
目录
执行DROP SPACE语句删除图空间后,为什么磁盘的大小没变化?
相关文档:
- nGQL命令汇总:nGQL 命令汇总 - NebulaGraph Database 手册
一、预备~
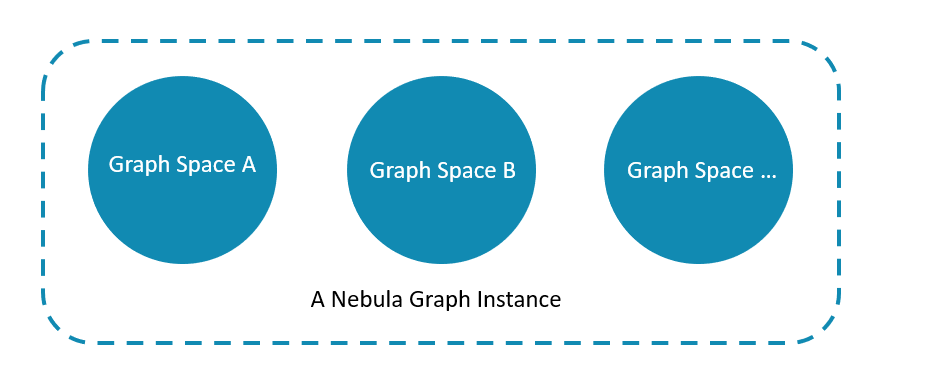
一个NebulaGraph实例由一个或多个图空间组成。每个图空间都是物理隔离的,用户可以在同一个实例中使用不同的图空间存储不同的数据集。
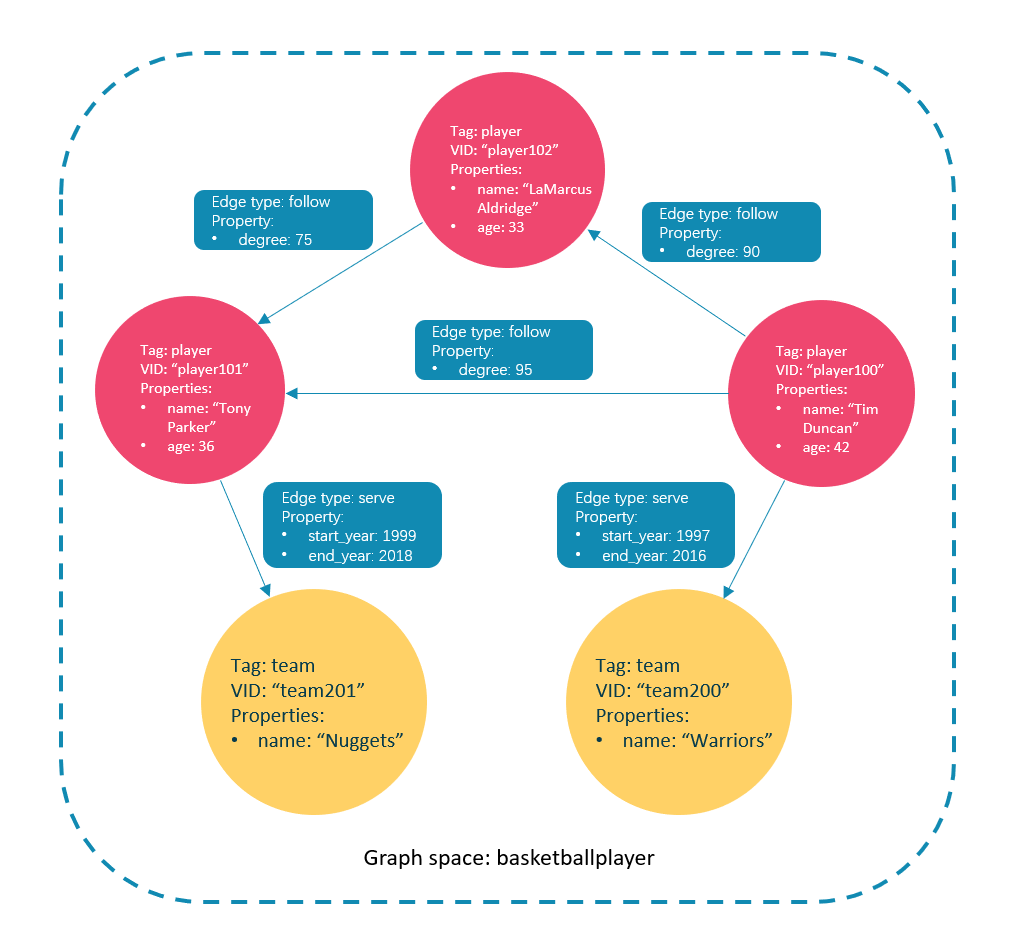
为了在图空间中插入数据,需要为图数据库定义一个Schema。NebulaGraph的Schema是由如下几部分组成。
| 组成部分 |
说明 |
| 点(Vertex) |
表示现实世界中的实体。一个点可以有一个或多个标签。 |
| 标签(Tag) |
点的类型,定义了一组描述点类型的属性。 |
| 边(Edge) |
表示两个点之间有方向的关系。 |
| 边类型(Edge type) |
边的类型,定义了一组描述边的类型的属性。 |
二、基础操作
(一) 图空间
1. 创建图空间
CREATE SPACE [IF NOT EXISTS] <graph_space_name> (
[partition_num = <partition_number>,]
[replica_factor = <replica_number>,]
vid_type = {FIXED_STRING(<N>) | INT[64]}
)
[COMMENT = '<comment>'];- partition_num:分片数,默认为10。建议设置为集群中硬盘数量的20倍(HDD硬盘建议为2倍)
- replica_factor:副本数,默认为1。建议生产环境为3,测试环境为1,必须为奇数
- vid_type*:指定点ID的数据类型,可选值为
FIXED_STRING(<N>)和INT64 - COMMENT:图空间描述
示例
# 创建示例图中图空间
CREATE SPACE IF NOT EXISTS basketballplayer (vid_type=FIXED_STRING(32)) comment="测试图空间";
