

思维导图:



6.3 数据依赖的公理系统笔记
Armstrong公理系统








- 目的:为函数依赖提供一套有效且完备的推理规则。
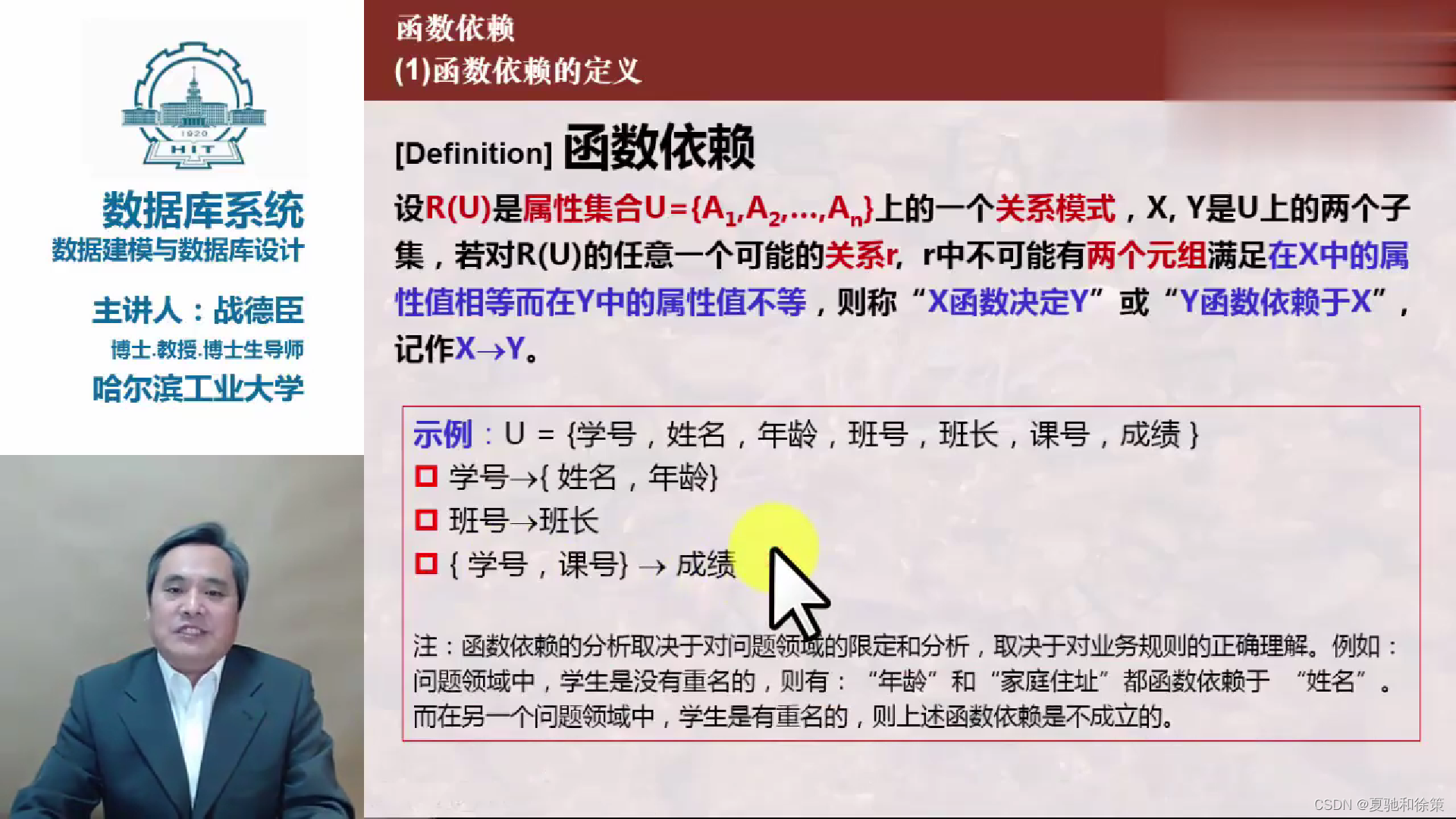
- 定义:如果关系模式R<U,F>中的任一关系r满足,对任意两组t和s,只要t[X]=s[X],则必有t[Y]=s[Y],那么称F逻辑蕴涵函数依赖X→Y。

