
你的理解是错误的。
博客系统有两种,一种是静态博客、一种是动态博客,还有托管服务类,它们的派系分别是:
- hexo、jekyll、hugo
- wordpress、typecho、tale
- Ghost、FarBox
我最早接触的是 wordpress 后来一一都折腾过,最后选择了比较灵活的 jekyll,尽管我开发了 tale 博客系统。
关于其他的疑问,题主可以看看这篇:搭建个人博客,你需要知道这些
据不完全统计,FTC去年至今至少起诉了三家低调通过SDK违法收集个人信息的公司[i],中国也有不少类似案例,说明该领域已成执法焦点。今天就根据诉状[ii]聊聊这个案子以及我国相关的法律规定。
一、为什么说SDK服务商低调?
SDK(Software Development Kit),是集成在应用程序(“App”)里的第三方工具包,为什么说SDK服务商低调,是因为其不是应用程序运营者,只是在应用程序中提供了某项功能,如地图、支付、统计、社交、广告等,从消费者感知的角度,存在感比较弱。据统计[iii],平均每款App会使用19.3个SDK,而微信SDK、腾讯Open SDK、小米推送SDK、华为SDK、支付宝SDK等被超过半数的App嵌入。
以微信为例[iv],接入的SDK包括:云闪付、微信支付、微粒贷、小程序/公众号、微信登录、广告服务。这其中,部分由腾讯提供,部分由第三方,如云闪付由中国银联提供。但正因为其存在感弱,所以其通过服务获取个人信息后如果违法处理的,也不容易被察觉,但监管机构还是发现了问题。
二、InMarket的SDK服务有哪些违法行为?
InMarket是一家德克萨斯州的数字营销平台和数据聚合商,它通过开发专业软件开发工具包(“InMarket SDK”)直接从移动设备收集位置数据,并利用移动设备位置数据向消费者的移动设备定向投放广告。
收集位置数据包括两种方式,一种是直接整合到其运营两款移动应用程序CheckPoints(完成小任务即可获得购物奖励)和ListEase(帮助消费者创建购物清单)收集移动设备的位置数据,另一种是向300多款的第三方应用程序开发商提供SDK接入服务进而出售并共享消费者的位置数据进行广告推广。InMarket收集消费者位置数据的做法和违法性可归纳如下:
1、InMarket自运营的两款应用程序的同意屏幕告知消费者其位置将被用于应用功能(赚取积分和保存列表),但未披露收集用户精确位置信息及用途;
违法性:收集行踪轨迹等敏感个人信息时,未同步告知用户其目的,或者目的不明确、难以理解;收集的个人信息类型或打开的可收集个人信息权限与现有业务功能无关。
2、InMarket的隐私政策虽然披露将把消费者数据用于定向广告,但其同意屏幕未链接到隐私政策,也未告知消费者应用程序的数据收集和使用做法。
违法性:在App首次运行时未通过弹窗等明显方式提示用户阅读App及SDK的隐私政策等个人信息收集使用规则;且未同步告知用户其收集个人信息和敏感个人信息的目的。
3、InMarket不要求使用其SDK的第三方应用程序获得消费者的知情同意,与应用程序开发商签订的合同对隐私方面没有更多要求,仅要求开发商遵守所有适用法律并维护符合法律要求的隐私政策;
违法性:以欺诈、诱骗等不正当方式误导用户,掩饰收集使用个人信息的真实目的违法收集个人信息;未逐一列出SDK收集使用个人信息的目的、方式、范围等。
4、InMarket将收集的消费者位置数据保留了五年之久;
违法性:未及时删除个人信息违反最小必要原则。
5、InMarket通过其算法将消费者的位置数据与广告相关兴趣点进行交叉比例,进行用户画像,形成广告产品牟利。
违法性:为“用户画像”、“算法推荐”等涉及不当自动化决策违反处理敏感个人信息的保护规则;利用用户个人信息和算法定向推送信息,未提供非定向推送信息的选项;违反其所声明的收集使用规则(涉及部分SDK),收集使用个人信息。
三、我国的监管规定和处罚案例
结合前述违法行为,假设InMarket是一家中国企业,其收集和处理消费者的个人信息的行为涉嫌违反《网络安全法》、《个人信息保护法》、《消费者权益保护法》等有关个人信息的法律规定,具体的违法内容,前文已经分析。同时,对SDK个人信息保护,我国监管部门还有非常详尽的具体规定。
《App违法违规收集使用个人信息行为认定办法》和工信部2023年2月发布的《关于进一步提升移动互联网应用服务能力的通知》,对App开发运营者主体、SDK自身、企业三方分别提出SDK的管理要求,具体包括:
1、App运营者需逐一列明App委托的第三方或嵌入的第三方代码、插件收集使用个人信息的目的、方式、范围,否则将被认定为未明示收集使用个人信息的目的、方式和范围。
2、App运营者使用SDK前对其进行个人信息保护能力评估,通过合同等形式明确约定各方权利和义务,确保个人信息处理依法合规。集中展示并及时更新嵌入的SDK名称、功能及其处理个人信息的规则。共同处理用户个人信息,侵害用户权益造成损害的,依法承担相应责任。
3、App运营者需公开明示个人信息处理规则,SDK独立采集、传输、存储个人信息的,应当单独作出说明。
4、SDK开发者遵循最小必要原则,根据不同应用场景或用途,明确SDK功能和对应的个人信息收集范围,并向App运营者提供功能模块及个人信息收集的配置选项,不得一揽子过度收集个人信息。
根据我们的查询,工信部和各地通管局近年来多次通报了侵害用户权益行为的SDK服务,包括一键登录、移动端应用订阅、AdSet广告、多酷单机、TalkingData、Adview广告在内的多款SDK被通报。
最后,虽然监管机构陆续加强对SDK收集和处理用户个人信息的监督,但如果SDK开发者或者App运营者能够根据监管机构要求,全面完成整改,那么就有可能减轻或免除相应的责任。相反,若是逾期不整改或整改不到位的,监管机构会优先选择下架相关产品或服务。如果情况严重,监管机构还会采取包括罚款在内行政处罚措施,甚至会追究刑事责任。
[i] 另两家是移动测量公司 Kochava和数字健康平台GoodRx。
[ii] https://www.ftc.gov/news-events/news/press-releases/2024/01/ftc-order-will-ban-inmarket-selling-precise-consumer-location-data
[iii] https://www.cfca.com.cn/upload/cpbg.pdf
[iv] support.weixin.qq.com/cgi-bin/mmsupport-bin/newreadtemplate?t=datalist/shared
Android studio的sdk下载url默认被某个太监的产品给拦了。
前言:
SDK安装时遇到的问题,做一个简单的留档,为以后遇到时自己能快速找到,也希望能帮助到需要的人。
前提:
安装好JDK和JRE,配置好环境变量
下载网址:
Android Studio 中文社区-安卓开发者工具集:Android SDK/JDK/ADT/Gradle/App-3.0正式版下载/安装/教程/外包/招聘
安装步骤:
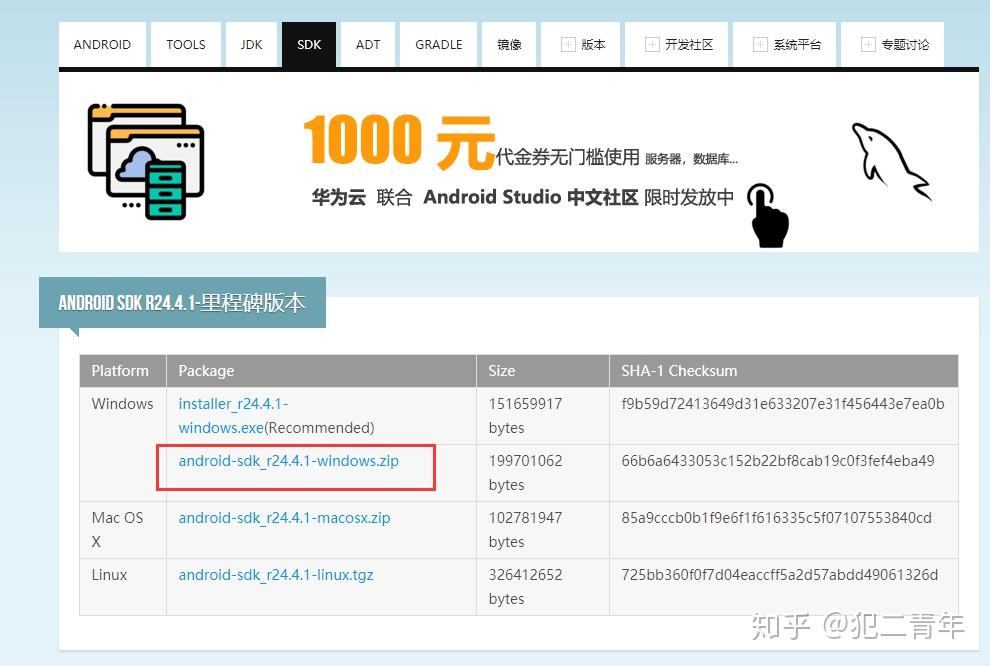
登录网址直接点击下载里面的SDK即可
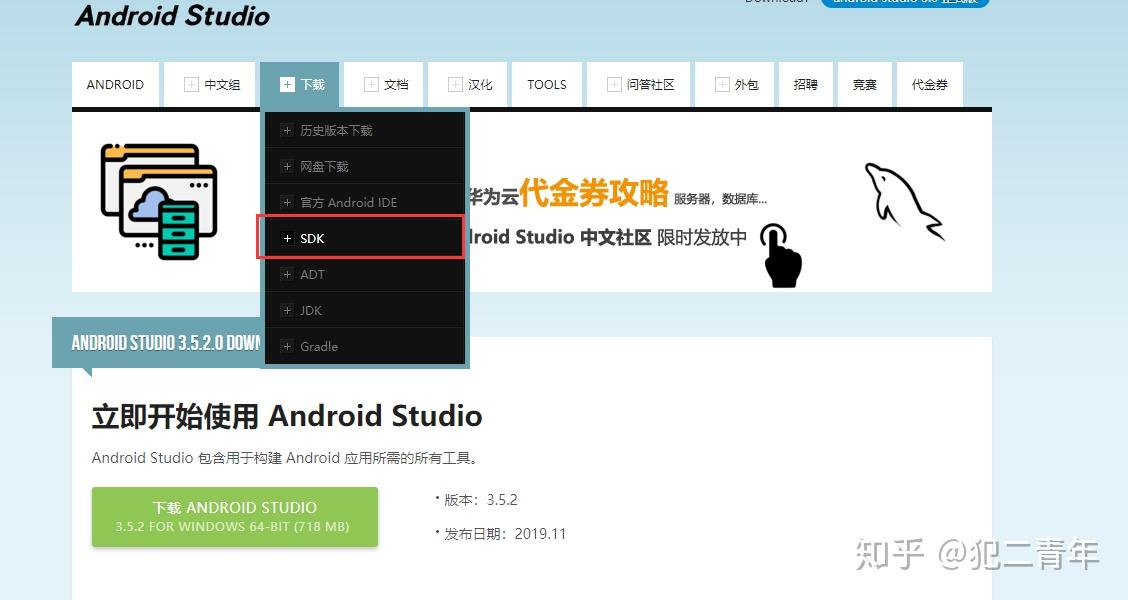
下载zip格式的直接解压到指定文件夹内即可
选择工具,安装工具:
解压以后双击打开SDK Manager.exe
Tools选择以下3个
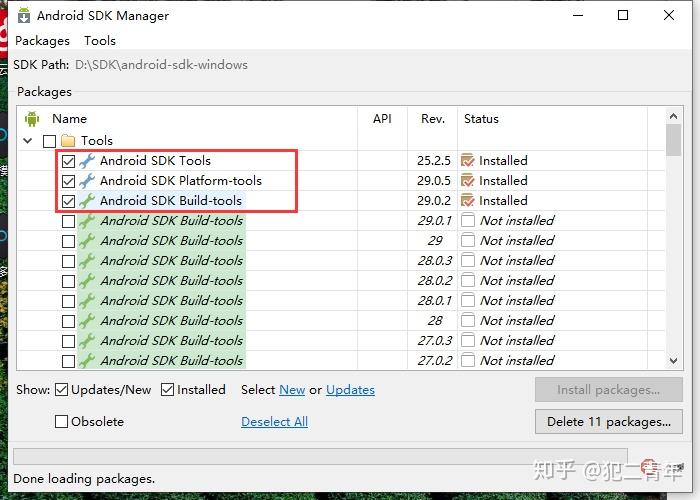
API版本选择最高版本即可,Android 10(API 29),内容全选
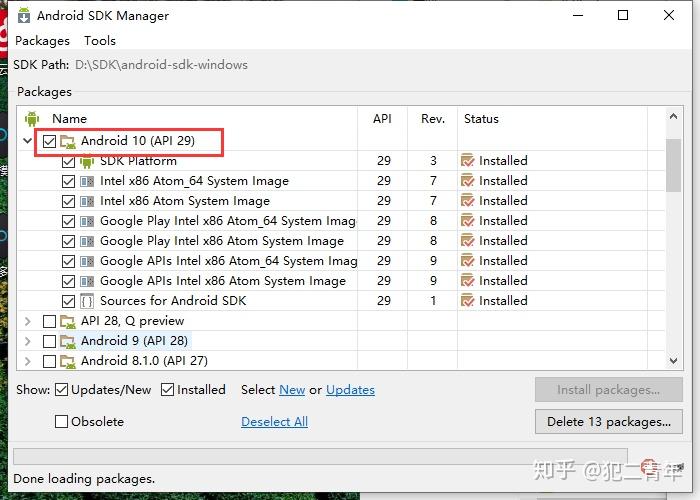
Extras如果有时间,全部下载,时间比较紧急,就选择以下3个即可
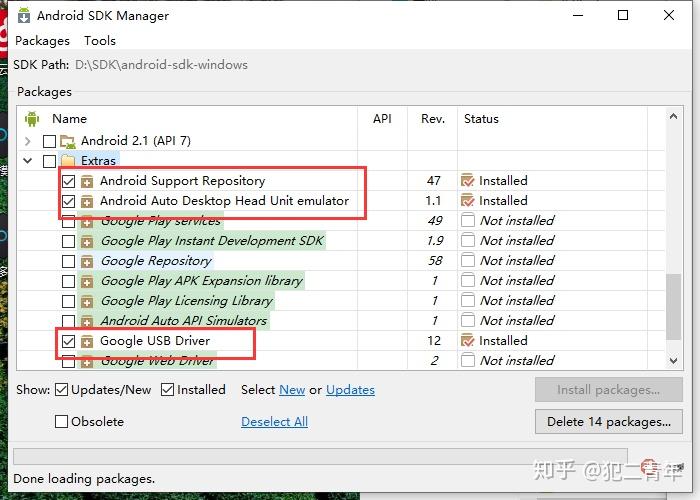
点击Install安装工具
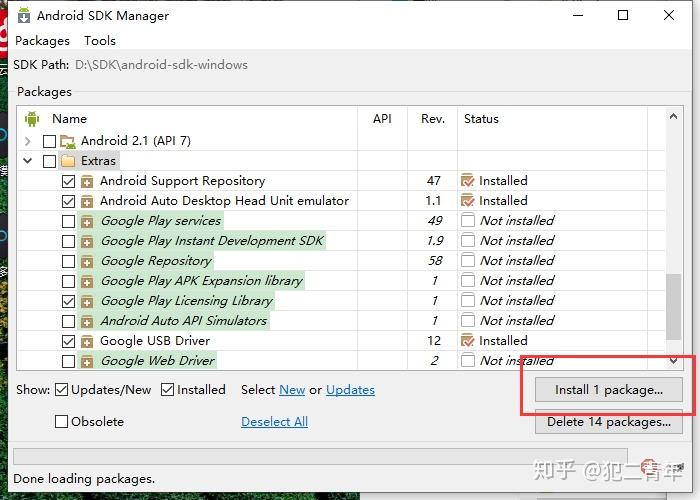
选中Accept license,点击Install,
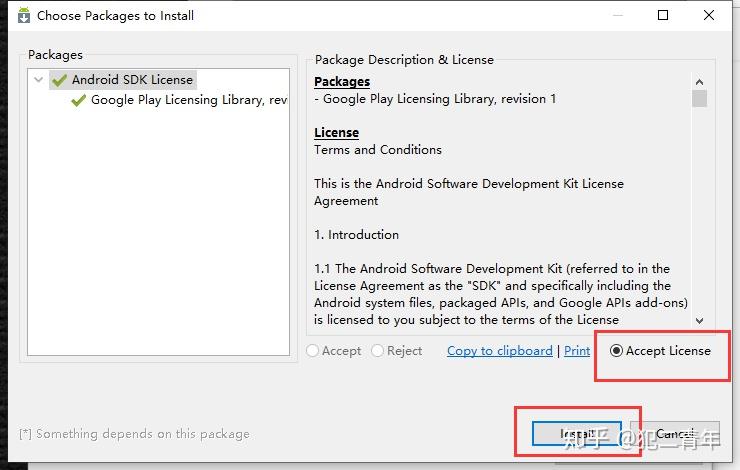
所有安装的工具Status变成以下状态安装完毕
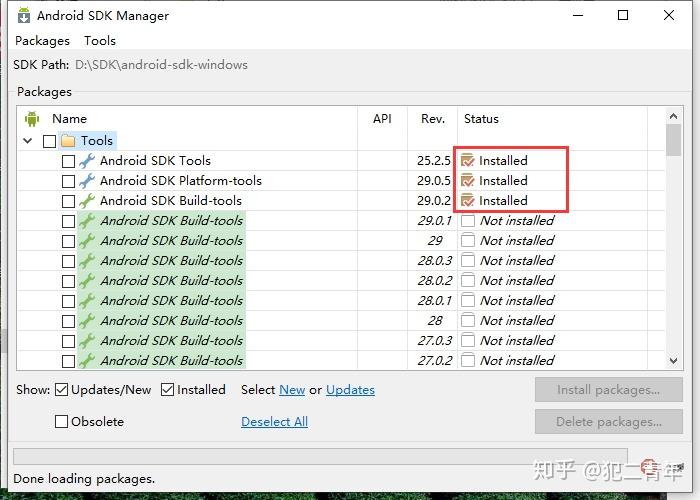
配置环境变量:
比如我的安装路径:
我的电脑(右键)-->属性-->高级系统设置-->环境变量
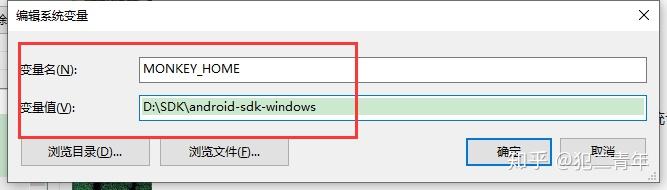
新建系统变量
变量名:(MONKEY_HOME)
变量值:D:\SDK\android-sdk-windows
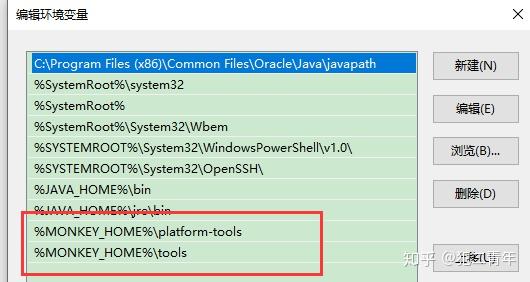
在系统变量Path最后添加:
%MONKEY_HOME%\platform-tools;%MONKEY_HOME%\tools
查看SDK和夜神模拟器版本:
WIN+R,输入CMD,打开DOS窗口,输入adb version

在夜神模拟器bin目录下面打开DOS窗口(快速打开:在路径栏输入cmd),输入adb version

因为我之前修改过,所以现在夜神模拟器版本和SDK版本一致,一般夜神模拟器版本要低
升级版本方法:
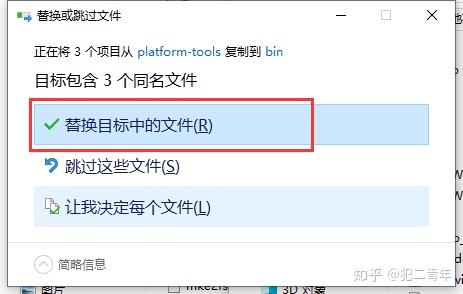
将SDK中platform-tools文件夹的以下三个文件复制到夜神模拟器中bin文件夹里面,选择替换
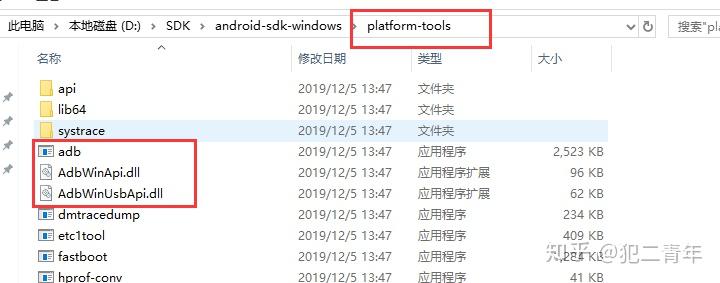
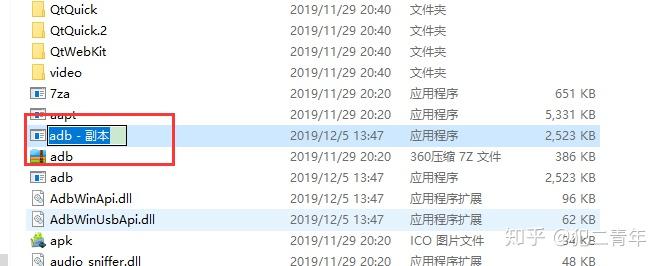
夜神模拟器中的nox_adb.exe也要替换掉,把原来的nox_adb.exe删除,再把adb.exe复制一遍,名字改为nox_adb.exe
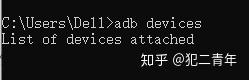
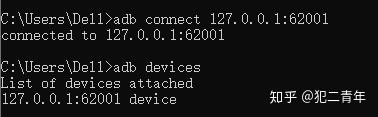
连接设备:
在DOS窗口输入adb devices,这时没有设备连接
打开夜神模拟器
在DOS窗口中:adb connect 127.0.0.1:62001,再次输入adb devices,这时显示有设备连接上了
常用模拟器默认端口号:
Genymotion模拟器5555
夜神模拟器62001/52001
海马玩模拟器26944
mumu模拟器7555
天天模拟器6555
逍遥安卓模拟器21503
BlueStacks蓝叠3模拟器5555
雷神安卓模拟器5555
腾讯手游助手5555
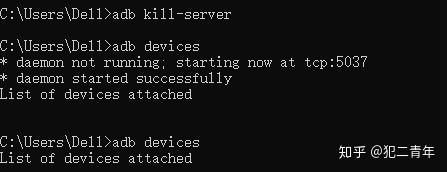
断开连接:
DOS窗口输入adb kill-server,所有设备断开连接
安装完成以后,如果再次出现“adb不是内部或外部命令,也不是可运行的程序
或批处理文件”时:
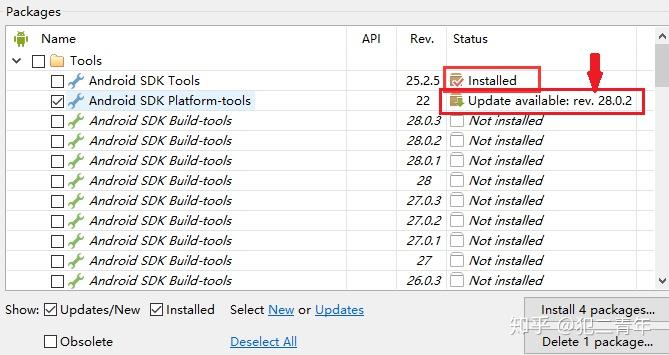
查看SDK Manager.exe文件
查看有没有文件出现需要更新的状态,如果有更新了以后就可以了
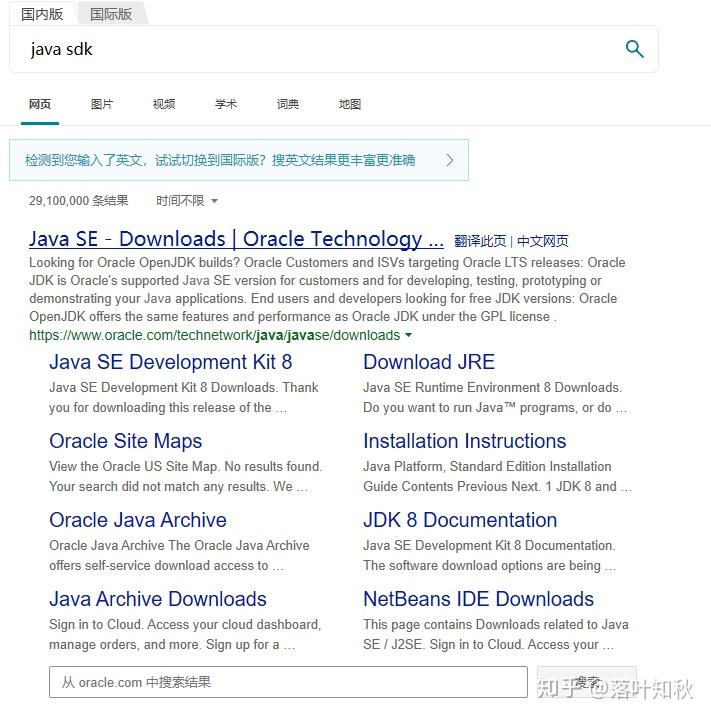
也就是下面对应的链接:
Java SE - Downloads
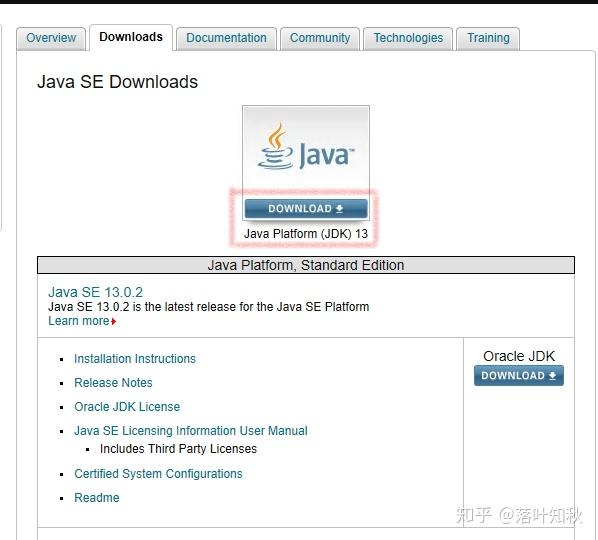
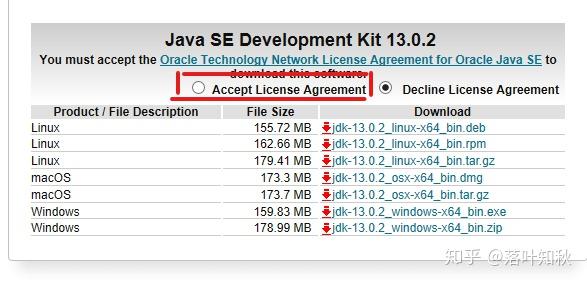
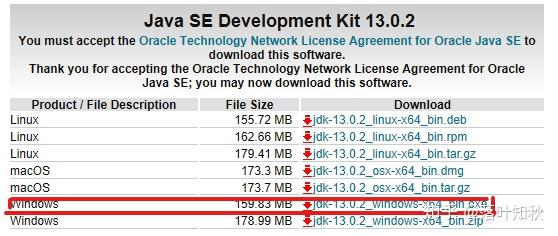

安装jdk,把jdk安装在事先创建好的文件夹中
安装完成后关闭
安装完成后:
Java 11及之后的版本没有jre,只有jdk,我们可以通过命令生成jre:
(1) 通过win10自带的搜索工具,搜索cmd,右击以管理员身份运行:
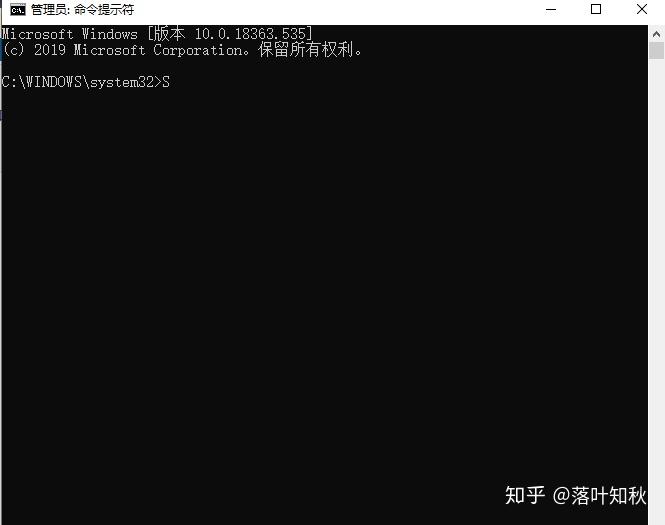
(2) 由于我的安装目录是:F:\Program Files\Java\SDK\jdk

所以进入安装目录
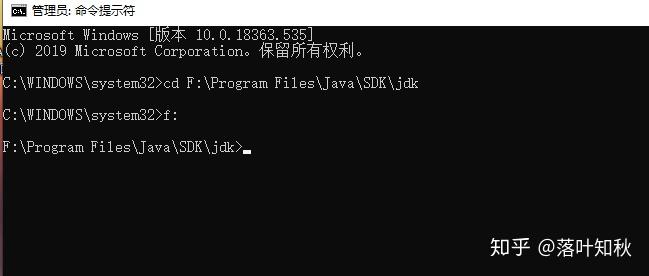
输入指令:bin\jlink.exe --module-path jmods --add-modules java.desktop --output jre后按回车

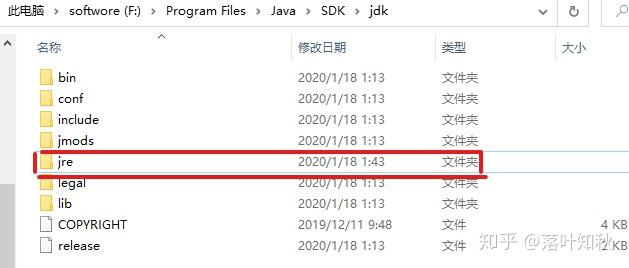
此时jre已经生成:

如图:
如图,依次此电脑>属性>高级系统设置>环境变量

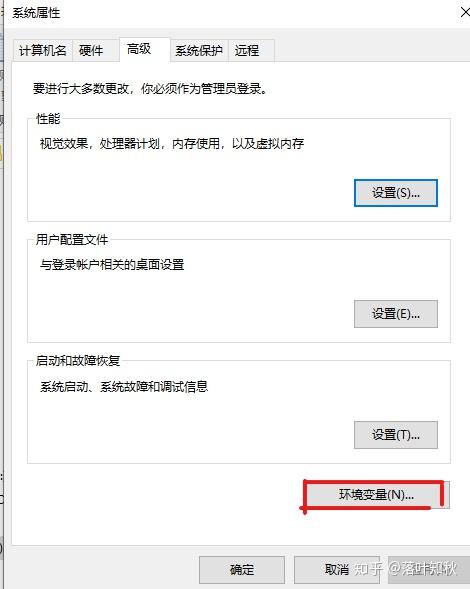
新建系统变量
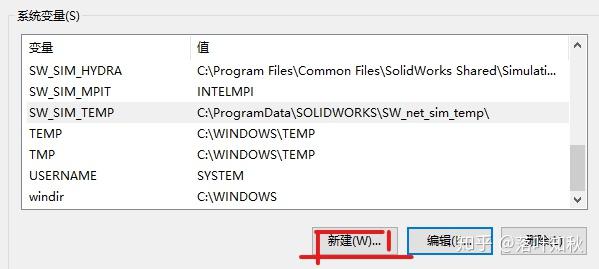
变量名和变量值(变量值由于安装路径不同,并不一定和下图值一样,但指向的路径是JDK安装的bin文件夹的位置)如下图所示:
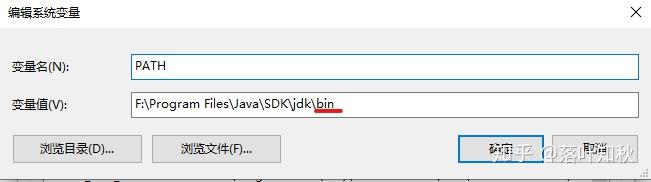
添加完成后确定,并关闭所有窗口。
如果已有PATH(大小写均可),那么直接双击打开PATH,然后点击新建,输入路径即可。
打开命令提示符,参考步骤6,分别输入java,javac,Java -version
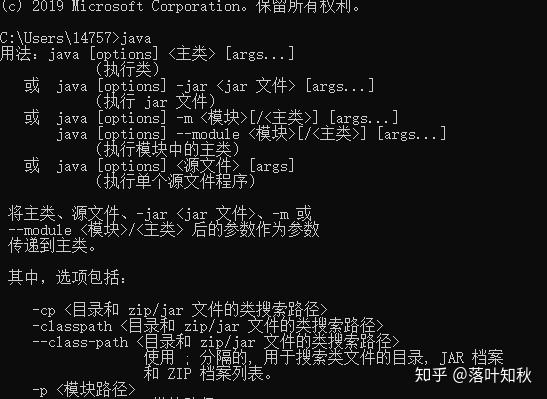

