
上文 制片不熬夜:Hiero花式上镜头号——入门篇 我们讲解了Rename Shots 基本操作,这篇里,我们要说一下神奇的 Token。
Token 是什么
你在加入某些微信群的时候,群公告会说,请将自己的昵称改成 姓名-城市-职业诸如此类的要求,你不假思索就知道自己该改成什么样的群昵称。
比如有些活动的报名,让你回复姓名+手机号+人数。
这里的姓名 城市 职业 手机号 人数在Hiero里叫Token。咱这里也不强行翻译了。
Hiero里使用的token都要用大括号括起来,比如{shot} {clip},跟普通字符做区分。
群昵称改成Hiero 的Token风格就是{name}-{city}-{job}。
Token 有哪些
这些Token不是你想写成就是啥的,是Hiero给你提供的有限的几个,不能瞎写。
在Rename Shots这个功能里,可用的Token有:
{shot}: 镜头的名字{clip}: 镜头素材的名字{track}: 镜头所在track的名字{sequence}:镜头所在的sequence的名字{event}: 镜头的剪辑序号{fps}: 镜头所在sequence的fps{filename}: 镜头素材的文件名
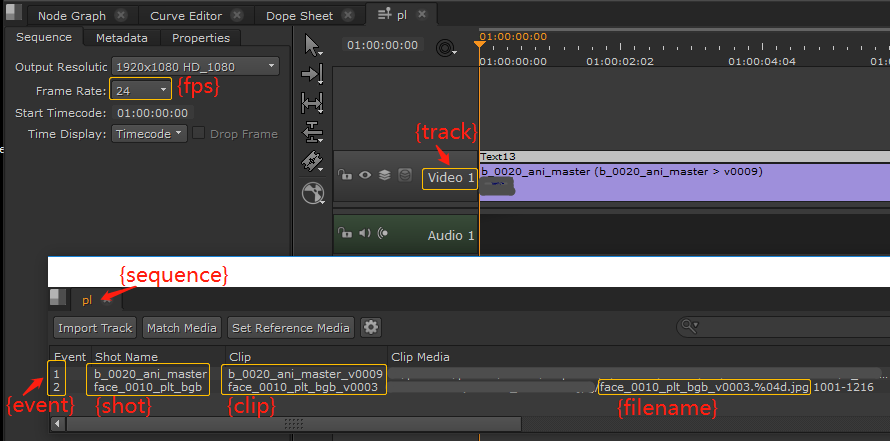
当你Rename时,Hiero对选中的镜头挨个进行操作,并将该镜头的信息带入到token中解析,将解析结果作为镜头的新名字。
类比到微信群昵称{name}-{city}-{job}:
- 当小明进群的时候,他的昵称就是
小明-北京-合成师 - 小花进群的时候,她的昵称就是
小花-上海-视效剪辑 - 懂?
前文我们介绍了Rename Shots...有6 种重命名模式:
- Simple Rename(支持
Token) - Find and Replace(支持
Token) - Sequential Rename(支持
Token) - Match Sequence
- Clip Name
- Change Case
我们拿 Simple Rename 来具体举例,它可以凭一己之力,可以取代 6 种模式的 3 种。
直接使用 Token
如果你写{clip}, 那么所有的镜头会被重命名为该镜头对应的素材名字。
等同于
Clip Name模式下的效果
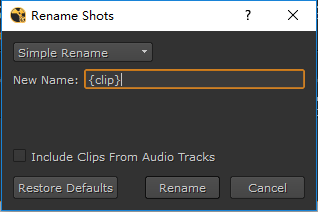
(后面我就不再截图了,都是填写在New Name那里。)
如果你写{shot},意思是把镜头重命名为镜头原来的名字,啥事也没干。
如果你写{filename},则镜头号会变成face_0010_plt_bga_v0003.1001.jpg(序列文件会显示第一帧)
除了{clip}之外,我们很少会只写一个Token,经常在次基础上做拼接。
拼接 Token
Token 可以和Token拼接,也可以和普通字符拼接。
举例
(滑动查看全部表格内容)
| Token | Result |
|---|---|
{event}{shot} |
1face_0010_plt_bga |
{shot}+{clip} |
face_0010_plt_bga+face_0010_plt_bga_v0003 |
{track}_{shot} |
pl_face_0010_plt_bga |
test_{shot} |
test_face_0010_plt_bga |
{shot}_hahaha |
face_0010_plt_bga_hahaha |
{event}_test_{shot} |
1_test_face_0010_plt_bga |
注意:大括号外面的是普通字符,写的是啥就是啥,不做修改
使用 Python 加持 Token
在这个神奇的大括号里,可以运行Python表达式!
