
最近接到公司任务,应客户要求要做ofd格式文件的电票识别。刚接到任务的时候我对于ofd格式文件知道的少之甚少。之前只是听到同事提起过这样的一种格式。在我当时的认知里就单纯的知道他是"中国版的PDF"。对于他的底层实现和用途一无所知。所以我接到任务的时候就着手规划解决流程。
- 先了解ofd底层实现,解析构造文件
- 熟悉构造文件的实现原理,根据文件特性提取数据
- 结构化数据,并根据数据特点重构造。
1、ofd文件特性
简短的说一下ofd文件吧,想详细了解的建议去看一下电子文件存储与交换板式文档。需要的可以私信我。
OFD格式是我国自主可控的电子文件版式文档格式。我有时候会跟别人解释国产PDF。
在OFD格式产生之前,电子文件存档格式并没有统一的国家或行业标准,档案工作中普遍采用DOC、WPS、PPTX等流式文件格式。内容易更改、转移过程存在安全隐患,并不符合电子文件长期保存要求。
一些格式依赖非自主可控技术,使用和服务都受限于外部厂商和技术,存在安全隐患。格式标准不公开,私有版式文档的格式解析、标准解释掌握在国外企业手中,文档信息资源的保密性存在隐患。
OFD格式优势
1)产权属于自主产权
2)具有便携性:文件小,可压缩比率大。测试显示生成的文件体量比PDF还要小。
3)具有开放性:易于入门,对于使用者来说更具开放性。
4)具有扩展性:预留了可扩展入口和自定义标引,设置了非接触式引用机制,为特性化提供支持。
5)呈现效果与设备无关,在各种设备上阅读、打印或印刷时,版面固定、不跑版。
6)应用广泛:无论是电子商务、电子公务,还是信息发布、文件交换,档案管理等都需要版式文档的技术支持。
据我了解,现在国内很多档案馆已经开始用OFD版式文档存档了,毕竟响应国家号召。
OFD采用的是"容器+文档"的方式描述和存储数据,容器是一个虚拟存储系统,将各类数据描述文件聚合起来,并提供相应的访问接口和数据压缩方法。
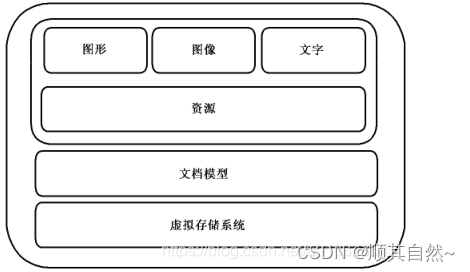
现在我们要知道OFD文件层次组织结构
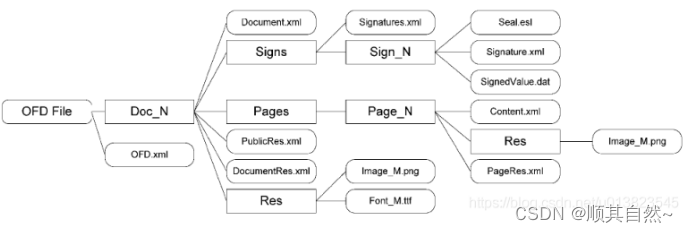
在我看来ofd文件最为重要的一点是底层通过xml来进行构造。使得板式固定和文件的稳定。既然是xml来实现那我们就可以通过xml入手。
新手的可以把ofd文件后缀改为zip(ofd本身就是压缩文件,文件名不是文件的一部分,是文件系统的一部分。文件名只是文件在文件系统中的映射标记,文件本身并不包含文件名),再进行解压就可以看到文件结构了
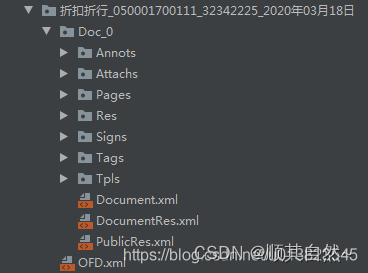
OFD文件层次组织结构
OFD.XML | 文件主入口文件,一个包内存在且只存在一个OFD.xml文件,此文件名不应修改
DOC_N | 第N个文档的文件夹
Document.xml | 文档的根节点
Page_N | 第N页文件夹
Content.cml | 第N页的内容描述
PageRes.xml | 第N页的资源描述