则安装成功
Android SDK(Software Development Kit,软件开发工具包)被软件开发工程师用于为特定的软件包、软件框架、硬件平台、操作系统等建立应用软件的开发工具的集合。它提供了 Android API 库和开发工具构建,测试和调试应用程序。简单来讲,Android SDK 可以看做用于开发和运行 Android 应用的一个软件。
Step1 解压SDK包
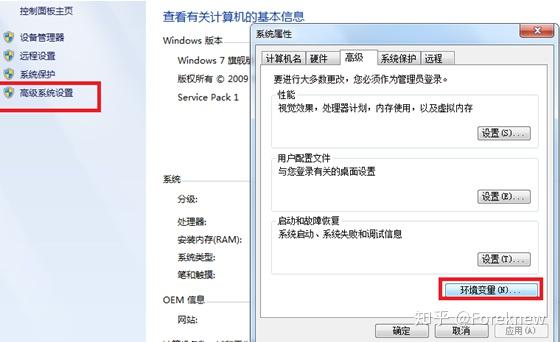
Step2设置环境变量
在桌面上右键点击”计算机”图标,选择“属性”, 选择高级系统设置->环境变量
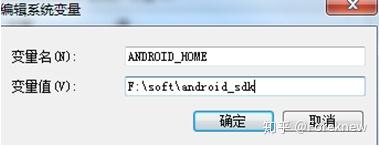
其中,变量值 F:\soft\android_sdk修改为本机sdk包解压的目录;
Step3 在path添加路径:
%ANDROID_HOME%\platform-tools;
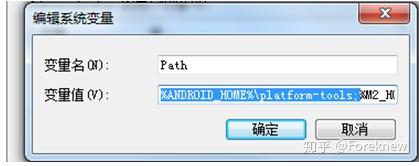
Step4 检查sdk环境是否正常
在cmd下输入命令
adb
如果可以正常显示命令,则说明配置成功.
3.1 安卓手机通过数据线连接到电脑,并且打开开发者调试模式(在手机设置里,因手机型号而位置不同,详细可以通过百度自己手机型的开发者模式);
手机是否连接上电脑,可以通过adb devices来查看,如果显示no devices attached,则表示没有连接上, 解决办法:建议在电脑和手机端各安装360手机助手.
如果手机连接不上电脑,还可以通过手机模拟器来模拟手机,安装夜神模拟器在电脑上,打开cmd,输入连接命令 adb connnect ip:端口号,操作如下图:
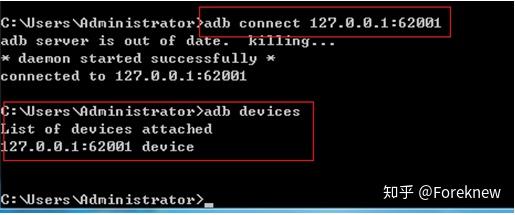
表示连接模拟器成功,一样可以使用各种adb命令.
接下来的章节我们会详细介绍:常见的adb命令,敬请关注!
想必各位APP开发者们对SDK都有一定了解,并且抱有爱恨交杂的情绪。
SDK,确实该爱。
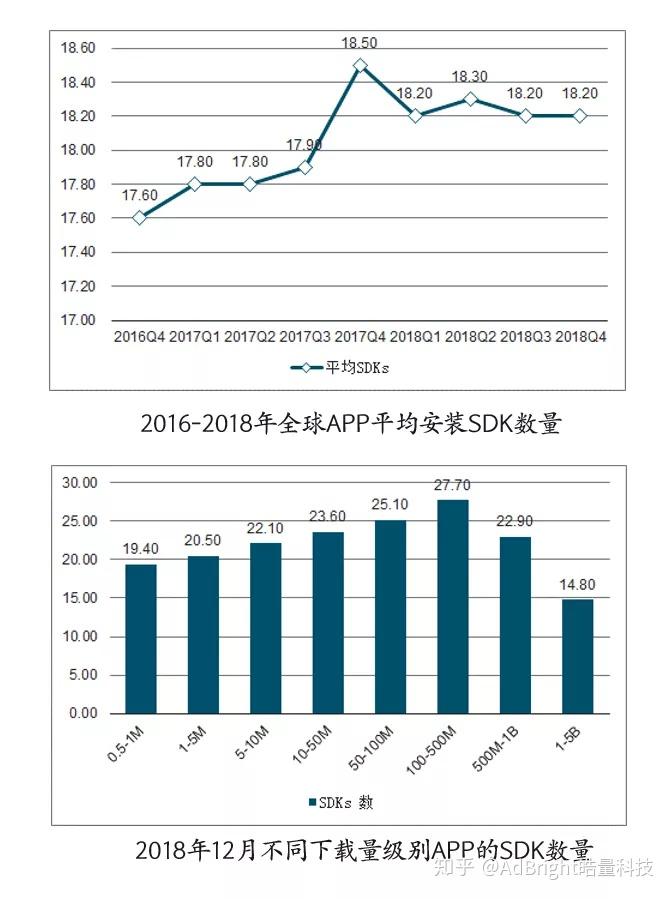
SDK可以提升开发和集成效率,降低开发成本,市面上现有的SDK覆盖支付、客服、后台、广告、测试分析报告、推送、追踪、云存储等多个领域,APP对SDK有较强的依赖性。根据观研天下发布的《2019年中国移动APP行业分析报告》,截至2018年12月,全球APP平均安装SDK数量达到18.2个,拥有100-500万下载量的APP的SDK平均安装数量最多,达27.7个。
SDK,真的该恨?
对于APP开发者来说,嵌入第三方SDK可能会引发安全问题,需要承担连带风险,比如SDK开发者的安全能力水平参差不齐,可能会导致SDK的安全漏洞;还有SDK开发者会在代码中故意预留“后门”,以便收集用户信息或执行越权操作。这些安全问题轻则让APP正常使用受到影响(卡顿),重则被应用商店下架,甚至需要承担法律责任。
广告SDK是SDK中的“重灾区”,相关的安全事件频发,也让很多APP开发者在选择上更为慎重,并且进行严格的审查。
本文AdBright将简要介绍广告SDK的类型和原理,并且提供相应的审查指引。
广义上,广告SDK代指为开发者提供广告相关功能(接入广告、广告监测等)的软件开发工具包。狭义上,广告SDK仅指帮助APP开发者接入广告,实现广告变现的软件开发工具包。广告SDK的类型较多,可以按下面的方式分类:
根据变现需求方的类型可以分为H5 SDK和APP SDK,按编程语言分又可以分为Java SDK、Objective-C SDK等。h5 SDK主要满足网页(包括各平台小程序)的变现需求,APP SDK则主要满足APP开发者的变现需求,其中Java SDK适用于Android应用,Objective-C SDK适用于iOS应用。
根据SDK开发者专注的垂直广告领域,可以分为激励广告SDK、互动广告SDK等。广告特性不同,适用的变现需求方也不同,激励广告SDK满足以休闲类游戏为主的游戏媒体的变现需求,互动广告SDK则适用类型更广,以工具类媒体为主。
根据SDK开发者的性质及商业目的,可以分为单一(single)广告SDK和聚合(mediation)广告SDK;SDK的开发者一般为广告联盟和广告技术公司。广告联盟开发自有的广告SDK,接入多个变现需求方,打造SSP平台,利用集群效应售卖流量并从中抽成;广告技术公司则开发聚合了多个广告联盟的SDK,帮助变现需求方一次接入多个广告联盟,收取服务费。
1.广告交易生态中的广告SDK
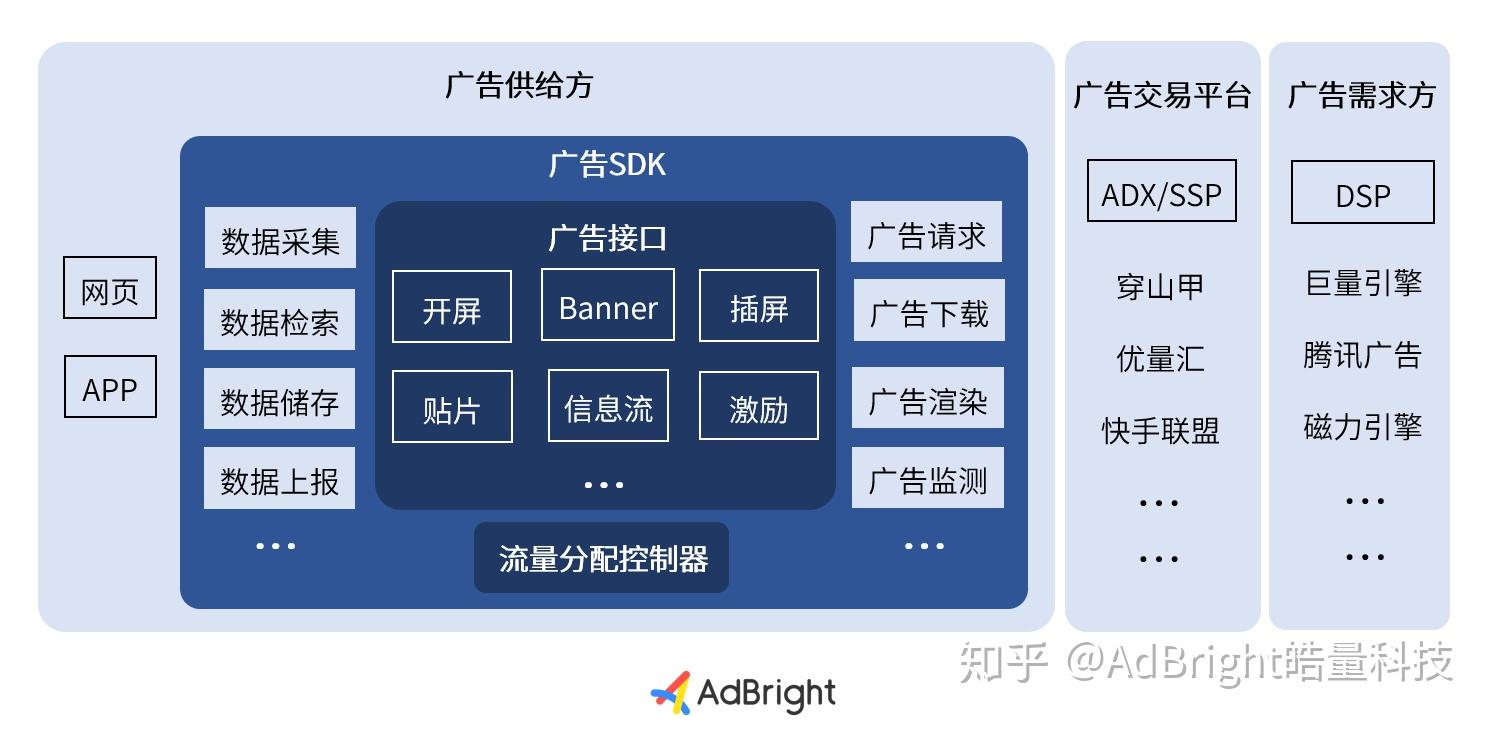
广告供给方:一般可称为媒体,分为网页和APP,从已嵌入的广告SDK中获取广告内容并展示。
广告SDK:广告供给方通过广告SDK的接口发起广告请求,请求内容包括广告位、广告素材尺寸、用户设备码等信息,并依靠流量分配控制器向广告交易平台分发广告请求。
广告交易平台:为ADX/SSP,接收广告请求和竞价信息,处理广告交易。
广告需求方:为DSP,在广告交易平台参与竞价,并向广告SDK回传广告内容。*
目前SSP与ADX功能模块趋同,故统称为广告交易平台
在广告交易生态中,广告SDK可以视为广告供给方参与广告交易的“门票”,串联起广告请求发起——广告创意展示——广告数据上报这一完整的广告交易链路,执行包括数据采集、数据检索、数据储存、数据上报、广告请求、广告下载、广告渲染、广告监测等在内的工作。
2.广告SDK的接入
在广告SDK真正发挥作用前,需要先完成接入。SDK开发者会为APP开发者分别提供iOS/Android SDK 接入文档,目前流程已经标准化,一般可以分为以下五步:第一步:加入文件
把广告SDK文件嵌入指定的项目目录中。第二步:构建关联向广告SDK添加引用,建立关系,包括添加配置、权限等。第三步:编写代码应用初始化及广告位开发,调用广告SDK提供的广告位模板。第四步:联调测试即测试广告交易流程,测试点包括流程是否顺畅(请求正常触发等),广告展示是否正常(无变形加载等适配问题)、广告数据是否正常(无数据错漏等情况)等。第五步:软件发布将嵌入广告SDK的应用上架&更新,完成后即可开始发起广告请求,开始广告变现。
对于APP开发者来说,只接入单一广告SDK意义并不大,一方面高度依赖某个联盟,导致风险过于集中,另一方面如果联盟无广告返回会造成流量浪费,收益减少。虽然SDK的接入流程已经标准化,但如果同时接入多个联盟的广告SDK,APP开发者仍需要付出大量的学习和开发成本,管理上也更为复杂,因此接入聚合广告SDK成为更高效的选择。
3.广告SDK的请求机制
APP开发者接入聚合广告SDK后能有了更多调整和选择,一次性对接多个广告联盟,可设置更灵活的请求机制和流量分配机制,目前市面上主流的聚合广告SDK的请求机制有下列三类:
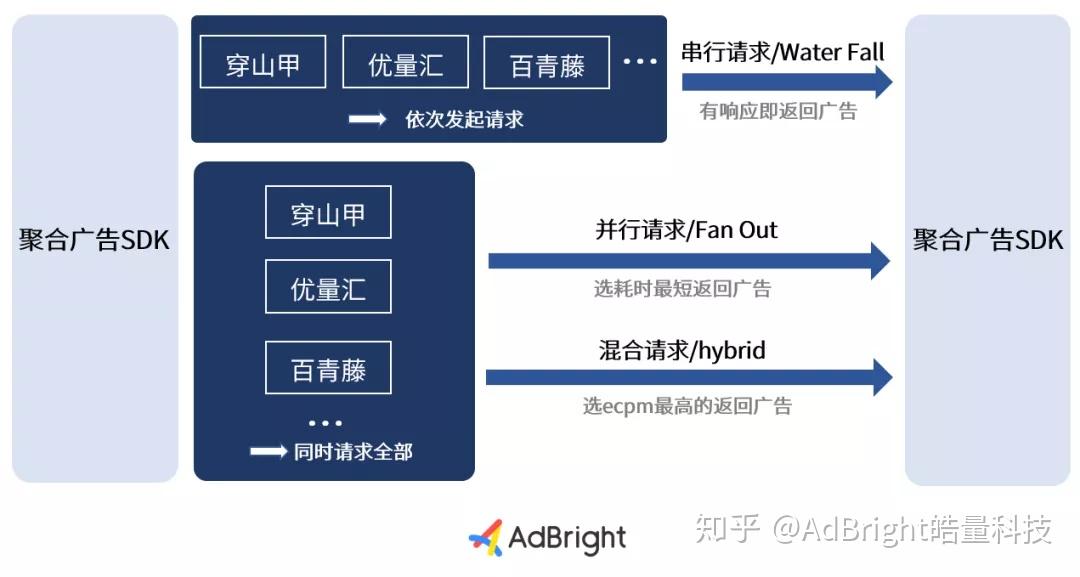
①WaterFall
即串行请求。聚合广告SDK按设定的顺序,依次向各个广告联盟发起广告请求,如果返回广告内容则进行展示广告。优点:得到广告内容即可展示广告内容,能够提升广告展示率;缺点:增加广告内容返回超时的几率,导致无法顺利进行广告展示,损失潜在的广告收益并且影响用户体验。
②Fan Out
即并行请求。聚合广告SDK一次请求所有的广告联盟,选择时间最短返回的广告内容并进行展示。优点:几乎可以保证每次流量都被填充,顺利完成广告展示;缺点:一次访问多个广告联盟的话,会造成部分广告联盟成功返回广告内容但总是无法曝光的情况,从而导致其降低引流权重,影响后续收益。
③Hybrid
即混合请求。聚合广告SDK一次请求所有的广告联盟,选择eCPM最高的广告联盟返回的广告内容(在广告联盟支持返回eCPM的前提下),并进行展示。优点:几乎可以保证每次流量都被填充,并且每次填充的都是ecpm最高的广告;缺点:除了Fan Out模式的缺点,此请求方式让聚合广告SDK需要进行较为复杂的逻辑判断,对其数据的处理速度和处理能力都要求较高,可能会导致广告展示率低。
三种方式各有利弊,在不考虑计算和数据处理能力的情况下,混合请求是最优请求方式。提升广告收益也是聚合广告SDK的价值所在,使用混合请求能够提升广告展示率、广告填充率、eCPM。
广告SDK的安全风险主要是SDK开发者瞒着APP设置“后门”获取用户信息,并且利用数据获利。
用户信息收集的风险也分等级,友盟+的高级产品研发专家马巍源曾整理风险级别,低风险为用户移动设备传感器的信息,包括光、声音、环境,极高风险则涉及用户已安装应用信息和账户信息这类最为私密的信息。
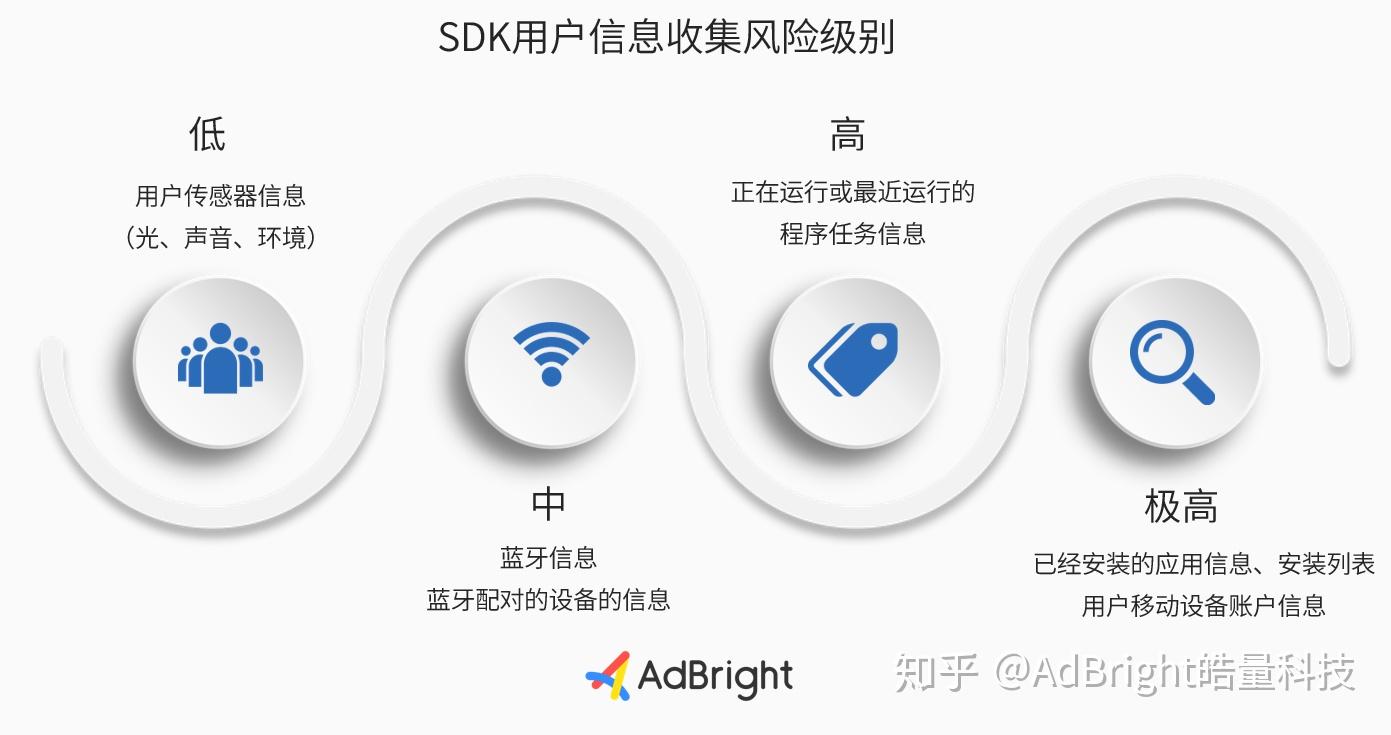
因此,审查是接入广告SDK的必要环节。对于APP开发者来说,既是对广告SDK的深入了解,能够提升后续的接入效率,也能理清风险点。审查方式可以分为三类,包括文档审查、工具审查和第三方审查:
1.文档审查
在SDK接入前进行审查,但SDK开发者一般不会直接在接入文档暴露“不当目的”。即APP开发者对SDK开发者提供的接入文档进行审查,查看是否有要求APP回传敏感信息,是否有涉及到双方未达成一致或有争议的内容。
2.工具审查
在联调测试环节使用抓包工具审查,常用的工具有Charles(青花瓷),能够支持Mac OS\Windows\Linux系统。即APP开发者使用抓包工具抓取接入SDK开发者的网络请求,并且分析是否有不在协议内的数据。

