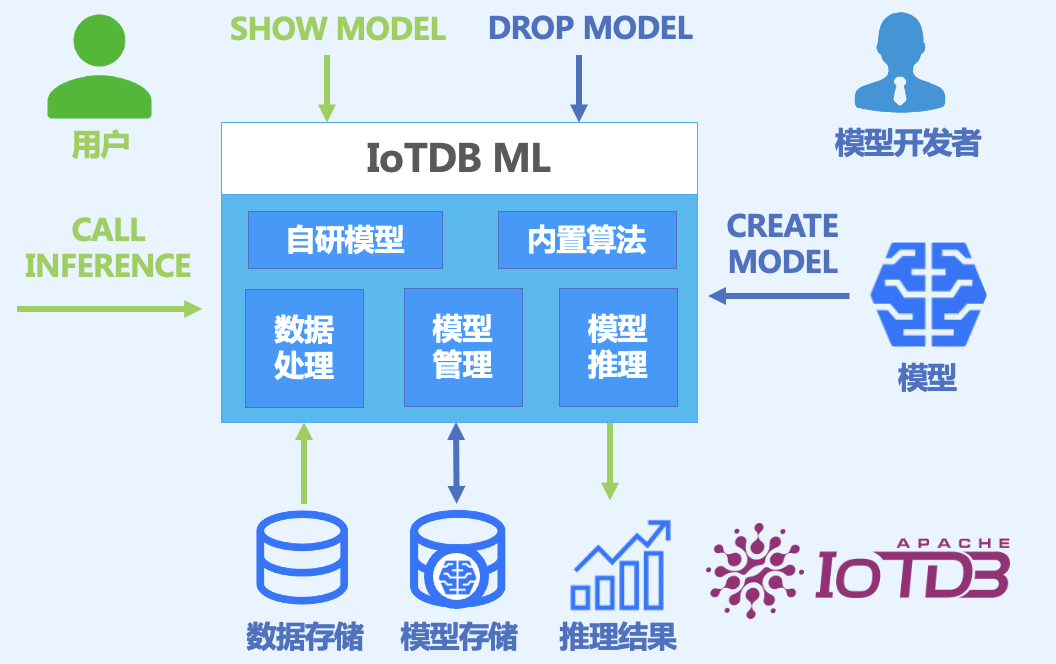
- 模型(Model):机器学习模型,以时序数据作为输入,输出分析任务的结果或决策。模型是AINode 的基本管理单元,支持模型的增(注册)、删、查、用(推理)。
- 创建(Create): 将外部设计或训练好的模型文件或算法加载到MLNode中,由IoTDB统一管理与使用。
- 推理(Inference):使用创建的模型在指定时序数据上完成该模型适用的时序分析任务的过程。
- 内置能力(Built-in):AINode 自带常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
AINode 的部署可参考文档 章节。
AINode 对时序数据相关的深度学习模型提供了模型创建及删除的流程,内置模型无需创建及删除,可直接使用,并且在完成推理后创建的内置模型实例将自动销毁。
通过指定模型输入输出的向量维度,可以注册训练好的深度学习模型,从而用于模型推理。
符合以下内容的模型可以注册到AINode中:
- AINode 支持的PyTorch 2.1.0、 2.2.0版本训练的模型,需避免使用2.2.0版本以上的特性。
- AINode支持使用PyTorch JIT存储的模型,模型文件需要包含模型的参数和结构。
- 模型输入序列可以包含一列或多列,若有多列,需要和模型能力、模型配置文件对应。
- 模型的输入输出维度必须在配置文件中明确定义。使用模型时,必须严格按照配置文件中定义的输入输出维度。如果输入输出列数不匹配配置文件,将会导致错误。
下方为模型注册的SQL语法定义。
SQL中参数的具体含义如下:
model_name:模型的全局唯一标识,不可重复。模型名称具备以下约束:
- 允许出现标识符 [ 0-9 a-z A-Z _ ] (字母,数字,下划线)
- 长度限制为2-64字符
- 大小写敏感
uri:模型注册文件的资源路径,路径下应包含模型权重model.pt文件和模型的元数据描述文件config.yaml
模型权重文件:深度学习模型训练完成后得到的权重文件,目前支持pytorch训练得到的.pt文件
yaml元数据描述文件:模型注册时需要提供的与模型结构有关的参数,其中必须包含模型的输入输出维度用于模型推理:
- 参数名参数描述示例input_shape模型输入的行列,用于模型推理[96,2]output_shape模型输出的行列,用于模型推理[48,2]
除了模型推理外,还可以指定模型输入输出的数据类型:
- 参数名参数描述示例input_type模型输入的数据类型['float32','float32']output_type模型输出的数据类型['float32','float32']
除此之外,可以额外指定备注信息用于在模型管理时进行展示
- 参数名参数描述示例attributes可选,用户自行设定的模型备注信息,用于模型展示'model_type': 'dlinear','kernel_size': '25'
除了本地模型文件的注册,还可以通过URI来指定远程资源路径来进行注册,使用开源的模型仓库(例如HuggingFace)。
在当前的example文件夹下,包含model.pt和config.yaml文件,model.pt为训练得到,config.yaml的内容如下:
指定该文件夹作为加载路径就可以注册该模型
也可以从huggingFace上下载对应的模型文件进行注册
SQL执行后会异步进行注册的流程,可以通过模型展示查看模型的注册状态(见模型展示章节),注册成功的耗时主要受到模型文件大小的影响。
模型注册完成后,就可以通过使用正常查询的方式调用具体函数,进行模型推理。
注册成功的模型可以通过show models指令查询模型的具体信息。其SQL定义如下:
除了直接展示所有模型的信息外,可以指定model id来查看某一具体模型的信息。模型展示的结果中包含如下信息:
其中,State用于展示当前模型注册的状态,包含以下三个阶段
- LOADING:已经在configNode中添加对应的模型元信息,正将模型文件传输到AINode节点上
- ACTIVE: 模型已经设置完成,模型处于可用状态
- DROPPING:模型删除中,正在从configNode以及AINode处删除模型相关信息
- UNAVAILABLE: 模型创建失败,可以通过drop model删除创建失败的model_name。
我们前面已经注册了对应的模型,可以通过对应的指定查看模型状态,active表明模型注册成功,可用于推理。
对于注册成功的模型,用户可以通过SQL进行删除。该操作除了删除configNode上的元信息外,还会删除所有AINode下的相关模型文件。其SQL如下:
需要指定已经成功注册的模型model_name来删除对应的模型。由于模型删除涉及多个节点上的数据删除,操作不会立即完成,此时模型的状态为DROPPING,该状态的模型不能用于模型推理。
SQL语法如下:
内置模型推理无需注册流程,通过call关键字,调用inference函数就可以使用模型的推理功能,其对应的参数介绍如下:
- built_in_model_name: 内置模型名称
- parameterName:参数名
- parameterValue:参数值
目前已内置如下机器学习模型,具体参数说明请参考以下链接。
下面是使用内置模型推理的一个操作示例,使用内置的Stray模型进行异常检测算法,输入为,输出为,我们通过SQL使用其进行推理。
SQL语法如下:
在完成模型的注册后,通过call关键字,调用inference函数就可以使用模型的推理功能,其对应的参数介绍如下:
- model_name: 对应一个已经注册的模型
- sql:sql查询语句,查询的结果作为模型的输入进行模型推理。查询的结果中行列的维度需要与具体模型config中指定的大小相匹配。(这里的sql不建议使用子句,因为在IoTDB中,并不会对列进行排序,因此列的顺序是未定义的,可以使用的方式确保列的顺序符合模型输入的预期)
- window_function: 推理过程中可以使用的窗口函数,目前提供三种类型的窗口函数用于辅助模型推理:
