
目录
Edge TPU(Tensor Processing Units)
海青智盈Gyrfalcon Technology Inc.(简称GTI)
需求
1.面积要小,5cm*8cm左右
2.目标识别速度要快,30fps左右
3.重量要轻,50g以下
4.功耗要低。电池供电,功耗小于15W
5.价格要合适
方案评估
- 树莓派+intel Movidius NCS或intel Movidius NCS2
NCS基于myriad 2,NCS2基于myriad X。NCS2处理速度是NCS 8倍
- up core或up board+intel Movidius NCS或intel Movidius NCS2
若树莓派处理速度不够,可以换成up板
- Jetson TX2+第三方小型底板
不知性能如何。配下来¥5000左右
- Jetson Xavier
相较于前一代Jetson TX2,可以提供超过20倍以上效能。
价格也比较过瘾,¥12999
- 研扬科技的UP AI core和UP AI core X
这两个单板分别采用intel Movidius myriad 2和myriad X处理器。功能和intel Movidius NCS一样。可不予考虑
- google AIY Edge TPU
NXP i.MX8M CPU板+ Edge TPU
才面世,还未供货
- cpu板+google AIY Edge TPU加速器
才面世,还未供货
- 角蜂鸟AI视觉套件
还是采用intel Movidius Myriad 2 VPU,多了一个摄像头
-
Laceli™ 人工智能计算棒
内置Lightspeeur® 2801S芯片的Laceli™ 人工智能计算棒可以在1瓦的功率下提供超过每秒9.3万亿次浮点运算的性能,而Movidius每瓦功率范围的运算力则是0.1万亿次。
看指标很牛叉,可以一试。小公司产品,技术支持、软件工具配套不一定完善。
1, 效率能耗比为9.3Tops/W
2, 单芯片峰值运算能力5.6Tops,运行VGG网络可到130FPS
3, 在功耗180毫瓦下,运行VGG网络可达30FPS;运行AlexNet网络可达48FPS.
4, ImageNet 图像分类运行网络精度:VGG为66%,Alexnet为58%,
综上所述,重点验证下面三种方案
1.CPU板+intel Movidius NCS或NCS2
2.Jetson TX2
3.CPU板+Laceli™ 人工智能计算棒
下面是各大公司的嵌入式AI方案详情:
intel
Mobileye
公司
Mobileye 专注自动驾驶,是 Autopilot 的幕后功臣,被intel收购
Mobileye,1999年成立,2007年推出首款产品,2014年8月1号在纽交所上市。公司主要从事汽车工业的计算机视觉算法和驾驶辅助系统芯片技术的研究。Mobileye的产品覆盖了全球50个国家,据官方资料显示,截至2015年底,Mobileye在全球有1000万的装载量,到2016年底会有273款车的SOP的合同。
EyeQ系列
Mobileye具有自主研发设计的芯片EyeQ系列,由意法半导体公司生产供应。现在已经量产的芯片型号有EyeQ1、Eye Q2、EyeQ3,EyeQ4
目前Mobileye后装产品的终端售价约为8000元左右,前装价格会低很多。
Mobileye不同芯片可以实现不同的ADAS功能。其中EYEQ2支持产品级的AEB,EyeQ3是支持full AEB。EyeQ2等级只能做到ASIL-B,EyeQ3可以做到ASIL-D等级。(ASIL,Automotive Safety Integration Level,汽车安全完整性等级,是ISO26262中的系统危害风险等级指标,从A到D产品的安全等级依次增加。)
EyeQ5将装备8枚多线程CPU内核,同时还会搭载18枚Mobileye的下一代视觉处理器。相比而言,EyeQ4作为上一代视觉SoC芯片,只配置了4个CPU内核和6个矢量微码处理器(Vector Microcode Processor,俗称VMP)
Movidius
公司
2016年9月英特尔宣布将收购计算机视觉创业公司Movidius,这家公司也是谷歌Project Tango 3D传感器技术背后的功臣。
Movidius Myriad 2 VPU

