
BOF图像检索
参考1
参考2
图像检索
图像检索如今已经应用在很多的领域,生活中我们最常见的例子就是百度识图,我们输入一张图片,它就可以帮我们搜索到很多相类似的图片。那么问题来了,类似百度识图这种图像搜索引擎,它是怎么识别出我们输入的图片的呢?同时在识别出我们的图片后,它又是从哪里把类似的图片显示给用户的呢?这就是后面要解释的图像检索。
图像检索主要有两个方面,一个是基于文本的图像检索(TBIR),另一个是基于内容的图像检索(CBIR)。
基于文本的图像检索
基于文本的图像检索主要是利用文本标注的方式为图像添加关键词,这种方式需要人为给每一张图像标注,非常耗费人工。
基于内容的图像检索
基于内容的图像检索免去了人工标注。这种检索方式首先需要准备一个数据集(dateset)作为训练,通过某种算法提取数据集中每张图像的特征(SIFT特征)向量,然后将这些特征存储起来,组成一个数据库,当需要搜索某张图片的时候,就输入这张图片,然后提取输入图片的特征,用某种匹配准则将提取的输入图片的特征和数据库中的特征进行比较,最后从数据库中按照相似度从大到小输出相似的图片。
BOF(Bag Of Feature)
原理(BOW和BOF)
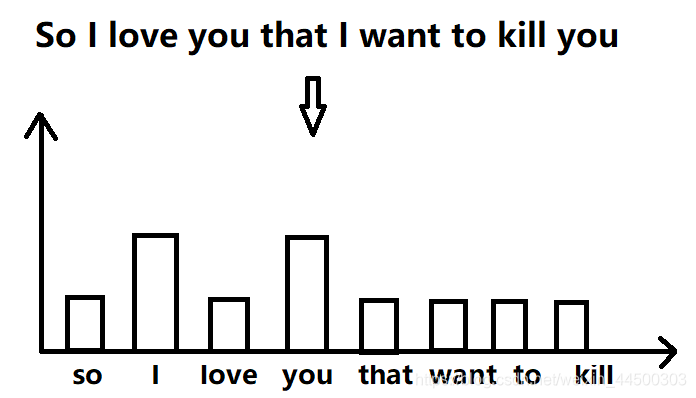
1、BOF的提出是从BOW的来的,BOW就是Bag Of Word,即将相同的单词打包到一起。在一篇文章中,假设不考虑单词的先后顺序关系以及语法正确与否,我们可以将相同的单词打包在一起,根据单词的频率(出现次数),构造文本描述子,类似直方图。这就是BOW。例如,如下图的一篇文章,其中I和you都出现两次,其他都只出现一次
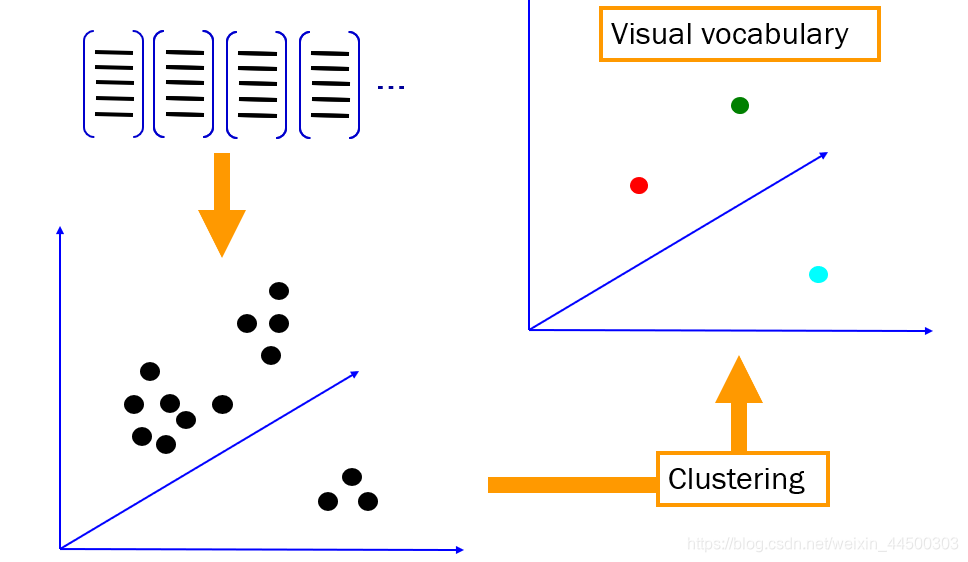
2、从上面的BOW中拓展到图像检索,我们可以将图像中的特征(SIFT特征)打包,构建唯一的特征标识符放到Bag中,构造视觉词典。