Res | 资源文件夹
PublicRes.xml | 文档公共资源索引
DocumentRes.xml | 文档自身资源索引
Image_M.png/Font_M.ttf | 资源文件
Signs | 数字签名存储目录
Singatures.xml | 签名列表文件
Sign_N | 第N个签名/签章
Signature.xml | 签名/签章描述文件
Seal.esl | 电子印章文件
SignedValue.dat | 签名值文件
我们看到OFD.XML 为主入口文件,OFD.xml文件的结构
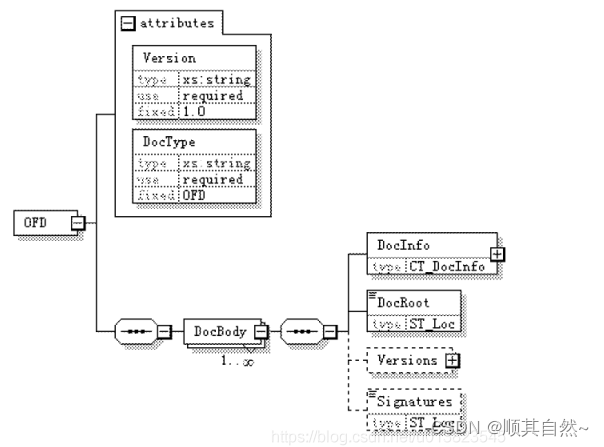
我们可以在主入口文件里面找到根文件(Document.xml)的相对位置,根文件里面会有我们所需的数据文件的索引。
一般来看我们简单提取文件中的数据我们只需要找到数据文件包括(文本数据及bbox的坐标,线条的坐标)在重构造了。我那示例图来说一下我们所需要的的数据。
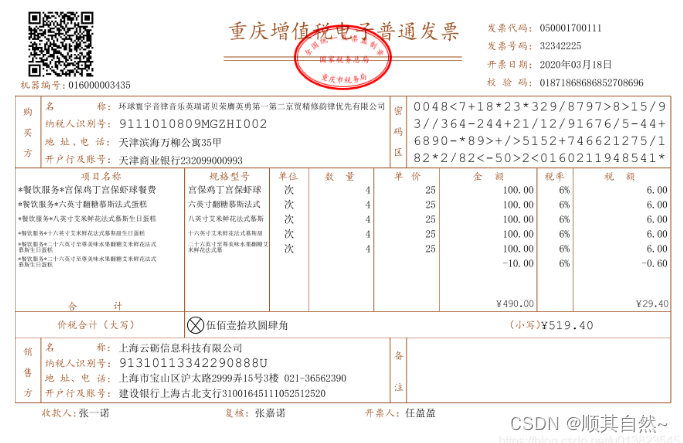
我们在图上可以看到有"重庆增值税电子普通发票 发票代码:"这样的红色文本,还有"050001700111"这样的黑色文本,还有红色的线条。这是我们所需要的 当然还会有二维码和印章,提取方式都是一样的。我们按照前三类去提取讲解。
2、数据提取思路
我们根据主入口文件找到根文件在根据找到数据文件,在根据数据文件去解析数据就OK。
1.先找到主入口文件,这个当然容易因为他就在最外层并且命名不会改变。我们现在就来看一下他的内容。
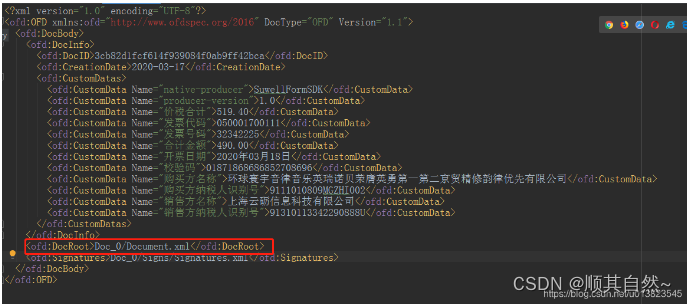
我们能看到图中红框的就是根文件的相对目录。我们可以把xml文件转成json处理,这个操作不会的同学们自行百度,或者私信我。我们再来看一下这个根文件内容。
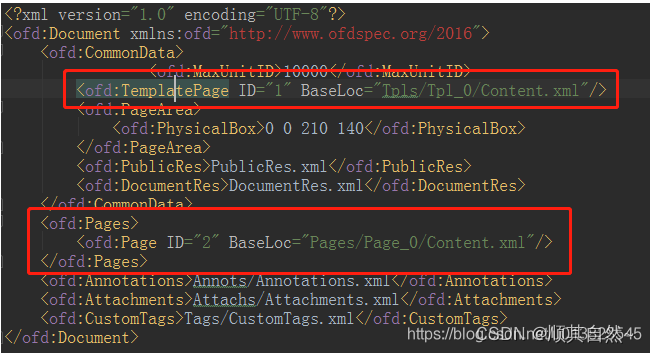
我们能看到红框1中的相对路径中的文件是上面提到的红色字体和线条的数据存放文件,红框2中的相对路径的文件是黑色字体的数据存放文件。我们解析出数据存放的文件路径那我们就可以去解析数据了。我们分别来看一下这两类数据文件内容。
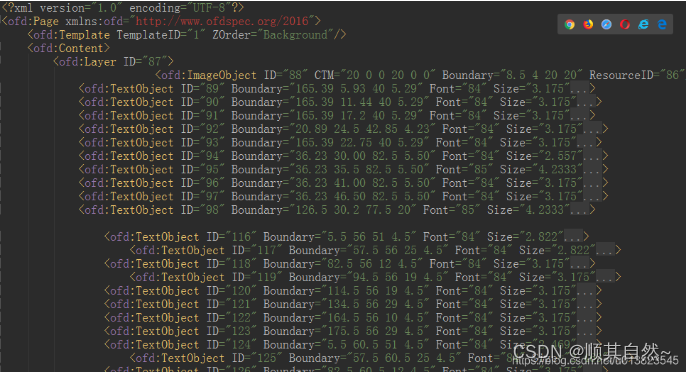
我们虽然找到了这个数据文件,但是数据结构还是比较复杂的,我是通过递归去找到需要的数据。当然同学们也可以评论自己更好的方法。Boundary四位数分别代表的是 x y w h。(ofd是左上角的x,y。pdf是左下角的x,y)这样我们就可以根据计算提供了x_mix,y_mix,x_max,y_max了这样我们就可以画出bbox了。线条和红色字体也是同一道理.这样我们可以根据自己的需求去重结构化了。当然这是高度个性化的开发,所以我这边就不做陈述了。
这样我们就可以把ofd数据解析出来了。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/108190.html