
1. 课程笔记
- 评测的重要性
大模型的测评是非常重要的,对于普通用户来说,测评能够让我们更好的了解模型的特色能力和实际效果。对于开发者而言,测评能够让我们监控模型能力的变化,从而指导优化模型生产。对于管理机构而言,测评能够减少大模型带来的社会风险。对于产业界来说,测评可以找到最适合的产业模型。那InternLM其实也是经过不断的测评调整才能达到如此好的效果。

- 评测的任务
包括传统NLP的内容,那大模型所有评测的其实会更多,所有的能力都是可以进行评测的。
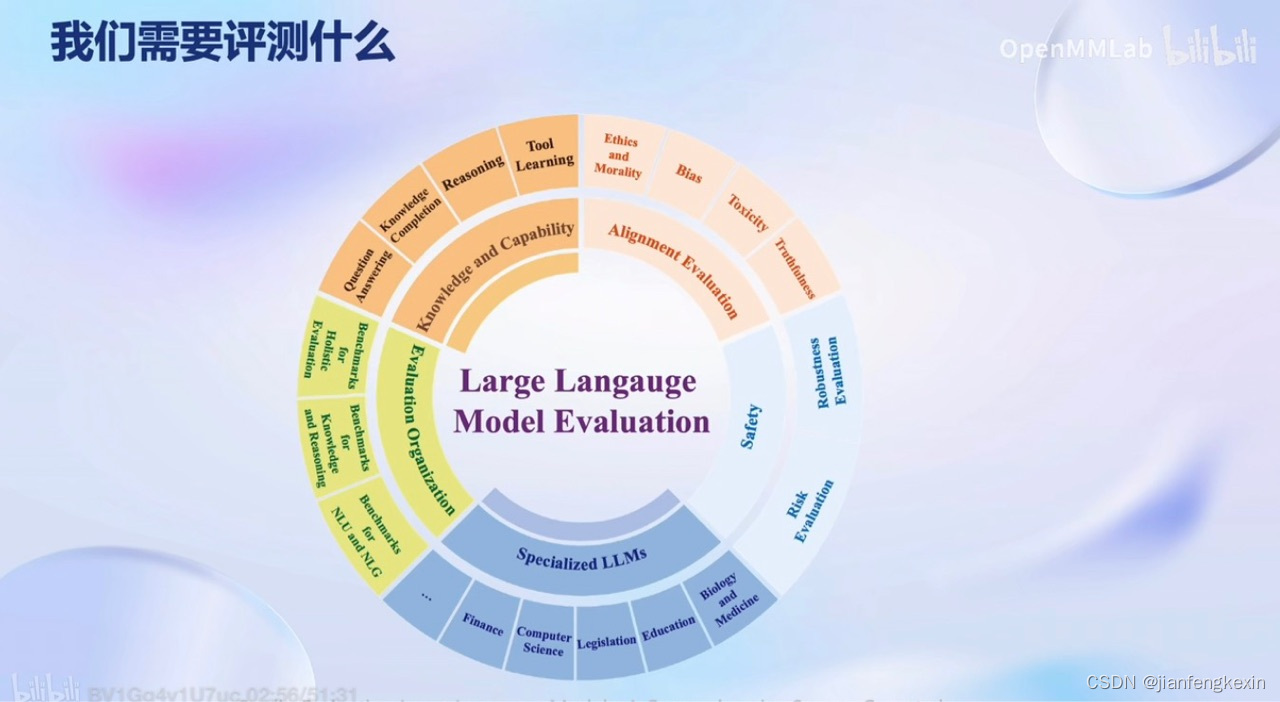
- 评测