3、视觉词典就是所有训练图像所提取的所有特征向量的集合,当图像多了,就难以避免视觉词典大小变得很大。这时候可以采用K-means聚类的方法。例如,一张图像可以提取出很多个SIFT特征点,这里面不难免有些很相似的特征点,将这些相似的特征点用K-Means聚类归到一个类别中,取聚类中心作为代表,代表这些相似特征点,这些聚类中心就是图像的“(视觉)单词”,以这些单词代表图像。单词的数量就是视觉词典的大小。
K-means聚类
1、BOF的k-means思想是最小化每个特征xi与其mk之间的距离欧式距离,计算公式如下:
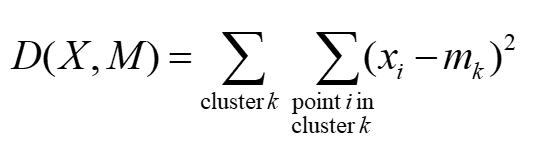
2、算法流程是
- 随机初始化K个聚类中心
- 对应每个特征,根据距离关系赋值给某个中心(类别)
- 对每个类别,根据其对应的特征集重新计算聚类中心
3、k-means聚类采用的是无监督学习策略(无师学习),聚类是实现视觉词典的关键。以下是一些视觉单词的样例


BOF算法的流程
1、准备一个训练图片集,提取这些图片的SIFT特征
2、对这些特征进行K-Means聚类,创建视觉词典。
3、针对输入特征集,根据视觉词典进行量化
4、输入测试图片,提取测试图片的SIFT特征,把输入图像转成视觉单词的频率直方图。
5、构造特征到图像的倒排表,通过倒排表快速索引相关图像。
6、根据索引结果进行直方图匹配
视觉单词的TF-IDF权重
1、在一篇文章中,有些单词的出现频率是比较高的,例如:you、to、of等,这些出现频率比较高的单词,在文本检索的时候会很大程度上导致文本检索错误。
2、IDF(逆文档词频):在图像检索的BOF算法中也是如此,有些相似的特征在很多图像中出现的频率较高,这些频率高的特征会导致图像检索到错误的图像,解决办法就是给提取的特征的添加上一个权重,如果这个特征出现的频率比较高,则的权值应该较低,相反,如果某些特征出现频率较低,则说明,它更能代表所对应的图像,则权值应该比较高。下图是IDF权值的计算公式,加1防止分母为0

3、TF(词频):逆文档词频针对的是提取的SIFT特征,而词频针对的是视觉单词。和上面的逆文档词频相反,如果一个视觉单词在一个图像中出现的频率较高,则它更能代表这个图像。TF的权值计算公式如下:

倒排表
1、构造倒排表可以快速索引图像,它是一个键值对的集合,类似C语言中的Map。假设有如下一个数据库和视觉词典,数据库图像含有100张图片I1~I100,视觉词典含有100个视觉单词W1~W100。
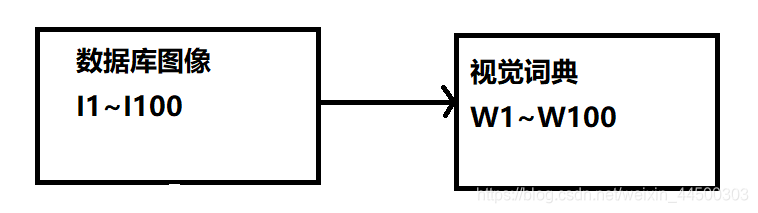
2、构造数据的倒排表,图中倒排表表示视觉单词W1在I1、I2图像中出现过,以此类推。现在输入一张图片Image0,它有5个特征。从倒排表的比较中可以发现,输入图像的视觉单词在图像I2中都有出现过,因此I2可以作为结果返回给用户。

