在使用Elasticsearch进行全文搜索的时候,默认是使用BM25计算的_score字段进行降序排序的。当我们需要用其他字段进行降序或者升序排序的时候,可以使用sort字段,传入我们想要的排序字段和方式。 当简单的使用几个字段升降序排列组合无法满足我们的需求的时候,我们就需要自定义排序的特性,Elasticsearch提供了function_score的DSL来自定义打分,这样就可以根据自定义的_score来进行排序。
1.第一个例子
首先新建一个索引test_ratings。
{
"test_ratings_v1" : {
"aliases" : {
"test_ratings" : { }
},
"mappings" : {
"doc" : {
"properties" : {
"comment" : {
"type" : "text",
"analyzer" : "ik_smart"
},
"create" : {
"type" : "date"
},
"id" : {
"type" : "integer"
},
"productId" : {
"type" : "integer"
},
"rating" : {
"type" : "integer"
},
"test" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"title" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"userId" : {
"type" : "integer"
}
}
}
},
"settings" : {
"index" : {
"refresh_interval" : "1s",
"number_of_shards" : "3",
"provided_name" : "test_ratings_v1",
"max_result_window" : "10000000",
"creation_date" : "1569227588095",
"number_of_replicas" : "0",
"uuid" : "cx7XVhITQnaBlqKtauZZow",
"version" : {
"created" : "6080199"
}
}
}
}
}
然后导入一些数据,一个基本的请求如下所示:
- function_score包裹的query内的DSL,就像我们平常使用的查询条件一样使用。
- field_value_factor表示query查询计算的_score再乘以rating字段的值
- missing 表示如果rating的值确实,用1作为默认值 用这样的请求,我们可以找出那些评论标题中带有喜欢,而且评分也很高的评论,最终 _score = _score * rating(default=1)
GET /test_ratings/_search
{
"query": {
"function_score": {
"query": {"match": {
"title": "喜欢"
}},
"field_value_factor": {
"field": "rating",
"missing": 1
}
}}
}
2.field_value_factor
上面的例子中已经简单的介绍了field_value_factor的作用了,现在再来看看field_value_factor内的一些参数
2.1 field
相乘的字段,该字段必须是数字类型。
2.2 factor
相乘的系数,可以自己调节相乘的系数
2.3 missing
定义字段缺省值
2.4 modifier
修正相乘值 有时候将字段值,直接和_score相乘效果不好,需要修正字段值,可选的值有:
| 选项 | 含义 |
|---|---|
| none | 默认值 |
| log | log(x) |
| log1p | log(1+x) |
| log2p | log(2+x) |
| ln | ln(x) |
| ln1p | ln(1+x) |
| ln2p | ln(2+x) |
| square | x^x |
| sqrt | x的平方根 |
| reciprocal | x的倒数 |
| 当factor和modifier同时使用的时候,factor优先于modifier | |
| 以log为例,最终分数会变为 _score = _score * log(factor * x) | |
| 当我们觉得评分0分和1分的区别大于4分和5分的区别的时候,就可以使用log来修正_score。 | |
| “` | |
| GET /test_ratings/_search | |
| { | |
| “query”: { |
"function_score": {
"query": {"match": {
"title": "喜欢"
}},
"field_value_factor": {
"field": "rating",
"missing": 0,
"modifier": "log1p"
}
}} }
当默认值为0的时候,使用log会报错,因此可以使用log1p来修正。
# 3.script_score
当我们使用field_value_factor和functions内简单的weight无法满足业务的时候,可以使用Elasticsearch提供的Painless脚本来自定义排序函数。
painless语法参考:[https://www.elastic.co/guide/en/elasticsearch/painless/6.8/painless-examples.html](https://www.elastic.co/guide/en/elasticsearch/painless/6.8/painless-examples.html)
一个简单的用法如下:
GET /test_ratings/_search { “query”: {“function_score”: { “query”: {“match”: { “title”: “喜欢” }}, “boost_mode”: “replace”, “script_score”: { “script”:{ “params”: { “a”:1, “b”:2 }, “source”: “_score + params.b * doc[‘rating’].value” } } }} }
## 3.1 params
自定义参数
## 3.2 source
指定脚本,可以使用doc['f']的方式访问原始字段值,也可以用_score访问计算后的score值
# 4.random_score
使用random_score可以让不同的人请求得到不同的排序结果,而同一个人请求可以得到相同的结果,使用如下:
GET /test_ratings/_search { “query”: {“function_score”: { “query”: {“match”: { “title”: “喜欢” }},