3.第三方审查
一般也是在联调测试环节进行审查,由第三方公司出面审查SDK,比如网易易盾、腾讯安全等。第三方公司有着更完整和全面的审查机制,能够出具权威客观的报告,但APP开发者需要付出更多成本。
技术不是原罪,使用技术的人才是。
广告SDK通过不断的技术创新,提升了广告交易的效率和效益,推进了广告市场的繁荣发展,让百万开发者受益,价值不容置疑。
广告SDK的潜在安全风险也不可小视,但令人欣喜的是,SDK相关的监管和法律法规在不断完善中。从2019年发布的《软件开发包(SDK)安全与合规白皮书》,再到近期国内首个SDK安全国家标准宣布正式立项。在可预见的将来,SDK行业的生态将会更为纯净、有序。
本文仅供参考,若您有疑问和其他见解,欢迎随时联系AdBright,共同探讨、合作共赢。
本篇文章将会手把手介绍sdk和api、OCR文字识别,以及如何通过不用手敲代码实现调取OCR的免费sdk服务,让大家深入了解深度学习以及sdk和api的调取实例。
- 首先,什么是OCR文字识别?
- “OCR 是英文Optical Character Recognition的缩写,意思是光学字符识别,简单来说就是识别图片里的文字信息。”其应用方式有,身份证OCR、行驶证OCR、驾驶证OCR、营业执照OCR、银行卡OCR、手写体OCR、车牌OCR等。
其次,令大家困惑已久并傻傻分不清楚的sdk和api到底是什么?在《产品经理必懂的后端技术》中已经讲过:
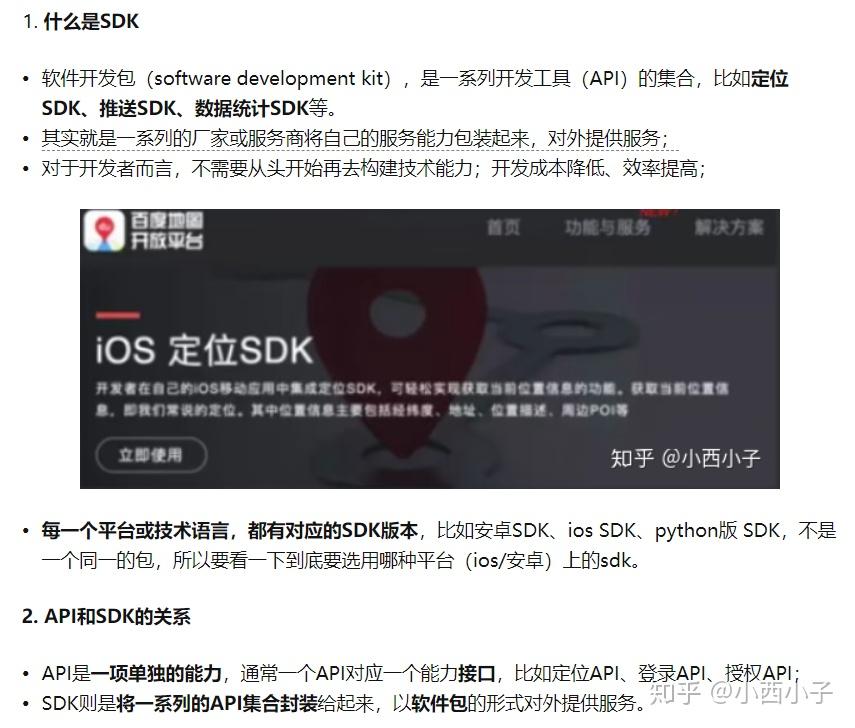
还昏吗?用一个贴近生活的例子来解释:
- 有一杯密封饮料,它的名字叫做“SDK”。
- 饮料上插着吸管,吸管的名字叫“API”。
- 如果你想喝到SDK里的饮料(让系统拥有SDK中的功能),你必须通过API这根吸管来实现(通过API连接你的系统和SDK工具包),否则你就喝不到饮料。
因此本篇文章的内容就是,如果你不想通过写代码来实现图片里的文字识别(OCR),那么你就可以通过调用大牛们已经训练好的超高精度的深度学习模型的软件开发包(sdk)的应用程序接口(api)来达到你的目的。
如果想看实践的完整教学视频可以登录腾讯云大学的OCR 文字识别接入指引,若想直接上手操作可阅读全文。
OCR 文字识别接入指引 - 腾讯云大学
步骤一 登录腾讯云官网,点击产品→人工智能产品→通用文字识别。
步骤二 点击右上方“接口文档”,查看api示例(ps产品经理必须一定要学会读api哦)。
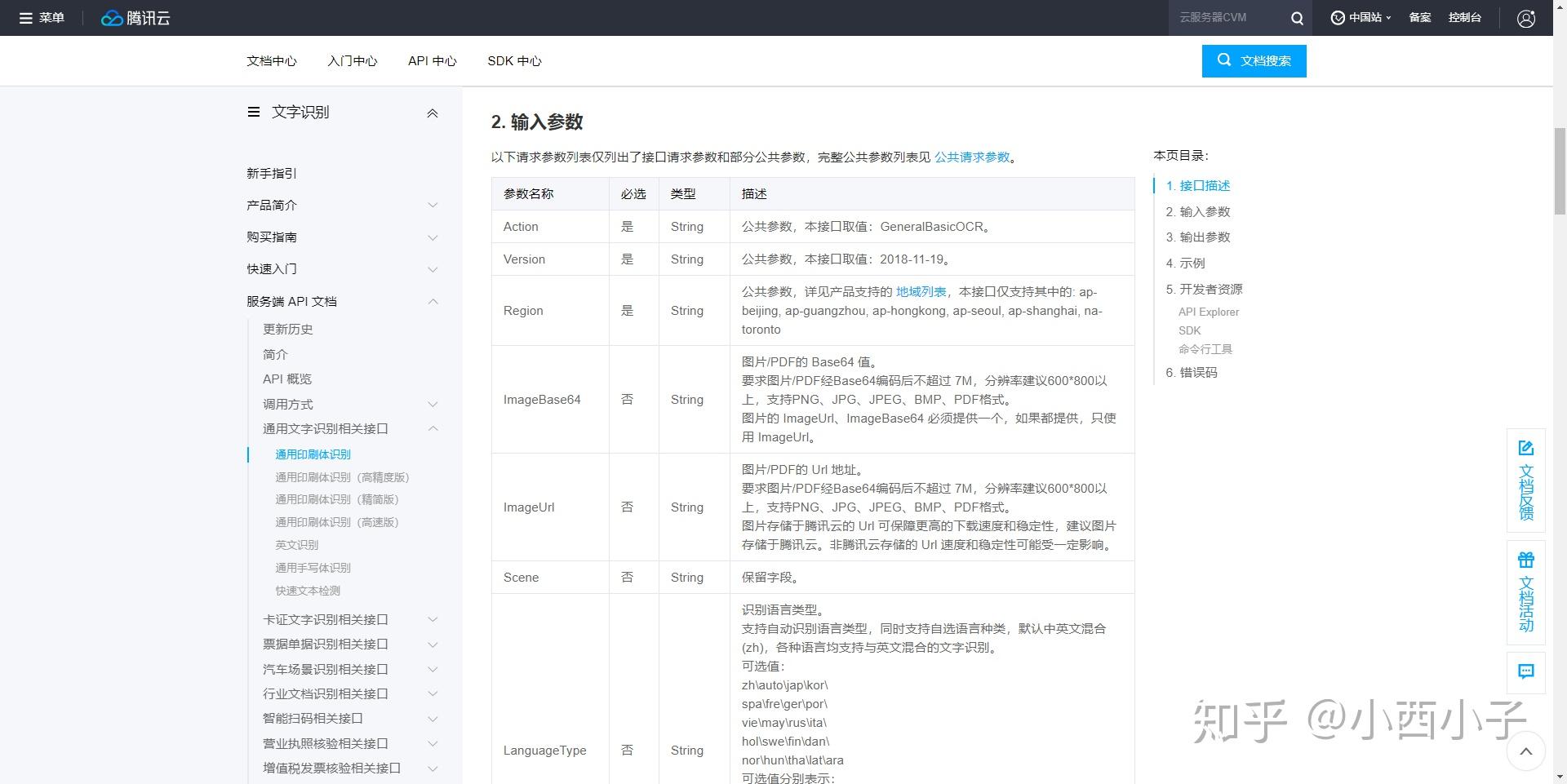
接口的参数有很多,其中最重要的是“Region(产品支持的地域)”和“ImageUrl*(图片url地址)”。
步骤三 刚刚那个界面一直拉到下面,点击API 3.0 Explorer,进入sdk调用界面。
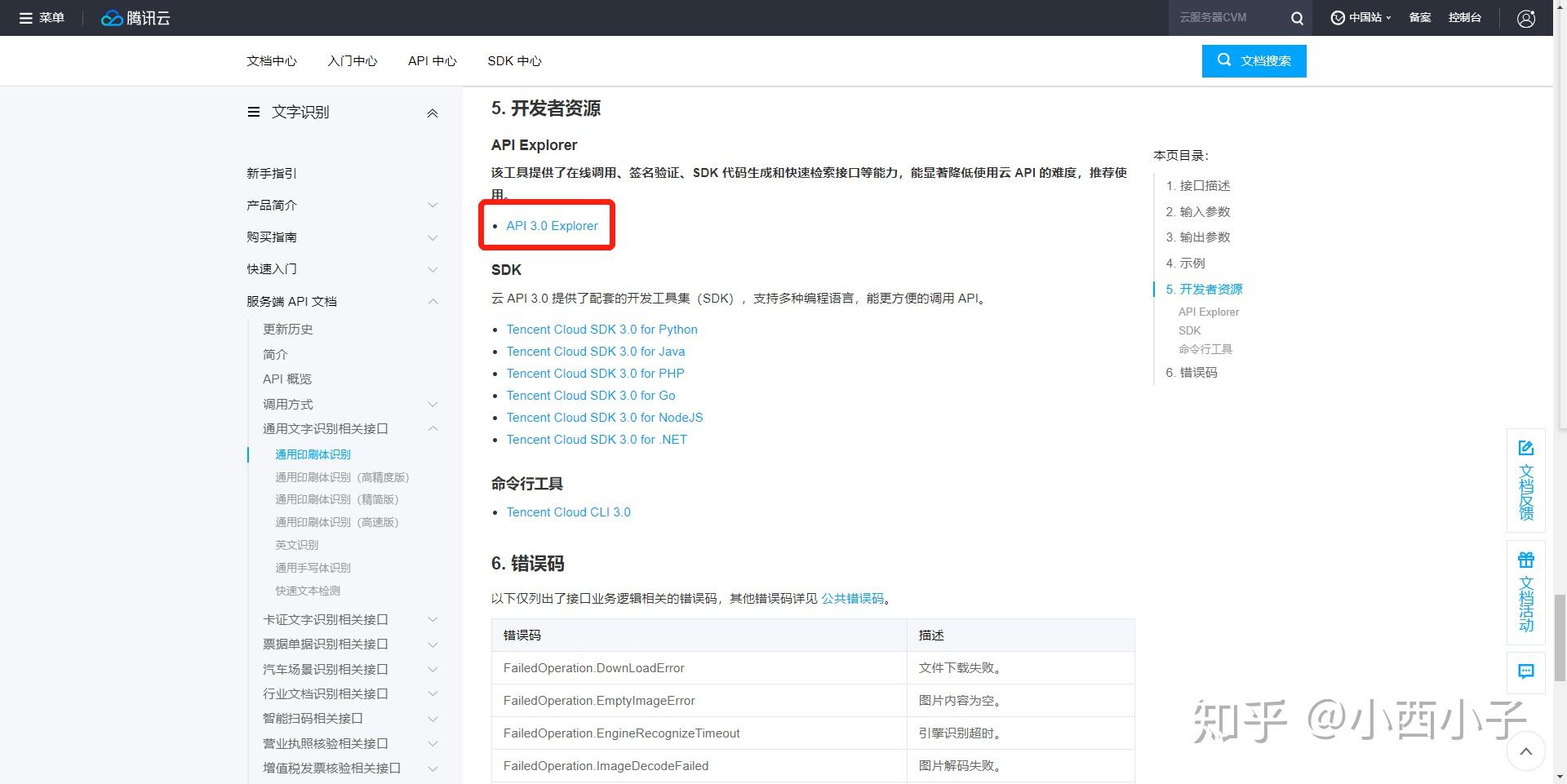
步骤四 点击个人密钥→查看文档,获取个人密钥(接口调用必须使用个人密钥)。
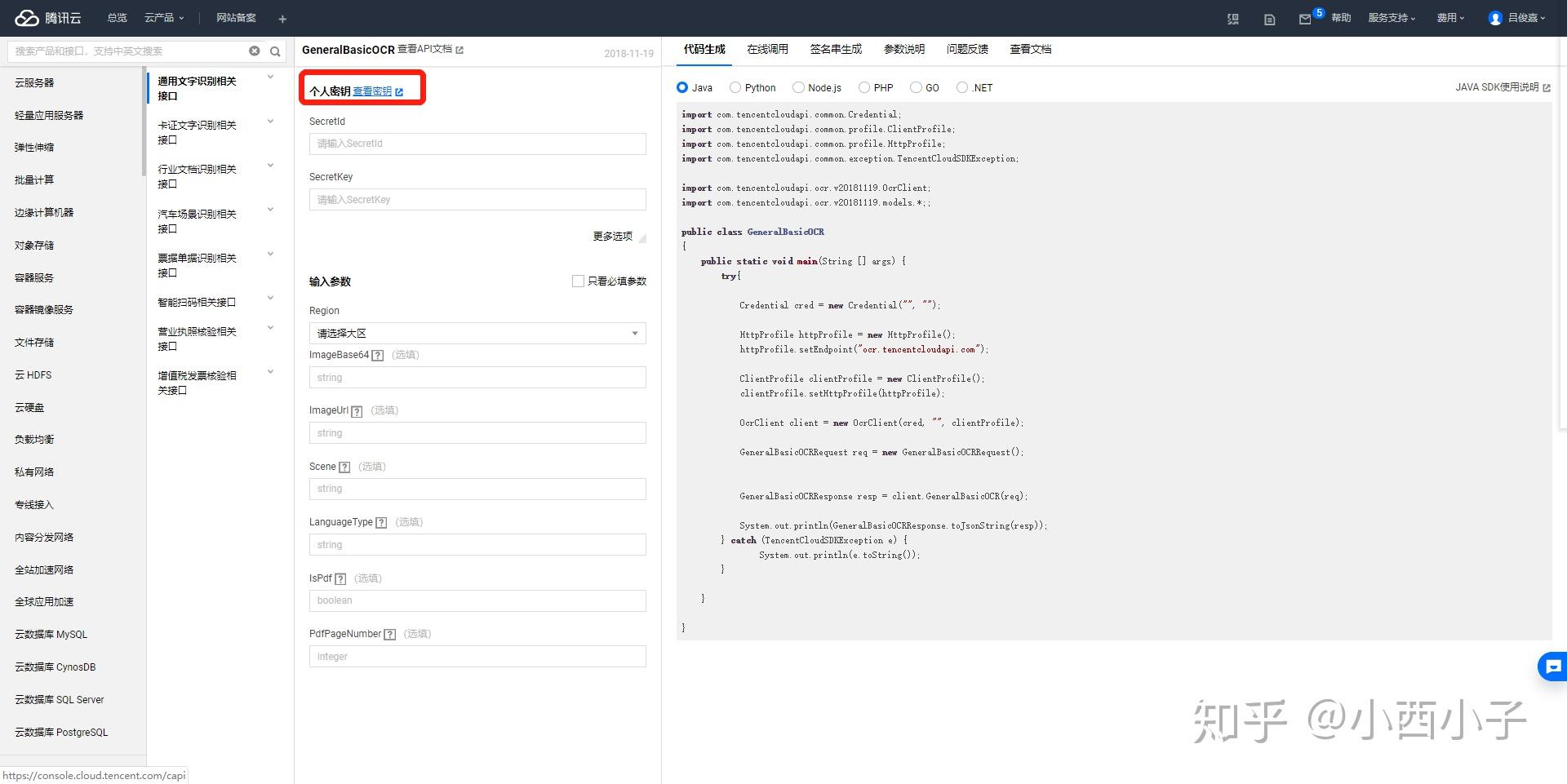
步骤五 点击“新建密钥”,查看和复制“SecretId”和“SecretKey”到sdk调用界面的对应位置。
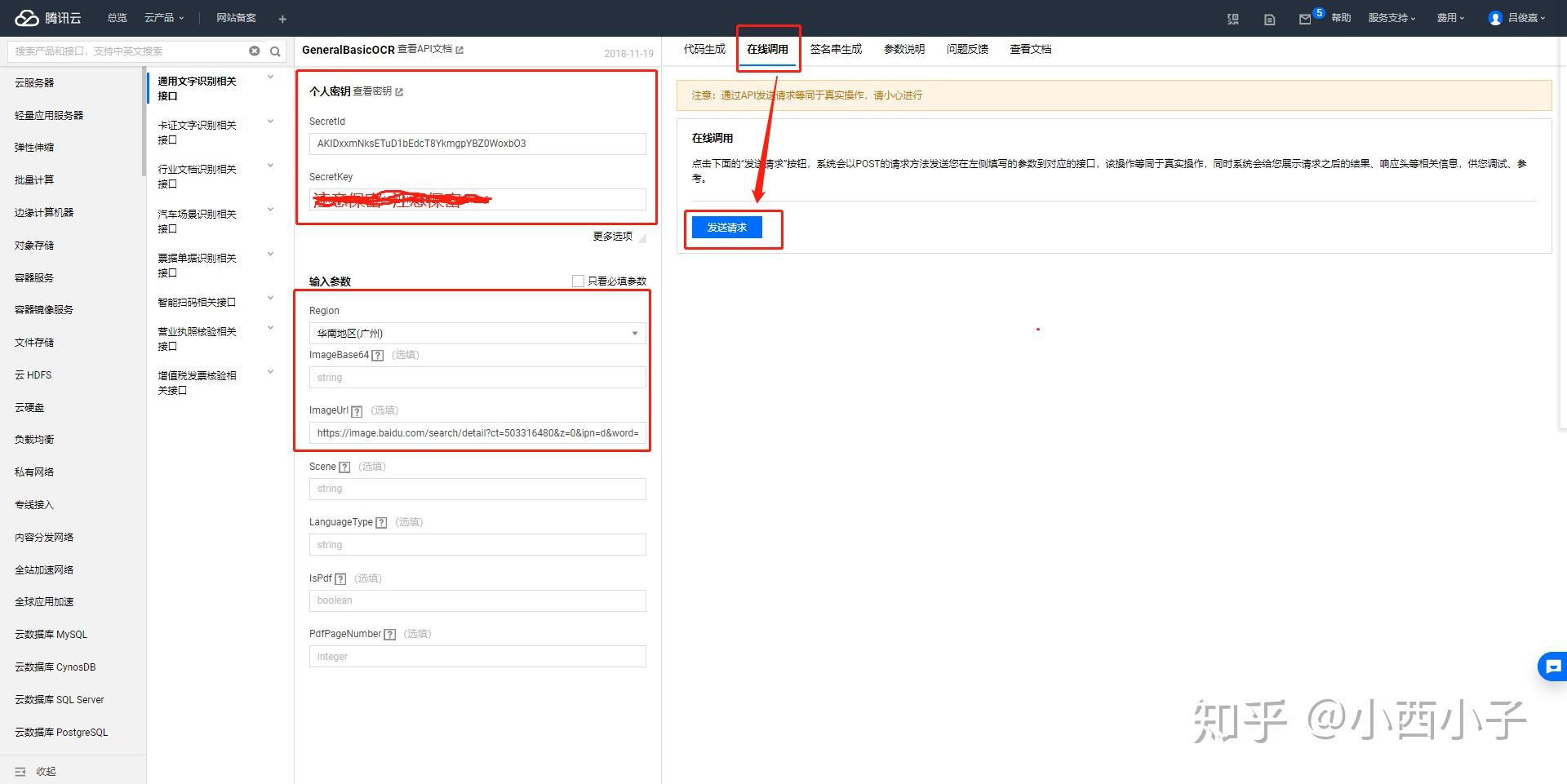
步骤六 接着填写输入参数,只需填写“Region(产品支持的地域,选择离你所在地最近的地址)”和“ImageUrl*(图片url地址)”,然后点击“在线调用”的“发送请求”,即可获取OCR模型的文字提取结果。
ps. 图片的url地址可以右键任意一个网络上的图片获取。
识别结果以json格式返回:
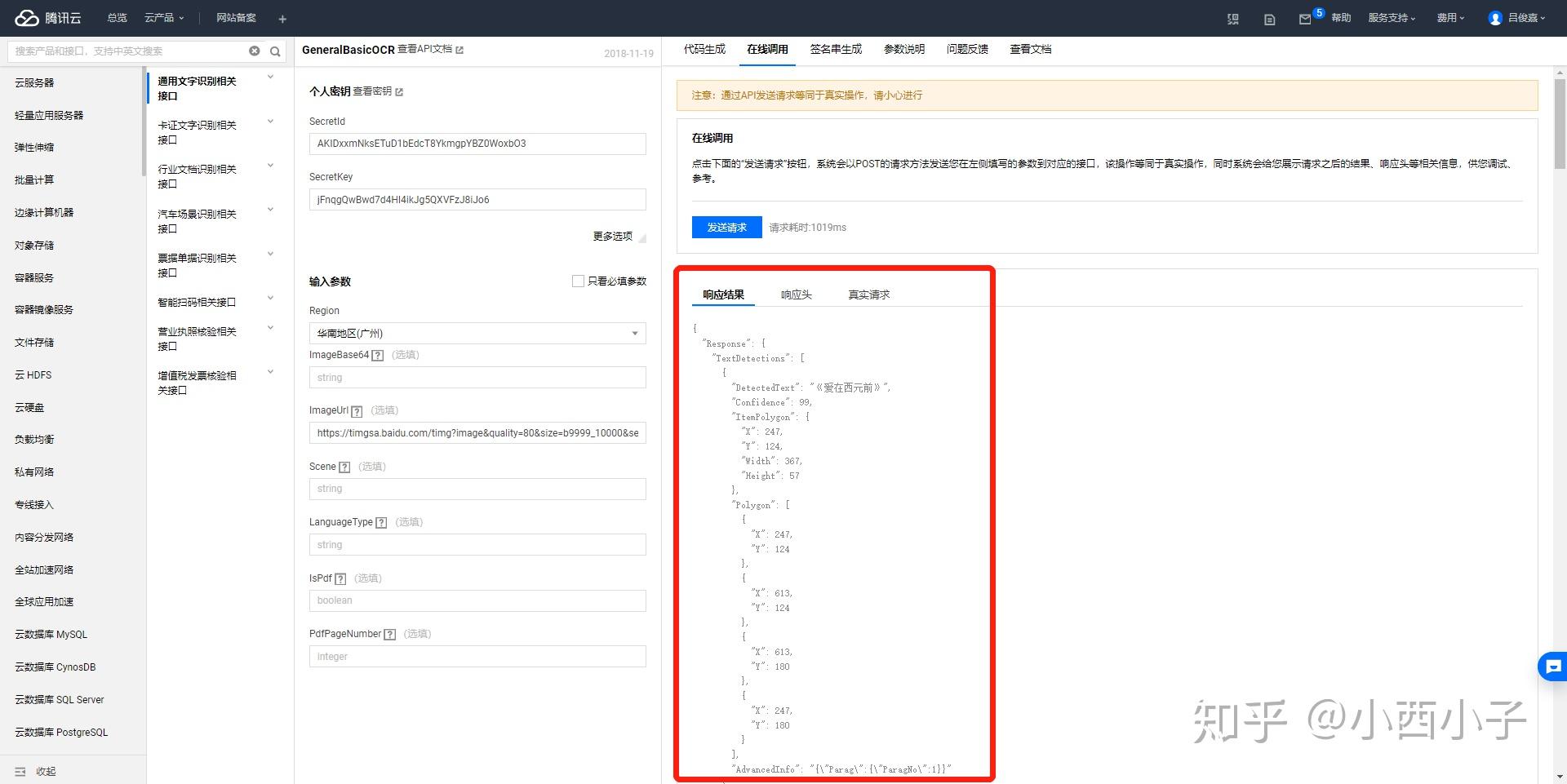
看到了“《爱在西元前》”,及其x轴y轴坐标位置。
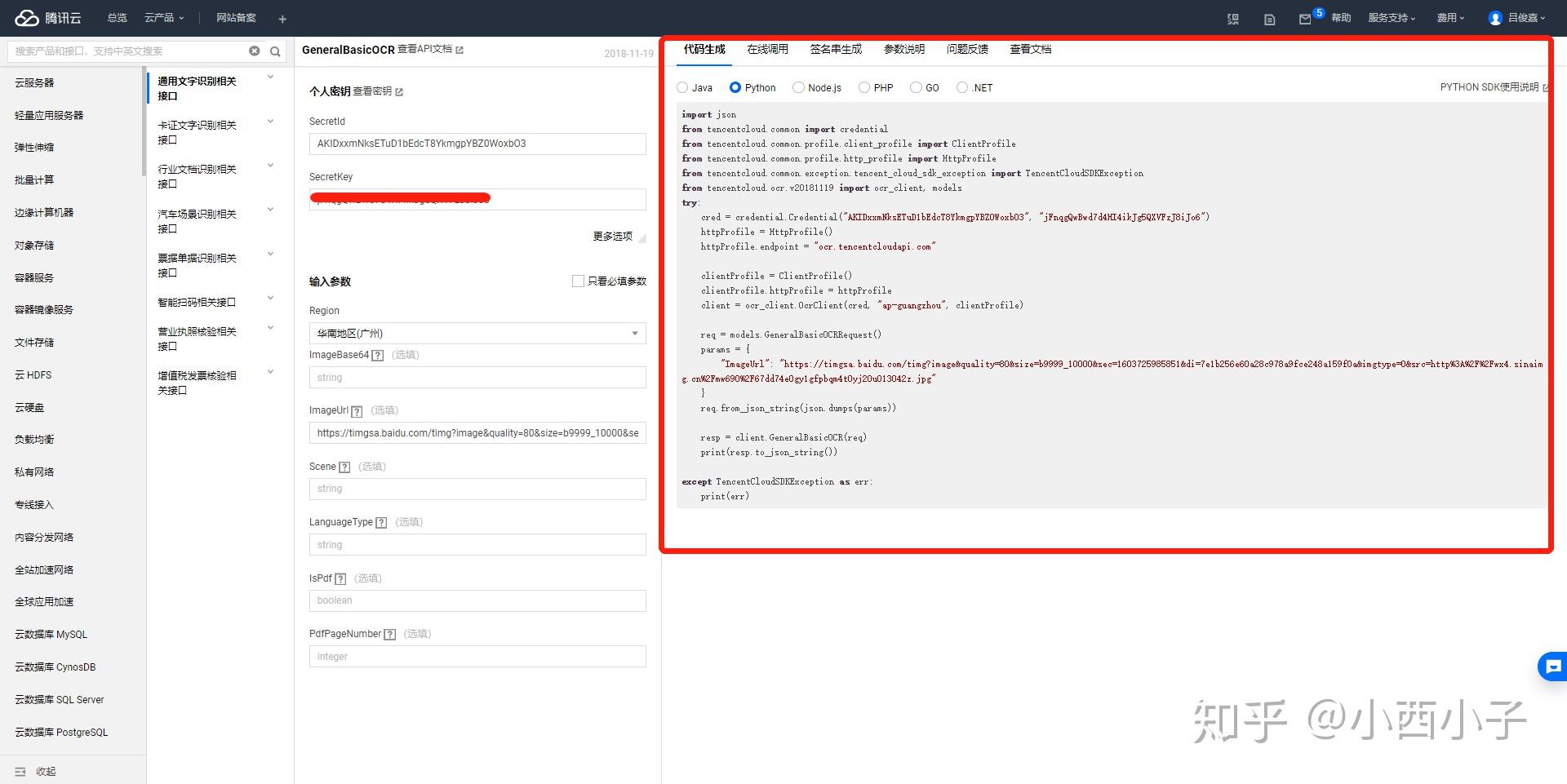
不会码代码不要紧,通过刚刚的调用过程已经自动根据填写的“个人密钥”和“输入参数”生成了对应的Java、python、Node.js、PHP等语言的代码,下面以python为例。
步骤一 在刚刚那个界面点击“代码生成”,选择“python”,点击右上角的“python SDK使用说明”。
步骤二 根据教程在python中pip安装sdk。
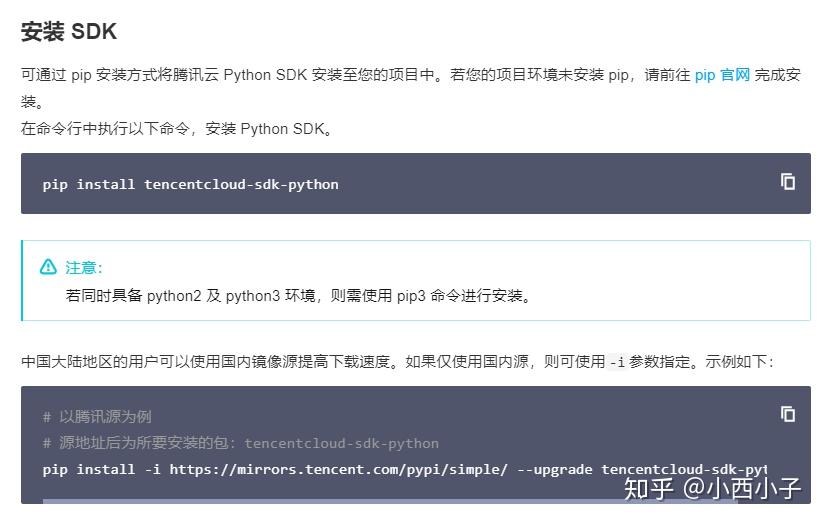
关于更多的pip技巧查看:
小西小子:万能python pip install大法
步骤三 复制刚刚的代码,然后到python的IDE界面进行运行调用sdk,即可完成OCR图像识别!
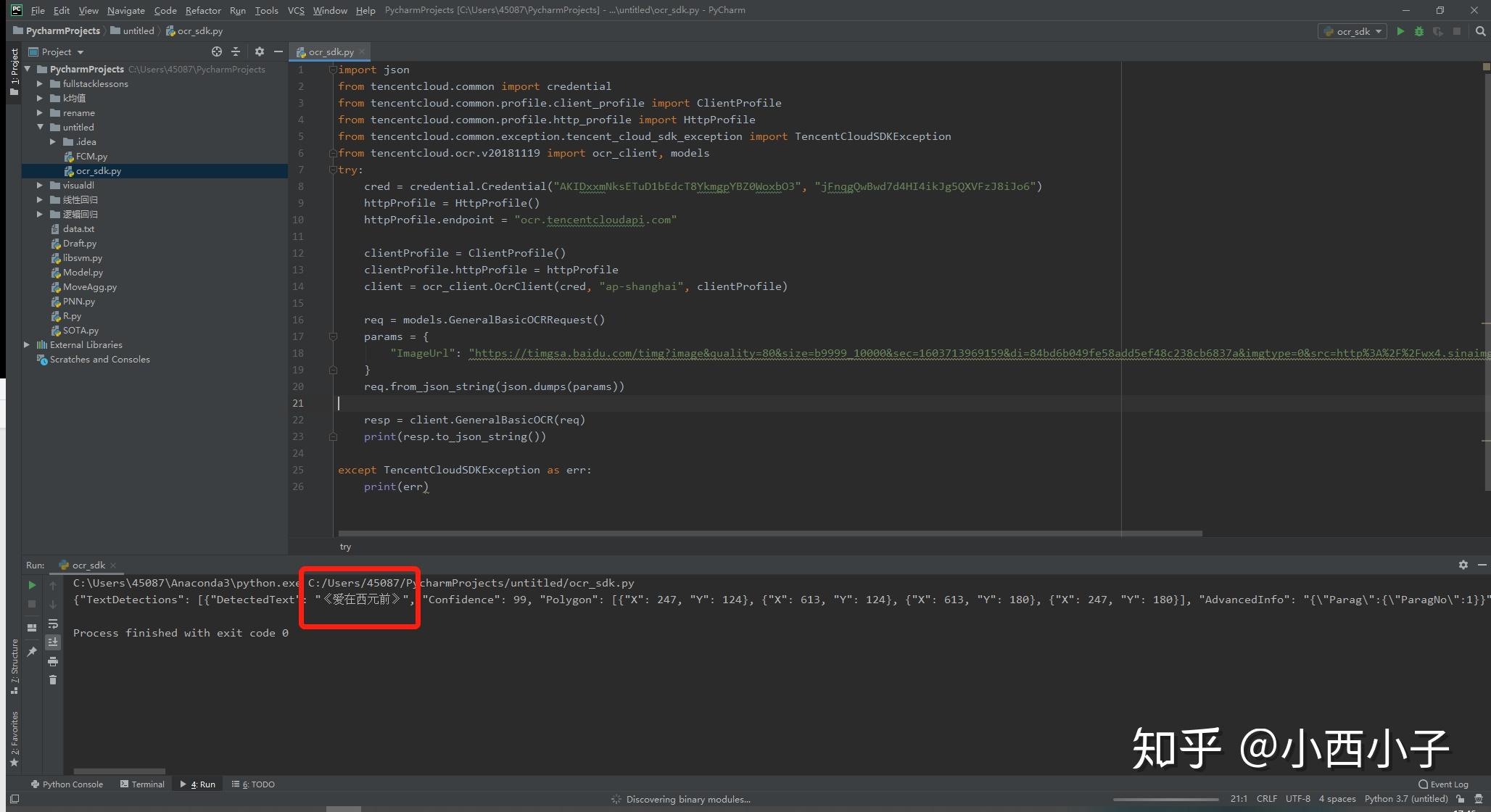
成功!
自此手把手教会了如何介绍了sdk和api的概念,并用OCR深度学习算法模型进行了实践,大家紧赶动手实操,之后就可以举一反三实现更多AI黑科技啦。
笔芯
SDK是什么?
SDK,即Software Development Kit的缩写,译作软件开发工具包。软件开发工具包是一个覆盖面相当广泛的名词,你甚至可以这么理解:辅助开发某一类软件的相关文档、范例和工具的集合都可以叫做SDK。
看到这儿你可能没懂SDK究竟是什么,别着急,慢慢往下看~
相信有过java学习经历的小伙伴们都知道,要运行java需要先在电脑上安装jdk,而jdk其实就是java SDK 。其安装过程就是下载一个EXE(Windows下)的应用程序,看起来好像jdk是一个应用程序。
然而实际上这个应用程序只是jdk的安装向导,它通过后台操作帮你在电脑上安装了Java的运行环境、工具和Java基础的类库,以上这些东西组合起来才是JDK的核心内容。
再举一个例子,我们的手机每天都会收到许多来自APP或系统的新闻推送、促销活动广告、短信验证码等等,它们大多都属于法规条文里规定的“第三方应用或服务”。
正是这些集成在APP里的第三方工具包,能够协助APP更加高效率、低成本地实现注入导航、支付、统计、广告等一系列功能。SDK就是这个例子里说到的第三方应用或服务。
相信通过以上两个例子,大家已经明白SDK究竟是什么了,自然也能明白,SDK并不单单是一个开发工具或程序。
SDK与API的区别
如果你还记得前边文章中企通查为大家介绍过的API,可能会有点疑惑:API可以调用第三方程序,SDK也可以使用第三方的软件,这两者之间有什么区别吗?
简单地讲,API是前端调用后端数据的一个通道,就是我们俗说的接口,通过这个通道可以无需调用源代码直接访问到后端的数据。
而SDK相当于是一个开发者集成的环境,API则是基于SDK之下的数据接口,可以在SDK的环境之下调用API数据。
你可以把SDK想象成一个虚拟的程序包,在这个程序包中有一份做好的软件功能,这份程序包几乎是全封闭的,只有一个小小接口可以联通外界,这个接口就是API。
SDK的组成
一个完整的SDK应该包括以下内容:
1.接口文件和库文件
笼统地说就是先前提到过的API。通过将底层的代码进行封装保护,提供给用户一个调用底层代码的接口。
2.帮助文档
用来解释接口文件和库文件(即API)的功能,以及介绍相关的开发工具,操作示例等。
3.开发示例
即简单的成品DEMO展示,包括源代码。
4.实用工具
通常是指用来协助用户进行二次开发的工具,比如二次开发向导、API 搜索工具、软件打包工具等。
SDK与信息安全
目前在国内互联网环境中大部分的SDK都是免费的,为了鼓励开发者使用其系统或者语言,许多SDK是免费提供的。
软件工程师通常从目标系统开发者那里获得软件开发包,也可以直接从互联网下载。

从SDK的被使用情况来看,App对SDK有较强的依赖性,SDK安全俨然已经成为整个移动互联网生态中极其关键的一环,它们收集哪些信息、如何使用和保护这些信息也就十分重要。
因此,由第三方SDK引入的安全问题也不容忽视。比如由于开发者的安全能力水平有限而导致的SDK安全漏洞;或是开发者故意预留“后门”,以便收集用户信息或执行越权操作。
截至目前,国内对于第三方SDK超出必要范围收集其他信息尚没有明确的相关条文规定。
奥德塔动态大数据资源中心基于互联网+大数据+人工智能技术构建,通过分布式数据采集集群、数据特征提取、机器学习和深度学习算法模型、NLP文本分析等技术实现了数据的实时更新、高度关联、动态下载、主动推送,为企业采购风控、销售客户评估、Al精准获客、精准招商、投融资、高校科研机构、政府事业单位提供了全方位的数据支持和数据应用解决方案;基于数据资源中心和分析专家团队为客户提供了行业产业分析报告、发展趋势报告和相关指数报告等专业咨询服务支持。
参考文献:
什么是SDK?_PlayGrrrrr的专栏-CSDN博客_sdk
https://mp.weixin.qq.com/s/oJs4MWJrUjvD7RpoZus65w1.从Amazon下载官方资料
amazon有已经封装好java SDK,可以直接调用API来获取Aor报表。
1.1下载 selling-partner-api-models-main.zip
1.2下载 swagger-codegen-cli-2.4.19.jar
2.1解压selling-partner-api-models-main.zip,打开selling-partner-api-models-main/models/sellers-api-model/sellers.json和selling-partner-api-models-main/models/reports-api-model/reports_2020-09-04.json。
2.2将swagger-codegen-cli-2.4.19.jar和sellers.json以及reports_2020-09-04.json放到一个新建的文件夹里面。
2.3使用swagger和xxx.json生成两个Java项目
// [path to selling-partner-api-models\clients\sellingpartner-api-aa-java folder]是指 selling-partner-api-models的下载路径\clients\sellingpartner-api-aa-java
//生成seller项目,这里的seller是一个新建的文件夹
java -jar C:\amazonApi\swagger-codegen-cli.jar generate -i C:\amazonApi\Sellers.json -l java -t [path to selling-partner-api-models\clients\sellingpartner-api-aa-java folder]\resources\swagger-codegen\templates\ -o C:\amazonApi\sellers
//生成repoet项目 ,这里的reports是一个新建的文件夹
java -jar C:\amazonApi\swagger-codegen-cli.jar generate -i C:\amazonApi\reports_2020-09-04.json -l java -t [path to selling-partner-api-models\clients\sellingpartner-api-aa-java folder]\resources\swagger-codegen\templates\ -o C:\amazonApi\reports 2.4 打开两个项目,打成jar包放到本地maven仓库
给sellers打包过程中缺少SellingPartnerAPIAA依赖
- 打包之前应该先用idea打开“你下载的selling-partner-api-models-main.zip解压包/clients/sellingpartner-api-aa-java”,然后使用maven将项目install到maven仓库里面
- 继续回到sellers中尝试进行打包,找不到包
com.amazon.SellingPartnerAPIAA,查看依赖发现没有引入,那我们就将起引入即可,然后打包就可以成功了
若给reports打包过程中出现了同样的问题,那么继续引入依赖并打包
3.1打开selling-partner-api-models-main/clients/sellingpartner-api-documents-helper这个项目,打成jar包放入本地maven仓库
<dependency>
<groupId>com.amazon.sellingpartnerapi</groupId>
<artifactId>sellingpartnerapi-aa-java</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>io.swagger</groupId>
<artifactId>swagger-java-client</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>com.amazon.sellingpartnerapi</groupId>
<artifactId>sellingpartner-api-documents-helper-java</artifactId>
<version>1.0.0</version>
</dependency>5.1配置AWS凭证
AWSAuthenticationCredentials awsAuthenticationCredentials = AWSAuthenticationCredentials.builder()
.accessKeyId("you accessKeyId")
.secretKey("you secretKey")
.region("us-east-1")//请求地区
.build();5.2 配置AWS凭证提供商
AWSAuthenticationCredentialsProvider awsAuthenticationCredentialsProvider = AWSAuthenticationCredentialsProvider.builder()
.roleArn("you roleArn")//IAM角色
.roleSessionName("you roleSessionName")
.build();5.3 配置LWA凭证
LWAAuthorizationCredentials lwaAuthorizationCredentials = LWAAuthorizationCredentials.builder()
.clientId("you clientId")
.clientSecret("you clientSecret")
.refreshToken("you refreshToken")
.endpoint("https://api.amazon.com/auth/o2/token")//LWA验证服务器URI
.build();5.4 创建reportAPI实例
ReportsApi reportsApi = new ReportsApi.Builder().awsAuthenticationCredentials(awsAuthenticationCredentials)
.awsAuthenticationCredentialsProvider(awsAuthenticationCredentialsProvider)
.lwaAuthorizationCredentials(lwaAuthorizationCredentials)
.endpoint("https://sellingpartnerapi-na.amazon.com")//请求地区
.build();6.1创建报表返回reportId
tip:创建报表比较消耗时间,写测试逻辑的时候建议将创建报表返回的reportId用变量保存起来,然后注释掉这一段(创建报表返回reportId的代码)
CreateReportSpecification body = new CreateReportSpecification();
body.setMarketplaceIds(Arrays.asList("you MarketplaceId","you MarketplaceId"...)); body.setReportType("GET_FLAT_FILE_ALL_ORDERS_DATA_BY_ORDER_DATE_GENERAL");
body.setDataStartTime(iso_start);// 示例:iso_start=OffsetDateTime.parse("2021-03-16T00:00:00Z")
body.setDataEndTime(iso_end);
CreateReportResponse report = reportsApi.createReport(body);如果获取报表出现org.codehaus.stax2.ri.EmptyIterator.getInstance()Ljava/util/Iterator;错误,请添加依赖
<dependency>
<groupId>org.codehaus.woodstox</groupId>
<artifactId>stax2-api</artifactId>
<version>4.1</version>
</dependency>6.2根据reportId查询创建报表状态并返回reportDocumentId
tip1: 这里获取的状态,最好加一个循环,因为amazon每次响应不一定是正确的
tip2: 在循环外定义status的时候,不要定义为空字符串或着null,会出现空指针异常
GetReportResponse apiReport = reportsApi.getReport(reportId);
Report payload = apiReport.getPayload();
String status = payload.getProcessingStatus().getValue();
//如果status为DONE说明创建成功,则会返回reportDocumentId6.3根据reportDocumentId获取报表下载的url和相关加密参数
GetReportDocumentResponse reportDocument = reportsApi.getReportDocument(payload.getReportDocumentId());6.4下载报表
DownloadHelper downloadHelper = new DownloadHelper.Builder().build();
AESCryptoStreamFactory aesCryptoStreamFactory = new AESCryptoStreamFactory.Builder(reportDocument.getPayload().getEncryptionDetails().getKey(), reportDocument.getPayload().getEncryptionDetails().getInitializationVector()).build();
DownloadSpecification downloadSpecification = new DownloadSpecification.Builder(aesCryptoStreamFactory, reportDocument.getPayload().getUrl()) .withCompressionAlgorithm(CompressionAlgorithm.fromEquivalent(reportDocument.getPayload().getCompressionAlgorithm())).build();
DownloadBundle downloadBundle = downloadHelper.download(downloadSpecification);
BufferedReader reader = downloadBundle.newBufferedReader();
//后续对reader对象进行操作,获取数据生成文件。PS:大家看了后觉得对自己有帮助可以三连留言,欢迎提出宝贵意见,如想进行技术交流欢迎加入Amazon各类API开发交流群!请添加技术人员微信:x118422邀请进群~
元宇宙,火得猝不及防。
短短几个月时间,Minecraft、Roblox 进入了更多人的视野,GREE、英伟达、微软等陆续发布相关产品解决方案,韩国、日本还从国家层面宣布大力布局元宇宙赛道。《头号玩家》描绘的情景似乎明天就能成为现实。

彭博行业研究报告预计元宇宙将在 2024 年达到 8000 亿美元市场规模,普华永道预计元宇宙市场规模在 2030 年将达到 1.5 万亿美元。市场潜力无限。
究竟什么是元宇宙?简单来说,元宇宙可以理解为平行于现实世界始终在线的虚拟世界。在这个世界中,除了吃饭、睡觉需要在现实中完成,其余包括工作、社交、娱乐等都可以在虚拟世界中实现。
神秘、未知,曾经只可能出现在梦中的幻境或许在不久的将来就能实现,想想就兴奋不已。
然而一个不得不承认的现实是:高拟真度的虚拟世界还没有建成,人们在虚拟世界的形象还没有立起来,终端还支撑不起那样的数据计算量,交互体验还不够好……一系列问题等着被攻克,元宇宙的大门还没有打开。
正如前文所述,互联网的终极目标——元宇宙,可以打破人类社会活动的空间与时间的界限。在一个创造的虚拟空间里,来自世界各地的人们进行着真实的社会活动,社交、商业、娱乐...而其中“虚拟人”和“实时互动”能力是必不可少的两大核心技术。
虚拟人代表了个体可辨识度的形象和身份,实时互动能力可以实现沉浸式真实的社交活动,最终模糊虚拟和现实的边界。
元宇宙中虚拟人是指具有数字化外形的虚拟人物,与具备实体的机器人不同,虚拟人依赖显示设备存在。
一般来说,我们将虚拟人分为两类:一类是真人可驱动的虚拟人,另一类是具有人工智能的 AI 智能虚拟人。
元宇宙是另一个真实的人类社会活动的无限广阔空间,所以技术上实现真人可驱动的虚拟人是迈入“新世界”的第一步,当然如《失控玩家》里具有自我意识的 NPC 虚拟人物如果也能在元宇宙中实现,更是让人无限遐想。