# 指定分片数量、副本数量和 VID 类型,并添加描述。
CREATE SPACE IF NOT EXISTS my_demo (partition_num=15, replica_factor=1, vid_type=FIXED_STRING(32)) comment="测试图空间";
# 克隆图空间
CREATE SPACE IF NOT EXISTS my_demo2 as my_demo;
# 查看图空间创建语句
SHOW CREATE SPACE my_demo2;2. 清空图空间
用于清空图空间中的点和边,但不会删除图空间本身及Schema信息
CLEAR SPACE [IF EXISTS] <space_name>;建议在执行CLEAR SPACE操作之后,立即执行SUBMIT JOB COMPACT操作以提升查询性能
需要注意的是,COMPACT 操作可能会影响查询性能,建议在业务低峰期(例如凌晨)执行该操作。
💡 只有God 角色的用户可以执行CLEAR SPACE语句
3. 其他
# 切换图空间
USE <graph_space_name>;
# 查询全部图空间
SHOW SPACES;
# 查看图空间信息
DESC SPACE <graph_space_name>;
# 删除图空间
DROP SPACE [IF EXISTS] <graph_space_name>;4. FAQ
执行DROP SPACE语句删除图空间后,为什么磁盘的大小没变化?
如果使用 3.1.0 之前版本的 NebulaGraph , DROP SPACE语句仅删除指定的逻辑图空间,不会删除硬盘上对应图空间的目录和文件。如需删除硬盘上的数据,需手动删除相应文件的路径,文件路径为<nebula_graph_install_path>/data/storage/nebula/<space_id>。其中<space_id>可以通过DESCRIBE SPACE {space_name}查看。
(二) 点类型
1. 创建Tag
CREATE TAG [IF NOT EXISTS] <tag_name>
(
<prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']
[{, <prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']} ...]