Movidius Myriad X VPU


Intel® Neural Myriad X拥有Movidius称之为神经计算引擎(Neural Compute Engine)的功能,这是一种集成在芯片上的DNN加速器。Movidius称,有了它,Myriad X的DNN推理吞吐量能达到每秒超过一万亿次运算(TOPS),而理论运算量能达到4+ TOPS。
Myriad X在相同功耗下的额外性能,很大程度上是因为其使用了16nm的制造工艺,台积电代工,从而能将节省的功率投入到SHAVE处理器,加速器,接口和内存中。
英特尔的Myriad™X VPU是Intel英特尔公司Movidius™的第三代和先进的VPU。英特尔的Myriad™X VPU是第一款采用神经计算引擎的产品 - 神经计算引擎 - 用于深度神经网络推理的专用硬件加速器。神经计算引擎与16个强大的SHAVE内核和超高吞吐量智能内存结构相结合,使Myriad X成为设备上深度神经网络和计算机视觉应用的行业领导者。英特尔的Myriad™X VPU已经接受了对成像和视觉引擎的额外升级,包括额外的可编程SHAVE核心,升级和扩展的视觉加速器,以及支持最多8个直接连接到VPU的高清传感器的原生4K ISP管道。
与Myriad™2一样,Myriad™X VPU可通过Myriad开发套件(MDK)进行编程,该套件包括所有必要的开发工具、框架和API,以在芯片上实现自定义视觉,成像和深度神经网络工作负载。
来源: https://item.taobao.com/item.htm?spm=a230r.1.14.122.5782720aARaQPt&id=582115922391&ns=1&abbucket=20#detail
Myriad X的其它主要参数如下:
-
Myriad X还有四个支持C语言的可编程128位VLIW矢量处理器( C-programmable 128-bit VLIW),源自Myriad 2的可配置MIPI通道,以及扩展了的2.5 MB芯片内存,更多固定功能的成像/视觉加速器。
-
与Myriad 2一样,Myriad X的向量单元是针对计算机视觉工作负载优化的SHAVE处理器。Myriad X还支持最新的LPDDR4。
-
Myriad X中的另一个新功能是4K硬件编码,支持30 Hz Hz(H.264/H.265)和60 Hz(M/JPEG)。接口方面,Myriad X支持USB 3.1和PCIe 3.0,这都是新加的功能。
-
虽然没有公开具体细节,但Myriad X VPU还附带SDK,其中包含神经网络编译器和专用的FLIC框架。不过目前没有关于参考硬件的细节。
来源: https://www.leiphone.com/news/201708/e034DEvlXgYMgqU6.html
除了神经计算引擎,Myriad X还通过独特地实时整合了成像、视觉处理和深度学习推理
- 可编程的128位VLIW向量处理器 :
通过为计算器视觉工作负载而优化的16个向量处理器,可同时运行多个成像和视觉应用流水线。
- 增加可配置的MIPI信道 :
通过丰富接口和16个MIPI信道,可以将最多8个高清RGB镜头直连到Myriad X,图像信号处理吞吐量最高每秒7亿像素,还支持USB 3.1、PCI-E 3.0。
- 强化的视觉加速器 :
利用20多个硬件加速器执行光流和立体深度等任务,不需 要额外的计算开销。
- 2.5MB多核异构同质片上内存 :
集中化的芯片内存架构,最高支持450GB/s内部带宽,尽量减少芯片外部数据传输,最小化数据访问的延迟并降低功耗。
- 4K视频硬件编码 :
支持4K/30Hz H.264/H.265、4K/60Hz M/JPEG格式。
Intel® Neural Compute Stick
Movidius™ Myriad™ 2 VPU

使用过Movidius NCS神经计算棒的同学应该清楚,NCS做推理是要将文件传输到NCS神经计算棒中处理的,而目前英特尔提供的SDK只支持USB2.0的速率传输,所以你现在使用那根USB3.0接口的神经计算棒,无论在USB2.0的主机(如树莓派)上还是USB3.0的主机(如UP Squared Board)上,速度其实还是没什么差别。
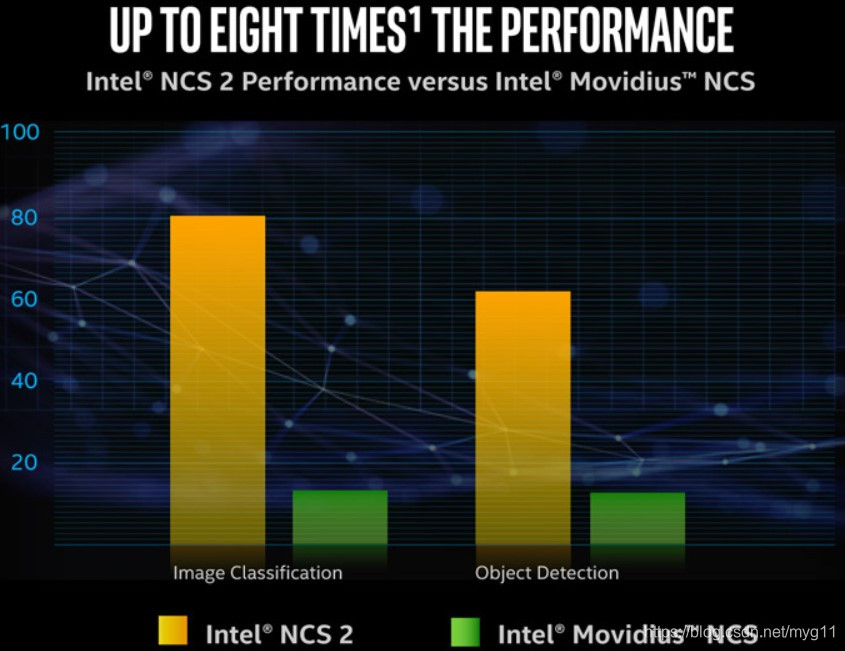
Intel® Neural Compute Stick 2
More Cores.More AI Inference.
Powered by the Intel® Movidius™ Myriad™ X Vision Processing Unit (VPU)
the Intel® NCS 2 delivers up to eight times the performance boost compared to the previous generation Intel® Movidius™ Neural Compute Stick (NCS).
Nervana
公司
Intel在2016年8月份以3.5亿美元收购了深度学习芯片公司Nervana Systems
两年前,Naveen Rao还是深度学习初创公司Nervana Systems的首席执行官兼联合创始人。在公司被英特尔收购后,Nervana成为了英特尔人工智能的核心战舰,Nervana NNP系列也应运而生,Naveen Rao则被任命为人工智能产品事业部的总负责人。
Nervana NNP
淘宝未搜到相关产品
专为深度学习而打造的神经网络处理器
Nervana芯片的独特之处在于它为计算扩展出大空间的缓存(类似CUDA共享内存),相当于GPU的10倍,而单个计算单元的缓存是GPU的50倍。
公司
人工智能系统极为复杂庞大,但脱离不了以下几个重要的组成部分。
• 用于训练网络模型的高性能硬件:Google有自家的TPU3.0
• 优质庞大的数据:作为Google引以为傲的东西一直在向世人展示着
• 优秀的神经网络算法:众多的神经网络模型来自Google
• 出众的深度学习框架:TensorFlow谁与争锋/为移动以及嵌入式设备而生的TensorFlow Lite
• 用于边缘计算的AI芯片:Google Edge TPU横空出世
而上面这些,Google全都有,莫要说国内AI芯片公司了,即便是放眼全球,谁能与之匹敌?这是否能给国内过吹的AI芯片行业一记当头棒喝!
Edge TPU(Tensor Processing Units)
预计10月供货
Edge TPU使用户能够以高效的方式,在高分辨率视频上以每秒30帧的速度,在每帧上同时执行多个最先进的AI模型。
Edge TPU是谷歌的专用ASIC芯片,专为在边缘运行TensorFlow Lite ML模型而设计。在设计Edge TPU时,我们非常注重在很小的占用空间内优化“每瓦性能”和“每美元性能”。Edge TPU的设计旨在补充谷歌云TPU,因此,你可以在云中加速ML的训练,然后在边缘进行快速的ML推理。你的传感器不仅仅是数据采集——它们还能够做出本地的、实时的、智能的决策。