图像检索代码
数据
训练集总共148张图片(不能再多了,再多就内存溢出了)
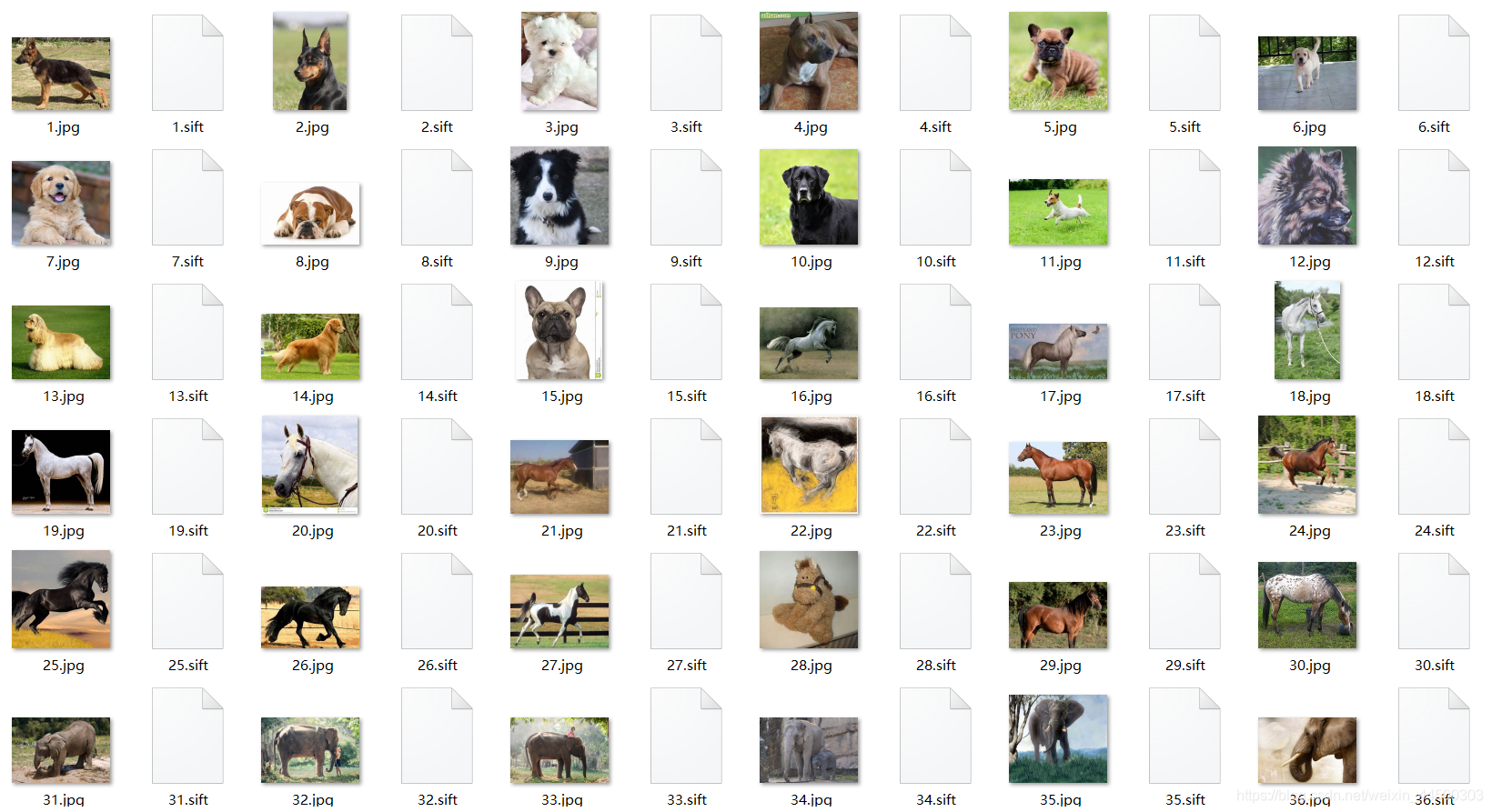
代码
1、给训练图像集生成词汇字典。生成字典之前要先提取图像的 SIFT特征点
# -*- coding: utf-8 -*- import pickle from PCV.imagesearch import vocabulary from PCV.tools.imtools import get_imlist from PCV.localdescriptors import sift #获取图像列表 # imlist = get_imlist('D:/pythonProjects/ImageRetrieval/first500/') imlist = get_imlist('D:/pythonProjects/ImageRetrieval/animaldb/') nbr_images = len(imlist) #获取特征列表 featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)] #提取文件夹下图像的sift特征 for i in range(nbr_images): sift.process_image(imlist[i], featlist[i]) #生成词汇 voc = vocabulary.Vocabulary('ukbenchtest') voc.train(featlist, 1000, 10) #保存词汇 # saving vocabulary with open('D:/pythonProjects/ImageRetrieval/animaldb/vocabulary.pkl', 'wb') as f: pickle.dump(voc, f) print('vocabulary is:', voc.name, voc.nbr_words) 2、将图像添加到数据库
# -*- coding: utf-8 -*- import pickle from PCV.imagesearch import imagesearch from PCV.localdescriptors import sift from sqlite3 import dbapi2 as sqlite from PCV.tools.imtools import get_imlist #获取图像列表 imlist = get_imlist('D:/pythonProjects/ImageRetrieval/animaldb/') nbr_images = len(imlist) #获取特征列表 featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)] # load vocabulary #载入词汇 with open('D:/pythonProjects/ImageRetrieval/animaldb/vocabulary.pkl', 'rb') as f: voc = pickle.load(f) #创建索引 indx = imagesearch.Indexer('testImaAdd.db',voc) indx.create_tables() # go through all images, project features on vocabulary and insert #遍历所有的图像,并将它们的特征投影到词汇上 for i in range(nbr_images)[:500]: locs,descr = sift.read_features_from_file(featlist[i]) indx.add_to_index(imlist[i],descr) # commit to database #提交到数据库 indx.db_commit() con = sqlite.connect('testImaAdd.db') print(con.execute('select count (filename) from imlist').fetchone()) print(con.execute('select * from imlist').fetchone()) 3、图像检索测试
# -*- coding: utf-8 -*- #使用视觉单词表示图像时不包含图像特征的位置信息 import pickle from PCV.localdescriptors import sift from PCV.imagesearch import