
文章目录
背景& 前置说明
因果推断在营销场景的应用主要是基于uplift Model预测营销干预带来的增益
Uplift model是一个增量模型,其目标是预测某种干预对于个体状态或行为的因果效应(ITE, individual treatment effect),那么如何表示这个增益模型呢?
假设有N个用户, Y i ( 1 ) Y_i(1) Yi(1)表示对用户干预后用户输出的结果,比如给用户i发放优惠券(干预)后用户下单(结果), Y i ( 0 ) Y_i(0) Yi(0) 表示没有对用户干预情况下的输出结果。用户i的因果效应的计算方式如下:
τ i = Y i ( 1 ) − Y i ( 0 ) \tau_i = Y_i(1) - Y_i(0) τi=Yi(1)−Yi(0)
训练增益模型目标就是最大化增量 τ i \tau_i τi,即有干预策略相对于无干预策略的提升,更简单的解释就是干预前后用户输出结果的差值。在实际使用时会采用所有用户的因果效应期望来衡量该用户群的整体表现,称为条件平均因果效应(CATE, Conditional Average Treatment Effect):
τ i = E [ Y i ( 1 ) ∣ X i ] − E [ Y i ( 0 ) ∣ X i ] \tau_i = E[Y_i(1)|X_i] - E[Y_i(0)|X_i] τi=E[Yi(1)∣Xi]−E[Yi(0)∣Xi]
上式中 X i X_i Xi是用户i的特征。
一、uplift建模的方法
在建模前我们需要注意一个很重要的问题:Uplift Model对样本要求很高,需要用户特征和干预策略相互独立。
那么什么样的样本用户有这样的特征,这样的样本又该如何获取?
最简单直接的方式就是随机A/B实验,A组采用干预策略,B组不进行任何干预,经过A组和B组的流量得到的两组样本在特征分布上基本一致(即满足CIA),可以通过模拟两组人群的 τ ( X i ) \tau(X_i) τ(Xi)进而得到个人用户的 τ ( X i ) \tau(X_i) τ(Xi)。因此随机A/B实验在Uplift Model建模过程中至关重要,在训练样本高度无偏情况下,模型才能表现出更好的效果。
1、T-Model,两个模型求差分
参考文章:Uplift-Model在贝壳业务场景中的实践
T-Learner,也叫T-Model,其中T代表two的意思,也即用两个模型。它的主要思想是对干预数据和无干预数据分别进行建模,预估时数据进入两个模型,用两个模型的预测结果做差值,来得到预估的增量。
1)模型原理 & 建模步骤
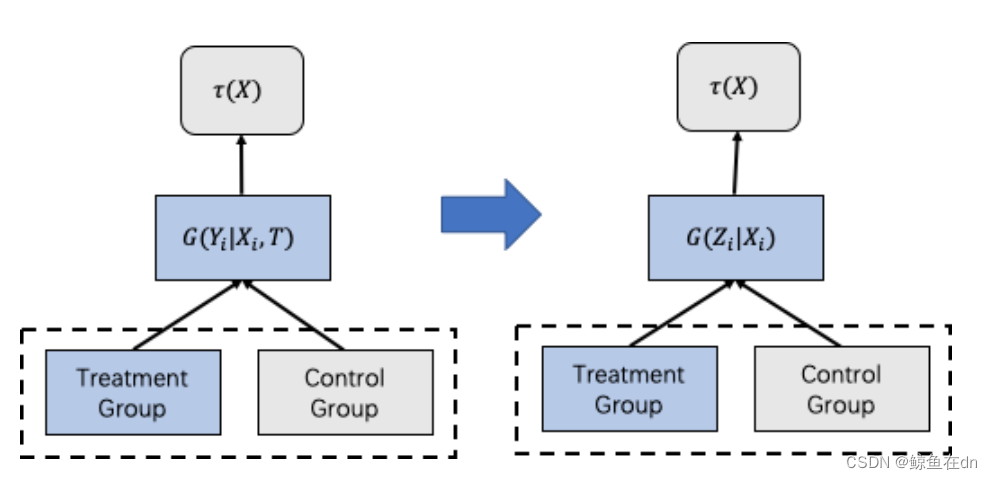
u p l i f t s o c r e = τ ( X ) = G T ( Y i ∣ X i ) − G C ( Y i ∣ X i ) uplift\ socre = \tau(X) = G^T(Y_i | X_i) - G^C(Y_i | X_i) uplift socre=τ(X)=GT(Yi∣Xi)−GC(Yi∣Xi)
- 模型 G T G^T GT 用来学习用户在有干预策略影响下的响应,另外一个模型 G C G^C GC用来学习用户在没有干预策略下的响应, Y i Y_i Yi是预测的输出, X i X_i Xi是用户特征。
- 对于预测组数据,分别过两个模型,将得到的模型预测分数做差,就得到uplift score。
- 在实际中以uplift score进行排序,由其高低决定是否进行干预。虽然两个模型单独训练容易累计误差传递到uplift score,但是考虑到实现简单迅速,可以将其作为baseline。


2)优缺点
- 优点:是原理比较简单直观,可以快速实现,可以直接套用现有的模型(LR/GBDT/NN)。
- 缺点:因为两个模型的精度不一定非常高,所以两个模型的误差会有叠加,并且因为有差分的操作,这是间接计算的增量。
2、S-Model,一个模型,将干预信号放在特征中