AIY Edge TPU
Edge TPU development kit
这个套件包括一个模块化系统(SOM),集合了谷歌的Edge TPU,一个NXP的CPU, Wi-Fi,和Microchip的安全元件。


AIY Edge TPU开发板规格:
◇ Edge TPU模块(SOM)规格
• CPU:NXP i.MX 8M SOC(四核Cortex-A53,Cortex-M4F)
• GPU:GC7000 Lite图形处理器
• ML加速器:Google Edge TPU
• RAM:1GB LPDDR4
• Flash:8GB eMMC
• 无线:Wi-Fi 2x2 MIMO(802.11b/g/n/ac 2.4/5GHz);蓝牙4.1
• 外形尺寸:40mm*48mm
底板规格
• 闪存:MicroSD
• USB:Type-C OTG、Type-C电源、Type-A 3.0 • Host、MicroUSB串口
• LAN:千兆以太网端口
• 音频:3.5mm音频插孔、数字PDM麦克风(x2);2.54mm 4针端子,用于立体声扬声器
• 视频:HDMI 2.0a(全尺寸)、MIPI-DSI-39针FFC连接器(4-lane)、MIPI-CSI2-24针FFC连接器(4-lane)
• GPIO:40pin扩展接口
• 功率:5V DC(USB Type-C)
• 外形尺寸:85mm*56mm
◇ 支持操作系统:Debian Linux,Android Things
◇ 支持深度学习框架:TensorFlow Lite
来源: http://www.dataguru.cn/article-13974-1.html
AIY Edge TPU加速器
AIY Edge TPU加速器是一个基于Google Edge TPU的USB设备型的神经网络加速设备,通过USB TYPE-C可以连接到任何基于Linux系统的PC机、单板计算机如树莓派等的设备上去执行机器学习推理。

产品规格:
• ML加速器:Google Edge TPU协处理器
• 连接器:USB Type-C(数据/电源)
• 外形尺寸:65毫米x 30毫米
• 支持操作系统:Debian Linux,Android Things
• 支持深度学习框架:TensorFlow Lite
总结
Edge TPU,Google AIY Edge TPU开发板以及AIY Edge TPU加速器都是有目的性而来的。
AIY Edge TPU开发板在树莓派的基础上完成了AI进化,并且性能也要高于树莓派,可谓是青出于蓝而胜于蓝;
而AIY Edge TPU加速器可以说是直接正面争锋Movidius NCS
英伟达nvidia
Jetson TX2
tx2是个核心板

