
文章的背景取自An Introduction to Gradient Descent and Linear Regression,本文想在该文章的基础上,完整地描述线性回归算法。部分数据和图片取自该文章。没有太多时间抠细节,所以难免有什么缺漏错误之处,望指正。
线性回归的目标很简单,就是用一条线,来拟合这些点,并且使得点集与拟合函数间的误差最小。如果这个函数曲线是一条直线,那就被称为线性回归,如果曲线是一条二次曲线,就被称为二次回归。数据来自于GradientDescentExample中的data.csv文件,共100个数据点,如下图所示:
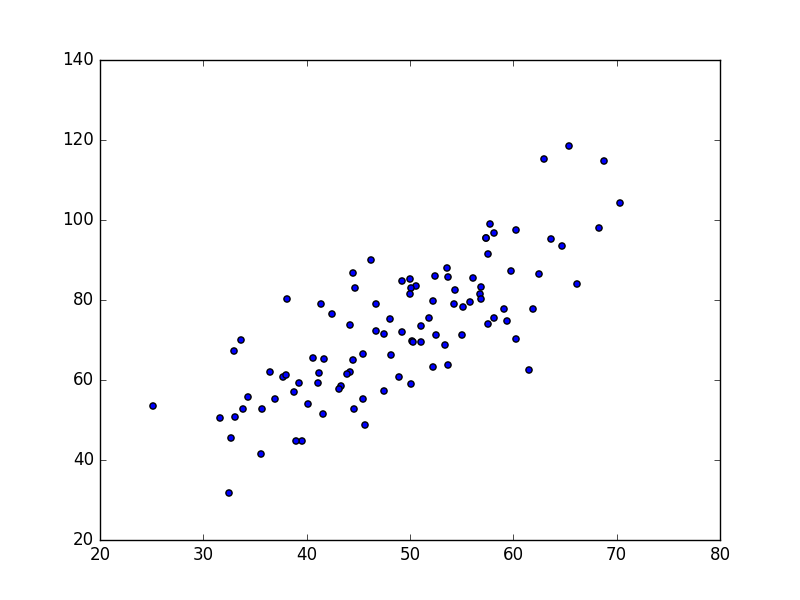
我们的目标是用一条直线来拟合这些点。既然是二维,那么这个公式相信对于中国学生都很熟悉。其中是直线在y轴的截距(y-intercept),是直线的斜率(slope)。寻找最佳拟合直线的过程,其实就是寻找最佳的和的过程。为了寻找最佳的拟合直线,这里首先要定义,什么样的直线才是最佳的直线。我们定义误差(cost function):
计算损失函数的python代码如下:
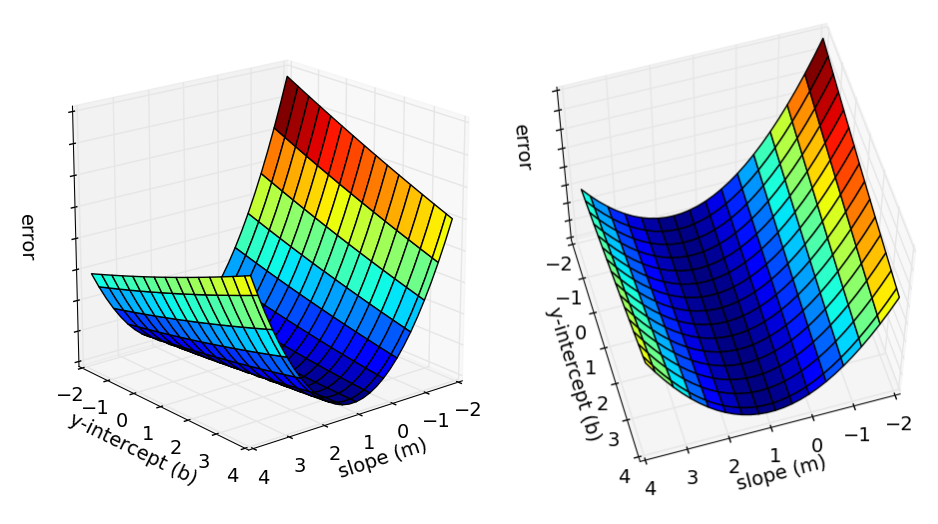
现在问题被转化为,寻找参数和,使得误差函数有最小值。在这里,和都被视为已知值。从下图看,最小二乘法所做的是通过数学推导直接计算得到最低点;而梯度下降法所做的是从图中的任意一点开始,逐步找到图的最低点。
从机器学习的角度来说,以上的数据只有一个feature,所以用一元线性回归模型即可。这里我们将一元线性模型的结论一般化,即推广到多元线性回归模型。这部分内部参考了机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)。假设有,,, 共个feature,为的系数,则
更一般地,我们可以得到广义线性回归。可以换成不同的函数,从而得到的拟合函数就不一定是一条直线了。