)
[TTL_DURATION = <ttl_duration>]
[TTL_COL = <prop_name>]
[COMMENT = '<comment>'];- prop_name:属性名称
- data_type:属性类型
- NULL | NOT NULL:是否支持为NULL,默认为NULL
- DEFAULT:指定属性默认值
- COMMENT:指定属性描述信息
- TTL_DURATION:指定时间戳差值,单位:秒。默认值为0,表示属性永不过期。
- TTL_COL:指定要设置存活时间的属性。属性的数据类型必须是int或者timestamp。一个 Tag 只能指定一个字段为TTL_COL。更多 TTL 的信息请参见 TTL
示例
# 创建示例图中TAG
CREATE TAG IF NOT EXISTS player(name string COMMENT '姓名', age int DEFAULT 20 COMMENT '年龄') COMMENT='人物';
CREATE TAG IF NOT EXISTS team(name string COMMENT '团队名') COMMENT='团队';
# 对字段 create_time 设置 TTL 为 100 秒。
CREATE TAG IF NOT EXISTS woman(name string, age int, married bool, salary double, create_time timestamp) TTL_DURATION = 100, TTL_COL = "create_time";2. 删除Tag
DROP TAG [IF EXISTS] <tag_name>;点可以有一个或多个Tag
- 如果某个点只有一个 Tag,删除这个 Tag 后,用户就无法访问这个点,下次 Compaction 操作时会删除该点,但与该点相邻的边仍然存在——这会造成悬挂边
- 如果某个点有多个 Tag,删除其中一个 Tag,仍然可以访问这个点,但是无法访问已删除 Tag 所定义的所有属性。
删除 Tag 操作仅删除 Schema 数据,硬盘上的文件或目录不会立刻删除,而是在下一次 Compaction 操作时删除。
NebulaGraph 3.6.0 中默认不支持插入无 Tag 的点。如需使用无 Tag 的点,
在集群内所有 Graph 服务的配置文件(nebula-graphd.conf)中新增:--graph_use_vertex_key=true
在所有 Storage 服务的配置文件(nebula-storaged.conf)中新增:--use_vertex_key=true
3. 更新Tag
ALTER TAG <tag_name>
<alter_definition> [[, alter_definition] ...]
[ttl_definition [, ttl_definition] ... ]
[COMMENT = '<comment>'];
alter_definition:
| ADD (prop_name data_type [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>'])
| DROP (prop_name)
| CHANGE (prop_name data_type [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>'])
ttl_definition:
TTL_DURATION = ttl_duration, TTL_COL = prop_name- tag_name:指定修改的Tag名称,一次只能修改一个Tag
- 可以在一个
ALTER TAG语句中使用多个ADD、DROP和CHANGE,用,分割 - ⚡当使用
CHANGE修改属性的数据类型时
-
- 仅允许修改
FIXED_STRING和INT类型的长度为更大的长度,不允许减少长度 - 仅允许修改
FIXED_STRING类型为STRING类型、修改FLOAT类型为DOUBLE类型 - 确保要修改的属性不包含索引,否则
ALTER TAG时会报冲突错误[ERROR (-1005)]: Conflict!。删除索引请参见 drop index - 确保新增的属性名不与已存在或被删除的属性名同名
- 仅允许修改
示例
CREATE TAG IF NOT EXISTS t1 (p1 string, p2 int);
ALTER TAG t1 ADD (p3 int32, p4 fixed_string(10));
ALTER TAG t1 TTL_DURATION = 2, TTL_COL = "p2";
ALTER TAG t1 COMMENT = 'test1';
ALTER TAG t1 ADD (p5 double NOT NULL DEFAULT 0.4 COMMENT 'p5') COMMENT='test2';
# 将 TAG t1 的 p3 属性类型从 INT32 改为 INT64,p4 属性类型从 FIXED_STRING(10) 改为 STRING。
nebula> ALTER TAG t1 CHANGE (p3 int64, p4 string);4. 其他
# 查询当前图空间中全部Tag
SHOW TAGS;
# 显示指定Tag信息
DESC[RIBE] TAG <tag_name>;
# 删除指定点上的指定Tag
DELETE TAG <tag_name_list> FROM <VID_list>;(三) 边类型
1. 创建Edge type
CREATE EDGE [IF NOT EXISTS] <edge_type_name>
(
<prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']
[{, <prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']} ...]
)
[TTL_DURATION = <ttl_duration>]
[TTL_COL = <prop_name>]
[COMMENT = '<comment>'];- prop_name:属性名称
- data_type:属性类型
- NULL | NOT NULL:是否支持为NULL,默认为NULL
- DEFAULT:指定属性默认值
- COMMENT:指定属性描述信息
- TTL_DURATION:指定时间戳差值,单位:秒。默认值为0,表示属性永不过期。
- TTL_COL:指定要设置存活时间的属性。属性的数据类型必须是int或者timestamp。一个 Tag 只能指定一个字段为TTL_COL。更多 TTL 的信息请参见 TTL
示例
# 创建示例图中Edge type
CREATE EDGE IF NOT EXISTS follow (degree int);
CREATE EDGE IF NOT EXISTS serve (start_year int, end_year int);
# 对字段 p2 设置 TTL 为 100 秒。
CREATE EDGE IF NOT EXISTS e1(p1 string, p2 int, p3 timestamp) TTL_DURATION = 100, TTL_COL = "p2";2. 删除Edge type
DROP EDGE [IF EXISTS] <edge_type_name>一个边只能有一个Edge type,删除这个 Edge type 后,用户就无法访问这个边,下次 Compaction 操作时会删除该边。
3. 更新Edge type
ALTER EDGE <edge_type_name>
<alter_definition> [, alter_definition] ...]