参考文章:阿里文娱智能营销增益模型 ( Uplift Model ) 技术实践
基于Two Model的差分响应模型,训练数据和模型都是相互独立,那么是否可以进行模型统一和数据共享呢?答案是肯定的,那就是基于One Model的差分响应模型,那么问题来了,数据共享、模型统一,怎么学习干预组合非干预组样本的差异呢?在阿里文娱中提到一种方法:在特征维度进行扩展,引入干预信号相关特征T(T为0代表干预组,否则为非干预组,T同样可以扩展为0-N,建模multiple-treatment问题,比如优惠券的不同额度,广告的不同素材)
1)模型原理 & 建模步骤
u p l i f t s o c r e = τ ( X ) = G T ( Y i ∣ X i , T = 1 ) − G C ( Y i ∣ X i , T = 0 ) uplift\ socre = \tau(X) = G^T(Y_i | X_i,T=1) - G^C(Y_i | X_i,T=0) uplift socre=τ(X)=GT(Yi∣Xi,T=1)−GC(Yi∣Xi,T=0)
这里的 T T T表示是否干预,作为特征传入模型中。

2) 优缺点
优点:
- 可以直接套用现有的分类模型
- 训练数据共享,模型学习更充分
- 避免双模型误差累积
- 通过一个模型可以对multiple-treatment进行建模,实用性更强
缺点: - 基础模型仍是响应模型,对uplift的建模是间接的,模型效果还有提升空间
3、标签转换
参考文章:Uplift-Model在贝壳业务场景中的实践
即使基于One Model的差分响应模型在训练数据和模型层面上打通,但其本质还是对于uplift的间接建模,更为严谨的一种实现实验组和对照组数据和模型打通的方法是:标签转换方法(Class Transformation Method),可以直接对 τ ( X i ) τ(X_i) τ(Xi)进行建模。
1)模型原理& 建模步骤
在二分类的情况下,这种方法的目标函数形式为
Z i = Y o b s T i + ( 1 − Y o b s ) ( 1 − T i ) Z_i = Y^{obs}T_i + (1-Y^{obs})(1-T_i) Zi=YobsTi+(1−Yobs)(1−Ti)
其中 Z i ∈ 0 , 1 Z_i∈{0,1} Zi∈0,1是转化后的标签,转化规则如下:
Z = { 1 i f T = 1 a n d Y = 1 1 i f T = 0 a n d Y = 0 0 o t h e r Z=\left\{ \begin{array}{ll} 1 \ \ if\ T=1\ and\ Y=1\\ 1 \ \ if\ T=0\ and\ Y=0\\ 0 \ \ other \end{array} \right. Z=⎩
⎨
⎧1 if T=1 and Y=11 if T=0 and Y=00 other
可以看到当用户处于实验组且转化和处于对照组未转化的用户对应的标签为1,其余对应标签为0,那这样优化目标就变成P(Z=1|X),引用的文章中有详细的数学证明,证明优化P(Z=1|X)就相当于优化τ(X),感兴趣的朋友可以自己看。
注意,标签转换要满足两个假设:
- 用户特征和干预策略相互独立
- 用户被分到实验组和对照组的概率一致P(T)=P©=0.5
第一个假设一直是我们强调的很好理解,第二个假设(个体对对照组和实验组的倾向必须一样)看似非常严格,幸运的是,可以通过一些转换操作来解决实验组和对照组的个人倾向不同的问题。最简单的方式就是对数据进行重采样使得数据满足假设,即使不满足也可以通过引入用户倾向分来进行调整,用户倾向分的证明方式见引用的文章。
4、Tree-base model
参考文章:董彦燊:因果推断在哈啰出行的实践探索
4.1 模型原理&模型优点
