
注:以下代码均在Jupyter中运行的。
基本功能列表

import pandas as pd 导入库

df = pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
创建一个DataFrame
| 代码 | 功能 |
| DataFrame() | 创建一个DataFrame对象 |
| df.values | 返回ndarray类型的对象 |
| df.iloc[ 行序,列序 ] | 按序值返回元素 |
| df.loc[ 行索引,列索引 ] | 按索引返回元素 |
| df.index | 获取行索引 |
| df.columns | 获取列索引 |
| df.axes | 获取行及列索引 |
| df.T | 行与列对调 |
| df. info() | 打印DataFrame对象的信息 |
| df.head(i) | 显示前 i 行数据 |
| df.tail(i) | 显示后 i 行数据 |
| df.describe() | 查看数据按列的统计信息 |
创建一个DataFrame
DataFrame()函数的参数index的值相当于行索引,若不手动赋值,将默认从0开始分配。columns的值相当于列索引,若不手动赋值,也将默认从0开始分配。
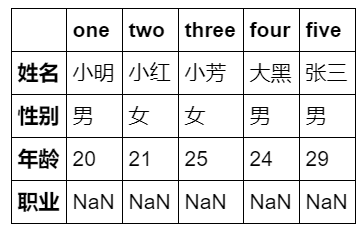
data = {
'性别':['男','女','女','男','男'],
'姓名':['小明','小红','小芳','大黑','张三'],
'年龄':[20,21,25,24,29]}
df = pd.DataFrame(data,index=['one','two','three','four','five'],
columns=['姓名','性别','年龄','职业'])
df运行结果:
df.values 返回ndarray类型的对象
ndarray类型即numpy的 N 维数组对象,通常将DataFrame类型的数据转换为ndarray类型的比较方便操作。如对DataFrame类型进行切片操作需要df.iloc[ : , 1:3]这种形式,对数组类型直接X[ : , 1:3]即可。
X = df.values
print(type(X)) #显示数据类型
X运行结果:
[['小明' '男' 20 nan]
['小红' '女' 21 nan]
['小芳' '女' 25 nan]
['大黑' '男' 24 nan]
['张三' '男' 29 nan]]df.iloc[ 行序,列序 ] 按序值返回元素
df.iloc[1,1]运行结果:
Index(['one', 'two', 'three', 'four', 'five'], dtype='object')df.loc[ 行索引,列索引 ] 按索引返回元素
df.loc['one','性别']运行结果:
男df.index 获取行索引
df.index运行结果:
Index(['one', 'two', 'three', 'four', 'five'], dtype='object')df.columns 获取列索引
df.columns运行结果:
Index(['姓名', '性别', '年龄', '职业'], dtype='object')df.axes 获取行及列索引
df.axes运行结果:
[Index(['one', 'two', 'three', 'four', 'five'], dtype='object'),
Index(['姓名', '性别', '年龄', '职业'], dtype='object')]df.T index 与 columns 对调
df.T运行结果:
df.info() 打印DataFrame对象的信息
df.info()运行结果:
Index: 5 entries, one to five
Data columns (total 4 columns):
姓名 5 non-null object
性别 5 non-null object
年龄 5 non-null int64
职业 0 non-null object
dtypes: int64(1), object(3)
memory usage: 200.0+ bytesdf.head(i) 显示前 i 行数据
df.head(2)运行结果:
若想要显示前几列数据,可用df.T.head(i)
df.tail(i) 显示后 i 行数据
df.tail(2)运行结果:
df.describe() 查看数据按列的统计信息
可显示数据的数量、缺失值、最小最大数、平均值、分位数等信息
年龄
count 5.000000
mean 23.800000
std 3.563706
min 20.000000
25% 21.000000
50% 24.000000
75% 25.000000
max 29.000000
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/hz/121302.html