head(window_size): 获取数据中最前的window_size个点用于模型推理,该窗口可用于数据裁剪

tail(window_size):获取数据中最后的window_size个点用于模型推,该窗口可用于数据裁剪
count(window_size, sliding_step):基于点数的滑动窗口,每个窗口的数据会分别通过模型进行推理,如下图示例所示,window_size为2的窗口函数将输入数据集分为三个窗口,每个窗口分别进行推理运算生成结果。该窗口可用于连续推理
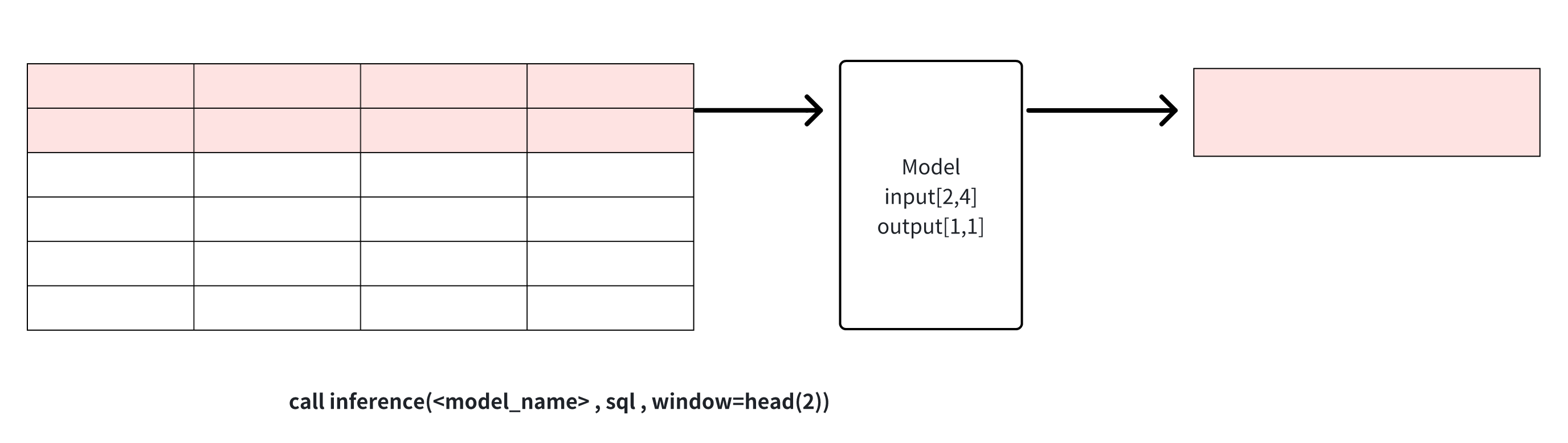
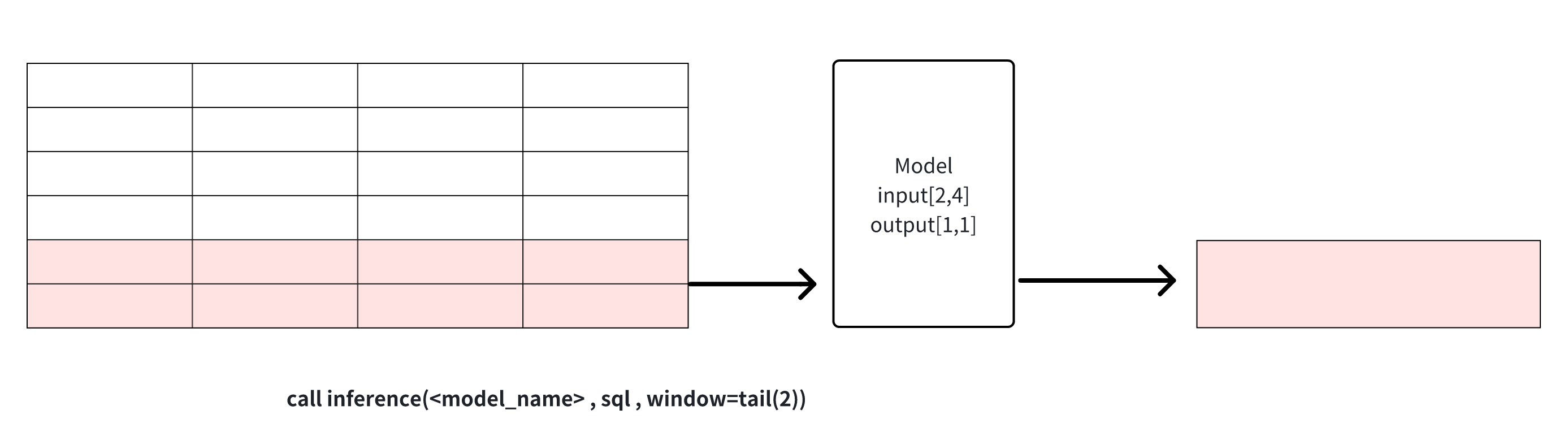
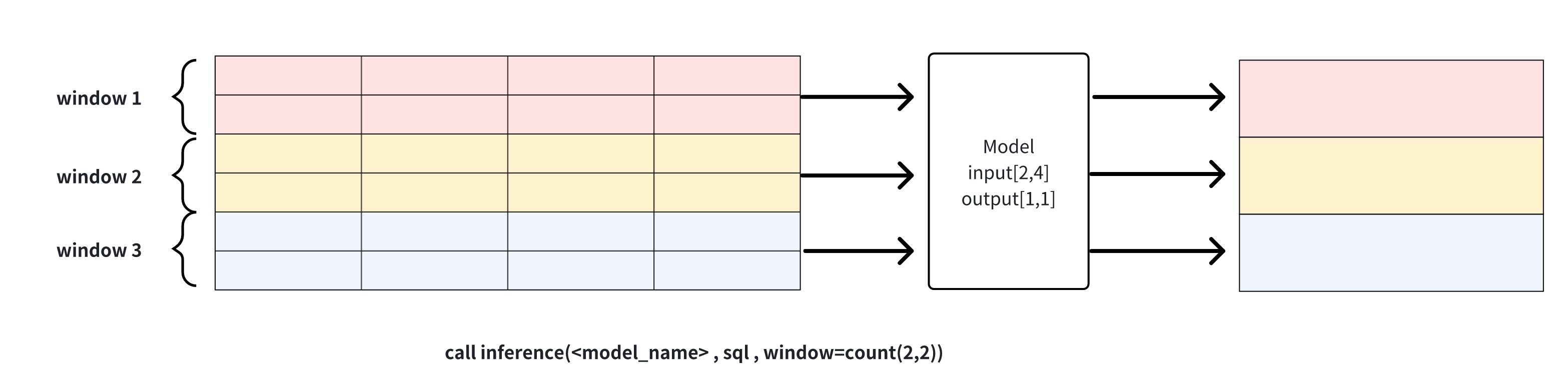
说明1: window可以用来解决sql查询结果和模型的输入行数要求不一致时的问题,对行进行裁剪。需要注意的是,当列数不匹配或是行数直接少于模型需求时,推理无法进行,会返回错误信息。
说明2: 在深度学习应用中,经常将时间戳衍生特征(数据中的时间列)作为生成式任务的协变量,一同输入到模型中以提升模型的效果,但是在模型的输出结果中一般不包含时间列。为了保证实现的通用性,模型推理结果只对应模型的真实输出,如果模型不输出时间列,则结果中不会包含。
下面是使用深度学习模型推理的一个操作示例,针对上面提到的输入为,输出为的预测模型,我们通过SQL使用其进行推理。
当数据量不定且想要取96行最新数据用于推理时,可以使用对应的窗口函数tail。head函数的用法与其类似,不同点在于其取的是最早的96个点。
该窗口主要用于计算式任务,当任务对应的模型一次只能处理固定行数据而最终想要的确实多组预测结果时,使用该窗口函数可以使用点数滑动窗口进行连续推理。假设我们现在有一个异常检测模型anomaly_example(input: [24,2], output[1,1]),对每24行数据会生成一个0/1的标签,其使用示例如下:
其中结果集中每行的标签对应每24行数据为一组,输入该异常检测模型后的输出。
使用AINode相关的功能时,可以使用IoTDB本身的鉴权去做一个权限管理,用户只有在具备 USE_MODEL 权限时,才可以使用模型管理的相关功能。当使用推理功能时,用户需要有访问输入模型的SQL对应的源序列的权限。
在部分工业场景下,会存在预测电力负载的需求,预测结果可用于优化电力供应、节约能源和资源、支持规划和扩展以及增强电力系统的可靠性。
我们所使用的 ETTh1 的测试集的数据为ETTh1。
包含间隔1h采集一次的电力数据,每条数据由负载和油温构成,分别为:High UseFul Load, High UseLess Load, Middle UseLess Load, Low UseFul Load, Low UseLess Load, Oil Temperature。
在该数据集上,IoTDB-ML的模型推理功能可以通过以往高中低三种负载的数值和对应时间戳油温的关系,预测未来一段时间内的油温,赋能电网变压器的自动调控和监视。
用户可以使用tools文件夹中的 向 IoTDB 中导入 ETT 数据集
我们可以在iotdb-cli 中输入以下SQL从 huggingface 上拉取一个已经训练好的模型进行注册,用于后续的推理。
该模型基于较为轻量化的深度模型DLinear训练而得,能够以相对快的推理速度尽可能多地捕捉到序列内部的变化趋势和变量间的数据变化关系,相较于其他更深的模型更适用于快速实时预测。
我们将对油温的预测的结果和真实结果进行对比,可以得到以下的图像。
图中10/24 00:00之前的数据为输入模型的过去数据,10/24 00:00后的蓝色线条为模型给出的油温预测结果,而红色为数据集中实际的油温数据(用于进行对比)。
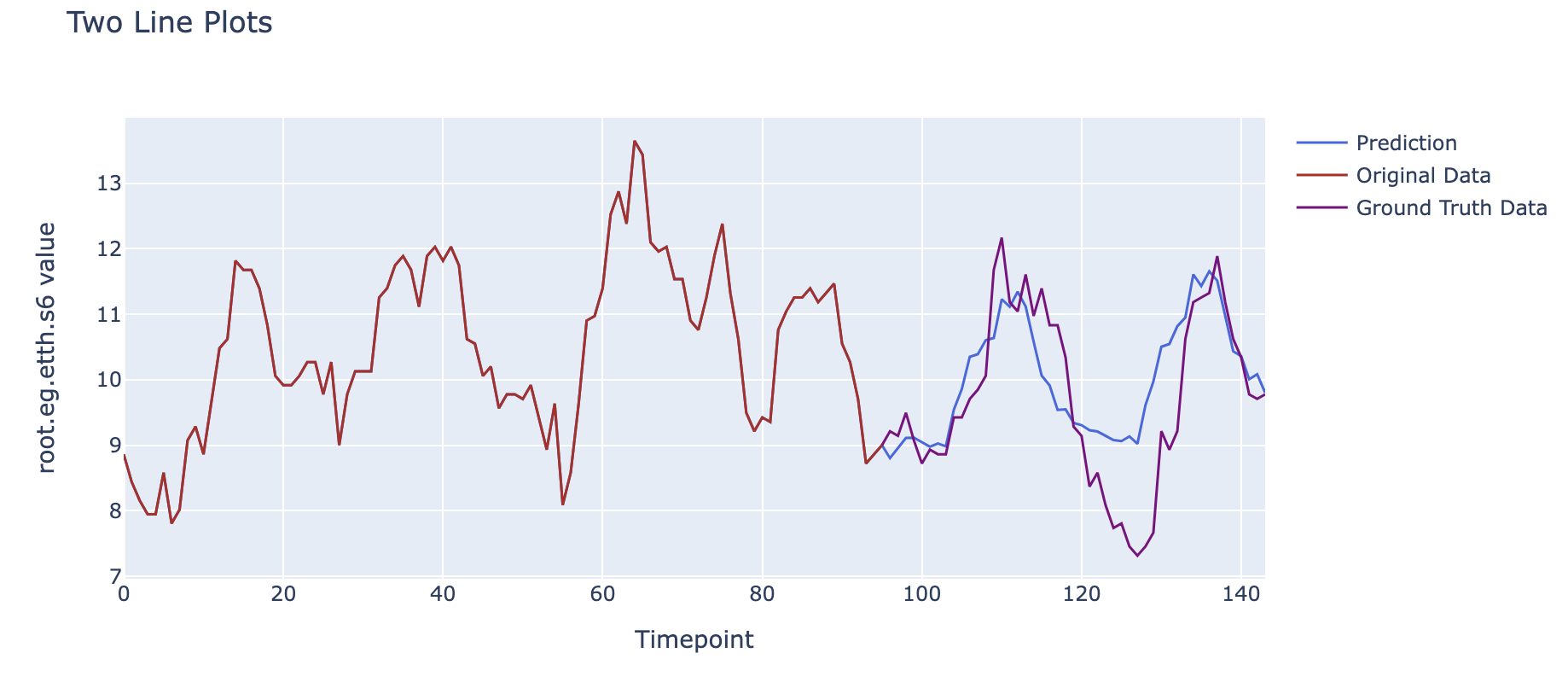
可以看到,我们使用了过去96个小时(4天)的六个负载信息和对应时间油温的关系,基于之前学习到的序列间相互关系对未来48个小时(2天)的油温这一数据的可能变化进行了建模,可以看到可视化后预测曲线与实际结果在趋势上保持了较高程度的一致性。
变电站需要对电流、电压、功率等数据进行电力监控,用于检测潜在的电网问题、识别电力系统中的故障、有效管理电网负载以及分析电力系统的性能和趋势等。
我们利用某变电站中的电流、电压和功率等数据构成了真实场景下的数据集。该数据集包括变电站近四个月时间跨度,每5 - 6s 采集一次的 A相电压、B相电压、C相电压等数据。
测试集数据内容为data。
在该数据集上,IoTDB-ML的模型推理功能可以通过以往A相电压,B相电压和C相电压的数值和对应时间戳,预测未来一段时间内的C相电压,赋能变电站的监视管理。
用户可以使用tools文件夹中的 导入数据集
我们可以在iotdb-cli 中选择内置模型或已经注册好的模型用于后续的推理。
我们采用内置模型STLForecaster进行预测,STLForecaster 是一个基于 statsmodels 库中 STL 实现的时间序列预测方法。
我们将对C相电压的预测的结果和真实结果进行对比,可以得到以下的图像。
图中 02/14 20:48 之前的数据为输入模型的过去数据, 02/14 20:48 后的蓝色线条为模型给出的C相电压预测结果,而红色为数据集中实际的C相电压数据(用于进行对比)。
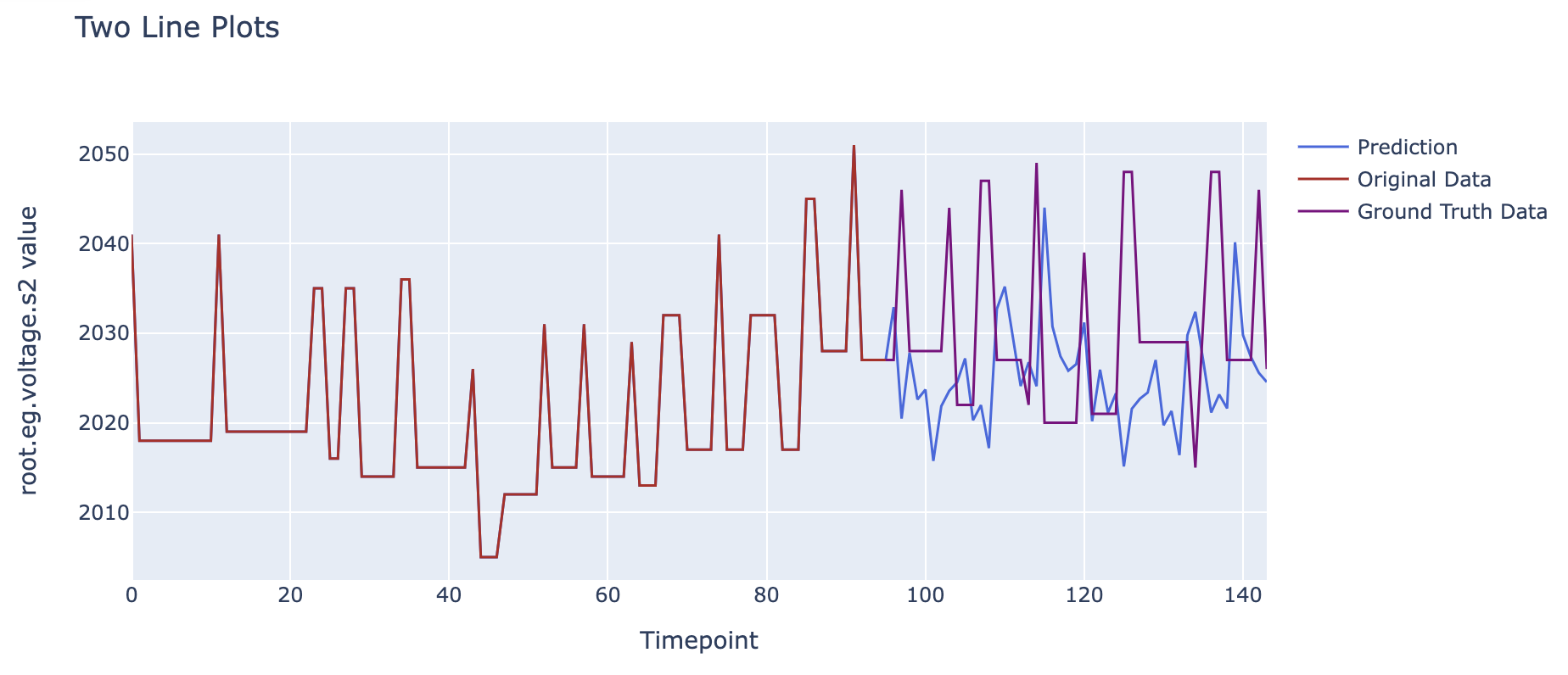
可以看到,我们使用了过去10分钟的电压的数据,基于之前学习到的序列间相互关系对未来5分钟的C相电压这一数据的可能变化进行了建模,可以看到可视化后预测曲线与实际结果在趋势上保持了一定的同步性。
在民航交通运输业,存在着对乘机旅客数量进行异常检测的需求。异常检测的结果可用于指导调整航班的调度,以使得企业获得更大效益。
Airline Passengers一个时间序列数据集,该数据集记录了1949年至1960年期间国际航空乘客数量,间隔一个月进行一次采样。该数据集共含一条时间序列。数据集为airline。
在该数据集上,IoTDB-ML的模型推理功能可以通过捕捉序列的变化规律以对序列时间点进行异常检测,赋能交通运输业。