把基于决策树的Uplift模型和普通分类决策树放在一起做个比较,二者主要不同在分裂的准则和目标。普通的决策树的分裂准则是信息增益,这样使得叶子节点的信息熵最少、类别的不确定性最小,以达到分类的目的;而基于决策树的Uplift模型的分类准则是分布散度,比如常用的有kl散度、卡方散度,这样可以使叶子节点中干预组和无干预组的分布差异最大,来达到提升增益的目的。
基于决策树的模型的优点:
① 树模型解释性比较强,这点对业务的应用比较有帮助。
② 直接对增量建模的准确性更高,对业务的提升是我们最关心的事情。

4.2、哈罗改进后的TreeCausal,算法流程

这里我们是以效用作为样本的label,那么以干预组和无干预组的人均效用的差值的平方作为节点的分裂准则,这里的目标是最大化人均效用差值的平方。
算法流程:
第一步,假设分裂前的数据集为theta,那么计算分裂前发券组和无券组样本人均效用的差异。这里我们效用的差异是这样定义的。G是每一个用户的label。我们对有干预组的每个人的效用做求和,再除以干预组的样本数,得到人均效用,再减去无干预组。这个差值做平方,这样可以计算出分裂前的效用差异。
第二步,根据某个特征f将数据集theta分成左右两个子集theta1和theta2,计算分裂后的人均效用差异,可以看一下右边的示意图。如果特征的值等于f,就可以分到左子集,如果不等于f,可以得到右子集。接着对每一个子集都计算人均效用的差异,再根据每一个子集的样本比例作为权重,加权求和,最终得到计算差异。
第三步,计算增益。分裂后的人均效用差异减去分裂前的人均效用差异,得到增益。
第四步,遍历数据集theta中所有的特征值,重复进行第二步、第三步,我们会得到很多对应不同特征值的增益。我们取增益最大时对应的特征值,作为节点的分裂值,将数据集分为左子集和右子集。
第五步,递归调用,对左子集和右子集再重复上述步骤,生成Treelift模型。
二、模型评估方法:Qini曲线,AUUC
2.1、Qini曲线
Qini 曲线是衡量 Uplift Model 精度方法之一,通过计算曲线下的面积,类似 AUC 来评价模型的好坏。其计算流程如下
(1) 在测试集上,将实验组和对照组分别按照模型预测出的增量由高到底排序,根据用户数量占实验组和对照组用户数量的比例,将实验组和对照组分别划分为十份,分别是 Top10%, 20%, . . . , 100%。
(2) 计算 Top10%,20%,…,100% 的 Qini 系数,生成 Qini 曲线数据 (Top10%,Q(Top10%)),(…,…), (Top100%, Q(Top100%))。Qini 系数定义如下:
Q ( i ) = n t , y = 1 ( i ) N t − n c , y = 1 ( i ) N c , i = 10 % , 20 % , . . . , 100 % Q(i) = \frac{n_{t,y=1}(i)}{N_t} - \frac{n_{c,y=1}(i)}{N_c},\ \ i=10\%,20\%,...,100\% Q(i)=Ntnt,y=1(i)−Ncnc,y=1(i), i=10%,20%,...,100%
其中, N t N_t Nt和 N c N_c Nc表示实验组和对照组的总样本量。当i取10%时, n t , y = 1 ( i ) n_{t,y=1}(i) nt,y=1(i)表示实验组uplift分数前10%用户中下单的用户数量, n c , y = 1 ( i ) n_{c,y=1}(i) nc,y=1(i)表示对照组中uplift分数前10%用户中下单的用户数量。
可以看出,Qini 系数分母是实验组和对照组的总样本量,如果实验组和对照组用户数量差别比较大,结果将变得不可靠。
2.2、AUUC
AUUC(Area Under the Uplift Curve) 的计算流程与 Qini 曲线的计算流程一样,计算前 10%、20%、. . . 、100% 的指标,绘制曲线,然后求曲线下的面积,衡量模型的好坏。
