
Ceph集群的检查可以简化为 MON 状态检查、OSD 状态检查和 PG 状态检查。上一章节我们重点介绍了 MON 的状态和维护方法。本章节将重点介绍 OSD 状态和块存储常用命令。
- Tips:如果是故障排查,请在确保 MON 状态正常的情况下进行 OSD 和 PG 状态检查。
- Tips:下面的简单理解只是为了方便理解,并不能完全代表实际名称的含义。
OSD: 全称 Object Storage Device,也就是负责响应客户端请求并返回具体数据的进程。一个 Ceph 集群一般都有很多个 OSD。可以简单理解为一块物理磁盘或分区。
Object:Ceph 最底层的存储单元是 Object 对象,每个 Object 包含元数据和原始数据。(简单理解:如果你上传了 1G 文件 file1,它将在客户端侧分割为默认 4M 大小的数据,每一个 4M 大小的数据就是一个 Object).
PG:全称 Placement Group,一般翻译为归置组,是一个逻辑的概念,一个 PG 包含多个 OSD 集合。引入 PG 这一层是为了让数据不直接指定后端 OSD,而是不直接绑定后端设备。
ceph的数据冗余有两种模式 副本(replicas)和 EC(纠删码),如果是副本模式,此时假定是3副本,则一个pg 对应osd集合是三个osd ,类似于pg 1.0 ->(osd1,osd2,osd3),此时pg1.0对应的副本分布存在于osd1和osd2和osd3上。
CRUSH: CRUSH 是 Ceph 使用的数据分布算法,算法分两步,第一步采用一致性hash来计算出pg,第二步则是计算出具体osd。
OSD 的守护进程只有运行和关闭两种状态,而 OSD 状态是指其在 Ceph 集群中的状态。分两个维度:
-
是否在集群中(in or out)(简单理解:osd 异常原因离线(down)300s内 ,则ceph会保留在集群内,超过300s ceph会自动将osd踢出集群,踢出去后状态为out。)
-
是否运行(up or down). (简单理解:ceph-osd 的守护进程是否运行,运行up ,否则down)
这两个维度是相互独立的因此有4种状态
问题1: 如何查看osd状态?
上面输出显示总共有3个osd, 3个osd处于 up,3个osd 处于in 状态。如果某osd down之后,怎么确定该osd处于哪个节点?
问题2: 查看osd对应的节点?

- Tips: 此时查看osd对应节点依赖crush map,crush 之后章节会做详细介绍。
之前文章我们提过分布式存储最大的特点就是要去中心化。如何做到去中心化了,ceph采用的方式就是一个字 算,那他是如何计算的了?网上有一大堆专业的文章给你来说明其是怎么计算的,这里我只想讲其算法的本质内容,力争让任何一个新手都能看懂的算法。
crush 算法的第一步将对象映射到对应的pg,crush 算法的第二部就是将pg 映射到对应osd集合。
首先会构造一个长度为0~2^32-1的整数空间,然后首尾相连,形成一个封闭的环,然后pg均匀分布在这个环里。
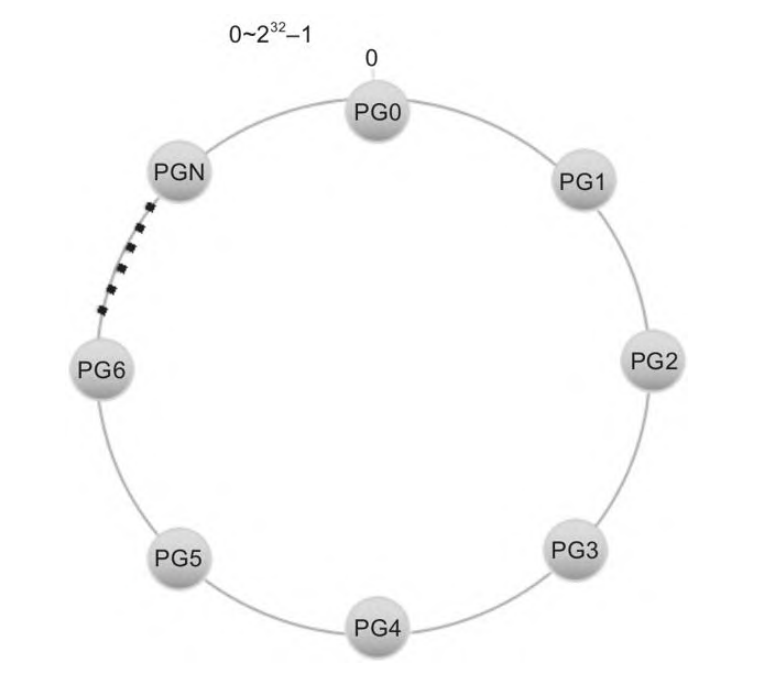
假设有一个对象名称为 my_large_object,其大小为 10MB。由于对象大于 4MB,Ceph 会将其切分成多个小对象。对于 10MB 的对象,分割方式如下:
- 切分
- 第一个对象:my_large_object.000(前 4MB)
- 第二个对象:my_large_object.001(接下来的 4MB)
- 第三个对象:my_large_object.002(最后的 2MB)
- 哈希运算:
对于每个切分后的对象,Ceph 使用一致性哈希算法进行哈希运算。
假设:
- my_large_object.000 的哈希值为 1234567890
- my_large_object.001 的哈希值为 0987654321
- my_large_object.002 的哈希值为 1122334455
-
获取 PG 数量:
假设该集群中有 128 个 PG(Placement Groups)。 -
取模运算:
- 对于第一个对象:1234567890 % 128 = 18,映射到 pg.18
- 对于第二个对象:0987654321 % 128 = 33,映射到 pg.33
- 对于第三个对象:1122334455 % 128 = 23,映射到 pg.23
映射到 PG:最终,Ceph 将每个小对象存储到对应的 PG 上:
my_large_object.000 存储到 pg.18
my_large_object.001 存储到 pg.33
my_large_object.002 存储到 pg.23
在实际的环境中pg是需要放在存储池(pool)中,存储池可以形象理解为一个目录而pg则是里面文件,其实无论是pg,还是pool都是逻辑概念,ceph实际上没有该实体。
问题3: 为什么需要单独设置pg这一逻辑概念?
按官方的文档的说法,就是为了使对象不直接指定后端的osd ,而找到pg问题的根源也变成了找到pg对应的osd。这样有什么好处了,因为osd 也就是磁盘会经常故障而需要替换,而pg做为逻辑概念可以保持相对固定。这样无论后端osd 怎么变化 pg位置是相对固定,pg 取模的值也相对固定。
tips: 这也同时告知我们集群的pg数需要提前规划,规划完成后尽量不要调整pg数量,一旦pg数据调整会造成大量数据的迁移和变更。
在实际的ceph集群中 pg是一个16进制数,刚才我们也说明了pg是存在存储池(pool)中,而存储池也是有一个编号{pool-num}的,默认是从1开始的非负正整数