[ttl_definition [, ttl_definition] ... ]
[COMMENT = '<comment>'];
alter_definition:
| ADD (prop_name data_type)
| DROP (prop_name)
| CHANGE (prop_name data_type)
ttl_definition:
TTL_DURATION = ttl_duration, TTL_COL = prop_name- edge_type_name:指定修改的Edge type名称,一次只能修改一个Edge type
- 可以在一个
ALTER TAG语句中使用多个ADD、DROP和CHANGE,用,分割 - ⚡当使用
CHANGE修改属性的数据类型时
-
- 仅允许修改
FIXED_STRING和INT类型的长度为更大的长度,不允许减少长度 - 仅允许修改
FIXED_STRING类型为STRING类型、修改FLOAT类型为DOUBLE类型 - 确保要修改的属性不包含索引,否则
ALTER EDGE时会报冲突错误[ERROR (-1005)]: Conflict!。删除索引请参见 drop index - 确保新增的属性名不与已存在或被删除的属性名同名
- 仅允许修改
示例
CREATE EDGE IF NOT EXISTS e1(p1 string, p2 int);
ALTER EDGE e1 ADD (p3 int, p4 string);
ALTER EDGE e1 TTL_DURATION = 2, TTL_COL = "p2";
ALTER EDGE e1 COMMENT = 'edge1';4. 其他
# 查询当前图空间中全部Edge type
SHOW EDGES;
# 显示指定Edge type信息
DESC[RIBE] EDGE <edge_type_name>(四) 点
1. 插入Vertex
一次可以在指定图空间插入一个或多个点
INSERT VERTEX [IF NOT EXISTS] [tag_props, [tag_props] ...]
VALUES VID: ([prop_value_list])
tag_props:
tag_name ([prop_name_list])
prop_name_list:
[prop_name [, prop_name] ...]
prop_value_list:
[prop_value [, prop_value] ...] - IF NOT EXISTS:仅检测
VID + Tag的值是否相同,不会检测属性值;并且会先读取一次数据是否存在,因此对性能会有明显影响 - tag_name*:点关联的Tag,一个点可以关联多个Tag
- vid*:点ID,在3.6.0中支持字符串和整数,需要在创建图空间时设置
- prop_name:需要设置的属性名称
- prop_value:根据
prop_name_list填写的属性值
示例
# 创建示例图中Values
INSERT VERTEX player (name, age) VALUES "player102": ("LaMarcus Aldperties", 33), "player101": ("Tony", 36), "player100": ("Tim", 42);
INSERT VERTEX team (name) VALUES "team201": ("Nuggets"), "team200": ("Warriors");
# 一次插入两个 Tag 的属性到同一个点。
INSERT VERTEX t3 (p1), t4(p2) VALUES "21": (321, "hello");
# 多次插入属性值,以最后一次为准
INSERT VERTEX t2 (name, age) VALUES "11":("n3", 14);
INSERT VERTEX t2 (name, age) VALUES "11":("n4", 15);
+-----------------------+
| properties(VERTEX) |
+-----------------------+
| {age: 15, name: "n4"} |
+-----------------------+
# 插入超长值后会被截断
CREATE TAG IF NOT EXISTS t5(p1 fixed_string(5) NOT NULL, p2 int, p3 int DEFAULT NULL);
INSERT VERTEX t5(p1, p2) VALUES "004":("shalalalala", 4);
+------------------------------------+
| properties(VERTEX) |
+------------------------------------+
| {p1: "shala", p2: 4, p3: __NULL__} |
+------------------------------------+2. 删除Vertex
DELETE VERTEX <vid> [ , <vid> ... ] [WITH EDGE];- 一次可以删除一个或多个点,可结合管道符使用。2.X默认删除点及关联边,3.6.0默认只删除点
WITH EDGE:删除该点关联的出边和入边,否则会存在悬挂边
示例
# 删除 VID 为 `team1` 的点,不删除该点关联的出边和入边。
DELETE VERTEX "team1";
# 删除 VID 为 `team1` 的点,并删除该点关联的出边和入边。
DELETE VERTEX "team1" WITH EDGE;