imagesearch from PCV.geometry import homography from PCV.tools.imtools import get_imlist # load image list and vocabulary #载入图像列表 #imlist = get_imlist('E:/Python37_course/test7/first1000/') imlist = get_imlist('D:/pythonProjects/ImageRetrieval/animaldb/') nbr_images = len(imlist) #载入特征列表 featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)] #载入词汇 with open('D:/pythonProjects/ImageRetrieval/animaldb/vocabulary.pkl', 'rb') as f: voc = pickle.load(f) src = imagesearch.Searcher('testImaAdd.db',voc)# Searcher类读入图像的单词直方图执行查询 # index of query image and number of results to return #查询图像索引和查询返回的图像数 q_ind = 0 # 匹配的图片下标 nbr_results = 148 # 数据集大小 # regular query # 常规查询(按欧式距离对结果排序) res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]] # 查询的结果 print ('top matches (regular):', res_reg) # load image features for query image #载入查询图像特征进行匹配 q_locs,q_descr = sift.read_features_from_file(featlist[q_ind]) fp = homography.make_homog(q_locs[:,:2].T) # RANSAC model for homography fitting #用单应性进行拟合建立RANSAC模型 model = homography.RansacModel() rank = {
} # load image features for result #载入候选图像的特征 for ndx in res_reg[1:]: try: locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1 except: continue # get matches matches = sift.match(q_descr,descr) ind = matches.nonzero()[0] ind2 = matches[ind] tp = homography.make_homog(locs[:,:2].T) # compute homography, count inliers. if not enough matches return empty list # 计算单应性矩阵 try: H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4) except: inliers = [] # store inlier count rank[ndx] = len(inliers) # sort dictionary to get the most inliers first # 对字典进行排序,可以得到重排之后的查询结果 sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True) res_geom = [res_reg[0]]+[s[0] for s in sorted_rank] print ('top matches (homography):', res_geom) # 显示查询结果 imagesearch.plot_results(src,res_reg[:6]) #常规查询 imagesearch.plot_results(src,res_geom[:6]) #重排后的结果 运行结果
每次运行修改K-means聚类的类别数量,观察运行结果
# 第二个参数是k-means聚类的类别 voc.train(featlist, 1000, 10) 检索的图像