如图所示第二列就是存储池的编号。而pg_num 则是存储池中pg的个数 。 {pool-num}.{pg-id} 就是pg的完整表示方式。
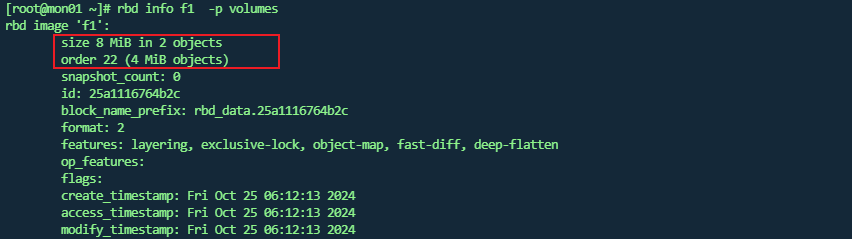
这里只是说有2个对象 ,对象大小为4MiB,并没有直观展示存储文件,事实上使用 rados 命令查看时没有看到类似00这样的文件。

这里主要是因为ceph 块存储是精简置备, 这里对该名称不做详细介绍,其实你只需要知道,精简置备的原则就是,随着文件的内容的扩容,该文件也是会不断变化的。
下面我们继续证明上述理论。
- 先删除原先的文件
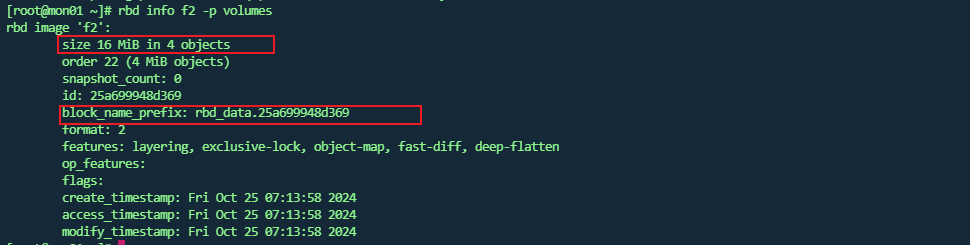
- 重新生成一个16M的文件f2
- 上传到volumes 存储池
- 查看存储池中的对象文件

-
rbd 查看块文件详情

此时 说明其文件存储前缀信息。通过上面图可以发现此时是没有 rbd_data.25a699948d369 这个文件的。 -
将块文件映射进Linux 内核中
此时会发现系统多了一个类似磁盘的设备/dev/rbd0此时就是f2文件的映射。
- 创建系统
- 挂载文件,并写入新文件写满16MB 文件
此时报错没有空间了,此时不要紧因为16M的文件,底层有一部分占用,实际可用是少于16M的


此时正好是4个文件。也就是证明之前我们所说的所有理论。也许小伙伴会问,你这么折腾的意义是什么?
个人观点:学习任何理论知识,要学以致用,实践是检验真理的唯一标准。 另一方面通过上述的操作也能让小伙伴们了解了如何使用ceph块存储,将ceph存储池文件映射进内核就是一个块设备,是不是十分简单。
下一张我们将重点介绍pg的状态,并结合实际例子来说明各种pg的状态详细含义,敬请期待。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ri-ji/5094.html