用户可以使用tools文件夹中的 导入数据集
IoTDB内置有部分可以直接使用的机器学习算法,使用其中的异常检测算法进行预测的样例如下:
我们将检测为异常的结果进行绘制,可以得到以下图像。其中蓝色曲线为原时间序列,用红色点特殊标注的时间点为算法检测为异常的时间点。
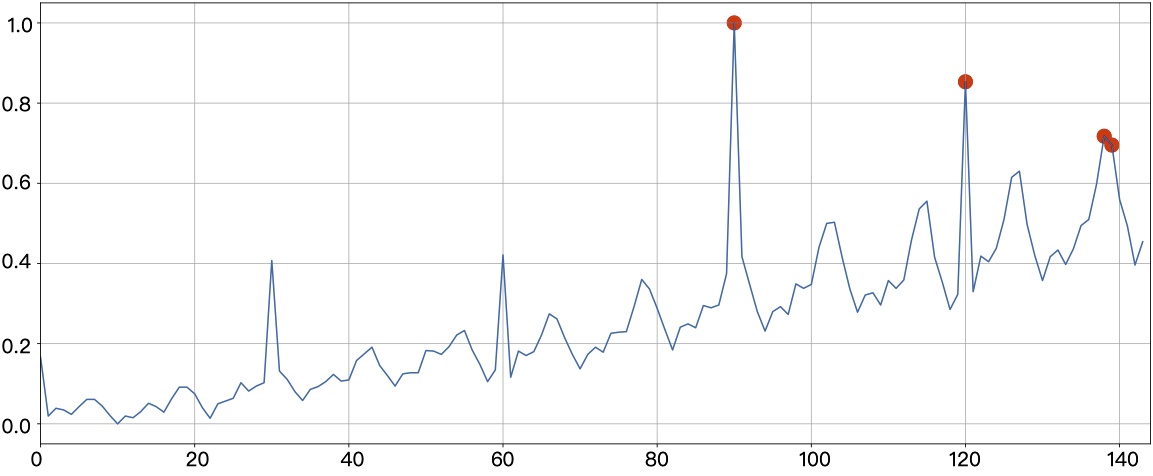
可以看到,Stray模型对输入序列变化进行了建模,成功检测出出现异常的时间点。
触发器提供了一种侦听序列数据变动的机制。配合用户自定义逻辑,可完成告警、数据转发等功能。
触发器基于 Java 反射机制实现。用户通过简单实现 Java 接口,即可实现数据侦听。IoTDB 允许用户动态注册、卸载触发器,在注册、卸载期间,无需启停服务器。
IoTDB 的单个触发器可用于侦听符合特定模式的时间序列的数据变动,如时间序列 root.sg.a 上的数据变动,或者符合路径模式 root.**.a 的时间序列上的数据变动。您在注册触发器时可以通过 SQL 语句指定触发器侦听的路径模式。
目前触发器分为两类,您在注册触发器时可以通过 SQL 语句指定类型:
- 有状态的触发器。该类触发器的执行逻辑可能依赖前后的多条数据,框架会将不同节点写入的数据汇总到同一个触发器实例进行计算,来保留上下文信息,通常用于采样或者统计一段时间的数据聚合信息。集群中只有一个节点持有有状态触发器的实例。
- 无状态的触发器。触发器的执行逻辑只和当前输入的数据有关,框架无需将不同节点的数据汇总到同一个触发器实例中,通常用于单行数据的计算和异常检测等。集群中每个节点均持有无状态触发器的实例。
触发器的触发时机目前有两种,后续会拓展其它触发时机。您在注册触发器时可以通过 SQL 语句指定触发时机:
- BEFORE INSERT,即在数据持久化之前触发。请注意,目前触发器并不支持数据清洗,不会对要持久化的数据本身进行变动。
- AFTER INSERT,即在数据持久化之后触发。
触发器的逻辑需要您编写 Java 类进行实现。
在编写触发器逻辑时,需要使用到下面展示的依赖。如果您使用 Maven,则可以直接从 Maven 库中搜索到它们。请注意选择和目标服务器版本相同的依赖版本。
编写一个触发器需要实现 类。
该类主要提供了两类编程接口:生命周期相关接口和数据变动侦听相关接口。该类中所有的接口都不是必须实现的,当您不实现它们时,它们不会对流经的数据操作产生任何响应。您可以根据实际需要,只实现其中若干接口。
下面是所有可供用户进行实现的接口的说明。
数据变动时,触发器以 Tablet 作为触发操作的单位。您可以通过 Tablet 获取相应序列的元数据和数据,然后进行相应的触发操作,触发成功则返回值应当为 true。该接口返回 false 或是抛出异常我们均认为触发失败。在触发失败时,我们会根据侦听策略接口进行相应的操作。
进行一次 INSERT 操作时,对于其中的每条时间序列,我们会检测是否有侦听该路径模式的触发器,然后将符合同一个触发器所侦听的路径模式的时间序列数据组装成一个新的 Tablet 用于触发器的 fire 接口。可以理解成:
请注意,目前我们不对触发器的触发顺序有任何保证。
下面是示例:
假设有三个触发器,触发器的触发时机均为 BEFORE INSERT
- 触发器 Trigger1 侦听路径模式:root.sg.*
- 触发器 Trigger2 侦听路径模式:root.sg.a
- 触发器 Trigger3 侦听路径模式:root.sg.b
写入语句:
序列 root.sg.a 匹配 Trigger1 和 Trigger2,序列 root.sg.b 匹配 Trigger1 和 Trigger3,那么:
- root.sg.a 和 root.sg.b 的数据会被组装成一个新的 tablet1,在相应的触发时机进行 Trigger1.fire(tablet1)
- root.sg.a 的数据会被组装成一个新的 tablet2,在相应的触发时机进行 Trigger2.fire(tablet2)
- root.sg.b 的数据会被组装成一个新的 tablet3,在相应的触发时机进行 Trigger3.fire(tablet3)
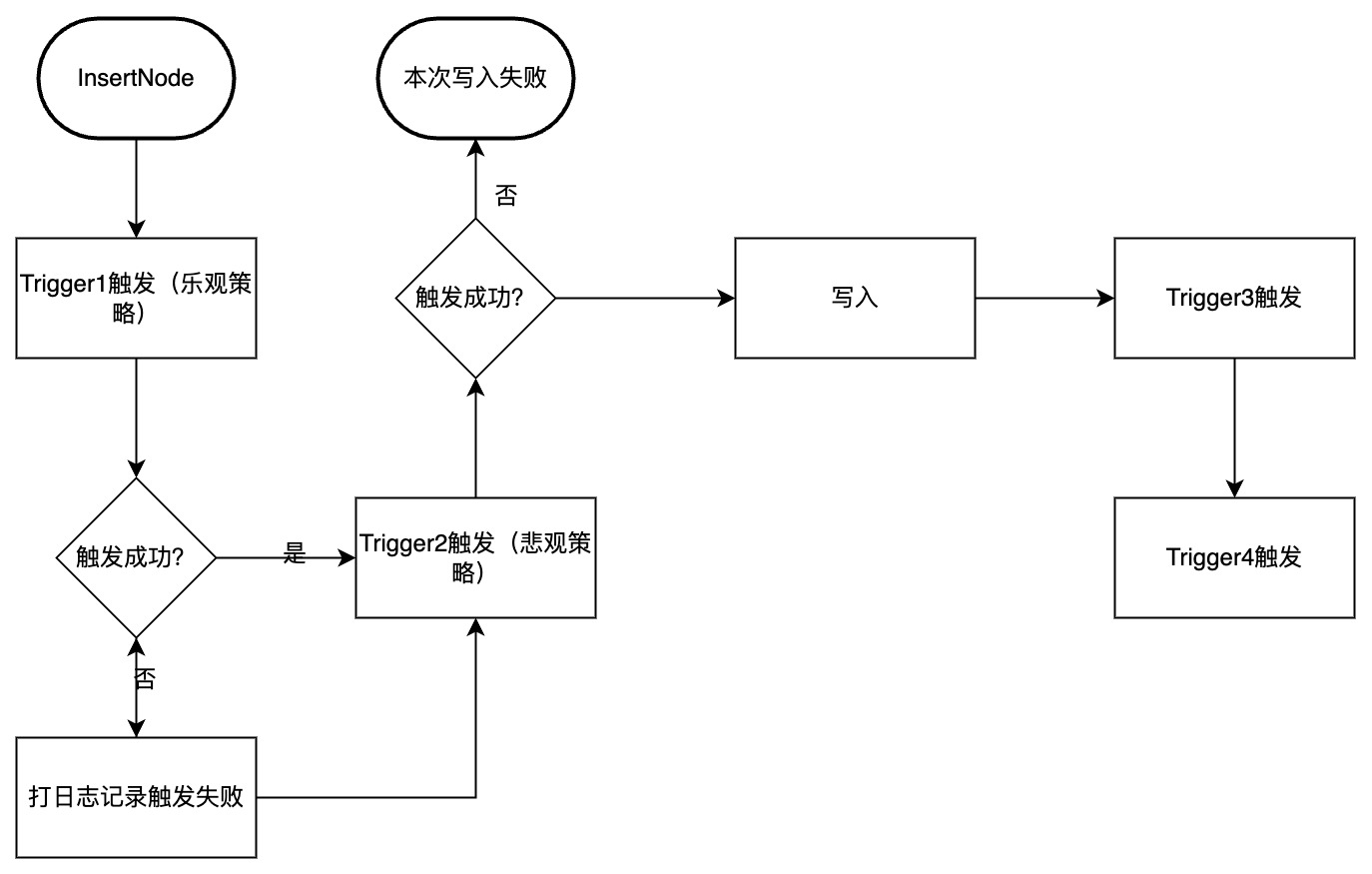
在触发器触发失败时,我们会根据侦听策略接口设置的策略进行相应的操作,您可以通过下述接口设置 ,目前有乐观和悲观两种策略:
- 乐观策略:触发失败的触发器不影响后续触发器的触发,也不影响写入流程,即我们不对触发失败涉及的序列做额外处理,仅打日志记录失败,最后返回用户写入数据成功,但触发部分失败。
- 悲观策略:失败触发器影响后续所有 Pipeline 的处理,即我们认为该 Trigger 触发失败会导致后续所有触发流程不再进行。如果该触发器的触发时机为 BEFORE INSERT,那么写入也不再进行,直接返回写入失败。
您可以参考下图辅助理解,其中 Trigger1 配置采用乐观策略,Trigger2 配置采用悲观策略。Trigger1 和 Trigger2 的触发时机是 BEFORE INSERT,Trigger3 和 Trigger4 的触发时机是 AFTER INSERT。 正常执行流程如下:
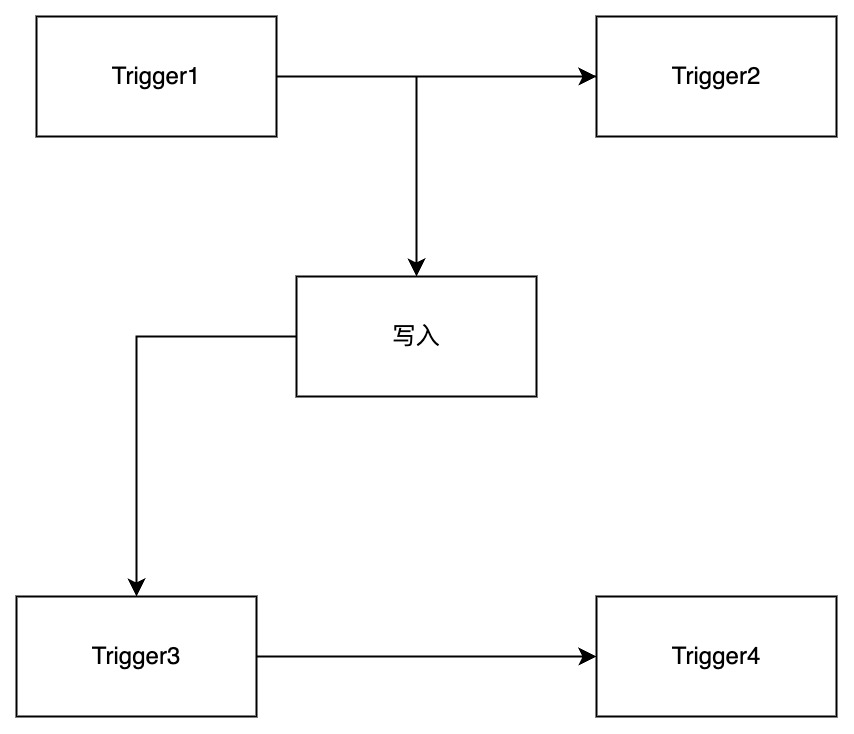
如果您使用 Maven,可以参考我们编写的示例项目 trigger-example。您可以在 这里 找到它。后续我们会加入更多的示例项目供您参考。
下面是其中一个示例项目的代码:
您可以通过 SQL 语句注册和卸载一个触发器实例,您也可以通过 SQL 语句查询到所有已经注册的触发器。
我们建议您在注册触发器时停止写入。
触发器可以注册在任意路径模式上。被注册有触发器的序列将会被触发器侦听,当序列上有数据变动时,触发器中对应的触发方法将会被调用。
注册一个触发器可以按如下流程进行:
- 按照编写触发器章节的说明,实现一个完整的 Trigger 类,假定这个类的全类名为
- 将项目打成 JAR 包。
- 使用 SQL 语句注册该触发器。注册过程中会仅只会调用一次触发器的 和 接口,具体请参考编写触发器章节。
