
基于uplift模型的营销增益
小O:小H,我们最近在做促销,针对一些群体发放优惠券。老板说有些用户不管发不发券都不会购买 ,就别浪费了。所以有办法识别吗?
小H:这个就是典型的营销增益了,一般会将用户分为四类:Treatment Responders(发放优惠购买TR)、Treatment Non-Responders(发放优惠不购买TN)、Control Responders(不发放优惠也会购买CR)、Control Non-Responders(不发放优惠不会购买CN)。其中Treatment Responders被称为营销敏感群体。
我们需要识别出TR群体进行营销刺激,对于TN和CR群体可以不发放优惠券以减少成本。而CN群体比较特殊,如果想尽可能的减少成本,可以选择不发放优惠券,若想提高用户的转化则可以选择发放优惠券进行刺激。
核心是如何计算uplift,本文针对CN群体采用发放优惠券的前提: u p l i f t = P T R + P C N − P T N − P C R uplift=P_{TR}+P_{CN}-P_{TN}-P_{CR} uplift=PTR+PCN−PTN−PCR。本文参考自Uplift模型提升用户增长。
数据探索
import pandas as pd import numpy as np import toad from sklearn.model_selection import train_test_split # 数据分区库 import xgboost as xgb # 导入自定义模块 import sys sys.path.append("/Users/heinrich/Desktop/Heinrich-blog/数据分析使用手册") from keyIndicatorMapping import * 以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-uplift】自动获取~
# 读取数据 raw_data=pd.read_csv('data.csv') raw_data.head() 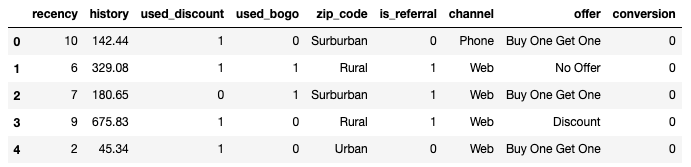
# 查看数据信息 toad.detector.detect(raw_data) 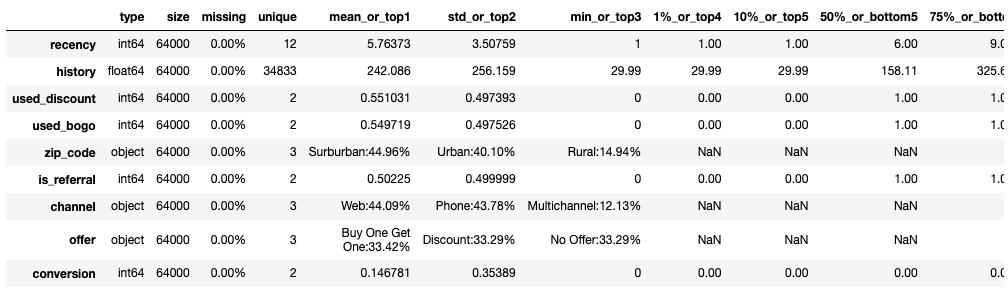
特征工程
# 替换字符串 zip_code_dic={
'Surburban':1, 'Urban':2, 'Rural':3 } channel_dic={
'Web':1, 'Phone':2, 'Multichannel':3 } offer_dic={
'Buy One Get One':1, 'Discount':2, 'No Offer':0 } raw_data=raw_data.replace({
'zip_code': zip_code_dic, 'channel':channel_dic, 'offer':offer_dic}) # 计算活动提升情况 def calc_uplift(df): # 计算各活动方式的转化率 base_conv = df[df.offer == 0]['conversion'].mean() disc_conv = df[df.offer == 2]['conversion'].mean() bogo_conv = df[df.offer == 1]['conversion'].mean() # 计算两活动转化率的提升效果 disc_conv_uplift = disc_conv - base_conv bogo_conv_uplift = bogo_conv - base_conv print('Discount Conversion Uplift: {0}%'.format(np.round(disc_conv_uplift*100,2))) if len(df[df.offer == 1]['conversion']) > 0: print('-'*60) print('BOGO Conversion Uplift: {0}%'.format(np.round(bogo_conv_uplift*100,2))) # 根据uplift score计算方式进行分类 # 设置对照-实验组 raw_data['campaign_group'] = 1 raw_data.loc[raw_data.offer == 0, 'campaign_group'] = 0 # 分类 raw_data['target_class'] = 0 # CN raw_data.loc[(raw_data.campaign_group == 0) & (raw_data.conversion == 1),'target_class'] = 1 # CR raw_data.loc[(raw_data.campaign_group == 1) & (raw_data.conversion == 0),'target_class'] = 2 # TN raw_data.loc[(raw_data.campaign_group == 1) & (raw_data.conversion == 1),'target_class'] = 3 # TR # 模型数据 df_model = raw_data.drop(['offer','campaign_group','conversion'],axis=1) df_model.head() 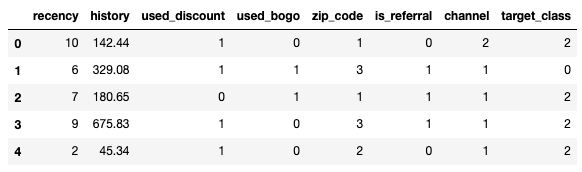
数据建模