Jetson TX2 runs Linux and provides greater than 1TFLOPS of FP16 compute performance in less than 7.5 watts of power.
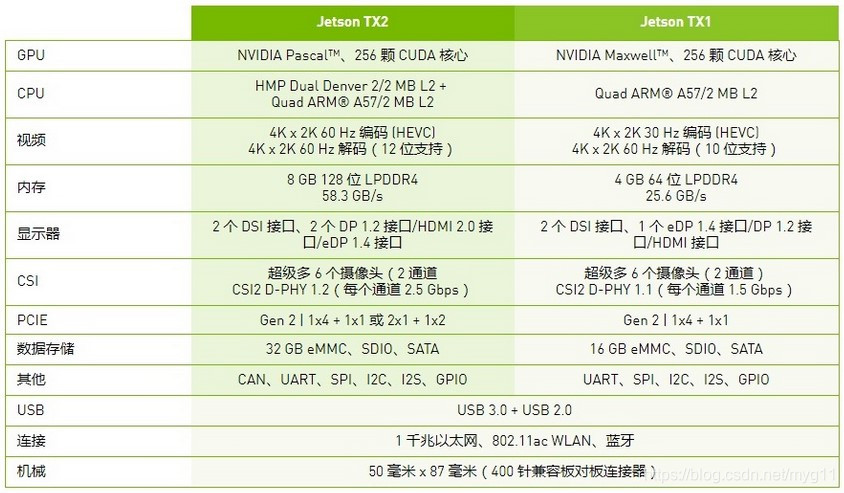
TX2模块:¥3661
官方有Jetson TX2 开发套件,核心板+底板。¥4498
款功能强大的开发者套件能够使主板的硬件功能和接口充分发挥效用,预装 Linux 开发环境。同时,它还支持 NVIDIA Jetpack SDK,包括 BSP、深度学习库、计算机视觉、GPU 计算、多媒体处理等众多功能。
网上也有很多第三方做的底板
https://item.taobao.com/item.htm?spm=2013.1.0.0.203d1c85lpVYEw&id=558116577026

底板价格¥1200~¥1500
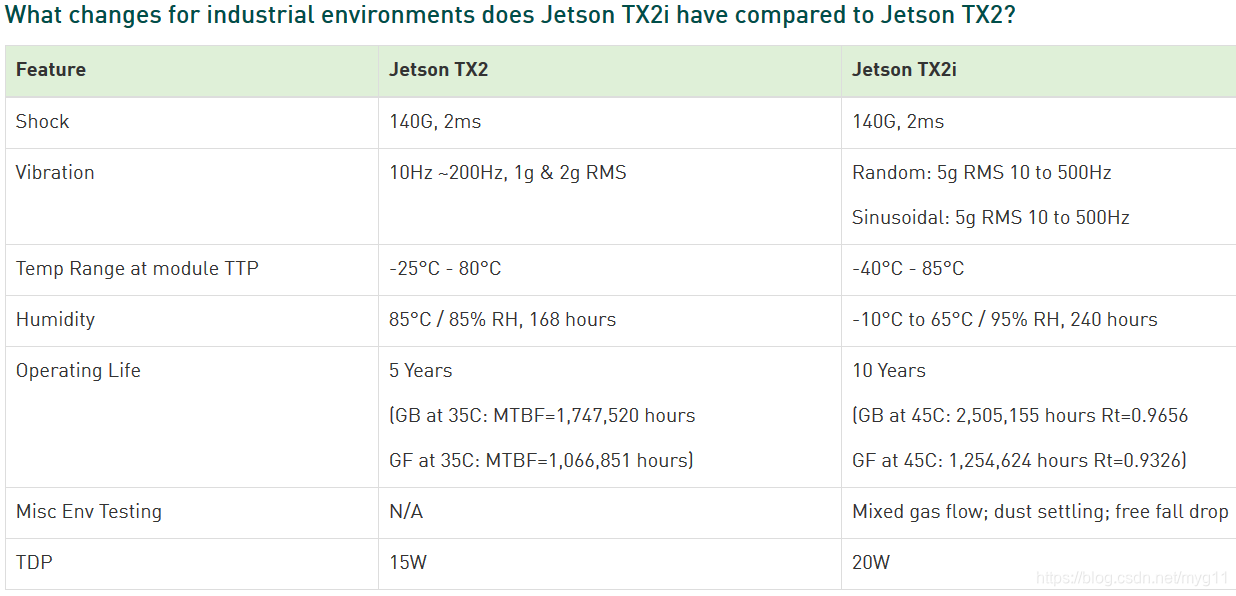
Jetson TX2i


Jetson AGX Xavier
来源: https://developer.nvidia.com/embedded/buy/jetson-xavier-devkit?from=groupmessage&isappinstalled=0
价格:¥12999
新一代Jetson Xavier相较于前一代Jetson TX2,可以提供超过20倍以上效能。
与Jetson TX2相比,Jetson AGX Xavier是一个更加丰富的计算环境。除了增加4个CPU核外,Xavier还增加了深度学习加速器(DLA)和视觉加速器(VA)
| GPU | 512-core Volta GPU with Tensor Cores |
| CPU | 8-core ARM v8.2 64-bit CPU, 8MB L2 + 4MB L3 |
| Memory | 16 GB 256-Bit LPDDR4x | 137 GB/s |
| Storage | 32GB eMMC 5.1 |
| DL Accelerator | (2x) NVDLA Engines* |
| Vision Accelerator | 7-way VLIW Vision Processor* |
| Encoder/Decoder | (2x) 4Kp60 | HEVC/(2x) 4Kp60 | 12-Bit Support |
| Size | 105 mm x 105 mm |
| Deployment | Module (Jetson AGX Xavier) |