完整 SQL 语法如下:
下面对 SQL 语法进行说明,您可以结合使用说明章节进行理解:
- triggerName:触发器 ID,该 ID 是全局唯一的,用于区分不同触发器,大小写敏感。
- triggerType:触发器类型,分为无状态(STATELESS)和有状态(STATEFUL)两类。
- triggerEventClause:触发时机,目前仅支持写入前(BEFORE INSERT)和写入后(AFTER INSERT)两种。
- pathPattern:触发器侦听的路径模式,可以包含通配符 * 和 **。
- className:触发器实现类的类名。
- uriClause:可选项,当不指定该选项时,我们默认 DBA 已经在各个 DataNode 节点的 trigger_root_dir 目录(配置项,默认为 IOTDB_HOME/ext/trigger)下放置好创建该触发器需要的 JAR 包。当指定该选项时,我们会将该 URI 对应的文件资源下载并分发到各 DataNode 的 trigger_root_dir/install 目录下。
- triggerAttributeClause:用于指定触发器实例创建时需要设置的参数,SQL 语法中该部分是可选项。
下面是一个帮助您理解的 SQL 语句示例:
上述 SQL 语句创建了一个名为 triggerTest 的触发器:
- 该触发器是无状态的(STATELESS)
- 在写入前触发(BEFORE INSERT)
- 该触发器侦听路径模式为 root.sg.**
- 所编写的触发器类名为 org.apache.iotdb.trigger.ClusterAlertingExample
- JAR 包的 URI 为 http://jar/ClusterAlertingExample.jar
- 创建该触发器实例时会传入 name 和 limit 两个参数。
可以通过指定触发器 ID 的方式卸载触发器,卸载触发器的过程中会且仅会调用一次触发器的 接口。
卸载触发器的 SQL 语法如下:
下面是示例语句:
上述语句将会卸载 ID 为 triggerTest1 的触发器。
可以通过 SQL 语句查询集群中存在的触发器的信息。SQL 语法如下:
该语句的结果集格式如下:
在集群中注册以及卸载触发器的过程中,我们维护了触发器的状态,下面是对这些状态的说明:
- 触发器从注册时开始生效,不对已有的历史数据进行处理。即只有成功注册触发器之后发生的写入请求才会被触发器侦听到。
- 触发器目前采用同步触发,所以编写时需要保证触发器效率,否则可能会大幅影响写入性能。您需要自己保证触发器内部的并发安全性。
- 集群中不能注册过多触发器。因为触发器信息全量保存在 ConfigNode 中,并且在所有 DataNode 都有一份该信息的副本。
- 建议注册触发器时停止写入。注册触发器并不是一个原子操作,注册触发器时,会出现集群内部分节点已经注册了该触发器,部分节点尚未注册成功的中间状态。为了避免部分节点上的写入请求被触发器侦听到,部分节点上没有被侦听到的情况,我们建议注册触发器时不要执行写入。
- 触发器将作为进程内程序执行,如果您的触发器编写不慎,内存占用过多,由于 IoTDB 并没有办法监控触发器所使用的内存,所以有 OOM 的风险。
- 持有有状态触发器实例的节点宕机时,我们会尝试在另外的节点上恢复相应实例,在恢复过程中我们会调用一次触发器类的 restore 接口,您可以在该接口中实现恢复触发器所维护的状态的逻辑。
- 触发器 JAR 包有大小限制,必须小于 min(, 2G),其中 是一个配置项,具体含义可以参考 IOTDB 配置项说明。
- 不同的 JAR 包中最好不要有全类名相同但功能实现不一样的类。例如:触发器 trigger1、trigger2 分别对应资源 trigger1.jar、trigger2.jar。如果两个 JAR 包里都包含一个 类,当 使用到这个类时,系统会随机加载其中一个 JAR 包中的类,最终导致触发器执行行为不一致以及其他的问题。
连续查询(Continuous queries, aka CQ) 是对实时数据周期性地自动执行的查询,并将查询结果写入指定的时间序列中。
用户可以通过连续查询实现滑动窗口流式计算,如计算某个序列每小时平均温度,并写入一个新序列中。用户可以自定义 子句去创建不同的滑动窗口,可以实现对于乱序数据一定程度的容忍。
注意:
- 如果where子句中出现任何时间过滤条件,IoTDB将会抛出异常,因为IoTDB会自动为每次查询执行指定时间范围。
- GROUP BY TIME CLAUSE在连续查询中的语法稍有不同,它不能包含原来的第一个参数,即 [start_time, end_time),IoTDB会自动填充这个缺失的参数。如果指定,IoTDB将会抛出异常。
- 如果连续查询中既没有GROUP BY TIME子句,也没有指定EVERY子句,IoTDB将会抛出异常。
- 为连续查询指定一个全局唯一的标识。
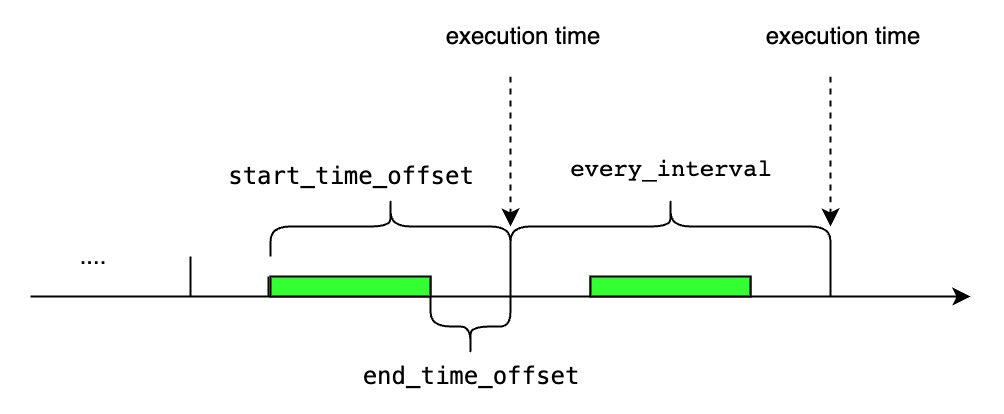
- 指定了连续查询周期性执行的间隔。现在支持的时间单位有:ns, us, ms, s, m, h, d, w, 并且它的值不能小于用户在配置文件中指定的。这是一个可选参数,默认等于group by子句中的。
- 指定了每次查询执行窗口的开始时间,即。现在支持的时间单位有:ns, us, ms, s, m, h, d, w。这是一个可选参数,默认等于子句中的。
- 指定了每次查询执行窗口的结束时间,即。现在支持的时间单位有:ns, us, ms, s, m, h, d, w。这是一个可选参数,默认等于.
- 表示用户期待的连续查询的首个周期任务的执行时间。(因为连续查询只会对当前实时的数据流做计算,所以该连续查询实际首个周期任务的执行时间并不一定等于用户指定的时间,具体计算逻辑如下所示)
- 可以早于、等于或者迟于当前时间。
- 这个参数是可选的,默认等于。
- 首次查询执行窗口的开始时间为.
- 首次查询执行窗口的结束时间为.
- 第i个查询执行窗口的时间范围是。
- 如果当前时间早于或等于, 那连续查询的首个周期任务的执行时间就是用户指定的.