基本规则
- 自反律 (Reflexivity Rule): 如果Y是X的子集,那么X→Y。
- 增广律 (Augmentation Rule): 如果X→Y,那么对于任意的属性集Z,XZ→YZ也成立。
- 传递律 (Transitivity Rule): 如果X→Y且Y→Z,那么X→Z。
推导规则
- 合并规则 (Union Rule): 如果X→Y且X→Z,那么X→YZ。
- 伪传递规则 (Pseudo Transitivity Rule): 如果X→Y且WY→Z,那么XW→Z。
- 分解规则 (Decomposition Rule): 如果X→YZ,那么X→Y且X→Z。


逻辑蕴含
- 逻辑蕴含是关于数据依赖的一种推理过程。如果一组函数依赖集合F蕴含另一个函数依赖X->Y(即从F中可以推导出X->Y),我们说X->Y由F逻辑上蕴含。

闭包
- 属性闭包 (Attribute Closure): 集合X关于函数依赖集F的闭包X+是指所有能由F推导出的依赖于X的属性集合。
- 函数依赖闭包 (Functional Dependency Closure): 集合F的闭包F*是指所有能由F逻辑蕴涵的函数依赖集合。
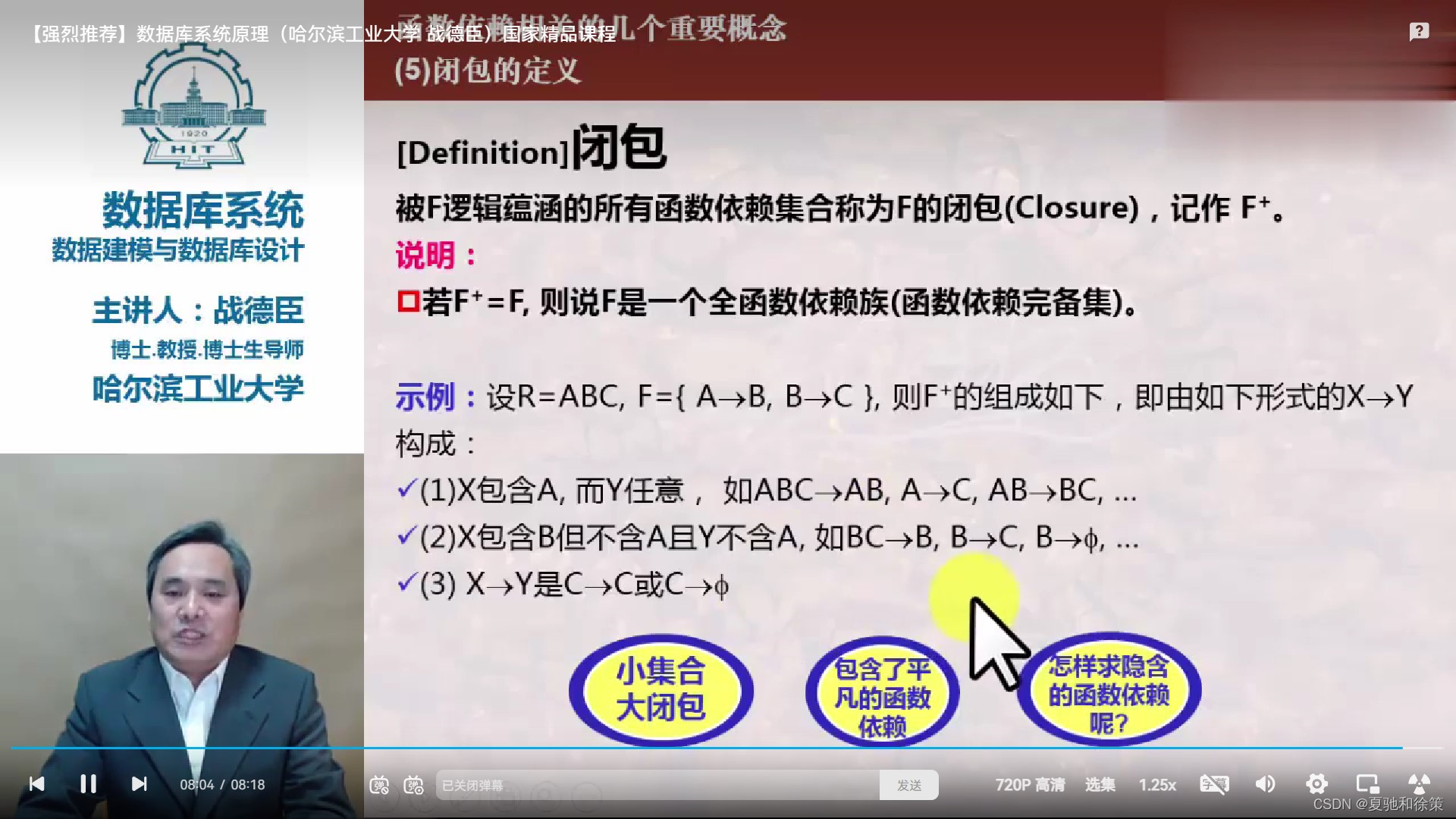
算法6.1
- 目的:计算属性集X关于函数依赖集F的闭包X+。
- 步骤:
- 初始化X+为X。
- 对于F中的每个函数依赖V→W,如果V包含在当前的X+中,将W中的所有属性加入到X+。
- 重复上述过程直到X+不再增大。
定理与证明
- Armstrong公理系统的有效性:所有可以从F推导出的函数依赖都是F中的函数依赖。
- Armstrong公理系统的完备性:F中的每一个函数依赖都可以使用Armstrong公理推导出来。
这一节的核心在于理解和掌握Armstrong公理系统及其推导规则的应用,以便能够判定特定的函数依赖是否能从已知的函数依赖集F中推导出来。理解闭包的概念和求解方法对于分析和解决数据依赖问题是至关重要的。

