
今天开心的玩游戏,突然发来通知,增加了一门课程,打开一看,噢,原来是雨课堂
其实,本来通过多开挂机的方式,完成了大部分的课程了,但是,还是想探究一下,这个原理,于是乎,留了几节课,用来实验。
为什么要这么玩呢,因为很久之前(非本次),某网站的长达几个小时的视频,通过python伪造请求,可以做到10s看完,非常有意思
这个网站的视频逻辑是不断发包请求
但是每个包的请求的视频点,不得超过太长时间,否则失效。以下为破解代码
import requests
import random
import time
import math
courseId = "****"
videoId = "****"
longtime = 1000
viewUUID = "****"
cs = {
"_fecdn_":"1",
"gr_user_id":"****",
"****_gr_session_id":"****",
"grwng_uid":"****",
"****":"true",
"UniqueKey":"****",
"lebanban_auth":"****",
"fb_auth":"****",
"****_gr_last_sent_sid_with_cs1":"****",
"****_gr_last_sent_cs1":"****",
"****_gr_cs1":"****",
"JSESSIONID":"****"
}
hs = {
"Host":"www.****.com",
"Connection":"keep-alive",
"Accept":"application/json, text/javascript, */*; q=0.01",
"X-Requested-With":"XMLHttpRequest",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4139.0 Safari/537.36 Edg/84.0.516.1",
"Content-Type":"application/x-www-form-urlencoded",
"Origin":"https://www.****.com",
"Sec-Fetch-Site":"same-origin",
"Sec-Fetch-Mode":"cors",
"Sec-Fetch-Dest":"empty",
"Referer":"https://www.****.com/course/introduction/"+courseId+".shtml",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
}
monitor = {
"courseId":courseId,
"videoId" : videoId,
"resourceType":"0",
"currentSec":0,
"viewUUID":viewUUID,
"bufferTime":0
}
end = math.floor(longtime * 60)
for c in range(1,end+5,5):
tranceId = (str(time.time()*1000)[:13]+str(random.randint(10,99)))[-11:];
monitor["currentSec"] = c
monitor["bufferTime"] = random.randint(1,99)
url = "https://www.****.com/learn/common/playstatistics.json?traceId=" + tranceId
rsp = requests.post(url,headers=hs,cookies=cs,params=monitor)
print(rsp.text)
回归正题,一起来了解一下雨课堂的情况。
反手就是打开 fiddler,点开课程抓包看看情况。
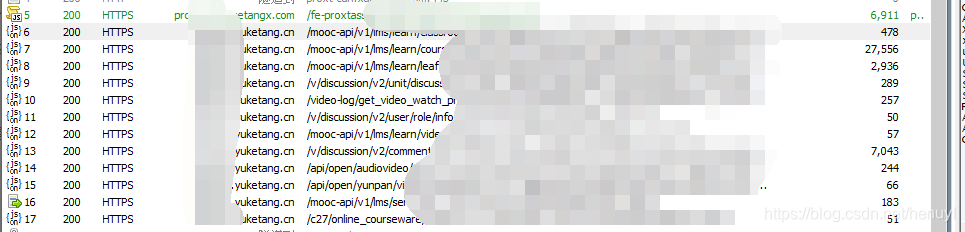
(远不止这些包)
每次请求,和得到的回包,都用notepad++记录一下,以便于之后,通过请求获取具体的课堂信息等
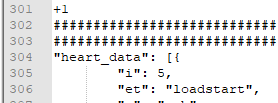 除了分析了300多行,想了解一下,每个包的目的等。
除了分析了300多行,想了解一下,每个包的目的等。
首先,我先教大家使用notepad++里面,好用的js和json的格式自动排版工具
JSTool和JSON Viewer。。。。。JSON Viewer可以一键将json格式化
至于JSTool,好羞愧啊,刚开始,有些参数没有弄明白,我直接去后台扒JS看了,emmmmmm,乱七八糟的(混淆了),放弃了。
接下来,我将具体说明每个请求和每个包的作用(*为手动马赛克)
先放上感觉没有用的包。
#获取学校信息(暂时没啥作用,因为返回来的包,没什么有价值的东西)
GET https://****.yuketang.cn/edu_admin/get_custom_university_info/?current=1
GET https://****.yuketang.cn/edu_admin/get_custom_university_info/?host_name=****.yuketang.cn&no_loading=true&term=latest&uv_id=0000
#导出列表(暂时没用)
GET https://****.yuketang.cn/edu_admin/display_data_dashboard/export_list/?no_loading=true&page_size=10&page=1
#回包
{"msg": "", "data": {"exporting_count": 0, "page_size": 0, "task_list": []}, "success": true}
回包含有我需要的参数的包。
# 获取课堂信息
GET https://****.yuketang.cn/mooc-api/v1/lms/learn/classroom_info/?classroom_id=****&sign=****&term=latest&uv_id=****
# 回包
{
"msg": "",
"data": {