- 如果当前时间迟于用户指定的,那么连续查询的首个周期任务的执行时间就是中第一个大于或等于当前时间的值。
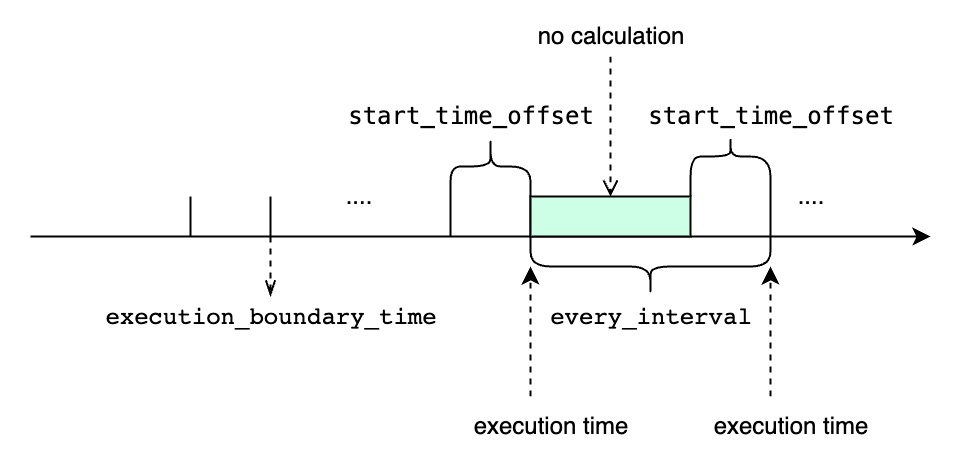
- <every_interval>,<start_time_offset> 和 <group_by_interval> 都应该大于 0
- <group_by_interval>应该小于等于<start_time_offset>
- 用户应该根据实际需求,为<start_time_offset> 和 <every_interval> 指定合适的值
- 如果<start_time_offset>大于<every_interval>,在每一次查询执行的时间窗口上会有部分重叠
- 如果<start_time_offset>小于<every_interval>,在连续的两次查询执行的时间窗口中间将会有未覆盖的时间范围
- start_time_offset 应该大于end_time_offset
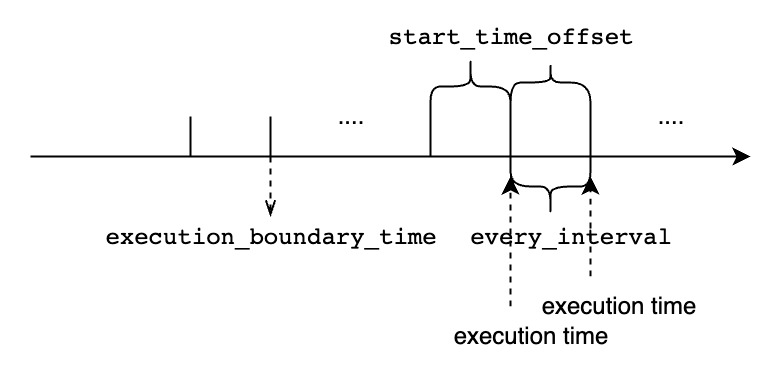
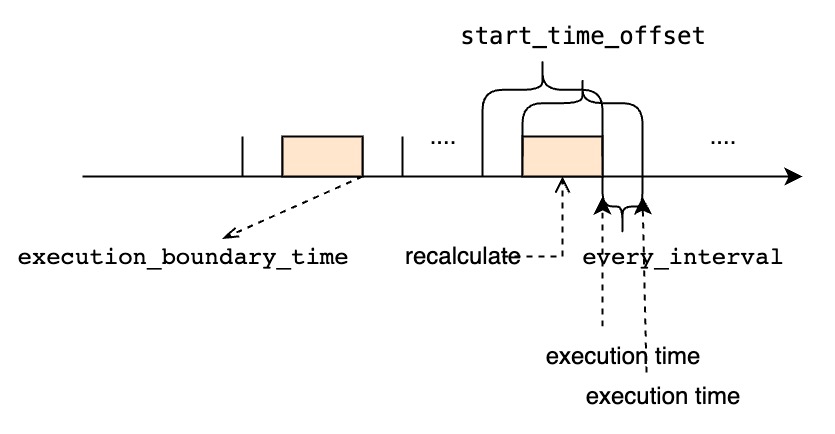
- 指定了我们如何处理“前一个时间窗口还未执行完时,下一个窗口的执行时间已经到达的场景,默认值是.
- 意味着即使下一个窗口的执行时间已经到达,我们依旧需要阻塞等待前一个时间窗口的查询执行完再开始执行下一个窗口。如果使用策略,所有的时间窗口都将会被依此执行,但是如果遇到执行查询的时间长于周期性间隔时,连续查询的结果会迟于最新的时间窗口范围。
- 意味着如果前一个时间窗口还未执行完,我们会直接丢弃下一个窗口的执行时间。如果使用策略,可能会有部分时间窗口得不到执行。但是一旦前一个查询执行完后,它将会使用最新的时间窗口,所以它的执行结果总能赶上最新的时间窗口范围,当然是以部分时间窗口得不到执行为代价。
下面是用例数据,这是一个实时的数据流,我们假设数据都按时到达。
在子句中使用参数指定连续查询的执行间隔,如果没有指定,默认等于。
计算出传感器每10秒的平均值,并且将查询结果存储在传感器下,传感器路径前缀使用跟原来一样的前缀。
每20秒执行一次,每次执行的查询的时间窗口范围是从过去20秒到当前时间。
假设当前时间是,如果把日志等级设置为DEBUG,我们可以在执行的DataNode上看到如下的输出:
并不会处理当前时间窗口以外的数据,即以前的数据,所以我们会得到如下结果:
使用子句中的参数指定连续查询每次执行的时间窗口的开始时间偏移,如果没有指定,默认值等于参数。
计算出传感器每10秒的平均值,并且将查询结果存储在传感器下,传感器路径前缀使用跟原来一样的前缀。
每10秒执行一次,每次执行的查询的时间窗口范围是从过去40秒到当前时间。
假设当前时间是,如果把日志等级设置为DEBUG,我们可以在执行的DataNode上看到如下的输出:
并不会写入全是null值的行,值得注意的是会多次计算某些区间的聚合值,下面是计算结果:
使用子句中的参数和参数分别指定连续查询的执行间隔和窗口大小。并且使用来填充没有值的时间区间。
计算出传感器每10秒的平均值,并且将查询结果存储在传感器下,传感器路径前缀使用跟原来一样的前缀。如果某些区间没有值,用填充。
每20秒执行一次,每次执行的查询的时间窗口范围是从过去40秒到当前时间。
假设当前时间是,如果把日志等级设置为DEBUG,我们可以在执行的DataNode上看到如下的输出:
值得注意的是会多次计算某些区间的聚合值,下面是计算结果:
使用子句中的参数和参数分别指定连续查询的执行间隔和窗口大小。并且使用来填充没有值的时间区间。
计算出传感器每10秒的平均值,并且将查询结果存储在传感器下,传感器路径前缀使用跟原来一样的前缀。如果某些区间没有值,用填充。
每20秒执行一次,每次执行的查询的时间窗口范围是从过去40秒到过去20秒。
假设当前时间是,如果把日志等级设置为DEBUG,我们可以在执行的DataNode上看到如下的输出:
值得注意的是只会计算每个聚合区间一次,并且每次开始执行计算的时间都会比当前的时间窗口结束时间迟20s, 下面是计算结果:
不使用子句,并在子句中显式使用参数指定连续查询的执行间隔。
计算以为前缀的所有的值,并将结果储存在另一个 database 中。除 database 名称不同外,目标序列与源序列路径名均相同。
每20秒执行一次,每次执行的查询的时间窗口范围是从过去20秒到当前时间。
假设当前时间是,如果把日志等级设置为DEBUG,我们可以在执行的DataNode上看到如下的输出:
并不会处理当前时间窗口以外的数据,即以前的数据,所以我们会得到如下结果:
展示集群中所有的已注册的连续查询
会将结果集按照排序。
执行以上sql,我们将会得到如下的查询结果:
BEGIN
SELECT count(s1)
INTO root.sg_count.d.count_s1
FROM root.sg.d
GROUP BY(30m)
ENDactive
删除指定的名为cq_id的连续查询:
DROP CQ并不会返回任何结果集。
删除名为s1_count_cq的连续查询:
目前连续查询一旦被创建就不能再被修改。如果想要修改某个连续查询,只能先用命令删除它,然后再用命令重新创建。
可以使用连续查询,定期将高频率采样的原始数据(如每秒1000个点),降采样(如每秒仅保留一个点)后保存到另一个 database 的同名序列中。高精度的原始数据所在 database 的可能设置的比较短,比如一天,而低精度的降采样后的数据所在的 database 可以设置的比较长,比如一个月,从而达到快速释放磁盘空间的目的。
我们可以通过连续查询对一些重复的查询进行预计算,并将查询结果保存在某些目标序列中,这样真实查询并不需要真的再次去做计算,而是直接查询目标序列的结果,从而缩短了查询的时间。
预计算查询结果尤其对一些可视化工具渲染时序图和工作台时有很大的加速作用。
IoTDB现在不支持子查询,但是我们可以通过创建连续查询得到相似的功能。我们可以将子查询注册为一个连续查询,并将子查询的结果物化到目标序列中,外层查询再直接查询哪个目标序列。
IoTDB并不会接收如下的嵌套子查询。这个查询会计算s1序列每隔30分钟的非空值数量的平均值:
为了得到相同的结果,我们可以:
1. 创建一个连续查询
这一步执行内层子查询部分。下面创建的连续查询每隔30分钟计算一次序列的非空值数量,并将结果写入目标序列中。
2. 查询连续查询的结果
这一步执行外层查询的avg([...])部分。
查询序列的值,并计算平均值:
SLIDING_TIME_WINDOW
SLIDING_SIZE_WINDOW
SESSION_TIME_WINDOW
STATE_WINDOW自定义时间序列生成函数,输入 k 列时间序列 m 行数据,输出 1 列时间序列 n 行数据,输入行数 m 可以与输出行数 n 不相同,只能用于SELECT子句中。UDAF-自定义聚合函数,输入 k 列时间序列 m 行数据,输出 1 列时间序列 1 行数据,可用于聚合函数出现的任何子句和表达式中,如select子句、having子句等。
功能描述
允许哪些客户端地址能连接 IoTDB
配置文件
conf/iotdb-system.properties
conf/white.list
配置项
iotdb-system.properties:
决定是否开启白名单功能
white.list:
决定哪些IP地址能够连接IoTDB
注意事项
- 如果通过session客户端取消本身的白名单,当前连接并不会立即断开。在下次创建连接的时候拒绝。
- 如果直接修改white.list,一分钟内生效。如果通过session客户端修改,立即生效,更新内存中的值和white.list磁盘文件
- 开启白名单功能,没有white.list 文件,启动DB服务成功,但是,拒绝所有连接。
- DB服务运行中,删除 white.list 文件,至多一分钟后,拒绝所有连接。
- 是否开启白名单功能的配置,可以热加载。
- 使用Java 原生接口修改白名单,必须是root用户才能修改,拒绝非root用户修改;修改内容必须合法,否则会抛出StatementExecutionException异常。
审计日志是数据库的记录凭证,通过审计日志功能可以查询到用户在数据库中增删改查等各项操作,以保证信息安全。关于IoTDB的审计日志功能可以实现以下场景的需求:
- 可以按链接来源(是否人为操作)决定是否记录审计日志,如:非人为操作如硬件采集器写入的数据不需要记录审计日志,人为操作如普通用户通过cli、workbench等工具操作的数据需要记录审计日志。
- 过滤掉系统级别的写入操作,如IoTDB监控体系本身记录的写入操作等。
通过审计日志功能追踪到所有用户在数据中的各项操作。其中所记录的信息要包含数据操作(新增、删除、查询)及元数据操作(新增、修改、删除、查询)、客户端登录信息(用户名、ip地址)。
客户端的来源
- Cli、workbench、Zeppelin、Grafana、通过 Session/JDBC/MQTT 等协议传入的请求
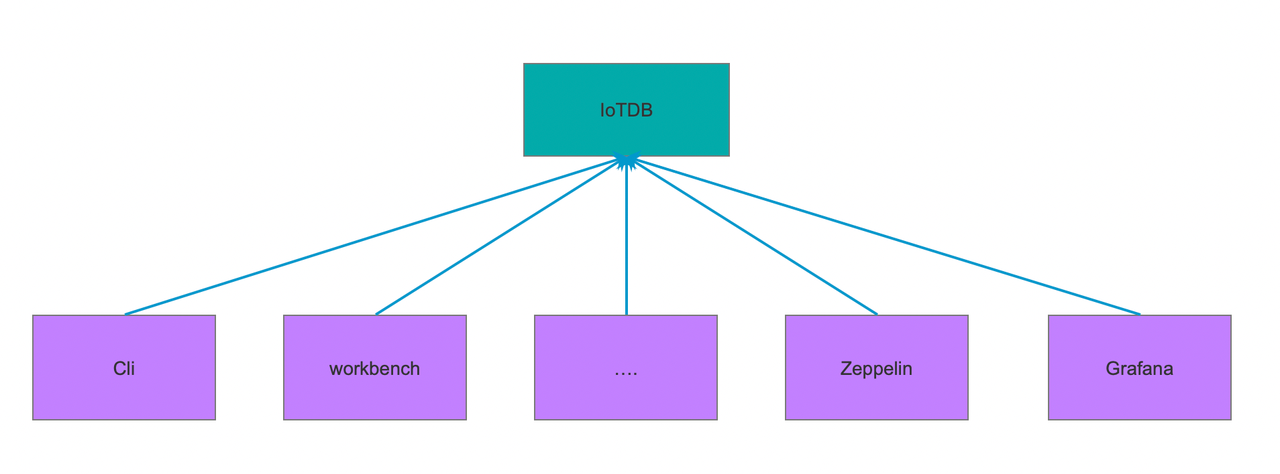
如非人为操作,硬件采集器通过 Session/JDBC/MQTT 写入的数据不需要记录审计日志
通过配置可以实现:
- 决定是否开启审计功能
- 决定审计日志的输出位置,支持输出至一项或多项
- 日志文件
- IoTDB存储
- 决定是否屏蔽原生接口的写入,防止记录审计日志过多影响性能
- 决定审计日志内容类别,支持记录一项或多项
- 数据的新增、删除操作
- 数据和元数据的查询操作
- 元数据类的新增、修改、删除操作
在iotdb-system.properties中修改以下几项配置
IoTDB 为用户提供了权限管理操作,为用户提供对数据与集群系统的权限管理功能,保障数据与系统安全。
