
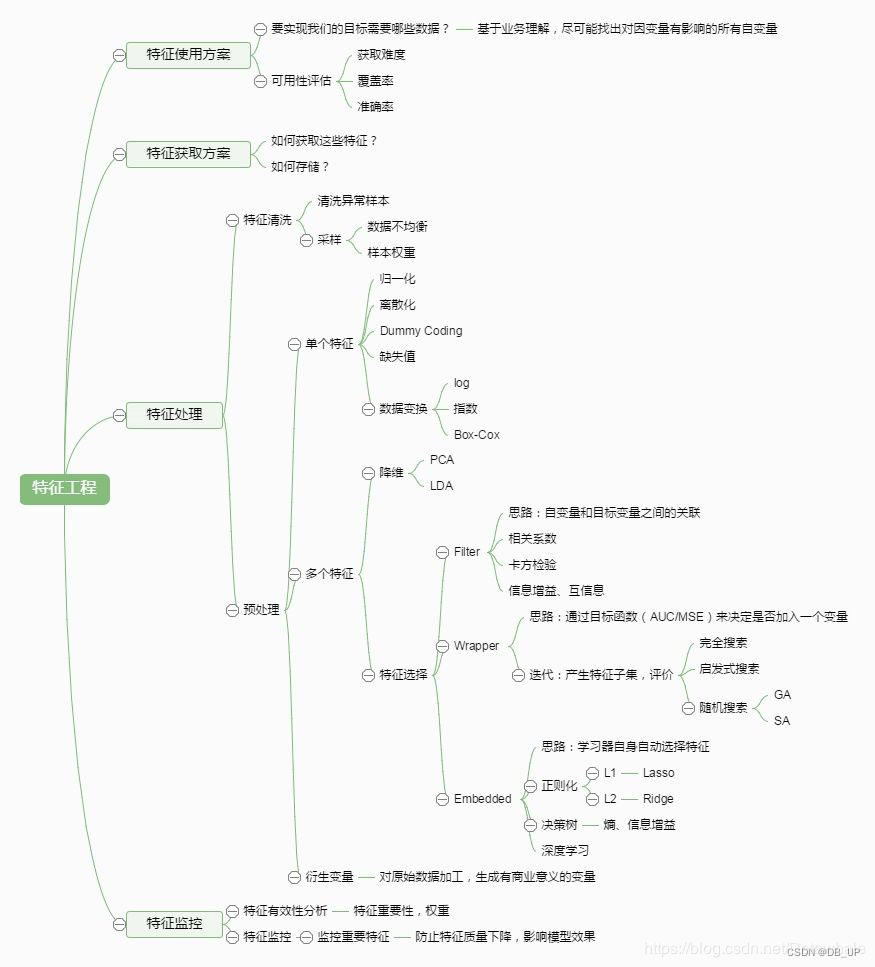
特征工程(Feature Engineering)对特征进行进一步分析,并对数据进行处理。
常见的特征工程包括:异常值处理、缺失值处理、数据分桶、特征处理、特征构造、特征筛选及降维等。

1.1 箱线图
箱线图筛选异常并进行截尾,这里不用删除,其原因为:
1、笔者已经合并了训练集和测试集,若删除的话,肯定会删除测试集的数据
2、删除有时候会改变数据的分布等
1.2 缺失值
关于缺失值处理的方式,有几种情况:
1、不处理(这是针对xgboost等树模型),有些模型有处理缺失的机制,所以可以不处理
2、如果缺失的太多,可以考虑删除该列
3、插值补全(均值,中位数,众数,建模预测,多重插补等)
4、分箱处理,缺失值一个箱。
1.3 数据分桶
连续值经常离散化或者分离成“箱子”进行分析,为什么要做数据分桶呢?·离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
1、离散后的特征对异常值更具鲁棒性,如age>30为1否则为0,对于年龄为200的也不会对模型造成很大的干扰;
2、LR属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
3、离散后特征可以进行特征交叉,提升表达能力,由M+N个变量编程M*N个变量,进一步引入非线形,提升了表达能力;
4、特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化当然还有很多原因,LightGBM在改进XGBoost时就增加了数据分桶,增强了模型的泛化性。
现在介绍数据分桶的方式:
等频分桶
等距分桶
Best-KS分桶(类似利用基尼指数进行二分类)
卡方分桶
最好将数据分桶的特征作为新一列的特征,不要把原来的数据给替换掉,所以在这里通过分桶的方式做一个特征出来看看,以power为例:
当然这里的新特征会有缺失。这里也放一个数据分桶的其他例子(迁移之用)
数据转换的方式有:
数据归一化(Min MaxScaler)
标准化(StandardScaler)
对数变换(log1p)
转换数据类型(astype)
独热编码(OneHotEncoder)
标签编码(LabelEncoder)
修复偏斜特征(boxcox1p)
归一化和标准化的区别:
归一化:对象为非高斯分布,缺点:容易受到异常值的影响。
标准化:对象为高斯分布,缺点:对分布要求严格;优点:处理之后数据更加正态化。
1.数值特征归一化,因为这里数值的取值范围相差很大
2.类别特征独热一下
3.关于高势集特征model,也就是类别中取值个数非常多的,一般可以使用聚类的方式,然后独热,这里就采用了这种方式:
在特征构造的时候,需要借助一些背景知识,遵循的一般原则就是需要发挥想象力,尽可能多的创造特征,不用先考虑哪些特征可能好,可能不好,先弥补这个广度。特征构造的时候需要考虑数值特征,类别特征,时间特征。
对于数值特征,一般会尝试一些它们之间的加减组合(当然不要乱来,根据特征表达的含义)或者提取一些统计特征
对于类别特征,我们一般会尝试之间的交叉组合,embedding也是一种思路(将离散变量转变为连续向量)
对于时间特征,这一块又可以作为一个大专题来学习,在时间序列的预测中这一块非常重要,也会非常复杂,需要就尽可能多的挖掘时间信息,会有不同的方式技巧。当然在这个比赛中涉及的实际序列数据有一点点,不会那么复杂。
eg:

1、时间特征的构造
根据上面的分析,可以构造的时间特征如下:
(1)汽车的上线日期与汽车的注册日期之差就是汽车的使用时间,一般来说与价格成反比