"random_score": {
"seed": 1,
"field": "userId"
},
"boost_mode": "replace"
}} }
## 4.1 seed
指定随机的种子,相同的种子返回相同排序,每个种子会为每个文档生成一个0-1的随机数,改随机数就是random_score的返回值,可以和其他filter或者外部打分一起使用。
## 4.2 field
对于相同shard的相同field的值,产生的随机数一样,因此在使用的时候,尽量选择值不一样的field。
# 5.functions
上面的例子中,每一个doc都会乘以相同的系数,有时候我们需要对不同的doc采用不同的权重。这时,使用functions是一种不错的选择。基本的用法如下:
GET /test_ratings/_search { “query”: { “function_score”: { “query”: { “match”: { “title”: “喜欢” } }, “functions”: [{ “filter”: { “term”: { “userId”: 209983 } }, “weight”: 5 }, { “filter”: { “term”: { “rating”: 5 } }, “weight”: 2 } ], “boost”: 2, “score_mode”: “max”, “boost_mode”: “multiply”, “min_score”: 18, “max_boost”: 4 } } }
## 5.1 filter
表示每一个不同分值的过滤器。
## 5.2 weight
表示对应的权重
上诉例子表示:对搜索召回的结果,userid=209983的doc,weight为5,rating=5的doc的weight为2
## 5.3 functions内其他内部参数
functions内支持script_score和field_value_factor等参数
# 6. function_score其他外部参数
还是以4中的例子来分析其他的外层参数
## 6.1 score_mode
表示functions内的每一项的计算方式,可选的计算方式有:
| 选项 | 含义 | | :-------- | --------:|
|multiply |functions内每一项weight相乘| |sum |functions内每一项weight相加|
|avg |functions内的weight求平均值| |first |functions内的第一个weight值|
|max |functions内的最大weight| |min |functions内的最小min|
## 6.2 max_boost
对functions计算的score的限制,表示functions返回的最值。适用field_value_factor等其他场景
## 6.3 boost
对functions计算出来的结果,再做相乘的系数。适用field_value_factor等其他场景
## 6.4 boost_mode
对boost和functions结果的乘积 和原始_score之间的计算方式。适用field_value_factor等其他场景,可选值为:
| 选项 | 含义 | | :-------- | --------:|
|multiply |结果和原始_score相乘| |replace |用计算结果替换原始_score |
|sum |结果和原始_score相加 | |avg |结果和原始_score求平均值 |
|max |求结果和原始_score最大值 | |min |求结果和原始_score最小值 |
## 6.5 min_score
限制最后召回的最低得分
## 6.6 weight
在外部也可以用weight,对每个文档乘一个系数。
# 7.衰减函数
有些时候我们需要某个字段等于一个特定值时分数最高,然后往两边或者一边递减,比如地理位置或者价格区间。这个时候可以使用衰减函数。基本使用如下:
{ “query”: { “function_score”: { “query”: { “match”: { “title”: “喜欢” } }, “gauss”: { “rating”: { “origin”: “2”, “offset”: “1”, “scale”: “0.5”, “decay”: “0.5” } }, “boost_mode”: “replace” } } }
其中rating是field名,gauss是衰减函数名
## 7.1 fiend内部参数
| 选项 | 含义 | | :-------- | --------:|
|origin |最佳值的位置,这个位置的score为1| |offset |最佳值两边的范围,在(origin-offset, origin+offset)范围内都是最大score:1|
|scale |衰减距离,从offset再往外scale衰减到指定decay值| |decay |指定的衰减值,到达scal的距离,衰减到decay|
## 7.2 衰减函数
目前支持三种衰减函数:gauss、exp、linear
衰减函数和参数见下图,参考[https://www.elastic.co/guide/en/elasticsearch/reference/6.8/query-dsl-function-score-query.html#function-random](https://www.elastic.co/guide/en/elasticsearch/reference/6.8/query-dsl-function-score-query.html#function-random)
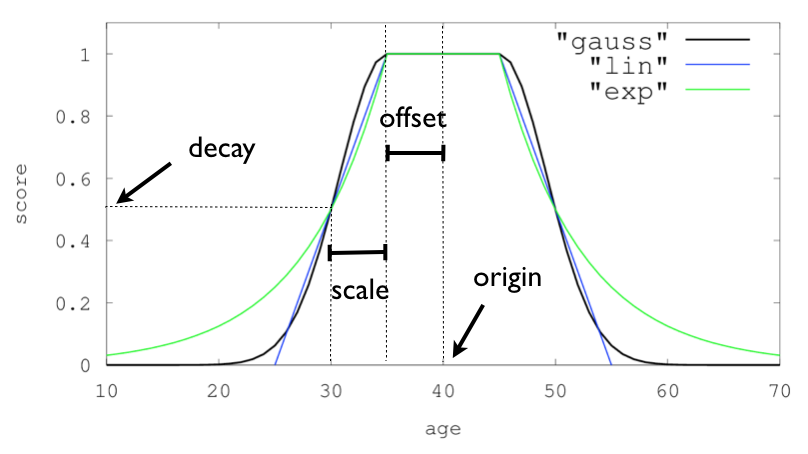
## 7.3 multi-values fields
在计算field的值到origin的距离时,如果field是一个多值的字段,则可以通multi_value_mode字段,来设置参与距离计算的值,可选值为:
| 选项 | 含义 | | :-------- | --------:|
|min |field内到origin的最小距离| |max |field内到origin的最大距离|
|avg |field内数组到origin的平均距离| |sum |field内数组到origin的距离之和|
# 8.总结
利用Elasticsearch的function_score功能,可以灵活的对搜索结果进行排序。但是在使用过程中尽量少使用script_score,script_score性能会有一些影响。
更多精彩内容,请关注公众号

今天的文章Elasticsearch function_score使用分享到此就结束了,感谢您的阅读。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/16184.html