本篇介绍IoTDB 中权限模块的基本概念、用户定义、权限管理、鉴权逻辑与功能用例。在 JAVA 编程环境中,您可以使用 单条或批量执行权限管理类语句。
用户即数据库的合法使用者。一个用户与一个唯一的用户名相对应,并且拥有密码作为身份验证的手段。一个人在使用数据库之前,必须先提供合法的(即存于数据库中的)用户名与密码,作为用户成功登录。
数据库提供多种操作,但并非所有的用户都能执行所有操作。如果一个用户可以执行某项操作,则称该用户有执行该操作的权限。权限通常需要一个路径来限定其生效范围,可以使用灵活管理权限。
角色是若干权限的集合,并且有一个唯一的角色名作为标识符。角色通常和一个现实身份相对应(例如交通调度员),而一个现实身份可能对应着多个用户。这些具有相同现实身份的用户往往具有相同的一些权限,角色就是为了能对这样的权限进行统一的管理的抽象。
安装初始化后的 IoTDB 中有一个默认用户:root,默认密码为 root。该用户为管理员用户,固定拥有所有权限,无法被赋予、撤销权限,也无法被删除,数据库内仅有一个管理员用户。
一个新创建的用户或角色不具备任何权限。
拥有 MANAGE_USER、MANAGE_ROLE 的用户或者管理员可以创建用户或者角色,需要满足以下约束:
4~32个字符,支持使用英文大小写字母、数字、特殊字符()
用户无法创建和管理员用户同名的用户。
4~32个字符,可使用大写小写字母、数字、特殊字符(),密码默认采用 MD5 进行加密。
4~32个字符,支持使用英文大小写字母、数字、特殊字符()
用户无法创建和管理员用户同名的角色。
IoTDB 主要有两类权限:序列权限、全局权限。
序列权限约束了用户访问数据的范围与方式,支持对绝对路径与前缀匹配路径授权,可对timeseries 粒度生效。
下表描述了这类权限的种类与范围:
允许插入、删除授权路径下的的序列数据。
允许在授权路径下导入、加载数据,在导入数据时,需要拥有对应路径的 WRITE_DATA 权限,在自动创建数据库与序列时,需要有 MANAGE_DATABASE 与 WRITE_SCHEMA 权限。READ_SCHEMA允许获取授权路径下元数据树的详细信息:
包括:路径下的数据库、子路径、子节点、设备、序列、模版、视图等。WRITE_SCHEMA允许获取授权路径下元数据树的详细信息。
允许在授权路径下对序列、模版、视图等进行创建、删除、修改操作。
在创建或修改 view 的时候,会检查 view 路径的 WRITE_SCHEMA 权限、数据源的 READ_SCHEMA 权限。
在对 view 进行查询、插入时,会检查 view 路径的 READ_DATA 权限、WRITE_DATA 权限。
允许在授权路径下设置、取消、查看TTL。
允许在授权路径下挂载或者接触挂载模板。
全局权限约束了用户使用的数据库功能、限制了用户执行改变系统状态与任务状态的命令,用户获得全局授权后,可对数据库进行管理。
下表描述了系统权限的种类:
允许用户将角色授予给其他用户,或取消其他用户的角色。USE_TRIGGER- 允许用户创建、删除、查看触发器。
与触发器的数据源权限检查相独立。USE_UDF- 允许用户创建、删除、查看用户自定义函数。
与自定义函数的数据源权限检查相独立。USE_CQ- 允许用户创建、开始、停止、删除、查看管道。
允许用户创建、删除、查看管道插件。
与管道的数据源权限检查相独立。USE_PIPE- 允许用户注册、开始、停止、卸载、查询流处理任务。
- 允许用户注册、卸载、查询注册流处理任务插件。EXTEND_TEMPLATE- 允许自动扩展模板。MAINTAIN- 允许用户查询、取消查询。
允许用户查看变量。
允许用户查看集群状态。USE_MODEL- 允许用户创建、删除、查询深度学习模型
关于模板权限:
- 模板的创建、删除、修改、查询、挂载、卸载仅允许管理员操作。
- 激活模板需要拥有激活路径的 WRITE_SCHEMA 权限
- 若开启了自动创建,在向挂载了模板的不存在路径写入时,数据库会自动扩展模板并写入数据,因此需要有 EXTEND_TEMPLATE 权限与写入序列的 WRITE_DATA 权限。
- 解除模板,需要拥有挂载模板路径的 WRITE_SCHEMA 权限。
- 查询使用了某个元数据模板的路径,需要有路径的 READ_SCHEMA 权限,否则将返回为空。
在 IoTDB 中,用户可以由三种途径获得权限:
- 由超级管理员授予,超级管理员可以控制其他用户的权限。
- 由允许权限授权的用户授予,该用户获得权限时被指定了 grant option 关键字。
- 由超级管理员或者有 MANAGE_ROLE 的用户授予某个角色进而获取权限。
取消用户的权限,可以由以下几种途径:
- 由超级管理员取消用户的权限。
- 由允许权限授权的用户取消权限,该用户获得权限时被指定了 grant option 关键字。
- 由超级管理员或者MANAGE_ROLE 的用户取消用户的某个角色进而取消权限。
- 在授权时,必须指定路径。全局权限需要指定为 root.**, 而序列相关权限必须为绝对路径或者以双通配符结尾的前缀路径。
- 当授予角色权限时,可以为该权限指定 with grant option 关键字,意味着用户可以转授其授权路径上的权限,也可以取消其他用户的授权路径上的权限。例如用户 A 在被授予的读权限时制定了 grant option 关键字,那么 A 可以将以下的任意节点、序列的读权限转授给他人, 同样也可以取消其他用户 下任意节点的读权限。
- 在取消授权时,取消授权语句会与用户所有的权限路径进行匹配,将匹配到的权限路径进行清理,例如用户A 具有 的读权限, 在取消 的读权限时,会清除用户A 的 的读权限。
用户权限主要由三部分组成:权限生效范围(路径), 权限类型, with grant option 标记:
每个用户都有一个这样的权限访问列表,标识他们获得的所有权限,可以通过 查看他们的权限。
在对一个路径进行鉴权时,数据库会进行路径与权限的匹配。例如检查 的 read_schema 权限时,首先会与权限访问列表的 进行匹配,匹配成功,则检查该路径是否包含待鉴权的权限,否则继续下一条路径-权限的匹配,直到匹配成功或者匹配结束。
在进行多路径鉴权时,对于多路径查询任务,数据库只会将有权限的数据呈现出来,无权限的数据不会包含在结果中;对于多路径写入任务,数据库要求必须所有的目标序列都获得了对应的权限,才能进行写入。
请注意,下面的操作需要检查多重权限
- 开启了自动创建序列功能,在用户将数据插入到不存在的序列中时,不仅需要对应序列的写入权限,还需要序列的元数据修改权限。
- 执行 select into 语句时,需要检查源序列的读权限与目标序列的写权限。需要注意的是源序列数据可能因为权限不足而仅能获取部分数据,目标序列写入权限不足时会报错终止任务。
- View 权限与数据源的权限是独立的,向 view 执行读写操作仅会检查 view 的权限,而不再对源路径进行权限校验。
IoTDB 提供了组合权限,方便用户授权:
组合权限并不是一种具体的权限,而是一种简写方式,与直接书写对应的权限名称没有差异。
下面将通过一系列具体的用例展示权限语句的用法,非管理员执行下列语句需要提前获取权限,所需的权限标记在操作描述后。
- 创建用户(需 MANAGE_USER 权限)
- 删除用户 (需 MANEGE_USER 权限)
- 创建角色 (需 MANAGE_ROLE 权限)
- 删除角色 (需 MANAGE_ROLE 权限)
- 赋予用户角色 (需 MANAGE_ROLE 权限)
- 移除用户角色 (需 MANAGE_ROLE 权限)
- 列出所有用户 (需 MANEGE_USER 权限)
- 列出所有角色 (需 MANAGE_ROLE 权限)
- 列出指定角色下所有用户 (需 MANEGE_USER 权限)
- 列出指定用户下所有角色
用户可以列出自己的角色,但列出其他用户的角色需要拥有 MANAGE_ROLE 权限。
- 列出用户所有权限
用户可以列出自己的权限信息,但列出其他用户的权限需要拥有 MANAGE_USER 权限。
- 列出角色所有权限
用户可以列出自己具有的角色的权限信息,列出其他角色的权限需要有 MANAGE_ROLE 权限。
- 更新密码
用户可以更新自己的密码,但更新其他用户密码需要具备MANAGE_USER 权限。
用户使用授权语句对赋予其他用户权限,语法如下:
用户使用取消授权语句可以将其他的权限取消,语法如下:
非管理员用户执行授权/取消授权语句时,需要对<PATHS> 有<PRIVILEGES> 权限,并且该权限是被标记带有 WITH GRANT OPTION 的。
在授予取消全局权限时,或者语句中包含全局权限时(ALL 展开会包含全局权限),须指定 path 为 root.**。 例如,以下授权/取消授权语句是合法的:
下面的语句是非法的:
<PATH> 必须为全路径或者以双通配符结尾的匹配路径,以下路径是合法的:
以下的路径是非法的:
根据本文中描述的 样例数据 内容,IoTDB 的样例数据可能同时属于 ln, sgcc 等不同发电集团,不同的发电集团不希望其他发电集团获取自己的数据库数据,因此我们需要将不同的数据在集团层进行权限隔离。
使用 创建用户。例如,我们可以使用具有所有权限的root用户为 ln 和 sgcc 集团创建两个用户角色,名为 ln_write_user, sgcc_write_user,密码均为 write_pwd。建议使用反引号(`)包裹用户名。SQL 语句为:
此时使用展示用户的 SQL 语句:
我们可以看到这两个已经被创建的用户,结果如下:
此时,虽然两个用户已经创建,但是他们不具有任何权限,因此他们并不能对数据库进行操作,例如我们使用 ln_write_user 用户对数据库中的数据进行写入,SQL 语句为:
此时,系统不允许用户进行此操作,会提示错误:
现在,我们用 root 用户分别赋予他们向对应路径的写入权限.
