
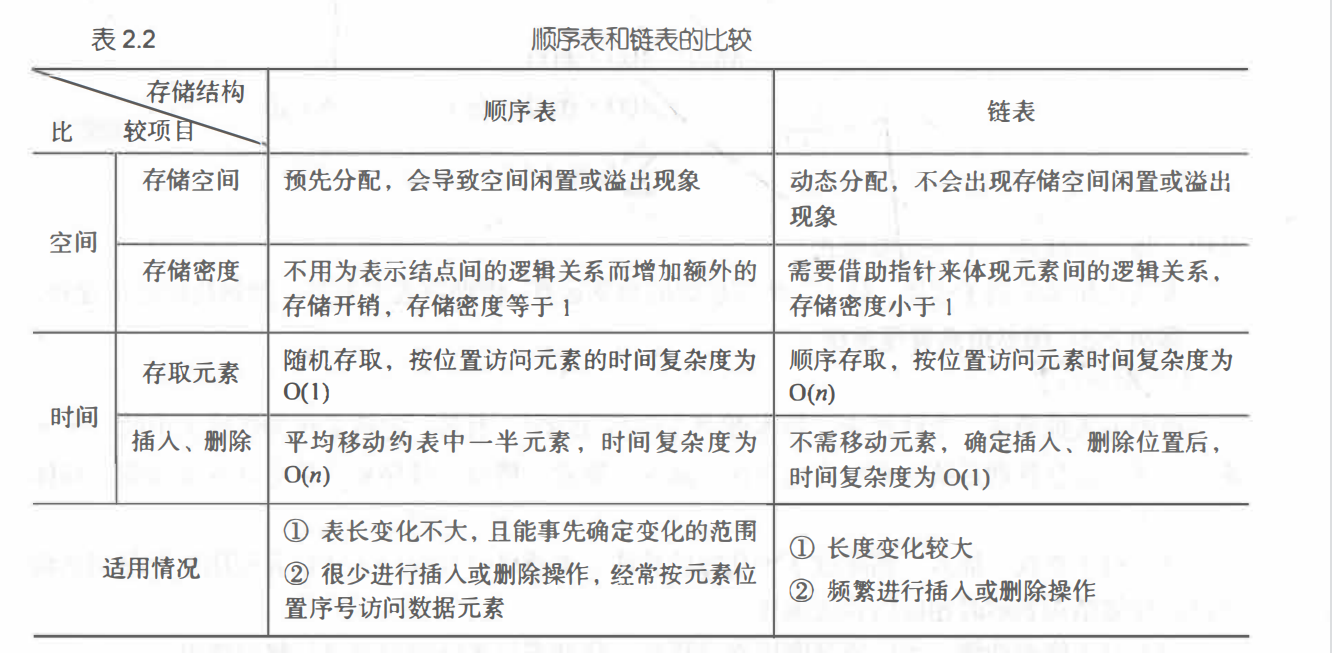
顺序表:采用顺序存储结构的线性表称为顺序表
#顺序表是线性表的顺序存储表示法,其数据元素用一段连续的地址空间,类似数组,其特点为逻辑上相邻,物理次序也是相邻的。
#假设顺序表中每个元素占用l个存储单元,并且第一个元素所占地址为存储单元的基地址,线性表中第i+1个元素的存储位置LOC(ai+1)和第i个元素的存储位置LOC(ai)有以下关系
LOC(ai+1)=LOC(ai)+l
LOC(ai+1)=LOC(a1)+(i-1)*l

Tip:①这里的SqList,相当于给该自定义结构类取了一个别名,定义该自定义类型变量时就可像这样SqList List;
2.1.2.1顺序表的初始化 int InitList(SqList *L)
算法步骤:
①为顺序表List分配一个预定义大小的数组空间,elem指向这段空间的基地址。
②分配空间成功,将当前表长设置为0(未插入数据,表长为0);
Tip:①该顺序表初始化函数所传的参数为指针类型,需创建个指针变量L指向List(上面的SqList List),再将该指针变量L传入。
②这里用if( ! (*L).elem )判断分配空间是否为空,c语言中,变量未赋值时其值是随机的。因此我们再创建变量List后,将List.elem赋值为NULL;使该判断有效。
③分配存储空间后将List.length<==>(*L).length赋值为0,当前表为空表。
2.1.2.2 顺序表的插入 int ListInsert(SqList *L,int i,ElemType e)
算法步骤:
①首先判断位置i是否合法(合法范围是1 <= i <= n+1)n为元素个数即顺序表长度。
②判断顺序表的存储空间是否已满(这里暂时不考虑扩展空间)。
③将第i个到第n个位置的元素依次向后移动一个位置。
④将要插入的元素e赋值到第i个位置。
⑤表长+1,完成插入。