# 结合管道符,删除符合条件的点。
GO FROM "player100" OVER serve WHERE properties(edge).start_year == "2021" YIELD dst(edge) AS id | DELETE VERTEX $-.id;GO FROM "player100" OVER serve:从起始顶点 "player100" 出发,沿着 serve 这个边类型进行遍历WHERE properties(edge).start_year == "2021":提取其属性中 start_year 字段值为 "2021" 的边YIELD dst(edge) AS id:从满足条件的边中提取目标顶点(dst(edge))ID,并将这些ID赋值给变量id| DELETE VERTEX $-.id:使用管道符,引用变量id,删除满足条件的顶点
3. 更新Vertex
一次只能针对一个Tag
UPDATE VERTEX ON <tag_name> <vid>
SET <update_prop>
[WHEN <condition>]
[YIELD <output>]- tag_name*:指定点的Tag
- vid*:点ID
- update_prop*:指定如何修改属性值
- condition:指定过滤条件
- output:指定语句的输出格式
示例
# 查看点”player101“的属性。
FETCH PROP ON player "player101" YIELD properties(vertex);
+--------------------------------+
| properties(VERTEX) |
+--------------------------------+
| {age: 36, name: "Tony"} |
+--------------------------------+
# 修改属性 age 的值,并返回 name 和新的 age。
UPDATE VERTEX ON player "player101" SET age = age + 2 WHEN name == "Tony Parker" YIELD name AS Name, age AS Age;
+---------------+-----+
| Name | Age |
+---------------+-----+
| "Tony" | 38 |
+---------------+-----+4. 插入或更新Vertex
插入或更新点属性,如果点存在,则修改点属性;否则插入新的点
一次只能针对一个Tag
UPSERT VERTEX性能远低于INSERT,因为UPSERT是一组分片级别的读取、修改、写入操作
⚡并发UPSERT同一个TAG或EDGE TYPE会报错
UPSERT VERTEX ON <tag> <vid>
SET <update_prop>
[WHEN <condition>]
[YIELD <output>]- tag*:指定点的Tag
- vid*:点ID
- update_prop*:指定如何修改属性值
- condition:指定过滤条件
- output:指定语句的输出格式
示例
# 查看点是否存在,结果 “Empty set” 表示顶点不存在。
FETCH PROP ON * "player666" YIELD properties(vertex);
+--------------------+
| properties(VERTEX) |
+--------------------+
+--------------------+
Empty set
UPSERT VERTEX ON player "player666" SET age = 30, name = "Joe" YIELD name AS Name, age AS Age;
+----------+----------+
| Name | Age |
+----------+----------+
| Joe | 30 |
+----------+----------+
# 修改已存在的点,查看点player101的属性。
FETCH PROP ON player "player101" YIELD properties(vertex);
+--------------------------------+
| properties(VERTEX) |
+--------------------------------+
| {age: 38, name: "Tony"} |
+--------------------------------+
UPSERT VERTEX ON player "player101" SET name = "Tony Parker" YIELD name AS Name, age AS Age;
+---------------+-----+
| Name | Age |
+---------------+-----+
| "Tony Parker" | 38 |
+---------------+-----+(五) 边
1. 插入Edge
一次可以在指定图空间插入一条或多条边,边是有方向的,从起始点(src_vid)到目的点(dst_vid)
为覆盖式插入。如果已有 Edge type、起点、终点、rank 都相同的边,则覆盖原边。
INSERT EDGE [IF NOT EXISTS] <edge_type> ( <prop_name_list> ) VALUES
<src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> )
[, <src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> ), ...];
<prop_name_list> :
[ <prop_name> [, <prop_name> ] ...]