我的理解:
- 函数依赖(Functional Dependency):
- 这是一种约束,表示在一张表(关系)中,一个字段的值能够确定另一个字段的值。例如,学生的学号可以唯一确定他们的姓名,这可以表示为学号 → 姓名。
- 阿姆斯特朗公理(Armstrong's Axioms):
- 这是一组基本规则,可以用来推导出一组函数依赖中所有有效的函数依赖。这个公理系统是完备的,意味着用它推导出的函数依赖是正确的,并且它能推导出所有正确的函数依赖。
- 闭包(Closure):
- 在这里,闭包是指给定一个属性集合后,根据已知的函数依赖能推导出这个集合能够决定的所有属性的集合。如果我们有一个属性集合X和一组函数依赖F,X的闭包(记作X⁺)就包括了所有可以被X唯一确定的属性。
理解了这些基本概念后,我们可以进一步探索这些概念是如何在实际数据库设计中应用的:
- 确定候选键:通过查找哪些属性集的闭包包含了所有其他属性,我们可以确定这些属性集是候选键。
- 推导函数依赖:使用阿姆斯特朗公理,我们可以从已知的函数依赖集中推导出新的函数依赖。
- 优化关系模式:了解哪些属性之间存在函数依赖,有助于数据库设计者避免数据冗余,优化数据库的结构。
更加形象理解:
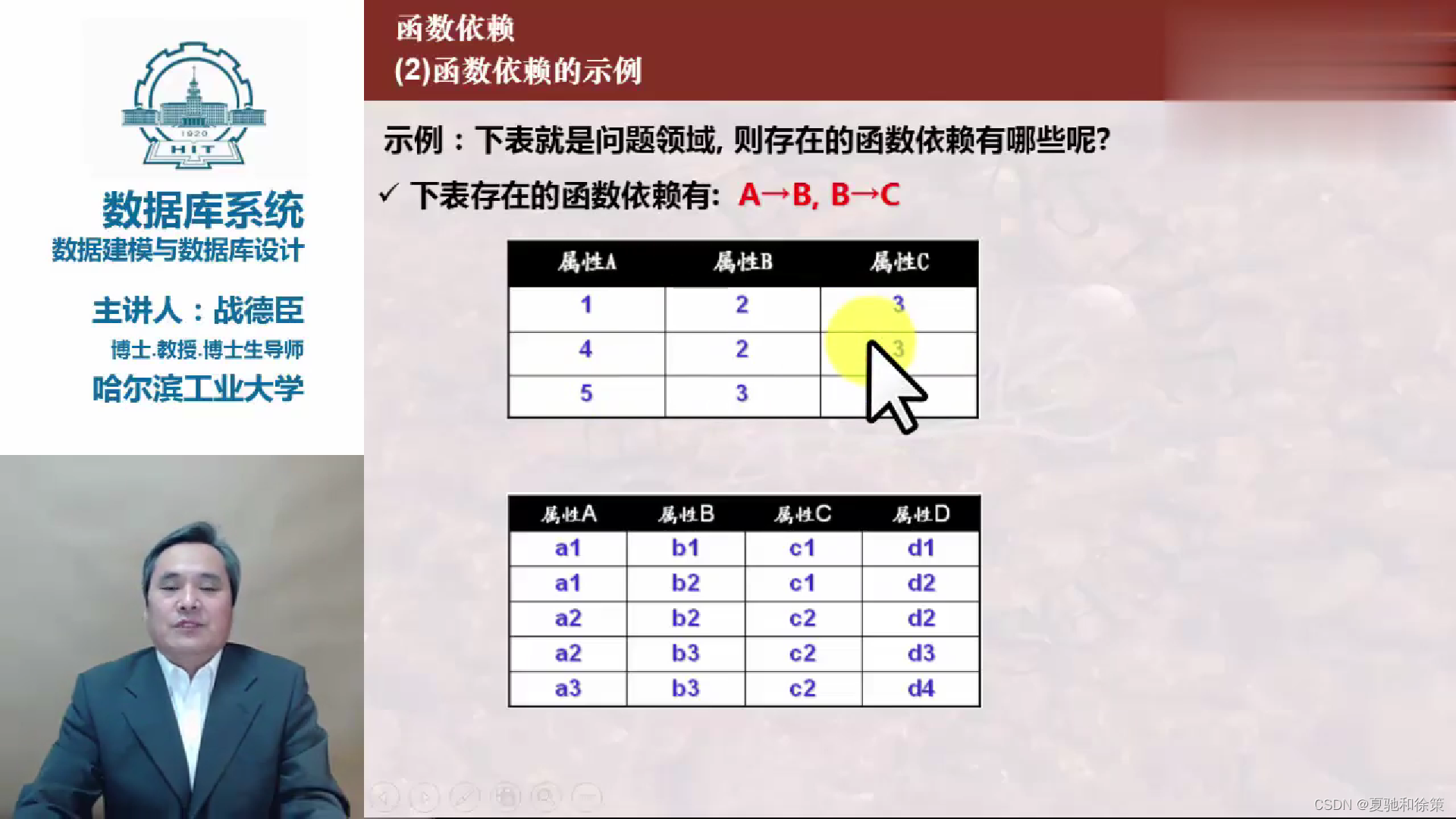
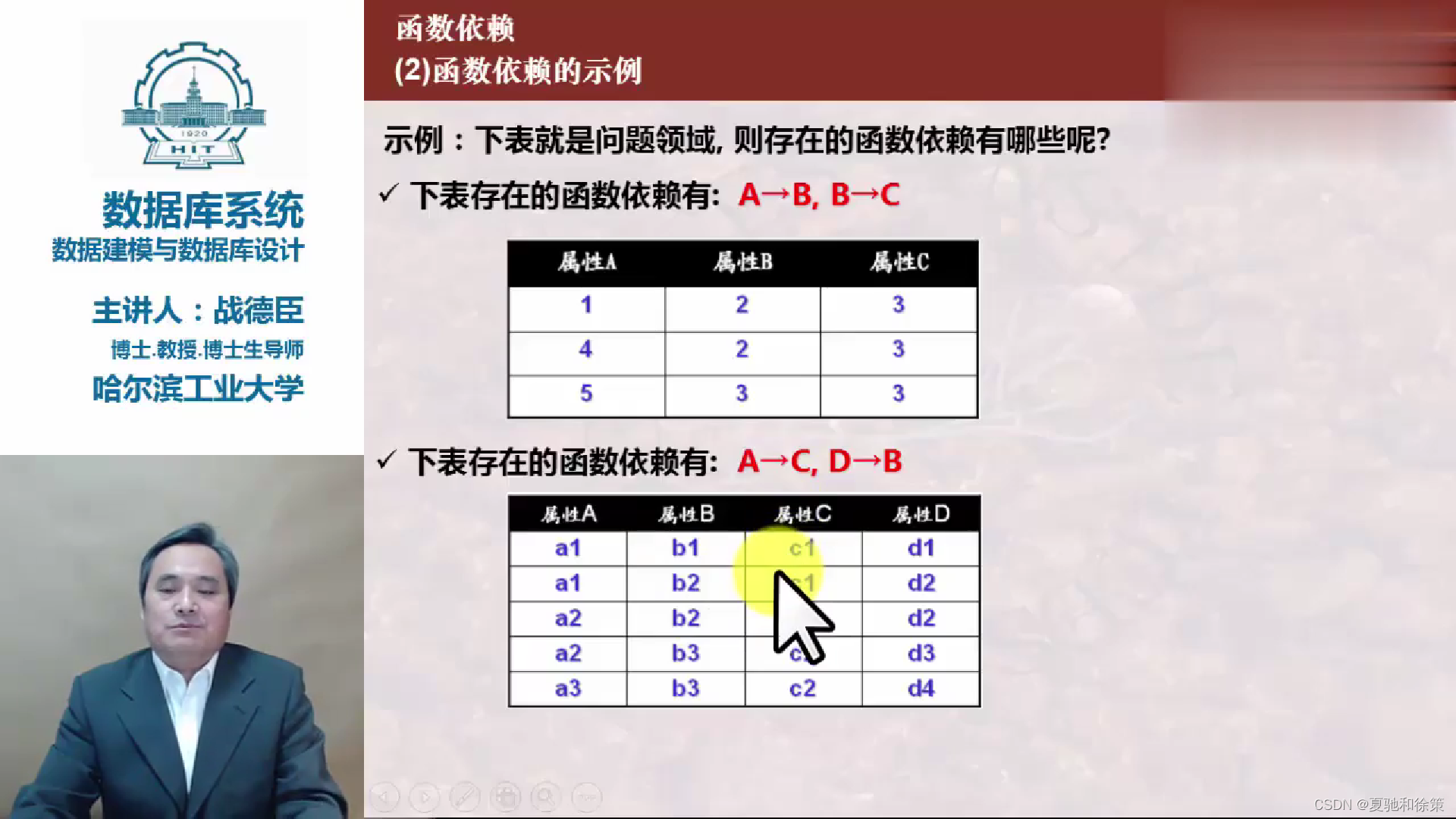