2.1 误差函数的进一步思考
这里有一个有意思的东西,就是误差函数为什么要写成这样的形式。首先是误差函数最前面的系数,这个参数其实对结果并没有什么影响,这里之所以取,是为了抵消求偏导过程中得到的。可以实验,把最前面的修改或者删除并不会改变最终的拟合结果。那么为什么要使用平方误差呢?考虑以下公式:
假定误差是独立同分布的,由中心极限定理可得,服从均值为,方差为的正态分布(均值若不为0,可以归约到)。进一步的推导来自从@邹博_机器学习的机器学习课件。
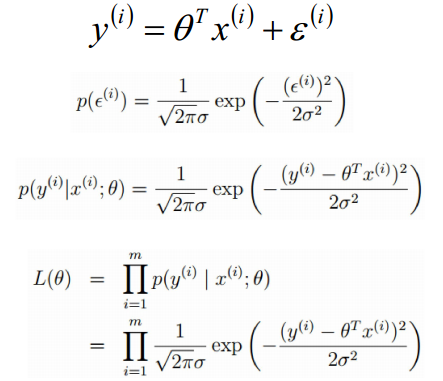
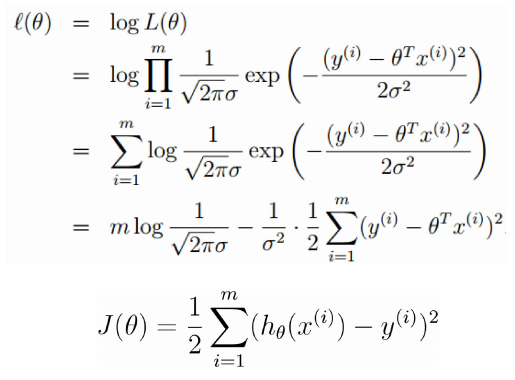
所以求的过程,就变成了求的过程,从理论上解释了误差函数的由来。
最小二乘法(normal equation)相信大家都很熟悉,这里简单进行解释并提供python实现。首先,我们进一步把写成矩阵的形式。为行列的矩阵(代表个样本,每个样本有个feature),和为行列的矩阵。所以
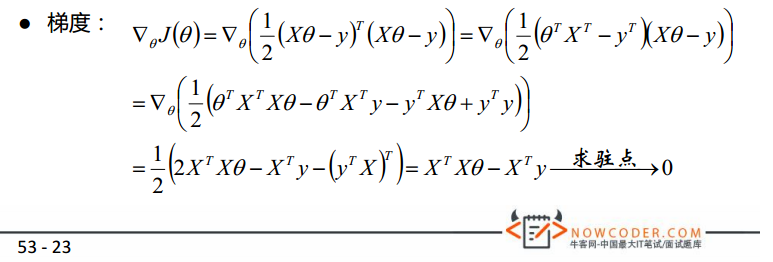
所以的最优解为:。
当然这里可能遇到一些问题,比如必须可逆,比如求逆运算时间开销较大。具体解决方案待补充。
3.1 python实现最小二乘法
这里的代码仅仅针对背景里的这个问题。部分参考了回归方法及其python实现。
程序执行结果如下:
b = 7.99102098227, m = 1.32243102276, error = 110.257383466, 相关系数 = 0.773728499888
拟合结果如下图:
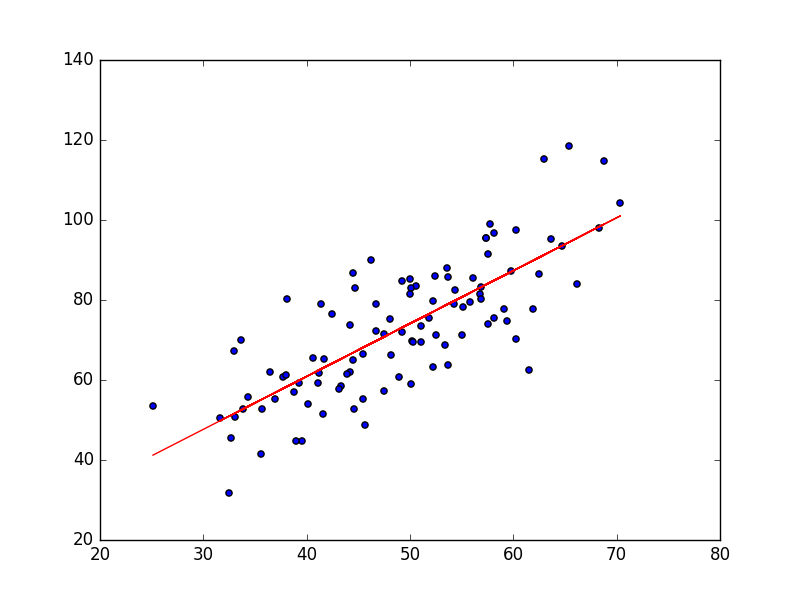
有了最小二乘法以后,我们已经可以对数据点进行拟合。但由于最小二乘法需要计算的逆矩阵,计算量很大,因此特征个数多时计算会很慢,只适用于特征个数小于100000时使用;当特征数量大于100000时适合使用梯度下降法。最小二乘法与梯度下降法的区别见最小二乘法和梯度下降法有哪些区别?。