"notice": false,
"end": 1611000000000.0, #课堂的结束时间(已随机修改)
"name": "***",
"start": 1604000000000.0,#课堂的开始时间(已随机修改)
"course_name": "***",
"is_class_end": false,
"teacher": {
"picture": "***",
"name": "***"
}
},
"success": true
}# 获取该课堂的章节
GET https://****.yuketang.cn/mooc-api/v1/lms/learn/course/chapter?cid=****&sign=****&term=latest&uv_id=**** HTTP/1.1
# 部分回包
"section_leaf_list": [{
"order": 0,
"leaf_list": [{
"name": "Video",
"is_locked": false,
"start_time": ****, # 开始时间
"chapter_id": ****, # 章节id
"section_id": ****, # 部分id(参数可能有用)
"leaf_type": 0,
"id": ****, #(参数可能有用)
"is_show": true,
"end_time": 0,
"score_deadline": 0,
"is_score": true,
"is_assessed": false,
"order": 0,
"leafinfo_id": **** #叶子id (参数可能有用)
}],
"chapter_id": ****,
"id": ****,
"name": "章节名称"
}下面这个包,几乎包含了所有的信息,大概如下
# 通过课堂名,章节名,还有sign还有university_id,获取信息
GET https://****.yuketang.cn/mooc-api/v1/lms/learn/leaf_info/****/****/?sign=****&term=latest&uv_id=****
# 回包
{
"msg": "",
"data": {
"sku_id": ****, # sku_id有用
"is_deleted": false,
"name": "Video",
"content_info": {
"status": "post",
"expand_discuss": false,
"score_evaluation": {
"score_proportion": {
"proportion": 0.5
},
"score": 1.0,
"id": 6,
"name": "****"
},
"download": [],
"is_score": true,
"is_discuss": true,
"remark": {
"remark": ""
},
"cover_desc": "",
"cover_thumbnail": "https://qn-next.xuetangx.com/****.jpg?imageView2/0/h/500",
"media": {
"lecturer": 0,
"ccid": "****",
"start_time": 0,
"cover": "https://qn-next.xuetangx.com/****.jpg",
"ccurl": "****",
"duration": 0000,
"end_time": 0,
"live_palyback_url": "",
"live_url": "",
"type": "video",
"teacher": []
},
"cover": "https://qn-next.xuetangx.com/****.jpg",
"leaf_type_id": null,
"context": "<!DOCTYPE html><html><head></head><body>\n</body></html>"
},
"classroom_id": "****",# classroom_id有用
"locked_reason": null,
"user_role": 3,
"leaf_type": 0,
"id": ****,
"has_classend": false,
"university_id": ****,# university_id有用
"be_in_force": false,
"score_deadline": 0,
"course_id": ****,# course_id有用
"user_id": ****,# user_id有用
"is_score": true,
"teacher": {
"org_name": "****",
"picture": "****",
"name": "****",
"department_name": "****",
"intro": "****",
"job_title": "****"
},
"is_assessed": false
},
"success": true
}# 获取user基本信息
GET https://****.yuketang.cn/edu_admin/get_user_basic_info/?term=latest&uv_id=****
# 回包
{
"msg": "",
"login_status": true,
"data": {
"school_new_name": "https://qn-next.xuetangx.com/****.png",
"year_terms": [
{
"year_name": "2020-2021学年",
"terms": [
{
"name": "第一学期",
"value": "202001"
}
]
}
],
"is_email_user": false,
"school_id": ****,
"is_assistant_teacher": false,
"all_year_terms": [
{
"year_name": "2020-2021学年",
"terms": [
{
"name": "第一学期",
"value": "202001"
}
]
}
],
"is_only_read": false,
