
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的人声和背景音乐分离算法系统
课题背景和意义
随着多媒体技术的快速发展,音频处理技术在生活中扮演着越来越重要的角色。其中,人声和背景音乐的分离是音频处理领域的一大挑战,尤其在音乐制作、语音识别和会议记录等领域具有广泛的应用前景。
实现技术思路
一、算法理论基础
1.1 语音分离算法
全连接神经网络是一种基本的神经网络模型,具有参数最多和计算量大的特点。它一般由输入层、隐藏层和输出层组成。其中,输入层和输出层仅各有一层,而隐藏层可由多个网络层组成。每个网络层中都含有许多神经,相邻的网络层之间的神经相互连接,而同层的神经互不相连。全连接神经网络根据隐藏层的数量,又可分为浅层神经网络和深度神经网络。其中,深度神经网络的隐藏层数量至少大于2。深度神经网络相较于浅层神经网络具有更强的表达能力,且能够拟合成所有映射函数,但是深度神经网络的参数数量一般较多,不易训练,需要大量的数据集。
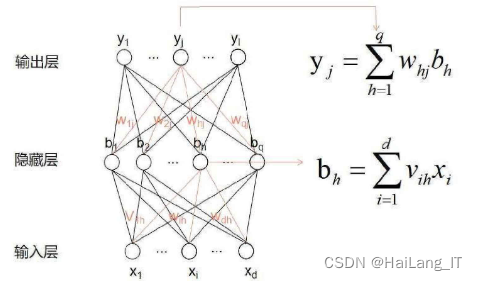
算法流程:
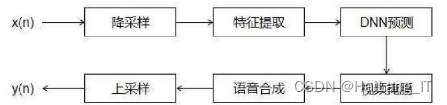
- 对输入的音频信号进行降采样操作,将信号从44.1 kHz降低到16 kHz。这是因为44.1 kHz是录音棚标准,而16 kHz是录音机能够接收的最低标准,在这个采样率下人耳能够得到清晰的音频信号,同时也减小了数据处理的时间。
- 接下来是特征提取阶段,选择耳蜗时频图作为特征输入,即将降采样后的音频信号通过Gabor滤波器得到。此时获得的输入向量的长度和宽度分别为(23,64)。
- 随后将得到的特征图输入到全连接神经网络中,该网络共有5层网络,每层包含2048个神经,并结合ReLU作为激活函数。
- 预测过程选择理想浮值掩膜作为预测目标,对传入的每一帧进行5次预测,并将5次的平均值作为结果,最后再乘以耳蜗时频图即可得到输出的结果。
- 为避免过拟合,在每一层的输出之后还增加了dropout层,dropout层以0.2的概率随机断开连接。
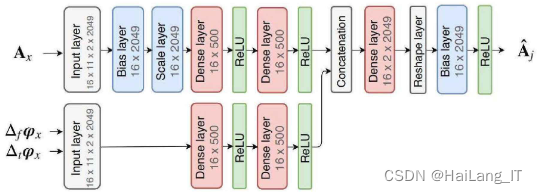
振幅与相位相结合的DNN神经网络包括上半部分和下半部分。上半部分网络处理振幅特征,首先通过偏置层和归一化层对特征进行处理,然后将处理后的数据输入到由500个隐藏层单组成的两个全连接层中进行特征提取。下半部分处理相位特征,它以时间和频率的导数作为输入,同样经过两个全连接层后,将前两个网络的输出进行堆叠,并生成幅度估计值。后续的偏置层和ReLU非线性函数也对这些幅度估计值进行归一化。
1.2 卷积神经网络
深度学习在计算机领域快速发展,并成为目前最热门的研究方向。卷积神经网络作为最基础的神经网络类型之一,经过进一步的发展,在图像识别领域展现了不可替代的作用。卷积神经网络的出现首次解决了全连接网络存在的一些问题,例如参数众多导致训练效率低下以及在图像特征提取时信息丢失的问题。卷积神经网络由三部分构成:卷积层、池化层和全连接层。卷积层的作用是通过扫描所有图像信息,提取出实验所需的全部局部特征;池化层利用降维的操作减少特征信息的冗余,可以提高训练的效率;最后全连接层将上述所有网络层输出的数据进行分析,实现最后的图像分类或识别。
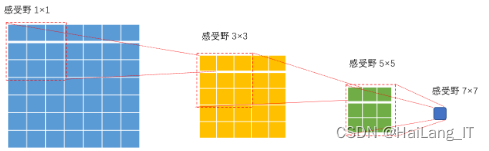
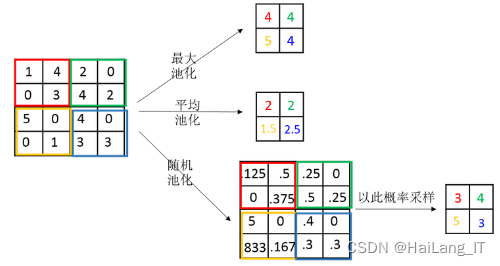