我们可以用一间图书馆作为比喻来理解函数依赖、阿姆斯特朗公理和闭包这三个概念。
- 函数依赖(Functional Dependency):
- 想象你走进了一家图书馆,每本书都有一个独一无二的编号,这个编号就像学生的学号一样。一旦你知道了这个编号,你就可以找到对应的书和书的所有信息,例如书名、作者等。这里,书的编号到书的信息就形成了一个函数依赖,因为编号能够唯一决定书的具体信息。
- 阿姆斯特朗公理(Armstrong's Axioms):
- 这些公理就像图书馆的检索系统规则。比如说,如果编号能确定书的作者,作者名能确定他的出生日期,那么我们可以通过编号也确定作者的出生日期。这个逻辑过程就像使用检索系统的规则去获取信息。阿姆斯特朗公理给了我们一套规则,来判断信息之间的这种“如果...那么...”关系是否成立。
- 闭包(Closure):
- 闭包就好比你手上有一串书的编号列表,你想要知道这些编号总共能给你多少信息。在图书馆中,你可能通过这些编号找到所有相关书的信息,甚至更多关联信息,比如这些书的作者写过的所有书、出版社等。闭包就是你能从起点信息出发,通过所有的函数依赖关系能得到的全部信息的集合。
- 闭包就好比你手上有一串书的编号列表,你想要知道这些编号总共能给你多少信息。在图书馆中,你可能通过这些编号找到所有相关书的信息,甚至更多关联信息,比如这些书的作者写过的所有书、出版社等。闭包就是你能从起点信息出发,通过所有的函数依赖关系能得到的全部信息的集合。