# 样本拆分 X = df_model.drop(['target_class'],axis=1) y = df_model.target_class X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=56) # XGB分类模型训练 param_dist = {
'objective':'multi:softmax', 'eval_metric':'logloss', 'use_label_encoder':False} model_xgb = xgb.XGBClassifier(param_dist) model_xgb.fit(X_train, y_train) XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1, eval_metric='logloss', gamma=0, gpu_id=-1, importance_type='gain', interaction_constraints='', learning_rate=0., max_delta_step=0, max_depth=6, min_child_weight=1, missing=nan, monotone_constraints='()', n_estimators=100, n_jobs=8, num_parallel_tree=1, objective='multi:softprob', random_state=0, reg_alpha=0, reg_lambda=1, scale_pos_weight=None, subsample=1, tree_method='exact', use_label_encoder=False, validate_parameters=1, verbosity=None) # 计算uplift_score y_prob = model_xgb.predict_proba(X) uplift_score=[] for i in y_prob: us=i[0]+i[3]-i[1]-i[2] uplift_score.append(us) raw_data['uplift_score'] = uplift_score raw_data.head() 
模型评估
# 模型评估 # 记录活动的base calc_uplift(raw_data) Discount Conversion Uplift: 7.66% ------------------------------------------------------------ BOGO Conversion Uplift: 4.52% # 高Uplift分数:客户的uplift分数>3/4分位数 raw_data_lift = raw_data.copy() uplift_q_75 = raw_data_lift.uplift_score.quantile(0.75) raw_data_lift = raw_data_lift[raw_data_lift.uplift_score > uplift_q_75].reset_index(drop=True) # 计算top1/4的用户的提升情况 calc_uplift(raw_data_lift) Discount Conversion Uplift: 30.29% ------------------------------------------------------------ BOGO Conversion Uplift: 26.18% top25%的uplift分数用户的转化提升效果明显高于基础
# 低Uplift分数:客户的uplift分数<1/2分位数 raw_data_lift = raw_data.copy() uplift_q_50 = raw_data_lift.uplift_score.quantile(0.5) raw_data_lift = raw_data_lift[raw_data_lift.uplift_score < uplift_q_50].reset_index(drop=True) # 计算bottom1/2的用户的提升情况 calc_uplift(raw_data_lift) Discount Conversion Uplift: -3.87% ------------------------------------------------------------ BOGO Conversion Uplift: -6.03% 50%的低uplift分数用户的转化提升效果明显低于基础
结果展示
# 评分直方图 def plot_score_hist(df, y_col, score_col, cutoff=None): """ df:数据集(含y_col,score列) y_col:目标变量的字段名 score_col:得分的字段名 cutoff :划分拒绝/通过的点 return :不同类型用户的得分分布图 """ # 预处理 x1 = df[df[y_col]==0][score_col] x2 = df[df[y_col]==1][score_col] x3 = df[df[y_col]==2][score_col] x4 = df[df[y_col]==3][score_col] # 绘图 plt.title('Uplift Score Hist') sns.kdeplot(x1,shade=True,label='CN') sns.kdeplot(x2,shade=True,label='CR') sns.kdeplot(x3,shade=True,label='TN') sns.kdeplot(x4,shade=True,label='TR') if cutoff!=None: plt.axvline(x=cutoff) plt.legend() return plt plot_score_hist(raw_data, 'target_class', 'uplift_score') plt.show() 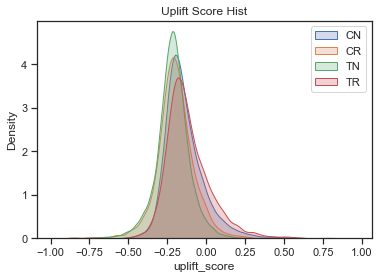
TR和CN有较高的uplift score,但是整体区分度一般
总结
其实质是进行多分类训练,然后依据公式计算uplift。因此可以对于高uplift_score的用户进行营销刺激,阈值可基于业务或者数据形式决定。
共勉~
今天的文章 基于uplift模型的营销增益分享到此就结束了,感谢您的阅读。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/85268.html