4.1. 梯度
首先,我们简单回顾一下微积分中梯度的概念。这里参考了方向导数与梯度,具体的证明请务必看一下这份材料,很短很简单的。
讨论函数在某一点沿某一方向的变化率问题。设函数在点的某一邻域内有定义,自点引射线到点且,如下图所示。
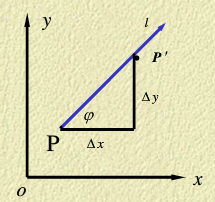
定义函数在点沿方向的方向导数为:
方向导数可以理解为,函数沿某个方向变化的速率。可以类比一下函数的斜率。斜率越大,函数增长得越快。那么现在问题来了,函数在点沿哪个方向增加的速度最快?而这个方向就是梯度的方向
从几何角度来理解,函数表示一个曲面,曲面被平面截得的曲线在平面上投影如下图,这个投影也就是我们所谓的等高线。

函数在点处的梯度方向与点的等高线在这点的法向量的方向相同,且从数值较低的等高线指向数值较高的等高线。
4.2 梯度方向计算
理解了梯度的概念之后,我们重新回到1. 背景中提到的例子。1. 背景提到,梯度下降法所做的是从图中的任意一点开始,逐步找到图的最低点。那么现在问题来了,从任意一点开始,和可以往任意方向”走”,如何可以保证我们走的方向一定是使误差函数减小且减小最快的方向呢?回忆4.1. 梯度中提到的结论,梯度的方向是函数上升最快的方向,那么函数下降最快的方向,也就是梯度的反方向。有了这个思路,我们首先计算梯度方向,
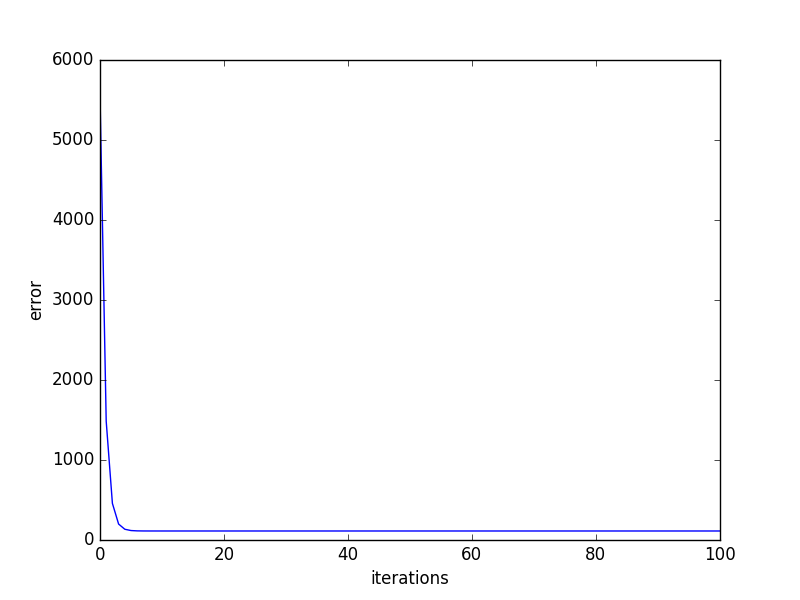
有了这两个结果,我们就可以开始使用梯度下降法来寻找误差函数的最低点。我们从任意的点开始,逐步地沿梯度的负方向改变和的值。每一次改变,都会得到更小的值,反复进行该操作,逐步逼近的最低点。
回到更一般的情况,对于每一个向量的每一维分量,我们都可以求出梯度的方向,也就是错误函数下降最快的方向:
4.3 批量梯度下降法
从上面的公式中,我们进一步得到特征的参数的迭代式。因为这个迭代式需要把m个样本全部带入计算,所以我们称之为批量梯度下降