我们使用 语句赋予用户权限,例如:
执行状态如下所示:
接着使用ln_write_user再尝试写入数据
授予用户权限后,我们可以使用 来撤销已经授予用户的权限。例如,用root用户撤销ln_write_user和sgcc_write_user的权限:
执行状态如下所示:
撤销权限后,ln_write_user就没有向root.ln.**写入数据的权限了。
角色是权限的集合,而权限和角色都是用户的一种属性。即一个角色可以拥有若干权限。一个用户可以拥有若干角色与权限(称为用户自身权限)。
目前在 IoTDB 中并不存在相互冲突的权限,因此一个用户真正具有的权限是用户自身权限与其所有的角色的权限的并集。即要判定用户是否能执行某一项操作,就要看用户自身权限或用户的角色的所有权限中是否有一条允许了该操作。用户自身权限与其角色权限,他的多个角色的权限之间可能存在相同的权限,但这并不会产生影响。
需要注意的是:如果一个用户自身有某种权限(对应操作 A),而他的某个角色有相同的权限。那么如果仅从该用户撤销该权限无法达到禁止该用户执行操作 A 的目的,还需要从这个角色中也撤销对应的权限,或者从这个用户将该角色撤销。同样,如果仅从上述角色将权限撤销,也不能禁止该用户执行操作 A。
同时,对角色的修改会立即反映到所有拥有该角色的用户上,例如对角色增加某种权限将立即使所有拥有该角色的用户都拥有对应权限,删除某种权限也将使对应用户失去该权限(除非用户本身有该权限)。
在 1.3 版本前,权限类型较多,在这一版实现中,权限类型做了精简,并且添加了对权限路径的约束。
数据库 1.3 版本的权限路径必须为全路径或者以双通配符结尾的匹配路径,在系统升级时,会自动转换不合法的权限路径和权限类型。
路径上首个非法节点会被替换为, 不在支持的权限类型也会映射到当前系统支持的权限上。
例如:
新旧版本的权限类型对照可以参照下面的表格(--IGNORE 表示新版本忽略该权限):
查询分析的意义在于帮助用户理解查询的执行机制和性能瓶颈,从而实现查询优化和性能提升。这不仅关乎到查询的执行效率,也直接影响到应用的用户体验和资源的有效利用。为了进行有效的查询分析,IoTDB V1.3.2及以上版本提供了查询分析语句:Explain 和 Explain Analyze。
- Explain 语句:允许用户预览查询 SQL 的执行计划,包括 IoTDB 如何组织数据检索和处理。
- Explain Analyze 语句:在 Explain 语句基础上增加了性能分析,完整执行SQL并展示查询执行过程中的时间和资源消耗。为IoTDB用户深入理解查询详情以及进行查询优化提供了详细的相关信息。与其他常用的 IoTDB 排查手段相比,Explain Analyze 没有部署负担,同时能够针对单条 sql 进行分析,能够更好定位问题。各类方法对比如下:
Explain命令允许用户查看SQL查询的执行计划。执行计划以算子的形式展示,描述了IoTDB会如何执行查询。其语法如下,其中SELECT_STATEMENT是查询相关的SQL语句:
Explain的返回结果包括了数据访问策略、过滤条件是否下推以及查询计划在不同节点的分配等信息,为用户提供了一种手段,以可视化查询的内部执行逻辑。
执行上方SQL,会得到如下结果。不难看出,IoTDB分别通过两个SeriesScan节点去获取column1和column2的数据,最后通过fullOuterTimeJoin将其连接。
Explain Analyze 是 IOTDB 查询引擎自带的性能分析 SQL,与 Explain 不同,它会执行对应的查询计划并统计执行信息,可以用于追踪一条查询的具体性能分布,用于对资源进行观察,进行性能调优与异常分析。其语法如下:
其中SELECT_STATEMENT对应需要分析的查询语句;VERBOSE为打印详细分析结果,不填写VERBOSE时EXPLAIN ANALYZE将会省略部分信息。
在EXPLAIN ANALYZE的结果集中,会包含如下信息:
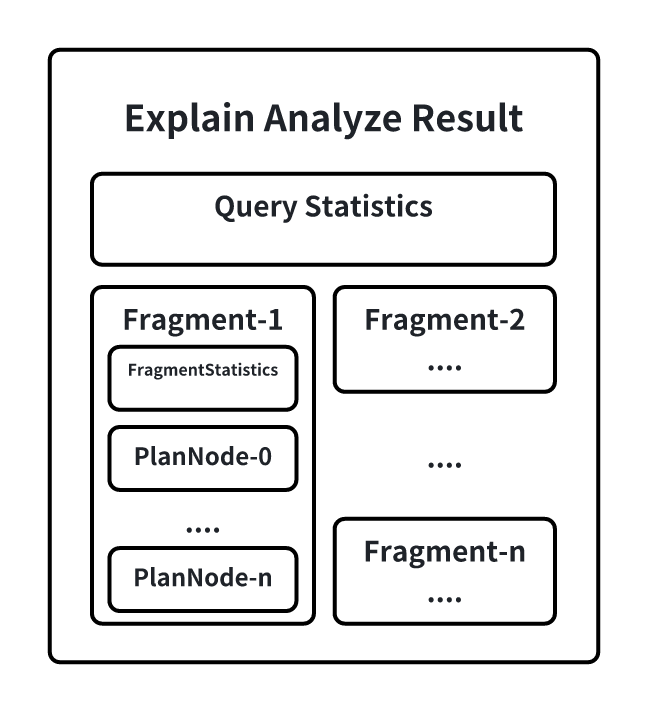
其中:
- QueryStatistics包含查询层面进的统计信息,主要包含规划解析阶段耗时,Fragment元数据等信息。
- FragmentInstance是IoTDB在一个节点上查询计划的封装,每一个节点都会在结果集中输出一份Fragment信息,主要包含FragmentStatistics和算子信息。FragmentStastistics包含Fragment的统计信息,包括总实际耗时(墙上时间),所涉及到的TsFile,调度信息等情况。在一个Fragment的信息输出同时会以节点树层级的方式展示该Fragment下计划节点的统计信息,主要包括:CPU运行时间、输出的数据行数、指定接口被调用的次数、所占用的内存、节点专属的定制信息。
- Explain Analyze 语句的结果简化
由于在 Fragment 中会输出当前节点中执行的所有节点信息,当一次查询涉及的序列过多时,每个节点都被输出,会导致 Explain Analyze 返回的结果集过大,因此当相同类型的节点超过 10 个时,系统会自动合并当前 Fragment 下所有相同类型的节点,合并后统计信息也被累积,对于一些无法合并的定制信息会直接丢弃(如下图)。
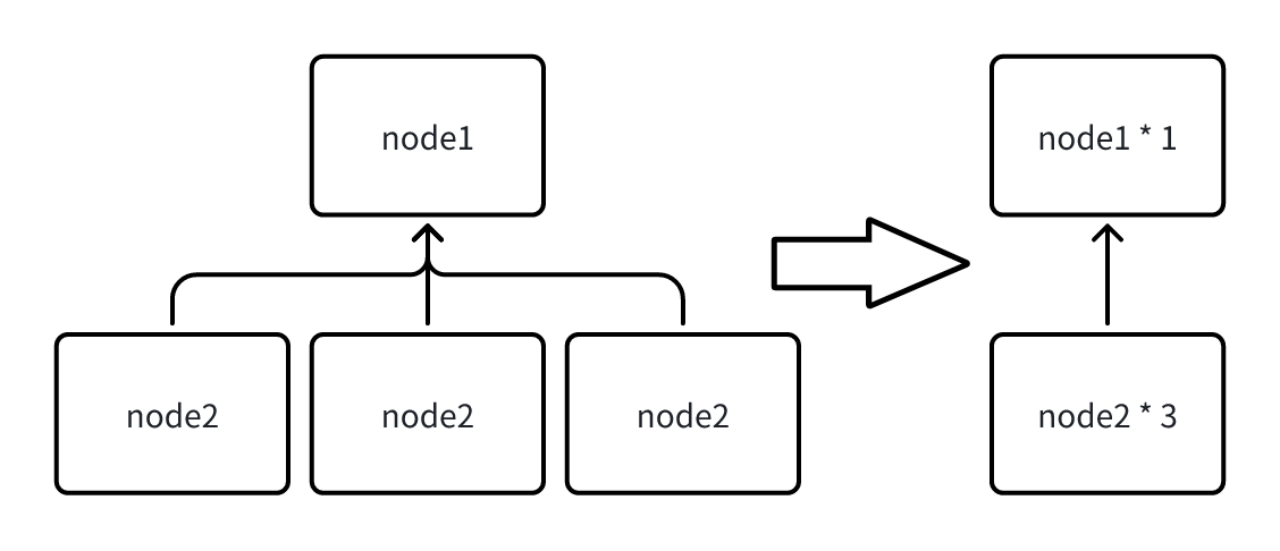
用户也可以自行修改 iotdb-system.properties 中的配置项来设置触发合并的节点阈值,该参数支持热加载。
- 查询超时场景使用 Explain Analyze 语句
Explain Analyze 本身是一种特殊的查询,当执行超时的时候,无法使用Explain Analyze语句进行分析。为了在查询超时的情况下也可以通过分析结果排查超时原因,Explain Analyze还提供了定时日志机制(无需用户配置),每经过一定的时间间隔会将 Explain Analyze 的当前结果以文本的形式输出到专门的日志中。当查询超时时,用户可以前往logs/log_explain_analyze.log中查看对应的日志进行排查。
日志的时间间隔基于查询的超时时间进行计算,可以保证在超时的情况下至少会有两次的结果记录。