Hiero会首先把Token替换成代表的值,然后再参与Python表达式的运算,表达式最后的值,就是最后镜头的新名字。
挨挨挨憋走!憋急着走!(尔康手
Muggle 的你不想进入魔法世界吗?
是的,你想!
下面让我们一起愉快的学一点Python知识吧!(〜^㉨^)〜
为讲解方便,下面我们都是用
{shot}来举例,换成其他Token都是可以的,根据你实际情况来选择。
索引——第x 位,出列!
索引(Index),就是给一队人(字符串),按顺序,每人发个编号,代表这个人(字符)。如下图。
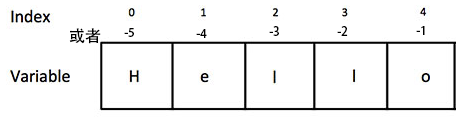
魔法世界是从第 0 位开始的。
如果我们的镜头名字叫Hello,那么
{shot[0]}就是H
{shot[3]}就是l
也可以倒着数:
{shot[-1]}就是o
{shot[-4]}就是e
如果想要He呢?{shot[0]}{shot[1]}
如果想要ello呢?我的天,要写四遍啊?!我是拒绝的,好在还有取一个范围的办法。
切片——从第x 个到第y 个,出列!
{shot[x:y]} 就是从第 x 个开始算,数到第 y 个停止,但是第 y 个不算在内。x, y 都是数字哦~
那么如果想要ello呢?可以这么写{shot[1:5]}
- 不能写
{shot[1:4]},也不能写成{shot[1:-1]}因为第 y(4/-1) 位不算在内。 - 但是不建议写成
{shot[1:5]},从某个位置开始一直到结尾,难道你还要数一下总共有多少个吗?
那怎么搞?
当我们的索引位置,是开头,或者是结尾的时候,可以省略不写哈哈哈哈
也就是说,拿到ello的常规做法是{shot[1:]}
如果想拿 He,当然可以 {shot[0]}{shot[1]},但这是初级魔法师的做法,{shot[:2]}才是优秀魔法师的做法。
E15_SZDS_V1_0120 里最后四位0120是我想要的,{shot[-4:]}给你。
重要提示:
在
Rename Shots...里不能输入:,因为这里的输入框被Hiero加了限制(截止Nuke Studio 11.2v2是这样)。但在其他地方,比如说
Export...功能那里是可以的。
我们需要换一种写法。别问为什么,照着抄吧。
{shot[1:4]}要写成{shot.__getitem__(slice(1,4))}
{shot[:4]} 要写成{shot.__getitem__(slice(4))}
{shot[2:]} 要写成{shot.__getitem__(slice(2, len(shot)))}
如果你试了没反应或者报错了,记得数一数括号有没有少...或者两个半角的下划线是不是输错了...o(>_
调整大小写——百变大小写
lower()全变小写。等同于Change case模式下的lowercase效果upper()全变大写。等同于Change case模式下的UPPERCASE效果title()变成英文标题的格式。等同于Change case模式下的Title Case效果capitalize()变成仅首字母大写。等同于Change case模式下的Capital case效果swapcase()翻转大小写,也就是大写的变小写,小写的变大写
小括号不能省哦~!
举例:
| Token | Result |
|---|---|
{shot.lower()} |
Ep01_pL_0010 -> ep01_pl_0010 |
{shot.upper()} |
Ep01_pL_0010 -> EP01_PL_0010 |
{shot.title()} |
ep01_pl_0010 -> Ep01_Pl_0010 |
{shot.capitalize()} |
ep01_pl_0010 -> Ep01_pl_0010 |
{shot.swapcase()} |
Ep01_pL_0010 -> eP01_Pl_0010 |
(滑动查看全部表格内容)
查找替换
replace(a, b) 将字符串里面的 a 字符替换成 b 字符。
等同于
Find and Replace模式
比如镜头名字叫 E15_SZDS_V1_0120 想把其中的_替换成-,则可{shot.replace('_', '-')}
比如要把镜头包含 pl 的全部替换成td,则可 {shot.replace('pl', 'td')}
注意要加引号呀!!把要查找和替换的内容包起来!