包括有主观题和客观题,大部分是客观题,因为比较好统计。
主要就是提出一个问题,然后看大模型的回答中是否有其中的内容,假如出现了就认为是答对了。
主观评测其实就是让人来判断大模型的回复是否是好的。当然除了人工以外,还能调用一些能力比较强的模型,比如说GPT4来判断的话也是很ok的。
除了主观题和客观题, 其实还有通过提示词工程来进行测评。就是说对于同一道题目,假如我换一个提示词的话,模型就回答不上来,那么也代表模型的鲁棒性很差。
- 常见的框架
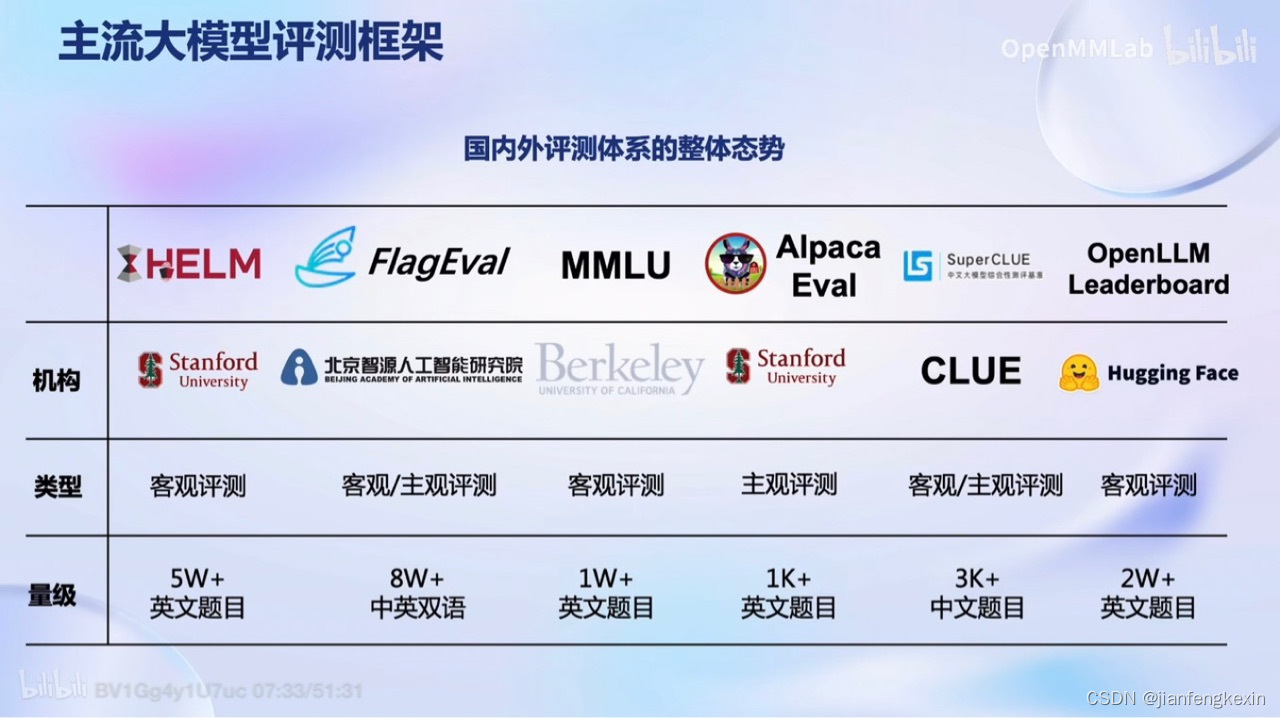
- OpenCampass的框架
学科、语言、知识、理解、推理、安全等等