Tip:①这里移动顺序标中第i到第n个元素采用的是下标表示法,elem[i-1]对应于第i个元素,这里要注意。
2.1.2.3 顺序表的取值 int GetElem(SqList List,int i,ElemType *e)
算法步骤:
①首先判断取值位置i是否合法(1<= i >=n)
②若取值位置合法,将第i个元素List.elem[i-1]赋值给e。
Tip:①这里传入的是ElemType *e,e是个指向ElemType类型变量的指针,接收该返回值即*e=List.elem[i-1]。
②想要接收第i个元素的值,就事先定义一个ElemType类型的变量e,再定义个该类型的指针变量pe指向变量e(pe>>e)。向函数传入指针变量pe即可。
2.1.2.4 顺序表的查找 int LocateElem(SqList List,ELemType e)
算法步骤:
①从第一个元素开始,依次与查找的元素e进行比较,若有e==List.elem[i],返回其位置i+1。
②未查到,查找失败。
Tip:①若所查找的元素值在顺序表中有多个,这里只返回第一个的位置(从第一个元素开始比较)。
2.1.2.5 顺序表的删除 int ListDelete(SqList *L,int i)
算法步骤:
①先判断删除位置i的合法性(1<= i <=n)。
②将第i+1个到第n个元素依次向前移动一个位置
③删除成功,表长-1。
2.1.2.6 顺序表的打印 int ListAll(SqList List)
算法步骤:
①首先判断顺序表是否为空表。
②若不为空表,从第一个元素List.elem[0]开始循环打印所有元素。
2.1.2.7 主函数的实现
2.1.2.8 结果演示
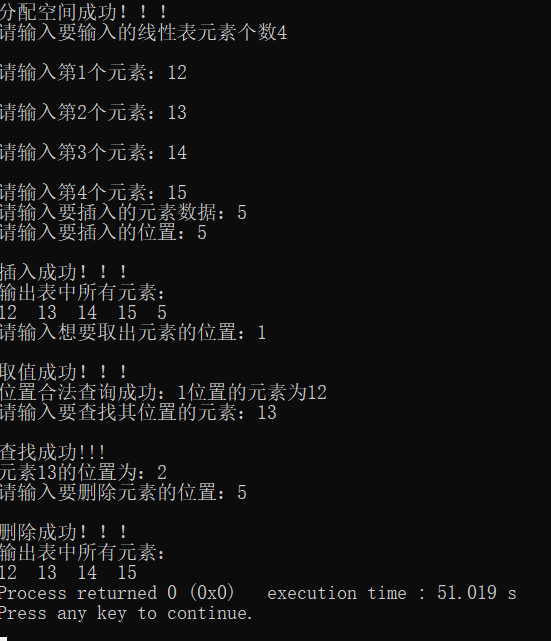
注意:本文章所有代码连起来,即可运行(当然开头导入两个头文件)。
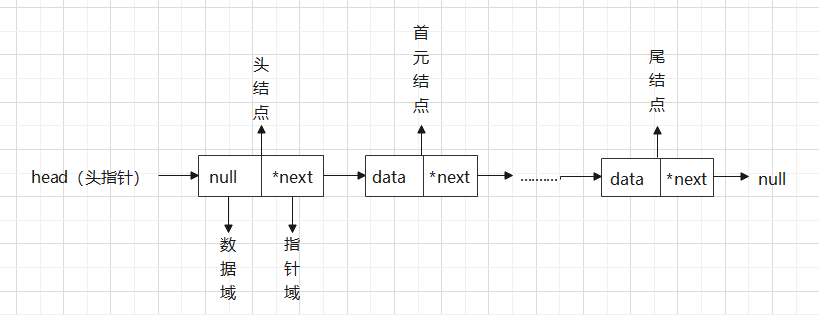