<prop_value_list> :
[ <prop_value> [, <prop_value> ] ...]- IF NOT EXISTS:仅检测
edge_type + src_vid + dst_vid + rank的值是否相同,不会检测属性值;并且会先读取一次数据是否存在,因此对性能会有明显影响 - edge_name*:边关联的Edge type,一个边只能指定一个Edge type
- src_vid*:起始点ID
- dst_vid*:目的点ID
- rank:边的rank(排名)值,默认为0
- prop_name_list:需要设置的属性名称列表
- prop_value_list:根据
prop_name_list填写的属性值
示例
# 创建示例图中Values
INSERT EDGE follow (degree) VALUES "player102" -> "player101": (75), "player100" -> "player102": (90), "player100" -> "player101": (95);
INSERT EDGE serve (start_year, end_year) VALUES "player100" -> "team200": (1997, 2016), "player101" -> "team201": (1999, 2018);
# 插入 rank 为 1 的边。
INSERT EDGE e1 () VALUES "10"->"11"@1:();
# 多次插入属性值。
nebula> INSERT EDGE e2 (name, age) VALUES "11"->"13":("n1", 13);
nebula> INSERT EDGE e2 (name, age) VALUES "11"->"13":("n1", 14);
nebula> FETCH PROP ON e2 "11"->"13" YIELD edge AS e;
+-------------------------------------------+
| e |
+-------------------------------------------+
| [:e2 "11"->"13" @0 {age: 14, name: "n1"}] |
+-------------------------------------------+
2. 删除Edge
DELETE EDGE <edge_type> <src_vid> -> <dst_vid>[@<rank>] [, <src_vid> -> <dst_vid>[@<rank>] ...]- 一次可以删除一条或多条边,可结合管道符使用
- 如何需要删除一个点的所有出边,请删除这个点,详见:删除Vertex
- ⚡如果不指定rank,则仅删除rank为0的边,需要删除所有的 rank,见如下示例。
示例
# 删除单条边
DELETE EDGE serve "player100" -> "team204";
# 结合管道符,删除两点之间同类型的所有rank的边。
GO FROM "player100" OVER follow WHERE dst(edge) == "player101" YIELD src(edge) AS src, dst(edge) AS dst, rank(edge) AS rank | DELETE EDGE follow $-.src -> $-.dst @ $-.rank;GO FROM "player100" OVER follow WHERE dst(edge) == "player101":从开始节点player100遍历目标节点为player101的follow类型的边YIELD src(edge) AS src, dst(edge) AS dst, rank(edge) AS rank:返回遍历结果并赋值变量| DELETE EDGE follow $-.src -> $-.dst @ $-.rank:使用管道符,引用变量,删除满足条件的全部边