- 整体平台框架
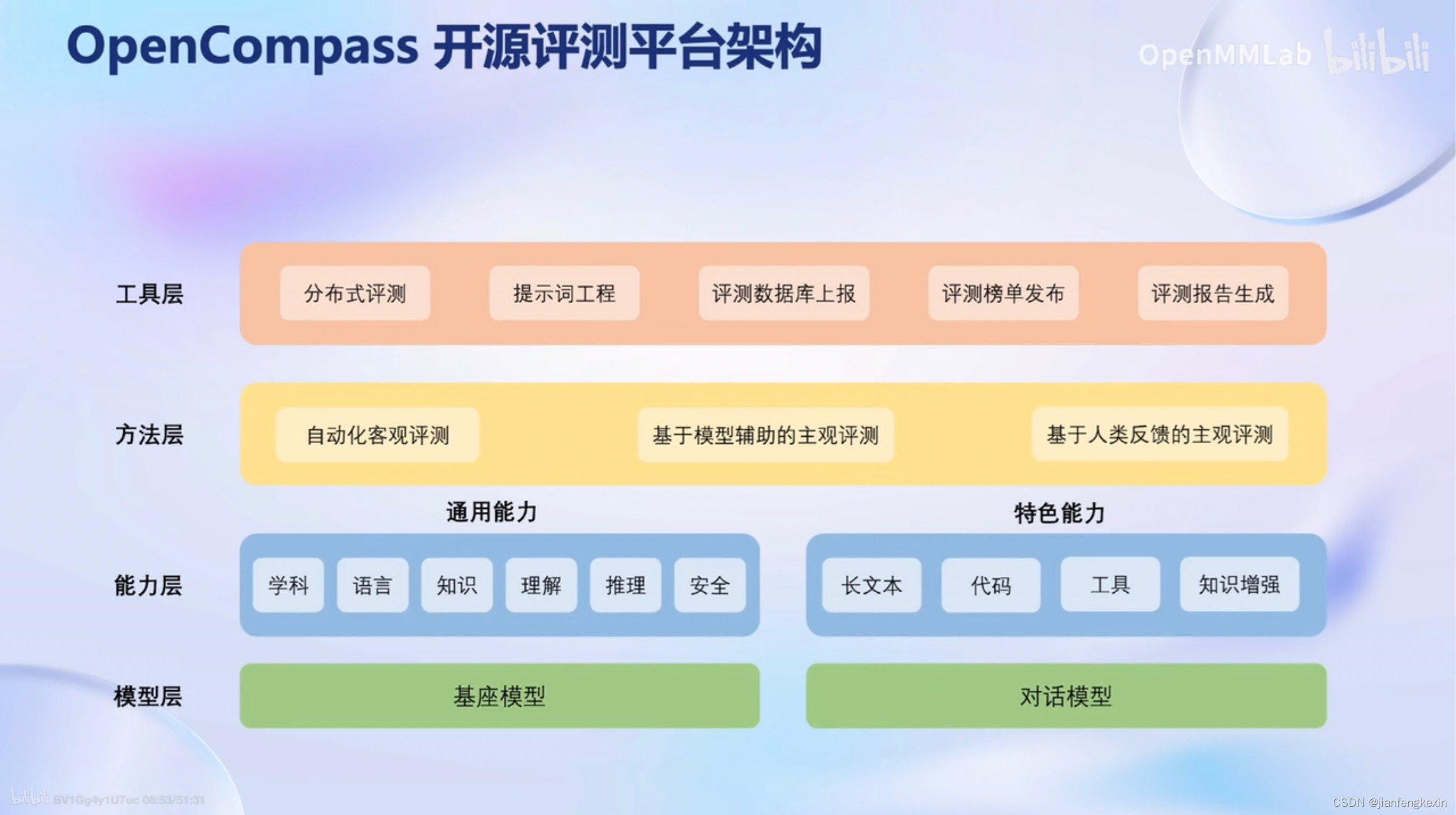
同时支持大量的模型
- 评测流水线测试
我们可以选择的模型包括自己的模型、Huggingface上的开源模型以及API接入的模型。
那评测的数据集我们不仅仅可以用已有的数据集,还可以把自己的评测数据集也放上去。
那在评测过程中,OpenCompass也提供了一些优化的方法,比如说并行处理等方式。
在评测完,也将输出多种的类型和内容。
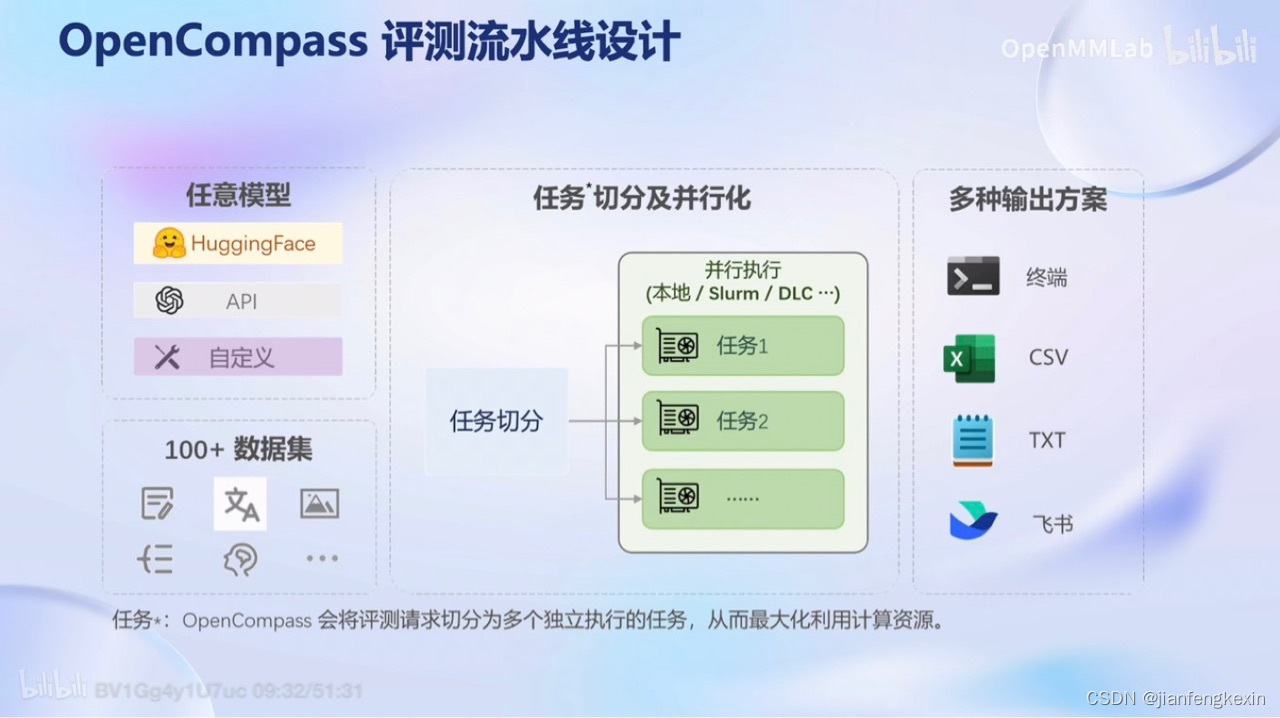
除此之外还有一些多模态、医疗、法律等评测指标。
- 大模型评测领域的挑战