"current_year_term": "202001",
"user_number": "****",
"platform_id": 3,
"school_color_list": [
"",
""
],
"is_fake": false,
"school_official_website": "http://www.tsinghua.edu.cn/publish/newthu/index.html",
"user_info": {
"user_id": ****,
"avatar": "****",
"name": "****"
},
"permissions": [],
"is_auditor": false,
"department_id": ****,
"school_icon": "https://qn-next.xuetangx.com/****.png",
"school_evaluation": false,
"school_name": "****",
"user_role": 3,
"is_edu_support": false,
"session_id": "****",
"department_name": "****",
"school_type": 1,
"school_new_logo": "https://qn-next.xuetangx.com/****.png"
},
"success": true
}这里自动跳过了暂时无用包
# 获取视频的观看进度
GET https://****.yuketang.cn/video-log/get_video_watch_progress/?cid=****&user_id=****&classroom_id=****&video_type=video&vtype=rate&video_id=****&snapshot=1&term=latest&uv_id=****
#
{
"****": {
"last_point": ****, # 最近的一次
"completed": 0,
"first_point": ****,
"video_length": ****,# 视频长度
"rate": ****
},
"message": null,
"code": 0,
"data": {
"****": {
"last_point": ****,
"completed": 0,
"first_point": ****,
"video_length": ****,
"rate": ****
}
}
}
这里提一下,可以利用爬虫来获取讨论区的内容并筛选
讨论区也是学生的作业,每个人必须要评论,可以通过爬虫获取,分析,重组评论,直接发包评论(有想法,没有去实现)
# 获取评论区
GET https://****.yuketang.cn/v/discussion/v2/comment/list/****/?_date=****&term=latest&offset=0&limit=10&web=web
# 回包
{
"msg": "",
"data": {
"good_comment_list": {
"count": 0,
"previous": null,
"results": [],
"next": null
},
"new_comment_list": {
"count": 64,
"previous": null,
"results": [
{
"to_user": ****,
"liked": 0,
"user_id": ****,
"is_essence": 0,
"replys": [],
"deleted": false,
"topic": ****,
"classroom_id": ****,
"ids": [
****,
],
"commented": 0,
"content": {
"text": "****",
"upload_images": []
},
"user_info": {
"user_id": ****,
"name": "****",
"school_number": "****",
"role": 5,
"avatar": "https://qn-next.xuetangx.com/****?imageView2/1/w/100/h/100",
"nickname": "****"
},
"is_top": 0,
"create_time": ****,
"score_status": 0,
"is_self": 0,
"is_praise": 0,
"score": 0,
"id": ****
},视频都在这个包,可以通过视频源地址下载(我不清楚网站有没有提供下载地址,没了解)
# 获取某视频的URL
https://****.yuketang.cn/api/open/audiovideo/playurl?_date=****&term=latest&video_id=****&provider=cc&file_type=1&is_single=0
# 回包
!!!!大家看到wsSecret了吗,从这里可以获取,其他地方好像也可以,我记不清了
{
"msg": "",
"data": {
"playurl": {
"sources": {
"quality20": [
"https://ws.cdn.xuetangx.com/****-20.mp4?wsSecret=****&wsTime=****"
], # 一个是高清的,一个是标清的,两个视频的地址
"quality10": [
"https://ws.cdn.xuetangx.com/****-10.mp4?wsSecret=****&wsTime=****"
]
},
"group": "chinanetcenter"
}
},
"success": true
}#大家都知道, 字幕是另外加的,通过这个请求,可获得所有字幕
https://****.yuketang.cn/mooc-api/v1/lms/service/subtitle_parse/?c_d=****&lg=0 # 下面是视频观看时发送的心跳包(!很重要,模拟观看用)
{
"heart_data": [{
"i": 5,
"et": "loadstart",
"p": "web",