研扬科技
UP单板
https://shop463938882.taobao.com/category-1415045995-1566998704.htm?spm=2013.1.w5842-18183892631.9.7e0944c66DG3Se&search=y&parentCatId=1366803755&parentCatName=UP+%B5%A5%B0%E5%BC%C6%CB%E3%BB%FA&parentCatPageId=1566998704&catName=UP+Squared%5CUP2#bd

UP board
¥799
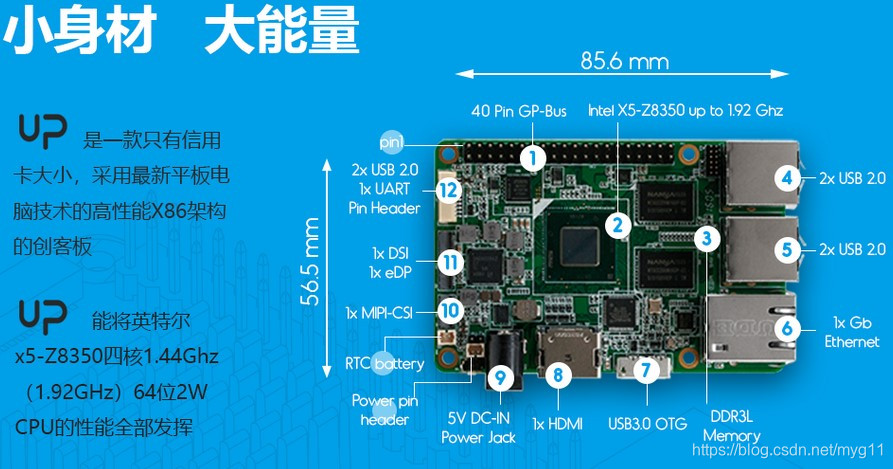

UP Squared\UP2
1299

UP Core
¥999
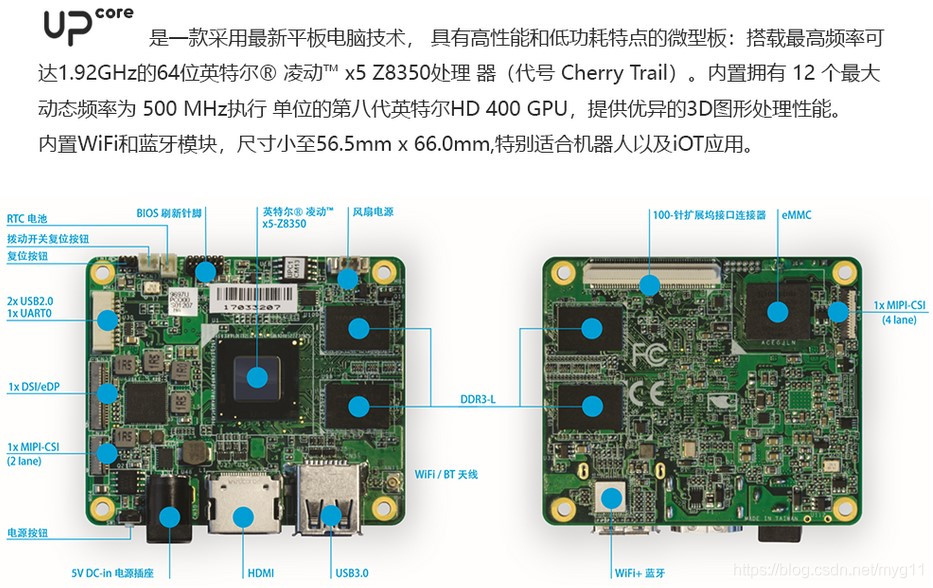

UP AI Edge
AI Core
¥579
http://www.eeboard.com/evaluation/upaicore/2/
http://sh.qihoo.com/pc/9bc9d17d3f051e904?sign=360_e39369d1
研扬AAEON和英特尔联合推出了名为AI Core的全新电路板,可以让硬件公司在自己的产品中轻松构建机器学习加速器。这块包含着可支援各种x86主机平台的Intel®Movidius™ Myriad™ 2 VPU的mini PCIe 模块具备Intel Movidius Myriad 2 VPU深度神经网路加速器低功耗和高性能的特点,还能相容神经运算软体开发套件(SDK),可以加速AI算法的执行速度,而功耗仅低至1W。
AICore较之英特尔的另外一款产品-U盘式Movidius神经计算棒,AICore体积更小、不易被撞到或者被误拔,可以在不改变代码的情况下直接将AI硬件投入量产。
本质上AI Core与Intel推出的NCS神经计算棒是没什么差别的,主要的不同在于传输方式

