
前言
废话少说,机器学习第七篇
主要整理的是常用降维方法:
PCA,LDA
为了能够持续更新和添加新的知识点,以及修改错误,建立了一个repo,欢迎大家来个star或者推荐给需要的朋友:
https://github.com/chehongshu/machine-learning-interview-chinese
以下问题多为自己和贝壳er总结以及网上整理,如有错误请指正,由于查阅时间太久了,也没法一一列出参考,不管怎么说,感谢喜欢分享的人。
资料整理:蜗牛、贝壳er
文章写作:蜗牛
1. 为什么要进行数据降维?
降维的必要性
- 多重共线性–预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。
- 高维空间本身具有稀疏性。一维正态分布有68%的值落于正负标准差之间,而在十维空间上只有0.02%。
- 过多的变量会妨碍查找规律的建立。
- 仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量可能落入仅反映数据某一方面特征的一个组内。
降维的目的:
- 减少预测变量的个数
- 确保这些变量是相互独立的
- 提供一个框架来解释结果 降维的方法有:主成分分析、因子分析、用户自定义复合等。
- PCA(Principal Component Analysis)不仅仅是对高维数据进行降维,更重要的是经过降维去除了噪声,发现了数据中的模式。
2. PCA算法具体是什么?
 PCA做的就是寻找到一组基(主成分),这组基互不相关,并且使得所有的数据变换为这组基上的坐标表示之后,方差值尽可能的大。
PCA做的就是寻找到一组基(主成分),这组基互不相关,并且使得所有的数据变换为这组基上的坐标表示之后,方差值尽可能的大。
如果说方差表示的一个变量之间数据之间的波动程度,那么协方差表示的两个变量(维度)之间的相关程度, 所以,如果想让两个基没有相关性,就要保证他们的协方差为0.
两个标准,一个就是需要特征之间的协方差为0,让协方差矩阵相似对角化,另一个就是尽量的使得方差最大,就是协方差矩阵对角化之后,把对角线上的素从大到小排列,尽量取大的那些个特征值对应的特征向量(他们的方差较大)

总结
- 降维是特征降维
- 做之前要对特征进行归一化,即高斯分布形态,mean=0
- 本质就是找一组基,这组基互不相关,并且其他维度映射到整个基上方差最大
- 协方差矩阵,对角线是能量即方差,负对角线是各个维度之间的相关性
- 所以要负对角线为0,所以用相似对角化
- 之后此时剩下的对角线上都是方差也就是特征值,选k个最大的
- 用这k个最为互不相关的基,使所有维度,都映射到整个基上得到新的坐标,此时达到降维效果
- pca主要目的就是降噪和去冗余
- 降噪:保留的维度之间相关性尽可能小
- 去冗余:保留下来的维度的能量即方差尽可能大(方差代表着信息的多少也就是能量的大小)
3.PCA中为什么要协方差矩阵相似对角化?
协方差矩阵度量的是维度和维度之间的关系,其主对角线上素是各个维度上的方差(能量),其他素是两两维度间的协方差,目的是让不同维度间的相关性尽可能小,也就是让协方差矩阵中非对角线素基本为0,这样的作法在数学上叫相似对角化。
相似对角化后的协方差矩阵主对角线上素是各个维度的新方差,它依然能反映维度各自的能量,此时它在数学上叫特征值,我们取前K个特征值,也就是选中了各自方差最大(信息量最大)的K个维度,由这些特征值对应的特征向量即可组成我们的基。
4. 线性判别分析LDA是什么?
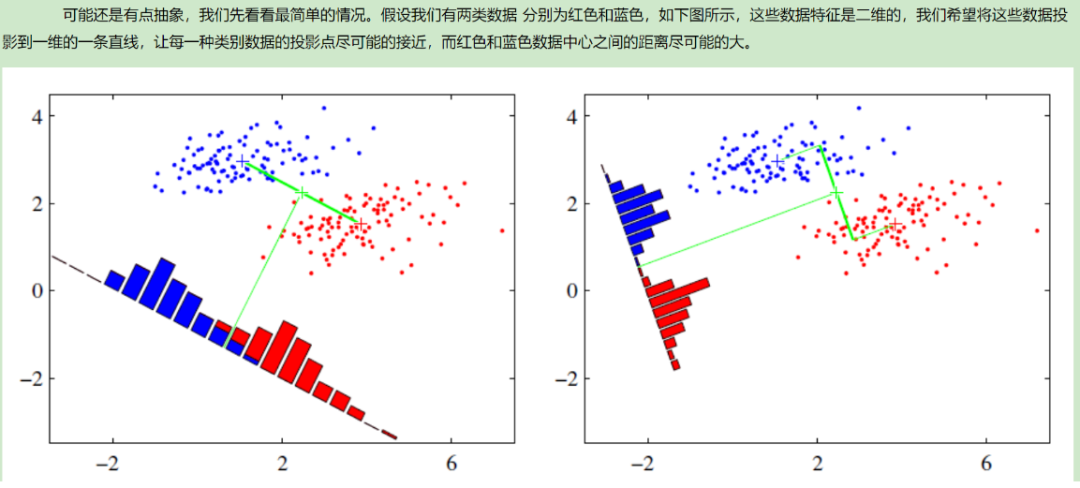
推荐阅读刘建平的博客:https://www.cnblogs.com/pinard/p/6244265.html 投影后类内方差最小,类间方差最大
5.LDA与PCA的相同点和不同点有哪些?
相同点
- 都是对数据进行降维
- 都使用了矩阵特征分解的思想
- 两者都假设数据符合高斯分布。
不同点
- LDA是有监督的降维方法,而PCA是无监督的降维方法
- LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。
- LDA除了可以用于降维,还可以用于分类。
- LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。
Reference
- https://blog.csdn.net/forest_world/article/details/
- https://www.cnblogs.com/pinard/p/6244265.html
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【AI四大名著】获取四本经典AI电子书
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/84178.html