1. 缺少高质量中文评测集
2. 难以准确提取答案
3. 能力维度不足
4. 测试集混入训练集(造成数据污染,结果不准确- 开发测试数据污染工具c)
5. 测试标准各异
6. 人工测试成本高昂
2. 做作业展示
InternLM-Chat-7B测评结果。
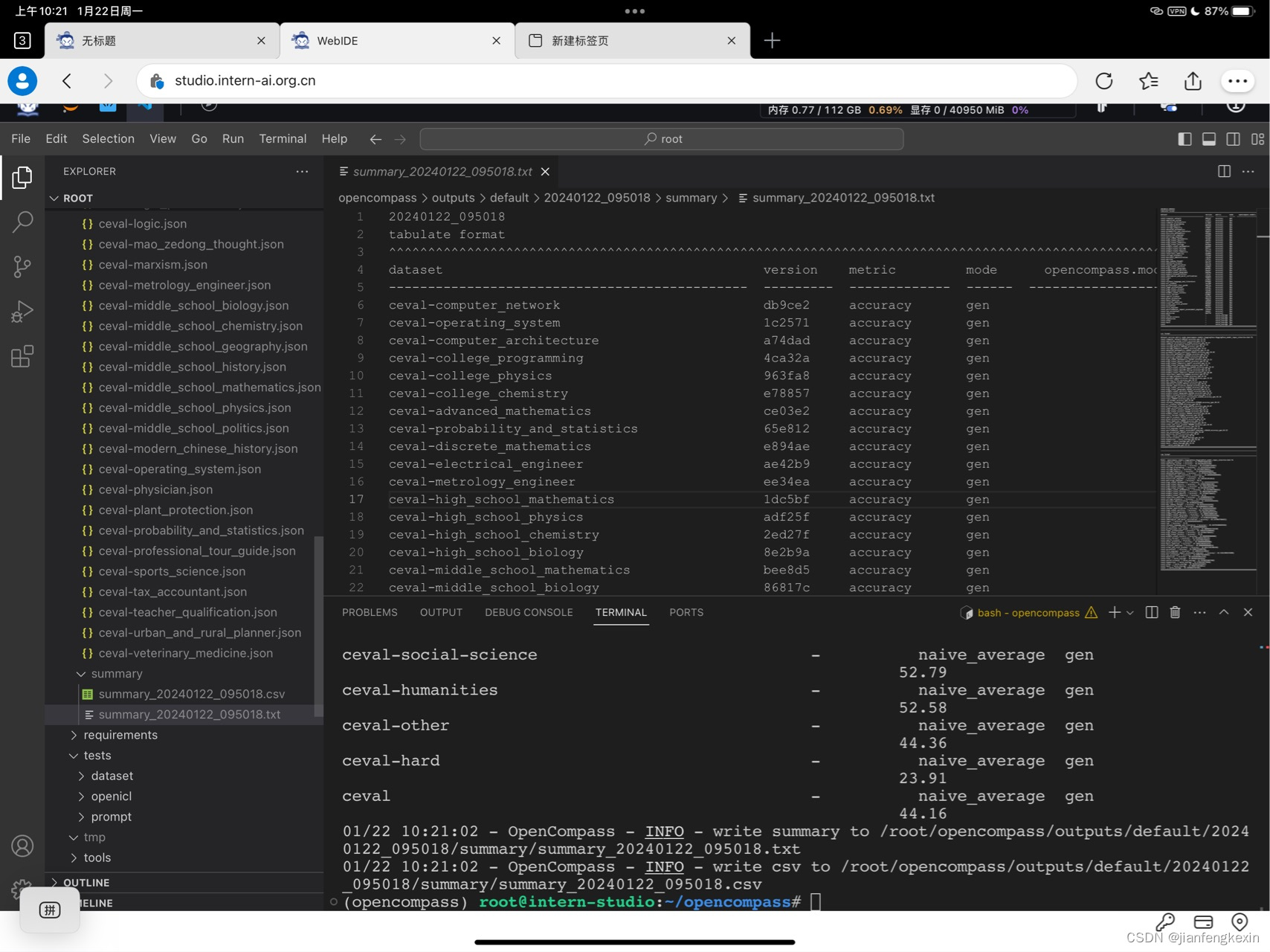
今天的文章 OpenCampass大模型测评(大模型实战训练营第六节笔记和作业)分享到此就结束了,感谢您的阅读。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/85489.html