
模型的训练需要大量的音频。所以我首先搜集了eason百多首wav的歌曲。鉴于国语与粤语的区别,因此我只选择了其中44首国语歌曲,尝试训练一下国语版的eason。(其实我更喜欢easonde粤语歌。)
下载好歌曲之后,需要去除背景音乐,得到纯净的人声。尝试自己构建模型过于复杂,音频剪辑的软件不方便批量操作。
这里需要用到一个github上开源的工具--slpeeter。通过这个工具,可以直接去分离人声与背景音乐,非常方便。效果也不错,分离速度也很快。下载不易,我将文件打包整理在百度网盘中,分享在文末。
这个工具有gui版的,下载之后直接打开。双击该gui应用程序即可。
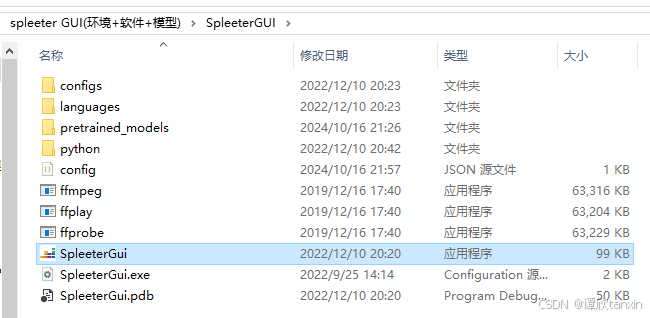
另外,分离背景音乐与人声需要用到该工具下的双声道模型。即下图中的2stems。将压缩包解压后将其中的模型复制到SpleeterGUI文件夹中的pretrained_models文件夹中(见上图)。
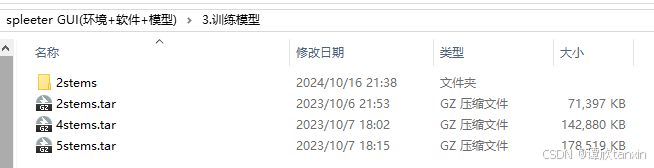

gui界面的使用:
parts to separate选择2,表示分离出两个声道。即背景音乐与人声。
save to:选择自己想要保存的路径即可。
带宽与音频时长默认即可。
将需要处理的音频文件直接拖到这个工具界面即可。
处理完之后会得到一个文件夹,文件夹包含两个音频文件。一个音频文件表示伴奏,一个表示人声(vocals)。
分离的效果还不错。
SpleeterGUI工具分享:
链接:https://bianchenghao.cn/s/1dR7wIRV9oQPrHuJxIv78-w?pwd=r1dr
提取码:r1dr
--来自百度网盘超级会员V5的分享
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/88860.html