3. 更新Edge
UPDATE EDGE ON <edge_type>
<src_vid> -> <dst_vid> [@<rank>]
SET <update_prop>
[WHEN <condition>]
[YIELD <output>]- edge_type*:指定边的Edge type
- src_vid*:边的起始ID
- dst_vid*:边的目的ID
- rank:边的rank(排名)值
- update_prop*:指定如何修改属性值
- condition:指定过滤条件
- output:指定语句的输出格式
示例
# 用 GO 语句查看边的属性值。
GO FROM "player100" OVER serve YIELD properties(edge).start_year, properties(edge).end_year;
+-----------------------------+---------------------------+
| properties(EDGE).start_year | properties(EDGE).end_year |
+-----------------------------+---------------------------+
| 1997 | 2016 |
+-----------------------------+---------------------------+
# 修改属性 start_year 的值,并返回 end_year 和新的 start_year。
UPDATE EDGE ON serve "player100" -> "team200"@0 SET start_year = start_year + 1 WHEN end_year > 2010 YIELD start_year, end_year;
+------------+----------+
| start_year | end_year |
+------------+----------+
| 1998 | 2016 |
+------------+----------+4. 插入或更新Edge
插入或更新边属性,如果边存在,则修改边属性;否则插入新的边
UPSERT EDGE性能远低于INSERT,因为UPSERT是一组分片级别的读取、修改、写入操作
⚡并发UPSERT同一个TAG或EDGE TYPE会报错
UPSERT EDGE ON <edge_type>
<src_vid> -> <dst_vid> [@rank]
SET <update_prop>
[WHEN <condition>]
[YIELD <properties>]- edge_type*:指定边的Edge type
- src_vid*:边的起始ID
- dst_vid*:边的目的ID
- rank:边的rank(排名)值
- update_prop*:指定如何修改属性值
- condition:指定过滤条件
- output:指定语句的输出格式
示例
# 查看点是否有 serve 类型的出边,结果 “Empty set” 表示没有 serve 类型的出边。
GO FROM "player666" OVER serve YIELD properties(edge).start_year, properties(edge).end_year;
+-----------------------------+---------------------------+