技术规格 [AI CORE]
来源: https://www.aaeon.com/cn/p/iot-gateway-maker-boards-ai-core
| specifications | |
| *soc | Intel® Movidius™ Myriad™ 2 2450 |
| *supportedframeworks | TensorFlow, Caffe |
| Form Factor | Mini PCI-Express |
| Dimension | 51 x 30 mm |
| System | x86_64 computer running Ubuntu 16.04 Available mPCI-E slot 1GB RAM 4GB free storage space |
AI CORE X
官网上没找到。不知是否已量产
UP AI CORE X Intel Movidius Myriad X 开发板
- Dedicated neural compute engine
- on-device deep neural networks and computer vision
- High performance
- 10X performance compared to previous generation
- Low power
- 1 TOPS @ 3 Watt TDP per Movidius™ Myriad™ X 2485
- Ready for field deployment
- MiniCard/mPCIe
- M.2 2230, 2242, 2280
- Industry-standard software tools
- Caffe
- TensorFlow
- OpenVINO Toolkit
Common to All Models
| Chipset | Movidius™ Myriad™ X 2485 |
| Onboard memory | 4 Gbits LPDDR4 |
| Extras | GPIO reset |
| Shipping | Free worldwide shipping |
Variations Between Models
| AI Core X | AI Core XM 2230 | AI Core XM 2242 | AI Core XM 2280 | AI Vision Plus X | |
|---|---|---|---|---|---|
| Form Factor | mPCIe | M.2 2230 E key | M.2 2242 B+M key | M.2 2280 M+B key | credit-card-sized |
| Myriad X SoCs | 1 | 1 | 1 | 2 | 3 |
| Dimensions | 51 x 30 mm | 22 x 30 mm | 24 x 42 mm | 22 x 80 mm | 90 x 56.5 mm |
| Thermal | Fan-less heatsink | Fan-less heatsink | Fan-less heatsink | Heatsink with active fan | Heatsink with active fan |
| Price | $94* | $94* | $94* | $144* | $259* |
来源: https://www.crowdsupply.com/up/ai-core-x
AI CORE X

AI CORE XM

Vision Plus X

海青智盈Gyrfalcon Technology Inc.(简称GTI)
公司简介
2017年初在硅谷成立。创始人均为硅谷华人人工智能科学家和半导体芯片资深工程专家及企业家。首席执行官董琪是著名图像传感器专家,拥有二十多年国际半导体开发与生产管理经验,曾是美国OMINVISION公司初创管理团队成员,先后担任技术开发副总裁和市场拓展副总裁。
旨在开发低成本、低功耗、高性能的人工智能处理器的芯片
光矛处理器 Lightspeeur® 2801S
Lightspeeur™光矛系列是全球首款可同时支持图像与视频、语音与自然语言处理的智能神经网络专用处理器芯片方案。Lightspeeur™芯片以其卓越的能耗效率比表现,在人工智能边缘计算与数据中心机器学习领域相比市场上其他方案高出几个数量级(敲黑板,划重点)。 无论是在训练模式或是推理模式下,Lightspeeur™芯片均可提供超高密度计算性能,成功克服了由存储器带宽而导致的性能瓶颈,支持真正的片上并行与原位计算。Lightspeeur™芯片支持CNN,RNN和LSTM等网络模型,同时支持标准的开源框架,如Caffe, TensorFlow和MXNet。软件开发 包提供一站式开发套件。
来源: https://www.taoguba.com.cn/Article/1831880/1
已于2017年九月从TSMC下线,该芯片采用28nm工艺,拥有高达5.6 TOPS/Watt 的卓越能耗效率比,在人工智能边缘计算与数据中心机器学习领域相比市场上其他方案高出几个数量级。
1, 效率能耗比为9.3Tops/W
2, 单芯片峰值运算能力5.6Tops,运行VGG网络可到130FPS
3, 在功耗180毫瓦下,运行VGG网络可达30FPS;运行AlexNet网络可达48FPS.
4, ImageNet 图像分类运行网络精度:VGG为66%,Alexnet为58%,
Laceli™ 人工智能计算棒
内置Lightspeeur® 2801S芯片的Laceli™ 人工智能计算棒可以在1瓦的功率下提供超过每秒9.3万亿次浮点运算的性能,而Movidius每瓦功率范围的运算力则是0.1万亿次。GTI这款计算棒不仅延续了超低功耗和高性能的出色表现,还因为不存在因功耗问题产生的散热问题,体型上比Movidius神经计算棒更为“苗条”,长宽及厚度仅为72毫米、20毫米和8毫米。其标准的3.0接口可以连接多种设备,不需要云连通性即可 赋予个人电脑、手提电脑和手机等设备直接运行实时深度学习的能力,同时支持Caffe和TensorFlow开源框架。