(2)对汽车的使用时间进行分箱,使用了3年以下,3-7年,7-10年和10年以上,分为四个等级,10年之后就是报废车了,应该会影响价格
(3)淡旺季也会影响价格,所以可以从汽车的上线日期上提取一下淡旺季信息
汽车的使用特征
createDate-regDate,反应汽车使用时间,一般来说与价格成反比。但要注意的问题就是时间格式,regDateFalse这个字段有些是0月,如果忽略错误计算的话,使用时间有一些会是空值,当然可以考虑删除这些空值,但是因为训练集和测试集合并了,那么就不轻易删除了。
本文采取的办法是把错误字段都给他加1个月,然后计算出天数之后在加上30天(这个有不同的处理方式,但是一般不喜欢删除或者置为空,因为删除和空值都有潜在的副作用)
汽车是不是符合报废
时间特征还可以继续提取,我们假设用了10年的车作为报废车的话,那么我们可以根据使用天数计算出年数,然后根据年数构造出一个特征是不是报废。
我们还可以对used_time进行分箱,这个是根据背景估价的方法可以发现,汽车的使用时间3年,3-7年,10年以上的估价会有不同,所以分一下箱。
这样就又构造了两个时间特征。ls_scrap表示是否报废,estivalue表示使用时间的分箱。
是不是淡旺季
这个是根据汽车的上线售卖时间看,每年的2,3月份及6,7,8月份是整个汽车行业的低谷,年初和年末及9月份是二手车销售的黄金时期,所以根据上线时间选出淡旺季。
根据汽车的使用时间或者淡旺季分桶进行统计特征的构造
类别特征的构造
经过上面的分析,可以构造的类别特征如下:
1、从邮编中提取城市信息,因为是德国的数据,所以参考德国的邮编,加入先验知识,但是感觉这个没有用,可以先试一下
2、最好是从regioncode中提取出是不是华东地区,因为华东地区是二手车交易的主要地区(这个没弄出来,不知道这些编码到底指的哪跟哪)
3、私用车和商用车分开(body Type提取)
4、是不是微型车单独处理,所以感觉那些车的类型OneHot的时候有点分散了(bodyType这个提取,然后one-hot)
5、新能源车和燃油车分开(在fuelType中提取,然后进行OneHot)
6、地区编码还是有影响的,不同的地区汽车的保率不同
7、品牌这块可以提取一些统计量,统计特征的话上面这些新构造的特征其实也可以提取注意,OneHot不要太早,否则有些特征就没法提取潜在信息了。
邮编特征
从邮编中提取城市信息,因为是德国的数据,所以参考德国的邮编,加入先验知识。
私用车和商务车分开(bodyType)
新能源车和燃油车分开(fuelType)
构造统计特征
这一块依然是可以构造很多统计特征,可以根据brand,燃油类型,gearbox类型,车型等,都可以,这里只拿一个举例,其他的类似,可以封装成一个函数处理。
以gearbox构建统计特征:
当然下面就可以把bodyType和fuelType删除,因为该提取的信息也提取完了,该独热的独热。
数据特征的构造
数值特征这块,由于大部分都是匿名特征,处理起来不是太好处理,只能尝试一些加减组合和统计对里程进行一个分箱操作
一部车有效寿命30万公里,将其分为5段,每段6万公里,每段价值依序为新车价的5/15、4/15、
3/15、2/15、1/15。假设新车价12万元,已行驶7.5万公里(5年左右),那么该车估值为12万元
×(3+3+2+1)+15=7.2万元。
V系列特征的统计特征
平均值,总和和标准差
特征筛选就是在高维度、已量化的特征向量中选择对指定任务更有效的特征组合,进一步提升模型性能。
详细可见特征提升之特征提取、特征筛选
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/76705.html