下面是Explain Analyze的一个例子:
得到输出如下:
触发合并后的部分结果示例如下:
CPU 时间也称为处理器时间或处理器使用时间,指的是程序在执行过程中实际占用 CPU 进行计算的时间,显示的是程序实际消耗的处理器资源。
墙上时间也称为实际时间或物理时间,指的是从程序开始执行到程序结束的总时间,包括了所有等待时间。
- WALL TIME < CPU TIME 的场景:比如一个查询分片最后被调度器使用两个线程并行执行,真实物理世界上是 10s 过去了,但两个线程,可能一直占了两个 cpu 核跑了 10s,那 cpu time 就是 20s,wall time就是 10s
- WALL TIME > CPU TIME 的场景:因为系统内可能会存在多个查询并行执行,但查询的执行线程数和内存是固定的,
- 所以当查询分片被某些资源阻塞住时(比如没有足够的内存进行数据传输、或等待上游数据)就会放入Blocked Queue,此时查询分片并不会占用 CPU TIME,但WALL TIME(真实物理时间的时间)是在向前流逝的
- 或者当查询线程资源不足时,比如当前共有16个查询线程,但系统内并发有20个查询分片,即使所有查询都没有被阻塞,也只会同时并行运行16个查询分片,另外四个会被放入 READY QUEUE,等待被调度执行,此时查询分片并不会占用 CPU TIME,但WALL TIME(真实物理时间的时间)是在向前流逝的
几乎没有,因为 explain analyze operator 是单独的线程执行,收集原查询的统计信息,且这些统计信息,即使不explain analyze,原来的查询也会生成,只是没有人去取。并且 explain analyze 是纯 next 遍历结果集,不会打印,所以与原来查询真实执行时的耗时不会有显著差别。
可能涉及 IO 耗时的主要有个指标,loadTimeSeriesMetadataDiskSeqTime, loadTimeSeriesMetadataDiskUnSeqTime 以及 construct[NonAligned/Aligned]ChunkReadersDiskTime
TimeSeriesMetadata 的加载分别统计了顺序和乱序文件,但 Chunk 的读取暂时未分开统计,但顺乱序比例可以通过TimeseriesMetadata 顺乱序的比例计算出来。
乱序数据产生的影响主要有两个:
- 需要在内存中多做一个归并排序(一般认为这个耗时是比较短的,毕竟是纯内存的 cpu 操作)
- 乱序数据会产生数据块间的时间范围重叠,导致统计信息无法使用
- 无法利用统计信息直接 skip 掉整个不满足值过滤要求的 chunk
- 一般用户的查询都是只包含时间过滤条件,则不会有影响
- 无法利用统计信息直接计算出聚合值,无需读取数据
- 无法利用统计信息直接 skip 掉整个不满足值过滤要求的 chunk
单独对于乱序数据的性能影响,目前并没有有效的观测手段,除非就是在有乱序数据的时候,执行一遍查询耗时,然后等乱序合完了,再执行一遍,才能对比出来。
因为即使乱序这部分数据进了顺序,也是需要 IO、加压缩、decode,这个耗时少不了,不会因为乱序数据被合并进乱序了,就减少了。
升级时,只替换了 lib 包,没有替换 conf/logback-datanode.xml,需要替换一下 conf/logback-datanode.xml,然后不需要重启(该文件内容可以被热加载),大约等待 1 分钟后,重新执行 explain analyze verbose。
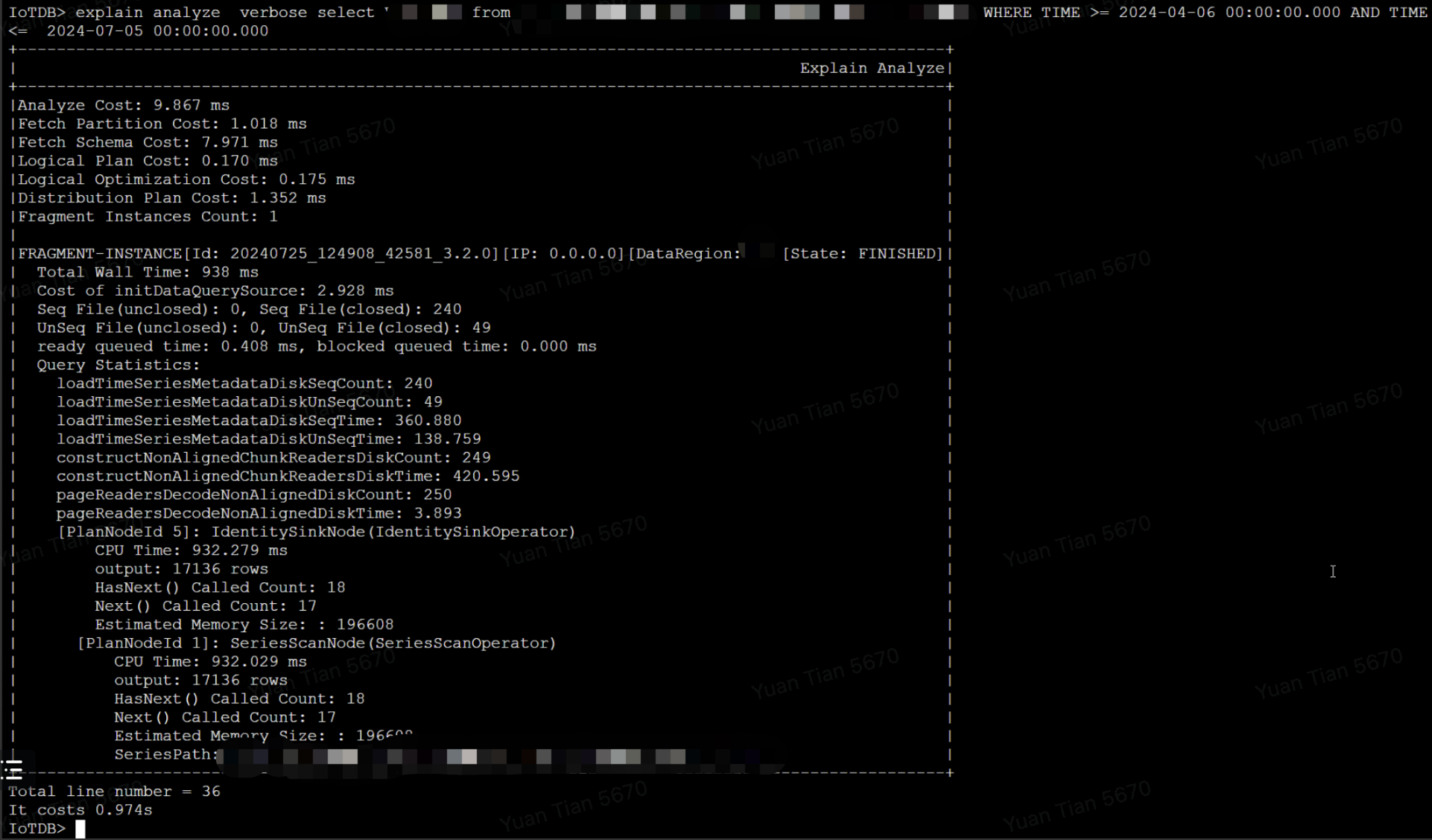
查询总耗时为 938 ms,其中从文件中读取索引区和数据区的耗时占据 918 ms,涉及了总共 289 个文件,假设查询涉及 N 个 TsFile,磁盘单次 seek 耗时为 t_seek,读取文件尾部索引的耗时为 t_index,读取文件的数据块的耗时为 t_chunk,则首次查询(未命中缓存)的理论耗时为 ,按经验值,HDD 磁盘的一次 seek 耗时约为 5-10ms,所以查询涉及的文件数越多,查询延迟会越大。
最终优化方案为:
- 调整合并参数,降低文件数量
- 更换 HDD 为 SSD,降低磁盘单次 IO 的延迟
执行如下 sql 时,查询超时(默认超时时间为 60s)
执行 explain analyze verbose 时,即使查询超时,也会每隔 15s,将阶段性的采集结果输出到 log_explain_analyze.log 中,从 log_explain_analyze.log 中得到最后两次的输出结果如下:
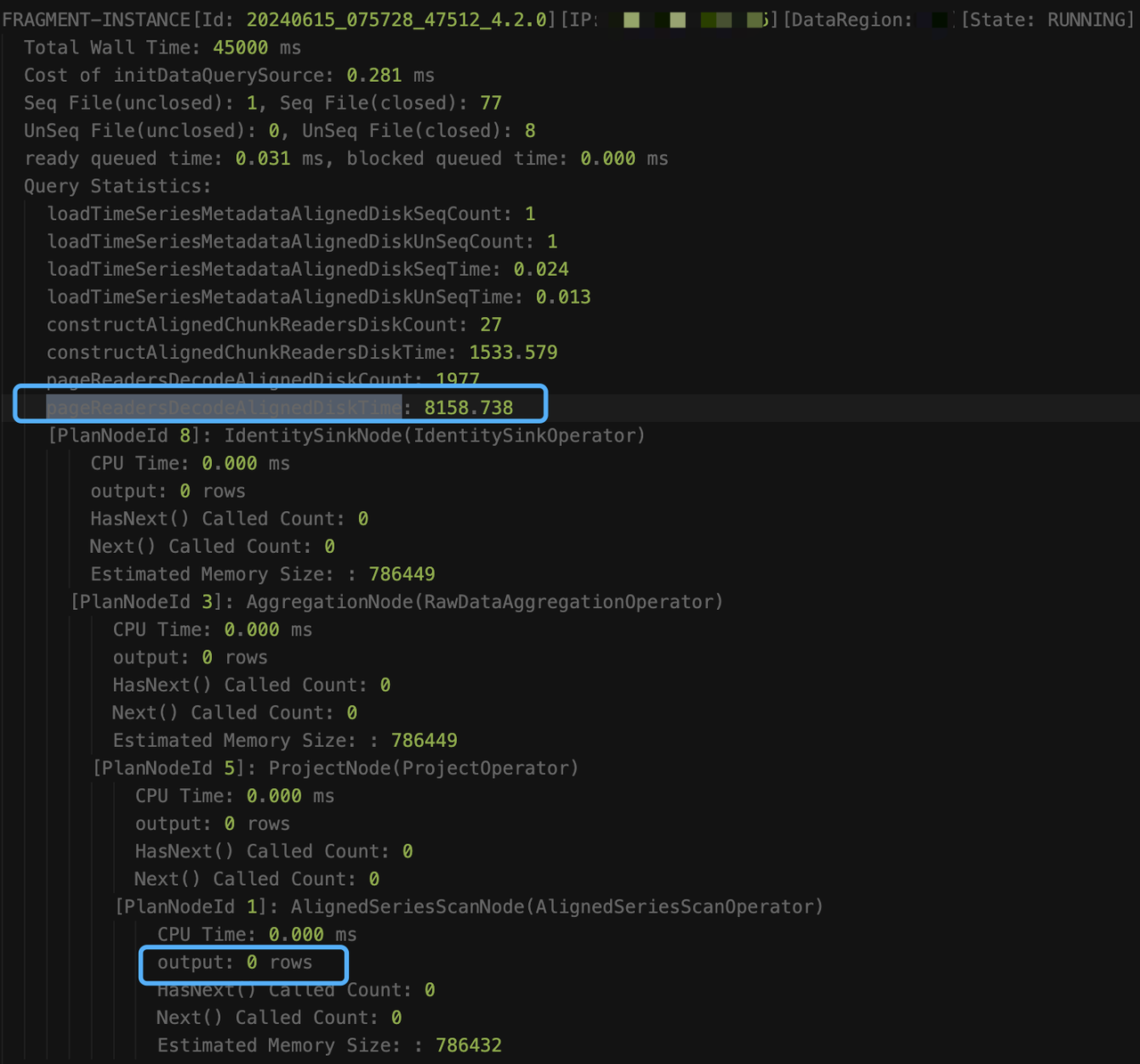
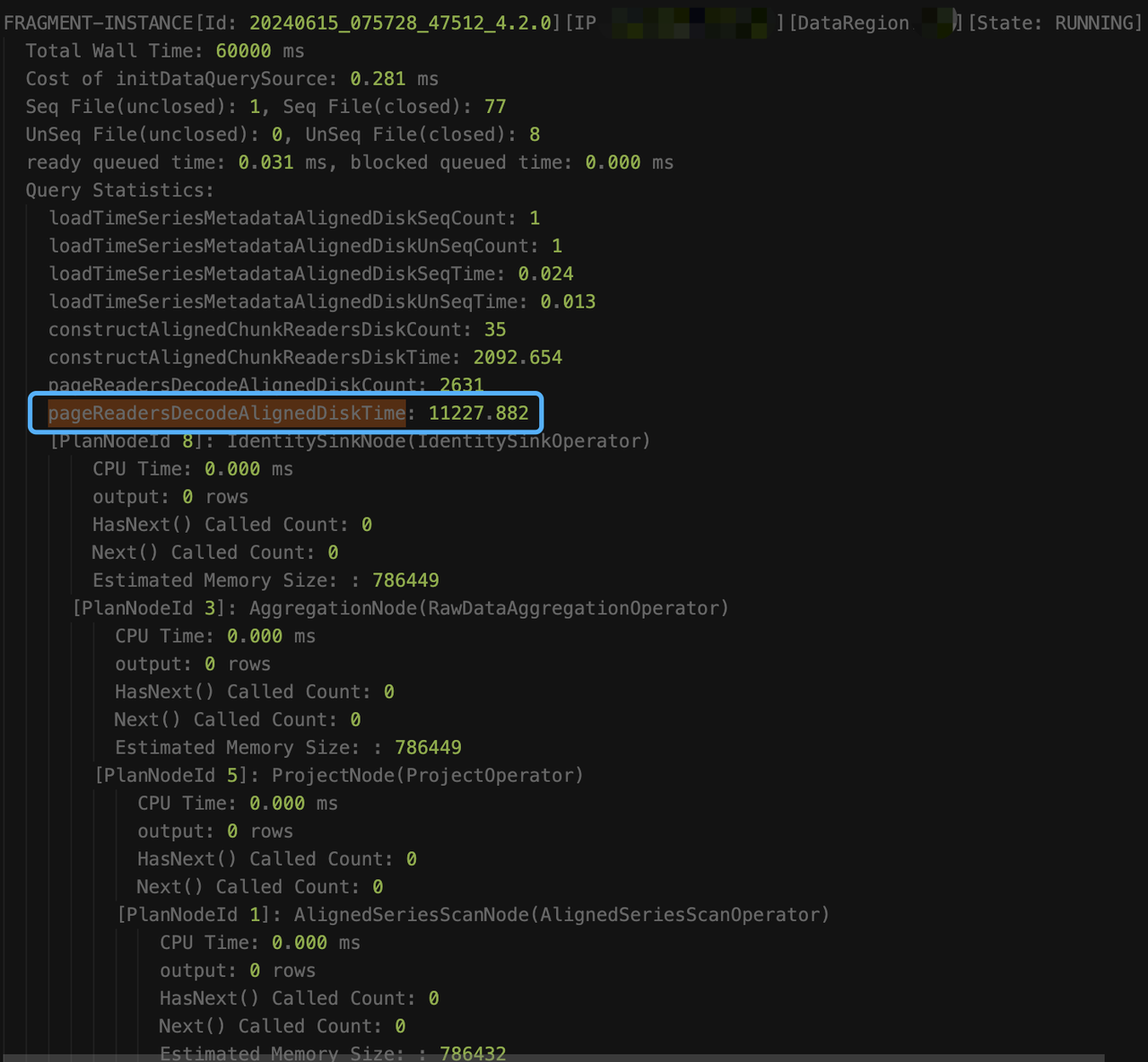
观察结果,我们发现是因为查询未加时间条件,涉及的数据太多 constructAlignedChunkReadersDiskTime 和 pageReadersDecodeAlignedDiskTime的耗时一直在涨,意味着一直在读新的 chunk。但 AlignedSeriesScanNode 的输出信息一直是 0,这是因为算子只有在输出至少一行满足条件的数据时,才会让出时间片,并更新信息。从总的读取耗时(loadTimeSeriesMetadataAlignedDiskSeqTime + loadTimeSeriesMetadataAlignedDiskUnSeqTime + constructAlignedChunkReadersDiskTime + pageReadersDecodeAlignedDiskTime=约13.4秒)来看,其他耗时(60s - 13.4 = 46.6)应该都是在执行过滤条件上(like 谓词的执行很耗时)。
最终优化方案为:增加时间过滤条件,避免全表扫描
用于修复由于系统 bug 导致的乱序
启动一个数据修复任务,扫描创建修复任务的时间之前产生的 tsfile 文件并修复有乱序错误的文件。
停止一个进行中的修复任务。如果需要再次恢复一个已停止的数据修复任务的进度,可以重新执行 .
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/58718.html