不同聚类类别数量得到的结果
1、类别K=100
常规查询结果

重排后的结果

2、类别K=500
常规查询结果

重排后查询结果

3、类别K=1000
常规查询结果

重排后的结果

结果分析
从上面的运行结果可以发现,随着聚类类别数量的增加,图像检索的结果越来越好,更加接近合理性。但是当类别数量K增加到某一个值得时候,图像检索的效果又开始下降。因此聚类类别数量能够很大程度的影响图像检索的效果。在我这里的运行结果中,类别数量K=500左右是比较好的,可能类别数量还需要再高一些,但是当增加到K=1000的时候图像检索的效果就开始下降了。一般最佳的K是通过穷举获得。
以类别K=1000的运行结果为例,输入一只小狗的图像,在数据库中检索,检索的结果显示了猫、狗、羊的的图像,并不全都是小狗的图像。观察输入的小狗图像,整体图像偏向橙黄色,角点位置一般处在狗的鼻子、嘴巴、眼睛、脚、耳朵的地方,因此提取出来的SIFT特征点一般就分部在这些地方。
而从数据库中检索出来的图像中,对于第二张小狗是偏黑,角点位置很明显鼻子、耳朵处,且颜色相近,这些地方的SIFT特征会和输入图像的鼻子耳朵的SIFT特征相似,因此被认为和输入图像匹配;
第三张小猫全身都比较黑,但是耳朵和眼镜处很明显是角点的位置,且颜色相近,因此小猫被当作是小狗显示出来了
第四张山羊的图像会被当作是小狗,是因为它在眼睛、耳朵、鼻子、嘴巴的地方特征点和输入图像相应位置的特征点相似,且都为黑色。虽然山羊大部分是白色,但是恰好是这些地方不会被当作是角点,所以这些地方被忽略了。
第四张小猫的情况和第三张的小猫比较相似,眼睛、耳朵处为角点,且为黑色、橙黄色,比较和输入图像的小狗接近。
第五章小狗和输入图像小狗相似的地方也是在于眼镜、嘴巴、鼻子处的SIFT特征。
实验过程遇到的问题
1、在提取图像的SIFT特征的时候,使用get_imlist方法图像没有从文件夹中读取出来,仔细看了一下读取文件的方法,必须要.jpg的格式,才能读取出文件。
2、读取图像,提取特征,生成词汇表的时候报了一下错误。原因是训练图像太多(原本有1000张),导致读取的时候超出了所能使用的内存空间最大容量。解决办法有两种,一种就是加大内存空间,第二种就是减少图像的数量,这里我选择了第二种,将图像数量减少到了148张
numpy.core._exceptions.MemoryError: Unable to allocate array with shape (, 128) and data type float64
3、在测试输入图像检索的时候,报错。查看报错的代码行,添加了try except语句后正常运行
File “D:/pythonProjects/ImageRetrieval/rearrangement_3.py”, line 46, in <module>
locs,descr = sift.read_features_from_file(featlist[ndx]) # because ‘ndx’ is a rowid of the DB that starts at 1
IndexError: list index out of range
#在报错行出添加try except语句 try: locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1 except: continue
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/81037.html