补零——我可是四位的镜头号
zfill(width) 不够 width(是个数字) 这么长的,全在左边补上0,本身就比 width 还长,就不用补了。
比如 {shot.zfill(4)}
- 2 -> 0002
- 20->0020
- 222 -> 0222
- 2310 -> 2310
- 45234 -> 45234
- ha -> 00ha
- hahaha -> hahaha
width 你可以设定为 3 等等任意数字。是不是跟入门篇的Pattern 那里很像?
真真是可惜啊,Token拿不到用户选择的镜头们的序号(跟 event 序号不一样),否则Sequential Rename模式也都可以被Simple Rename干掉!
分割
split(str) 使用str去分割。
比如E15_SZDS_V1_0120 我想要的是 V1,当然你可以{shot[9:11]}拿到,但是如果其他镜头名字叫E3_SZDS_V1_0120 呢?{shot[9:11]}得到的是_V,偏了。(冒号那里要转换成__getitem__(slice(9,11)))
这是我们观察到,这个镜头号由下划线连接而成,则可以使用
{shot.split('_')} 分割成了 E15 SZDS V1 0120 这四个部分。
如果只到此为止,你会发现,镜头名字改成了['E15', 'SZDS', 'V1', '0120']。
我们还需要进一步,拿到 V1,还记得索引吗??告诉我V1在里面是第几个?第 2 个(从 0 开始别忘了)。
改进一下 {shot.split('_')[2]} 就拿到 V1了
混合使用
上述介绍的所有用法我们可以各种组合,拿E15_SZDS_V1_0120作为 shot 。
对使用{shot.split('_')[2].lower()} ,在得到了V1后又使用了lower(),结果就是v1
也可以{shot.lower().split('_')[2]} 先 lower 再 split。
{shot.split('_')[-1].zfill(6)} -> 000120
{shot[:4].lower()}_{shot.split('_')[-1].zfill(6)} -> e15_000120
(冒号那里要转换成__getitem__(slice(4)))
当然我们大可不必非得一次搞定,可以多进行几次。
Python的字符串还有一些魔法,但是在这里不是很常用,你也可以通过https://www.runoob.com/python/python-strings.html 去多了解一下。
总结
上文说的有 3 个可被取代的模式为:
- Find and Replace 可以通过 Simple Rename 的
{shot.replace(a, b)}取代 - Clip Name 可以通过 Simple Rename
{clip}取代 - Change Case 可以通过 Simple Rename 的如下表达式取代
{shot.lower()}{shot.upper()}{shot.title()}{shot.capitalize()}
当我们拿到镜头后,观察一下。
如果镜头名字跟如下信息有关联吗,如果有,可以通过Simple Rename+Token方式,进行一次,或多次操作,得到基本的镜头名字,然后再配合Find and Replace 或者Change case进行二次调整。
如果镜头名字完全没有线索,但是好在镜头号有连续现象,可以通过Sequential Rename一段一段进行批量上号。
进一步思考
如果镜头名字跟上述信息无关,顺序还是乱七八糟没有规律:
我的新镜头名字是要从
Shotgun或ftrack里确定的呢?是要从剪辑师的剪辑工程里拿的呢?
eld里呢?xml里呢?excel/csv里呢?
可不可以我提供好新名字的列表,给我按照顺序,挨个重命名选中的镜头?
不管新名字列表的来源是Shotgun导出的csv也好,edl/xml 也好,甚至是自己在excel里手动输入的也好,全部处理成,一个镜头名字一行的纯文本,复制镜头名字到剪切板,然后有个工具,咔嚓一下,就把剪切板里的镜头名字,按顺序加到选中的镜头上。完工。
对,这个工具就是下一篇要更新的。
等一下!
我能发明自己的
Token吗?当然可以!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://bianchenghao.cn/bian-cheng-ji-chu/97944.html