因此元宇宙的虚拟人应具备以下三方面特征:
- 虚拟人外在形象,拥有人的外观或者卡通等有趣生动的外貌,具有特定的相貌、性别和性格等人物特征;
- 虚拟人表达能力,拥有人的行为,具有用语言、面部表情和肢体动作表达的能力;
- 虚拟人感知互动能力,拥有人的思想,具有识别外界环境、并能与人交流互动的能力。
外在、表达、感知,这些我们几乎每个现实人类都拥有的能力,对技术和设备的要求其实很高。
首先,爱美之心人皆有之,现实生活中的我离“盛世美颜”还有那么一小段距离,也许在新的世界里,我可以拥有“人生如果再来一次”的机会,倾国倾城走向人生巅峰。但是创建一个“美而好”虚拟形象,并不是一件容易的事情。AI 和图像的技术门槛很高,例如 3D 建模,高算力和渲染对设备性能要求等都是是一个业界难题。
其次,拥有了“沉鱼落雁、闭月羞花、倾国倾城”的盛世美颜后,光是一个静态形象,没有表情、没有肢体表达,元宇宙的世界瞬间变成“行尸走肉”的世界。这里涉及到语音交互(TTS、ASR、NLP 等)、动画合成(驱动、渲染)等 AI 相关技术,对技术要求的门槛可想而知。
最后,元宇宙映射的是真实人类世界,那么人类社会活动的基本元素“互动”是构建元宇宙的最关键一环,为了还原真实线下的无违和感的互动体验,需要低延时、高质量的实时通信服务保障,但是当前复杂多变的公网环境、终端设备等因素对通信传输是一大挑战。
为了能够在“新世界”里“自由翱翔”,虚拟形象要“美好”,表达要“清楚”,沟通互动要“顺畅”……需要解决很多问题,但是目前互联网广大用户还是以移动端手机为主,机型种类等也复杂多样。
因此,不需要外戴设备,又能解决实现虚拟人互动所需强大算力引起的性能问题,同时在复杂网络环境也能保障实时互动效果的解决方案,是当前最契合实际也是最好切入“元宇宙”的不二之选。
网易云信,来了!
https://xg.zhihu.com/plugin/544489fb615b9bb5ea76ff4119cbd3c1?BIZ=ECOMMERCE针对当前面临的诸多难题,网易云信联合网易伏羲实验室推出业界首个「虚拟形象+RTC」融合 SDK,并且基于该融合 SDK 形成网易云信虚拟形象实时互动解决方案。
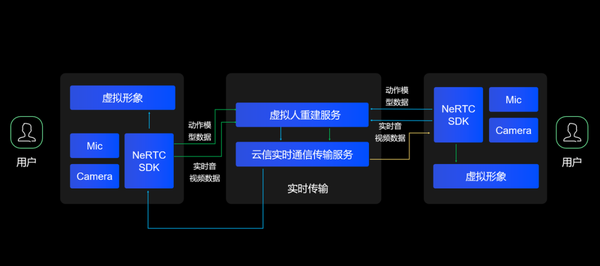
该解决方案不仅可以生动还原虚拟人形象,同时结合了网易云信 WE-CAN(Communications Acceleration Network)实时传输能力,可以实现虚拟人实时互动,帮助企业客户 0 门槛也可实现虚拟形象实时互动场景,迈出元宇宙的第一步。
 表情迁移 DEMOhttps://www.zhihu.com/video/1443938273983275008
表情迁移 DEMOhttps://www.zhihu.com/video/1443938273983275008具体来说,网易云信虚拟形象实时互动解决方案具备六大优势:
1. 形象:高度还原,极致灵动。
网易云信虚拟形象实时互动解决方案可以通过摄像头或上传的视频检测用户面部表情动作,从而驱动 3D 虚拟人物做出相同表情,包括五官表情、头部姿态、眼球运动、吐舌头等均能还原追踪。
 动作迁移DEMOhttps://www.zhihu.com/video/1443938417990602752
动作迁移DEMOhttps://www.zhihu.com/video/1443938417990602752部分传统的做法为了减少设备性能要求,往往以牺牲用户体验作为代价,例如动画匹配方式:当用户进行说话,或者动作行为后,在预设的“表情、动作数据库”进行帧动画的匹配,最后对一系列帧进行匹配播放实现虚拟人的“表达”。但是人类的行为是多样化的、随机的,不可能对所有行为进行预知预设,可想而知会出现所谓的“面瘫”或者“僵尸”。
而网易云信虚拟形象实时互动解决方案采用的是“端上实时捕捉、云上实时驱动”的方案,相比动画匹配方案,更真实灵动。
2. 硬件:无需穿戴设备,手机即可实现。
网易云信虚拟形象实时互动解决方案支持使用普通单目摄像头进行迁移,无需其他动捕设备,简单便捷。只需普通的移动端设备或者 PC 端设备安装网易云信 SDK 后即可生成并驱动虚拟人,和远端真人驱动的虚拟人进行实时互动。
3. 性能:端-云协同,千元机也可畅玩。
用户通过终端设备(移动端或者 PC 端)进行音视频采集后,通过网易云信的 SDK 进行动作模型数据输出,连同采集到的音视频数据传输到云端进行虚拟形象重建合成。
通过在云端进行动捕数据分析建模渲染,网易云信虚拟形象实时互动解决方案极大地减轻双端算法性能压力,降低了用户入门门槛,让更多千元机用户也可以提前体验虚拟互动的乐趣,感受元宇宙福利。
4. 互动:低延时无卡顿,堪比“面对面沟通”。
作为融合通信云专家,网易云信的 RTC 能力在行业一直处于领先地位。针对元宇宙中必不可少的“实时互动”场景,网易云信 WE-CAN 全球智能路由网络为“0 距离”沟通保驾护航。
面对复杂多样的网络环境、良莠不齐的终端设备,WE-CAN 可以稳定提供全球范围内毫秒级延时的实时互动能力,通过智能路由网络择优选择最佳路线,百毫秒内触达全球数百个国家和地区,为 99.9% 的通话提供无卡顿的音视频服务。基于高可靠低延时的网易云信 WE-CAN 全球智能路由网络,网易云信虚拟形象实时互动解决方案可以实现虚拟人实时互动,像现实世界面对面对话一样。
5. 便捷:1 个 SDK 实现 2 大核心技术。
面对元宇宙中虚拟形象和实时互动两大难题,网易云信的一体化解决方案将虚拟形象和 RTC 在技术层面深度结合封装,客户再也无需对接多个供应商,只需一个 SDK 就可以构建一个充满遐想的高体验的虚拟形象实时互动场景。
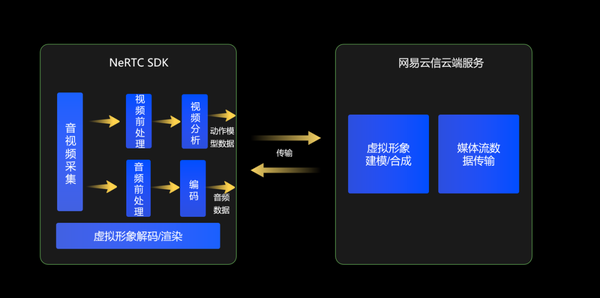
网易云信「虚拟形象+RTC」融合 SDK 承担了音视频采集/前处理,数据分析、编码传输、解码渲染等轻量级工作,将复杂的高算力的工作转移到云端,借助融合 SDK 形成高效的端-云协同工作模式,提供虚拟形象实时互动一体化能力。跨越高深的技术壁垒,只需这一个 SDK。
6. 场景:多行业应用,降本增效快人一步。
值得一提的是,网易云信虚拟形象实时互动解决方案不仅能够应用于元宇宙世界或娱乐社交行业,还可以广泛应用于各行各业,帮助企业降本增效的同时,也能提升客户体验,从而提高用户留存率,创造营收。
(1)金融行业
虚拟数字人客户服务,提供 7 x 24 小时不打烊的温暖服务。

(2)电商行业
虚拟人直播带货+客户服务,带来业务营收、客户体验双重提升。

尽管进入元宇宙需要解决这样或那样的问题,但不可否认,元宇宙场景的实现、元宇宙产业的成熟,只是时间问题。《头号玩家》里的场景可能还得再想象几年,但虚实融合已是互联网发展的大趋势。
一直以来,网易云信精益求精地打磨技术,站在行业前沿探寻风向,希望能够帮助行业客户不错失每一个机会。
现在,欢迎各位朋友和网易云信一起,迈出进入元宇宙的第一步。
https://xg.zhihu.com/plugin/544489fb615b9bb5ea76ff4119cbd3c1?BIZ=ECOMMERCEMegFile 本文作者:旷视李阳
旷视研究院在探索大数据存储方案的过程中,先后尝试了多种文件存储系统,包括 POSIX 协议的本地存储、OSS 等。
多种文件存储系统带来了开发上的困难,对于存储于不同文件系统的文件,在访问时需要针对不同文件系统的 SDK 编写复杂的代码,增加了开发者的工作量。除此之外,跨系统的文件访问在代码实现上也不够优雅,导致代码不易读。
为了解决上述问题,我们开发了 MegFile 。
MegFile 作为 Python 文件读写 SDK,主要提供三个特性:
- 方便、齐全并和标注库风格保持一致的 API
- 快速 s3 文件文件读写
- 支持 s3 的 Glob AP
与 Python 标准库相似,MegFile 提供了函数式 API 和 Path-Like API 两种文件访问方式。
以 smart 开头的函数库提供了形如 smart_open, smart_glob,smart_listdir,smart_exists 等函数,来进行文件访问;同时,用户也可以使用 SmartPath 构建一个 Pathlike 对象,提供了open,unlink,remove 等方法。
不论是 SmartPath 还是 smart 系列函数,都能够识别不同文件系统路径协议 (例如:file:///path/to/file、s3://bucket/key),并正确完成对应的操作,为多种文件系统提供了统一流畅的访问体验,极大简化了跨后端文件访问的代码量和编写难度。
在大型项目和读写密集型任务上,文件读写速度非常重要。如果为了支持跨后端文件读写而牺牲读写速度是得不偿失的。在 MegFile 中,使用 smart_open 方法不仅可以打开各种协议的资源,在旷视内部最常用的 s3 协议上的 reader / writer 内部提供了多线程实现,并通过自适应的预读策略,使得其速度比目前已知 Python 竞品(smart-open 和 facebook-iopath)都要快。具体对比呈现在后文表中。
MegFile 读 s3 文件如此快的秘诀,就是多线程加预读。
在 MegFile 中,s3 所有的文件读写都是以块为单位的,一个块的大小为 8MB。在 s3 读取文件时,会通过线程池预读若干块数据到本地,本地维护一个 LRU 来存储数据块,为每个文件最多维护 16 个块。
而预读的策略,通过观察用户的行为,我们发现,用户通常会以三种模式访问文件:
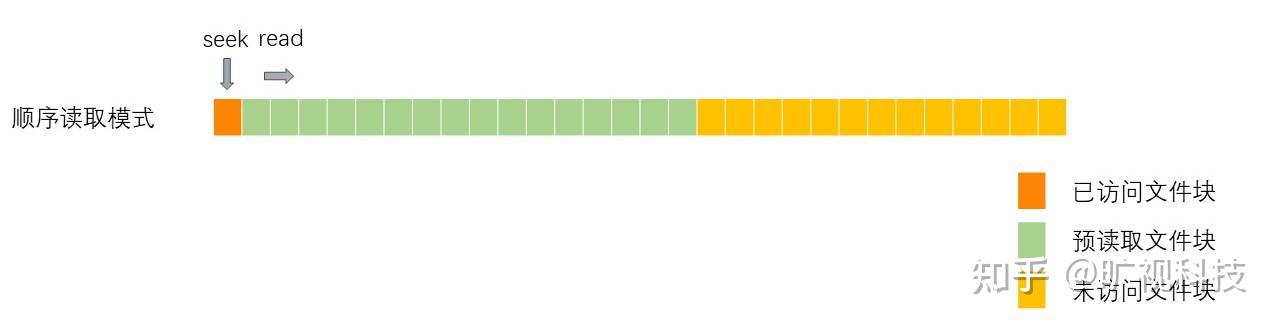
- 从头到尾完整顺序读取文件,这种方式最常见,称之为:顺序读取模式
- 在 2、3 个位置来回跳着读,常见于读取 tar 包和视频时,在文件的 header 和 内容 之间来回读取,称之为:多块反复读取模式
- 在随机的位置读取很少数据,称之为:纯随机读
MegFile 的 S3PrefetchReader 能够通过记录用户在每个文件句柄上过往的行为,判断用户有几个读取的热区,来自适应选择这 3 种读取模式加快读取速度。
当文件被顺序读取时,文件只有一个读取热区,reader 会预读 16(LRU 的大小) / 1(读取热区个数) = 16 个块。
with smart_open('path/to/file') as fd:
fd.read()预读的文件块如图所示:
顺序读取的性能对比如下表所示:
| 库 | 模式 | 文件大小 | 耗时 | 读写速度 |
|---|---|---|---|---|
| smart-open | 'r' | 1GB | 7.308 s ± 196.33 ms | 136.84 MB/s |
| iopath | 'r' | 1GB | 4.08 s ± 170 ms | 245.09 MB/s |
| MegFile | 'r' | 1GB | 4.054 s ± 460.94 ms | 246.68 MB/s |
| smart-open | 'r' | 10MB | 258.77 ms ± 37.96 ms | 38.64 MB/s |
| iopath | 'r' | 10MB | 197 ms ± 5.12 ms | 50.76 MB/s |
| MegFile | 'r' | 10MB | 196.98 ms ± 2.17 ms | 50.77 MB/s |
| smart-open | 'w' | 1GB | 26.467 s ± 1.454 s | 37.78 MB/s |
| iopath | 'w' | 1GB | 14.2 s ± 228 ms | 70.42 MB/s |
| MegFile | 'w' | 1GB | 12.687 s ± 97.75 ms | 78.82 MB/s |
| smart-open | 'w' | 10MB | 1.306 s ± 37.41 ms | 7.66 MB/s |
| iopath | 'w' | 10MB | 717 ms ± 235 ms | 13.94 MB/s |
| MegFile | 'w' | 10MB | 401.40 ms ± 40.93 ms | 24.91 MB/s |
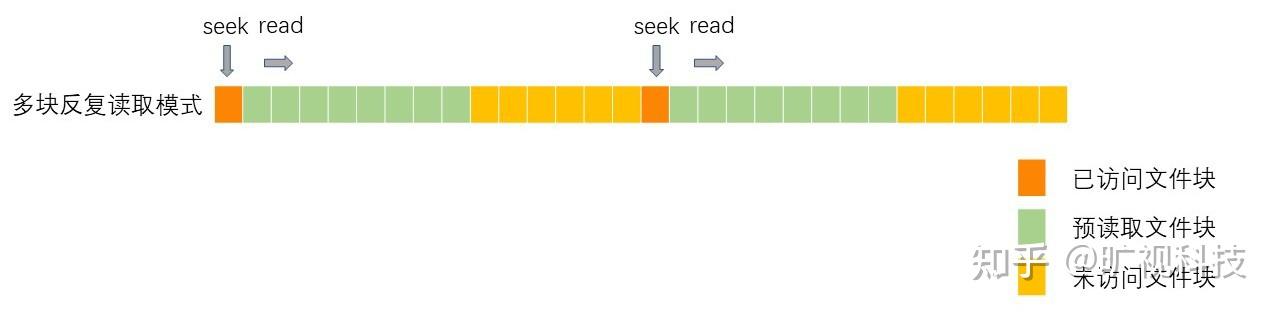
当文件在若干个块中不停切换时,reader 会为每个热区预读取 [16 / n] 个块,n 为读取热区的数量,进入多块反复读取模式,以加快读取 tar 包和视频等结构化文件的读取速度。
with smart_open('path/to/file') as fd:
fd.seek(0)
fd.read(1024) # 读取文件头
fd.seek(65536)
fd.read(1024) # 读取数据内容
fd.seek(0)
fd.read(1024) # 读取文件头
fd.seek(65536 + 1024)
fd.read(1024) # 读取数据内容
...预读的文件块如图所示:
多块反复读的性能对比如下表所示:
| 库 | 模式 | 耗时 | 文件大小 | 读取内容总大小 | 读写速度 |
|---|---|---|---|---|---|
| smart-open | 'r'(触发多块反复读) | 5.41 s ± 1.63 s | 1 GB | 80 MB | 14.44 MB/s |
| MegFile | 'r'(触发多块反复读) | 1.25 s ± 563 ms | 1 GB | 80 MB | 64 MB/s |
| iopath | 'r'(触发多块反复读) | 4.96 s ± 356 ms | 1 GB | 80 MB | 16.13 MB/s |
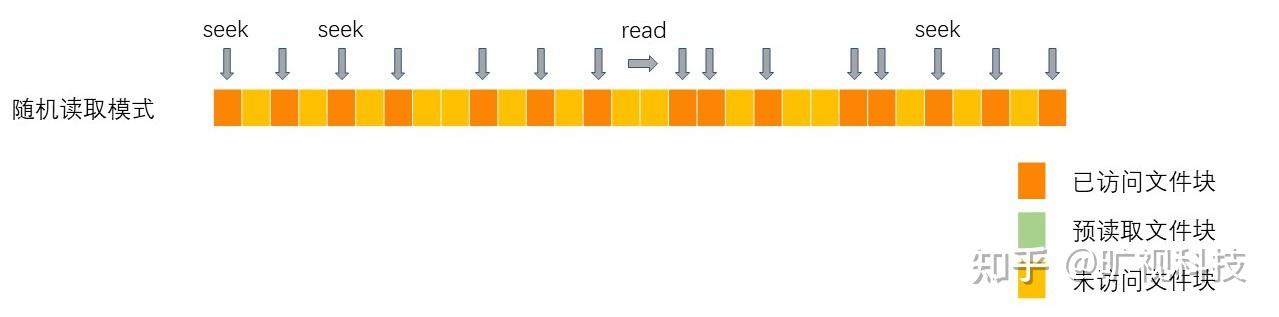
当文件读取的热区大于 16 个,每次只会读取 [16 / 16] = 1 个块,也就是不再预读文件,同时,如果每次 seek 后读取内容都小于 8KB 时,会进入随机读取模式。
这时我们认为预读已经不再划算,每次用户需要多少数据就读取多少数据是最优解,因此这时 reader 不会再预读数据,并且不再一次性读取 8MB 数据。
with smart_open('path/to/file') as fd:
fd.seek(2048)
fd.read(1024) # 随机读一段
fd.seek(65536)
fd.read(1024) # 再随机读一段
...读取的文件块如图所示:
随即读取的性能对比如下:
| 库 | 模式 | 耗时 | 文件大小 | 读取内容大小 | 读写速度 |
|---|---|---|---|---|---|
| smart-open | 'r'(随机读取) | 32.4 s ± 2.86 s | 1 GB | 4000 MB | 123.46 MB/s |
| iopath | 'r'(随机读取) | 3.4 s ± 296 ms | 1 GB | 4000 MB | 1076.47 MB/s |
| MegFile | 'r'(随机读取) | 27 s ± 2.17 s | 1 GB | 4000 MB | 148.15 MB/s |
由于 iopath 会把整个文件下载下来再进行访问,所以在文件大小不大且多次随即读写的情况下,优于 refile 和 smart-open,但当文件过大时,可能导致内存溢出。
MegFile 考虑到文件下载速度和随机读取性能,在文件小于 256 MB 时,不进入随即读取模式,而采用多块随即读的策略,在这样的情景下,性能对比如下表:
| 库 | 模式 | 耗时 | 文件大小 | 读取内容大小 | 读写速度 |
|---|---|---|---|---|---|
| smart-open | 'r'(随机读取) | 2.05 s ± 274 ms | 128 MB | 400 MB | 195.15 MB/s |
| iopath | 'r'(随机读取) | 555 ms ± 110 ms | 128 MB | 400 MB | 720.72 MB/s |
| MegFile | 'r'(随机读取) | 355 ms ± 97.1 ms | 128 MB | 400 MB | 1126.76 MB/s |
在 writer 的写入数据时,维护了最多 2 个数据块。默认采用多线程 multipart upload 的上传方式获得更高的速度。但是在写入大量小文件时,使用 multipart 上传文件,每个文件需要 create_multipart_upload / upload_part / complete_multipart_upload 三次 API 请求,会导致 QPS 过大,因此,当数据块不超过 2 块时,会使用 put_object 方法上传文件。
通过 reader / writer 的自适应多模式读写, 在 s3 协议上取得了目前已知 Python 竞品都要快的文件读写性能。
glob 是用于匹配符合指定模式的文件集合的一种语言,在操作系统终端和 Python 中都支持 glob 语法进行文件匹配,在 MegFile 中也支持基本的 glob 进行文件匹配。
相比标准库的 glob 模块,MegFile glob 额外支持了 zsh 中 {} 进行选择匹配的扩展语法,例如:s3://bucket/video.{mp4,avi}。在 s3 上不仅支持匹配同一个 bucket 上的路径,还能够对多个 bucket 上的文件进行匹配。
smart_glob('s3://{bucket1,bucket2}/key')
smart_glob('s3://bucket/[2-3]/**/?.mp4')
smart_glob('/folder/[123]/video{.avi,.mp4}')在最开始实现 s3 上的 glob 时,我们仿照将 Python 标准库的 glob 方法,将 os.listdir 改用 s3 API 实现,完成了我们的 glob 的第一个版本。但是实际使用过程中,我们发现这个 glob 的实现,在 s3 中存在大量目录,每个目录中文件较少的场景下,速度很慢;分析其原因,我们认为频繁地调用 listdir,也就是在每个目录上调用 list_object_v2 请求,会导致 QPS 过高,因此我们对 glob 进行了进一步改进。
新版的 glob 在 s3 上在根目录上调用 list_objects_v2 一次性得到所有包含匹配前缀的所有路径,再与模式串进行匹配。相比第一版中基于 listdir 逐层目录匹配的 glob,大大减少了请求次数,速度有了显著提升,在一些特殊的场景下,速度甚至可比第一版 glob 提升 3 个数量级。
通过上述功能,MegFile 提供了统一且完善的文件操作体验。通过使用 MegFile 访问文件,你能丝滑无感地在不同后端访问文件,让你能够更聚焦在自己项目的逻辑而不是「这个文件在哪个后端」的问题,同时还无需担心由此带来的性能问题。
MegFile 已在GitHub上开源,欢迎大家试用体验:
https://github.com/megvii-research/megfile既然我们已经从零到一完成了 App 的开发工作,那这次不妨来看看 FinClip 移动端工程师整理的如何编写属于我们的第一个 SDK 吧!大家也可以回顾下 iOS 开发 App 的教程。
finobird:如何在iOS系统开发出自己的 App?
App 的开发更偏向于用户层面,从 UI 展示到业务逻辑处理,全程处理用户的行为。而 SDK 面向的是开发者,开发更偏向于功能方面,注重功能的开发实现。在今天的文章中,我们一起来聊聊设计 SDK 的那些事。
SDK 全称 Software Development Kit,广义上的 SDK 是为特定的软件包、软件框架、硬件平台、操作系统等建立应用程序时所使用的开发工具的集合(在 iOS 项目中,SDK 也被称为库)。
在 iOS 开发或 Android 开发中,不可避免会需要使用第三方工具提升产品的开发效率,比如用于消息推送的极光,用于第三方支付与登录的支付宝,微信等等。但大多数商用产品都不会直接给出源码(可能只有为爱发电的开源项目才会无私提供源码),而我们在开发 App 时就需要将这些第三方 SDK 集成在我们的项目之中。
SDK 的全称是 Software Development Kit,翻译过来是软件开发工具包,这是一种被用来辅助开发某类软件而编写的特定软件包。
一款好用且设计充分的 SDK 必须要遵循以下 4 条基本原则,即:
- SDK 安全,稳定
- 统一的开发规范
- Library 小而精
- 不依赖第三方 SDK
- 安全,稳定:考虑到 SDK 是需要嵌入到 App 里面去的,所以 SDK 最重要的特性就是安全性,不会因为乱开放接口而导致 App 数据泄露;其次重要的是 SDK 的稳定性, SDK 的 Crash 如果没有被捕获进行处理,则会导致应用彻底崩溃(这样就会导致第三方接入的 App 体验性非常差),甚至会直接导致接入方的用户流失;
- 统一的开发规范:对于 SDK 开发规范来说,统一的命名规范很重要,最好的状态是“接入方看到接口命名就能知道是哪家厂商的 SDK”,换句话说就是 SDK 的命名规范统一,形成自己公司的品牌效应,此外也方便开发者进行接入使用。此外也需要具有自己的编码规范,你可以在网上找到大厂的规范模板,并通过借鉴整理出属于自己的规范,从而尽早统一代码风格;
- Library 小而精:小是指要避免造成接入方的App增加很大,不然会引起接入方的不满,甚至下架。精是指功能要专注,比如极光推送,就是专注推送相关的功能;
- 不依赖第三方 SDK:这个也很好理解,SDK 中如果又依赖其他第三方 SDK, 不仅会导致 SDK 的体积变大,也会影响接入方集成 SDK 的相关成本。
如同上文所说,在 iOS 开发中,我们将 SDK 称为“库”,我们是这样对其定义的:
- 一般是给应用提供通用服务的,非独立运行的程序集合;
- 一般都是编译过的,方便使用。
我们会根据库的调用方法分为“静态库”和“动态库”两种:
- 静态连接:一般是指在创建应用程序的时候,将库集成进去,这样做的好处就是应用程序包自身可以独立运行,而不好的地方就是包会略显臃肿,库不能共享(静态库经常以 .a 结尾);
- 动态连接:创建应用的时候只约定好与库之间的调用关系,而不彻底将库包集成进应用。这样在应用运行时,需要运行环境中提供库,并且连接装载。优劣与静态库相反,动态链接库需要库环境,但由于本身不集成库内容,会比较小,同时也为和其他应用共享库的使用提供了可能(常见的动态库是 Windows 下的 .dll,Linux 下的 .so,Mac 下的 .dylib/.tbd)。
特别注意:平时我们经常说的 Framework (in Apple) 是 Cocoa/Cocoa Touch 程序中使用的一种资源打包方式,可以将代码文件、头文件、资源文件、说明文档等集中在一起,方便开发者使用。也就是说我们的 Framework 其实是资源打包的方式,和静态库动态库的本质是没有什么关系。
如果说要找出静态库与动态库的区别,那可以从文件链接(每个源代码模块独立编译,然后按照需要将他们组装起来,这个组装模块的过程,就是链接)的角度进行解释:
- 静态库:链接时会被完整的复制到可执行文件中,所以如果两个程序都用了某个静态库,那么每个二进制可执行文件里面,都会含有这份静态库的代码;
- 动态库:链接时不复制,而是在程序启动后动态加载,然后再进行符号决议(符号绑定)。理论上动态库只存在一份就可以了。其他的程序都可以动态链接到这个动态库上面,从而节省内存(内存中只有一份动态库)。另外一个好处是,由于动态库并不绑定到可执行程序上,所以我们想升级这个动态库就很容易,windows和linux上面一般插件和模块机制都是这样实现的。
具体的优劣势可以看这张表:
| 库类型 | 优点 | 缺点 |
| 静态库 | 1. 目标程序没有外部依赖,直接就可以运行。2. 效率较动态库高。 | 1. 会使用目标程序的体积增大。 |
| 动态库 | 1. 不需要拷贝到目标程序中,不会影响目标程序的体积。2. 同一份库可以被多个程序使用(因为这个原因,动态库也被称作共享库)。3. 编译时才载入的特性,也可以让我们随时对库进行替换,而不需要重新编译代码。实现动态更新 | 1. 动态载入会带来一部分性能损失(可以忽略不计)2. 动态库也会使得程序依赖于外部环境。如果环境缺少动态库或者库的版本不正确,就会导致程序无法运行(Linux lib not found 错误)。 |
静态库可以简单理解为一堆目标文件(.o/.obj)的打包体(并非二进制文件),而动态库可以简单理解为 一个没有 main 函数的可执行文件。
有一个背景知识需要注意,iOS 官方规定不允许存在动态库,并且所有的 IPA 都需要经过 Apple 的私钥加密后才能用,即使你用了动态库也会因为签名错误而无法加载(越狱和非 App Store 除外)。于是这就把开发者自己开发动态库这件事变成为了天方夜谭。
iOS8 之前的 iOS 应用都是运行在沙盒当中的,不同程序之间不能共享代码,并且 iOS 又是单进程运行的(也就是某一时刻只有一个进程在运行),那么即使你写个共享库也无法共享给他人。
而动态下载代码又是被苹果官方明令禁止的,也就是说动态库的优势完全无法发挥,所以动态库也就没有存在的必要了。
但是这一切问题都随着 iOS8 发布之后的 App Extesion 特性, Swift 的诞生发生了奇妙的改变。
由于 iOS 主 App 需要和 Extension 共享代码,Swift 语言机制也需要动态库,于是苹果后来提出了 Embedded Framework,这种动态库允许 APP 和 App Extension 共享代码(动态库的生命被限定在一个APP进程内)。
更简单的解释:虽然提供了动态库,但这是被阉割的动态库。
尽管如此,这种动态库(Embedded Framework) 和系统的 UIKit.Framework 还是有很大区别的。传统的动态库是给多个进程使用的,而这里的动态库(Embedded Framework)是给单个进程里面多个可执行文件用的。
系统的 Framework 不再需要拷贝到目标程序中,我们自己做出来的动态库(Embedded Framework) 哪怕是动态的,最后也还是要拷贝到 App 中(App 和 Extension 的 Bundle 是共享的)。所以苹果没有直接把这种 Embedded Framework称作动态库而是叫 Embedded Framework。
上面提到的 Swift 也有原因,在 Swift 的项目中如果要在项目中使用外部代码,可选的方式只有两种,一种是把代码拷贝到工程中,另一种是用动态 Framework。使用静态库是不支持的。
这个问题的根本原因是, Swift 的运行库没有被包含在 iOS 系统中,反而会被打包进 App 中(这也是造成 Swift App 体积大的原因),静态库会导致最终的目标程序中包含重复的运行库。
第一步:创建 App 工程,命名为 RealDemo