针对此例,梯度下降法一次迭代过程的python代码如下:
其中learningRate是学习速率,它决定了逼近最低点的速率。可以想到的是,如果learningRate太大,则可能导致我们不断地最低点附近来回震荡; 而learningRate太小,则会导致逼近的速度太慢。An Introduction to Gradient Descent and Linear Regression提供了完整的实现代码GradientDescentExample。
这里多插入一句,如何在python中生成GIF动图。配置的过程参考了使用Matplotlib和Imagemagick实现算法可视化与GIF导出。需要安装ImageMagick,使用到的python库是Wand: a ctypes-based simple ImageMagick binding for Python。然后修改C:Python27Libsite-packagesmatplotlib__init__.py文件,在
后面加上:
即可在python中调用ImageMagick。如何画动图参见Matplotlib动画指南,不再赘述。
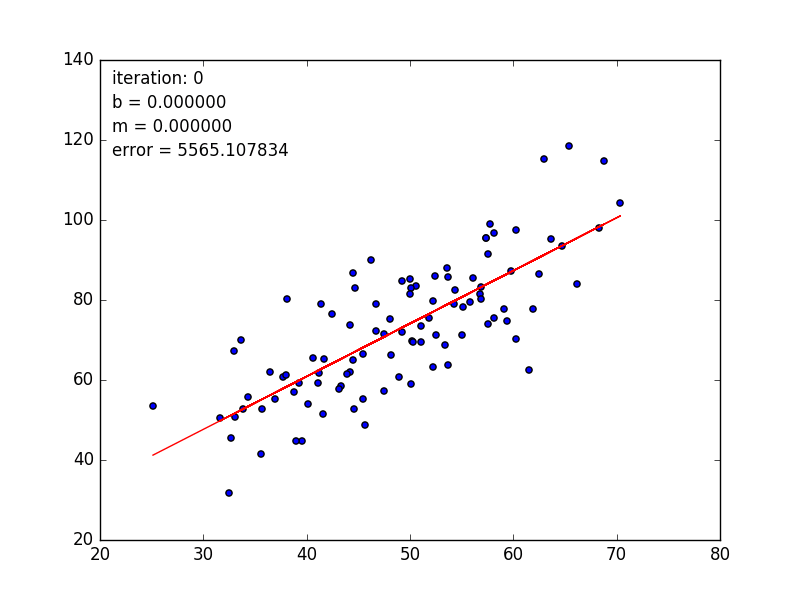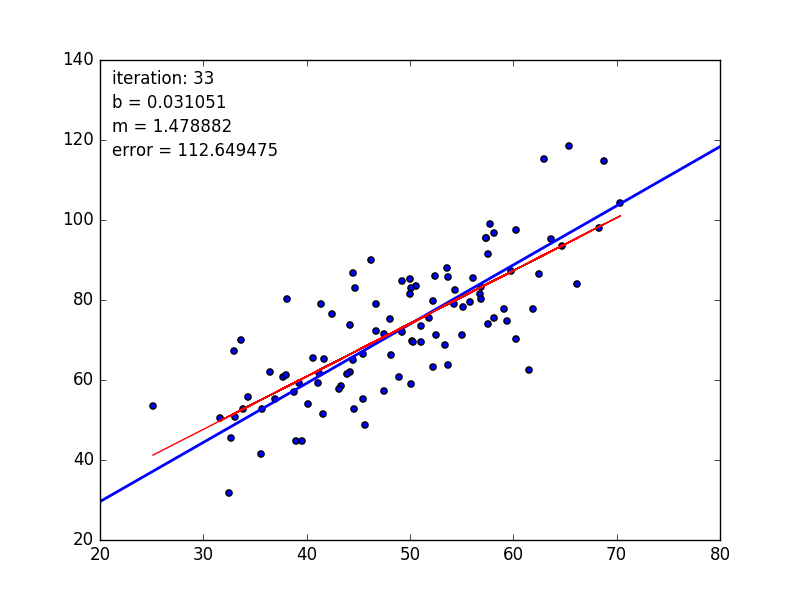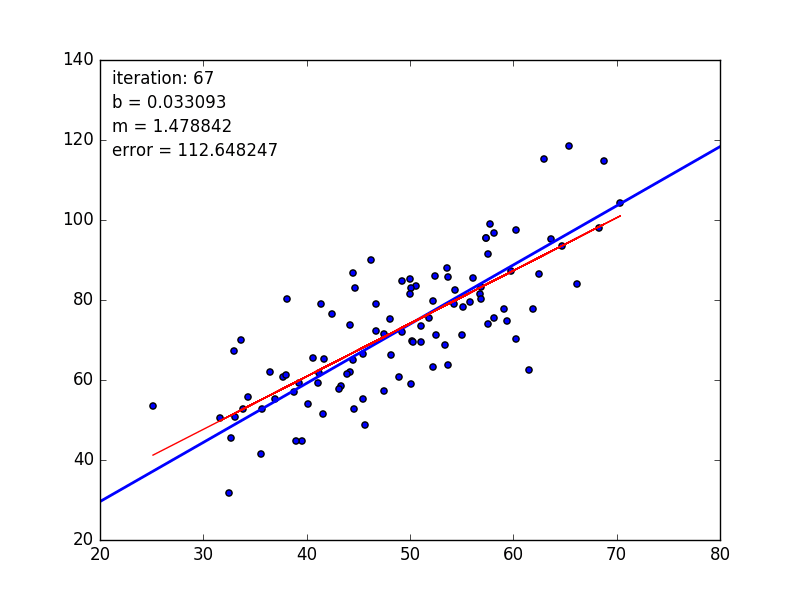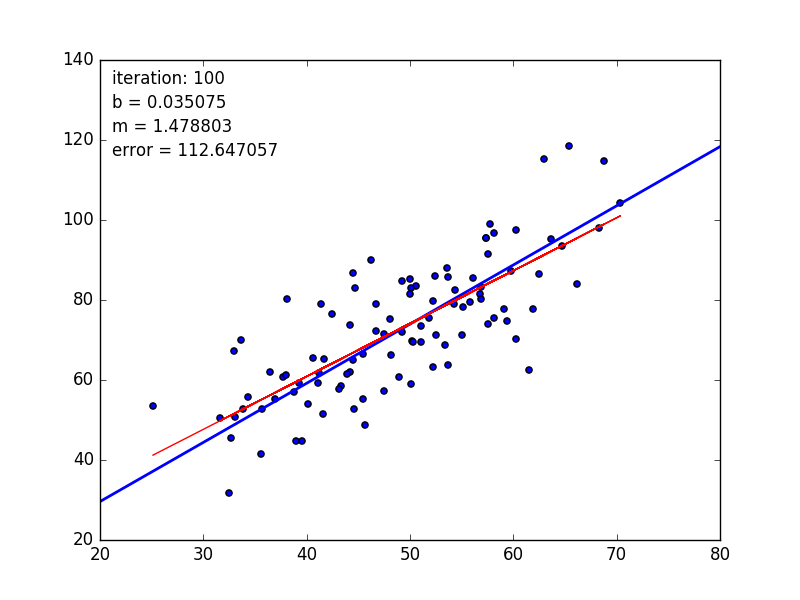
learningRate=0.0001,迭代100轮的结果如下图:
After {100} iterations b = 0.0350749705923, m = 1.47880271753, error = 112.647056643, 相关系数 = 0.773728499888