所以,如果你想要设计一个图书馆的数据库,了解这些概念就可以帮助你确保,例如,通过书的编号能高效地找到所有相关信息,并且确保没有重复和冗余(比如,不会有两条记录对应一个编号)。通过应用这些规则,你可以确保图书馆数据库既完整又高效。

6.3 数据依赖的公理系统
1. Armstrong公理的完备性和有效性
- 完备性和有效性保证了从一组函数依赖(FD)集合出发,可以导出所有能够由它们推理出的FD。
- 这意味着,如果通过公理能够导出一个FD,那么这个FD是在公理系统下隐含的,即公理体系能够捕捉FD之间的所有逻辑关系。
2. 函数依赖集的等价性
- 如果两个函数依赖集F和G能够导出彼此的所有FD,那么它们被认为是等价的。
- 引理6.3提供了一个判断两个FD集等价性的算法。如果F可以导出G的所有FD,同时G也可以导出F的所有FD,那么F和G等价。
3. 最小依赖集
- 一个FD集如果不能进一步简化,即无法通过移除或替换其中的FD而保持等价,则称为最小依赖集。
- 最小依赖集具有三个特点:
- 所有FD的右侧只有一个属性。
- 不能移除任何FD而保持集合等价。
- 不能替换任何FD的左侧子集而保持集合等价。
4. 极小化FD集的过程
- 分为三个步骤:
- 确保所有FD的右侧只包含一个属性。
- 移除任何可移除的FD而不改变集合的闭包。
- 替换左侧可以替换的属性,以简化FD。
5. 最小依赖集的非唯一性
- 一个FD集可能有多个最小依赖集,这取决于FD的处理顺序。
6. 应用于关系模式
- 如果两个关系模式具有等价的FD集,那么它们是等效的。
- 这意味着在数据库设计中,可以用一个等价的FD集来替换另一个,而不会影响模式的约束。
我的理解:
概念理解
- Armstrong公理的完备性和有效性
- 想象我们有一个积木盒子(公理体系)和一组积木(函数依赖)。完备性就像是这个盒子包含了所有你需要的积木类型,来构建任何你想要的结构(推导出的函数依赖)。有效性保证了你使用这些积木建造的每一个结构(推导出的函数依赖)都是按照规则(数据依赖规则)构建的。
- 函数依赖集的等价性
- 假设有两个烹饪食谱(函数依赖集F和G),它们用不同的步骤描述如何做一个菜(数据关系)。如果通过遵循任何一个食谱,最终做出来的菜(蕴含的数据关系)都是一样的,那么这两个食谱就可以认为是等价的。
- 最小依赖集
- 可以将其类比为配方中的原料清单。最小依赖集要求这个清单上的每一项都是不可替代的(不能移除FD),每个原料都不能更简单(不能替换FD的左侧),而且要求每个原料单独列出(FD的右侧只有一个属性)。
极小化过程
- 分解属性
- 这就像是将一个复杂的食谱步骤(多个属性的函数依赖)拆分成简单的小步骤(单个属性的函数依赖),确保每一步只完成一个特定的任务。
- 移除非必要的依赖
- 如果某个烹饪步骤(函数依赖)实际上是不必要的,因为它的结果已经在其他步骤中实现了,那么这个步骤可以被移除。
- 简化依赖的前提条件
- 将复杂的步骤条件(FD的左侧)简化,只留下实际需要的条件(属性)来完成该步骤。
最小依赖集的非唯一性
- 就像不同的厨师可能会有不同的做法来准备同一道菜,但最后的结果都是那个菜,函数依赖集也可能有多种最小化的版本。
应用于关系模式
- 如果两家餐馆的菜单上(关系模式)提供的是等效的菜肴,尽管它们使用不同的食谱(函数依赖集),顾客体验的结果将是一样的。
通过这些比喻,我们可以形象地理解这段文本中数据库理论的抽象概念。简而言之,这是关于如何从一组给定的函数依赖中提炼出一个尽可能简洁而无冗余的依赖集,这个集合既满足原有的数据约束,又是最简化的表示形式。