"n": "ws",
"lob": "cloud4",
"cp": 0,
"fp": 0,
"tp": 0,
"sp": 1,
"ts": "****",
"u": ****,
"uip": "",
"c": ****,
"v": ****,
"skuid": ****,
"classroomid": "****",
"cc": "****",
"d": 0,
"pg": "****",
"sq": 1,
"t": "video"
}, {
"i": 5,
"et": "seeking",
"p": "web",
"n": "ws",
"lob": "cloud4",
"cp": ****,
"fp": 0,
"tp": ****,
"sp": 1,
"ts": "****",
"u": ****,
"uip": "",
"c": ****,
"v": ****,
"skuid": ****,
"classroomid": "****",
"cc": "****",
"d": ****,
"pg": "****",
"sq": 2,
"t": "video"
}, {
"i": 5,
"et": "loadeddata",
"p": "web",
"n": "ws",
"lob": "cloud4",
"cp": ****,
"fp": 0,
"tp": ****,
"sp": 1,
"ts": "****",
"u": ****,
"uip": "",
"c": ****,
"v": ****,
"skuid": ****,
"classroomid": "****",
"cc": "****",
"d": ****,
"pg": "****",
"sq": 3,
"t": "video"
}, {
"i": 5,
"et": "playing",
"p": "web",
"n": "ws",
"lob": "cloud4",
"cp": 70,
"fp": 0,
"tp": 70,
"sp": 1,
"ts": "****",
"u": ****,
"uip": "",
"c": ****,
"v": ****,
"skuid": ****,
"classroomid": "****",
"cc": "****",
"d": ****,
"pg": "****",
"sq": 5,
"t": "video"
}, {
"i": 5,
"et": "pause",
"p": "web",
"n": "ws",
"lob": "cloud4",
"cp": ****,
"fp": 0,
"tp": 70,
"sp": 1,
"ts": "****",
"u": ****,
"uip": "",
"c": ****,
"v": ****,
"skuid": ****,
"classroomid": "****",
"cc": "****",
"d": ****,
"pg": "****",
"sq": 6,
"t": "video"
}]
}还有许多包,这里就不赘述了。
既然大概的发包情况都了解了,那么,开始写代码吧,先把全局变量安排好
import requests
import random
import time
import math
import json
####################
csrftoken = "0"
sessionid = "0"
video_id = "0"
classroom_id = "0"
sign = "0"
university_id = "0"
####################
nowDate = str(int(time.time() * 1000)) # 跳动时间
theDate = str(int(time.time() * 1000)) # 全局时间
course_id = "123" # cid
user_id = "123" # user_id
sku_id = "" # sku_id
cc_id = "" # ccid
wsSecret = "" # wsSecret
####################
last_point = 0
first_point = ""
video_length = ""
heart_beat_time = 1
####################接下来,构造请求头,cookies等json包
headers = {
"Host" : "0",
"Connection" : "keep-alive",
"Accept" : "application/json, text/plain, */*",
"X-CSRFToken" : csrftoken,
"xtbz" : "cloud",
"university-id" : university_id,
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"Sec-Fetch-Site" : "same-origin",
"Sec-Fetch-Mode" : "cors",
"Sec-Fetch-Dest" : "empty",
"Referer" : "https://0/pro/lms/" + sign + "/" + classroom_id + "/video/" + video_id,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9"
}
heart_headers = {
"Host": "0.yuketang.cn",
"Connection": "keep-alive",
"Content-Length": "881",
"Accept": "*/*",
"X-CSRFToken": csrftoken,
"X-Requested-With": "XMLHttpRequest",
"xtbz": "cloud",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"Content-Type": "application/json",