G ( i ) = ( n t , y = 1 ( i ) n t ( i ) − n c , y = 1 ( i ) n c ( i ) ) ( n t ( i ) + n c ( i ) ) , i = 10 % , 20 % , . . . , 100 % G(i) = (\frac{n_{t,y=1}(i)}{n_t(i)} - \frac{n_{c,y=1}(i)}{n_c(i)})(n_t(i)+n_c(i)),\ \ i=10\%,20\%,...,100\% G(i)=(nt(i)nt,y=1(i)−nc(i)nc,y=1(i))(nt(i)+nc(i)), i=10%,20%,...,100%
当i取10%时, n t ( i ) n_t(i) nt(i)表示实验组前10%用户数量, n c ( i ) n_c(i) nc(i)表示对照组前10%用户数量,可以看出,AUUC 指标计算方法可以避免实验组和对照组用户数量差别较大导致的指标不可靠问题。
值得注意的是,当分桶时,对照组边界点预估出的增量与实验组边界点的预估值有较大差别时候,以上的两个评估指标似乎都显得不那么可靠了。 因此在实际中,我们使用的往往是 AUUC 另外的一种计算方法。
我们将实验组和对照组放在一起根据增量值从高到低排序,将数据划分为N份,计算前1、2、……、N的指标,其中N为实验组和对照组的样本总和。当i=10时, n t , y = 1 ( i ) n_{t,y=1}(i) nt,y=1(i)表示前10个用户中用户属于实验组且下单的用户数量, n c , y = 1 ( i ) n_{c,y=1}(i) nc,y=1(i)表示前10个用户中用户属于对照组且下单的用户数量; n t ( i ) n_t(i) nt(i)表示前10个用户中属于实验组的用户数量, n c ( i ) n_c(i) nc(i)表示前10个用户中,用户属于对照组的用户数量。
2.3、AUUC的理解(对比auuc与auc)
AUUC 是一个很重要且奇怪的指标。说重要,是因为它几乎是 Uplift Model 在离线阶段唯一一个直观的,可解释的评估模型优劣的指标。说奇怪,是因为它虽然本质上似乎借鉴了分类模型评价指标 AUC 的一些思想,但是习惯了 AUC 的算法工程师们在初次接触的时候一定会被它搞得有点迷糊。
作为在分类模型评估上的标杆,AUC 的优秀不用过多赘述。其中最优秀的一点是它的评价结果稳定到可以超越模型和样本本身而成立,只要是分类问题,AUC0.5 是随机线,0.6 的模型还需要迭代一下找找提升的空间,0.6-0.8 是模型上线的标准,而 0.9 以上的模型就需要考虑一下模型是否过拟合和是否有未知强相关特征参与了模型训练。 一法抵万法,我们可以抛开特征,样本和模型构建的细节而直接套用这套准则。
然而这个特点对于 AUUC 就完全是奢望了。通过 AUUC 的公式可以看出,AUUC 最终形成的指标的绝对值大小是取决于样本的大小的。也就是说,在一套测试样本上,我们的 AUUC 可能是 0 到 1W,而换了一套样本,这个值可能就变成了 0 到 100W。这使得不同测试样本之间模型的评估变为了不可能。也使得每次模型离线的迭代的前提必须是所有模型都使用同一套测试样本。当我们训练完一个新的模型,跑出一个 40 万的 auuc,我们完全无从得知这个值背后代表着模型精度如何,我们只能拿出旧的模型在同样测试集上跑出 auuc 然后相互比较。这无疑让整个训练迭代过程变得更痛苦了一点。
三、T-learner代码实现示例
T-learner 、标签转换的代码地址:https://github.com/PGuti/Uplift
四、参考文章汇总
参考文章1:Uplift-Model在贝壳业务场景中的实践
参考文章2:阿里文娱智能营销增益模型 ( Uplift Model ) 技术实践
参考文章3:董彦燊:因果推断在哈啰出行的实践探索
参考文章4:DiDi Food 中的智能补贴实战漫谈
参考文章5:https://blog.csdn.net/u0/article/details/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/87063.html