池化层出现在连续的卷积层之间,并常常被间接插入。池化层的操作类似于卷积层,通过池化核在整幅特征图上滑动,得到缩减特征后的特征图。常见的池化层包括最大池化和平均池化,最大池化选择池化区域内的最大值作为该区域的输出结果,平均池化计算池化区域内的平均值作为该点的输出结果。池化层的操作很好地减少了卷积层的数据表示,有效控制了数据体量,减少了网络中的参数数量,也能够有效防止过拟合。
1.3 人声分离
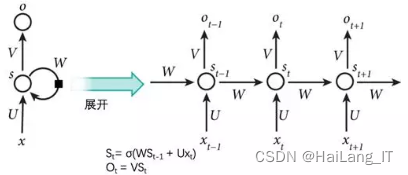
循环神经网络(RNN)是一种具有循环连接的神经网络结构,能够对序列数据进行建模和处理。相比于前馈神经网络,RNN在处理序列数据时考虑了时间上的依赖关系。RNN的关键特点是引入了循环连接,使得网络中的隐藏状态可以传递到下一个时间步,从而使网络能够捕捉到序列数据中的时序信息。每个时间步,RNN接收当前输入和前一个时间步的隐藏状态,并通过学习得到的权重进行信息传递和计算。这种循环连接的设计使得RNN能够具有记忆能力,对过去的输入进行记忆并影响当前的输出。
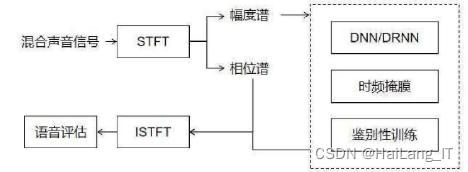
将单通道音频信号m分离为人声信号si和背景音乐信号s2。模型使用了MIR-1K数据集,该数据集包含1000个歌曲片段,其中歌手声音和背景音乐声音分别存放在不同的声道中,所有歌曲采用16kHz采样率的wav格式。处理流程:首先,将左右声道的人声和背景声混合为mixturesignal。然后,通过短时傅里叶变换获得混合音频信号的振幅谱和相位谱,傅里叶变换的时长选择为64ms,偏移量为32ms。混合音乐的振幅谱可以通过右侧虚线框中的分离模型得到分离出的伴奏和人声。随后,通过逆傅里叶变换将得到的伴奏和人声转换为我们可以听到的音频信号。
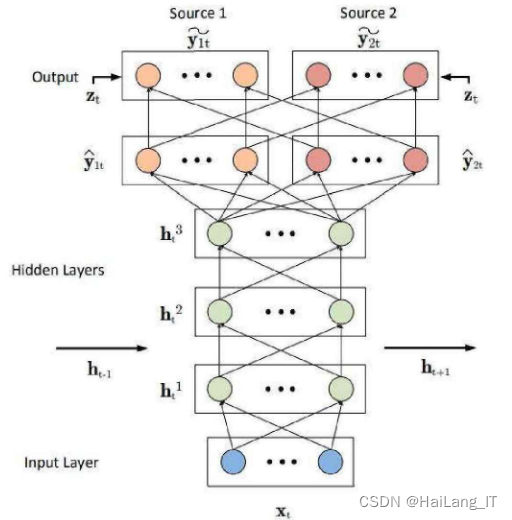
在人声分离模型中,使用了DNN/DRNN作为循环层,总共有三个循环层作为隐藏层,每层有1000个神经。最后一个隐藏层将结果输入到两个全连接层中。DRNN能够有效地分离出人声和背景音乐的一个关键点是利用了时频掩蔽技术。当人声和伴奏声通过DRNN模型的第一个全连接层时,得到的值是丸和i2t,该层称为浮值掩膜层。随后,模型通过人声与背景音乐的初始预算值计算出浮值掩膜,再用掩膜和原始音乐相乘得到模型的输出结果。
这个分离模型利用深度循环网络的结构和时频掩蔽技术,能够有效地分离出人声和背景音乐。隐藏层的循环结构允许模型捕捉音频数据中的时序信息,而浮值掩膜层和掩膜相乘操作则实现了对音频信号的频域信息进行控制和分离。
二、 数据集
2.1 数据集
为了构建这一算法系统,我首先需要一个合适的数据集进行模型训练。由于网络上缺乏现成的、针对人声和背景音乐分离的数据集,我决定自制一个数据集。我录制了多段包含人声和背景音乐的音频,并对这些音频进行了精细的标注,以便模型能够学习到准确的人声和背景音乐特征。此外,我还采用了数据增强技术,如音频混合、噪声添加等,以增加数据集的多样性和模型的泛化能力。
2.2 数据扩充
在数据扩充方面,我采用了多种技术来增加数据集的多样性和规模。首先,我对原始音频进行了不同程度的裁剪和混合,以生成更多具有不同特性的样本。其次,我引入了噪声和混响等干扰因素,以模拟真实环境中的复杂音频条件。最后,我还采用了数据重采样技术,将不同采样率的音频统一到同一采样率下,以确保模型能够处理不同来源的音频数据。