第二步:关闭 RealDemo 工程,然后在 RealDemo 目录下创建 Framework 工程,命名为 RealSDK
第三步:设置 Framework 工程的 Build Settings
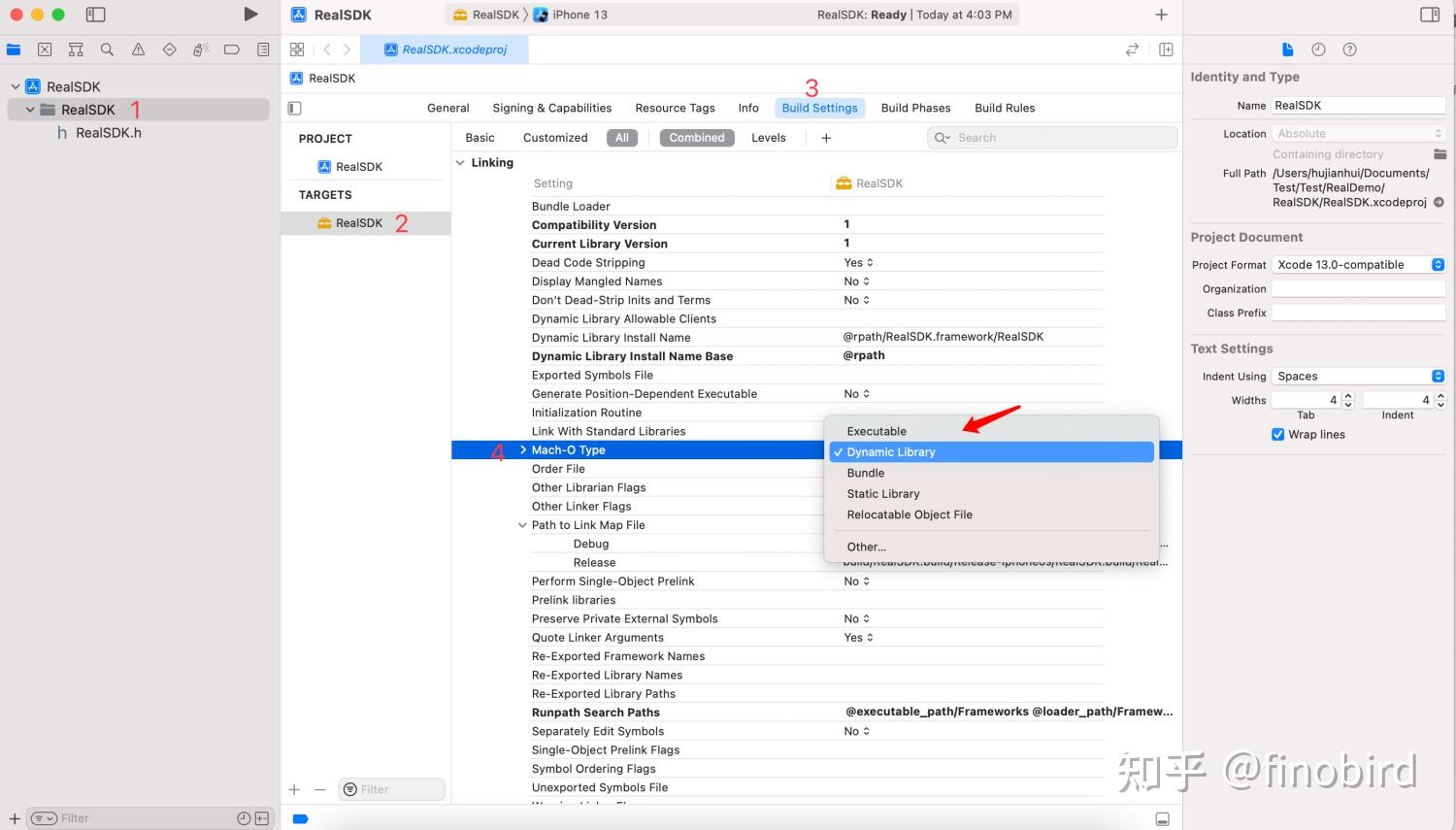
第四步:关闭RealSDK工程,创建 WorkSpace,命名为 RealDemo
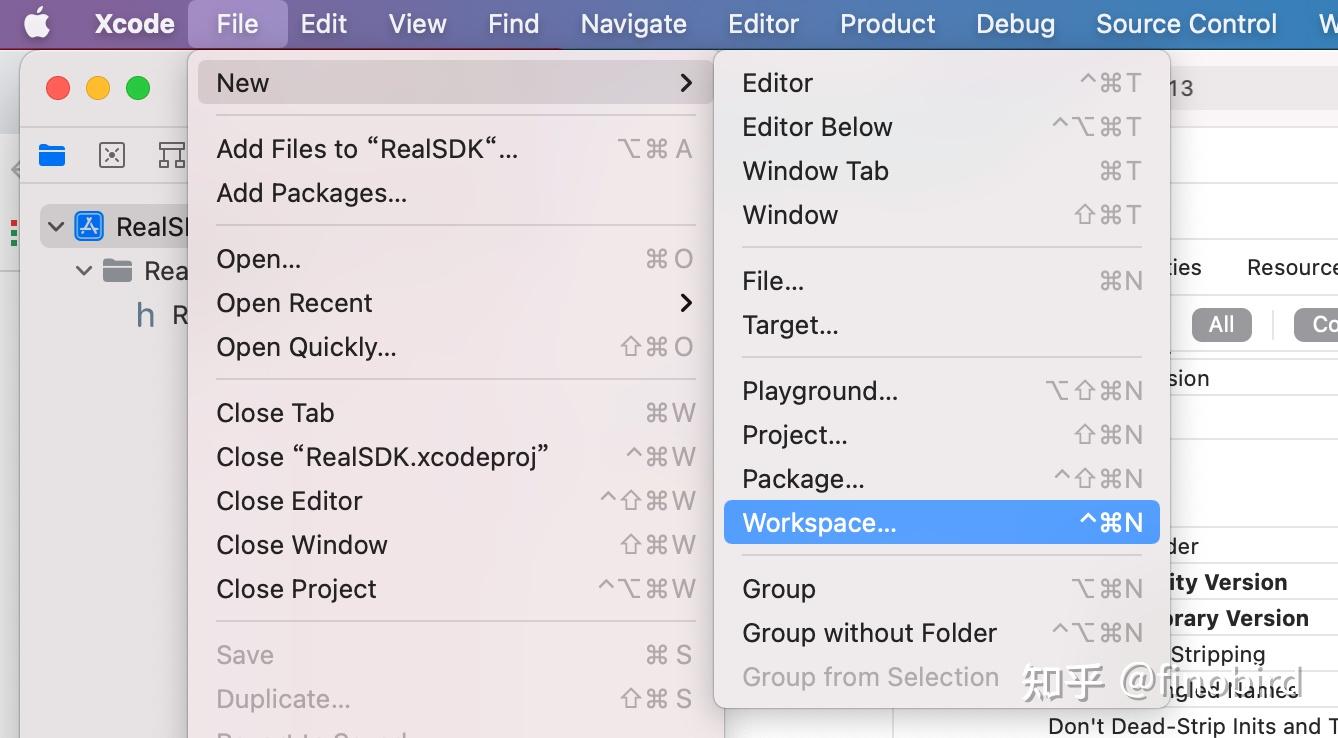
第五步:连接 Framework 工程和 App 工程
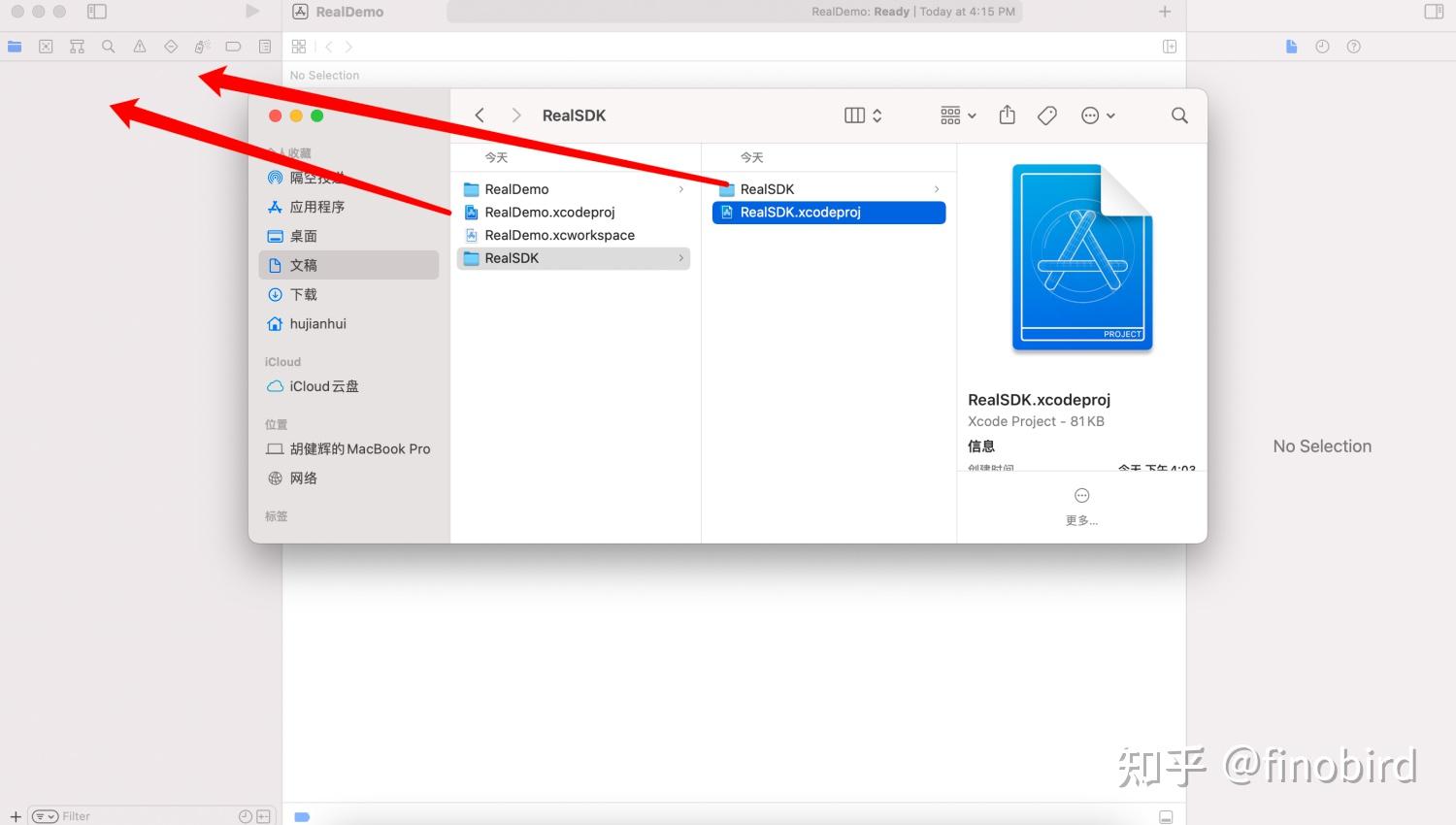
我们需要先打开 RealDemo.xcworkspace,打开后你会发现这里空空如也。
然后我们直接把需要连接的 Framework 工程(RealSDK.xcodeproj)和 App 工程(RealDemo.xcodeproj)拖进来就可以了!
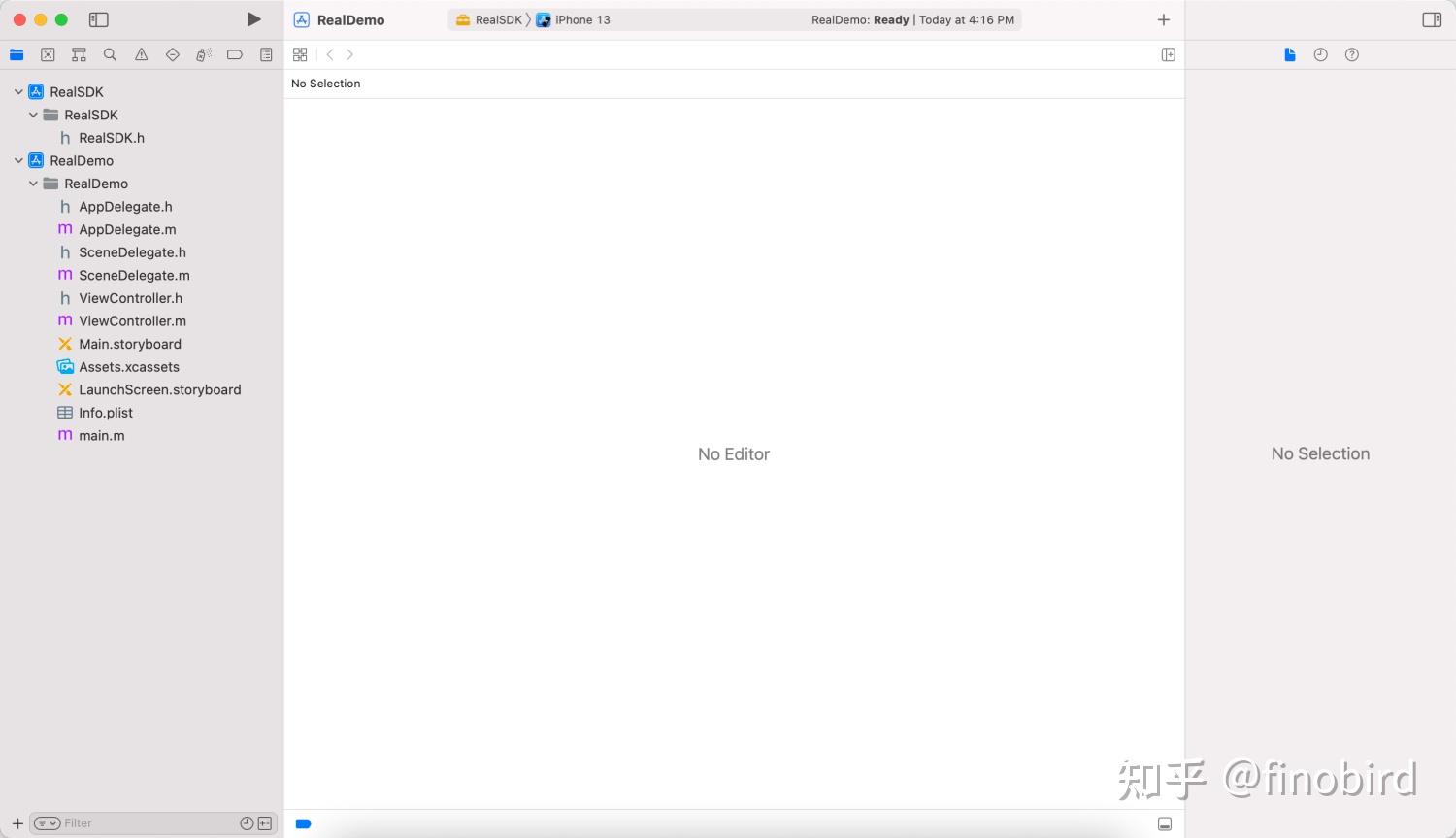
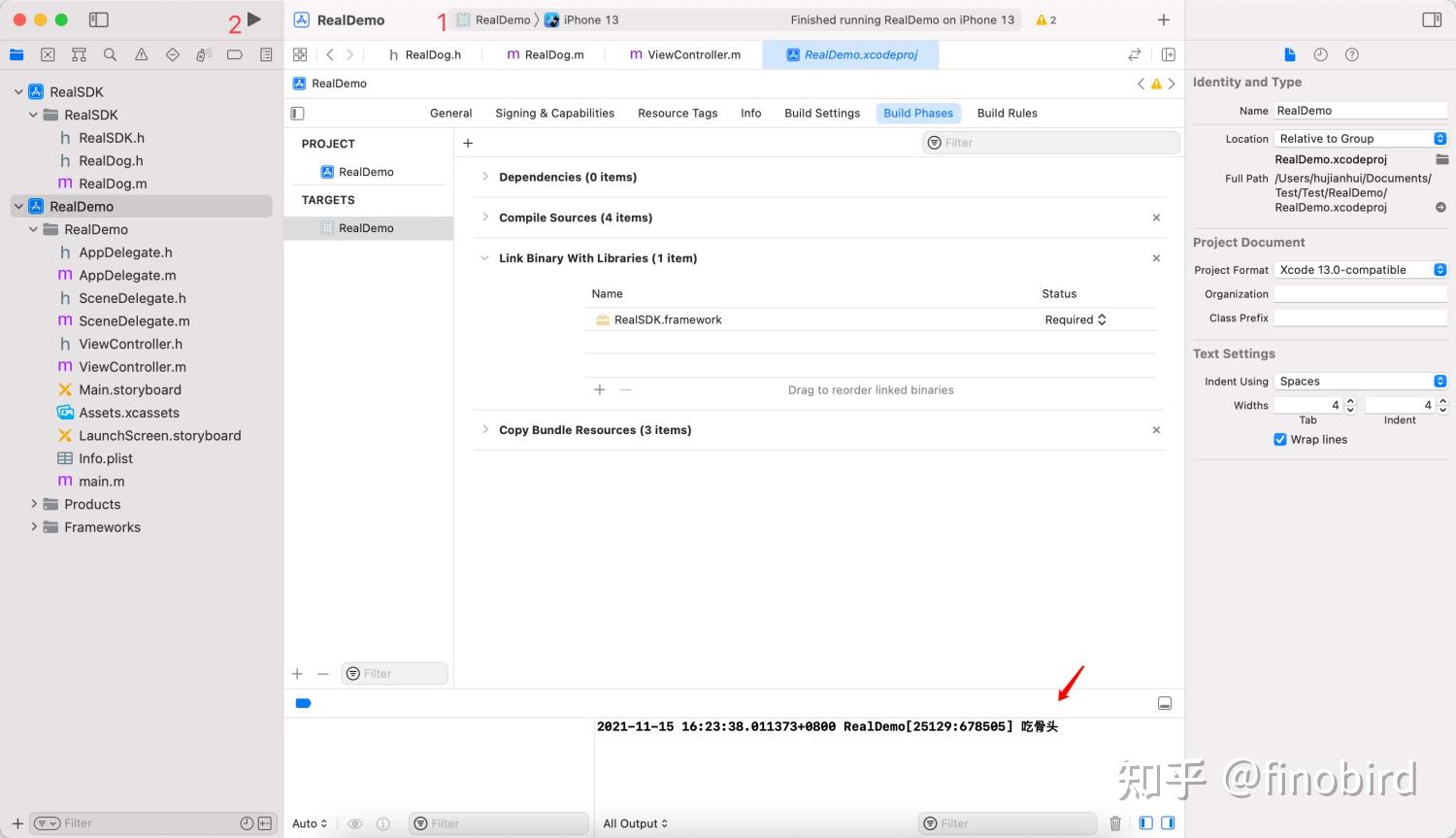
第六步:把 Framework 添加到 App 工程中
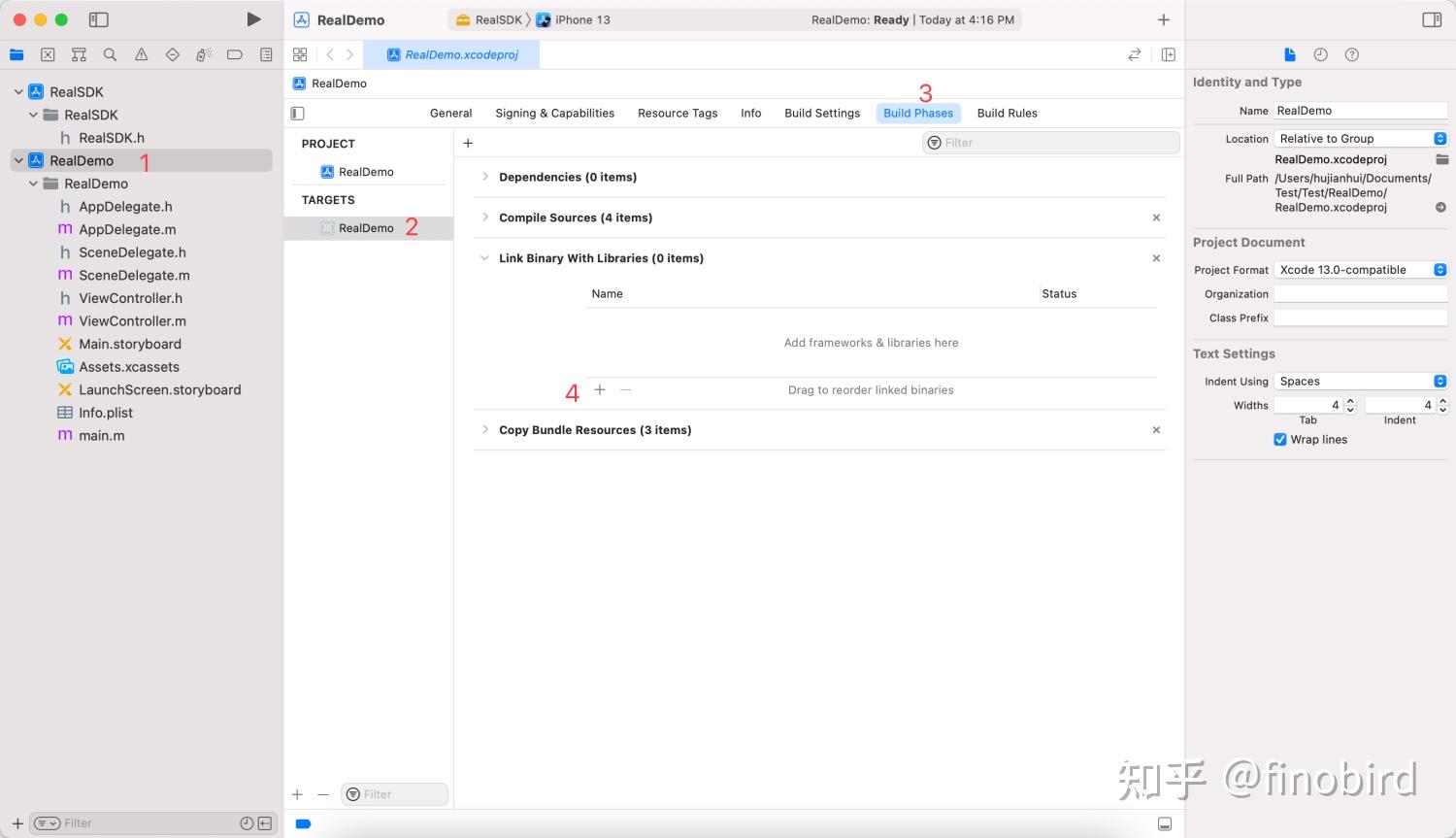
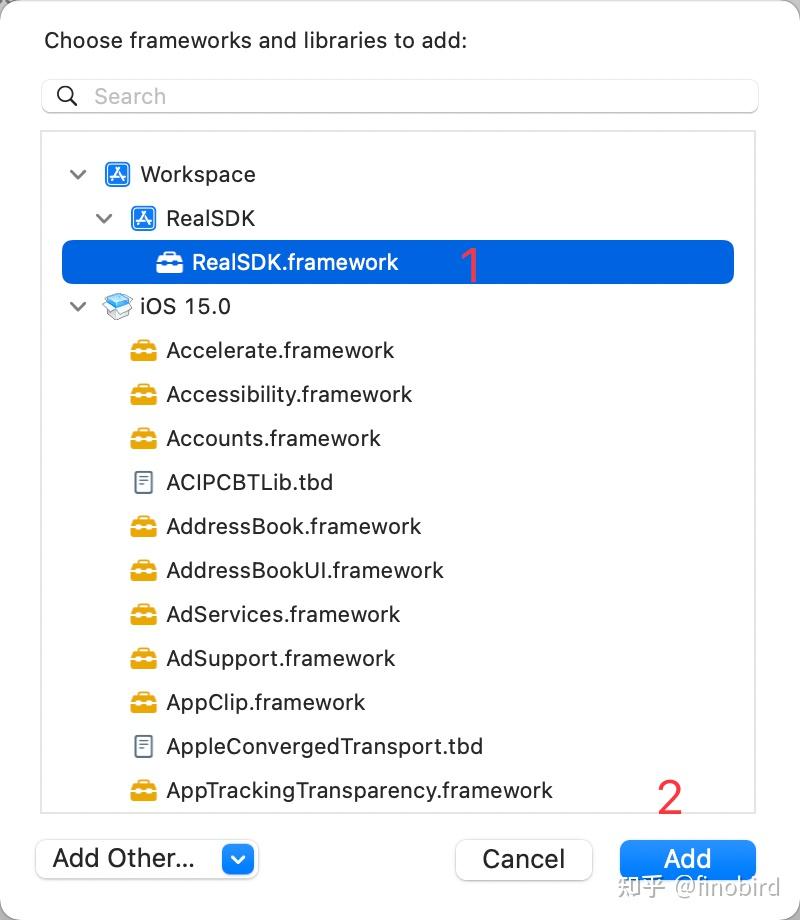
有过 SDK 开发经验的同学到这里应该已经看明白了,所谓实时联调说白了就是用 WorkSpace 把两个工程连接起来而已,跟 Pod 的原理有几分相似。
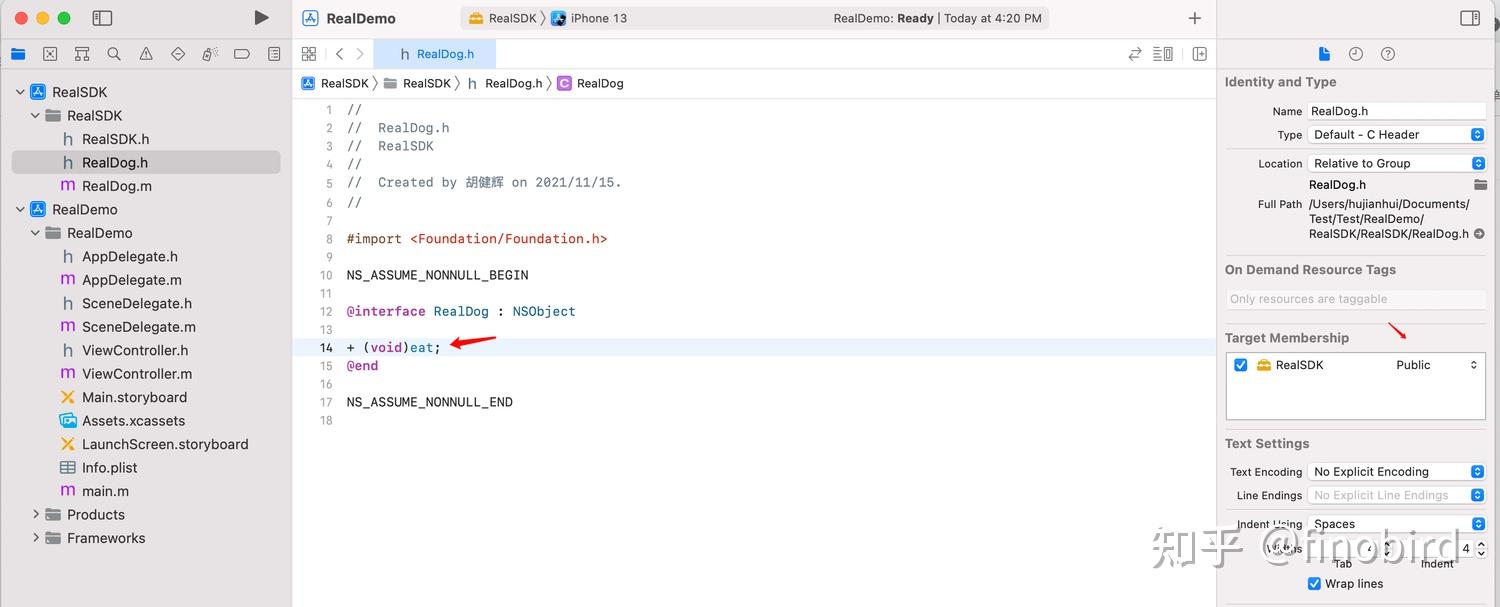
第七步:给 Framework 加点功能
我们需要增加一个 RealDog 类,定义一个 eat 方法,实现里面打印一句话“吃骨头”。然后修改 RealDog.h 的 Target Membership 为 Public,意思为公开头文件。
RealDog的实现如下:
@implementation RealDog
+ (void)eat {
NSLog(@"吃骨头");
}
@end第八步:在 App 的 ViewController 调用一下 SDK 的方法
#import "ViewController.h"
#import <RealSDK/RealDog.h>
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
[RealDog eat];
}
@end第九步:运行一下,可以发现App工程成功调用了SDK的方法
第一步:添加一个 Aggregate Target
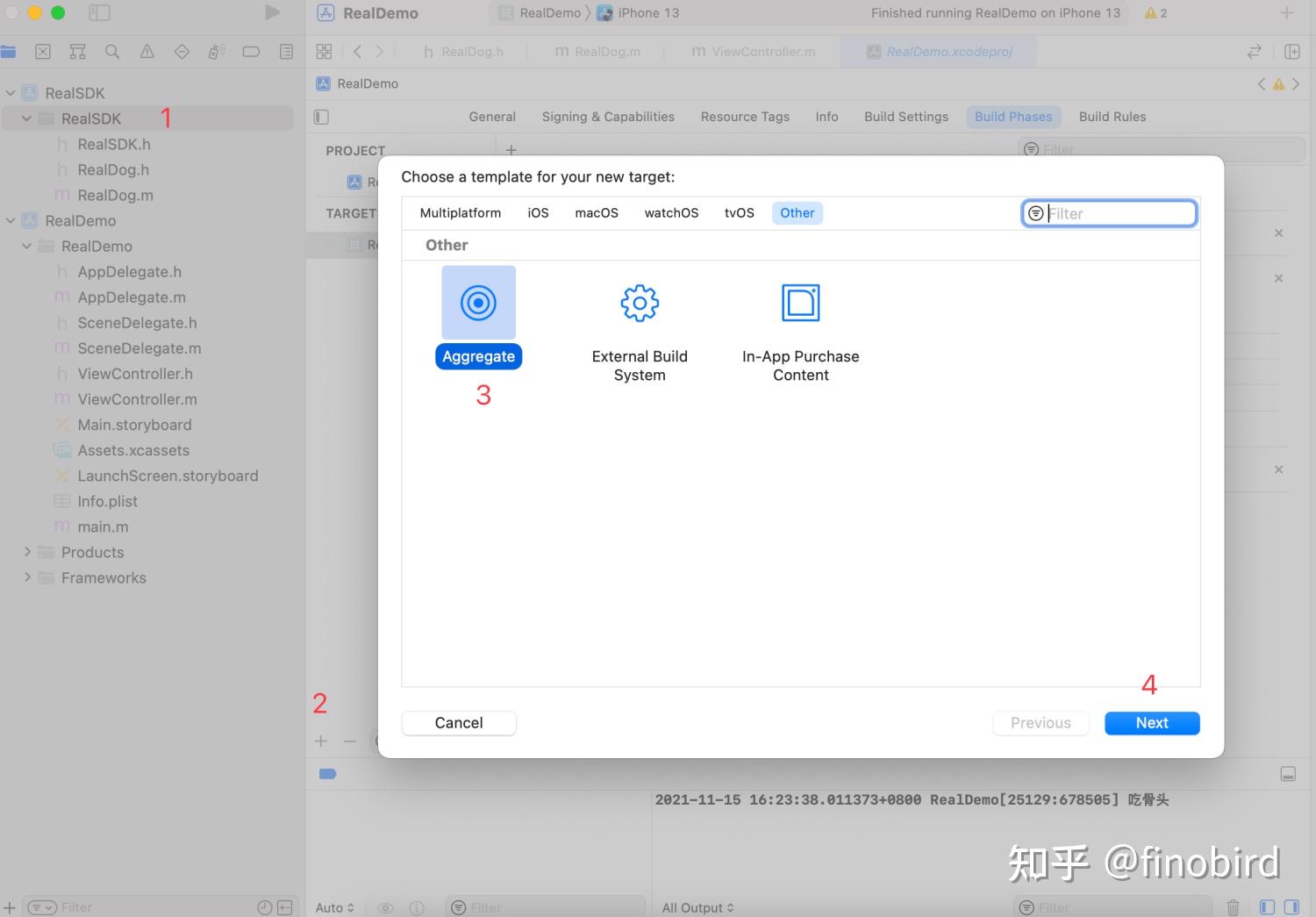
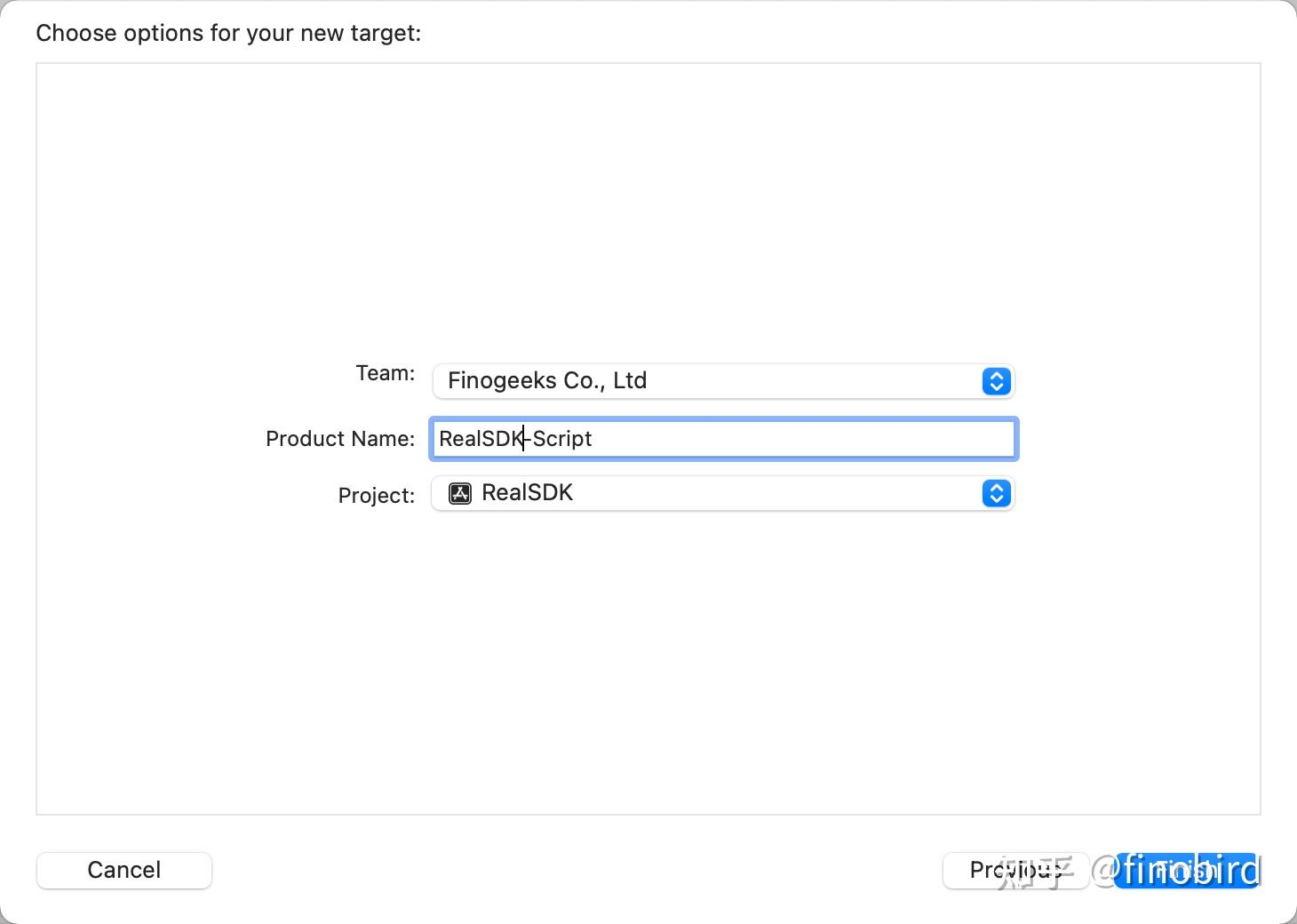
第二步:将 Aggregate Target 命名为“RealSDK-Script”
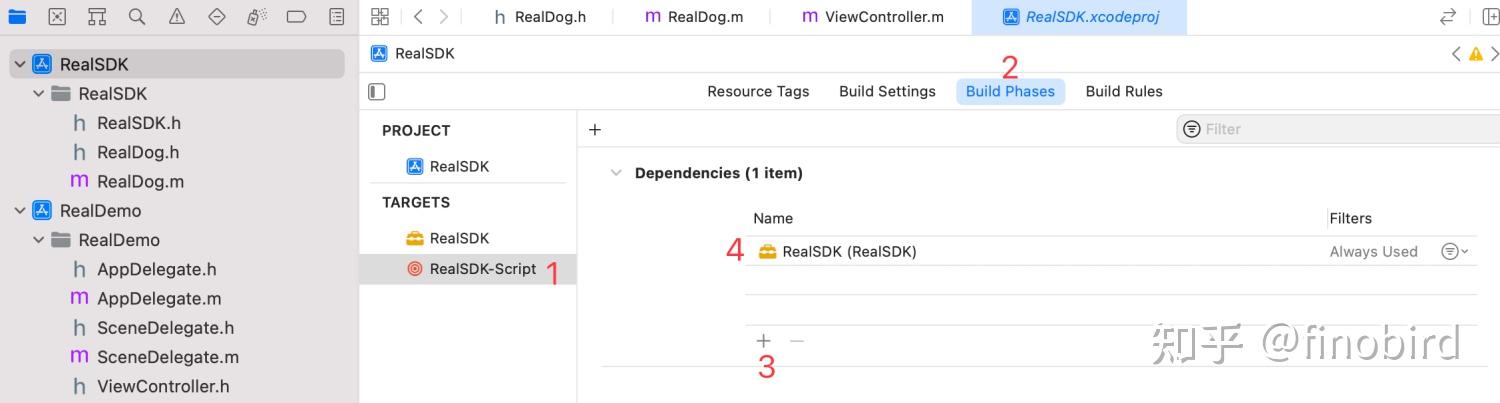
第三步:依赖 RealSDK
第四步:添加脚本
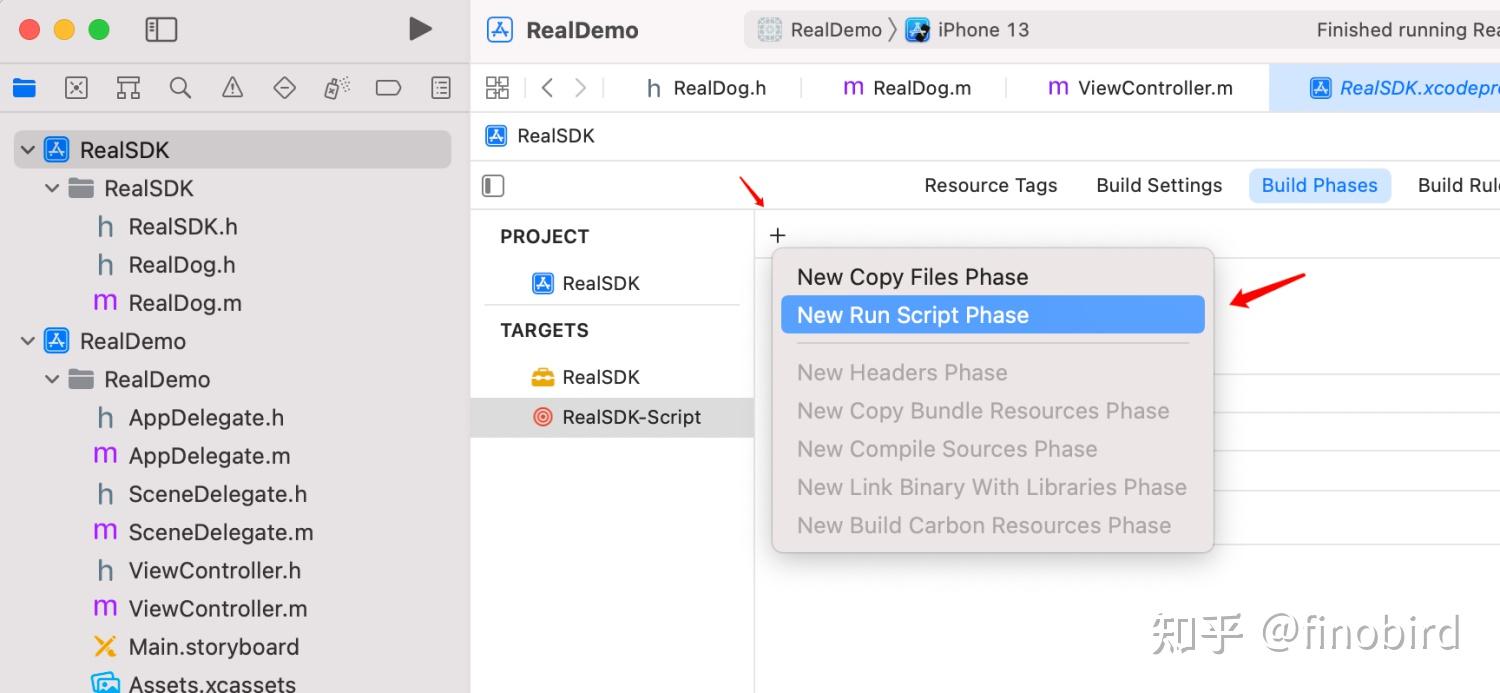
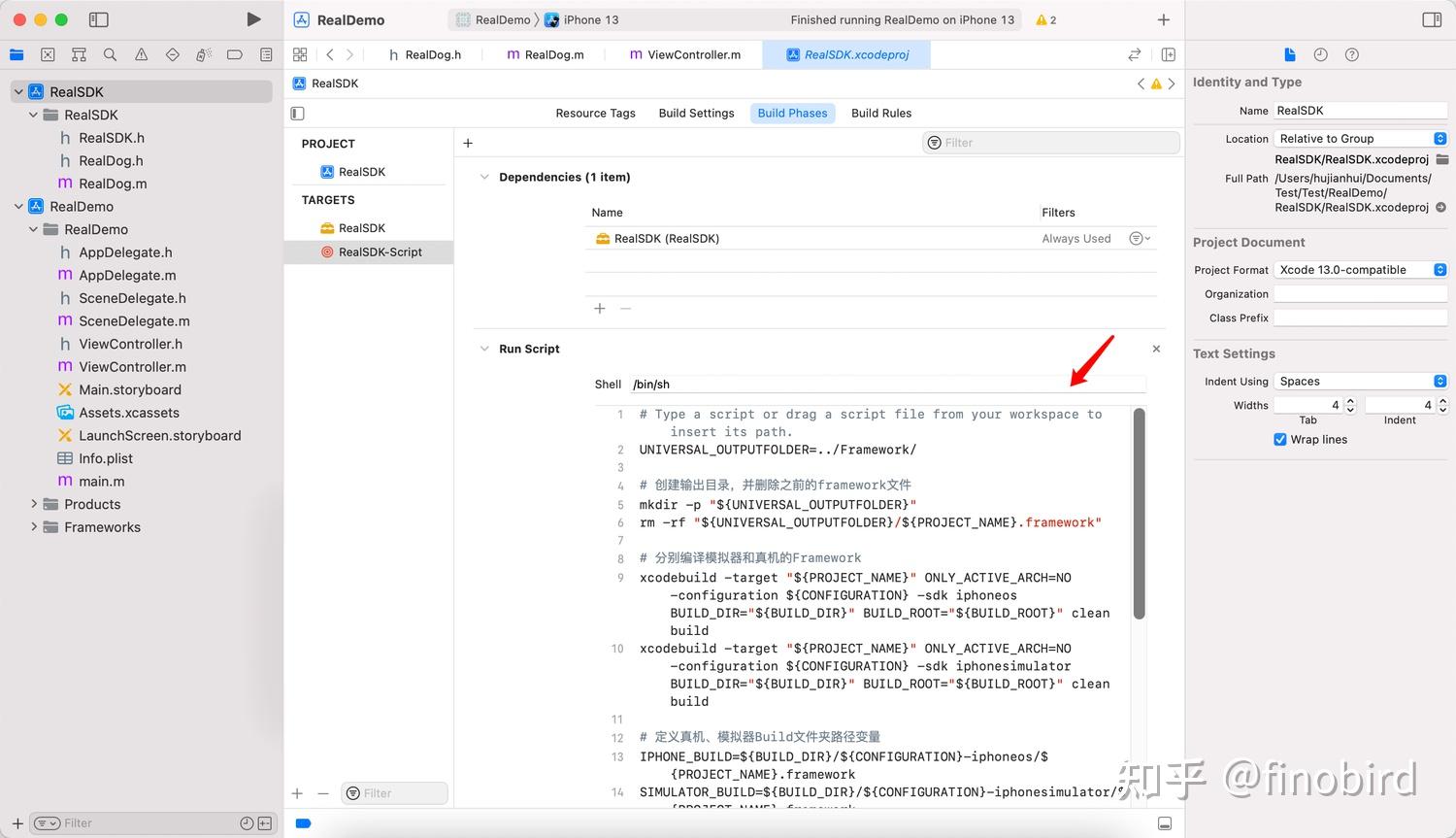
这个脚本是通用的,各位同学直接复制粘贴即可:
# Type a script or drag a script file from your workspace to insert its path.
UNIVERSAL_OUTPUTFOLDER=https://www.zhihu.com/topic/Framework/
# 创建输出目录,并删除之前的framework文件
mkdir -p "${UNIVERSAL_OUTPUTFOLDER}"
rm -rf "${UNIVERSAL_OUTPUTFOLDER}/${PROJECT_NAME}.framework"
# 分别编译模拟器和真机的Framework
xcodebuild -target "${PROJECT_NAME}" ONLY_ACTIVE_ARCH=NO -configuration ${CONFIGURATION} -sdk iphoneos BUILD_DIR="${BUILD_DIR}" BUILD_ROOT="${BUILD_ROOT}" clean build
xcodebuild -target "${PROJECT_NAME}" ONLY_ACTIVE_ARCH=NO -configuration ${CONFIGURATION} -sdk iphonesimulator BUILD_DIR="${BUILD_DIR}" BUILD_ROOT="${BUILD_ROOT}" clean build
# 定义真机、模拟器Build文件夹路径变量
IPHONE_BUILD=${BUILD_DIR}/${CONFIGURATION}-iphoneos/${PROJECT_NAME}.framework
SIMULATOR_BUILD=${BUILD_DIR}/${CONFIGURATION}-iphonesimulator/${PROJECT_NAME}.framework
# 拷贝framework到univer目录
cp -R "${IPHONE_BUILD}" "${UNIVERSAL_OUTPUTFOLDER}/"
#cp -R "${SIMULATOR_BUILD}" "${UNIVERSAL_OUTPUTFOLDER}/"
# 定义输出路径变量
OUTPUT_PATH=${UNIVERSAL_OUTPUTFOLDER}/${PROJECT_NAME}.framework
# 合并framework,输出最终的framework到build目录
lipo -create "${IPHONE_BUILD}/${PROJECT_NAME}" "${SIMULATOR_BUILD}/${PROJECT_NAME}" -output "${OUTPUT_PATH}/${PROJECT_NAME}"第五步:运行脚本

