
一、导入数据操作
例如: load data local inpath ‘/root/test.txt’ into table t.user01;
例如:load data inpath ‘hdfs://node01:9000/user/test.txt’ into table t.user01;
3.load data命令,可分为load data local inpath和load data inpath。两者的区别在于local导入的是本地文件而不加local的导入的是HDFS文件—相当于直接将文件进行相应的上传
4.insert into--------添加数据,适合内、外部表,不适合分区
二、hive分区partition(分成不同的文件目录进行存储)
- 静态分区
1.必须在表定义的时候先去指定对应的分区字段(分区字段一定不能与表中的字段重复)。
2.单分区建表
create table user01( id int, name string ) partitioned by (one int); 上传数据:load data local inpath '/root/test.txt' into table t.user01 partition(one=10); 单分区表,按one分区,在表结构中存在id,name,one三列,以one为文件呀区分。 3.双分区建表
创建表 create table user02( id int, name string ) partitioned by (one int,sex string); 上传数据:load data local inpath '/root/test2.txt' into table t.user02 partition(one=10,sex='man'); 双分区表,按one和sex分区,在表结构中存在id,name,one,sex四列,先以one为文件呀区分,在以sex子文件夹区分。 - 动态分区
1.修改权限
方法一:修改配置conf/hive-site.xml(彻底)
方法二:在hive内部使用set命令,hive.exec.dynamic.partiton=true //开启动态分区
set hive.exec.dynamic.partiton.mode=nostrict //默认strict。至少有一个静态分区
方法三:hive启动的时候设置 (和方法二相似)set换成hive --hiveconf
2.双分区创建
我person.txt文档中的数据格式
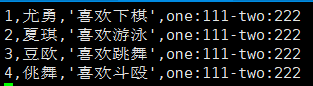
创建表 create table person01( id int, name string, hobbys array<String>, address map<string ,string> ) partitioned by (age int ,sex string) row format delimited fields terminated by ',' collention items terminated by '-' map keys terminated by ':' lines terminated by '\n' 上传数据:load data local inpath '/root/person.txt' into table t.person01 partition(age=18,sex='man'); 克隆一个与上面表架构一样的表 create table person02 like person01;(表中无数据) 写入数据 from person01 insert overwrite table from pserson02 partition (age,sex) select * distribute by age,sex sort by (id asc); //这是一条语句,这样就能添加数据,完成操作 *一个表写入另一个表中数据操作* from table_name1 //已经存在的表格并且要有数据 insert overwrite table table_name2 //overwrite代表覆盖 partition (分区一,分区二...) //分区 select * distribute by 分区一,分区二,... //distribute by进行划分 sort by (表中字段,排序类型); //进行排序(可写可不写,看业务是否需要) 注:这是一条语句。 - 分区操作
添加分区
alter table 表名 add partition(分区一,分区二,…);
也就是说添加分区的时候不能直接添加,而是需要将原来的分区也要包含其中,完成相应的排序
删除分区
alter table 表名drop partition (分区一,分区二,…)
删除分区的时候,会将所有存在的分区都删除
三、hive分桶cluster(分成几个桶进行存储)
我的文档数据
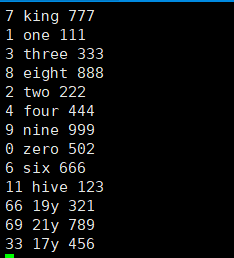
1.开启分桶
set hive.enforce.bucketing=true
2.创建桶
创建表 create table psnbucket ( id int, name string, age int ) clustered by (id) into 4 buckets row format delimited fields terminated by ','; 克隆一个与上面表架构一样的表 create table psnbucket02 like psnbucket;(表中无数据) 加载数据 insert into table psnbucket select * from psnbucket02; 抽样 select * from psnbucket tablesample(bucket 1 out of 4 on id); //查看第一个桶里的数据 select * from psnbucket tablesample(bucket 2 out of 4 on id); //查看第二个桶里的数据 select * from psnbucket tablesample(bucket 3 out of 4 on id); //查看第三个桶里的数据 select * from psnbucket tablesample(bucket 4 out of 4 on id); //查看第四个桶里的数据 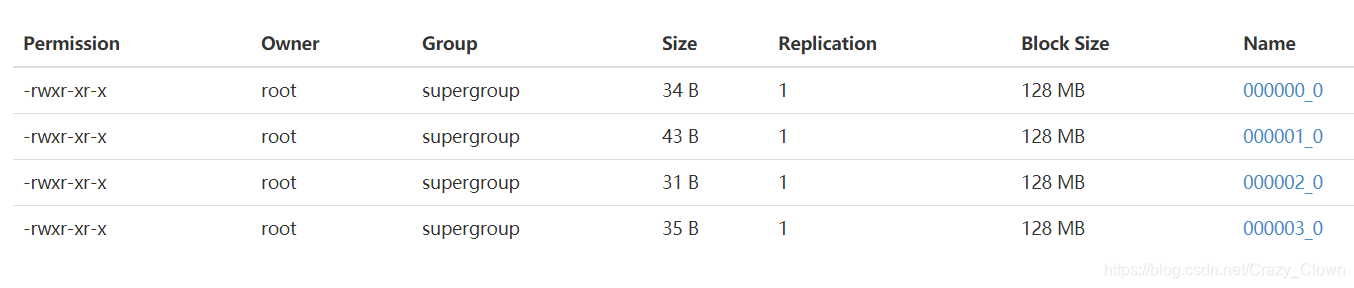
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/89083.html