价格:¥499
来源: https://item.taobao.com/item.htm?spm=a1z10.5-c-s.w4002-18997614503.13.74e857daps3JYX&id=579425310110
触景无限科技(北京)有限公司
公司
作为领先的嵌入式人工智能感知平台开发者,触景无限科技(北京)有限公司致力于前端感知核心技术的创新与突破,构建嵌入式人工智能行业解决方案, 将视觉等感知智能赋予机器万物,助推人工智能的大规模产业化与新生态建设。
视觉卡模块

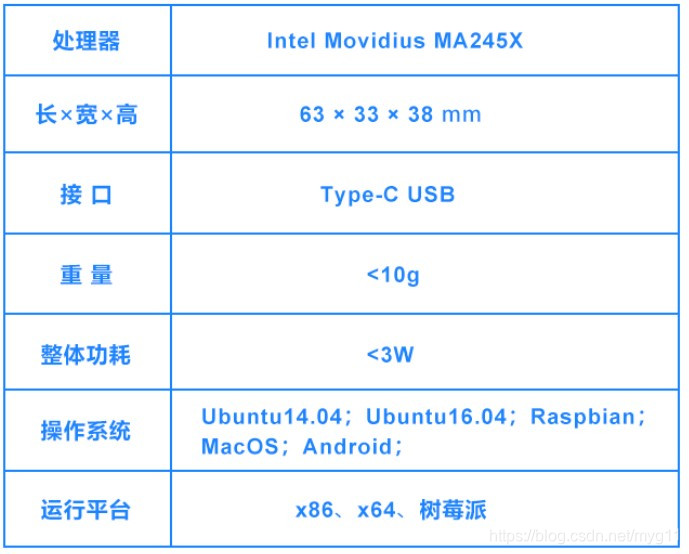
角蜂鸟(Horned Sungem)AI视觉套件
官网售价699元
Movidius Myriad 2 VPU的小主板+一个摄像头模组


角蜂鸟和NCS计算棒有什么区别呢,大家可以直观的看到,它们核心都是Movidius芯片,角蜂鸟多了一个定制的摄像头,并非树莓派的2M相机,分辨率常用的为640*360以及1920*1080。此外,NCS用的模型经过转换,角蜂鸟也可以使用,同时针对一些场景和使用案例,角蜂鸟也做了一些优化。角蜂鸟内部有8种定制神经网络模型,从Mnist手写字识别,人脸识别到物体分类,物体识别等。
原文:https://blog.csdn.net/yaked/article/details/81262339
恩智浦
BlueBox自动驾驶开发平台
BlueBox仅适用于授权客户购买。每个订单将在完成前进行审查。我们对由于审批过程而给您带来的不便表示歉意。
恩智浦BlueBox是一款开发平台,能够为开发自动驾驶汽车的工程师提供必要的性能、功能安全和汽车可靠性。作为BLBX2-xx系列的新成员,该器件集成了S32V234汽车视觉和传感器融合处理器、S2084A嵌入式计算处理器和S32R27雷达微控制器。
恩智浦BlueBox平台具备强大的性能,能够分析驾驶环境,评估风险因素,然后指示汽车的行为。
专为自动驾驶设备的BlueBox中央计算引擎。BlueBox结合了雷达、LIDAR(激光探测与测量)、视觉传感以及加载的车联网(Vehicle to Everything, V2X)系统,来将车辆周围的情景建模,进行安全决策,来保护车辆及乘客。所有的计算元素使用了量产或样本的NXP芯片,让系统做好了上路准备。
在无人驾驶车辆系统中,多个传感器数据流都汇入BlueBox引擎,数据流结合起来,将车辆周围的物理环境创造一个360°实时模型。平台具有NXP芯片支持的LIDAR系统、雷达和视觉节点,NXP S32V处理器从中获取传感数据输入,通过传感融合能力创造一个地图。S32V包括了图形引擎,专门带有高质量图形处理加速器,还带有汽车级别的功能性安全引擎。
BlueBox引擎是一个基于:Linux语言的开源平台,汽车制造商可以自行根据需要定制。公司称,BlueBox已经出货,全球五大汽车制造商的中的四家都已经收到了BlueBox。从2015年9月起,公司就已经为这些优选的客户发货。
来源: https://www.cnbeta.com/articles/tech/501897.htm
来源: https://www.nxp.com/cn/products/processors-and-microcontrollers/arm-based-processors-and-mcus/s32-automotive-platform/nxp-bluebox-autonomous-driving-development-platform:BLBX
i.MX 8系列
Cortex-A53、Cortex-A72、Cortex-A35 + Cortex-M4
强大的解决方案,具有先进的神经网络处理、图形、机器视觉、视频、音频、语音和安全关键应用。
赛灵思Xilinx
Zynq
看看它的内部结构:
1、四核A53处理器 CPU
2、一个GPU Mali-400MP
3、一个Cortex-R5 CPU
4、电源管理单元,AMS单元
5、H.265(HEVC)视频编解码器
6、安全模块
7、UltraScale FPGA 单元;
这其实就是一款异构处理器,如前所述,它是一款ASIC就级的异构处理器!而且是64位,采用16nm FinFET工艺的处理器!而且是采用FPGA实现硬加速的处理器!但是这个ARM是不是偏弱了一点?做深度学习还是欠把火后。
来源: https://blog.csdn.net/seahillpass/article/details/75453188
中星微
2016年6月20日,中星微“数字多媒体芯片技术”国家重点实验室在京宣布,中国首款嵌入式NPU(神经网络处理器)芯片诞生,目前已应用于全球首款嵌入式视频处理芯片“星光智能一号”。
http://www.eeboard.com/evaluation/air-t/