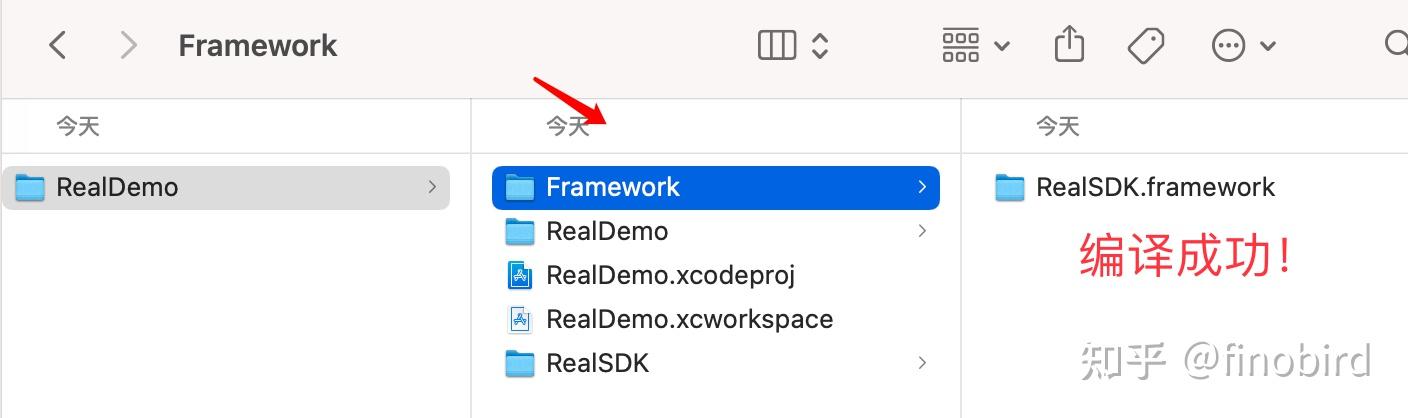
第六步:查看结果
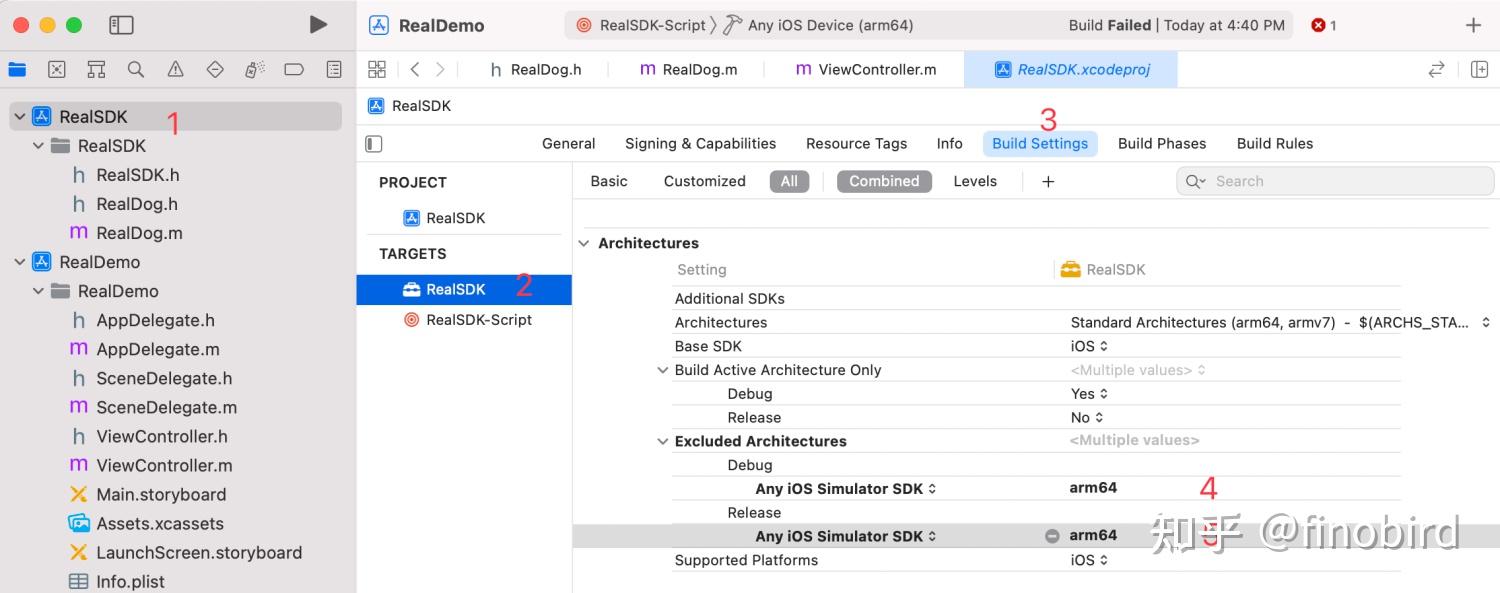
如果你的 Mac 是最新的 M1芯片,那么可能会出现以下报错:
fatal error: lipo: /Users/hujianhui/Library/Developer/Xcode/DerivedData/RealDemo-ckvcidkkuvgpadeiqrvgjdyikcdc/Build/Products/Debug-iphoneos/RealSDK.framework/RealSDK and /Users/hujianhui/Library/Developer/Xcode/DerivedData/RealDemo-ckvcidkkuvgpadeiqrvgjdyikcdc/Build/Products/Debug-iphonesimulator/RealSDK.framework/RealSDK have the same architectures (arm64) and can't be in the same fat output file你只需要去除 iOS 模拟器的 arm64 架构即可,方法如下:
1. Framework 中使用 Category
在 Framework 工程的 Build Setting 中添加 -ObjC。另外,使用我们 SDK 的 App 的 Build Setting 中也要添加 -ObjC。
2. Framework 支持 bitcode
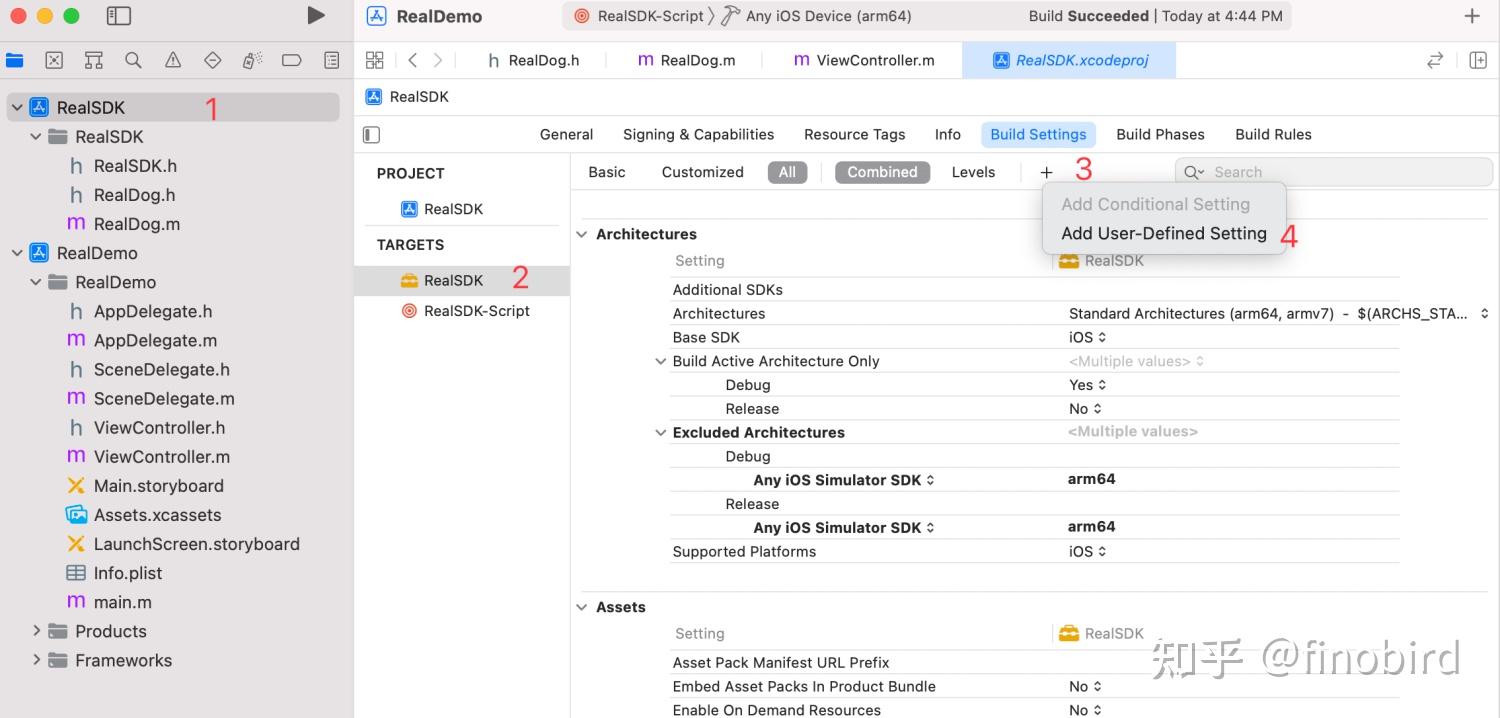

如果正确按照教程,那相信你已经成功的做出了属于自己的第一个 iOS SDK,本期教程依然基于 mac 电脑进行实现,如果你的电脑是 Windows 或者其他操作系统,还需要进行一些其他的灵活配置。
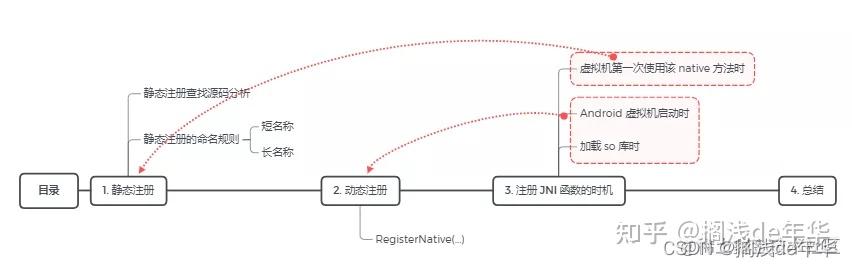
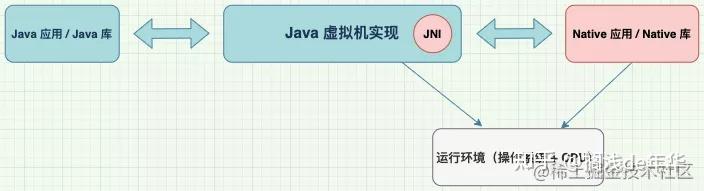
1. 什么是 JNI 函数注册:
当 Java 虚拟机调用 native 方法时,需要调用对应的 JNI 函数,而 JNI 函数注册讨论的就是如何确定 natvie 方法与 JNI 函数之间的映射关系。
2.JNI函数注册的方式:
1)静态注册
2)动态注册
3.JNI函数注册方式的优缺点:
1)静态注册:
静态注册的优点是简单,因为静态注册采用的是基于约定的命名规则,所以可以通过 javah 或 IDE 自动生成函数声明。缺点是修改 Java 类名或方法名时,需要同步修改 JNI 函数命名。
2)动态注册:
动态注册的优点是灵活,因为动态注册可以自由定义 Java 方法和 JNI 函数命名的映射,当 Java 类名或方法名时只需要修改映射关系即可。缺点是牺牲了静态注册基于约定带来的便捷性。
HelloWorld.java
package com.xurui.hellojni;
public class HelloWorld {
public native void sayHi();
}com_xurui_hellojni_HelloWorld.h
JNIEXPORT void JNICALL Java_com_xurui_hellojni_HelloWorld_sayHi
(JNIEnv *, jobject);2)命名规则
静态注册的命名规则分为「无重载」和「有重载」两种情况:无重载时采用「短名称」规则,有重载时采用「长名称」规则。
短名称规则(short name)
1、前缀 Java_;
2、类的全限定名(带下划线分隔符_);
3、方法名
长名称规则(long name)
4、在短名称后追加两个下划线(__)和参数描述符
提示: 使用javap命令可以生成符合命名约定的头文件。
2.动态注册
除了基于约定的静态注册外,还可以通过动态注册来确定 native 方法和 JNI 函数的映射关系。动态注册需要使用 RegisterNatives(...) 函数。
RegisterNatives(...) 函数:
一般会在JNI_Onload(...)函数中执行动态注册,例如:
android_media_MediaPlayer.cpp
jint JNI_OnLoad(JavaVM* vm, void* /* reserved */) {
...
if (register_android_media_MediaPlayer(env) < 0) {
ALOGE("ERROR: MediaPlayer native registration failed\n");
goto bail;
}
...
}
-> 2、调用 AndroidRuntime::registerNativeMethods
static int register_android_media_MediaPlayer(JNIEnv *env) {
return AndroidRuntime::registerNativeMethods(env,
"android/media/MediaPlayer", gMethods, NELEM(gMethods));
}
1、native 方法与 JNI 方法的映射关系
static const JNINativeMethod gMethods[] = {
{
"nativeSetDataSource",
"(Landroid/os/IBinder;Ljava/lang/String;[Ljava/lang/String;"
"[Ljava/lang/String;)V",
(void *)android_media_MediaPlayer_setDataSourceAndHeaders
},
{
"_setDataSource",
"(Ljava/io/FileDescriptor;JJ)V",
(void *)android_media_MediaPlayer_setDataSourceFD}
},
...
}以上代码中,gMethods数组定义了 native 方法与 JNI 方法的映射关系,而调用 AndroidRuntime::registerNativeMethods 函数最终会调用RegisterNatives(...)函数,依次绑定 gMethods 数组中的每个映射关系。
JNIHelp.cpp
-> 调用 AndroidRuntime::registerNativeMethods
-> 最终调用的是:JNIHelp.cpp
extern "C" int jniRegisterNativeMethods(C_JNIEnv* env, const char* className,
const JNINativeMethod* gMethods, int numMethods) {
JNIEnv* e = reinterpret_cast<JNIEnv*>(env);
scoped_local_ref<jclass> c(env, findClass(env, className));
3、关注点:调用 RegisterNatives
if ((*env)->RegisterNatives(e, c.get(), gMethods, numMethods) < 0) {
...
}
return 0;
}其中,JNINativeMethod 是定义在jni.h中的一个结构体
typedef struct {
const char* name; native 方法名
const char* signature; native 方法的方法描述符
void* fnPtr; JNI 函数指针
} JNINativeMethod;提示: 这里需要提醒下,很多资料都把 signature 说成是 JNI 这个知识下的概念,事实上它是 JVM 字节码中用于描述方法的字符串,是字节码中的概念。
注册 JNI 函数的时机主要分为三种,这三种场景都是比较常见的:
| 注册的时机 | 对应的注册方式 |
|---|---|
| 1、虚拟机第一次调用 native 方法时 | 静态注册 |
| 2、Android 虚拟机启动时 | 动态注册 |
| 3、加载 so 库时 | 动态注册 |
1、虚拟机第一次调用 native 方法时: 这种时机对应于静态注册,当虚拟机第一次调用该 native 方法时,会先搜索对应的 JNI 函数并注册。
2、Android 虚拟机启动时: 在 App 进程启动流程中,在创建虚拟机后会执行一次 JNI 函数注册。我们在很多 Framework 源码中可以看到 native 方法,但找不到调用 System.loadLibrary(...) 的地方,其实是因为在虚拟机启动时就已经注册完成了
AndroidRuntime.cpp
void AndroidRuntime::start(const char* className, const Vector<String8>& options, bool zygote) {
...
if (startReg(env) < 0) {
ALOGE("Unable to register all android natives\n");
}
...
}
start -> startReg:
int AndroidRuntime::startReg(JNIEnv* env) {
androidSetCreateThreadFunc((android_create_thread_fn) javaCreateThreadEtc);
env->PushLocalFrame(200);
if (register_jni_procs(gRegJNI, NELEM(gRegJNI), env) < 0) {
env->PopLocalFrame(NULL);
return -1;
}
env->PopLocalFrame(NULL);
return 0;
}
startReg->register_jni_procs:
static int register_jni_procs(const RegJNIRec array[], size_t count, JNIEnv* env) {
for (size_t i = 0; i < count; i++) {
执行 JNI 注册
if (array[i].mProc(env) < 0) {
return -1;
}
}
return 0;
}
static const RegJNIRec gRegJNI[] = {
REG_JNI(register_com_android_internal_os_RuntimeInit),
REG_JNI(register_com_android_internal_os_ZygoteInit_nativeZygoteInit),
REG_JNI(register_android_os_SystemClock),
REG_JNI(register_android_util_EventLog),
...
}
struct RegJNIRec {
int (*mProc)(JNIEnv*);
}可以看到,Android 虚拟机启动时,会调用startReg()。其中会遍历调用gRegJNI数组,这个数组是一系列注册 JNI 函数的函数指针。
3、加载 so 库时: 在加载 so 库时,会回调JNI_Onload(..),因此这是注册 JNI 函数的好时候,例如上面提到的MediaPlayer也是在这个时候注册 JNI 函数。
1、应理解注册 JNI 函数的两种方式:静态注册 & 动态注册;
2、应理解静态注册的函数命名约定、动态注册调用的RegisterNatives(...);
3、应知晓注册 JNI 函数的三个时机。
参考资料
- 《Android JNI 原理分析》 —— Gityuan 著
- 《JNI 编程指南》
来源:带你梳理 JNI 函数注册的方式和时机 - 掘金
作者:彭丑丑
本人毕业至今基本都是在做SDK相关的开发,但做了这么长时间貌似也没正经复盘一次。
然而最近,我做了一些思考:
- 什么样的SDK才能称之为一个好的SDK。
- 怎么才能做出一个好的SDK。
- 怎么才能做好一个项目。
这里和大家分享一下,也希望听到大家的看法。
下面是我的粗浅看法:
- 接口简单易用:用户可以快速方便的接入,在确保提供相应能力的前提下,对外暴露的接口越少越简单越好。接口越多,用户接入的复杂性就越高,出bug的概率就越大。
- 接入的第三方库要做成插件化:一个SDK想要获取某些能力不可避免的要接入一些三方库。这里一定要做好隔离,实现同样的功能,可以灵活替换其他同类型的三方库。功能侧做好mock,当发生某一问题时(比如CPU占用率高、难以排查的内存泄漏等),可以灵活去掉某个三方库,缩小复现路径,方便定位问题。
- 完备的日志:关键函数调用一定要有log,可以在调试某个不容易复现的问题时打印完整的调用路径,方便定位问题,其实最好能有一个全链路追踪方案。这种方案也是我一直想要做的,但苦于到现在还没有找到合适的实现方法。
- 参数可配置:很多参数不要写死,最好做成可配置的。
- 要有监控手段:比如内存、CPU占用率、帧率等的监控。保证质量第一,质量问题要量化,确定好什么指标才算是高质量SDK。
- 线上出问题后可定位:这一般取决于SDK的log覆盖程度,以及开发人员的调试能力和经验。
其实这和开发一个好的项目类似,下面是我一些粗浅的想法:
- 整个项目代码风格统一:在项目启动前确定代码规范,C++的话一般都是参考的Google的编码规范。项目的编译环境、设计风格也要统一,比如消息传递方式、模块如何调用方通知错误、软件如何向用户通知错误、如何组织数据结构、模块间通信机制等。
- 想清楚:不用着急动手,写代码之前一定要想清楚。开发一个SDK之前要设计好整个架构,这可能会设计出多种架构,最好都能给出架构图,然后说明每个架构的优缺点。从中选择最合适的架构,想清楚自己的取舍,为什么选择了这个,而非其他。
- 文档先行:这里不要求文档格式,先制定方案,核心诉求是想清楚之后再开发。重要核心功能最好拉上组内核心成员review,尽可能对方案做进一步优化。
- 方便扩展:这其实还是涉及到SDK的架构问题,我见到过很多扩展性非常差的SDK,迭代需求非常困难,牵一发而动全身。想要做好扩展性,我想更多的还是要知道SDK的发展方向,只有预测到将来会有什么需求才能更好的设计架构。当然,也没必要过度设计,架构都是一点点演进的,没有一步到位的架构。其实只要合理定义好模块,抽象好接口,SDK的扩展性还是大体可以保证的。
- 接口设计:做好接口的抽象与设计,让用户没有错误调用的机会。比如你的参数类型是enum class,用户想传错参数都不可能,编译就会报错。
- 模块划分清晰:模块边界要清晰,尽量减少模块之间的耦合度,确定好每个模块的输入和输出,做好团队协作与沟通,每个模块划分责任人,确定时间点。
- 测试先行:这是基本的编程原则啦,但貌似真正做到的也没几个,我在这块做的也不好...但还是要说一说,写代码之前要提前想好测试方案,不要一口气写完一大块代码,要一边写代码一遍测试,真正出现问题时也更好定位。
- 做好质量的监控与保障:
- 要有监控的手段,比如音视频SDK中一些常见的指标:
- CPU占用
- GPU占用
- 内部状态
- 内存
- 帧率
- 型号
- 错误和崩溃信息
- 画面评估:
- 声音是否卡顿
- 音画是否同步
- 是否有回声
- 做好自动化测试,测试的代码覆盖率要超过90%
- 跨平台:SDK最好做成跨平台的,拿我常做的移动端SDK来说,一般要求移动端SDK要支持双端,即Android和iOS。所以一般都会使用双端都支持的Native语言开发,即C/C++。
- 为什么不使用平台相关的语言,而使用Native开发?
- 因为把所有业务逻辑都沉到底层,用一套语言实现,这样在后期需求迭代和维护时可以只使用一份人力,如果使用双端上层Android和OC语言开发,同一套需求需要使用双倍人力,而且双端效果可能还不一致,排期也可能不一致,bug数也可能不一致。可能会影响整个SDK的交付进度。
- 这里可能大家会有些问题,比如某些功能只能使用上层语言开发,比如Android的Camera和MediaCodec,iOS的AVCaptureSession和VideoToolBox等,这怎么办?
- 这里要按功能做好抽象,拿录制来说,只需要提供开启录制、停止录制的接口即可,内部谁管你怎么实现呢。可以设计成同一个头文件,然后把平台差异化隐藏在实现中,使用条件编译的方式选择编译某个平台下的源文件。
- 三方库接入:要确保做好封装,做到模块化、可复用、可插拔。比如setBeautify、setFilter、setSticker等。
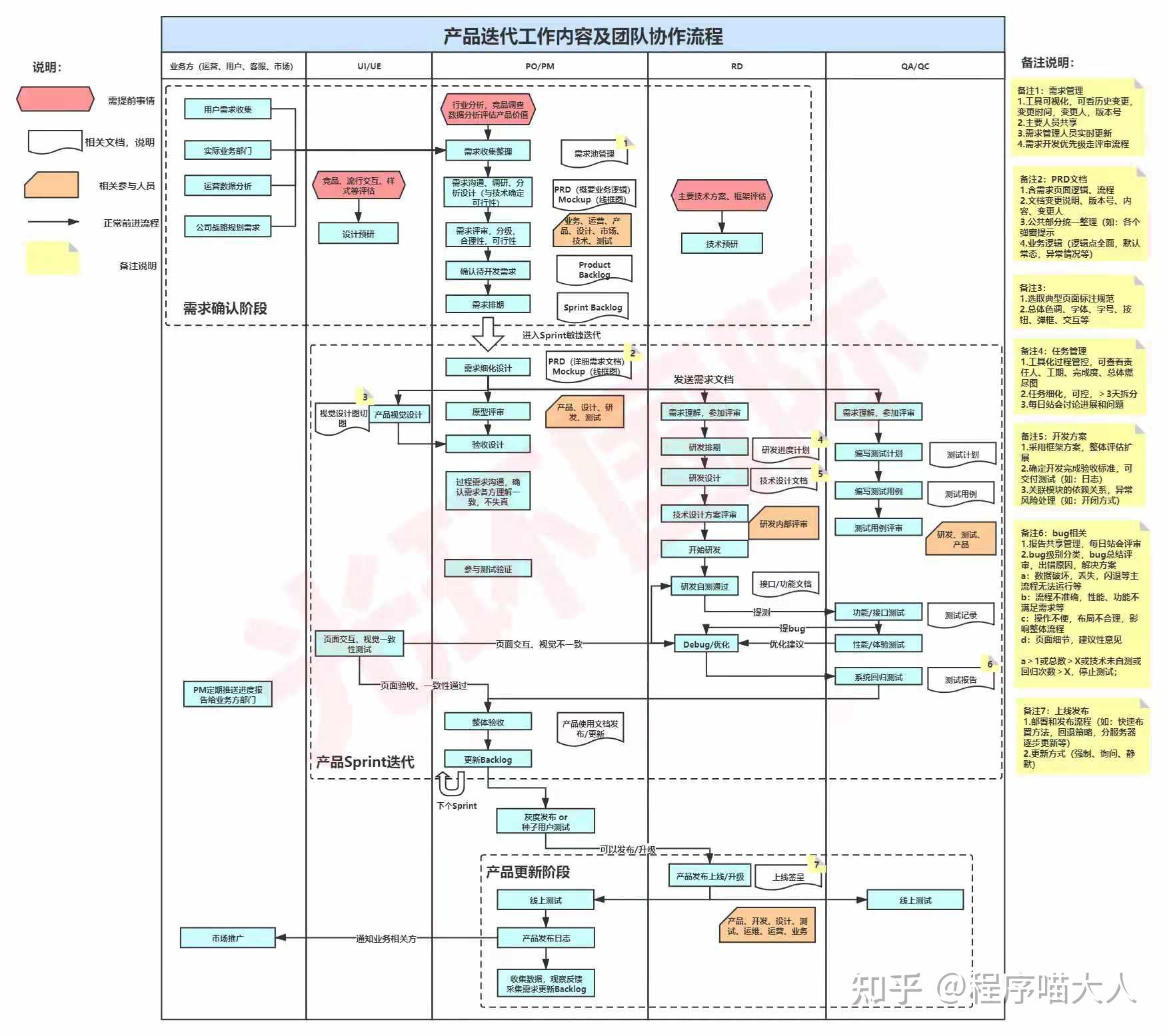
我认为做好一个项目的前提是人,要有合适的人。其次还是要规范好流程,关于开发流程方面的东西,我对此还知之甚少,贴一个群友分享的产品迭代流程图吧:
然后还有一位前辈给我发的开源项目邮件里说了一些他的看法,我感觉非常不错,这里也贴出来给大家看看:
1.希望有完备而用心的UT,追求100%逻辑覆盖率,UT维护良好,短小易读
2.子系统解耦良好,各模块相对独立,以标准化IO接口,通过项目基础库进行通讯,能独立更新迭代,独立进行测试
3.不需要过多的smoke test
4.子系统通讯和管理所经由的基础库希望由技术过硬的大佬写,希望跨平台,而且可读性高
5.数据链路有类似kernel的各种数据统计,数据统计不应耦合于业务,而是有数据统计子系统,高度解耦的方式
6.使用好的log,多线程库,数据解析库,通讯库,而不是自己写
7.迅捷的编译,提交任何代码都需要门禁,快速的跑全量UT与smoke
8.每日daily自动化跑全量UT与smoke,weekly性能测试;自动化测试跑出来的bug可以自动建立并根据模块自动分派给个人
9.希望使用比较新一点的技术栈
什么样的流程才更合理?做些什么能够更好的保证工程质量?不知道大家对此有什么想法?希望能向大家学习。

SDK,全称:software development kit, 软件开发工具包。

软件开发工具包一般都是一些软件工程师为特定的软件包、软件框架、硬件平台、操作系统等建立应用软件时的开发工具的集合。
软件开发工具广义上指辅助开发某一类软件的相关文档、范例和工具的集合。
软件开发工具包是一些被软件工程师用于为特定的软件包、软件框架、硬件平台、操作系统等创建应用软件的开发工具的集合,一般而言SDK即开发Windows平台下的应用程序所使用的SDK。它可以简单的为某个程序设计语言提供应用程序接口API的一些文件,但也可能包括能与某种嵌入式系统通讯的复杂的硬件。一般的工具包括用于调试和其他用途的实用工具。SDK还经常包括示例代码、支持性的技术注解或者其他的为基本参考资料澄清疑点的支持文档。
客户端SDK是为第三方开发者提供的软件开发工具包,包括SDK接口、接入文档、以及demo等。
可以在任何第三方应用中集成,使用方便。
sdk和api的区别有以下几点:
1、组成不同:
sdk软件开发工具包括广义上指辅助开发某一类软件的相关文档、范例和工具的集合。API(应用程序接口)是一些预先定义的函数,或指软件系统不同组成部分衔接的约定。
2、用途不同:
api目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。软件开发工具包一般都是一些软件工程师为特定的软件包、软件框架、硬件平台、操作系统等建立应用软件时的开发工具。
3、内容不同:
为了使用API函数,就要有跟API所对应的 .h和 .lib文件,而SDK正是提供了一整套开发Windows应用程序所需的相关文件、范例和工具的“工具包”。SDK包含了使用API的必需资料,所以也常把仅使用API来编写Windows应用程序的开发方式叫作“SDK编程”。