Tip:①这里最后一行LNodex相当于给自定义结构类型struct LNode取别名,后面可直接用LNode类型定义新结点。
②这里的*LinkList定义了一个指向LNodel类型的指针类型,即指向结点的指针类型,如定义LinkList L,L就是一个LNode类型的指针变量,指向结点。是一级指针。
③链表和顺序表的空间分配有些不同,顺序表是预分配,类似数组,事先分配一定大小的空间,不够可以扩大。而链表是每次给加入的结点分配内存,所以他们的内存地址并不连续。
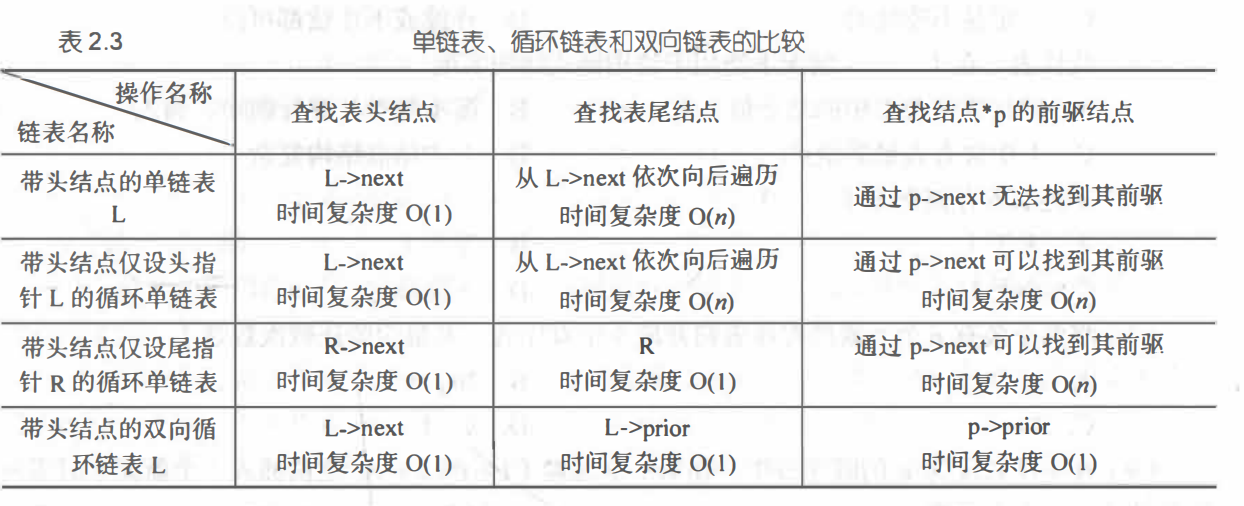
2.2.2.1 单链表的初始化 int InitList(LinkList *L)
算法步骤:①让头指针作为分配空间的基地址来分配空间给头结点。
②使头结点的指针域指向为空,即为空表。
Tip:①L为二级指针,指向一个(指向结点的)指针,这里*L为头指针,指向头结点
②(*L)代表头指针,头指针是指向头结点的,则(*L)->next代表头结点的next不熟悉的可看本文底部,pi->data和i.data的理解。
2.2.2.2 头插法创建(插入结点)单链表 int CreateListHead(LinkList *L,int n)
算法步骤:
①定义一个新结点*p给其分配空间。
②给新结点*p的数据域赋值。
③将新结点*p插入到头结点后面。
2.2.2.3 尾插法创建(插入结点)单链表 int CreateListTail(LinkList *L,int n)
算法步骤:
①定义一个新结点*p给其分配空间。
②给新结点*p的数据域赋值。
③将新结点*p插入到尾结点后面。
Tip:①头插法是将新结点插到头结点后面,结果是倒序的。
②尾插法是将新结点插到尾结点后面,结果正序。
2.2.2.4 链表的长度获取 int GetLength(LinkList *L)
算法步骤:
①在函数内用length计结点个数。
②从首元结点开始判断,若存在则length+1。
③返回length值。
Tip:①若链表为空表,则length为0。