def crop_and_mix_audio(input_audio_path, output_dir): audio = AudioSegment.from_file(input_audio_path) audio_duration = len(audio) / 1000 # 音频时长(秒) for crop_length in crop_lengths: if crop_length > audio_duration: continue crop_start = random.uniform(0, audio_duration - crop_length) crop_end = crop_start + crop_length cropped_audio = audio[int(crop_start * 1000):int(crop_end * 1000)] cropped_audio = normalize(cropped_audio) # 归一化音频 for mix_ratio in mix_ratios: # 随机选择另一个音频进行混合 mix_audio_path = random.choice(os.listdir(output_dir)) mix_audio = AudioSegment.from_file(os.path.join(output_dir, mix_audio_path)) # 调整混合音频的长度和音量 mix_audio = mix_audio[:len(cropped_audio)] mix_audio = normalize(mix_audio)三、实验及结果分析
PyQt5作为Python和Qt两个技术的融合产物,在兼容性方面体现出了与Python的良好兼容性。同时,它也具备Qt强大的GUI库功能,能够胜任美观、复杂的界面开发。PyQt5拥有多个类和函数方法,作为一个跨平台库,几乎可以在所有平台上运行,包括Windows、Unix和macOS。
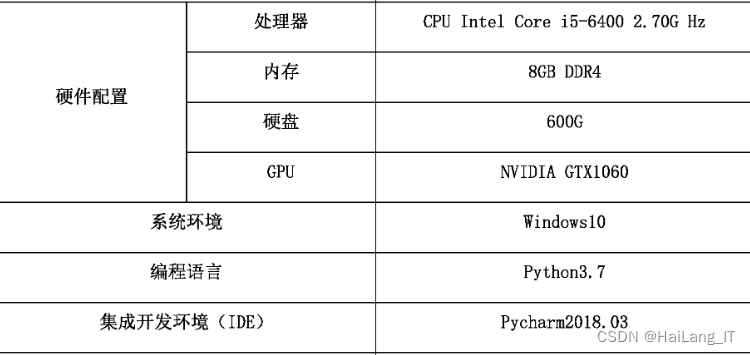
相关代码示例:
import numpy as np import tensorflow as tf # 加载模型 model = tf.keras.models.load_model('path_to_model') # 加载音频文件 audio_data = np.load('path_to_audio_file') # 预处理音频数据 preprocessed_data = preprocess_audio(audio_data) # 进行人声分离 separated_data = model.predict(preprocessed_data) # 后处理分离后的数据 postprocessed_data = postprocess_audio(separated_data) # 保存分离后的音频文件 save_audio(postprocessed_data, 'path_to_output_file')海浪学长项目示例:





最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
今天的文章 毕业设计:基于深度学习的人声和背景音乐分离算法系统分享到此就结束了,感谢您的阅读。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/97580.html