| properties(EDGE).start_year | properties(EDGE).end_year |
+-----------------------------+---------------------------+
+-----------------------------+---------------------------+
Empty set
UPSERT EDGE on serve "player666" -> "team200" SET start_year = 2020, end_year = 2021 YIELD start_year, end_year;
+------------+----------+
| start_year | end_year |
+------------+----------+
| 2020 | 2021 |
+------------+----------+(六) 作业管理
1. 支持的作业
SUBMIT JOB STATS
对当前图空间进行统计
其他作业操作详见官方文档
2. 查看作业
查看单个作业运行详情
SHOW JOB <job_id>;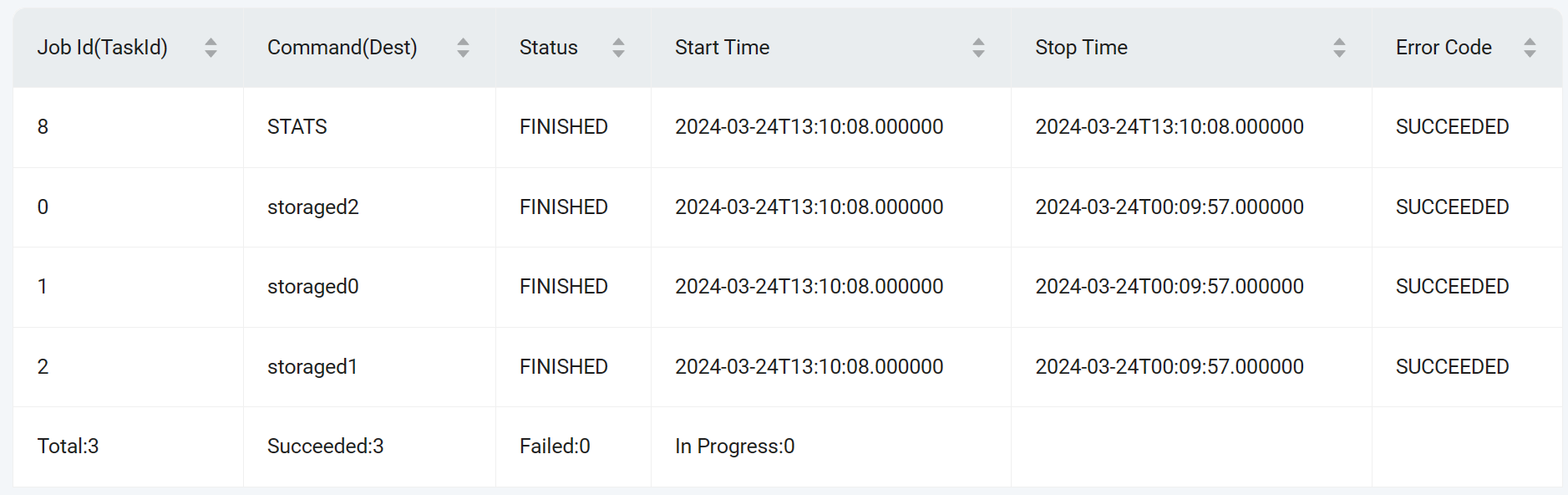
| 参数 |
说明 |
| Job Id(TaskId) |
第一行显示作业 ID,最后一行显示作业相关的任务总数,其他行显示作业相关的任务 ID。 |
| Command(Dest) |
第一行显示执行的作业命令名称,最后一行显示作业相关的成功的任务数。其他行显示任务对应的 nebula-storaged 进程。 |
| Status |
显示作业或任务的状态,最后一行显示作业相关的失败的任务数。详情请参见作业状态。 |
| Start Time |
显示作业或任务开始执行的时间,最后一行显示作业相关的正在进行的任务数。 |
| Stop Time |
显示作业或任务结束执行的时间,结束后的状态包括FINISHED、FAILED或STOPPED。 |
| Error Code |
显示作业或任务的错误码。 |
状态说明
| 状态 |
说明 |
| QUEUE |
作业或任务在等待队列中。此阶段Start Time为空。 |
| RUNNING |
作业或任务在执行中。Start Time为该阶段的起始时间。 |
| FINISHED |
作业或任务成功完成。Stop Time为该阶段的起始时间。 |
| FAILED |
作业或任务失败。Stop Time为该阶段的起始时间。 |
| STOPPED |
作业或任务停止。Stop Time为该阶段的起始时间。 |
| REMOVED |
作业或任务被删除。 |
查看作业列表
SHOW JOBS;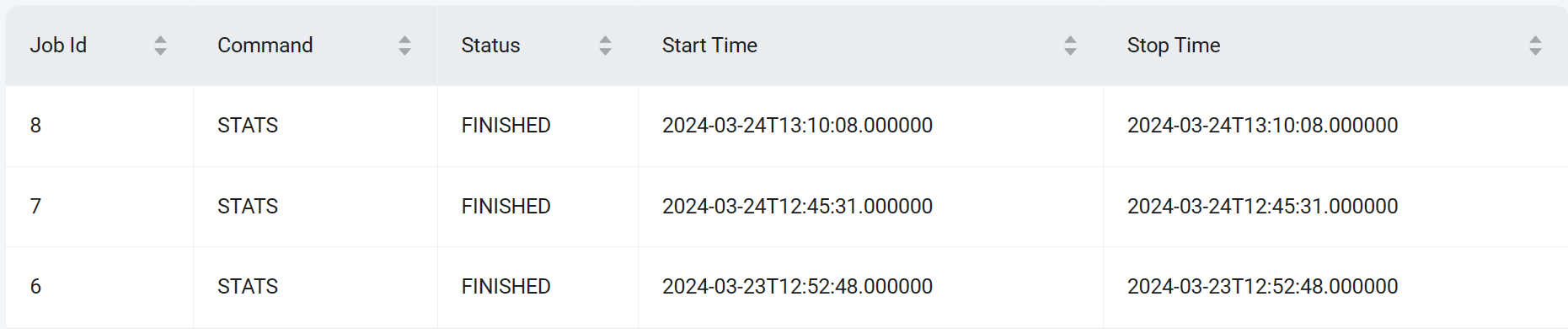
3. 停止作业
STOP JOB <job_id>;4. 重新执行作业
RECOVER JOB [<job_id>];- 重新执行当前图空间内状态为
FAILED、STOPPED的作业,未指定job_id时,会从最早的作业开始尝试重新执行
5. FAQ
如何排查作业问题
SUBMIT JOB操作使用的是HTTP端口,请检查Storage服务机器上的HTTP端口是否正常工作。可以执行如下命令调试:
curl "http://{storaged-ip}:19779/admin?space={space_name}&op=compact"三、查询
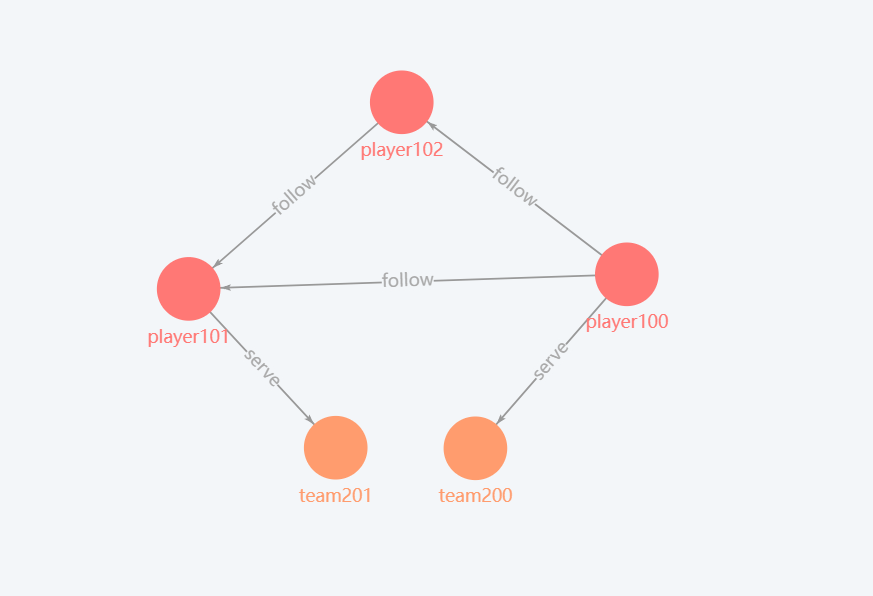
💡查询当前图空间中全部点
MATCH (v) RETURN v;

💡查询当前图空间中全部点和边
MATCH ()-[e]->() RETURN e;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/83033.html