
1 知识图谱分类
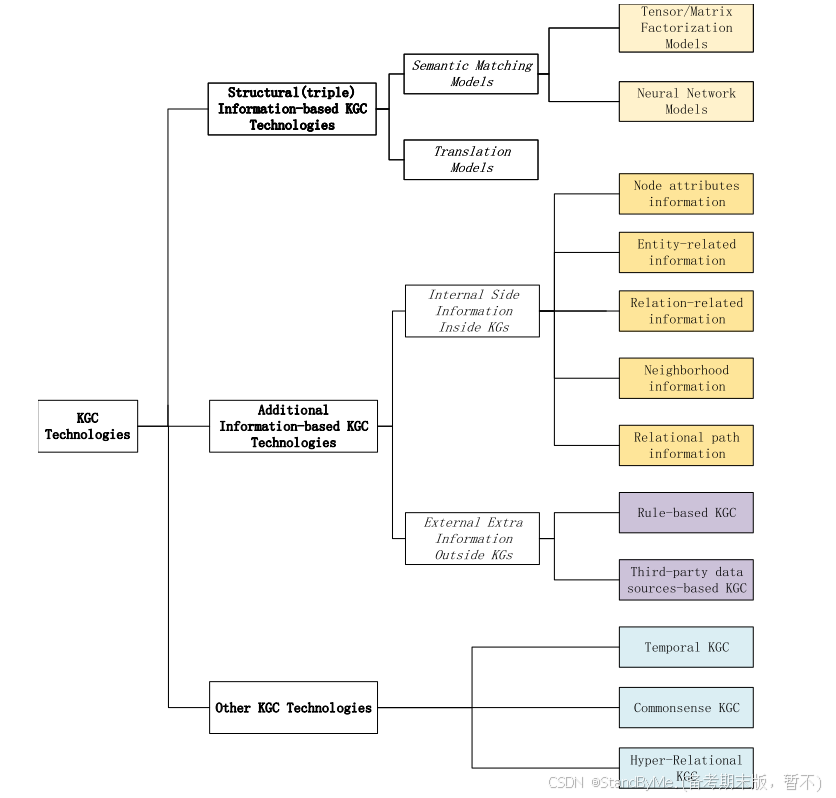
1.1 根据是否依赖于附加信息
最近的知识图谱补全(KGC)研究总结为两大类:
 基于外部信息的KGC方法中的基于规则的vKGC方法的解释:
基于外部信息的KGC方法中的基于规则的vKGC方法的解释:
这种方法依赖于从知识图谱中或外部数据源中提取的逻辑规则或模式。虽然规则本身并不是外部信息,但这些规则可以从外部数据源中获取,或者是基于已有数据生成的。这些规则用于推断知识图谱中缺失的关系。例如,可以使用模式或逻辑推理来生成新的三组。
基于外部信息的KGC方法中的基于第三方数据源的KGC方法的解释:
这种方法通过整合外部的第三方数据源来补全知识图谱。这些数据源包括其他知识库、数据库、网页数据、社交媒体数据等。通过从这些外部来源获取信息,可以增强和扩展现有的知识图谱。例如,从维基百科、Freebase、DBpedia等开放知识库中提取新的实体和关系,或者使用网页爬虫从互联网上收集相关数据。
1.2 从全面性的角度分类
时态知识图补全(TKGC)
常识知识图补全(CSKGC)
超关系知识图补全(HKGC)
2
2.1 知识图谱补全的三个子任务
三重分类、链接预测和关系预测

三重分类:给定一个三组,目标是确定当前的三组是否为真。
链接预测:给定三组目标是预测缺失的头部实体或尾部实体。
关系预测:给定部分三组,目标是预测两个实体之间缺失的关系。
2.2 KGC流程概述
2.2.1 KGC过程的三个部分
KGC过程包括三个部分:模型学习、候选处理和事实识别。
①模型学习:KGC模型通常是一个分类模型或排序模型,其目标是预测一个KG的候选三重是否正确。
在构建KGC模型之前,通常有一个预处理步骤负责数据准备,其中包括负采样(有时这不是必要的步骤,也可以在模型训练期间在线完成)和数据集分割。负采样的目的是在原KG中加入可变数量的负样例,以应对KG只包含正样例的问题。数据集拆分负责将待处理的KG数据拆分为训练集、验证集和测试集。拆分的数据集接下来将用于训练和评估KGC模型。
构建模型过程中,会经历一个评估过程,通过各种评估指标进行评估。一个满意的评估结果通常意味着一个好的KGC模型。
②候选处理:目的是获得可验证的三组。
具体过程:
- 候选集合生成:
- 这个阶段生成一个可能的三组集合,这些三组是潜在的正确答案,但目前还不存在于知识图谱(KG)中。候选集合的生成可以通过算法自动完成,也可以通过人工方法来进行。
- 候选过滤:
- 由于初始生成的候选集合通常非常大,包含许多不太可能正确的候选,因此需要对候选集合进行过滤。这一步骤旨在删除那些不太可能正确的候选,同时保留尽可能多的有希望的候选。过滤工作通常是通过应用几个过滤规则或剪枝策略来完成的。
③事实鉴定
将模型学习中学习到的KGC模型应用到上述候选处理生成的有希望的候选集合中,得到被认为是正确的、有可能被添加到KG中的缺失三组集合。
2.2.2 两种训练技术:负抽样和排名设置
(1) 负采样
负抽样的基本思想:给定KG中的现有三组均为正确三组,即(h, r, t)∈t,其中t为正三组集合。由于KGC模型需要借助负三组进行训练和验证,因此需要进行负抽样,即构造负三组,构造负三组集合T '。一般来说,负抽样是从一个正确的三组中随机替换一个实体或关系(实践中有两种选择:只替换实体素或同时替换三组中的实体和关系),使其成为一个错误的三组。例如,对于(Bill Gates, gender, male)的情况,当我们将“Bill Gates”替换为KG中的其他随机实体(如“Italy”)时,就形成了一个负三重(Italy, gender, male),并且它是一个负三重(其标签为“false”)。然而,有时随机替换后形成的三组仍然成立。例如,在上面的示例中,如果将头部实体随机替换为KG中的另一个实体“Steve Jobs”,我们会发现三组变为(Steve Jobs, gender, male),并且仍然有效。在这种情况下,我们通常考虑从T '中过滤掉这种“负三组”。