After {1000} iterations b = 0.0889365199374, m = 1.47774408519, error = 112.614810116, 相关系数 = 0.773728499888
After {1w} iterations b = 0.607898599705, m = 1.46754404363, error = 112.315334271, 相关系数 = 0.773728499888
After {10w} iterations b = 4.24798444022, m = 1.39599926553, error = 110.786319297, 相关系数 = 0.773728499888
4.4 随机梯度下降法
批量梯度下降法每次迭代都要用到训练集的所有数据,计算量很大,针对这种不足,引入了随机梯度下降法。随机梯度下降法每次迭代只使用单个样本,迭代公式如下:
可以看出,随机梯度下降法是减小单个样本的错误函数,每次迭代不一定都是向着全局最优方向,但大方向是朝着全局最优的。
这里还有一些重要的细节没有提及,比如如何确实learningRate,如果判断何时递归可以结束等等。
- An Introduction to Gradient Descent and Linear Regression
- 方向导数与梯度
- 最小二乘法和梯度下降法有哪些区别?
- GradientDescentExample
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
- @邹博_机器学习
- 回归方法及其python实现
- 使用Matplotlib和Imagemagick实现算法可视化与GIF导出
- Wand: a ctypes-based simple ImageMagick binding for Python
- Matplotlib动画指南
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/39655.html