2.2.2.5 单链表的取值 int GetElem(LinkList *L,int i,ElemType *e)
算法步骤:
①指针p指向头结点,j来计数j初始值为0(头结点对应位置0)。
②从头结点开始依次顺着指针域判断,指针域不为空则。
1.p指向下一结点。
2.计数器j+1。
3.判断j是否与i相等,相等则找到位置i的值赋值给*e。
③②无结果则i不合法。
Tip:①参数中e为指向ElemType类型变量的指针变量,所以取值结果不需返回,只需将结果赋值给*e即可。
2.2.2.6 单链表的查找 LinkList LocateElem(LinkList *L,ElemType e,int *pi)
算法步骤:
①指针p指向首元结点。
②从首元结点开始顺着指针域判断,若存且数据域不与e相同继续往下查找。
③返回p,查找成功p为该结点地址值,失败则p为null(尾结点的指针域为空)。
2.2.2.7 单链表的插入 int ListInsert(LinkList *L,int i,ElemType e)
算法步骤:
①查找结点ai-1并由p指向该结点。
②定义一个新结点*s,其数据域赋值为e。
③将新结点*s的指针域指向结点ai。
④将结点*p的指针域指向新结点*s。
Tip:①实际上就是定一个新结点将其插入到结点ai-1和结点ai之间。
2.2.2.8 单链表的删除 int ListDelete(LinkList *L,int i)
原理步骤:
①找到结点a(i-1)由指针p指向该结点。
②临时保存待删除的结点a(i)的地址于q中,以备释放资源。
③将a(i-1)结点的指针域指向a(i+1)结点。
④释放结点a(i)的空间。
Tip:①插入和删除的差异性。
2.2.2.9 单链表的清空 int ListClear(LinkList *L)
2.2.2.10 单链表的打印 void PrintfList(LinkList *L)
2.2.2.11 主函数的实现
2.2.2.12 结果演示