负采样策略:三种常见的采样策略有均匀采样(“unif”)、伯努利负采样方法(“bern”)和基于生成对抗网络(GAN)的负采样。
均匀采样是一种相对简单的抽样策略,其目的是按照抽样的均匀分布对负三组进行抽样。通过这种方式,以相同的概率对所有实体(或关系)进行抽样。
Bernoulli负采样:由于某种关系对应的头部实体和尾部实体的数量分布不均衡,即存在一对多、多对一、多对多等多种类型的关系,以统一的方式替换头部实体或尾部实体是不合理的。因此,“伯尔尼”策略[15]在不同的概率下替换三组的头部实体或尾部实体。形式上,对于某一关系r,‘’Bern‘’统计关系r的所有三组中每个尾实体对应的头部实体(记为Hpt)的平均个数和每个头实体(记为TPh)对应的尾实体的平均个数,然后以概率TPh/(TPh+Hpt)对每个头实体进行采样,类似地,它以概率Hpt/(TPh+Hpt)对每个尾实体进行采样。‘’Bern‘’抽样技术在许多任务中表现良好,它比"unif"可以减少假阴性标签。
基于GAN的负采样:Cai等人将生成负样本的方式改为基于GAN的采样,采用强化学习的方式,由GAN生成器负责生成负样本;鉴别器可以使用平移模型获得实体和关系的向量表示,然后对生成的负三组进行评分,并将相关信息反馈给生成器,为其负样本生成提供经验。近年来,出现了一系列基于GAN的负采样技术,相关实验表明,此类方法可以获得高质量的负样本,有利于在知识表示模型的训练过程中对三组进行正确的分类。
(2)排名设置
在预测(Barack Obama,parent,Natasha Obama)(一对多关系)的尾实体时,KGC(知识图谱完成)模型可能会给 (Barack Obama,parent,Malia Obama)更高的得分。这是因为在知识图谱中,可能存在 (Barack Obama,parent,Malia Obama)这样的事实。依据是否接受其他有效答案,采用原始设置还是过滤设置来计算排名。
假设我们有一个测试事实 (Barack Obama,parent,Natasha Obama),知识图谱中还有另一个有效事实 (Barack Obama,parent,Malia Obama)。
在原始设置中,如果模型给出的 (Barack Obama,parent,Malia Obama)的得分高于 (Barack Obama,parent,Natasha Obama),这将被视为一个错误。
在过滤设置中,因为 (Barack Obama,parent,Malia Obama)是一个有效事实,它将被过滤掉,不被视为错误。
原始设置: 过滤设置
过滤设置
 关于加1操作:
关于加1操作:


3 KG内的内部边信息
KG中蕴含的丰富信息(即内部信息)在KG学习中经常被使用,这些不可忽略的信息对于KGC和知识感知应用中获取知识嵌入的有用特征起到了重要作用。通常,KG内的公共内部边信息包括节点属性信息、实体相关信息、关系相关信息、邻域信息和关系路径信息。(未完待续)
今天的文章 关于知识图谱补全(KGC)的一些总结分享到此就结束了,感谢您的阅读。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/87692.html