Deepwave
AIR-T全称Artificial Intelligence Radio - Transceiver ,即人工智能无线电收发器。
AIR-T是由Deepwave公司推出的具有嵌入式高性能计算功能的软件定义无线电开发板,支持的频率范围从300 MHz到6 GHz。AIR-T通过允许AI引擎完全控制硬件,从而大大降低了无线电中实现自主信号识别,干扰抑制等功能所需的价格和性能瓶颈,从而实现完全自主的SDR。
AIR-T开发板尺寸为17.0*17.0*3.5cm,包含了三个独特的数字处理器,夸张一点说,它甚至可以为信号处理类应用提供任何想要的功能。
- FPGA:用于严格的实时操作环境
- GPU:用于高性能并行处理
- CPU:用于控制、I/O口、DSP以及软件应用
简单来了解下AIR-T开发板的参数:
双通道MIMO收发器Analog Devices 9371(规格书)
- - 300 MHz至6 GHz
- - 100 MHz带宽Rx *2
- - 100 MHz带宽Tx *2
数字信号/深度学习处理器
- - Xilinx Artix 7 FPGA(规格书)
- - NVIDIA Jetson TX2【ARM Cortex-A57 CPU(4核);NVIDIA Denver2 CPU(2核);NVIDIA Pascal GPU(256核心) ;8 GB内存】(规格书)
连通性
- - 通过1 PPS和10 MHz进行GPS同步
- - USB 3.0,USB 2.0 / 3.0,SATA
- - 高速数字I / O(GPIO / UART)
- - 1 Gbps以太网
双电源模式
- - 22/14瓦特
AIR-T算是专为那些开发低成本AI,深度学习和高性能无线系统的工程师和研究人员提供的一种全新理念的无线电开发解决方案
当然也可能是目前最贵AI开发板之一了,价格4995美金。
深鉴科技
“听涛”系列SoC
深鉴还宣布会有一个神秘新品将于2018上半年震撼上市——“听涛”系列SoC。将采用28nm TSMC制造,采用DP4006 Aristotle核心,功耗1.1W,达到4.1TOPS峰值性能。这是由深鉴自主研发的深度学习SoC,2018年上半年将装载于深鉴的解决方案中。这将是深鉴布局深度学习芯片技术,首次实现芯片级产品化的正式开始。

DP-8000
DP-8000是深鉴科技推出的一款基于Xilinx Zynq-7010 SoC系列开发平台
华为
HiKey 970
HiKey 970是华为的第三代开发板,具有更强的计算能力、更丰富的硬件接口,支持主流操作系统和人工智能栈。HiKey 970基于全球首个内置NPU神经网络单元的AI移动计算平台麒麟970,集成4* Cortex-A73@2.36GHz+4* Cortex-A53@1.86GHz,Mali-G72 MP12 GPU,6GB LPDDR4 SDRAM , 64GB UFS高速存储,可提供强大AI算力、支持硬件加速、性能强劲。
除此之外,HiKey 970集成了华为创新设计的HiAI框架,以及其他主流的神经网络框架,不但支持CPU、GPU AI运算,还支持基于NPU的神经网络计算硬件加速,能效和性能 分别可达CPU运算的50倍、25倍,能够让开发者进行深度学习算法、智能机器人、智慧城市领域的开发。自从中兴事件发酵以来,国产芯的需求是愈来愈强烈,因此,如麒麟970类似的一些民族品牌肩负着国之大器的任务,任重而道远。
参考价:约2000元
来源:http:// http://www.eeboard.com/evaluation/boardtop10/5/
寒武纪
没找到开发板
Cambricon-1A
高性能硬件架构及软件支持
兼容Caffe、Tensorflow、MXnet等主流AI开发平台,已多次成功流片
国际上首个成功商用的深度学习处理器IP产品,可广泛应用于计算机视觉、语音识别、自然语言处理等智能处理关键领域。
Cambricon-1H8
低功耗版
面向视觉应用
针对视觉领域设计的深度学习处理器IP产品。与寒武纪1A相比,在同样的处理能力下具有更低的功耗和面积,可广泛应用于智能摄像头、智能驾驶、无人机等领域。
Cambricon-1H16
更高性能版
完备的通用性
1A的升级版本,能效比得到数倍提升,拥有更广泛的通用性,可广泛应用于计算机视觉、语音识别、自然语言处理等智能处理关键领域。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/108216.html