"Origin": "https://0.yuketang.cn",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "https://0.yuketang.cn/pro/lms/" + sign + "/" + classroom_id + "/video/" + video_id,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9"
}
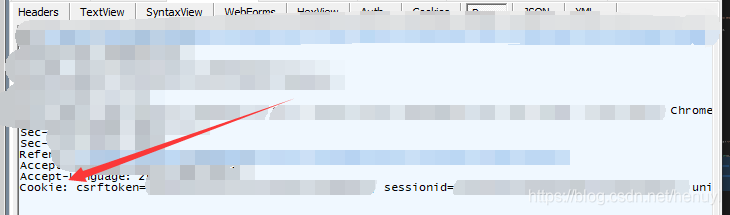
cookies = {
"csrftoken" : csrftoken,
"sessionid" : sessionid,
"university_id" : university_id,
"platform_id" : "3"
}
get_video_watch_progress = {
"cid" : course_id,
"user_id" : user_id,
"classroom_id": classroom_id,
"video_type" : "video",
"vtype" : "rate",
"video_id" : video_id,
"snapshot" : "1",
"term" : "latest",
"uv_id" : university_id
}
leaf_info = {
"sign" : sign,
"term" : "latest",
"uv_id" : university_id
}
heart_beat = {
"heart_data": [ # 自行构造,此为删减
{
"i": 5,
"et": "heartbeat",
"p": "web",
"n": "ws",
"lob": "cloud4",
"cp": str(int(float(last_point))+ heart_beat_time * 5),
"fp": 0,
"tp": last_point,
"sp": 1,
"ts": nowDate,
"u": user_id,
"uip": "",
"c": course_id,
"v": video_id,
"skuid": sku_id,
"classroomid": classroom_id,
"cc": cc_id,
"d": video_length,
"pg": "****",
"sq": heart_beat_time,
"t": "video"
}
]
}接下来,通过GET https://0.yuketang.cn/mooc-api/v1/lms/learn/leaf_info/这个
def getInfor():# 获取信息
url = "https://0.yuketang.cn/mooc-api/v1/lms/learn/leaf_info/" + classroom_id + "/" + video_id + "/"
rsp = requests.get(url,headers = headers, cookies = cookies, params = leaf_info)
jRes = json.loads(rsp.text)
course_id = jRes["data"]["course_id"]
user_id = jRes["data"]["user_id"]
sku_id = jRes["data"]["sku_id"]
cc_id = jRes["data"]["content_info"]["media"]["ccid"]
print("详细信息查询" + str(course_id) + " : " + str(user_id) + " : " + str(sku_id) + " : " + str(cc_id))通过模拟
def getClass():
global heart_beat_time
for i in range(10):
url = "https://0.yuketang.cn/video-log/get_video_watch_progress/"
rsp = requests.get(url,headers = headers, cookies = cookies, params = get_video_watch_progress)
jRes = json.loads(rsp.text)
last_point = jRes[video_id]["last_point"]
first_point = jRes[video_id]["first_point"]
video_length = jRes[video_id]["video_length"]
print("第 " + str(heart_beat_time) + " 次视频进度查询" + str(last_point) + " : " + str(first_point) + " : " + str(video_length))
nowDate = str(int(time.time() * 1000)) # 跳动时间
url = "https://0.yuketang.cn/video-log/heartbeat/ "
heart_beat["heart_data"][0]["ts"] = nowDate
rsp = requests.post(url,headers = heart_headers, cookies = cookies, params = heart_beat)
print("第 " + str(heart_beat_time) + " 次心脏:" + rsp.text)
heart_beat_time += 1
sleep(000000000000000000000000000000)===============================================================
===============================================================
cookies等怎么获取呢
如果大家想了解更多这种原理等, 可以看看之前的cf活动领取器,通过抓包发包进行操作,超级方便。
还记得逆战当初出活动(貌似是爱丽丝)翻车了,通过穷举,获取红包,白嫖了好几百块的东西,233333333
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/107277.html