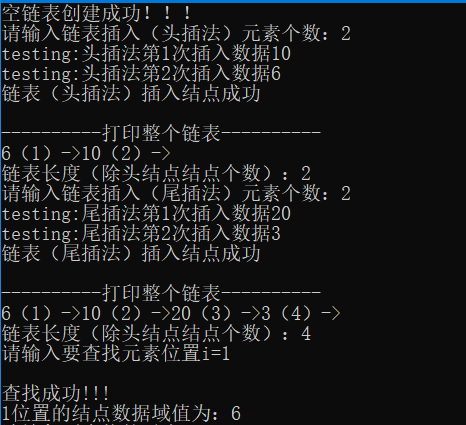
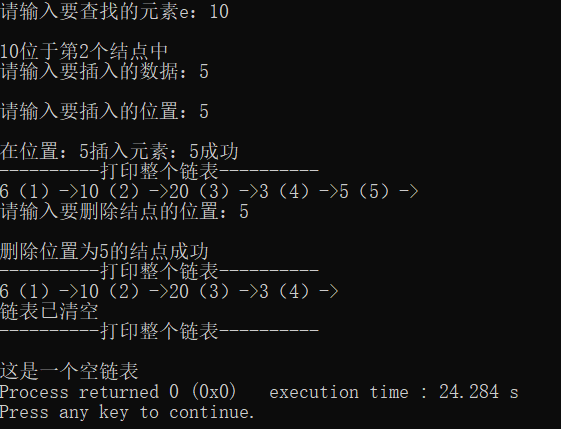
注意:代码连起来,即可运行(当然开头导入两个头文件)。

双向链表:相比单链表,其有两个指针域,一个指向直接前驱,一个指向直接后继。
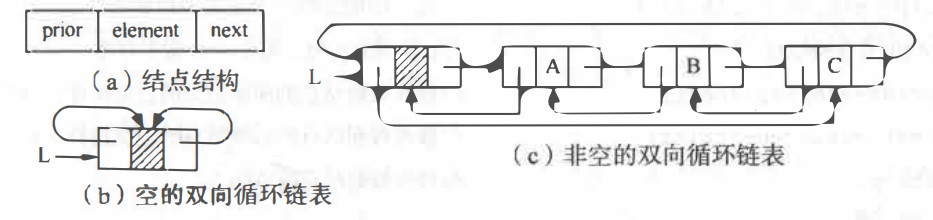
2.2.4.2.1 双向链表的初始化
Tip:①双向链表的初始化和单链表基本一致,这里将头结点的前驱指针域赋值为空,方便后面测试前驱指针域是否两两相连
2.2.4.2.2 头插法创建双向链表
这里就先讲一下双向链表的插入,单链表只需改动后继指针域next,而双向链表还要改动前驱指针域prior。
值得注意的是是否在尾结点后面插入。其操作也有所不同。
尾部插入:
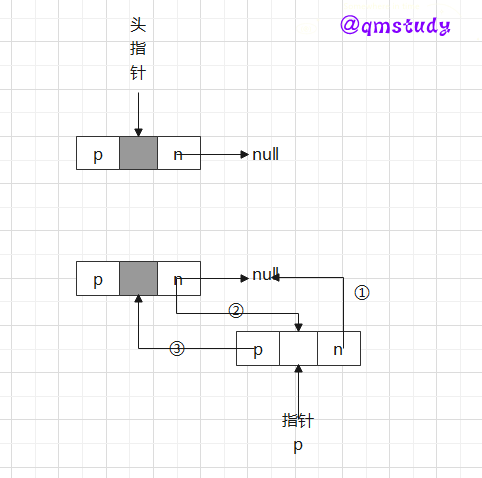
非尾部插入:
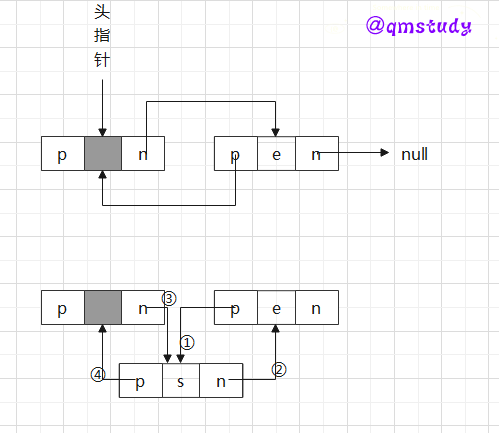
Tip:①考虑到尾部插入和非尾部插入操作有些不同,算法中进行了插入位置是否为尾部的判断。
②当然这里是头插法,只需判断是否存在首元结点即可(在头结点后插入结点)。
2.2.4.2.3 双向链表的插入
以上已经讲述插入的方法,知晓其与单链表插入的异同,还需要注意尾部和非尾部插入的情况。
Tip:①考虑到尾部插入和非尾部插入操作有些不同,算法中进行了插入位置是否为尾部的判断。
2.2.4.2.4 双向链表的删除
双向链表的删除操作和单链表不同,和插入类似,尾部结点和非尾部结点的删除情况也不同。
尾部结点删除:
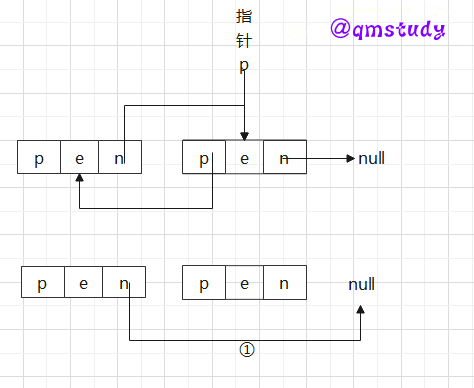
非尾部结点删除:
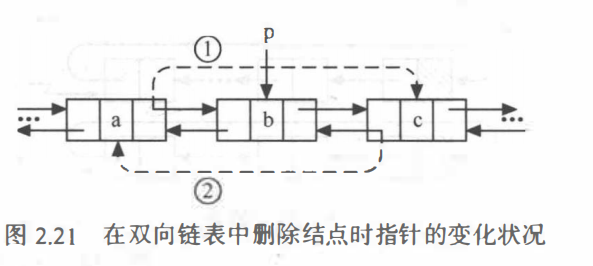
Tip:①注意区分删除尾结点和非尾结点的情况。
1.为什么单链表的插入和删除没有这种差别呢?