客户端SDK测试,就是对提供给开发者工具包里面的内容进行测试,因此测试的主要内容有:
1) SDK接口和文档
SDK接口是测试的主要对象,也是核心的内容。
2)SDK日志打印
对开发者来说,SDK接口里面的具体实现是透明的,当上层调用时遇到问题,可以依赖SDK打印的日志来定位分析。所以SDK日志是否完备,有助于问题的顺利解决,对应用开发者、测试人员、SDK提供方来说都很重要。
3) 程序示例:demo
demo是SDK提供方用来展示如何调用接口实现具体的功能,也可以作为开发者直观感受SDK接入的效果
根据需求和开发平台不同,会有以下常见的测试类型:
1、功能的测试
主要是场景覆盖和接口参数覆盖。主要测试各种参数下组合下的返回值。
考虑数据缓存和存储
考虑是否有回调
考虑对请求成功、或失败的处理结果与预期一致
2、兼容性的测试
根据产品需求是市场排行,确保兼容选取的设备机型、版本、分辨率等,并兼容其他软件
考虑模拟器的支持
覆盖多平台的,还要考虑多端消息数据包互通
3、性能方面的测试
满足特定的性能指标(CPU、内存、耗电量、流量等)
特定场景性能:比如登录需要同步大量的数据包和离线消息,需要考虑对数据包的解析和本地储存的性能
4、稳定性方面的测试
业务场景在一定压力下,持续运行一段时间,接口功能和设备资源占有无异常。
5、弱网环境测试
对弱网,及其他不同类型网络和不同网络环境,SDK接口均应有较好的处理
对比依据是新老版本、竞品效果
6、安全性方面的测试
隐私数据的保护、访问权限控制、用户服务鉴权等
1、了解业务流程,确定开放给开发者都有哪些接口
2、了解SDK用到的所有协议,每个协议中字段的意义和作用以及server端处理逻辑
3、接口要校验输入参数各种输入情况是否能正确处理,返回值的正确性,是否有数据缓存到本地,检查是否有回调,如果有对于请求成功、请求失败(包括无网络、服务器返回非200错误代码)是否都有调用
4、测试中对每个请求都应该抓包测试,查看请求的字段、参数值、返回值是否正确
5、对于协议中必传字段,SDK中是否校验为空的情况
6、查看是否存在多发、少发请求的情况
7、对于异步请求的结果在其他地方(A类中)会用到的情况,检查是否存在网络较慢情况下,未完成请求数据为空时A类就用到数据
尽管我爸是跨国总裁我妈是世界选美冠军,我五岁掌握四国语言六岁开始学芭蕾钢琴十岁出国比赛全球冠军十五岁考入剑桥十八岁开始一边读博一边帮我爸管理公司……
然而没办法。
我樊美绪注定爱上男主,一路作死,阻挠男女主感情,被男主搞得家破人亡,还被黑帮轮流侮辱最后跳楼自杀。
有那么几个小时,作为一个卷王,我不想努力了。
一
「今天交不上房租,就从这里滚出去!」
我戴着墨镜跷着二郎腿坐在这间小房子的破旧的沙发上,我的保镖队长正威吓着这家租客。
中年夫妇赖在地上做出了要钱没有要命一条的架势,屋子里走出来了一个穿着格子裙的齐刘海女生。
她圆圆的眼睛含着晶莹的泪水,走过来蹲在我的脚下,啪嗒一声眼泪掉在了我的鞋尖上。
「姐姐,我们的房租对您来说不过是一双鞋一件衣服,您为什么一定要把我们逼上死路呢?」
我摘下墨镜打量着这个女生。
很难想象,面前这个散发着土气看起来人畜无害的人会抢走我的未婚夫还霸占我的家产。
回忆起她把我卖给黑帮老大的画面,我动了动腿甩开了楚楚可怜的田甜。
「你们死不死和我没关系。我只知道你们半年没交房租了,不交租就要,搬出去。」
田甜捂着胸口瘫在地上,似乎被我踹得不轻。
我勾勾手指,身后的保安马上从怀里掏出来一块鹿皮擦了擦我的小皮鞋。
田甜的妈妈冲上来护住了田甜,声嘶力竭道,「欺负我的女儿就从我的尸体上迈过去!」
田甜声泪俱下,「有钱有势就可以把别人的尊严踩在脚下了么!」
我挑挑眉,对这家人的厚脸皮有些不可思议。
但我不准备废话,摆了摆手。
保镖队长马上心领神会,「明白!小姐!」
几个保镖马上掏出麻袋开始给家里的东西打包,准备全部丢出去。
二
「住手!」
低沉的嗓音微微含着怒意,众人纷纷往门口看去。
路名穿着深灰色的西装站在门口,此刻正皱着眉看向屋内。
我顺着路名的目光望去,正扑在柜子上负隅顽抗的田甜泪流满面却一脸倔强。
原来从这个时候他就对这个白莲花一见钟情了。
我笑着起身拉住了路名的手,「宝贝,你怎么来了~」
路名这才回过神,恢复了宠溺神态,「叔叔说你心情不好要出来捡钱,我就知道你肯定是来收租了。」
从前怎么没发现他宠溺的表情如此敷衍和虚伪呢?
但我仍然装作和平常一样,撒着娇说,「哥哥总能猜到我的心思!」
我眼角的余光瞥着田甜,她的表情楚楚可怜,但眼里却写满了嫉妒和渴望。
我故意转移话茬,跺着脚噘嘴道,「哥哥你看她们都欠我半年的房租了~」
路名眼神就没有离开过田甜,他安抚我道,「也没几个钱,哥哥这就带你去吃大餐!买包包!好不好……」
「至于房租,美绪,做人得大气一点,他们也不容易的,你就再宽限他们一个月,好吗?」
路名语气柔情似水,却把我架上了道德的高地。
为了配合路名英雄救美成功,我对他的提议表现出了极大的兴趣。
我重新戴上了墨镜,「好吧那就再宽限你们一个月。」
想起来什么我转身走回屋内,蹲在了田甜的身边,「还有我这双鞋,高定,十几万,你的弱碱性体液,差点腐蚀了它的皮面。」
田甜的眼里迸发出了恨意。
「美绪……」路名对我的嚣张跋扈和奢靡作风表现出了极大的不认同,忍不住叫了我一声。
看着被我刺激到不行的田甜和不满的路名,我得意地拍拍手,反正这人设是改不了了,不如恶毒到底。
三
「樊总~能不能不和路名结婚?」
在怒刷路名几十万后我拖着长长的尾音冲进了我爸的办公室,身后跟着拎着大包小包的一排保镖。
想起路名心疼又不得不装大方地打肿脸充胖子模样,我就想笑。
我爸推了推他的老花镜,「你不是哭着闹着非他不嫁?」
我转了转眼珠,「我喜欢上了别人。」
「而且路家公司那么破,很穷诶~」我又嘀咕了一句。
我爸头都没抬,「胡闹!」而后他又打起了亲情牌,「虽然路家没家底,但是路名是个很有才华很有担当的孩子,对你也是实打实的好。」
「爸爸身体一年不如一年,你又接不了咱们家这么大的产业,找个上门女婿,不是很好么。」
我想起梦里爸爸在我订婚没几年就确诊了恶性肿瘤晚期,我眼睛一酸。
「我们樊家的产业!当然是我这个唯一的女儿来接手!」
我爸终于放下了手里的文件,语重心长地看着我,「你妈走得早,爸爸奋斗一辈子,就是为了让你像小公主一样无忧无虑,不为生活操心。」
可你这是养虎为患啊爸爸,不得已我转移了思路。
「假如我找了一个比路名条件更好的未婚夫您是不是就可以和路家取消婚约了?」
我爸仔细打量了我几眼,似乎在判断我是不是在和往常一样胡闹。
「可以。」
「爸爸说了,你的事情,你都可以自己做主。」
我眼睛又一酸,就是这么好的爸爸,被白莲花制造的负面新闻和社会舆论压垮,让本就垮了的身体加速恶化,我身上的钱又全被路名转移走了,最后导致我连抢救他的钱都没有。
突然我意识到了什么。
我爸同意我取消婚约,这说明我可以改变一些什么。
就算最终我臭名远扬身败名裂,那我也一定拼尽全力让我爸有个善终。
我走出了办公室。
「喂,姜弋。有时间见一面吗?」
四
姜弋是我在剑桥的同学。
这是我 22 岁毕业三年以后我们第一次见面。
每次我努力想拿到第一,前面必定会横空出世一个姜弋。
在被他碾压了数年终于毕业后,我再也没联系过他。
「樊樊,几年没见,你还是这么漂亮。」
姜弋笑意吟吟地坐在我的对面,白色的衬衫更显得人干净利落。
「听你妈说你最近在相亲?」
没想到我上来就问这么直接的问题,他道貌岸然的帅气脸上的笑容有轻微的僵硬。
「对两家都有益的合作,何乐而不为,况且……」
我往前探过身子,食指轻轻地覆上了他柔软的两片薄唇,「嘘。」
「和我结婚。对你家,更有益。」
姜弋有些诧异地打量了我几下,确定我没有在恶搞他之后,他沉默了几秒。
「什么时候结婚。」
不愧是我选中的结婚对象,爽快。
我缩回来手,跷起了二郎腿。
「明天。」
姜弋喝了一口咖啡,摇了摇头。
我正欲开口,他看了看手表,有条不紊道。
「民政局还有三个半小时下班,我家离得挺近的。不如你陪我去取一下户口本,今天就领证。」
我点点头,朝身后的保镖队长勾了勾手指,「现在去我爸床头把我家户口本偷过来。两个小时候民政局门口看不见你,你就不要再来上班了。」
保镖队长一个鲤鱼打挺,「是!小姐!」
五
我和姜弋一人拿着一个结婚证坐在车上相顾无言。
「我希望这件事可以先不公开。」我打破了沉默。
姜弋看起来丝毫不意外,「没问题。」
「可能要隐瞒得久一点。」我得寸进尺。
「嗯可以。」
「虽然我们是法定夫妻,但是如果你有了心仪的对象,也可以告知我,我不会阻碍你的,但是希望你先不要公开。」
我大度的补了一句。
见姜弋没吱声,我心一软解释道,「我必须这么做,不然……」
「嗯我都知道。」
姜弋没头没尾地说了一句,而后下车扬长而去。
留我一个人在车上凌乱。
什么你知道,你知道个屁。
在梦里我不是没有尝试过在定亲当天装病悔婚耍无赖悔婚甚至是直接逃跑,但是命运没有一次不是把我拖回到既定的轨道上。
所以我决定在和路名的定亲宴上当众公布我和姜弋的婚讯。
丢人是丢人了点,不过这样路家就丝毫没有反应余地。
我就不信,他路家能不要脸到纠缠一个已婚妇女!
关于为什么要选择跨平台的实现方式
Write Once, Run AnyWhere.
越来越多的业务需求都有统一的业务诉求,按照传统的方式,在开发、测试、维护上的成本都是乘以N的,体验也很难做到一致性,特别是复杂的业务,实现成本高,导致功能不能很快的上线,各端侧对齐存在成本,综合来看,这样或者类似的业务基于研发效率等考虑,选择用跨平台的实现方式是非常有必要的。
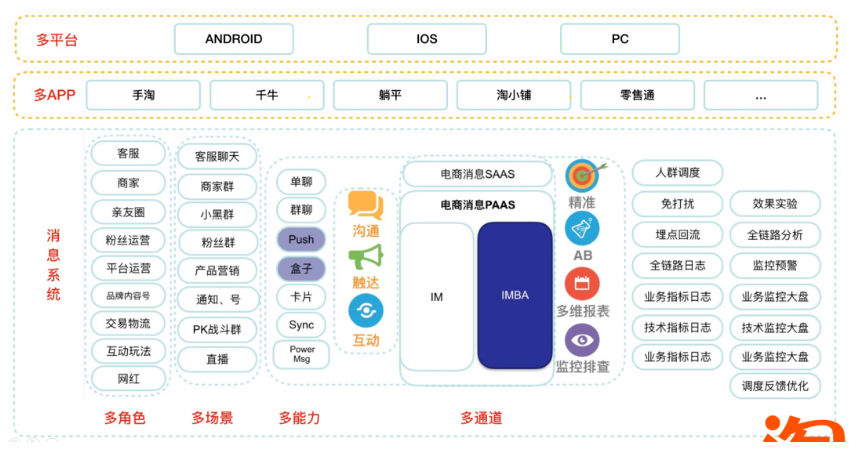
多角色的运营,多场景的触发,多重能力的支持,导致我们的消息系统十分的复杂,历史发展下的多通道消息系统底层由于历史发展衍生出3个子系统分别是:
- BC消息 - 最早的阿里旺旺就是基于此
- AMP消息 - 淘宝天猫的各类运营基于此,衍生出来的主要业务包括商家群、淘友、达人业务等,
- IMBA消息 - 主要是号方面相关的消息,包括BC通知类的消息、达人运营,品牌号运营等
分别在不同的BU维护,而这些在多平台运营下都是需要的,比如多角色的融合,多载体运行的诉求,每个载体又有多种平台。
基于以上背景,研发一个高可用、高复用、可定制的跨终端消息模块是非常有必要的。
关于语言的选择
选择编译型语言还是解释型语言,我觉得是没有绝对而言的,具体选择哪个要根据面对业务形态,适配的终端类型等多方面抉择而言,这里说下我们选择C++作为跨平台开发的首选语言一些背景。
- 我们团队本身是客户端的业务型团队,当前需要跨平台的业务主要是消息以及消息衍生业务的开发、维护和创新。
- 主要的终端包括移动IOS、移动安卓、MAC、WINDOWS。
- 主要载体包括淘宝app、天猫app、千牛app、淘特app、1688app、ICBU app等等。
C++作为天然的跨平台语言,可以高效无缝的调用系统能力,有丰富的技术生态,综合组内的技术栈,是比较契合我们的。
其实也跟集团里其他几个有类似需求的团队聊过,目前选择比较多的也是C++技术栈,本文也将以C++作为跨平台选型语言为主要来讲述。
即使是对于客户端而言,可选择跨平台语言也是众多的,通常跟随着跨平台技术方案一起来看会比较好一些,没有绝对的对和错,只有是否适合你。
关于基础库的选择
既然选择了C++作为我们跨平台开发的基础语言,那么面临的第一个问题是需要有一个功能较为完备,且符合当前诉求的基础库。我们调研了市面上几个主流的基础库
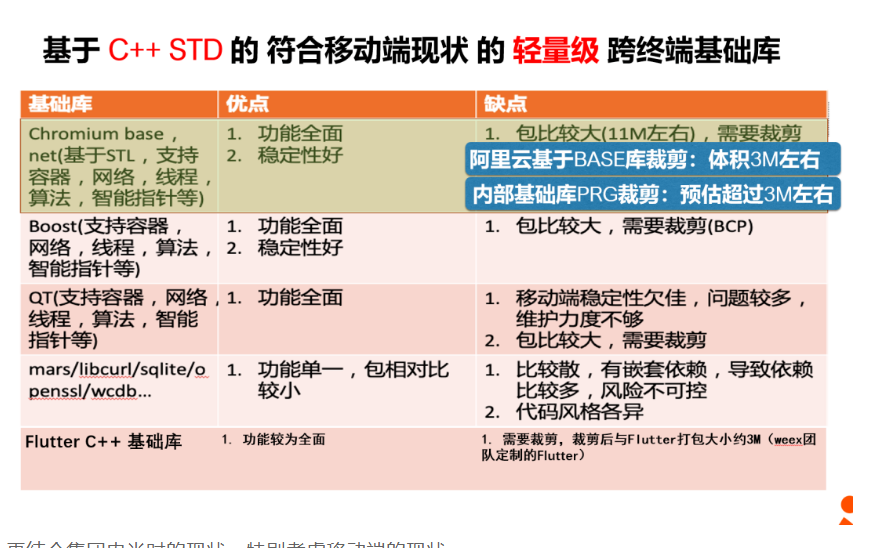
再结合集团内当时的现状,特别考虑移动端的现状:
- 包大小问题
- 集团中多种中间件(mtop、db、accs等)要不然已然跨终端,要不然在各端上都有较为优秀的独立sdk提供,基于第一点考虑,这一部分不需要在基础库里二次建设。
综合以上因素,集团内没有合适的足够小的且满足需求的c++基础库,因此我们当时决定自研一个基于C++ STD的符合移动端现状的轻量级跨终端基础库。
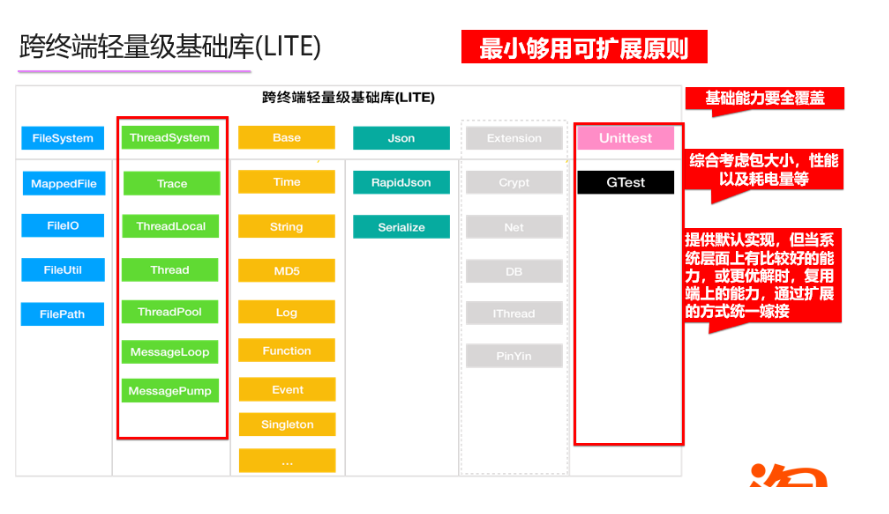
这里是跨终端轻量级基础库(LITE)的一个功能集合图,在对这部分进行设计的时候,主要考虑的几个设计原则:
- 基础能力要圈覆盖,
- 综合考虑包大小,性能 以及耗电量等
- 除了提供默认实现外,当系统层面有比较好的能力、或更优解时时,复用端上的能力,通过统一的方式嫁接。举个例子,集团中间件mtop,accs等,亦或者诸如Crypt模块,我们期望用比较简单的方式去实现,调用了Openssl的加解密接口,熟悉Openssl的同学都知道他的库大小在1M左右,同时IOS系统直接就提供Openssl能力,所以在做这一部分的时候我们提供了默认实现,同时开放统一接口接入系统能力,从而实现包大小最优。
总结一下设计原则9个字:最小够用可扩展原则。
| 平台 | 包大小(kb, 基础功能) | 说明 |
| ANDROID | 43kb | 动态库,v8a |
| IOS | 116 | 静态库,实际占app大小 |
| Windows | 47kb | x86 |
包大小情况如图(未包含淘宝天猫基础客户端能力,包含后略增加60k左右)。
目前Lite库已经作为淘系C++基础库集成在集团的近100个App里,除了包大小优势外,稳定性也极佳,百万分之1左右的崩溃率(淘宝双端统计),同时与淘宝天猫架构组合作,无缝提供淘宝天猫客户端基础能力(log、埋点、键值存储等)。
关于跨平台的架构选择
通常技术还是为业务服务,还是贴近业务来讲述,能更有体感一些,这样也更直观的把我们遇到的问题和背后思考透漏给大家,作为参考,还是以消息为例:
我们面临的问题和诉求:
- 屏蔽通道,以统一的数据模型方式对外提供:底层需要对接3个服务端(多通道),同时每个server端提供的能力、功能又高度相似,需要抽象后统一屏蔽提供给上层,此外相关数据需要跨通道或者屏蔽通道存储。
- 调用方线程不统一:业务部分需要处理来自不同线程的高并发(于客户端而言)请求。
- 多语言:接入层需要适配不同平台,ANDROID-JAVA,IOS、MACOS-Object C,WIN-C++。
- 多维度支持定制:
- 业务定制:业务上需要面对不同的APP可以有不同的功能定制,这里还包括支持通道的可配置,业务能力的可定制等,举个例子:在淘特里无群聊服务,但是在淘宝里这一部分又是需要的,在千牛里需要有商家群,但不需要有淘友关系群,等等基于业务、以及包大小考虑的定制。
- 线程调度定制:基于耗电量、系统资源、平台特性等考虑,需要线程调度方案的可定制。在移动端对耗电量比较敏感且系统资源有限,但是PC端上对性能要求会更高一些,如何在统一的方案里支持线程调度的平台级、甚至是业务级别定制。
- 网络流量管理定制:对网络能力一方面要有统一的监控,方便判断MTOP的各种API调用情况分析,另一方面需要有统一的切面能力,在MTOP的调用上做二次业务级别的网络流量接口优化定制。
- DB管理定制:基于FD、平台特定等考虑,需要DB管理可以根据不同的平台有不同的定制策略,在移动端采用单用户一库多表的形式,在pc端性能最大化采用多库多表甚至需要支持不同app的不同db管理方案可定制。
- 基础能力复用:对于集团通用的基础组件,需要有统一的能力从外部获取从而方便c++层使用。
- 稳定性保障:是否方便做单元测试,设计上如何避免单元测试对内部代码的入侵。
基于以上,我们设计了MessageSDK的架构大致如下:
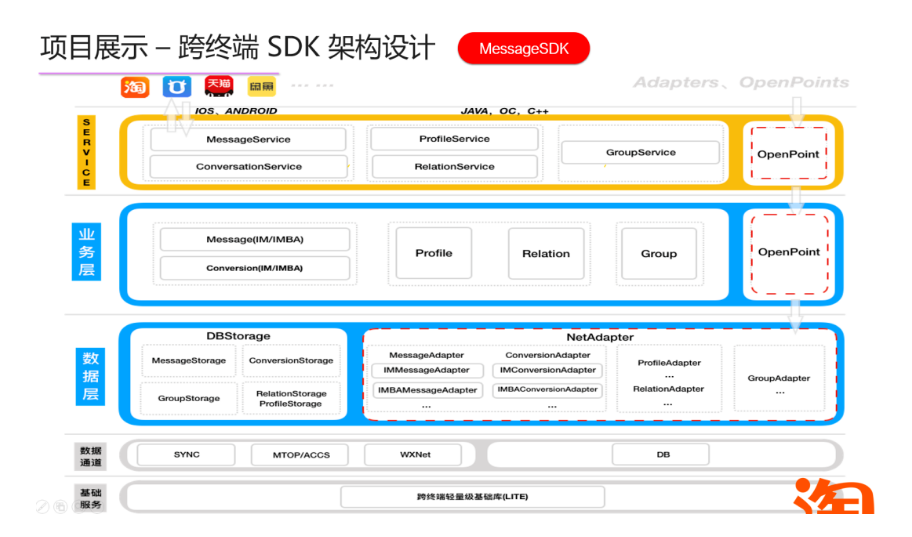
来整体看下上面的设计是如何解决这些问题的。
总体分5部分,Service层,业务层,数据层,数据通道层以及基础服务层。从上到下看整个架构设计
- Service层:也就是我们通常说的Wrapper层,其目的是为了翻译业务层C++的接口,提供三种方式的直接接入,Java,Oc,C++,需要说明的是这一层不要做除语言转换外的任何代码,一来方便问题排查,wrapper不做额外的处理和问题排查,二来业界也有不少自动化实现语言翻译的工具,有关这部分我们后面部分详细聊。
- 业务层:业务逻辑的一个组合,以消息为例,按模块分为三个子模块第一个消息模块,第二个profile模块,第三个群模块,模块与模块之间相对独立,做强制隔离,代码无耦合,功能可定制化
- 数据层:分为两部分本地存储以及网络存储,其目的是屏蔽数据来源以统一的方式提供给业务层,让业务不感知通道来源,同时在这一层还吃掉所有的耗时操作,IO以及网络请求,其中Adpter主要是屏蔽通道之间的差异,这一部分支持整体可替换,目的提高扩展性,可定制接入三方通道
- 数据通道层:这一部分就是数据来源的通道,主要有SYNC,WXNet,DB等
- 基础服务层:是一个跨平台的c++基础库。
其实客户端按层分割的设计理念,无论是在PC时代还是现在的移动互联,都不是什么显而易见的事儿,主要关注下这里面的差异点也可以说是这种框架设计的优点。
- 便捷:service我们只做语言层面的胶水,缩短后期排查问题的整个链路,方便后期排查和定位问题。同时自动化的实现也再次降低了维护成本。
- 开放:上图右侧是Openpoint能力,主要是通过一些标准化的开放点去开放一些能力,让接入方做更多的业务属性,简单来说【每个业务有特定的开放点,用统一的形式开放出去】
- 定制:
- 业务定制:模块与模块之间相互完全独立,代码无耦合,强制隔离,实现功能的可定制化,让业务方可以自由的进行业务形态组合的同时做到包大小最优,
- 线程调度定制:统一线程调度处理方案,抽象线程配置策略,多app可自由配置,上层可选择平台级线程调度最优方案。
- 网络流量管理定制:网络调用处统一切面处理,一方面对瞬时相同请求做拦截合并,大幅度降低服务端压力,另一方面针对业务级别做原子调用的合并定制,减少服务端查询量,此外切面处进行统一打点处理,方便客户端做调用流量监控。
- DB管理定制:同线程调度定制,统一DB管理分配方案,抽象库分配策略,多app可自由配置,上层可选择平台级线程调度的最优方案。
- 扩展:对外提供整体能力,又可以动态替换,目的是提供一种能力让接入方可以放入自己的数据通道,从而实现一个业务的扩展,此方法也极大的方便了后期做统一的单元测试。
于CPP程序员而言,线程模型是非常重要的,好的设计可以从架构上就避免掉后期一系列隐秘的bug,这里包括一系列问题,比如:
- 在移动端上,通常调用者不关心调用线程,但是在数据层又需要做统一的数据修改和聚合能力
- 业务层频繁调用,过多的锁除了可能会出现死锁外,也不利于性能最大化。
- 部分接口如果IO、NET时间过长可能导致整个流程中断,或异常。
来看下跨终端SDK架构设计的线程模型:
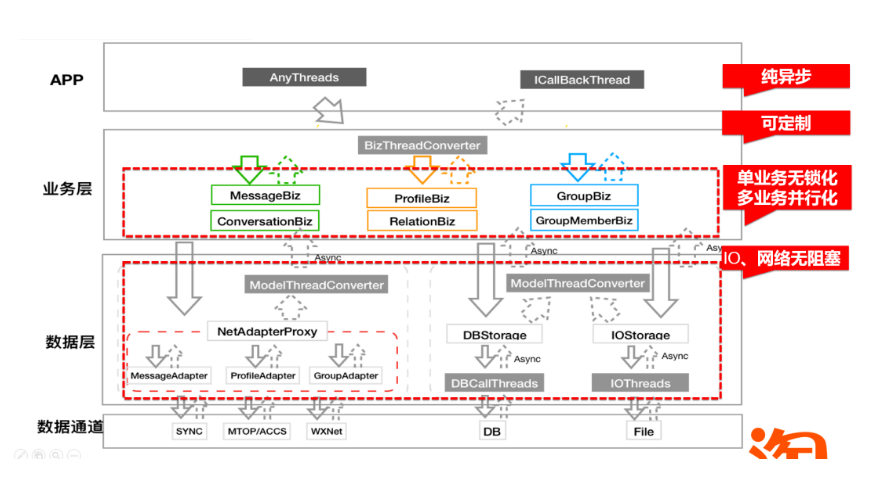
- 接入层:不限制调用线程,降低接入成本
- 业务层 : 按模块做隔离,单独运行在自己的业务线程里,在biz层做业务无锁话的同时,做到单业务无锁化,多业务并行化
- Model层 : 主要是做IO、网络操作,目的是为了业务线程IO、网络无阻塞
整个线程模型的特点:纯异步,可定制,单业务无锁化,多业务并行化,IO网络无阻塞。
C++工程脚手架及C++工程标准化
C++作为天然的跨平台语言,可以高效无缝的调用系统能力,有丰富的技术生态。但是实际面向Android、iOS、Windows、Mac等多平台的开发过程并不顺滑,主要存在以下问题:
- 平台特性差异、开发语言、开发工具链、编译打包等
- 多平台下项目配置维护成本高
- 胶水(语言转换层)代码人工接入成本高、重复性工作大、门槛高(主要是对于C++开发者)
- 业务及技术框架选型困难
- 构建发布方案规范化较差、集团研发平台对跨平台构建发布的设计不足
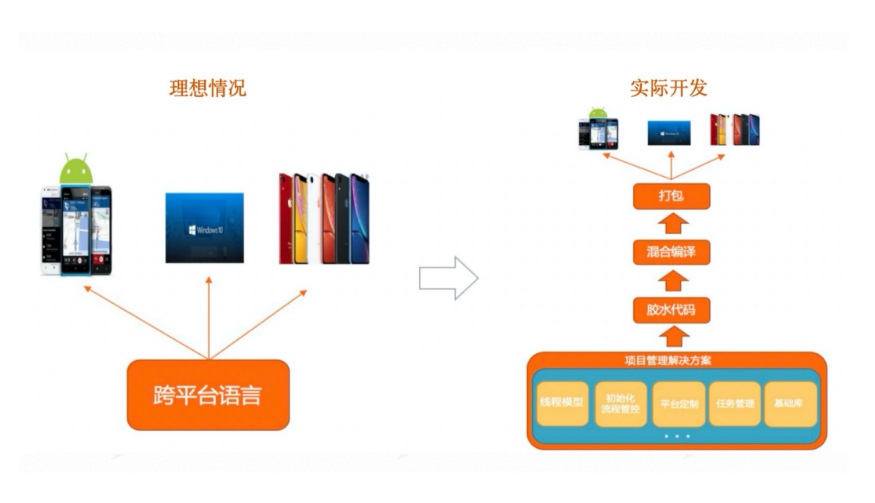
我们在想,SDK开发流程是否可以是一个可被SOP的过程?如果有统一的跨平台SDK开发SOP流程,特别是对于新入此行的同学,当然是非常友好的。想想coder如果可以上来就可以写业务代码,不用关心框架,工程模型,打包方案等等,是不是美滋滋。
为了解决上述共性问题,结合之前我们在消息SDK上的相关经验,我们启动了Eyas(雏鹰)项目。
Eyas旨在进一步结合集团技术能力,降低跨终端开发成本,为其提供标准化的作业流程,包括跨平台基础库组件化、业务框架通用化、配置一体化、语言转换层代码工具化,以及发布能力统一化等一整套解决方案,让开发者们可以在轻量级认识跨终端的同时,更专注于业务本身。
Eyas的中文是雏鹰,我们希望通过Eyas,可以一起在跨终端的蓝海中探索无限可能,同时可以孵化出更多跨平台的模块,让开发者低成本开发跨平台SDK,保证多平台业务一致性,提升业务开发效率的同时降低测试成本。
为了让开发者可以更快的上手跨平台的开发,我们拟定了一套跨平台SDK开发的作业流程,同时在每一步都提供了对应的解决方案,所有的解决方案均提供工具化的方式来高效、低成本的辅助开发者们进行跨平台SDK的开发。下图是MTL4上C++跨平台研发工作流:
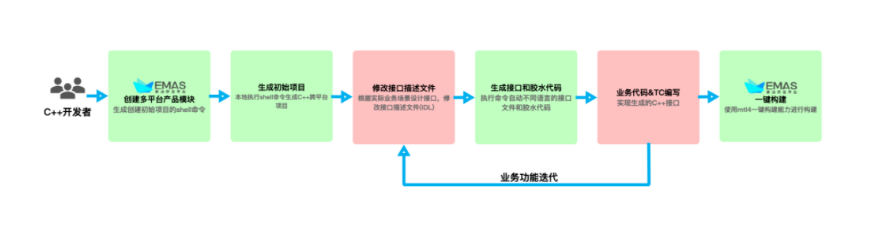
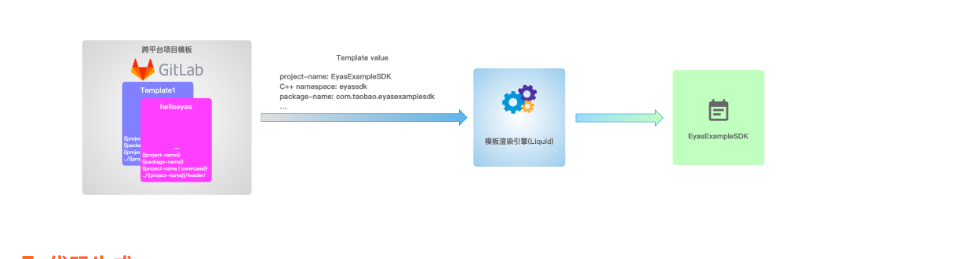
其中 IDL(接口描述)的编写 以及 功能代码编写,需要开发者根据实际业务进行开发。我们从项目创建、代码生成、编译选项和构建四个维度分析。
跨终端团队在以往的桌面端开发中积累了很多SDK开发经验,也有一套成熟的SDK框架代码,但是我们在孵化新SDK时候,还是要花一定时间在SDK的通用代码的拷贝上,无法快速的复制出一个新的SDK项目。
开发者都是懒惰的,为了尽可能的复用代码,提升开发效率,开发者发明了宏,也发明了模板编程。为了支持复用SDK框架通用代码和项目配置,我们提供了基于项目模板创建项目的工具,快速实现项目工程从0到1的过程。
其实对于刚涉足到跨终端开发的开发者,创建了可以编译不同平台产物的项目就已经开启了跨平台的大门。
代码生成
代码生成即语言胶水层代码工具化,由于平台开发的语言差异,需要有一层胶水代码来进行语言的翻译,胶水代码本身是没有业务逻辑的,并且耗费开发成本,人工编写代码也会带来出错的风险。我们使用胶水代码自动化来解决该问题。
胶水代码自动化的原理:
根据接口的idl描述生成接口文件和胶水代码
JNI: C++ <-> Java交互的胶水代码
ObjCPP: C++ <-> ObjC交互的胶水代码
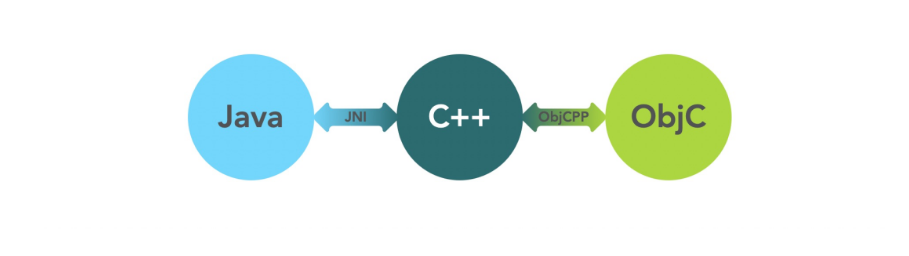
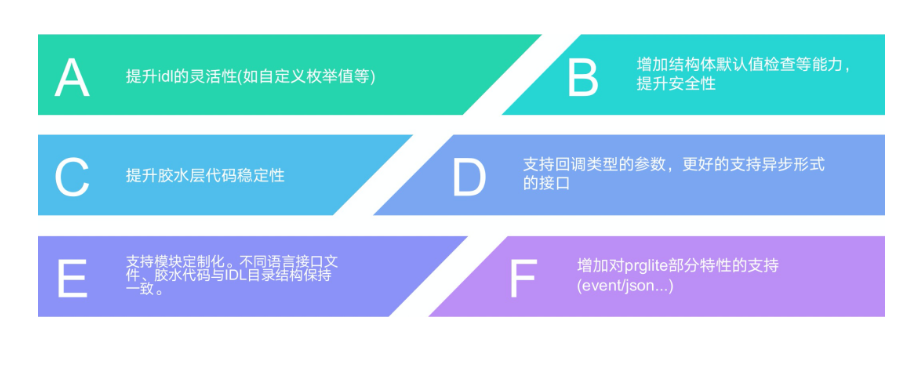
我们基于djinni(地址:https://github.com/dropbox/djinni)进行了二次开发,提升安全性的同时增加了多项feature,更容易对复杂项目做模块定制化能力。
编译配置+依赖管理
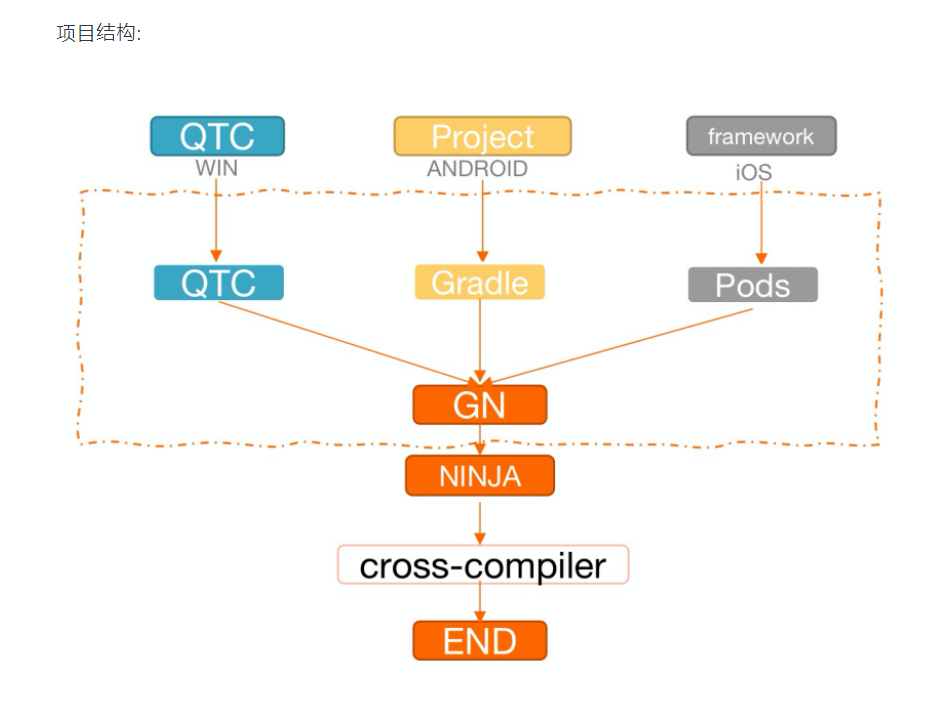
支持以下能力:
- 使用GN管理工程和源码文件,确保多端的C++项目配置一致。
- 统一多平台业务模块定制化能力。
- 支持多平台下不同IDE编码和调试。
- 结合集团技术能力,统一依赖管理解决方案,支持通过一份配置文件管理多平台下的依赖。
原文链接
本文为阿里云原创内容,未经允许不得转载。
原创文章,转载请注明出处:https://www.armbbs.cn/forum.php?mod=viewthread&tid=119562
版本迭代是嵌入式开发永久的痛,这么多年不知道浪费了多少时间在版本迭代上。
部分系统组件还好点,有个LTS长期支持版,而厂家SDK和IDE环境可谓惨不忍睹,一代版本一代坑。
https://www.bilibili.com/video/BV1qu4y1d7wV
https://www.bilibili.com/video/BV1qu4y1d7wV刚开始接触M内核芯片的时候就是用的这款IDE,最早有MDK2(主要是51使用), MDK3, 进入MDK4后,MDK4.54算是一个经典版本,最早搞M内核那波人,很多人都是用的这个版本上手的。
迭代到MDK4.74后,开启了MDK5时代,刚开始的MDK5.0X和MDK5.1X就是填坑,所以用MDK4转载到MDK5的人还不是很多。
芯片厂家新出的新品没法再用MDK4,必须转战到MDK5了。KEIL为了缓解用户的对MDK4的依赖,推出MDK5后,仅接着搞了个MDK5对MDK4的兼容包。初期推广的时候,很多人不知道这个兼容包。