总结:

重点:
- Armstrong公理系统: 这是一个由三条基本规则组成的公理系统,用于推导出所有可能的函数依赖。这些公理是反射律、增强律、和传递律。
- 公理的完备性和有效性: 完备性意味着所有在一个关系中有效的函数依赖都可以使用这些公理推导出来;有效性意味着使用这些公理推导出来的任何函数依赖都是在该关系中有效的。
- 函数依赖集的等价性: 两个函数依赖集等价是指它们能够导出彼此的所有函数依赖。
- 最小依赖集: 一个函数依赖集的最小化版本,其中不包含冗余的依赖,且每个依赖都是不可分割的。
难点:
- 理解和应用公理: 理解三条Armstrong公理如何独立和联合使用来推导新的函数依赖是复杂的。
- 构造最小依赖集: 确定一个函数依赖集是否已经是最小的,或者如何通过去除冗余来减少到最小依赖集,这个过程可以是非直观的。
- 等价性和覆盖的证明: 证明两个函数依赖集等价或者一个集合覆盖另一个集合,需要彻底的理解函数依赖集以及能够运用逻辑推理。
易错点:
- 混淆导出和蕴含: 忘记Armstrong公理所导出的函数依赖和实际在数据关系中蕴含的函数依赖是等价的。
- 忽略属性的单独影响: 在最小化过程中,容易忽略对函数依赖右侧只能有单一属性的要求。
- 错误地移除函数依赖: 在尝试简化函数依赖集时,错误地移除了某些必要的函数依赖。
- 最小依赖集的非唯一性: 错误地假设最小依赖集是唯一的,而实际上可能有多个不同的最小依赖集可以表示同一关系。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/102522.html