小明:这种差别其实是对双链表的前驱指针域操作造成的
①插入:插入一个新结点,假如是在两结点直接插入,所插入结点的直接后继结点的前驱指针域需指向所插入结点。假如是在尾部插入,所插入结点无后继(后继指针域指向为空),则不存在对后面结点的前驱指针域的操作,因为所插入结点的直接后继结点不存在。
②删除:删除一个结点,假如删除非尾部结点,所删除的结点有直接后继结点,直接后继结点的前驱指针域需指向所删除结点的直接前驱结点,假如是删除尾部结点,则所删除无直接后继结点。无对直接后继结点的前驱指针域的操作。
2.那为什么第一个结点和非第一个没有这种差别呢?
小明:小编文章讲的表都是带头结点的,第一个结点一定有一个直接前驱那就是头结点。
2.2.4.2.5 双向链表的打印
2.2.4.2.6 双向链表前驱指针域连接的判断
原理步骤:
①先找到尾结点。
②从尾结点开始顺着前驱指针域依次将每个结点的数据域的值输出。
2.2.4.2.7 主函数的实现
2.2.4.2.8 结果演示
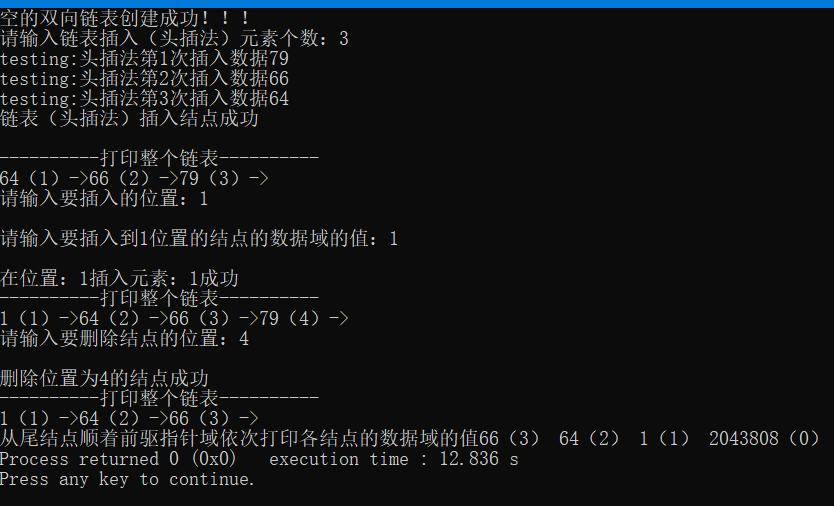
注意:代码连起来,即可运行(当然开头导入两个头文件)。
求解一般集合的并集
已知集合A={0,6,1,2},集合B={0,7,2,1},求集合A,B的并集,易得他们的并集{0,6,1,2,7},下面通过运用线性表来进行操作。
算法步骤:
①我们可以创建两个顺序表LA,LB,
②把集合A的成员插入表LA中,集合B的成员插入表LB中。
③从表LB第一个元素开始,每次与表LA所有元素进行比较。
④如果无相同的元素,则将其元素值赋值到LA中,否则不操作----这里可用查找函(LocateElem)数进行判断。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/8114.html