将MDK4使用MDK5强行打开后,各种各样的问题,被搞得头都大了。把所有的例子都用MDK5重新创建下,有点不现实,例子太多了。后来不断摸索,搞了个骚操作,直接修改MDK4工程后缀 uvproj 改成 MDK5的后缀 uvprojx即可,大部分例子都可以这么方便的使用MDK5打开。
MDK5 AC5编译HAL库带brower info堪称史诗级灾难,编译10来分钟都是小意思。编译慢就算了,电脑CPU都飙到100%了,电脑什么都干不了,只能干等着。
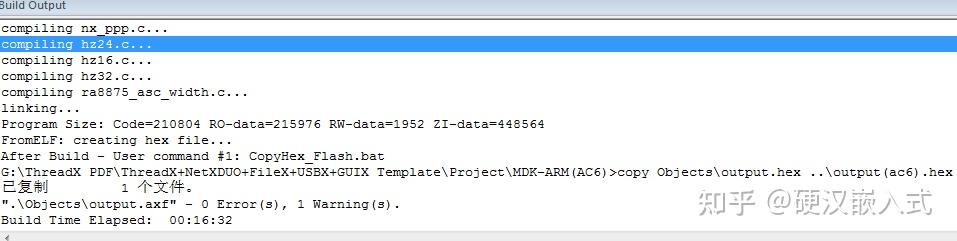
为了缓解用户的焦虑,开始推进MDK AC6,刚开始的时候还挺开心,带browser info编译速度快了很多,当编译完毕后,发现go to def不能用,研究了下,原来是把browser info生成搞到了后台。实际总时间和AC5区别不大。
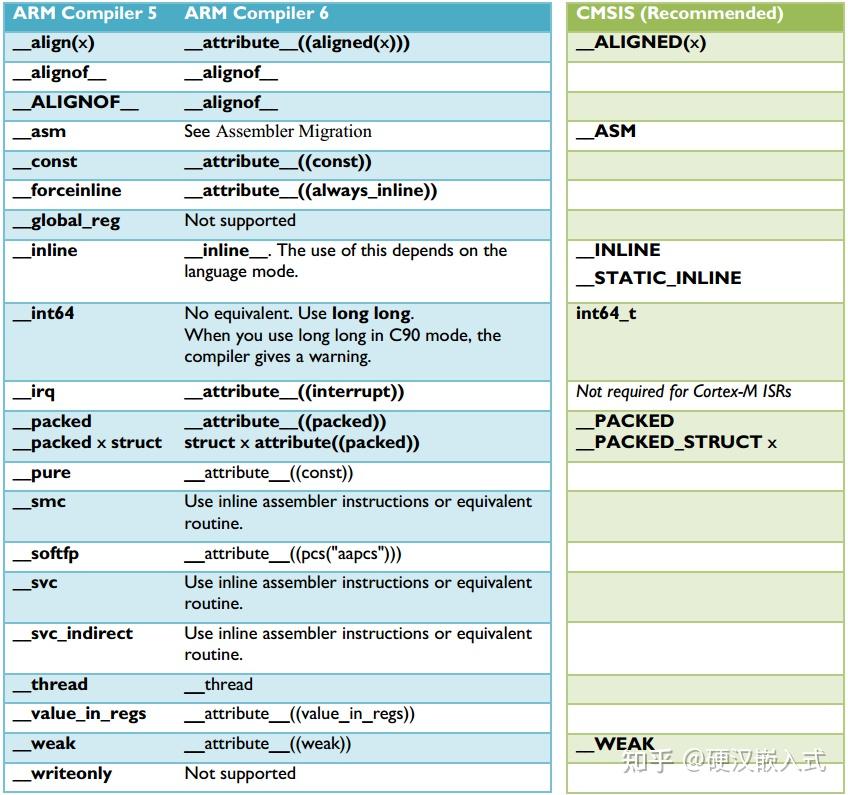
这个痛点,估计近几年无法得到解决,因为市面上大量开源工程依然是MDK AC5创建的,更重要的是工程中一些开源组件不支持MDK AC6,这就给转战MDK AC6带来很大难度。虽然KEIL后来出了AC5转AC6文档,但杯水车薪,复杂工程的修改难度太大了。
既然这么麻烦,为什么还要转战AC6,因为AC5从MDK5.37开始正式推出历史舞台,后面出的M23,M33,M55,M85等芯片也没法用AC5了。
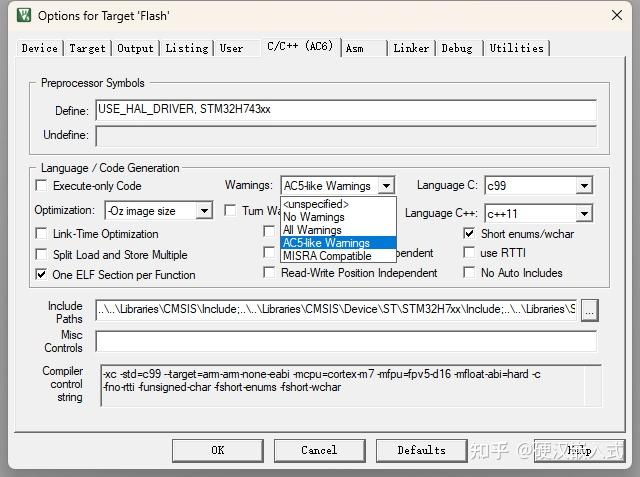
现在的大部分工程依然要使用AC5 LINK警告类型
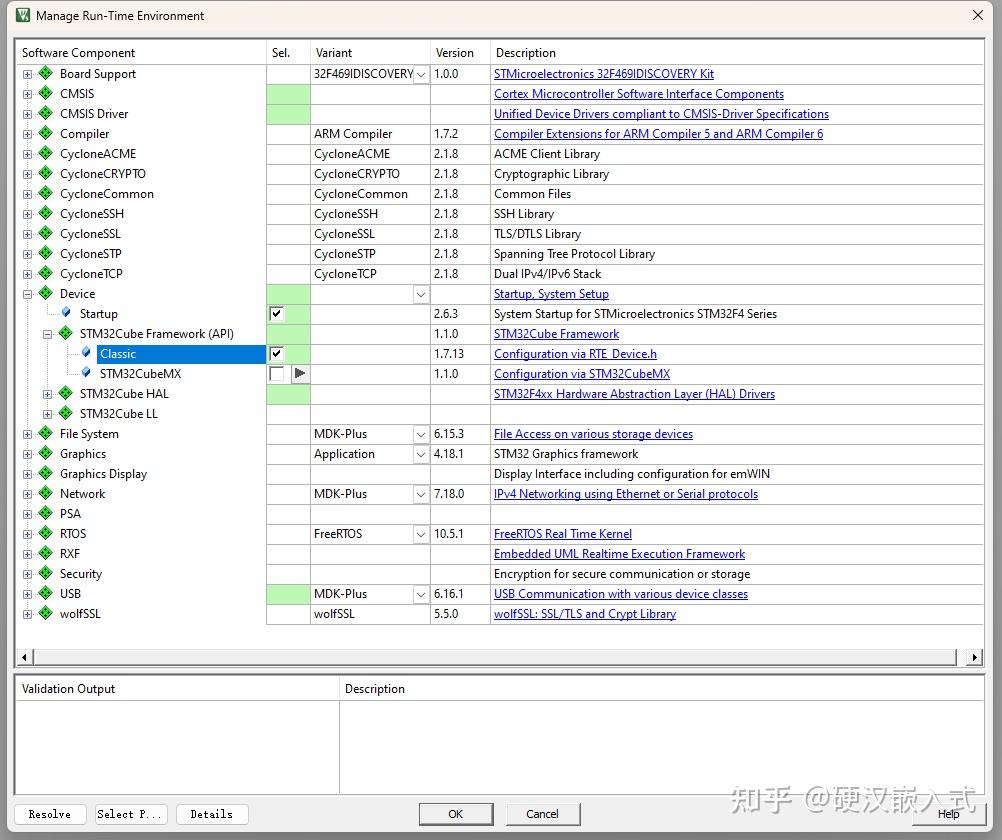
早期的芯片还支持MDK RTE经典创建方式,这个方式非常好用,也非常给力,这个值得肯定。
后来新出的芯片,同样是灾难级表现,以STM32H7为例,不再支持经典方式了,RTE必须配合STM32CubeMX一起使用, 而且对应的工程必须使用指定MDK版本,CMSIS版本和STM32H7软件包版本。
本来官网下载就奇卡无比,最近还搞了骚操作,让本就难用的下载问题“雪上加霜”,软件包的下载变得超级难用
这个必将又是一顿疯狂操作。

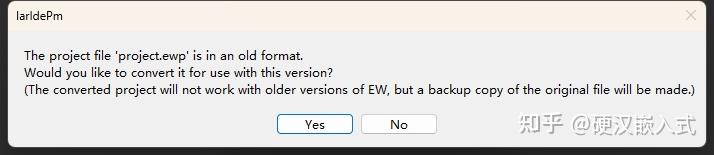
IAR最早用的是IAR6.3,之后陆续使用了7.x ,8.x和9.x
IAR早期版本最大的缺点就是毫无兼容性可言,你的工程是版本创建的,就必须使用那个版本打开。到后来的IAR8.X和9.X好了很多,可以强制转换之前老版本创建的程序了。
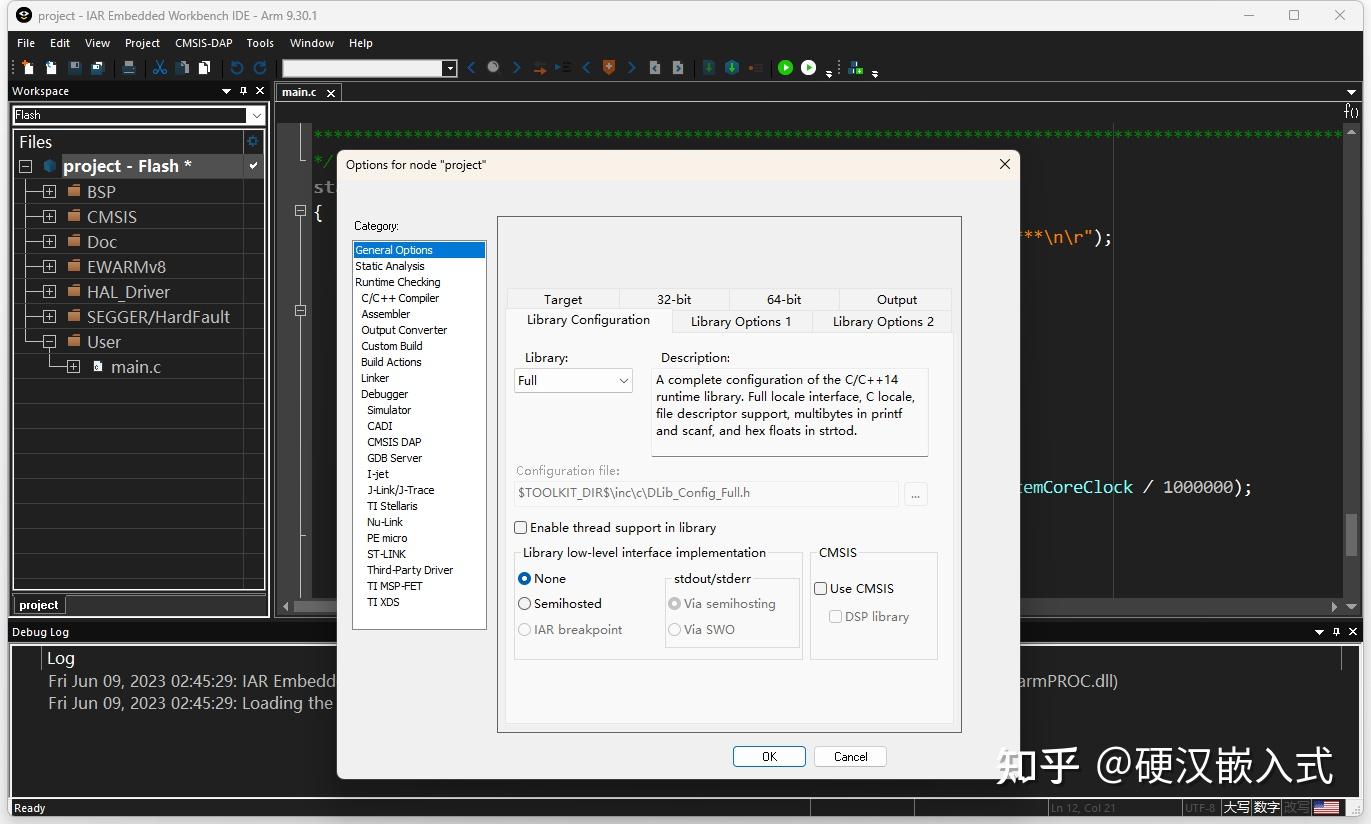
除了兼容性问题,新出的IAR9.X带来了一个坑,之前的fputc和fgetc重定向串口没法用了,必须用他们官方的重定向方式解决。
https://www.armbbs.cn/forum.php?mod=viewthread&tid=109542
基于GCC创建的IDE环境,同样是各种兼容性问题,以Embedded Studio为例,之前用V5.X创建的工程,现在使用V7,X就无法正常编译,直接报错。
这找谁说理去,网友们一打开,无法正常编译,这用户体验不太舒服。
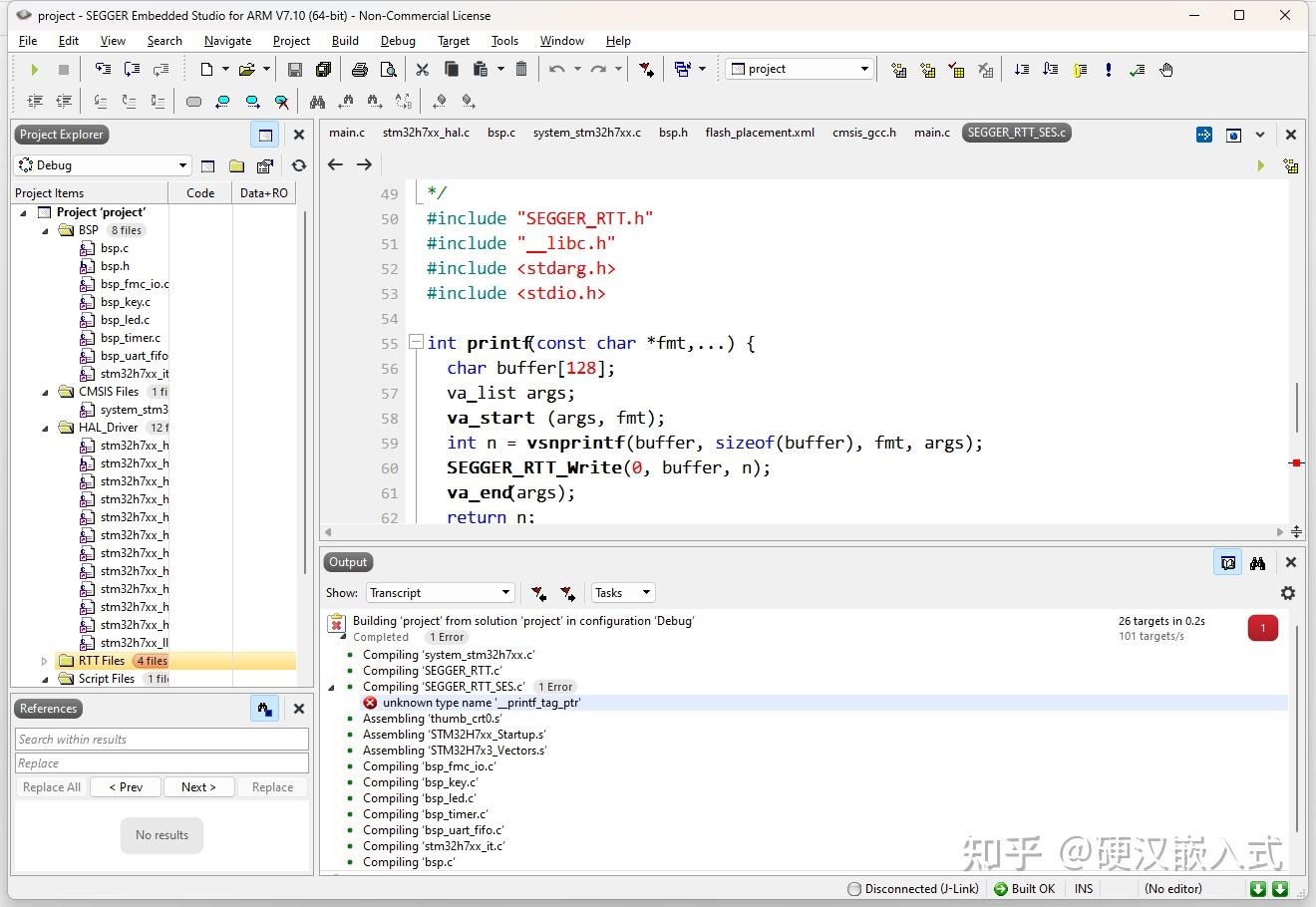
基于eclipse/vscode/clion + gcc + openocd的玩法,我用的少,没有研究过版本兼容问题。
芯片厂家的SDK也是各种坑,各种折腾用户。
以STM32为例进行说明
本来早期的F1,F2,F3,F4等系列,标准库玩法已经很成熟了,时间关键的地方再倒腾下寄存器方式加速实现,大部分项目也够用。但后面为了配合STM32CubeMX图形化开发工具,不得不推出HAL和LL库。
对于用户做产品还好点,但像我们这种做开发板的,就是灾难,不得不做HAL库和标准库两个版本。甚至必要的情况下还得提供全部使用STM32CubeMX创建的工程。
有时候版本迭代不考虑兼容性,同样让人头疼,以串口代码为例,后面的升级竟然直接来个删除结构体成员的骚操作:
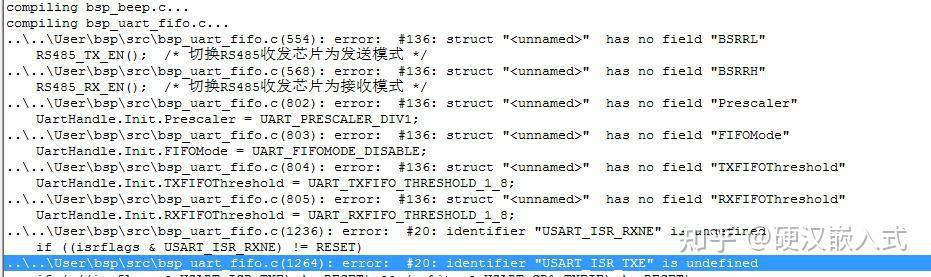
针对各种兼容问题,大家有什么好的思路来解决这些问题,欢迎分享,个人用倒是没什么,但是团队之间或者网上分享给别,兼容性就不得不考虑了。
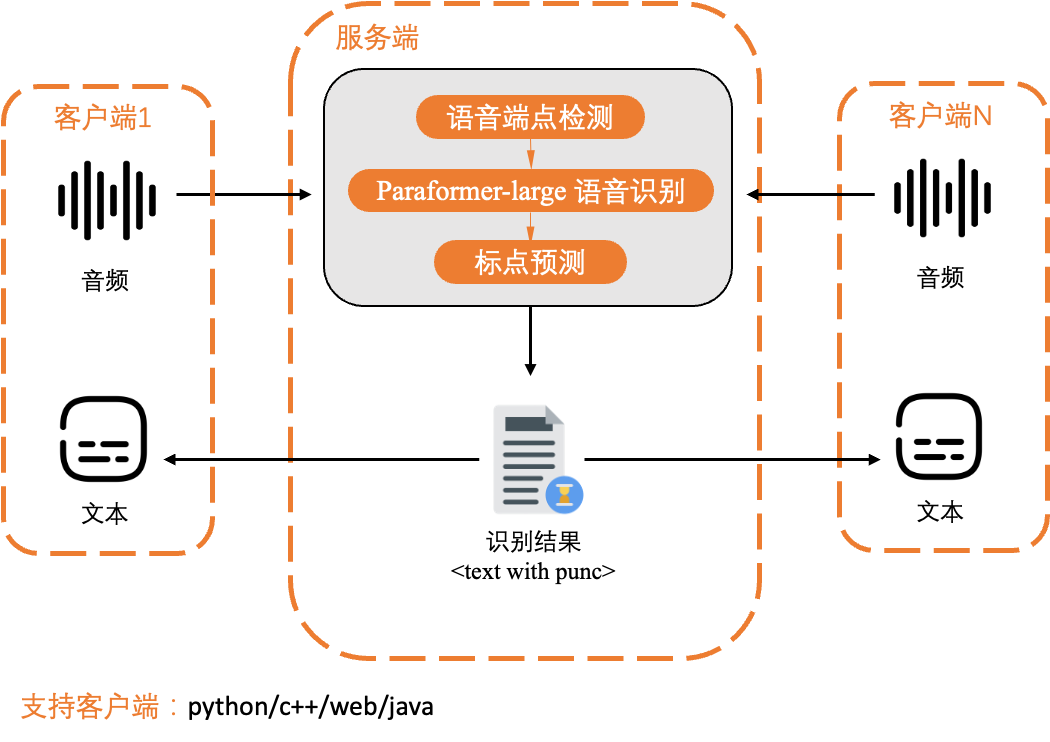
FunASR是由达摩院语音实验室开源的一款语音识别基础框架,集成了语音端点检测、语音识别、标点断句等领域的工业级别模型,吸引了众多开发者参与体验和开发。为了实现工业落地的最后一公里,开发了FunASR runtime-SDK,方便开发者高效、便捷地进行语音识别服务部署。
离线转写
力献语音识别全链路工业级模型
FunASR runtime-SDK提供了一款功能强大的语音离线文件转写开源工具,可以高精度、高效率、高并发(>100)的支持长音频离线转写。该SDK结合了达摩院语音实验室在Modelscope社区开源的语音端点检测、语音识别、标点等模型,支持模型的ONNX导出与量化,并提供了可方便快捷的部署到本地或者云端服务器的一键化部署脚本。开发者可以基于该SDK,便捷的构建高精度、高并发、高效率的离线文件转写服务。
四大优势
便捷、高精度、高效率、长音频链路
便捷部署提供了一键部署FunASR runtime-SDK的方案,通过funasr-runtime-deploy-offline-cpu-zh.sh可一键完成docker安装、镜像启动、服务部署,详见FunASR离线文件转写服务便捷部署教程 :https://github.com/alibaba-damo-academy/FunASR/blob/main/funasr/runtime/docs/SDK_tutorial_zh.md
高精度
FunASR runtime-SDK集成了达摩院语音实验室在ModelScope开源数据训练的工业级语音识别模型Paraformer-large,保证了端到端转写效果的精度。
下方表格对比了Paraformer-large与当前最优SOTA模型识别效果:
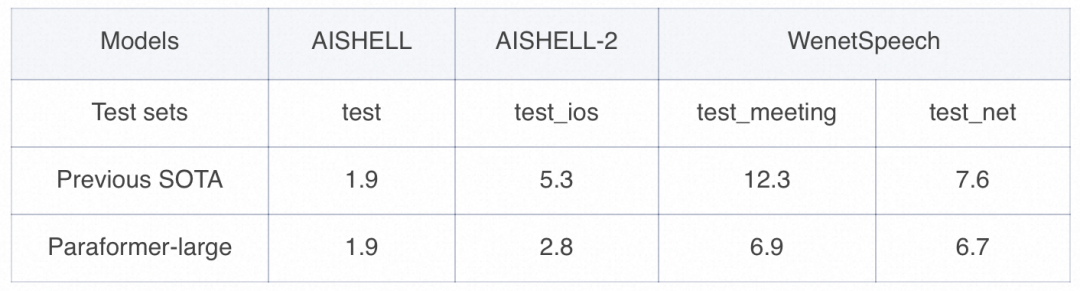
集成了Paraformer-large模型的阿里云语音识别服务API,在三方评测榜单SpeechIO最新6月评测中取得了SOTA效果。详情见 SpeechIO Leaderboard。https://mp.weixin.qq.com/s/eAgvlgwLqWQ9CQRRduUmtg
高推理效率
FunASR runtime-SDK中的语音端点检测(VAD)、语音识别(ASR)、标点断句(PUNC)模型均通过onnx 量化导出实现推理加速,其中ASR模型为基于Paraformer的非自回归模型,相比于目前普遍采用的自回归模型具有明显的推理效率优势,可同时支持多线并发,可以准确、高效地对音频进行转写。采用AISHELL-1测试集测试了FunASR runtime-SDK的转写加速比,CPU8369B上的吞吐率为562。不同配置下的详细吞吐率指标如下表:
Intel(R) Xeon(R) Platinum 8369B CPU @ 2.90GHz 16core-32processor with avx512_vnni
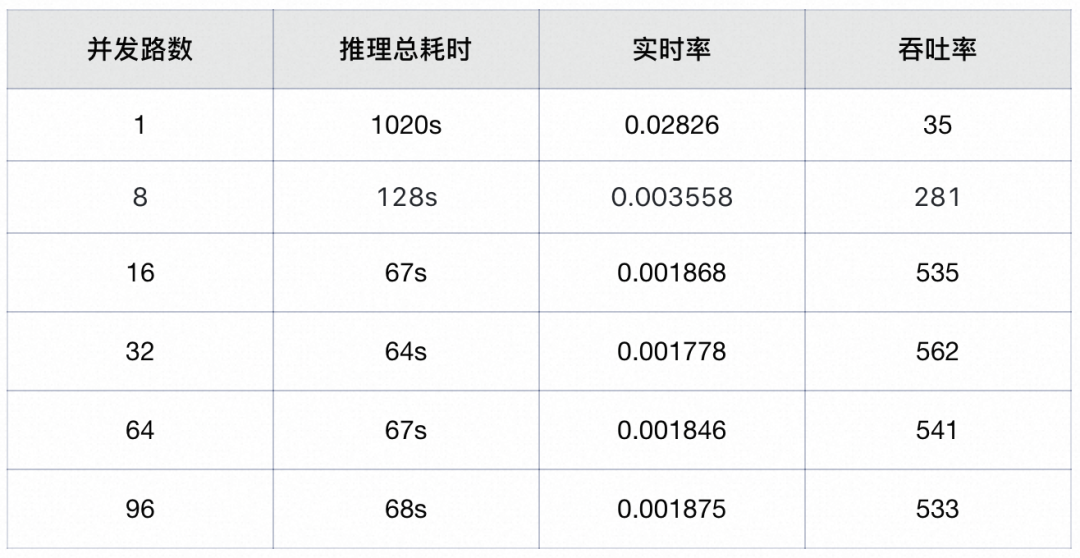
更多详细结果见benchmark: https://github.com/alibaba-damo-academy/FunASR/blob/main/funasr/runtime/docs/benchmark_onnx_cpp.md
长音频链路
FunASR runtime-SDK提供了一套完整的语音识别链路,包括语音端点检测(VAD)、语音识别(ASR)、标点断句(PUNC),可用于高效转写长音频,用户可以无需进行二次开发。
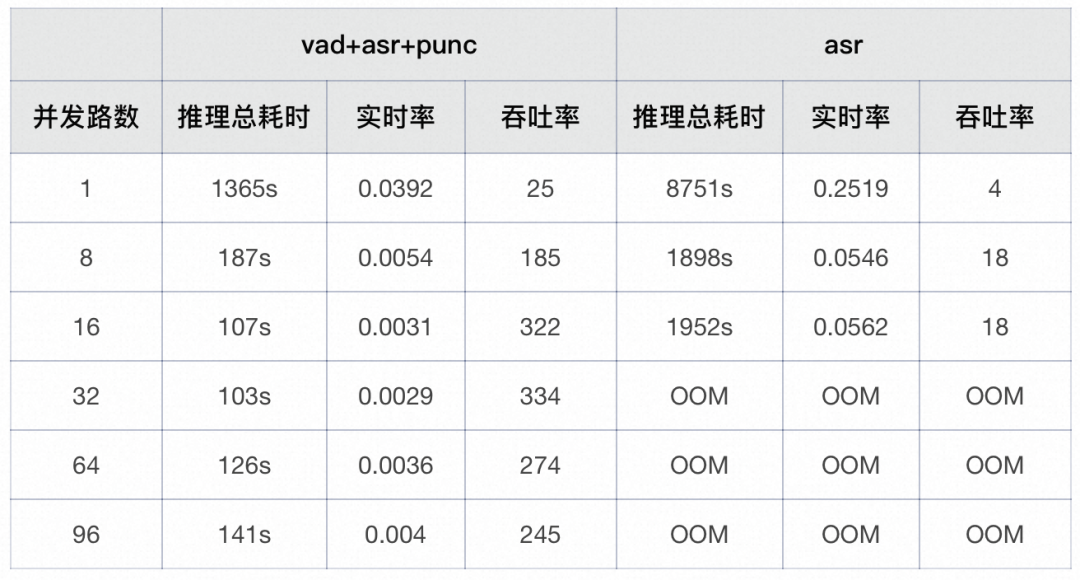
在一个长音频测试集上(时长为0~24min)分别对asr链路、vad+asr+punc链路进行了测试,asr链路在并发32线时会OOM,vad+asr+punc链路的吞吐率为334,相比asr链路有明显优势。不同配置下的详细吞吐率指标如下表:
Intel(R) Xeon(R) Platinum 8369B CPU @ 2.90GHz 16core-32processor with avx512_vnni
使用指南
精简操作,即刻安装
FunASR runtime-SDK当前已开源。
开源工具包地址 :
https://github.com/alibaba-damo-academy/FunASR/blob/main/funasr/runtime/readme_cn.md
步骤如下:
第一步:下载安装部署工具
curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/funasr-runtime-deploy-offline-cpu-zh.sh;第二步:安装部署
sudo bash funasr-runtime-deploy-offline-cpu-zh.sh install --workspace https://www.zhihu.com/topic/20096920/funasr-runtime-resources第三步:测试与使用运行上面安装指令后,会在https://www.zhihu.com/topic/20096920/funasr-runtime-resources下载samples, 为客户端测试工具,支持python/c++/java/html网页等语言。以Python语言客户端为例,进行说明,支持多种音频格式输入(.wav, .pcm, .mp3等),也支持视频输入(.mp4等),以及多文件列表wav.scp输入以下代码:
python3 wss_client_asr.py --host "127.0.0.1" --port 10095 --mode offline --audio_in "https://www.zhihu.com/topic/audio/asr_example.wav"运行上面客户端指令后,即可对音频进行识别转写。同时在云端部署了FunASR runtime-SDK服务,用户可以直接在浏览器中进行体验:
https://101.37.77.25:1336/static/index.html
FunASR-runtime-SDK背后的语音技术:
开源|业界首个应用落地的非自回归端到端语音识别模型,推理效率可提升10倍
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/61975.html